使用request爬取拉钩网信息
通过cookies信息爬取
分析header和cookies
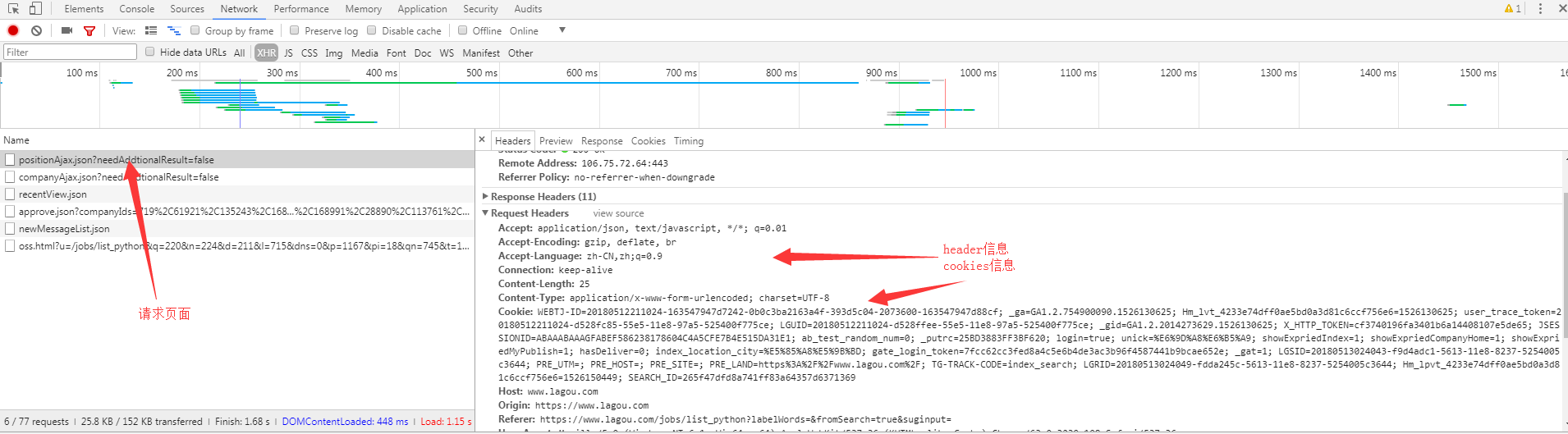
通过subtext粘贴处理header和cookies信息
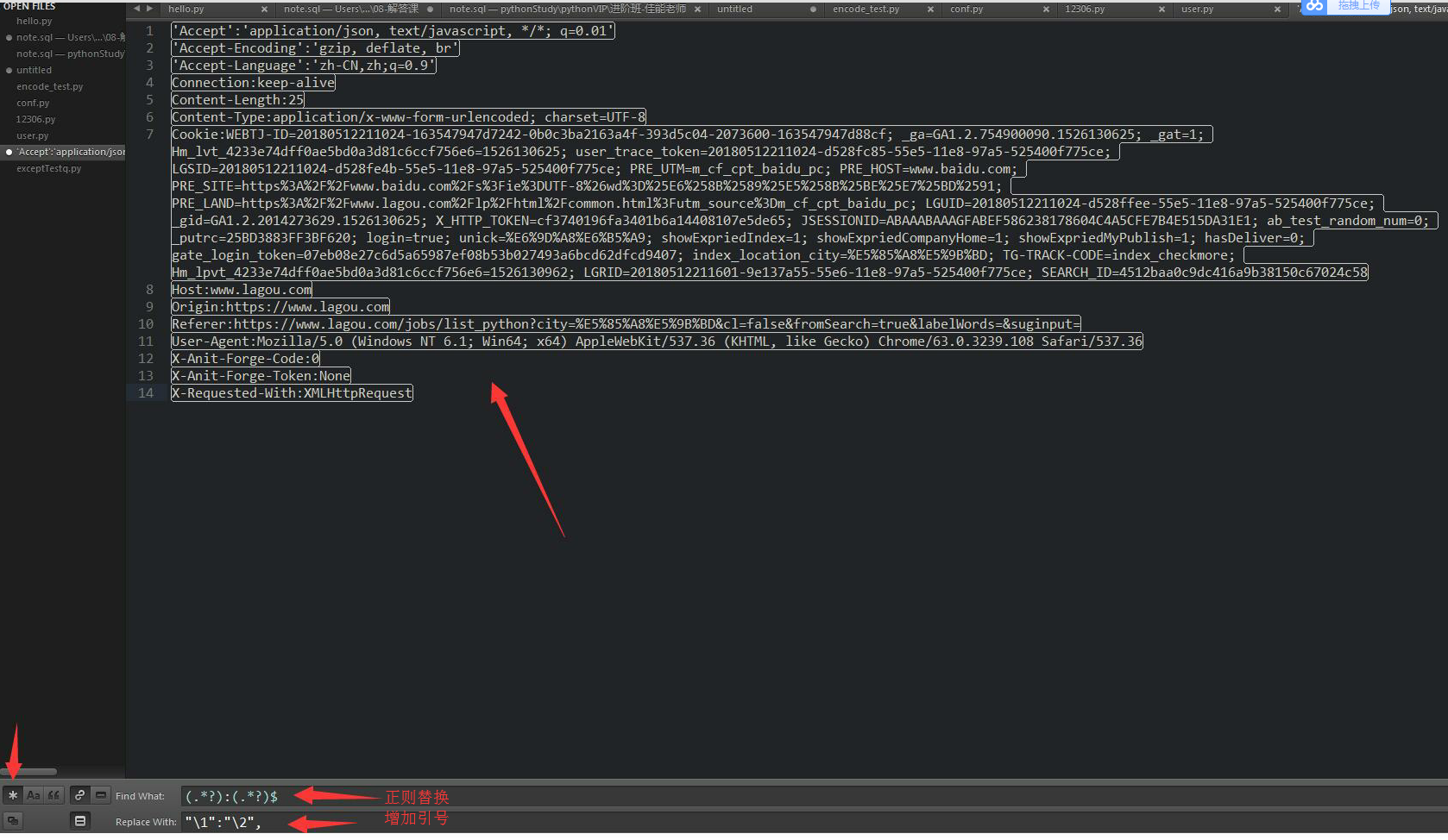
处理后,方便粘贴到代码中

爬取拉钩信息代码
import requests
class LagouSpider(object):
def __init__(self):
self.url ='https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false'
self.headers ={
"Accept":"application/json, text/javascript, */*; q=0.01",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"Connection":"keep-alive",
"Content-Length":"",
"Content-Type":"application/x-www-form-urlencoded; charset=UTF-8",
"Cookie":"", #根据每个人登录信息填写
"Host":"www.lagou.com",
"Origin":"https://www.lagou.com",
"Referer":"https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36",
"X-Anit-Forge-Code":"",
"X-Anit-Forge-Token":"None",
"X-Requested-With":"XMLHttpRequest"
}
self.offset = 0
self.data = {
"first":'true',
"pn":0, # 页数请求
"kd":'python' # 查询关键字
}
self.pos_li = []
self.total = 0
self.pageNo = 0
self.resultSize = 0
def start_request_total(self):
"""
得到拉钩网页数信息
:return:
"""
response = requests.post(url=self.url, headers=self.headers, data=self.data)
