使用pca/lda降维
PCA主成分分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 用鸢尾花数据集 展示 降维的效果
from sklearn.datasets import load_iris
iris = load_iris()
data = iris.data # 特征值
target = iris.target # 目标值
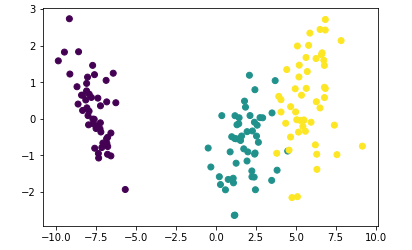
# 绘制平面散点图
plt.scatter(data[:,0],data[:,1],c=target)# 如果要想分类准确 需要考虑所有特征
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(data,target,test_size=0.1)
from sklearn.neighbors import KNeighborsClassifier
X_train,X_test,y_train,y_test = train_test_split(data,target,test_size=0.1)
KNeighborsClassifier().fit(X_train,y_train).score(X_test,y_test)
如果只是打分一次 会有很多偶然因素
所以 应该 做交叉验证
# 定义一个函数 调用函数 传入 模型 数据集的特征值和目标值
# 函数内部会按照 多个比例 对数据集进行切分 然后获取平均分
def cross_verify(model,data,target):
scores = []
# 按照不同比例去切分 训练集 和 测试集
for i in np.arange(0.1,0.2,0.01):
X_train,X_test,y_train,y_test = train_test_split(data,target,test_size=i)
score = model.fit(X_train,y_train).score(X_test,y_test)
# 把每次打分 加入到分数列表中
scores.append(score) return np.array(scores).mean()
cross_verify(KNeighborsClassifier(),data,target) # 94-97之间 # 0.981
使用PCA来对数据进行降维
# decomposition 分解
from sklearn.decomposition import PCA
# 获取
# n_components 用来控制保留多少个特征 可以传入整数表示保留特征的个数 还可以传入小数表示保留的特征的比例
pca = PCA(n_components=2)
# 训练模型
pca.fit(data) # pca只是找当前数据自身内部的最大差异 不关心各种分类之间的差别 所以只传入data即可 target可以不传
data.shape # 150个样本 4个特征
# 对高维度的数据 进行降维 转换
pca_data = pca.transform(data)
# pca.fit_transform
pca_data.shape # 样本还是原来的样本 只是特征从4个压缩到了2个
对比散点图
plt.scatter(data[:,0],data[:,1],c=target)

plt.scatter(pca_data[:,0],pca_data[:,1],c=target)
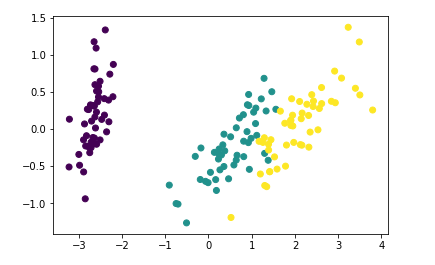
cross_verify(KNeighborsClassifier(),pca_data,target) # 降低维度是否会影响准确率呢 95-97 大部分情况下降维并不会影响准确率 而且会提高速度
LDA
# discriminant_analysis判别分析
# 线性判别分析 LinearDiscriminantAnalysis
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(data,target) # lda是要查看 各个分类之间的差异 所以需要传入各个样本的分类的目标值
lda_data = lda.transform(data)
# lda.fit_transform
对比散点图
plt.scatter(pca_data[:,0],pca_data[:,1],c=target)
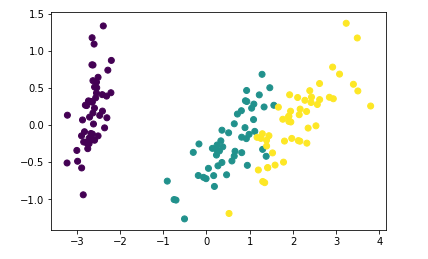
plt.scatter(lda_data[:,0],lda_data[:,1],c=target)
cross_verify(KNeighborsClassifier(),lda_data,target) # 使用lda进行降维 也不会对准确率产生很大影响
使用pca/lda降维的更多相关文章
- 用scikit-learn进行LDA降维
在线性判别分析LDA原理总结中,我们对LDA降维的原理做了总结,这里我们就对scikit-learn中LDA的降维使用做一个总结. 1. 对scikit-learn中LDA类概述 在scikit-le ...
