Verilog对数据进行四舍五入(round)与饱和(saturation)截位
转自https://www.cnblogs.com/liujinggang/p/10549095.html
一、软件平台与硬件平台
软件平台:
操作系统:Windows 8.1 64-bit
开发套件:Vivado2015.4.2 Matlab2016a
仿真工具:Vivado自带仿真器
二、引言
在利用Verilog写数字信号处理相关算法的过程中往往涉及到对数据的量化以及截位处理。而在实际项目中,一种比较精确的处理方式就是先对截位后的数据进行四舍五入(round),如果在四舍五入的过程中由于进位导致数据溢出,那么我们一般会对信号做饱和(saturation)处理。所谓饱和处理就是如果计算结果超出了要求的数据格式能存储的数据的最大值,那么就用最大值去表示这个数据,如果计算结果超出了要求的数据格式能存储的数据的最最小值,那么就用最小值去表示这个数据。这里先不给例子,下文会详细描述这种情况。
为了叙述方便,本文先做如下规定:如果一个有符号数的总位宽为32位(其中最高位为符号位),小数位宽为16位,那么这个有符号数的数据格式记为32Q16。依次类推,10Q8表示这个数是一个有符号数(最高位为符号位),且总位宽为10位,小数位宽为8位。16Q13表示这个数是一个有符号数(最高位为符号位),且总位宽为16位,小数位宽为13位。总而言之,下文如果定义一个数据为mQn(m和n均为正数且m>n)格式,那么我们可以得到三个重要的信息:
1、mQn是一个有符号数,最高位为符号位
2、mQn数据的总位宽为m
3、mQn数据的小数位宽为n
三、Verilog中有符号数据的补位与截位
3.1 有符号数与无符号数
顾名思义,有符号数指的就是带有符号位的数据,其中最高位就是符号位(如果最高位为0,那么表示是正数,如果最高位为1,那么表示是负数);无符号数就是不带有符号位的数据。
考虑一个4位的整数4’b1011.如果它是一个无符号数据,那么它表示的值为:1*23+0*22+1*21+1*20 = 11.如果它是一个有符号数,那么它表示的值为:1*(-23)+0*22+1*21+1*20 = -5.所以相同的二进制数把它定义为有符号数和无符号数表示的数值大小有可能是不同的。同时,这里也告诉大家,有符号数和无符号数转化为10进制表示的时候唯一的区别就是最高位的权重不同,拿上例来说,无符号数最高位的权重是23而有符号数最高位的权重是-23。
正因为有符号数和无符号数最高位的权重不同,所以他们所表示的数据范围也是不同的。比如,一个4位的无符号整数的数据范围为0~15,分别对应二进制4’b0000~4’b1111,而一个4位的有符号整数的数据范围为-8~7,分别对应二进制4’b1000~4’b0111.
扩展到一般情况,一个位宽为m的无符号整数的数据范围为0~2m-1,而一个位宽为m的有符号整数的数据范围为-2(m-1)~2(m-1)-1。
3.2 有符号整数的符号位扩展
问题:如何把一个4位的有符号整数扩展成6位的有符号整数。
假设一个4位的有符号整数为4’b0101,显然由于最高位为0,所以它是一个正数,如果要把它扩展成6位,那么只需要在最前面加2个0即可,扩展之后的结果为:6’b000101。
在看另外一个例子,假设一个4位的有符号整数为4’b1011,显然由于最高位为1,所以它是一个负数,如果要把它扩展成6位,那么这里要千万注意了,前面不是添2个0,而是添2个1,扩展之后的结果为:6’b111011。为了确保数据扩位以后没有发生错误,这里做一个简单的验证:
4’b1011 = 1*(-23)+0*22+1*21+1*20 = -8 + 0 + 2 + 1 = -5
6’b111011 = 1*(-25)+1*24+1*23+0*22+1*21+1*20 = -32+16+8+2+1=-5
显然扩位以后数据大小并未发生变化。
综上得出结论:对一个有符号整数进行扩位的时候为了保证数据大小不发生变化,扩位的时候应该添加的是符号位。
3.3 有符号小数
有了前面两小节的基础以后接下来研究一下有符号小数。前面已经规定了有符号小数的记法。
假设一个有符号小数为4’b1011,它的数据格式为4Q2,也就是说它的小数位为2位。那么看看这个数表示的10进制数是多少
4’b10.11 = 1*(-21)+0*20+1*2-1+1*2-2 = -2 + 0 + 0.5 + 0.25 = -1.25
显然,小数的计算方法实际上和整数的计算方法是一样的,只不过我们要根据小数点的位置来确定对应的权重。
接下来看看有符号小数的数据范围。就拿4Q2格式的数据来说,它的数据范围为-2~(2-1/22),分别对应二进制4’b1000~4’b0111.扩展到一般情况,mQn格式数据的数据范围为-2(m-n-1)~2(m-n)-1/2n。
最后再来看看有符号小数的数据扩展。假设一个有符号小数为4’b1011,它的数据格式为4Q2,现在要把这个数据用6Q3格式的数据存储。显然需要把整数部分和小数部分分别扩一位,整数部分采用上一节提到的符号位扩展,小数部分则在最后面添一个0,扩展以后的结果为6’b110110,接下来仍然做一个验证
4’b10.11 = 1*(-21)+0*20+1*2-1+1*2-2 = -2 + 0 + 0.5 + 0.25 = -1.25
6’b110.110 = 1*(-22)+1*21+0*20+1*2-1+1*2-2 +0*2-3= -4 + 2 + 0 + 0.5 + 0.25 + 0 = -1.25
显然,扩位以后数据大小并未发生变化。
总结:有符号小数进行扩位时整数部分进行符号位扩展,小数部分在末尾添0.
