(Review cs231n) Training of Neural Network2
FFDNet---matlab 调用并批处理
format compact;
global sigmas; % input noise level or input noise level map
addpath(fullfile('utilities')); folderModel = 'models';
folderResult= 'results';
save_folder = 'datasets_c'; showResult = 1;
useGPU = 0; % CPU or GPU. For single-threaded (ST) CPU computation, use "matlab -singleCompThread" to start matlab.
pauseTime = 0; imageNoiseSigma = 50; % image noise level
inputNoiseSigma = 50; % input noise level load(fullfile('models','FFDNet_gray.mat'));
net = vl_simplenn_tidy(net); if useGPU
net = vl_simplenn_move(net, 'gpu') ;
end file_name = 'E:\QQ\401668597\FileRecv\af2019-cv-training-20190312\';
sub_file_name_list = dir(file_name); %获取所有子文件夹
num_sub_file = length(sub_file_name_list);
if num_sub_file>0
for fn = 3:num_sub_file
image_file = ['E:\QQ\401668597\FileRecv\af2019-cv-training-20190312\',sub_file_name_list(fn).name,'\'];
image_file_b = [image_file,'*_c.jpg'];
image_list = dir(image_file_b); %得到该文件夹的所有图像的名字
for in = 1:length(image_list)
image_name = [image_file,image_list(in).name];
fprintf('%d,%s',in,image_name); %开始进行处理
label = imread(image_name); %打开图像
[w,h,~]=size(label);
if size(label,3)==3
label = rgb2gray(label);
end
label = im2double(label);
% add noise
randn('seed',0);
noise = imageNoiseSigma/255.*randn(size(label));
input = single(label + noise); if mod(w,2)==1
input = cat(1,input, input(end,:)) ;
end
if mod(h,2)==1
input = cat(2,input, input(:,end)) ;
end % tic;
if useGPU
input = gpuArray(input);
end % set noise level map
sigmas = inputNoiseSigma/255; % see "vl_simplenn.m". % perform denoising
res = vl_simplenn(net,input,[],[],'conserveMemory',true,'mode','test'); % matconvnet default
% res = vl_ffdnet_concise(net, input); % concise version of vl_simplenn for testing FFDNet
% res = vl_ffdnet_matlab(net, input); % use this if you did not install matconvnet; very slow % output = input - res(end).x; % for 'model_gray.mat'
output = res(end).x; if mod(w,2)==1
output = output(1:end-1,:);
input = input(1:end-1,:);
end
if mod(h,2)==1
output = output(:,1:end-1);
input = input(:,1:end-1);
end if useGPU
output = gather(output);
input = gather(input);
end
if showResult
%imshow(cat(2,im2uint8(input),im2uint8(label),im2uint8(output)));
imshow(cat(2,im2uint8(input),im2uint8(output)));
save_dir = [save_folder,image_list(in).name]
imwrite(output,save_dir);
%
%imwrite(im2uint8(output), fullfile(folderResultCur, [nameCur, '_' num2str(imageNoiseSigma,'%02d'),'_' num2str(inputNoiseSigma,'%02d'),'_PSNR_',num2str(PSNRCur*100,'%4.0f'), extCur] ));
drawnow;
pause(pauseTime)
end end end
end
Adam不会让你的学习速率降为0,因为它是leaky gradient; 如果使用的是Adagrad, 学习率最后会自动的下降为0。
集成学习
1. 对训练集中大量独立的模型进行训练,而不仅仅对于单一模型;
2.在测试的时候将结果进行平均。(效果可以提高2%的提升)
使用集成学习的小技巧
当你在训练神经网络时设置一些检查点,通常是每个时期建立一个,对每个检查点都去验证这在验证集中的表现。
这说明你可以在模型中设置不同的检查点,然后在处理集合中使用它们,这被证明能够使得结果有所改善,这样的话你不需要对不同的独立模型进行训练,而只需要训练一下,但是需要设置相应的检查点。
while True:
data_batch = dataset.sample_data_batch()
loss = networdk.forward(data_batch)
dx = network.backward()
x +=-learning_rate * dx
x_test = 0.995*x_test + 0.005*x # use for test set 类似于一个加权的加权的概念
设定了另一个参数集合x_test,x_test是对我现在的参数x的一个指数衰减,当使用x_test和数据集和验证集的时候,得到的结果总是要比使用x更好,这就像一个之前一些参数进行加权的集合。
想一下对你的碗装函数进行优化,在最低点周围不停的移动,然后做一个对这些所有的一个平均值,能够更加接近最低点。
Regularization(dropout)
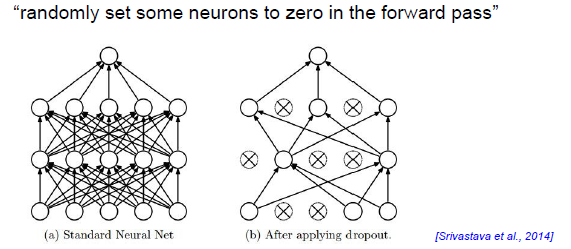
然你的神经网络的节点随机失活,随机把一些神经元置零,
p = 0.5 #probablity of keeping a unit active. higher = less dropout def train_setp(X): #forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
# first dropout mask
U1 = np.random.rand(*H1.shape) < p #产生了一个bool型的和
H1相同维度的矩阵,乘一个二进制数U1,U1为0或1,这个数取决于一个值大于0小于1的数
它比P大还是比P小,np.random.rand(*H1.shape)是一个和H1相同维度的数组.U1是一个以
50%概率输出0或1的过滤器,让隐藏层激活函数乘以这个过滤器,使得激活函数中的一半失活。
H1 *= U1
H2 = np.maximum(0,np.dot(W2,H1)+b)
U2 = np.random.rand(*H2.shape) <p
H2 *= U2
out = np.dot(H2, W3) + b3
前向传播中每一层都失活一半,在反向传播中也要使用随机失活; 随机失活一定在两个过程都要用,在反向传播中也要让梯度乘以U1和U2(两个随机失活过滤器),让一部分梯度失活。
失活的为什么好?