html = response.json()
# 得到拉钩工作信息总数
print(html['content']['positionResult'])
self.total = html['content']['positionResult']['totalCount']
# 得到拉钩工作信息每页展示数
self.resultSize = html['content']['positionResult']['resultSize']
# 从0开始
self.pageNo = int(self.total / self.resultSize) if self.total % self.resultSize > 0 else int(self.total / self.resultSize)-1
print(self.pageNo)
print(len(html['content']['positionResult']['result']))
def start_request(self):
"""
得到拉钩每页工作信息
:return:
"""
response = requests.post(url=self.url, headers=self.headers, data=self.data)
html = response.json()
# 得到拉钩工作信息
print(html['content']['positionResult']['result'])
self.pos_li.append(html['content']['positionResult']['result'])
def main(self):
self.start_request_total()
for i in range(self.pageNo):
self.start_request()
print(len(self.pos_li)) # 得到页数
if __name__ == '__main__':
la = LagouSpider()
la.main()
展示结果

使用request爬取拉钩网信息的更多相关文章
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- selelinum+PhantomJS 爬取拉钩网职位
使用selenium+PhantomJS爬取拉钩网职位信息,保存在csv文件至本地磁盘 拉钩网的职位页面,点击下一页,职位信息加载,但是浏览器的url的不变,说明数据不是发送get请求得到的. 我们不 ...
