NodeJS简单爬虫
NodeJS简单爬虫
- 最近一直在追火星的一本书,然后每次都要去网站看,感觉很麻烦,于是,想起用爬虫爬取章节,务实派,说干就干!
爬取思路
- 1、该网站的页面呈现出一定的规律
- 2、使用NodeJS的request模块发起请求
- 3、对获取到的数据进行处理
- 4、使用NodeJS的fs模块将数据写入文件
源码说明
//声明需要的模块
var request = require('request');
var fs=require("fs");
//小说章节的标题
var title="";
//小说章节的内容
var article="";
//对应的网页序号
var i=1;
//写入流
var ws;
var get=()=>{
//发起请求
request('http://www.nitianxieshen.com/'+i+'.html', function (error, response, body) {
try{
if (!error && response.statusCode == 200) {
//截取标题与段落
title = body.match(/<div class="post_title">([\s\S]*)<\/h1>/i)[0].split("</div>")[0];
article = body.match(/<div class="post_entry">([\s\S]*)<\/div>/i)[0].split("</div>")[0];
//去除多余的符号
title=title.replace("h1", "").replace("h1", "").replace(/[</a-z_"=>\r\n ]/g, "");
article=article.replace(/br/g, "\r\n").replace(/[</a-z1=_".:&;>]/g, "");