3.4 两个有符号数的和
两个有符号数相加,为了保证和不溢出,首先应该把两个数据进行扩展使小数点对齐,然后把扩展后的数据继续进行一位的符号位扩展,这样相加的结果才能保证不溢出。
举例:现在要把5Q2的数据5’b100.01和4Q3的数据4’b1.011相加。
Step1、由于5Q2的数据小数位只有2位,而4Q3的数据小数点有3位,所以先把5Q2的数据5’b100.01扩位为6Q3的数据6’b100.010,使它和4Q3数据的小数点对齐
Step2、小数点对齐以后,然后把4Q3的数据4’b1.011进行符号位扩展成6Q3的数据6’b111.011
Step3、两个6Q3的数据相加,为了保证和不溢出,和应该用7Q3的数据来存储。所以需要先把两个6Q3的数据进行符号位扩展成7Q3的数据,然后相加,这样才能保证计算结果是完全正确的。
以上就是两个有符号数据相加需要做的一系列转化。回过头来思考为什么两个6Q3的数据相加必须用7Q3的数据才能准确的存储他们的和。因为6Q3格式数据的数据范围为-4~4-1/23;那么两个6Q3格式的数据相加和的范围为-8~8-1/22;显然如果和仍然用6Q3来存一定会溢出,而7Q3格式数据的数据范围为-8~8-1/23,因此用7Q3格式的数据来存2个6Q3格式数据的和一定不会溢出。
结论:在用Verilog做加法运算时,两个加数一定要对齐小数点并做符号位扩展以后相加,和才能保证不溢出。
3.5 两个有符号数的积
两个有符号数相乘,为了保证积不溢出,积的总数据位宽为两个有符号数的总位宽之和,积的小数数据位宽为两个有符号数的小数位宽之和。简单来说,两个4Q2数据相乘,要想保证积不溢出,积应该用8Q4格式来存。这是因为4Q2格式数据的范围为:-2~(2-1/22),那么两个4Q2数据相乘积的范围为:(-4+1/2)~4,而8Q4格式的数据范围为:-8~(8-1/24),一定能准确的存放两个4Q2格式数据的积。
结论: mQn和aQb数据相乘,积应该用(m+a)Q(n+b)格式的数据进行存储。
3.6 四舍五入(round)
前面讲的都是对数据进行扩位,这一节说的是对数据截位时如何进行四舍五入以提高截位后数据的精度。
假设一个9Q6格式的数据为:9’b011.101101,现在只想保留3位小数位,显然必须把最后三位小数位截掉,但是不能直接把数据截成6’b011.101,这样是不精确的,工程上一般也不允许这么做,正确的做法是先看这个数据是正数还是负数,因为9’b011.101101的最高位为0,所以它是一个正数,然后再看截掉部分(此例中截掉部分是最末尾的101)的最高位是0还是1,在数据是正数的情况下,如果截掉部分的最高位为1,那么是需要产生进位的,所以,最终9’b011.101101应该被截成6’b011.110.