1. 我们只用网络的一半,网络的表达能力会变小很多,就能减小在训练中涉及的变量数(从而减少过拟合的概率)。
偏差-方差均衡的概念。

用神经网络计算猫的分数,随机失活的作用就是强制你的代码,使你的表示对于图片的表示是冗余的,你需要这个冗余,因为你并不能控制在随机失活的过程,所有你需要让猫的分数依赖更多的特征,每一个特征都可能失活,无论某个决定性特征是否被失活的情况下进行准确的分类。
2. 训练一个由很多小模型集成而成的大模型,每个子网络和原网络之间并不能很好的分享参数,在反向传播中只有我们在正向传播中用到的神经元的参数才会被更新,关闭就不会有梯度更新。
如果神经元失活,前一层的所有与这个神经元的连接都不会更新,所以在随即失活过程中,你其实只是训练了一个在某一次取样中,原网络的一部分。 换句话来说,每一个随机失活后的网络,都是一个新的模型,他只会被数据训练一次。
当你们失活一个神经元的时候,就是把这个神经元的输出值乘0,那么它对于损失函数没有影响,在反向传播中他的梯度就是0,他的值在计算损失函数中没有用到,权值就不再更新。
如果取样了网络的一部分,我们只会用一个数据点来训练这个子网络(因为每次循环中都有新的子网络)。
一般每次保留50%,用这种方式训练子网络都一样大。
每一层的结果乘失活的掩码,然后才得到失活的结果,也就是说没有对神经元进行改变,而只是对输出的值进行了改变。
在每次循环中,我们先得到一个mini-batch,然后在神经网络中取样,得到哪些没有失活的神经元,组成子网络。然后进行前向和反向的传播,从而得到梯度,更新参数。
失活的比例选择
对于参数规模比较大的,需要进行强正则的话,这些层可以失活很多神经元;在卷积神经网络中,规模比较小,失活的比例应该小一些。 前几层失活少,后多。
能不能针对每一个神经元进行一定概率的失活?
这招叫做 dropout connect
dropout的使用在测试和训练过程中的表现

这个神经元更新的期望值实际上是测试环节中的一半,所以在测试环节中,你想用全部的神经元,必须补偿多出来的一半,这个一半实际上是因为我们在失活的失活用的概率是50%。
所以在测试环节的前向传播,所以神经元都要乘0.5,如果不这样做,输出分布会改变。通过降低激活函数的输出值来改变输出的期望。
# 定义测试 的前向传播 def predict(X):
#ensemble forward pass
H1 = np.maximum(0,np.dot(W1,X)+b1) * p #Note:scale
H2 = np.maximum(0,np.dot(W2,H1)+b2) *p # Note:scale
out = np.dot(w3,H2) +b3
P就是随机失活的概率,在这里就是一半,这个P降低了激活函数的值,所以输出值的期望也就和训练环节中的期望值输出一样了,修正随机失活造成的影响。
使得使用dropout后的训练和测试的期望输出值能够匹配。
反向失活也是处理训练和测试差异的方法,如下
p = 0.5 #probablity of keeping a unit active. higher = less dropout def train_setp(X): #forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
# first dropout mask
U1 = np.random.rand(*H1.shape) < p /p #产生了一个bool型的和
H1相同维度的矩阵,乘一个二进制数U1,U1为0或1,这个数取决于一个值大于0小于1的数
它比P大还是比P小,np.random.rand(*H1.shape)是一个和H1相同维度的数组.U1是一个以
50%概率输出0或1的过滤器,让隐藏层激活函数乘以这个过滤器,使得激活函数中的一半失活。
H1 *= U1
H2 = np.maximum(0,np.dot(W2,H1)+b)
U2 = np.random.rand(*H2.shape) <p /p
H2 *= U2
out = np.dot(H2, W3) + b3
在H1乘以U1这个随机失活矩阵之前,让U1除以失活的概率,也是让U1值变大,训练过程中扩大,测试时就可以不乘以P,不管测试环节,让训练中的激活函数变大,修正了测试和训练之间的差异,这种反向失活最为常见。
反向失活对系统的影响最小,在反向传播中也是小的改动,能够让网络提升。
(Review cs231n) Training of Neural Network2的更多相关文章
- (Review cs231n) Backpropagation and Neural Network
损失由两部分组成: 数据损失+正则化损失(data loss + regularization) 想得到损失函数关于权值矩阵W的梯度表达式,然后进性优化操作(损失相当于海拔,你在山上的位置相当于W,你 ...
