Mybatis的延迟加载和缓存
1. MyBatis中的延迟加载,也称为懒加载,是指在进行关联查询时,按照设置延迟加载规则推迟对关联对象的select查询。延迟加载可以有效的减少数据库压力。
注意:MyBatis的延迟加载只是对关联对象的查询有延迟设置,对于主加载对象都是直接执行查询语句的。
2.MyBatis根据对关联对象查询的select语句的执行时机,分为3种类型:
直接加载
侵入式延迟加载
深度延迟加载
直接加载
执行完对主加载对象的select语句,马上执行对关联对象的select查询
侵入是延迟
执行对主加载对象的查询时,不会执行对关联对象的查询。但是当要访问主加载对象的详情时,就会马上执行关联对象的select查询。即对关联对象的查询执行,侵入到了主加载对象的详情访问中。也可以这样理解:将关联对象的详情侵入到了主加载对象的详情中,即将关联对象的详情作为主加载对象详情的一部分出现了
深度延迟
执行对主加载对象的查询时,不会执行对关联对象的查询。访问主加载对象的详情时也不会执行关联对象的select查询。只有当真正访问关联对象的详情时,才会执行对关联对象的select查询。
注意:延迟加载的应用要求:关联对象的查询与主加载对象的查询必须是分别进行的select语句,不能是使用多表连接所进行的select查询。因为,多表连接查询,实质是对一张表的查询,对由多个表连接后形成的一张表的查询。会一次性将多张表的所有信息查询出来。
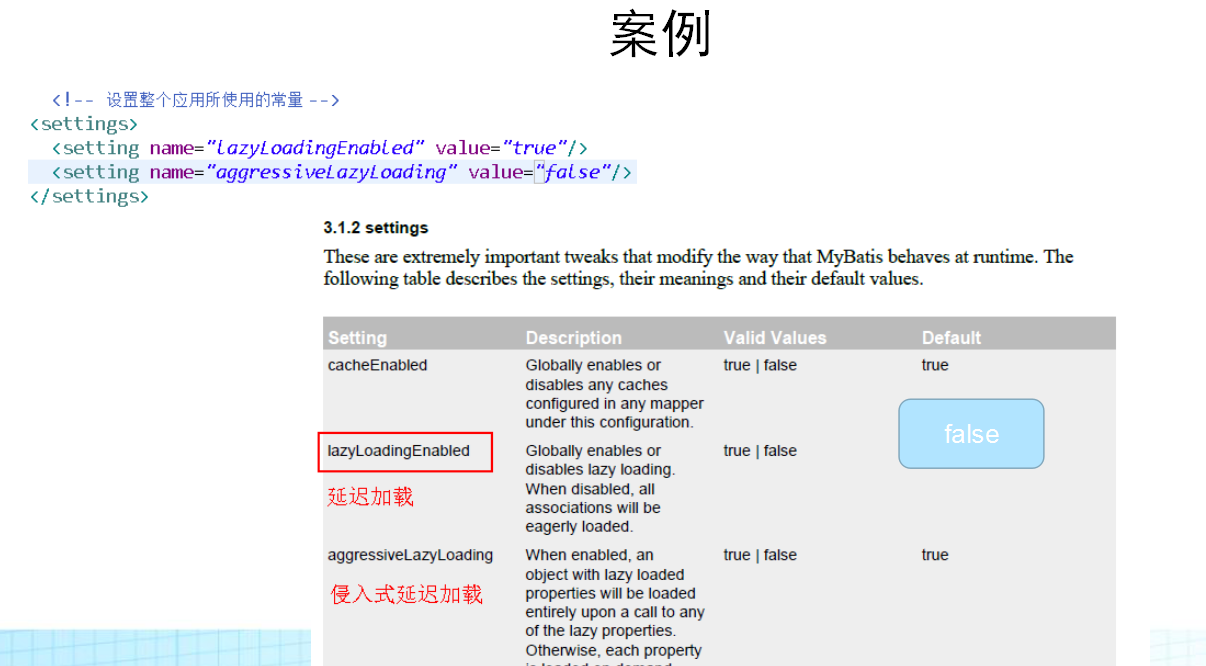
查询缓存
查询缓存的使用,主要是为了提供查询访问速度。将用户对同一数据的重复查询过程简化,不再每次均从数据库查询获取结果数据,从而提高访问速度。
缓存的说明
MyBatis查询缓存机制。根据缓存区的作用域与生命周期,可划分为两种:一级缓存和二级缓存。
MyBatis查询缓存的作用域是根据映射文件的namespace划分的,相同的namespace的mapper查询数据放在同一个缓存区域。不同namespace下的数据互不干扰。无论是一级缓存还是二级缓存,都是按照namespace进行分别存放的。
但是一级、二级缓存的不同之处在于,SqlSession一旦关闭,则SqlSession中的数据将不存在,即一级缓存就不复存在。而二级缓存的生命周期与整个应用同步,与SqlSession是否关闭无关。换句话说,一级缓存是在同一线程(同一SqlSession)间共享数据,而二级缓存是在不同线程(不同的SqlSession)间共享数据。
一级缓存存在性的证明:
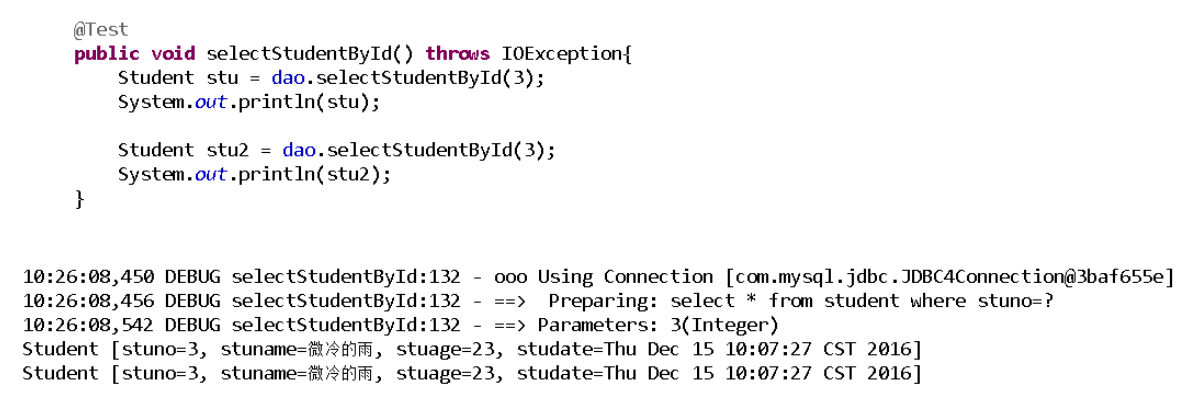
一级缓存---从缓存中查找数据的依据
缓存的底层实现是一个Map,Map的value是查询结果
Map的key,即查询依据,使用的ORM架构不同,查询依据是不同的
MyBatis的查询依据是:Sql的id+SQL语句