如果是负数则正好相反。假设一个9Q6格式的数据为:9’b100.101101,由于最高位是1,所以这个数是一个负数,然后再看截断部分的最高位以及除最高位的其他位是否有1,此例中截断部分(截断部分为末尾的101)的最高位为1,而且除最高位以外的其他位也有为1的情况,由于负数最高位的权重是(-22),所以对于这种情况是不需要进位的,与正数不同的是,负数不进位是需要加1的。因此最终9’b100.101101应该被截成6’b100.110。
假设a是一个9Q6格式的数据,要求把小数位截成3位。下面是Verilog代码:
assign carry_bit = a[8] ? ( a[2] & ( |a[1:0] ) ) : a[2] ;
assign a_round = {a[8], a[8:3]} + carry_bit ;
上面的代码第一行是通过判断符号位a[8]和截断部分数据特征来确定是否需要进位,如果a[8]是0,计算得到的carry_bit为1,则表示是a是正数,且截断是需要进位;如果a[8]是1,计算得到的carry_bit为1,则表示是a是负数,且截断是不需要进位的,负数不进位需要加1。代码第二行为了保证进位后数据不溢出,所以扩展了一位符号位。
3.7 饱和(saturation)截位
所谓饱和处理就是如果计算结果超出了要求的数据格式能存储的数据的最大值,那么就用最大值去表示这个数据,如果计算结果超出了要求的数据格式能存储的数据的最最小值,那么就用最小值去表示这个数据。
例1:有一个6Q3的数据为6’b011.111,现在要求用4Q2格式的数据去存储它,显然6’b011.111转化为10进制如下:
6’b011.111 = 1*21+1*20+1*2-1+1*2-2+1*2-3 = 3.875
而4Q2格式的数据能表示的数据的最大值为4’b01.11,转化为10进制为1.75,因此4Q2格式的数据根本无法准确的存放3.875这个数据,这样就是所谓的饱和情况。在这种情况下,饱和处理就是把超过了1.75的所有数据全部用1.75来表示,也就是说,6Q3的数据为6’b011.111如果非要用4Q2格式的数据来存储的话,在进行饱和处理的情况下最终的存储结果为:4’b01.11。
例2:有一个6Q3的数据为6’b100.111,现在要求用4Q2格式的数据去存储它,显然6’b100.111转化为10进制如下:
6’b100.111 = 1*(-22)+1*2-1+1*2-2+1*2-3 = -4 + 0.5 + 0.25 + 0.125 = -3.125
而4Q2格式的数据能表示的数据的最小值为4’b10.00,转化为10进制为-2,因此4Q2格式的数据根本无法准确的存放-3.125这个数据,这是另一种饱和情况。在这种情况下,饱和处理就是把超过了小于-2的所有数据全部用-2来表示,也就是说,6Q3的数据为6’b100.111如果非要用4Q2格式的数据来存储的话,在进行饱和处理的情况下最终的存储结果为:4’b10.00。
四、实例演示(a + b * c)
4.1 题目要求
假设a的数据格式为16Q14,b的数据格式为16Q14,c的数据格式为16Q15,请计算s=a+b*c的值,其中s的数据格式为16Q14。在截位的过程中利用四舍五入(round)的方式保证数据精度,如果有数据溢出的情况,请用饱和截位的方式进行处理。编写完Verilog代码以后利用Matlab产生a、b、c的数据对写的Verilog代码进行仿真,并保证Matlab运算得到的数据和Verilog运算得到的数据全部相同。最后,有条件的利用VCS统计代码覆盖率(Code Coverage),确保条件覆盖率(Condition Coverage)达到100%。
4.2 要求分析
1、先分析b*c。由于b的数据格式为16Q14,c的数据格式为16Q15,所以为了保证b*c的乘积不溢出,那么b*c的乘积的数据格式为(16+16)Q(14+15),即32Q29。
2、再分析加法。由于a的数据格式为16Q14,而b*c的积的数据格式为32Q29,所以相加之前要先把a扩展成32Q29格式的数据,又为了保证相加的结果不溢出,相加之前还要把两个32Q29格式的数据进行1位符号位扩展成33Q29格式的数据以后再相加,相加得到的和的数据格式为33Q29.
3、最后,由于要求最终的结果为16Q14,所以需要把33Q29的数据截位为16Q14,如果出现数据溢出的情况,需要用饱和截位的方式进行处理。
分析完毕以后,就开始进行代码的编写。
4.3 Verilog代码分析
本题的Verilog代码如下

1 module dsp(
2 input I_clk ,
3 input I_rst_n ,
4 input signed [15:0] I_a , // 16Q14
5 input signed [15:0] I_b , // 16Q14
6 input signed [15:0] I_c , // 16Q15
7 output signed [15:0] O_s // 16Q14
8 );
9
10 reg signed [15:0] R_a_16Q14 ;// 16Q14
11 reg signed [15:0] R_b_16Q14 ;// 16Q14
12 reg signed [15:0] R_c_16Q15 ;// 16Q15
13
14 wire signed [31:0] W_mult_b_c_32Q29 ; //32Q29
15 wire signed [32:0] W_s_33Q29 ; // 33Q29
16 wire signed [31:0] W_a_32Q29 ;
17
18 wire carry_bit ;
19 wire [18:0] W_s_19Q14_round ;
20
21 always @(posedge I_clk or negedge I_rst_n)
22 begin
23 if(!I_rst_n)
24 begin
25 R_a_16Q14 <= 16'd0 ;
26 R_b_16Q14 <= 16'd0 ;