- sklearn LDA降维算法
sklearn LDA降维算法 LDA(Linear Discriminant Analysis)线性判断别分析,可以用于降维和分类.其基本思想是类内散度尽可能小,类间散度尽可能大,是一种经典的监督式 ...
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- PCA和LDA降维的比较
PCA 主成分分析方法,LDA 线性判别分析方法,可以认为是有监督的数据降维.下面的代码分别实现了两种降维方式: print(__doc__) import matplotlib.pyplot as ...
- KNN PCA LDA
http://blog.csdn.net/scyscyao/article/details/5987581 这学期选了门模式识别的课.发现最常见的一种情况就是,书上写的老师ppt上写的都看不懂,然后绕 ...
- 运用PCA进行降维的好处
运用PCA对高维数据进行降维,有一下几个特点: (1)数据从高维空间降到低维,因为求方差的缘故,相似的特征会被合并掉,因此数据会缩减,特征的个数会减小,这有利于防止过拟合现象的出现.但PCA并不是一种 ...
- PCA数据降维
Principal Component Analysis 算法优缺点: 优点:降低数据复杂性,识别最重要的多个特征 缺点:不一定需要,且可能损失有用的信息 适用数据类型:数值型数据 算法思想: 降维的 ...
- 初识PCA数据降维
PCA要做的事降噪和去冗余,其本质就是对角化协方差矩阵. 一.预备知识 1.1 协方差分析 对于一般的分布,直接代入E(X)之类的就可以计算出来了,但真给你一个具体数值的分布,要计算协方差矩阵,根据这 ...
随机推荐
- kafka8 编写简单消费者
1.eclipse运行消费者代码.代码如下 package cn.test.mykafka; import java.util.Arrays; import java.util.Properties; ...
- [js]变量提升-关于条件
条件函数变量提示于全局中函数变量提升不一样. 条件中: 函数变量提升, 只是声明(现新版本浏览器中) if(g()){ function g() { return true } console.log ...
- 安装和使用ZFS
一.安装和使用ZFS Centos7上安装和使用ZFS:https://blog.csdn.net/linuxnews/article/details/51286358
- NLP:Gensim库之word2vec
Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达.它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法, ...
- mongoose findByIdAndUpdate不执行的解决方法
请参考Mongoose的文档 1.findOneAndUpdate([query], [doc], [options], [callback]) 有callback传递才执行. 2.exec是prom ...
- Scrapy框架的学习(6.item介绍以及items的使用(提前定义好字段名))转载https://blog.csdn.net/wei18791957243/article/details/86259688
在Scrapy框架中的items.py的作用 1.可以预先定义好要爬取的字段 items.py import scrapy class TencentItem(scrapy.I ...
- 让sublime可以和visual studio一样自动在运算符前后添加空格的插件
用过vs的人都知道,vs会自动在代码中运算符的前后加空格,比如 i=1; 换行后会自动变成i = 1; 开始觉得这个挺烦的,后来习惯了,发现这个功能还是挺好的,然代码更清晰. 最近换了sublimet ...
- 改变FileUpload文件上传控件的显示方式,选择文件后自动上传
一.Aspx页面: <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="File ...
- flutter key
随意点开一个Widget,就会发现,可以传递一个参数Key.那这个Key到底是干啥子,有什么用呢? Flutter是受React启发的,所以Virtual Dom的diff算法也参考过来了(应该是略有 ...
- 【题解】Luogu P4054 [JSOI2009]计数问题
原题传送门 我自闭了qaq 这道题非常简单,因为1<=c<=100,所以直接对每个c开二维树状数组,操作就跟模板一样 写码5分钟,调码半小时,这道题的输入顺序是x1,x2,y1,y2,我真 ...