ws=fs.createWriteStream(title+".txt");
ws.write(title+"\r\n\r\n","utf8");
ws.write(article,"utf8");
ws.end();
console.log(title+".txt"+" 正在写入...");
ws.on("finish", ()=>console.log("写入完成!"));
ws.on("error", ()=>console.log("写入错误!"));
}
}catch(err){
//部分章节的序号不连续,不要停止,等待自动爬取完就好,打印出该log后自动无视掉
//好吧,其实后面有一段挺长的不连续的...有兴趣的可以再加个判断条件
console.log("本次爬取失败");
//目前更新的最新章节序号未到2900,确保能爬取完
if(i>2900) clearInterval(timer);
}
})
}
var timer=setInterval(function(){
get();
i++;
}, 2000);//爬取的间隔时间不建议太短,1~2秒比较保险
效果
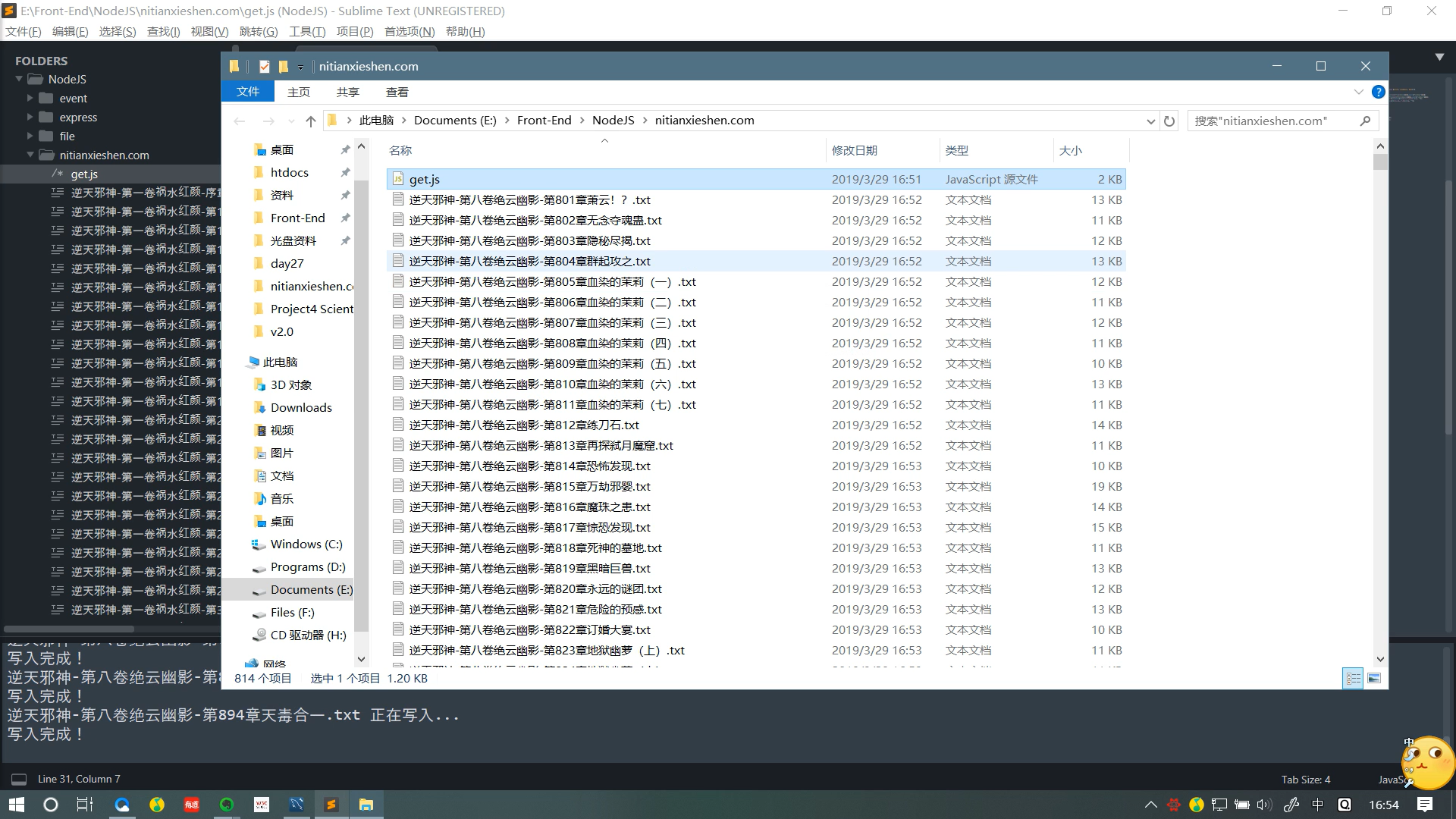
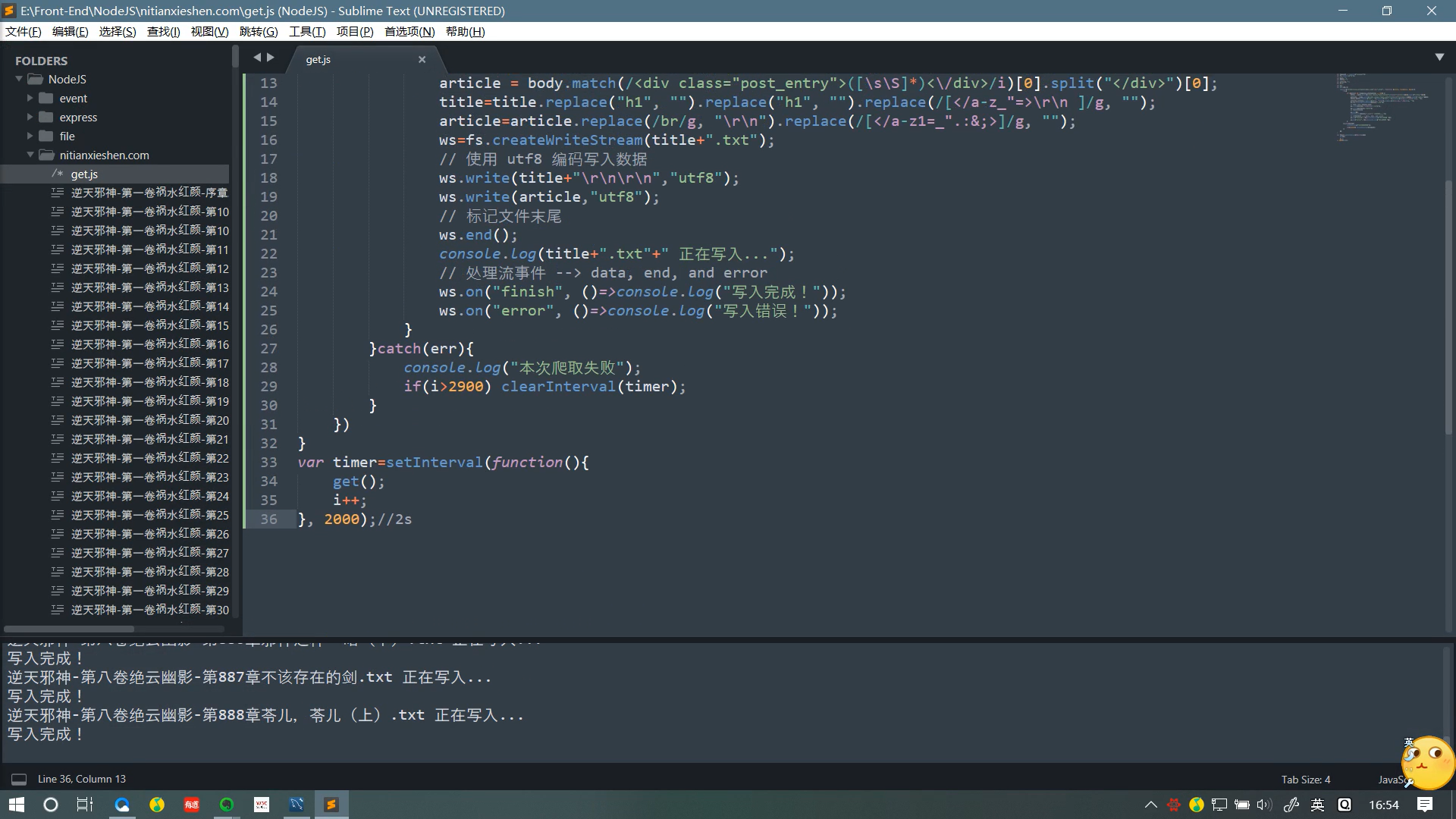
声明
- 本文章仅供学习,爬取的资源请在爬取后的24小时内删除,勿将爬取到的东西商用,喜欢火星的可以支持火星哈。
NodeJS简单爬虫的更多相关文章
- nodejs的简单爬虫
闲聊 好久没写博客了,前几天小颖在朋友的博客里看到了用nodejs的简单爬虫.所以小颖就自己试着做了个爬博客园数据的demo.嘻嘻...... 小颖最近养了条泰日天,自从养了我家 ...