27 R_c_16Q15 <= 16'd0 ;
28 end
29 else
30 begin
31 R_a_16Q14 <= I_a ;
32 R_b_16Q14 <= I_b ;
33 R_c_16Q15 <= I_c ;
34 end
35 end
36
37 assign W_mult_b_c_32Q29 = R_b_16Q14 * R_c_16Q15 ;
38 assign W_a_32Q29 = {R_a_16Q14[15], R_a_16Q14, {15{1'b0}}} ;
39 assign W_s_33Q29 = {W_a_32Q29[31], W_a_32Q29} + {W_mult_b_c_32Q29[31], W_mult_b_c_32Q29} ;
40
41 assign carry_bit = W_s_33Q29[32] ? ( W_s_33Q29[14] & (|W_s_33Q29[13:0]) ) : W_s_33Q29[14] ;
42 assign W_s_19Q14_round = {W_s_33Q29[32],W_s_33Q29[32:15]} + carry_bit ;
43
44 assign O_s = (W_s_19Q14_round[18:15] == 4'b0000 || W_s_19Q14_round[18:15] == 4'b1111) ? W_s_19Q14_round[15:0]:{W_s_19Q14_round[18],{15{!W_s_19Q14_round[18]}}} ;
47
48 endmodule
1、代码第37行计算的是b*c的值,由于b的数据格式为16Q14,而c的数据格式为16Q15,所以他们的乘积定义的数据格式为32Q29,这样可以保证乘积绝不会溢出。
2、代码第38行把16Q14格式的数据a扩展到32Q29格式,这么做的目的是让a和b*c的值的小数点对齐以保证做加法运算的时候不会出错
3、代码第39行是把a和b*c的结果进行相加,为了保证相加的结果不会溢出,那么相加前必须对两个加数进行一位的符号位扩展。
4、第41行和第42行代码就是对a+b*c的结果截位后进行四舍五入(round)。由于a+b*c结果的数据格式为33Q29,根据题目要求要把它变成16Q14格式的数据,所以第一步需要做的就是把33Q29格式数据的最后15位小数位(也就是要把W_s_33Q29[14:0]位截掉)截掉,但是截掉W_s_33Q29[14:0]以后,一定要判段是否需要进位,第41行的代码就是用来产生进位的逻辑,计算出这个进位以后,然后把这个进位加到W_s_33Q29[32:15]上完成四舍五入(round)的操作,值得注意的是,为了保证加上进位的时候数据不会溢出,在加进位之前一定要对W_s_33Q29[32:15]进行1位的符号位扩展。
5、完成了四舍五入(round)的操作以后,那么小数部分我们已经全部处理完毕,接下来就来处理整数部分。由于完成四舍五入以后的数据W_s_19Q14_round的数据格式为19Q14,我们的目标是要把他进一步截位成16Q14的数据,所以我们需要把W_s_19Q14_round的高3位W_s_19Q14_round[18:16]截掉。如果W_s_19Q14_round[18:16]和W_s_19Q14_round[15]相同,也就是说W_s_19Q14_round[18:15]==4'b0000 或W_s_19Q14_round[18:15]==4'b1111,那么说明W_s_19Q14_round[18:16]是W_s_19Q14_round[15]位的符号位扩展,我们可以直接把高三位W_s_19Q14_round[18:16]截掉保留W_s_19Q14_round[15]位即可。但如果W_s_19Q14_round[18:16]和W_s_19Q14_round[15]不相同,也就是说W_s_19Q14_round[18:15]==4'b0000 或W_s_19Q14_round[18:15]==4'b1111不成立的情况下,那么说明W_s_19Q14_round这个数据所表示的值用16Q14格式的数据是存不下的,会发生溢出,这种情况题目要求我们用饱和截位的方式进行处理,处理方式就很简单了,直接判断W_s_19Q14_round的最高位W_s_19Q14_round[18],如果W_s_19Q14_round[18]为0,那么代表W_s_19Q14_round是一个正数,饱和处理就是把它变成16Q14格式数据能够存储的最大整数16'b0_111111111111111,如果W_s_19Q14_round[18]为1,那么代表W_s_19Q14_round是一个负数,饱和处理就是把它变成16Q14格式数据能够存储的最小负数16'b1_000000000000000。代码见44行。
到此,整个代码编写与分析完毕。
完成代码的编写以后接下来就要写一个测试文件来测试代码的正确性。大致的思路是用Matlab产生符合条件的a、b、c的数据,然后通过Verilog系统调用$readmemh或$readmemb读进来送给dsp.v模块进行计算,接着把dsp.v模块的输出写到另外一个.txt文件中,然后和Matlab计算的结果进行对比,如果所有的数据的每一个bit都没有错误,而且你的Verilog代码覆盖率(Code Coverage)达到了100%(没用过VCS的同学可以暂时先不用关系代码覆盖率的概念),那么才证明你写的dsp.v模块功能是OK的。
测试激励文件的代码如下所示
1 `timescale 1ns / 1ps
2
3 module tb_dsp;
4 reg I_clk ;
5 reg I_rst_n ;
6 reg [15:0] I_a ;
7 reg [15:0] I_b ;
8 reg [15:0] I_c ;
9
10 wire [15:0] O_s ;
11
12 parameter C_DATA_LENGTH = 4096 ;
13
14 reg [15:0] M_mem_a[0:C_DATA_LENGTH - 1] ;
