Hadoop_MapReduce流程
Hadoop学习笔记总结
01. MapReduce
1. Combiner(规约)
Combiner号称本地的Reduce。

问:为什么使用Combiner?
答:Combiner发生在Map端,对数据进行规约处理,数据量变小了,传送到reduce端的数据量变小了,传输时间变短,作业的整体时间变短。减少了reduce的输入。
问:为什么Combiner不作为MR运行的标配,而是可选步骤哪?
答:因为不是所有的算法都适合使用Combiner处理,例如求平均数。使用了规约,造成了最终结果的不同。
问:Combiner本身已经执行了reduce操作,为什么在Reducer阶段还要执行reduce操作哪?
答:combiner操作发生在map端的,处理一个任务所接收的文件中的数据,不能跨map任务执行;并且,处理的是局部有序数据,不是全局有序数据。
job.setCombinerClass(MyCombiner.class);//其实就是一个另一个Reducer函数
2. Shuffle机制
Shuffle描述着数据从map task输出到reduce task输入的这段过程。(包括了分组、排序、规约和缓存机制)
(1) split切片概念
- map的数量不是由Block块数量决定,而是由split切片数量决定。
- 切片是一个逻辑概念,指的是文件中数据的偏移量范围
- 切片的具体大小应该根据所处理的文件的大小来调整。
- 最佳的分片大小应该与块相同。因为如果跨越了两个数据块,节点一般不会同时存储这两个块,因而会造成网络传输,较低效率。
- 数据本地化优化。(1)、避免了调用同一个机架中空闲机器运行该map任务,(2)、其它机架来处理(小概率)。浪费集群宽带资源。
(2) shuffle流程

Map端:分区排序规约
- 每个map有一个环形内存缓冲区,用于存储任务的输出。默认大小100MB(io.sort.mb属性),一旦达到阀值0.8(io.sort.spill.percent),一个后台线程把内容写到(spill)磁盘的指定目录(mapred.local.dir)下的新建的一个溢出写文件。
- 写磁盘前,后台线程会根据将要传入的reducer将数据分区partition,排序sort。一个个小spill的写,写满了就再新建一个溢出文件(spill file)。在每个分区中,后台线程会按键进行内排序,再写入磁盘spill。如果有combiner,运行combine使得map的输出数据更加紧凑,减少传递到磁盘和传递给reduce的数据。
- 等最后记录写完,合并全部溢出写文件为一个已分区且已排序的文件。combiner也会在写到磁盘之前再次执行。
map总结:map输出-->环形缓冲区-->分区,排序,规约(如果有)-->小spill文件-->合并到磁盘。
Reduce端:复制,合并排序
- reduce任务的复制阶段。Reducer通过Http方式得到输出文件的分区。(通过appMaster告知)。少量的复制线程并行获取map的输出,每个map完成时间不同,只要一个map完成,reduce就开始复制输出。
- NodeManager为运行Reduce任务。复制阶段把Map输出(整体溢出文件)复制到Reducer的内存或磁盘(由map输出大小决定)。
- 排序阶段。合并map输出在Reducer的内存或磁盘中(关于为什么内存和磁盘都有,日后总结)。然后也是基于key值得排序,将局部有序的数据合并成全局有序的数据。然后执行reduce方法。
reduce总结:复制map输出,合并排序
总结,shuffle流程的过程其实就是,分组+排序(map和reduce都有排序)的过程,还有在map和reduce端的缓存机制。
在map端的排序和reduce端的排序是分别有序和整体排序的关系。
想要优化整个过程,可以增大内存,减少溢出文件的IO和提高溢出阀值等
(3) MRAppMaster的任务监控调度机制,带shuffle机制的job流程图
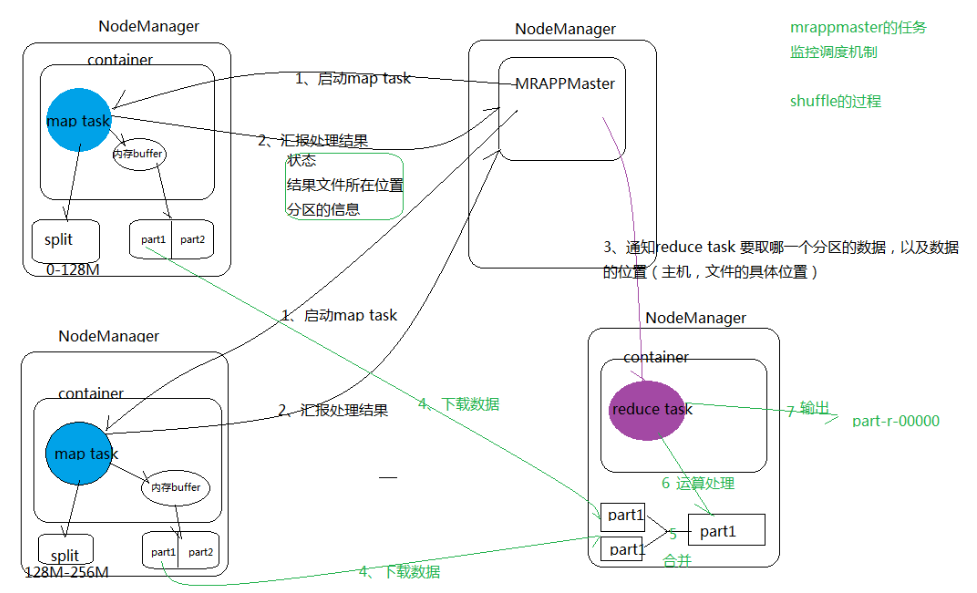
和之前Yarn框架管理,组成了整个MapReduce资源的分配和任务调度的过程。
3. Partitioner分区和ReduceTasks数量
Map的结果,会通过partition函数分发到Reducer上。它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。
默认的HashPartitioner
public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
即:key运算结果相同的被分到同一组,哪个key到哪个Reducer的分配过程,是由Partitioner规定的。
输入是Map的结果对<key, value>和Reducer的数目,输出则是分配的Reducer(整数编号)。就是指定Mappr输出的键值对到哪一个reducer上去。
总结:分区Partitioner主要作用在于以下两点
(1)根据业务需要,产生多个输出文件;
(2)多个reduce任务并发运行,提高整体job的运行效率
job.setPartitionerClass(AreaPartitioner.class);
job.setNumReduceTasks(3);
Ps:当分组有6个。当ReduceTask任务有10个时,只有6个输出文件有数据,其它的为空文件;当Task任务时5个时,报错,因为有的分组找不到reduce函数。
4. 自定义分区、排序、分组的总结
