【faster-rcnn】训练自己的数据集时的坑
注:本文写于早期学习摸索阶段,不免有错误、不到位的理解,仅用做遇到相同错误的人参考。后续一直在使用RBG大神的py-faster-rcnn。
既然faster-rcnn原版发表时候是matlab版代码,那就用matlab版代码吧!不过遇到的坑挺多的,不知道python版会不会好一点。
======= update =========
总体上包括这些步骤,请注意检查:
1 获取数据;(标准数据集/比赛数据/自行收集数据)
2 整理图片名和标注信息格式、指定训练集和测试集;(转voc格式,同时记得修改vocinit.m中类别信息;或者自己修改代码中读取数据的地方)
3 正确使用均值图像:手动算一个或用默认的减去128,别用错
4 选择网络与设定网络参数(solver和net);(根据业务需求和显存大小设定;修改网络中目标类别数量)
5 检查batch_size;
6 检查anchor;
7 清空cache目录;
8 开始训练;
9 确保电脑供电且不会休眠睡眠;
10 执行测试;整理测试结果
======= update =========
anyway,这里记录一下我遇到的几个错误和解决办法
这里假设你已经配置好了faster-rcnn。我是在win10下配置的,显卡GTX 970,使用ZF网络。
0. 准备数据集
官方训练时用的是voc2007系列数据,那就转换成这个系列的好了,主要包括:0.下载数据集 1.整理图片 2.xml格式的annotation文件 3.txt格式指定训练集、测试集、验证集、训练验证集,以及每个类别各自的这四种文件
0.0 下载数据集
看具体情况,比如做某个比赛,那就下载;如果是自己收集的数据集,那就统一放到一起
0.1 整理图片
主要是图片格式统一,比如都是png
以及,命名规范,比如统一是6位长度的数字:000001.png,并且序号是连续的
训练图片和测试图片都放在一个JPEGImages目录里
0.2 xml格式的annotation文件
其实voc2007这种方式:为每张图片编写一个xml文件,记录图片各种元信息(作者、文件名、宽度高度深度、来源),以及bounding box坐标信息(左上、右下定点)等,很蛋疼啊,图片多的话每次处理xml文件读写I/O就增大了。anyway,遵守标准的好处是省的自己造各种工具。
这里贴一个例子好了,000001.xml:
<annotation>
<folder>VOC2007</folder>
<filename>000001.png</filename>
<source>
<database>My Database</database>
<annotation>VOC2007</annotation>
<image>flickr</image>
<flickrid>NULL</flickrid>
</source>
<owner>
<flickrid>NULL</flickrid>
<name>chriszz</name>
</owner>
<size>
<width>1280</width>
<height>720</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>369</xmin>
<ymin>403</ymin>
<xmax>409</xmax>
<ymax>418</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>434</xmin>
<ymin>375</ymin>
<xmax>443</xmax>
<ymax>401</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>461</xmin>
<ymin>368</ymin>
<xmax>471</xmax>