- Training Deep Neural Networks
http://handong1587.github.io/deep_learning/2015/10/09/training-dnn.html //转载于 Training Deep Neural ...
- 【转】Principles of training multi-layer neural network using backpropagation
Principles of training multi-layer neural network using backpropagation http://galaxy.agh.edu.pl/~vl ...
- Training (deep) Neural Networks Part: 1
Training (deep) Neural Networks Part: 1 Nowadays training deep learning models have become extremely ...
- Quantization aware training 量化背后的技术——Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
1,概述 模型量化属于模型压缩的范畴,模型压缩的目的旨在降低模型的内存大小,加速模型的推断速度(除了压缩之外,一些模型推断框架也可以通过内存,io,计算等优化来加速推断). 常见的模型压缩算法有:量化 ...
- (Review cs231n) The Gradient Calculation of Neural Network
前言:牵扯到较多的数学问题 原始的评分函数: 两层神经网络,经过一个激活函数: 如图所示,中间隐藏层的个数的各数为超参数: 和SVM,一个单独的线性分类器需要处理不同朝向的汽车,但是它并不能处理不同颜 ...
- cs231n --- 3 : Convolutional Neural Networks (CNNs / ConvNets)
CNN介绍 与之前的神经网络不同之处在于,CNN明确指定了输入就是图像,这允许我们将某些特征编码到CNN的结构中去,不仅易于实现,还能极大减少网络的参数. 一. 结构概述 与一般的神经网络不同,卷积神 ...
- 《Population Based Training of Neural Networks》论文解读
很早之前看到这篇文章的时候,觉得这篇文章的思想很朴素,没有让人眼前一亮的东西就没有太在意.之后读到很多Multi-Agent或者并行训练的文章,都会提到这个算法,比如第一视角多人游戏(Quake ...
- CVPR 2018paper: DeepDefense: Training Deep Neural Networks with Improved Robustness第一讲
前言:好久不见了,最近一直瞎忙活,博客好久都没有更新了,表示道歉.希望大家在新的一年中工作顺利,学业进步,共勉! 今天我们介绍深度神经网络的缺点:无论模型有多深,无论是卷积还是RNN,都有的问题:以图 ...
随机推荐
- 外部访问docker容器(docker run -p/-P 指令)
容器中可以运行一些网络应用,要让外部也可以访问这些应用,可以通过 -P(大写) 或 -p (小写) 参数来指定端口映射. (1)当使用 -P 标记时,Docker 会随机映射一个 49000~4990 ...
- Ubuntu 10.04下架设流媒体服务器
Ubuntu 10.04下架设流媒体服务器 个人建议:使用DarwinStreamingSrvr5.5.5,因为DarwinStreamingSrvr6.0.3安装过程中有很多问题需要解决! 目前主流 ...
- HOOK IDT频繁蓝屏(Window 正确 HOOK IDT)
环境 win7x64 Microsoft Windows [版本 6.1.7601]也是一个朋友 HOOK IDT 测试 问我IDT为啥老是蓝屏.结果是因为swapgs问题. 如果你知道swapgs作 ...
- java基础---->String中replace和replaceAll方法
这里面我们分析一下replace与replaceAll方法的差异以及原理. replace各个方法的定义 一.replaceFirst方法 public String replaceFirst(Str ...
- React 性能调优总结
React 性能调优总结 首先要说一个库: why-did-you-update, 地址:why-did-you-update, 利用这个库可以在页面上快速看到多余渲染的问题: 因为多数情况下我们在R ...
- 面试准备——(三)Selenium(1)基础问题及自动化测试
转载:https://www.cnblogs.com/lesleysbw/p/6413880.html 面试准备——(三)Selenium(1)基础问题及自动化测试 滴滴面试: 1. 自己负责哪部 ...
- 如何看待淘宝二手交易APP“闲鱼”推出的新功能“闲鱼小法庭”?
转:https://www.zhihu.com/question/55487716?utm_source=qq&utm_medium=social
- nw.js---开发一个百度浏览器
使用nw.js开发一个简单的百度浏览器就很简单了,只需要在配置里面写入: { // "main": "index.html", "main" ...
- [LeetCode] Longest Substring Without Repeating Characters 最长无重复字符的子串
Given a string, find the length of the longest substring without repeating characters. Example 1: In ...
- openssl内核升级
由于工作需要,防止安全漏洞需要对openssl升级现在整理出centos6.8和ubuntu14.4升级 centos升级openssl 1.首先去OpenSSL的网站 https://www.ope ...