15 reg [15:0] M_mem_b[0:C_DATA_LENGTH - 1] ;
16 reg [15:0] M_mem_c[0:C_DATA_LENGTH - 1] ;
17 reg [13:0] R_mem_addr ;
18 reg R_data_vaild ;
19 reg R_data_vaild_t ;
20
21 dsp u_dsp
22 (
23 .I_clk,
24 .I_rst_n(I_rst_n),
25 .I_a(I_a), // 16Q14
26 .I_b(I_b), // 16Q14
27 .I_c(I_c), // 16Q15
28 .O_s(O_s)
29 );
30
31
32
33 initial begin
34 I_clk = 0 ;
35 I_rst_n = 0 ;
36
37 #67 I_rst_n = 1 ;
38 end
39
40 initial begin
41 $readmemh("E:/VIVADO_WORK/cnblogs12_round_saturation/Matlab/a_16Q14.txt",M_mem_a);
42 $readmemh("E:/VIVADO_WORK/cnblogs12_round_saturation/Matlab/b_16Q14.txt",M_mem_b);
43 $readmemh("E:/VIVADO_WORK/cnblogs12_round_saturation/Matlab/c_16Q15.txt",M_mem_c);
44 end
45
46 always #5 I_clk = ~I_clk ;
47
48 always @(posedge I_clk or negedge I_rst_n)
49 begin
50 if(!I_rst_n)
51 begin
52 I_a <= 16'd0 ;
53 I_b <= 16'd0 ;
54 I_c <= 16'd0 ;
55 R_mem_addr <= 14'd0 ;
56 R_data_vaild <= 1'b0 ;
57 end
58 else if(R_mem_addr == C_DATA_LENGTH )
59 begin
60 R_mem_addr <= C_DATA_LENGTH ;
61 R_data_vaild <= 1'b0 ;
62 end
63 else
64 begin
65 I_a <= M_mem_a[R_mem_addr] ;
66 I_b <= M_mem_b[R_mem_addr] ;
67 I_c <= M_mem_c[R_mem_addr] ;
68 R_mem_addr <= R_mem_addr + 1'b1 ;
69 R_data_vaild <= 1'b1 ;
70 end
71 end
72
73 always @(posedge I_clk or negedge I_rst_n)
74 begin
75 if(!I_rst_n)
76 R_data_vaild_t <= 1'b0 ;
77 else
78 R_data_vaild_t <= R_data_vaild ;
79 end
80
81
82 integer fid ;
83
84 initial begin
85 fid = $fopen("E:/VIVADO_WORK/cnblogs12_round_saturation/Matlab/s_vivado.txt" , "w");
86 if(!fid)
87 begin
88 $display("**********************Can Not Open File*************************************");
89 $finish;
90 end
91 else
92 begin
93 $display("**********************Open File Success*************************************");
94 end
95 end
96
97 always @(posedge I_clk )
98 begin
99 if(R_data_vaild_t)
100 $fdisplay(fid,"%d",$signed(O_s));
101 else if(R_mem_addr == C_DATA_LENGTH)
102 begin
103 $fclose(fid) ;
104 $finish ;
105 end
106 end
107
108 endmodule
这段代码需要注意一下几点:
1、$readmemh系统调用后面文件的路径一定要填绝对路径,而且路径分隔符是左斜杠"/",而不是右斜杠"\"。
2、我之所以要把R_data_valid延时一拍为R_data_valid_t是因为我在dsp.v模块中把a、b、c三个数据都延时了一拍,这里是为了保证数据对齐。
下一小节会详细的介绍如何产生测试激励文件中a、b、c三个数据的方法。
4.4 利用Matlab产生a、b、c三个数据
Matlab里面有现成的量化数据的函数,它们分别是quantizer函数和quantize函数。其中quantizer函数用来产生量化格式,quantize函数用来调用quantizer函数的结果对数据进行量化,具体的用法在Matlab命令行中输入doc quantizer和doc quantize可以查看。
产生a、b、c三个数据的Matlab代码如下:
clear
clc
data_length = 4096 - 8 ; % 定义数据长度,其中排除8种边界条件
a_min = -2 ; %a的数据格式为16Q14,所以它的最小值为-2
a_max = 2 - 1/(2^14) ; %a的数据格式为16Q14,所以它的最大值为2 - 1/(2^14)
b_min = -2 ; %b的数据格式为16Q14,所以它的最小值为-2
b_max = 2 - 1/(2^14) ; %b的数据格式为16Q14,所以它的最大值为2 - 1/(2^14)