在第3节已经讲述了分区(partition)的概念,在分区过后,每个分区里面的数据按照key进行排序、分组。排序会在map和reduce过程中多次调用。在reduce端排序之后,具有相同Key值的记录是属于同一个分组的传入reduce()方法。
下面以二次排序SecondSort为例讲解:
job.setSortComparatorClass()
job.setGroupingComparatorClass()
1.自定义key
创建的自定义key:NewPairKey需要实现的接口:WritableComparable,可序列的并且可比较的
static class NewPairKey implements WritableComparable<NewPairKey> {
int first = 0;
int second = 0;
//空构造器和含参构造器
//序列化,将IntPair转化成使用流传送的二进制
public void write(DataOutput out) throws IOException {}
//反序列化,从流中的二进制转换成IntPai
public void readFields(DataInput in) throws IOException {}
// NewPairKey的比较逻辑
public int compareTo(NewPairKey o) {}
// 新建的类应该重写的方法
public String toString() {}
public boolean equals(Object obj) {}
public int hashCode() {}
}
2.排序的比较逻辑
Key排序的规则:
如果设置了job的setSortComparatorClass(KeyComparator.class),作为key比较函数类
public static class KeyComparator extends WritableComparator{}
如果没有设置,则系统会自动使用自定义类NewPairKey中实现的compareTo()方法作为key比较的。上面的方法不是必要的。但是都是构造了新的比较逻辑。
// 当NewPairKey进行排序时,会调用该方法,第一列升序排列,第一列不同时,第二列升序排列。
@Override
public int compareTo(NewPairKey o) {
int minus = this.first - o.first;
if (minus != 0) {
return minus;
}
return this.second - o.second;
}
Ps:上面的compareTo(NewPairKey o)参数类型是NewPairKey,需要将字节流反序列化成NewPairKey对象再比较,造成了新建对象的额外开销。
RawComparator接口允许其实现直接比较数据流中的记录,无需先把数据流反序列化为对象,加速比较!。
如下面IntWritable默认是实现源码。
public class IntWritable implements WritableComparable<IntWritable> {
private int value;
public IntWritable() {}
public IntWritable(int value) {
set(value);
}
/** Set the value of this IntWritable. */
public void set(int value) {
this.value = value;
}
/** Return the value of this IntWritable. */
public int get() {
return value;
}
@Override
public void readFields(DataInput in) throws IOException {
value = in.readInt();
}
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(value);
}
/** Returns true iff <code>o</code> is a IntWritable with the same value. */
@Override
public boolean equals(Object o) {
if (!(o instanceof IntWritable))
return false;
IntWritable other = (IntWritable) o;
return this.value == other.value;
}
@Override
public int hashCode() {
return value;
}
/** Compares two IntWritables. */
@Override
public int compareTo(IntWritable o) {
int thisValue = this.value;
int thatValue = o.value;
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0 : 1));
}
@Override
public String toString() {
return Integer.toString(value);
}
/** A Comparator optimized for IntWritable. */
public static class Comparator extends WritableComparator {
public Comparator() {