Hibernate的查询依据是:查询结果对象的id
增删改对一级缓存的影响:
增删改会清空一级缓存
MyBatis缓存:
1. 一级缓存: 基于PerpetualCache 的 HashMap本地缓存,其生命周期为 Session,当 Session flush 或 close 之后,该Session中的所有 Cache 就将清空。
2. 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。
3. 对于缓存数据更新机制,当某一个作用域(一级缓存Session/二级缓存Namespaces)进行了 C/U/D 操作后,默认该作用域下所有 select 中的缓存将被clear。
开启二级缓存的三个条件
1.你cacheEnabled=true,默认值为true
2.你得在Mapper文件中,<cache/>
3.Entity Implements Serializable
增删改对二级缓存的影响
1.增删改也会清空二级缓存
2.对于二级缓存的清空实质上是对value清空为null,key依然存在,并非将Entry<k,v>删除
3.从DB中进行select查询的条件是:
1.缓存中根本不存在这个key
2.存在key对应的Entry,但是value为null
二级缓存的配置
<cache
eviction="FIFO"
flushInterval="60000"
size="512"
readOnly="true"/>
这个更高级的配置创建了一个 FIFO 缓存,并每隔 60 秒刷新,存数结果对象或列表的 512 个引用,
而且返回的对象被认为是只读的
可用的回收策略
LRU – 最近最少使用的:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
默认的是 LRU。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒
形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的
可用内存资源数目。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回
缓 存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。
可读写的缓存 会返回缓存对象的拷贝(通过序列化) 。这会慢一些,但是安全,因此默认是 false。
Mybatis的延迟加载和缓存的更多相关文章
- Mybatis(五) 延迟加载和缓存机制(一级二级缓存)
踏踏实实踏踏实实,开开心心,开心是一天不开心也是一天,路漫漫其修远兮. --WH 一.延迟加载 延迟加载就是懒加载,先去查询主表信息,如果用到从表的数据的话,再去查询从表的信息,也就是如果没用到从表的 ...