c_min = -1 ; %c的数据格式为16Q15,所以它的最小值为-1
c_max = 1 - 1/(2^15) ; %c的数据格式为16Q15,所以它的最大值为1 - 1/(2^15)
% 产生4088个均匀分布在a、b、c最大值与最小值之间的随机数
a_rand = a_min + (a_max - a_min)*rand(1,data_length) ;
b_rand = b_min + (b_max - b_min)*rand(1,data_length) ;
c_rand = c_min + (c_max - c_min)*rand(1,data_length) ;
% 产生8种边界条件
a_boundary = [a_min a_min a_min a_min a_max a_max a_max a_max] ;
b_boundary = [b_min b_min b_max b_max b_min b_min b_max b_max] ;
c_boundary = [c_min c_max c_min c_max c_min c_max c_min c_max] ;
% 随机数与边界值组合成为待量化的数据
a = [a_boundary a_rand];
b = [b_boundary b_rand];
c = [c_boundary c_rand];
% 定义量化规则,根据题目要求量化需采用四舍五入与饱和截位的方式
quan_16Q14_pattern = quantizer('fixed','round','saturate',[16,14]);
quan_16Q15_pattern = quantizer('fixed','round','saturate',[16,15]);
quan_33Q29_pattern = quantizer('fixed','round','saturate',[33,29]);
% 把a、b、c三个数据按照要求进行量化
a_16Q14 = quantize(quan_16Q14_pattern,a);
b_16Q14 = quantize(quan_16Q14_pattern,b);
c_16Q15 = quantize(quan_16Q15_pattern,c);
% 计算a + b * c的值
s = a_16Q14 + b_16Q14 .* c_16Q15 ;
% 根据题目要求,s的数据格式为16Q14,所以这里把s量化为16Q14格式的数据
s_16Q14 = quantize(quan_16Q14_pattern,s);
% 把量化后的a、b、c变成整数方便写入.txt文件中
a_integer = a_16Q14 * 2^14 ;
b_integer = b_16Q14 * 2^14 ;
c_integer = c_16Q15 * 2^15 ;
s_integer = s_16Q14 * 2^14 ;
% 由于在Verilog中测试激励文件的系统调用$readmemh读入的数据格式为16进制,所以
% 把数据写入.txt文件中之前需要把数据转化为补码的格式,这样负数才不会写错
a_complement = zeros(1,length(a_integer));
b_complement = zeros(1,length(b_integer));
c_complement = zeros(1,length(c_integer));
% 把量化后的a转化为补码
for i = 1:length(a_complement)
if(a_integer(i) < 0)
a_complement(i) = 2^16 + a_integer(i) ;
else
a_complement(i) = a_integer(i) ;
end
end
% 把量化后的b转化为补码
for i = 1:length(b_complement)
if(b_integer(i) < 0)
b_complement(i) = 2^16 + b_integer(i) ;
else
b_complement(i) = b_integer(i) ;
end
end
% 把量化后的c转化为补码
for i = 1:length(c_complement)
if(c_integer(i) < 0)
c_complement(i) = 2^16 + c_integer(i) ;
else
c_complement(i) = c_integer(i) ;
end
end
% 把量化后的a的补码写入txt文件
fid_a = fopen('a_16Q14.txt','w');
fprintf(fid_a, '%x\n', a_complement);
fclose(fid_a);
% 把量化后的b的补码写入txt文件
fid_b = fopen('b_16Q14.txt','w');
fprintf(fid_b, '%x\n', b_complement);
fclose(fid_b);
% 把量化后的c的补码写入txt文件
fid_c = fopen('c_16Q15.txt','w');
fprintf(fid_c, '%x\n', c_complement);
fclose(fid_c);
% 把量化后的s以整数形式写入txt文件,方便和vivado计算的结果进行对比
fid_s = fopen('s_matlab.txt','w');
fprintf(fid_s, '%d\n', s_integer);
fclose(fid_s);
这段代码基本都做了详细的注释,这里在强调几点:
1、Matlab中的“*”表示矩阵相乘,如果要对两个向量对于的数据进行乘法运算应该要用“.*”
2、由于有符号数都是用补码进行存放的,所以在把数据写入txt文件之前一定要先把数据变成补码的格式