super(IntWritable.class);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
int thisValue = readInt(b1, s1);
int thatValue = readInt(b2, s2);
return (thisValue < thatValue ? -1 : (thisValue == thatValue ? 0
: 1));
}
}
static { // register this comparator
WritableComparator.define(IntWritable.class, new Comparator());
}
}
从IntWritable 的例子中,可以看到:
1、把WritableComparator当IntWritable的内部类,写到里面
2、如何注册一个自定义的WritableComparator。
此处注意一下,关注static { WritableComparator.define(IntWritable.class,new Comparator())} 的位置。
参看《http://blog.itpub.net/30066956/viewspace-2112283/》
3.分组函数类
WritableComparator是RawComparator接口的实现。功能:1.提供了原始compare()方法的一个默认实现;2.和充当RawComparator实例的工厂(《权威指南P105》)。和WritableComparable区别详情见《http://www.cnblogs.com/robert-blue/p/4159434.html》
job.setGroupingComparatorClass(MyGroupingComparator.class).
static class MyGroupingComparator implements RawComparator<NewPairKey> {
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return WritableComparator.compareBytes(b1, s1, Integer.SIZE / 8,
b2, s2, Integer.SIZE / 8);
}
@Override
public int compare(NewPairKey arg0, NewPairKey arg1) {
return arg0.first - arg1.first;
}
}
总结
分组:
- 实际上,没有使用自定义分组也能实现二次排序逻辑。
- 使用了自定义分组后,分组的逻辑变成不再以整个NewPairKey作为比较,而是以fisrt为标的,把一些相同键的键值进行合并组,测试可知:Reduce input groups=16变成了4。
- compare方法需要知道比较的是Int型数据,就是4个字节的比较,Long型数据就是8个字节的比较。
分区和分组的区别:
- 分区是对输出结果文件进行分类拆分文件以便更好查看,比如一个输出文件包含所有状态的http请求,那么为了方便查看通过分区把请求状态分成几个结果文件。
- 分组就是把一些相同键的键值对进行进行合并组;分区之后数据全部还是照样输出到reduce端,而分组的话就有所减少了。当然这2个步骤也是不同的阶段执行。分区是在map端执行,环形内存缓冲区输出到溢出文件的时候就是按照分区输出;分组是在reduce端。
Group Comparator的执行过程:
- 在reduce阶段,reducer接收到所有映射到这个reducer的map输出后,调用key比较函数类对所有数据排序得到全局有序数据。然后开始构造一个key对应的value迭代器。这时就要用到分组,使用job.setGroupingComparatorClass设置的分组函数类。只要这个比较器比较的两个key相同,他们就属于同一个组,它们的value放在一个value迭代器。
需要Group Comparator吗?
- 问:mapper产生的中间结果经过shuffle和sort后,每个key整合成一个记录,每次reduce方法调用处理一个记录,但是group的目的是让一次reduce调用处理多条记录,为什么?
- 答:如果不用分组,那么同一组的记录就要在多次reduce方法中独立处理,那么有些状态数据就要传递了,就会增加复杂度,在一次调用中处理的话,这些状态只要用方法内的变量就可以的。
关于WritableComparable、RawComparator和WritableComparator联系与区别下回再总结了。
参考《Hadoop权威指南》
《http://www.cnblogs.com/robert-blue/p/4159434.html》
《http://blog.itpub.net/30066956/viewspace-2112283/》
初接触,记下学习笔记,还有很多问题,望指导,谢谢。
Hadoop_MapReduce流程的更多相关文章
- Linux下服务器端开发流程及相关工具介绍(C++)
去年刚毕业来公司后,做为新人,发现很多东西都没有文档,各种工具和地址都是口口相传的,而且很多时候都是不知道有哪些工具可以使用,所以当时就想把自己接触到的这些东西记录下来,为后来者提供参考,相当于一个路 ...
- 基于netty http协议栈的轻量级流程控制组件的实现
今儿个是冬至,所谓“冬大过年”,公司也应景五点钟就放大伙儿回家吃饺子喝羊肉汤了,而我本着极高的职业素养依然坚持留在公司(实则因为没饺子吃没羊肉汤喝,只能呆公司吃食堂……).趁着这一个多小时的时间,想跟 ...