<ymax>395</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>571</xmin>
<ymin>473</ymin>
<xmax>593</xmax>
<ymax>490</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>674</xmin>
<ymin>470</ymin>
<xmax>683</xmax>
<ymax>478</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>693</xmin>
<ymin>471</ymin>
<xmax>714</xmax>
<ymax>480</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>976</xmin>
<ymin>413</ymin>
<xmax>998</xmax>
<ymax>438</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1004</xmin>
<ymin>396</ymin>
<xmax>1011</xmax>
<ymax>410</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1024</xmin>
<ymin>388</ymin>
<xmax>1031</xmax>
<ymax>405</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1046</xmin>
<ymin>388</ymin>
<xmax>1071</xmax>
<ymax>406</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>1114</xmin>
<ymin>390</ymin>
<xmax>1143</xmax>
<ymax>410</ymax>
</bndbox>
</object>
<object>
<name>sign</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>913</xmin>
<ymin>431</ymin>
<xmax>928</xmax>
<ymax>458</ymax>
</bndbox>
</object>
</annotation>
记得所有xml文件的文件名要和图片序号一一对应:000001.xml对应000001.png
并且,所有xml文件放到Annotations目录中
0.3 txt文件指定训练集、测试集等
在ImageSets/Main目录下保存这些文件。比如我的任务是检测交通标识,只有一个类别需要检测,或者说是二分类问题,只需要判断一个bbox区域是否为交通标识(sign),那么我创建sign对应的4个文件;以及4个表示总体的训练、验证、训练验证、测试的txt文件:
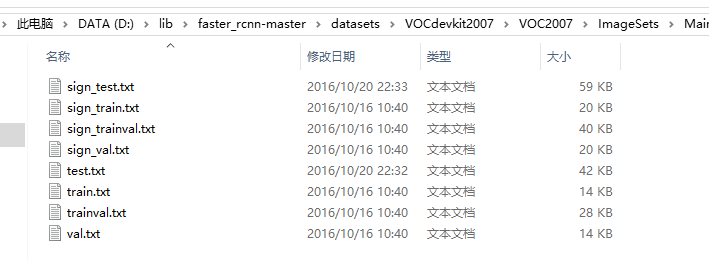
其中,sign_train、sign_test、sign_trainval、sign_val每行格式相同
图片id(不带后缀,不用全路径) +1或-1(表示这张图片中是否包含sign类别的区域)
对于我的情况,类别标签都是+1
然后是train、val、trainval、test文件,其中trainval是train和val的拼接。
这里我是需要
1 修改faster-rcnn的几个代码细节
1.0 experiments\script_faster_rcnn_VOC2007_ZF.m第30、31行
这里默认居然是用select search生成region proposal,我也是醉了。
改成:
dataset = Dataset.voc2007_trainval(dataset, 'train', use_flipped);