3、代码运行结束后会产出一个警告,提示运算过程中出现了溢出,这个是正常的,而且是我故意设计的,溢出的情况Matlab会按照quantizer函数定义的量化Pattern进行处理,所以如果之前写的Verilog的代码没问题的话,那么Matlab的运算结果和Vivado得到的结果应该是完全相同的。
4、代码运行结束以后,在和代码相同的目录下会产生四个txt文件,其中a_16Q14.txt,b_16Q14.txt,c_16Q15.txt用来被testbench中的$readmemh读进去,s_matlab.txt文件用来和s_vivado.txt进行后面的数据对比。
到此为止,已经得到了符合要求的a、b、c的测试数据,接下来就需要写一个Matlab的脚本对Matlab的计算结果s_matlab.txt与Vivado的计算结果s_vivado.txt进行对比,看是否数据完全相同。测试脚本的代码如下:
clear
clc
filename1 = 's_matlab.txt' ;
filename2 = 's_vivado.txt' ;
% s_matlab = textread(filename1, '%d') ;
% s_vivado = textread(filename2, '%d') ;
% 把txt文件中的数据读入并转化为一维数组,上面2行注释的代码和下面6行代码的作用是完全一样的
% 由于Matlab目前的版本不推荐使用textread,所以我使用了textscan函数进行处理
fid1 = fopen(filename1, 'r');
fid2 = fopen(filename2, 'r');
s_matlab = textscan(fid1, '%d') ;
s_vivado = textscan(fid2, '%d') ;
s_matlab = cell2mat(s_matlab) ;
s_vivado = cell2mat(s_vivado) ;
count = 0 ;
% 对s_vivado.txt的数据与s_matlab.txt的数据进行对比
for i = 1:length(s_vivado)
if(s_vivado(i) == s_matlab(i))
msg = sprintf('s_vivado(%d) is equal s_matlab(%d), Verification Pass', i , i) ;
disp(msg) ;
count = count + 1 ;
else
msg = sprintf('s_vivado(%d) is not equal s_matlab(%d), Verification Fail', i , i) ;
disp(msg) ;
end
end
msg = sprintf('Total Pass Number is %d', count) ;
disp(msg) ;
上面的代码就是把s_vivado.txt和s_matlab.txt的数据读进来然后做一个对比,如果数据完全相同,那么说明你用Verilog写的四舍五入(round),截位饱和的逻辑应该是没问题的,但是工作只完成了95%,剩下还有5%的工作我们需要进一步看代码覆盖率是否达到了100%(没用过VCS的可以忽略这一步)。下面写看一下上述代码的运行截图
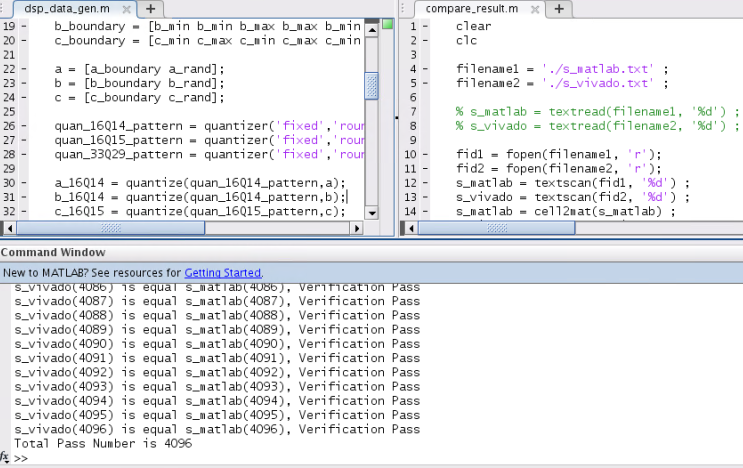
由上图可以看出,Matlab与Vivado计算产生的4096个的数据完全相同。可初步确认逻辑基本正确,下一小节在看看代码覆盖率。
4.5 查看代码覆盖率(Code Coverage)
数字IC设计工程师用的仿真器大多是Synopsys公司的VCS和Verdi,VCS有一个非常重要的功能就是查看代码覆盖率(Code Coverage)。代码覆盖率(Code Coverage)分5种,分别为行覆盖率(line)、切换覆盖率(Toggle)、状态机覆盖率(FSM)、条件覆盖率(Condition)以及分支覆盖率(Branch)。针对这个例子来说,由于在dsp.v模块中对W_a_16Q14的低15位进行了补0,所以切换覆盖率(Toggle)不可能达到100%,这是合理的,但是条件覆盖率(Condition)一定要达到100%,因为代码中的每一个条件对应一种数据处理的场景,所以如果条件覆盖率(Condition)没达到100%,那么证明你产生的测试数据还没有覆盖所有的情况,需要回过头去思考原因。由于VCS又是一个大话题,所以这一节不说细节,直接给出代码覆盖率(Code Coverage)的截图如下图所示

由上图可知条件覆盖率确实为100%,证明我们产生的测试数据已经覆盖到了代码中的每种情况,至此可以下结论:整个四舍五入、饱和截位的逻辑全部验证完成。
五、总结
本文的数字信号处理的例子尽管非常简单,只是一个普通的乘加结构,但是基本上涵盖了利用Verilog做数字信号处理时需要关注的方方面面。学完本文你应该知道:
1、无符号数与有符号数的本质区别:最高位的权重不同
2、有符号数符号位扩展的原理
3、mQn格式数据的数据范围
4、两个有符号数相加,应该先把小数点对齐,然后做一位的符号位扩展以后才能相加
5、Verilog四舍五入(round)原理
6、饱和截位的原理
7、用Matlab产生$readmemh可读入的数据
8、用Matlab验证算法结果的正确性
六、参考资料
1、verilog实现 floor, round 四舍五入 和 saturation 操作。链接:http://bbs.21ic.com/icview-2626038-1-1.html
2、Matlab定点量化。链接:https://blog.csdn.net/sunlight369/article/details/42742235
Verilog对数据进行四舍五入(round)与饱和(saturation)截位的更多相关文章
- 【设计经验】5、Verilog对数据进行四舍五入(round)与饱和(saturation)截位
一.软件平台与硬件平台 软件平台: 操作系统:Windows 8.1 64-bit 开发套件:Vivado2015.4.2 Matlab2016a 仿真工具:Vivado自带仿真器 二.引言 在利用 ...