- 通过重建Hosting系统理解HTTP请求在ASP.NET Core管道中的处理流程[下]:管道是如何构建起来的?
在<中篇>中,我们对管道的构成以及它对请求的处理流程进行了详细介绍,接下来我们需要了解的是这样一个管道是如何被构建起来的.总的来说,管道由一个服务器和一个HttpApplication构成 ...
- nginx+iis+redis+Task.MainForm构建分布式架构 之 (redis存储分布式共享的session及共享session运作流程)
本次要分享的是利用windows+nginx+iis+redis+Task.MainForm组建分布式架构,上一篇分享文章制作是在windows上使用的nginx,一般正式发布的时候是在linux来配 ...
- 8、Struts2 运行流程分析
1.流程分析: 请求发送给 StrutsPrepareAndExecuteFilter StrutsPrepareAndExecuteFilter 询问 ActionMapper: 该请求是否是一个 ...
- Hawk 6. 高级话题:子流程系统
子流程的定义 当流程设计的越来越复杂,越来越长时,就难以进行管理了.因此,采用模块化的设计才会更加合理.本节我们介绍子流程的原理和使用. 所谓子流程,就是能先构造出一个流程,然后被其他流程调用.被调用 ...
- 流程开发Activiti 与SpringMVC整合实例
流程(Activiti) 流程是完成一系列有序动作的概述.每一个节点动作的结果将对后面的具体操作步骤产生影响.信息化系统中流程的功能完全等同于纸上办公的层级审批,尤其在oa系统中各类电子流提现较为明显 ...
- zookeeper源码分析之五服务端(集群leader)处理请求流程
leader的实现类为LeaderZooKeeperServer,它间接继承自标准ZookeeperServer.它规定了请求到达leader时需要经历的路径: PrepRequestProcesso ...
- zookeeper源码分析之四服务端(单机)处理请求流程
上文: zookeeper源码分析之一服务端启动过程 中,我们介绍了zookeeper服务器的启动过程,其中单机是ZookeeperServer启动,集群使用QuorumPeer启动,那么这次我们分析 ...
随机推荐
- Jquery中的日历插件
这个插件很简单:只需要在HTML代码中引入插件如下,CLASS名和click事件函数固定! <!doctype html> <html lang="en"> ...
- jQuery原型方法.pushStack源码分析
这次分析的方法跟前面不同,虽然pushStack也是原型方法之一,但是我们几乎从不用在页面调用,在参考手册里面也没有这个方法的使用说明,但是这个方法还是非常重要的,在使用很多jQuery的其他方式都会 ...
- [web安全]Web应用漏洞攻击分析与防范
网站攻击主要分为以下几类: (1) sql注入攻击 SQL Injection:就是通过把SQL命令插入到Web表单递交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令.它是利 ...
- Android基础面试题
1. 请描述一下Activity 生命周期. 答: 如下图所示.共有七个周期函数,按顺序分别是: onCreate(), onStart(), onRestart(), onResume(), onP ...
- Android使用Fragment来实现TabHost的功能(解决切换Fragment状态不保存)以及各个Fragment之间的通信
以下内容为原创,转载请注明:http://www.cnblogs.com/tiantianbyconan/p/3360938.html 如新浪微博下面的标签切换功能,我以前也写过一篇博文(http:/ ...
- iOS定时器、延迟执行
1.通用方式(并不是实时调用并且会卡顿): // 一般用于更新一些非界面上的数据 [NSTimer scheduledTimerWithTimeInterval:时间间隔 target:self se ...
- Android 短信的还原
上篇文章讲到<Android 短信的备份>,本文主要实现Android 短信的还原,即是将一条 布局文件: <RelativeLayout xmlns:android="h ...
- 使用AndroidStudio进行NDK开发简单配置
1. 准备工作 在实际写代码之前,首先我们还是需要做一些准备工作: 下载NDK开发包:Android官方下载页面 配置系统环境变量 下载好NDK开发包之后,直接解压到任意目录,然后需要配置一下系统环境 ...
- 创建一个Android项目
当我们的eclipse安装了SDK后,点击Window-->Perference-->DDMS.eclipse界面立即转为DDMS界面. 这时,我们可以打开我们的服务端(安卓模拟器或者是我 ...
- C# 依赖缓存
使用轮询的方式 数据库: 在VS的命令里面输入 aspnet_regsql.exe -S (local) -U sa -P 123456 -d ERP_SQL -ed 上面这句是用来设置哪个服务器上的 ...