- 爬取拉钩网上所有的python职位
# 2.爬取拉钩网上的所有python职位. from urllib import request,parse import json,random def user_agent(page): #浏览 ...
- python爬虫(三) 用request爬取拉勾网职位信息
request.Request类 如果想要在请求的时候添加一个请求头(增加请求头的原因是,如果不加请求头,那么在我们爬取得时候,可能会被限制),那么就必须使用request.Request类来实现,比 ...
- Python 爬取拉钩网工作岗位
如果拉钩网html页面做了调整,需要重新调整代码 代码如下 #/usr/bin/env python3 #coding:utf-8 import sys import json import requ ...
- ruby 爬虫爬取拉钩网职位信息,产生词云报告
思路:1.获取拉勾网搜索到职位的页数 2.调用接口获取职位id 3.根据职位id访问页面,匹配出关键字 url访问采用unirest,由于拉钩反爬虫,短时间内频繁访问会被限制访问,所以没有采用多线程, ...
- 【实战】用request爬取拉勾网职位信息
from urllib import request import urllib import ssl import json url = 'https://www.lagou.com/jobs/po ...
- 使用nodejs爬取拉勾苏州和上海的.NET职位信息
最近开始找工作,本人苏州,面了几家都没有结果很是伤心.在拉勾上按照城市苏州关键字.NET来搜索一共才80来个职位,再用薪水一过滤,基本上没几个能投了.再加上最近苏州的房价蹭蹭的长,房贷压力也是非常大, ...
- 爬虫基本库request使用—爬取猫眼电影信息
使用request库和正则表达式爬取猫眼电影信息. 1.爬取目标 猫眼电影TOP100的电影名称,时间,评分,等信息,将结果以文件存储. 2.准备工作 安装request库. 3.代码实现 impor ...
随机推荐
- const命令声明变量应注意的几点
对于复合类型的变量,变量名不指向数据,而是指向数据所在的地址.const命令只是保证变量名指向的地址不变,并不保证该地址的数据不变,所以将一个对象声明为常量必须非常小心. const person = ...
- 将python、pip 加入环境变量
加python: CMD里输: path=%path%;C:\Python27 其中 C:\Python27 为python的exe所在的文件夹 加pip: CMD里输: path= ...
- MAC shell ps 命令详解(转)
ps命令为我们提供了一次性的查看进程结果,它所提供的查看结果不是动态连续的:如果想对进程时间监控,应该用top工具 Linux中的ps命令是Process Status的缩写.ps命令用来列出系统中当 ...
- git回滚远程仓库
关于远程仓库回滚 首先,必须要明白的一件事,任何普通用户不能擅自做有关远程仓库回退的操作,如果你擅自回滚了远程仓库,会对项目团队其他人造成不可预知的影响.如果需要回退版本,先联系项目的仓库管理员,在团 ...
- face_recognition 相关依赖
centos-v:7 python-v:3.7 IDE:pycharm 安装顺序: boost boost-py cmake numpy opencv-python scipy 安装方法:settin ...
- https 网络传输安全架设
1:在集群的情况下,不能在tomcat上 架构ssl 而是在总路由nginx上架设具体实现如下截图 非对称加密是当前流行的加密传输方式 证书是什么 . 在浏览器证书查看 证书是访问请求时 https ...
- 6J - 盐水的故事
挂盐水的时候,如果滴起来有规律,先是滴一滴,停一下:然后滴二滴,停一下:再滴三滴,停一下...,现在有一个问题:这瓶盐水一共有VUL毫升,每一滴是D毫升,每一滴的速度是一秒(假设最后一滴不到D毫升,则 ...
- ES6 扩展运算符
ES6的扩展运算符则可以看作是rest参数的逆运算.可以将数组转化为参数列表. 如:console.log(1,...[2,3,4],5) //1 2 3 4 5 用于合并数组: [1,2, ...m ...
- ad_imh
1. stc15 ad_1.7 9600 1t #include < #include <absacc.h> #include <stdio.h> #includ ...
- UML标准建模语言与应用实例
一.基本信息 标题:UML标准建模语言与应用实例 时间:2012 出版源:科技创新导报 领域分类:UML标准建模语言 面向对象 系统分析与设计 二.研究背景 问题定义:UML建模语言用图形来表现典型的 ...