[HDFS_4] HDFS 的 Java 应用开发
0. 说明
在 IDEA下 进行 HDFS 的 Java 应用开发
通过编写代码实现对 HDFS 的增删改查操作
1. 流程
1.1 在项目下新建 Moudle
略
1.2 为 Moudle 添加 Maven 框架支持
略
1.3 添加 Maven 依赖
<dependencies>
<!-- Hadoop Client依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency> <!-- 单元测试依赖 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency> </dependencies>
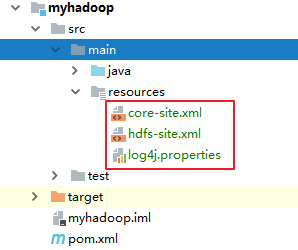
1.4 将 Hadoop/etc/ha 目录下的 [core-site.xml] [hdfs-site.xml] [log4j.properties] 存入 resources 中
2. 代码编写
package hadoop.hdfs; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
import org.junit.Test; import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException; /**
* IDEA 下测试 HDFS 的增删改查
*/
public class TestHDFS { // 1. 测试读取
@Test
public void testRead() throws IOException { // 初始化配置文件
Configuration conf = new Configuration(); // 初始化文件系统
FileSystem fs = FileSystem.get(conf); // 初始化路径
Path p = new Path("/a.txt"); // 通过文件系统获取输入流
// FSDataInputStream 是 inputStream 的装饰流,可以通过普通流方式操纵 fis
FSDataInputStream fis = fs.open(p); int len = 0;
byte[] buf = new byte[1024]; while ((len = fis.read(buf)) != -1) {
System.out.println(new String(buf, 0, len));
}
fis.close();
} // 2. 测试读取并通过 IOUtils 拷贝文件到本地
@Test
public void testRead2() throws Exception { // 初始化配置文件
Configuration conf = new Configuration();
// 初始化文件系统
FileSystem fs = FileSystem.get(conf); // 初始化路径
Path p = new Path("/a.txt"); // 通过文件系统获取输入流
// FSDataInputStream 是 inputStream 的装饰流,可以通过普通流方式操纵 fis
FSDataInputStream fis = fs.open(p); FileOutputStream fos = new FileOutputStream("D:/1.txt"); // 通过 IOUtils 拷贝文件
IOUtils.copyBytes(fis, fos, 1024); fis.close();
fos.close();
System.out.println("ok"); } // 3. 测试写文件,将本地文件写入到 HDFS 中
@Test
public void testwrite() throws IOException { // 设置系统用户名
System.setProperty("HADOOP_USER_NAME", "centos"); // 初始化配置文件
Configuration conf = new Configuration();
// 初始化文件系统
FileSystem fs = FileSystem.get(conf); // 获得输入流
FileInputStream fis = new FileInputStream("E:/p_data/test/customers.txt"); // 初始化路径
Path pout = new Path("/b.txt"); // 通过文件系统获取输出流
// FSDataOutputStream 是 outputStream 的装饰流,可以通过普通流方式操纵 fos
FSDataOutputStream fos = fs.create(pout); // 通过 IOUtils 拷贝文件
IOUtils.copyBytes(fis, fos, 1024); fis.close();
fos.close();
System.out.println("ok"); } // 创建文件夹
@Test
public void testMkdir() throws IOException { // 设置系统用户名
System.setProperty("HADOOP_USER_NAME", "centos"); // 初始化配置文件
Configuration conf = new Configuration();
// 初始化文件系统
FileSystem fs = FileSystem.get(conf); boolean b = fs.mkdirs(new Path("/aaa")); System.out.println(b); } // 删除文件夹
@Test
public void testDelete() throws IOException { // 设置系统用户名
System.setProperty("HADOOP_USER_NAME", "centos"); // 初始化配置文件
Configuration conf = new Configuration();
// 初始化文件系统
FileSystem fs = FileSystem.get(conf); boolean b = fs.delete(new Path("/aaa"),true); System.out.println(b);
} // 文件末尾追加文件
@Test
public void testAppend() throws IOException { // 设置系统用户名
System.setProperty("HADOOP_USER_NAME", "centos"); // 初始化配置文件
Configuration conf = new Configuration();
// 初始化文件系统
FileSystem fs = FileSystem.get(conf); // 通过文件系统获取输出流
// FSDataOutputStream 是 outputStream 的装饰流,可以通过普通流方式操纵 fos
FSDataOutputStream fos = fs.append(new Path("/a.txt")); // 通过文件系统获取输入流
// FSDataInputStream 是 inputStream 的装饰流,可以通过普通流方式操纵 fis
FileInputStream fis = new FileInputStream("E:/p_data/add.txt"); // 通过 IOUtils 拷贝文件
IOUtils.copyBytes(fis,fos,1024); fis.close();
fos.close();
} // 通过递归列出指定文件夹下的文件或文件夹信息
public static void testList(String path) {
try {
// 初始化配置文件
Configuration conf = new Configuration();
// 初始化文件系统
FileSystem fs = FileSystem.get(conf); FileStatus[] statuses = fs.listStatus(new Path(path)); for (FileStatus status : statuses) {
if (status.isDirectory()) {
path = status.getPath().toString();
System.out.println(path);
testList(path);
} else {
System.out.println(status.getPath().toString());
}
} } catch (Exception e) {
e.printStackTrace();
}
} public static void main(String[] args) {
testList("/");
} }
[HDFS_4] HDFS 的 Java 应用开发的更多相关文章
- 2 weekend110的HDFS的JAVA客户端编写 + filesystem设计思想总结
HDFS的JAVA客户端编写 现在,我们来玩玩,在linux系统里,玩eclipse 或者, 即,更改图标,成功 这个,别慌.重新换个版本就好,有错误出错是好事. http://www.eclips ...