- MyBatis的延迟加载和缓存机制
延迟加载: 什么是延迟加载: MyBatis中的延迟加载,也称为懒加载,是指在进行关联查询时,按照设置延迟规则推迟对关联对象的select查询.延迟加载可以有效的减少数据库压力. MyBatis根据对 ...
- mybatis 配置延迟加载 和 缓存
<!-- MyBatis延迟加载时,创建代理类 --> <dependency> <groupId>cglib</groupId> <artifa ...
- Mybatis学习(五)————— 延迟加载和缓存机制(一级二级缓存)
一.延迟加载 延迟加载就是懒加载,先去查询主表信息,如果用到从表的数据的话,再去查询从表的信息,也就是如果没用到从表的数据的话,就不查询从表的信息.所以这就是突出了懒这个特点.真是懒啊. Mybati ...
- mybatis的延迟加载、一级缓存、二级缓存
mybatis的延迟加载.一级缓存.二级缓存 mybatis是什么? mybatis是一个持久层框架,是apache下的开源项目,前身是itbatis,是一个不完全的ORM框架,mybatis提供输入 ...
- Mybatis延迟加载、缓存
一.Mybatis中的延迟加载 1.延迟加载背景:Mybatis中Mapper配置文件中的resultMap可以实现高级映射(使用association.collection实现一对一及一对多(多对多 ...
- mybatis教程5(延迟加载和缓存)
关联关系 在关系型数据库中,表与表之间很少是独立与其他表没关系的.所以在实际开发过程中我们会碰到很多复杂的关联关系.在此我们来分析下载mybatis中怎么处理这些关系 1对1关系 我们有一张员工表(T ...
- MyBatis延迟加载和缓存(4)
一.项目创建 1.项目目录结构 2.数据库配置和上一篇的一样,这里不再描述.下面创建mybatis配置文件SqlMapConfig.xml <?xml version="1.0&quo ...
- mybatis的一对一,一对多查询,延迟加载,缓存介绍
一对一查询 需求 查询订单信息关联查询用户信息 sql语句 /*通过orders关联查询用户使用user_id一个外键,只能关联查询出一条用户记录就可以使用内连接*/ SELECT orders.*, ...
随机推荐
- ps和AI使用过程中的易错点整理
ps:1.视图工具:1)标尺2)参考线3)网格:视图-->--显示>-->网格4)修改网格:编辑-->首选项>-->参考线.网格和切片 5)放大工具:画布中单击可放 ...
- NPOI操作Excel(一)--NPOI基础
用C#读取Excel的方法有很多中,由于近期工作需要,需要解析的Excel含有合并单元格以及背景色等特殊要求,故在网上查了一些关于读Excel的方法的优缺点,觉得NPOI能满足我的需要,所以搜索了一些 ...
- c++ 链表基础功能实现
#include<stack> struct ListNode { int m_nValue; ListNode* m_pNext; }; ListNode* CreateListNode ...
- 步步为营-104-Lambda语句
1:Lambda的拼接 首先借助一个Lambda的帮助类 using System; using System.Collections.Generic; using System.Linq; usin ...
- SQL语法汇总
以下默认为mySQL与SQLsever都能使用SQLsever不能使用的另外标出来了 显示数据库SHOW DATABASES;进入其中一个数据库USE students;显示进入数据库中的所有表SHO ...
- java基础应用循环的应用
1.1 [经典面试题]: &&(短路与)与&(非短路与)的区别: 表达式1 && 表达式2 表达式1如果为false,表达式2不执行,整个表达式结果为false ...
- vue 踩坑记录
1.绑定双击事件用 @dblclick 不要用@ondblclick 在vue中@=on 2.Vue中路由跳转踩坑. 比如我的路由如下定义 routes: [ { path: "/&quo ...
- [转]MySQL 数据类型(float)的注意事项
http://www.cnblogs.com/zhoujinyi/archive/2013/04/26/3043160.html 可能由于版本关系,我的mysql5.7插入数据超过范围时会提示,126 ...
- Asp.net MVC - 使用PRG模式(附源码)
阅读目录: 一. 传统的Asp.net页面问题 二.Asp.net MVC中也存在同样的问题 三.使用PRG模式 四.PRG模式在MVC上的实现 一. 传统的Asp.net页面问题 一个传统的Asp. ...
- 再理解tcp backlog
在Linux 2.2以前,backlog大小包括了半连接状态和全连接状态两种队列大小.linux 2.2以后,分离为两个backlog来分别限制半连接SYN_RCVD状态的未完成连接队列大小跟全连接E ...