『TensorFlow』网络操作API_中_损失函数及分类器



一、误差值
度量两个张量或者一个张量和零之间的损失误差,这个可用于在一个回归任务或者用于正则的目的(权重衰减)。
l2_loss
tf.nn.l2_loss(t, name=None)解释:这个函数的作用是利用 L2 范数来计算张量的误差值,但是没有开方并且只取 L2 范数的值的一半,具体如下:
output = sum(t ** 2) / 2输入参数:
t: 一个Tensor。数据类型必须是一下之一:float32,float64,int64,int32,uint8,int16,int8,complex64,qint8,quint8,qint32。虽然一般情况下,数据维度是二维的。但是,数据维度可以取任意维度。name: 为这个操作取个名字。输出参数:
一个
Tensor,数据类型和t相同,是一个标量。
使用例子
#!/usr/bin/env python
# -*- coding: utf-8 -*- import numpy as np
import tensorflow as tf input_data = tf.Variable( np.random.rand(2, 3), dtype = tf.float32 )
output = tf.nn.l2_loss(input_data)
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print sess.run(input_data)
print sess.run(output)
print sess.run(tf.shape(output))
二、分类器
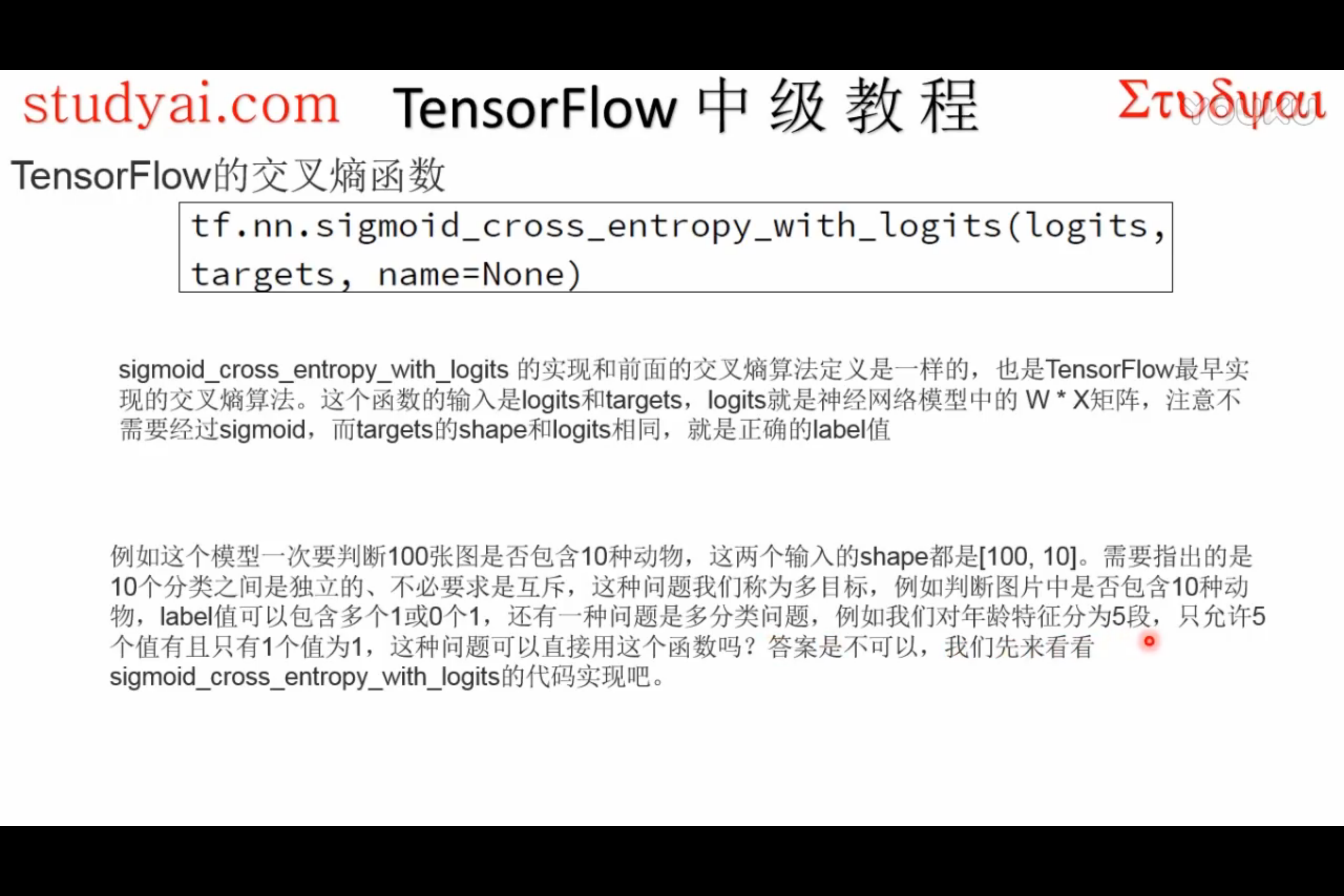
sigmoid_cross_entropy_with_logits
sigmoid_cross_entropy_with_logits
tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None)解释:这个函数的作用是计算
logits经 sigmoid 函数激活之后的交叉熵。对于一个不相互独立的离散分类任务,这个函数作用是去度量概率误差。比如,比如,在一张图片中,同时包含多个分类目标(大象和狗),那么就可以使用这个函数。
为了描述简洁,我们规定
x = logits,z = targets,那么 Logistic 损失值为:x - x * z + log( 1 + exp(-x) )为了确保计算稳定,避免溢出,真实的计算实现如下:
max(x, 0) - x * z + log(1 + exp(-abs(x)) )输入参数:
logits: 一个Tensor。数据类型是以下之一:float32或者float64。targets: 一个Tensor。数据类型和数据维度都和logits相同。name: 为这个操作取个名字。输出参数:
一个
Tensor,数据维度和logits相同。
使用例子:
#!/usr/bin/env python