- nodejs实现简单爬虫
nodejs结合cheerio实现简单爬虫 let cheerio = require("cheerio"), fs = require("fs"), util ...
- NodeJS制作爬虫全过程
这篇文章主要介绍了NodeJS制作爬虫的全过程,包括项目建立,目标网站分析.使用superagent获取源数据.使用cheerio解析.使用eventproxy来并发抓取每个主题的内容等方面,有需要的 ...
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- [Java]使用HttpClient实现一个简单爬虫,抓取煎蛋妹子图
第一篇文章,就从一个简单爬虫开始吧. 这只虫子的功能很简单,抓取到”煎蛋网xxoo”网页(http://jandan.net/ooxx/page-1537),解析出其中的妹子图,保存至本地. 先放结果 ...
- 简单爬虫,突破IP访问限制和复杂验证码,小总结
简单爬虫,突破复杂验证码和IP访问限制 文章地址:http://www.cnblogs.com/likeli/p/4730709.html 好吧,看题目就知道我是要写一个爬虫,这个爬虫的目标网站有 ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- python 简单爬虫diy
简单爬虫直接diy, 复杂的用scrapy import urllib2 import re from bs4 import BeautifulSoap req = urllib2.Request(u ...
随机推荐
- windows、Linux同步外网NTP服务器时间
配置 Windows 时间服务以使用外部时间源 要将内部时间服务器配置为与外部时间源同步,请使用以下方法之一: 软件自动配置 Windows 时间服务 若要自动修复此问题,请单击“下载”按钮. 在“ ...
- CentOS7使用ZFS文件系统
默认情况下,CentOS7并没有含ZFS支持的文件和,需要进行更新和安装第三方库. Step 1:安装第三方库和更新系统 [root@localhost ~]# rpm -Uvh http://www ...
- 算法练习LeetCode初级算法之数组
删除数组中的重复项 官方解答: 旋转数组 存在重复元素 只出现一次的数 官方解答: 同一个字符进行两次异或运算就会回到原来的值 两个数组的交集 II import java.util.Arr ...
- react项目搭建
1.下载安装node.js,需要node.js环境. 2.经过挑选,决定选择creat-react-app这个项目脚手架,然后输入指令安装 $ npm install -g crea ...
- node.js中使用 http-proxy 创建代理服务器
代理,也称网络代理,是一种特殊网络服务,允许一个终端通过代理服务与另一个终端进行非直接的连接,这样利于安全和防止被攻击. 代理服务器,就是代理网络用户去获取网络信息,就是信息的中转,负责转发. 代理又 ...
- win10下使用wget
一.下载 官网:http://gnuwin32.sourceforge.net/packages/wget.htm 下载地址:http://downloads.sourceforge.net/gnuw ...
- webplus知识点小结
1.返回首页,要在首页栏目里面加链接,直接预览站点的时候地址栏那个地址就行 2.上传图片变色问题,要传jpg格式,不要png 3.留言板制作:后台组件管理->留言板->获取链接 然后在留言 ...
- zeromq示例代码
http://www.oschina.net/code/snippet_614253_55034 将zeromq代码使用vc集中到一个解决方案中 可编译可调调试 vc2015
- 安装及使用virtualenv
安装tensorflow之virtualenv 在安装之前首先保证ubuntu.python,以及一些相应的包安装成功. 1.安装virtualenv#(1) pip $ sudo apt-get i ...
- VM下载安装
VM下载 VM是一款收费软件,要找有密钥的下载. 我的网盘 > 软件 > 常用电脑工具 > VM VM安装 参考链接中的安装步骤 http://blog.java1234.com/b ...