正则化,L1,L2
机器学习中在为了减小loss时可能会带来模型容量增加,即参数增加的情况,这会导致模型在训练集上表现良好,在测试集上效果不好,也就是出现了过拟合现象。为了减小这种现象带来的影响,采用正则化。正则化,在减小训练样本误差的同时,限制参数的增长,限制参数过多或者过大,从而提高模型的泛化性。
1. L1 正则化
L1 正则化公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值:

2. L2 正则化
L2 正则化公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和:
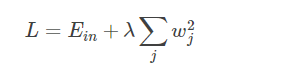
L1范式和L2范式的区别
(1) L1范式是对应参数向量绝对值之和
(2) L1范式具有稀疏性
(3) L1范式可以用来作为特征选择,并且可解释性较强(这里的原理是在实际Loss function 中都需要求最小值,根据L1的定义可知L1最小值只有0,故可以通过这种方式来进行特征选择)
(4) L2范式是对应参数向量的平方和,再求平方根
(5) L2范式是为了防止机器学习的过拟合,提升模型的泛化能力
L2正则 对应的是加入2范数,使得对权重进行衰减,从而达到惩罚损失函数的目的,防止模型过拟合。保留显著减小损失函数方向上的权重,而对于那些对函数值影响不大的权重使其衰减接近于0。相当于加入一个gaussian prior。
L1正则 对应得失加入1范数,同样可以防止过拟合。它会产生更稀疏的解,即会使得部分权重变为0,达到特征选择的效果。相当于加入了一个laplacean prior。
正则化,L1,L2的更多相关文章
- 机器学习 - 正则化L1 L2
L1 L2 Regularization 表示方式: $L_2\text{ regularization term} = ||\boldsymbol w||_2^2 = {w_1^2 + w_2^2 ...
- 正则化 L1 L2
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1ℓ1-norm和ℓ2ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数. L1正则化和 ...
- 【深度学习】L1正则化和L2正则化
在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况.正则化是机器学习中通过显式的控制模 ...
- L1正则化比L2正则化更易获得稀疏解的原因
我们知道L1正则化和L2正则化都可以用于降低过拟合的风险,但是L1正则化还会带来一个额外的好处:它比L2正则化更容易获得稀疏解,也就是说它求得的w权重向量具有更少的非零分量. 为了理解这一点我们看一个 ...
- 机器学习之正则化【L1 & L2】
前言 L1.L2在机器学习方向有两种含义:一是L1范数.L2范数的损失函数,二是L1.L2正则化 L1范数.L2范数损失函数 L1范数损失函数: L2范数损失函数: L1.L2分别对应损失函数中的绝对 ...
- L1正则化和L2正则化
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择 L2正则化可以防止模型过拟合(overfitting):一定程度上,L1也可以防止过拟合 一.L1正则化 1.L1正则化 需注意, ...
- L1正则化与L2正则化的理解
1. 为什么要使用正则化 我们先回顾一下房价预测的例子.以下是使用多项式回归来拟合房价预测的数据: 可以看出,左图拟合较为合适,而右图过拟合.如果想要解决右图中的过拟合问题,需要能够使得 $ ...
- L1,L2范数和正则化 到lasso ridge regression
一.范数 L1.L2这种在机器学习方面叫做正则化,统计学领域的人喊她惩罚项,数学界会喊她范数. L0范数 表示向量xx中非零元素的个数. L1范数 表示向量中非零元素的绝对值之和. L2范数 表 ...
- ML-线性模型 泛化优化 之 L1 L2 正则化
认识 L1, L2 从效果上来看, 正则化通过, 对ML的算法的任意修改, 达到减少泛化错误, 但不减少训练误差的方式的统称 训练误差 这个就损失函数什么的, 很好理解. 泛化错误 假设 我们知道 预 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
随机推荐
- stm32f7699遇到的犯二问题
没有看到stlink的驱动,难道板子坏了?? 结果:USB线的问题,换了一根用过的线,就行了:
- imu_tk标定算法
IMU(惯性测量单位)是机器人中非常流行的传感器:其中,它们被用于惯性导航[1],姿态估计[2]和视觉惯性导航[3],[4],也使用 智能手机设备[5]. 机器人技术中使用的IMU通常基于MEMS(微 ...
- asp.net mvc ef 性能监控调试工具 MiniProfiler
MiniProfiler是一款针对.NET, Ruby, Go and Node.js的性能分析的轻量级程序.可以对一个页面本身,及该页面通过直接引用.Ajax.Iframe形式访问的其它页面进行监控 ...
- Python IDLE arcpy设置环境变量
在IDLE中 import arcpy help(arcpy) 得到的路径为: 但是在arcmap中,路径为: 说明IDLE的环境变量设置有问题: 在windows的环境变量中设置环境变量PYTHON ...
- 利用StateListDrawable给button动态设置背景
项目中,遇到相同样式的Button,只是stroke颜色不一样.为了实现一个,就得写两个shape文件,一个selector文件:多个还得重复写. 解决方法: 结合StateListDrawable给 ...
- 选择排序(Python实现)
目录 1. for版本--选择排序 2. while版本--选择排序 3.测试用例 4. 算法时间复杂度分析 1. for版本--选择排序 def select_sort_for(a_list): ' ...
- [LeetCode] 90.Subsets II tag: backtracking
Given a collection of integers that might contain duplicates, nums, return all possible subsets (the ...
- workman项目设置开机自启动
https://blog.csdn.net/xxq929604980/article/details/78558317 http://man.linuxde.net/chkconfig 1.脚本编写 ...
- MySQL Backup mydumper
生产环境中有一实例每天使用mysqldump备份时长达到了2个小时53分钟,接近3个小时,还不算上备份文件归档的时间,这个时间对于逻辑备份来说有点久.为了提高逻辑备份效率,打算替换为使用mydumpe ...
- Docker 基础 (二)
网络管理 容器网络模式 Docker支持5种网络模式 bridge 默认网络,Docker启动后默认创建一个docker0网桥,默认创建的容器也是添加到这个网桥中 host 容器不会获得一个独立的n ...