- (转)Python3的四舍五入round()函数坑爹?不,更科学!
原文:https://blog.csdn.net/lly1122334/article/details/80596026 Python3的四舍五入round()函数坑爹?不,更科学!Python2中, ...
- JS对象 四舍五入round() round() 方法可把一个数字四舍五入为最接近的整数。 语法: Math.round(x)
四舍五入round() round() 方法可把一个数字四舍五入为最接近的整数. 语法: Math.round(x) 参数说明: 注意: 1. 返回与 x 最接近的整数. 2. 对于 0.5,该方法将 ...
- systemverilog中实现饱和截位和饱和截位的分析
截位(rnd/prnd/floor):都是去掉低位数据的操作(去掉低位低精度的数据,或者说小数位,降低数据的精度) 饱和(sat/sym_sat):都是去掉高位数据的操作,(去掉无符号数高位的0,或者 ...
- SQL Server 数值四舍五入,小数点后保留2位
1.round() 函数是四舍五入用,第一个参数是我们要被操作的数据,第二个参数是设置我们四舍五入之后小数点后显示几位. 2.numeric 函数的2个参数,第一个表示数据长度,第二个参数表示小数点后 ...
- delphi 四舍五入Round函数【百帖整理】
在最近版本的Delphi Pascal 编译器中,Round 函数是以 CPU 的 FPU (浮点部件) 处理器为基础的.这种处理器采用了所谓的 "银行家舍入法",即对中间值 (如 ...
- python 向上取整ceil 向下取整floor 四舍五入round
#encoding:utf-8 import math #向上取整 http://www.manongjc.com/article/1335.html print "math.ceil--- ...
- Oracle trunc()函数的用法及四舍五入 round函数
--Oracle trunc()函数的用法/**************日期********************/1.select trunc(sysdate) from dual --2011 ...
- python(50):python 向上取整 ceil 向下取整 floor 四舍五入 round
取整:ceil 向下取整:floor 四舍五入:round 使用如下:
随机推荐
- Android深入四大组件(八)广播的注册、发送和接收过程
前言 我们接着来学习Android四大组件中的BroadcastReceiver,广播主要就是分为注册.接收和发送过程.建议阅读此文前请先阅读Android深入理解四大组件系列的文章,知识重复的部分, ...
- 洗礼灵魂,修炼python(26)--编程核心之“递归”
递归 1.什么是递归: 其实前面都提过,但没有详细讲.多次调用自身就叫递归 看图,这种就叫递归 看过盗梦空间没?其实也是递归 2.递归需要满足条件: 有调用函数自身 有一个正确的返回条件来结束 在使用 ...
- Sql Server中查询当天,最近三天,本周,本月,最近一个月,本季度的数据的sql语句
--当天: --最近三天: --本周: select * from T_news WHERE (DATEPART(wk, addtime) = DATEPART(wk, GETDATE())) AND ...
- Unity Chan 3D Asset
Unity Chan 3D Asset 我真的很久沒再家裡開unity,不過今天让我久违的開了 下载地址 :http://ref.gamer.com.tw/redir.php?url=http%3A ...
- rsync续传大目录一例
场景 要将大约60T的文件从一台服务器上搬到另外一台上.两边分区还不一样大,一边是一个整的60T大分区,另一边是15T一个的小分区. 解决思路 类比茶壶倒水,一个分区一个分区的填,填满一个再填第二个. ...
- 浅copy与深copy举例
例1: #!/usr/bin/env python import copy d1 = {'x':1,'y':2,'z':[3,4.5]} d2 = d1 d3 = d1.copy() d4 = co ...
- HTML 中点击<a>标签,页面跳转执行过程
HTML链接使用的是<a>标签 点击超链接,后台的执行大致如下: <a href="https://www.baidu.com">超链接</a> ...
- iOS-单选cell的实现
一.思路 先设置一个chooseCelltag标记(类型为NSIndexPath),然后在点击cell触发的时候,如果tag设置有值,就设置 UITableViewCell *selectedCell ...
- 月球美容计划之最小生成树(MST)
寒假学的两个算法,普里姆,克鲁斯卡尔最终弄明确了.能够发总结了 先说说普里姆,它的本质就是贪心.先从随意一个点開始,找到最短边,然后不断更新更新len数组,然后再选取最短边并标记经过的点,直到全部的点 ...
- NOIP 2000 进制转换
题目描述 我们可以用这样的方式来表示一个十进制数: 将每个阿拉伯数字乘以一个以该数字所处位置的(值减1)为指数,以10为底数的幂之和的形式.例如:123可表示为 1\times 10^2+2\time ...