- HDFS的Java客户端编写
总结: 之前在教材上看hdfs的Java客户端编写,只有关键代码,呵呵…….闲话不说,上正文. 1. Hadoop 的Java客户端编写建议在linux系统上开发 2. 可以使用eclipse,ide ...
- spark之java程序开发
spark之java程序开发 1.Spark中的Java开发的缘由: Spark自身是使用Scala程序开发的,Scala语言是同时具备函数式编程和指令式编程的一种混血语言,而Spark源码是基于Sc ...
- 一次失败的尝试hdfs的java客户端编写(在linux下使用eclipse)
一次失败的尝试hdfs的java客户端编写(在linux下使用eclipse) 给centOS安装图形界面 GNOME桌面环境 https://blog.csdn.net/wh211212/artic ...
- Hadoop之HDFS(三)HDFS的JAVA API操作
HDFS的JAVA API操作 HDFS 在生产应用中主要是客户端的开发,其核心步骤是从 HDFS 提供的 api中构造一个 HDFS 的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS ...
- day03-hdfs的客户端操作\hdfs的java客户端编程
5.hdfs的客户端操作 客户端的理解 hdfs的客户端有多种形式: 1.网页形式 2.命令行形式 3.客户端在哪里运行,没有约束,只要运行客户端的机器能够跟hdfs集群联网 文件的切块大小和存储的副 ...
- hadoop学习(五)----HDFS的java操作
前面我们基本学习了HDFS的原理,hadoop环境的搭建,下面开始正式的实践,语言以java为主.这一节来看一下HDFS的java操作. 1 环境准备 上一篇说了windows下搭建hadoop环境, ...
- Hadoop(五):HDFS的JAVA API基本操作
HDFS的JAVA API操作 HDFS在生产应用中主要是客户端的开发,其核心步骤是从HDFS提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件. 主 ...
- 5款强大的Java Web开发工具
1.WebBuilder这是一款开源的可视化Web应用开发和运行平台.基于浏览器的集成开发环境,采用可视化的设计模式,支持控件的拖拽操作,能轻松完成前后台应用开发:高效.稳定和可扩展的特点,适合复杂企 ...
随机推荐
- android UI:Fragment碎片
碎片(Fragment) 嵌入与活动中的UI片段,为了合理的分配布局而存在,这是我的简单理解.多用于兼顾手机与平板的UI,也适用于灵活高级的UI制作. Demo 简单的按键切换两片不同的Demo 新建 ...
- jenkins内部分享ppt
持续集成Continuous integration简介(持续集成是什么) .持续集成源于极限编程(XP),是一种软件实践,软件开发过程中集成步骤是一个漫长并且无法预测的过程.集成过程中可能会爆 ...
- 基于Docker+Prometheus+Grafana监控SpringBoot健康信息
在微服务体系当中,监控是必不可少的.当系统环境超过指定的阀值以后,需要提醒指定的运维人员或开发人员进行有效的防范,从而降低系统宕机的风险.在CNCF云计算平台中,Prometheus+Grafana是 ...
- 基于Flume的日志收集系统方案参考
前言 本文将简单介绍两种基于Flume的日志收集系统可能的架构方案,可根据不同的实际场景参考使用. 方案一 示例图如下: 说明: 每个日志源(http上报.日志文件等)对应一个Agent-c用于收集对 ...
- win10 HTTP 错误 500.21 - Internal Server Error
错误描述: HTTP 错误 500.21 - Internal Server Error 处理程序“ExtensionlessUrlHandler-Integrated-4.0”在其模块列表中有一个错 ...
- 【学习笔记】JS设计模式总结
前言:这段时间都在学习Vue的知识,虽然手边放着一本js高程,但确实好久没有好好复习了.温故而知新,因此特意把JS常见的设计模式总结,希望对大家有所帮助... 1. 工厂模式 释义:像工厂一样流水线般 ...
- [SDOI2010] 外星千足虫
Description 公元2089年6月4日,在经历了17年零3个月的漫长旅行后,"格纳格鲁一号"载人火箭返回舱终于安全着陆.此枚火箭由美国国家航空航天局(NASA)研制发射,行 ...
- 四层和七层负载均衡的特点及常用负载均衡Nginx、Haproxy、LVS对比
一.四层与七层负载均衡在原理上的区别 图示: 四层负载均衡与七层负载均衡在工作原理上的简单区别如下图: 概述: 1.四层负载均衡工作在OSI模型中的四层,即传输层.四层负载均衡只能根据报文中目标地址和 ...
- MYSQL中SHOW的使用整理收藏
好记性不如乱笔头吧....下面收藏整理了mysql中show 的使用技巧....有需要的博友可以看看哈 a. show tables或show tables from database_name; / ...
- MarkDown常用格式
常用格式 ** :加粗 <br> : 换行 > :可以用来引用文章,很漂亮. 可以展开的文件夹格式 <details> <summary>框架</sum ...