# -*- coding: utf-8 -*- import numpy as np
import tensorflow as tf input_data = tf.Variable( np.random.rand(1,3), dtype = tf.float32 )
output = tf.nn.sigmoid_cross_entropy_with_logits(input_data, [[1.0,0.0,0.0]])
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print sess.run(input_data)
print sess.run(output)
print sess.run(tf.shape(output))
早期使用,后来多使用softmax。

softmax
tf.nn.softmax(logits, name=None)解释:这个函数的作用是计算 softmax 激活函数。
对于每个批
i和 分类j,我们可以得到:softmax[i, j] = exp(logits[i, j]) / sum(exp(logits[i]))输入参数:
logits: 一个Tensor。数据类型是以下之一:float32或者float64。数据维度是二维[batch_size, num_classes]。name: 为这个操作取个名字。输出参数:
一个
Tensor,数据维度和数据类型都和logits相同。
使用例子:
#!/usr/bin/env python
# -*- coding: utf-8 -*- import numpy as np
import tensorflow as tf input_data = tf.Variable( [[0.2, 0.1, 0.9]] , dtype = tf.float32 )
output = tf.nn.softmax(input_data)
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print sess.run(input_data)
print sess.run(output)
print sess.run(tf.shape(output))
log_softmax
tf.nn.log_softmax(logits, name=None)解释:这个函数的作用是计算 softmax 激活函数。
对于每个批
i和 分类j,我们可以得到:softmax[i, j] = log(exp(logits[i, j]) / sum(exp(logits[i])))输入参数:
logits: 一个Tensor。数据类型是以下之一:float32或者float64。数据维度是二维[batch_size, num_classes]。name: 为这个操作取个名字。输出参数:
一个
Tensor,数据维度和数据类型都和logits相同。
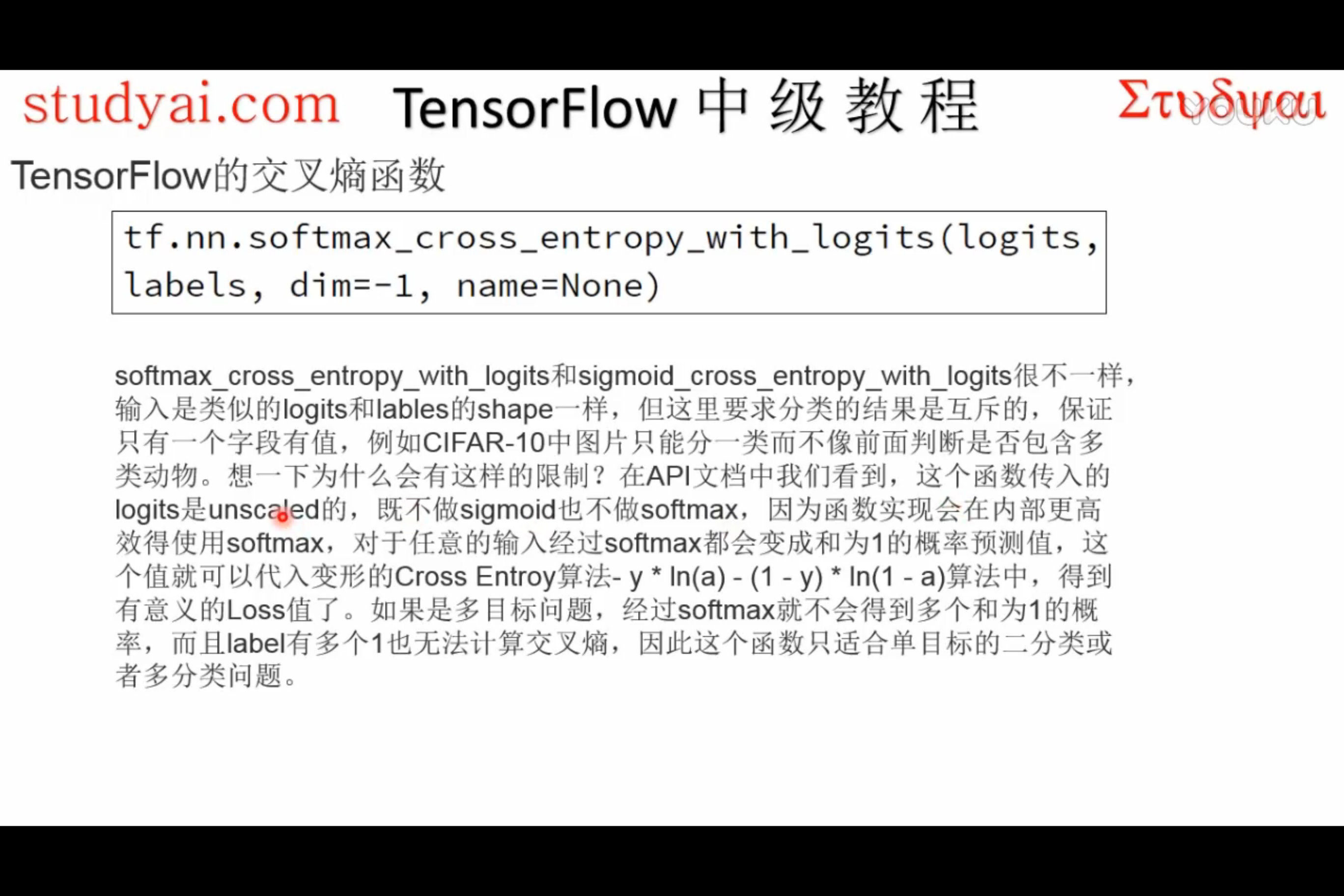
softmax_cross_entropy_with_logits
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)解释:这个函数的作用是计算
logits经 softmax 函数激活之后的交叉熵。对于每个独立的分类任务,这个函数是去度量概率误差。比如,在 CIFAR-10 数据集上面,每张图片只有唯一一个分类标签:一张图可能是一只狗或者一辆卡车,但绝对不可能两者都在一张图中。(这也是和
tf.nn.sigmoid_cross_entropy_with_logits(logits, targets, name=None)这个API的区别)警告:输入API的数据
logits不能进行缩放,因为在这个API的执行中会进行 softmax 计算,如果logits进行了缩放,那么会影响计算正确率。不要调用这个API区计算 softmax 的值,因为这个API最终输出的结果并不是经过 softmax 函数的值。
logits和labels必须有相同的数据维度[batch_size, num_classes],和相同的数据类型float32或者float64。
使用例子:
#!/usr/bin/env python
# -*- coding: utf-8 -*- import numpy as np
import tensorflow as tf input_data = tf.Variable( [[0.2, 0.1, 0.9]] , dtype = tf.float32 )
output = tf.nn.softmax_cross_entropy_with_logits(input_data, [[1,0,0]])
with tf.Session() as sess:
init = tf.initialize_all_variables()
sess.run(init)
print sess.run(input_data)
print sess.run(output)
print sess.run(tf.shape(output))

sparse_softmax_cross_entropy_with_logits
tf.nn.sparse_softmax_cross_entropy_with_logits(logits, labels, name=None)解释:这个函数的作用是计算
logits经 softmax 函数激活之后的交叉熵,同softmax_cross_entropy_with_logits,只是logits的shape是[batch, class], label的shape是[batch],不用人为one_hot编码。
weighted_cross_entropy_with_logits

『TensorFlow』网络操作API_中_损失函数及分类器的更多相关文章
- 『TensorFlow』网络操作API_上
简书翻译原文 卷积层 卷积操作是使用一个二维的卷积核在一个批处理的图片上进行不断扫描.具体操作是将一个卷积核在每张图片上按照一个合适的尺寸在每个通道上面进行扫描.为了达到好的卷积效率,需要在不同的通道 ...
- 『TensorFlow』网络操作API_下
一.优化器基类介绍 标注一点,优化器中的学习率可以是tensor,这意味着它可以feed, learning_rate: A Tensor or a floating point value. 正常使 ...
- 『TensorFlow』SSD源码学习_其一:论文及开源项目文档介绍
一.论文介绍 读论文系列:Object Detection ECCV2016 SSD 一句话概括:SSD就是关于类别的多尺度RPN网络 基本思路: 基础网络后接多层feature map 多层feat ...
- 『TensorFlow』SSD源码学习_其五:TFR数据读取&数据预处理
Fork版本项目地址:SSD 一.TFR数据读取 创建slim.dataset.Dataset对象 在train_ssd_network.py获取数据操作如下,首先需要slim.dataset.Dat ...
- 『TensorFlow』SSD源码学习_其二:基于VGG的SSD网络前向架构
Fork版本项目地址:SSD 参考自集智专栏 一.SSD基础 在分类器基础之上想要识别物体,实质就是 用分类器扫描整张图像,定位特征位置 .这里的关键就是用什么算法扫描,比如可以将图片分成若干网格,用 ...
- 『TensorFlow』SSD源码学习_其八:网络训练
Fork版本项目地址:SSD 作者使用了分布式训练的写法,这使得训练部分代码异常臃肿,我给出了部分注释.我对于多机分布式并不很熟,而且不是重点,所以不过多介绍,简单的给出一点训练中作者的优化手段,包含 ...
- 『TensorFlow』SSD源码学习_其四:数据介绍及TFR文件生成
Fork版本项目地址:SSD 一.数据格式介绍 数据文件夹命名为VOC2012,内部有5个子文件夹,如下, 我们的检测任务中使用JPEGImages文件夹和Annotations文件夹. JPEGIm ...
- 『TensorFlow』SSD源码学习_其三:锚框生成
Fork版本项目地址:SSD 上一节中我们定义了vgg_300的网络结构,实际使用中还需要匹配SSD另一关键组件:被选取特征层的搜索网格.在项目中,vgg_300网络和网格生成都被统一进一个class ...
- 『TensorFlow』SSD源码学习_其七:损失函数
Fork版本项目地址:SSD 一.损失函数介绍 SSD损失函数分为两个部分:对应搜索框的位置loss(loc)和类别置信度loss(conf).(搜索框指网络生成的网格) 详细的说明如下: i指代搜索 ...
随机推荐
- 图像分类(三)GoogLenet Inception_v3:Rethinking the Inception Architecture for Computer Vision
Inception V3网络(注意,不是module了,而是network,包含多种Inception modules)主要是在V2基础上进行的改进,特点如下: 将滤波器尺寸(Filter Size) ...
- keras实现textcnn
https://github.com/MoyanZitto/keras-cn/blob/master/docs/legacy/blog/word_embedding.md 这个链接将带有embedin ...
- webdriver入门-Java
webdriver入门-Java 如何用webdriver打开一个浏览器,我们常用的浏览器有firefox和IE两种,firefox是selenium支持得比较成熟的浏览器,很多新的特性都会在fi ...
- WIN7搭建ASP站点
在WIN7配置IIS用于搭建ASP站点(非ASP.NET) ,仅安装.配置必要文件. 1.安装IIS管理工具,用于支持静态页面. 2.添加匿名访问权限. 搭建站点指定到特定文件夹,浏览静态页面会报如下 ...
- break,continue的区别
break 终止循环, continue 跳出本次循环,进入下一次循环 username = 'Loker'passwd = '123456' for i in range(3): user = in ...
- Java中 == 和 equals 的问题
== : 它的作用是判断两个对象的地址是不是相等.即,判断两个对象是不是同一个对象.(基本数据类型==比较的是值,引用数据类型==比较的是内存地址) equals() : 它的作用也是判断两个对象是否 ...
- POJ 2533 裸的LIS
A numeric sequence of ai is ordered if a1 < a2 < ... < aN. Let the subsequence of the given ...
- 正则表达式 re.findall 用法
正则 re.findall 的简单用法(返回string中所有与pattern相匹配的全部字串,返回形式为数组)语法: findall(pattern, string, flags=0) import ...
- 当SQL Server的实例位于集群的特定节点时,数据库无法远程访问
搭建好了一个集群环境,发现当SQL Server的实例位于集群的其中一个节点时,数据库无法远程访问,报如下错误.但在另一个 节点时,数据库访问正常. 标题: 连接到服务器 -------------- ...
- C#简单的九九乘法表
for(int i=1;i<10;i++) { for(int j=1;j<=i;j++) { Console.Write("{0}*{1}={2}",j,i,i*j) ...