dataset = Dataset.voc2007_test(dataset, 'test', false);
1.1 experiments\+Dataset\voc2007_test.m第11行、第14行,test改成val
这个真的是太坑了,在这里我卡了大半天。为什么会卡在这个地方,然后程序一直运行出错呢?以及,程序出错大概如下:
错误使用 proposal_prepare_image_roidb>scale_rois (line 110) 两个输入数组的单一维度必须相互匹配,...
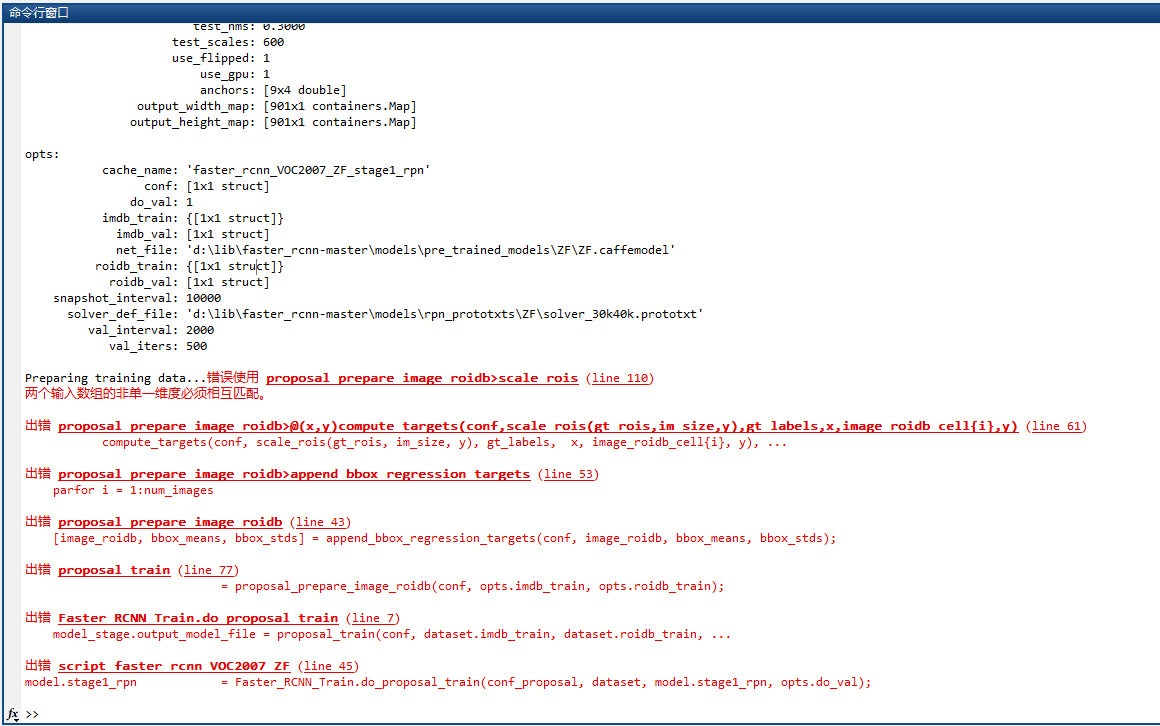
设断点debug后发现,roidb_train里各种字段都有值(比如gt、坐标、阈值、类别等);而roidb_val里面是空的。
实际上是在experiments\+Faster_RCNN_Train\do_proposal_train.m里面,把dataset.roidb_test赋值给roidb_val了:
function model_stage = do_proposal_train(conf, dataset, model_stage, do_val)
if ~do_val
dataset.imdb_test = struct();
dataset.roidb_test = struct();
end
model_stage.output_model_file = proposal_train(conf, dataset.imdb_train, dataset.roidb_train, ...
'do_val', do_val, ...
'imdb_val', dataset.imdb_test, ...
'roidb_val', dataset.roidb_test, ... # 尼玛,在这里赋值了
'solver_def_file', model_stage.solver_def_file, ...
'net_file', model_stage.init_net_file, ...
'cache_name', model_stage.cache_name);
end
问题就是在这里了,不多说。那么接下来就是把experiments\+Dataset\voc2007_test.m第11行、第14行,test改成val,保证以后在imdb\cache目录下有val的mat数据存在,roidb_val也不会说里面内容都为空的了。
2 修改网络参数
看到下面这张图应该知道要改那几个文件了:
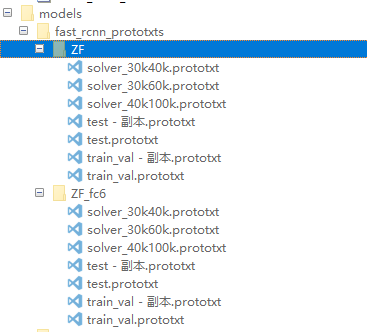
具体可以参考小咸鱼的faster-rcnn matlab版的配置
【faster-rcnn】训练自己的数据集时的坑的更多相关文章
- faster rcnn训练自己的数据集
采用Pascal VOC数据集的组织结构,来构建自己的数据集,这种方法是faster rcnn最便捷的训练方式
- Fast R-CNN训练自己的数据集时遇到的报错及解决方案
最近使用Fast R-CNN训练了实验室的数据集,期间遇到一些报错,主要还是在配置环境上比较麻烦,但可以根据提示在网上找到解决这些错误的办法.这里我只记录一些难改的报错,以后再遇见这些时希望能尽快解决 ...
- Faster Rcnn训练自己的数据集过程大白话记录
声明:每人都有自己的理解,动手实践才能对细节更加理解! 一.算法理解 此处省略一万字.................. 二.训练及源码理解 首先配置: 在./lib/utils文件下....运行 p ...
- caffe学习三:使用Faster RCNN训练自己的数据
本文假设你已经完成了安装,并可以运行demo.py 不会安装且用PASCAL VOC数据集的请看另来两篇博客. caffe学习一:ubuntu16.04下跑Faster R-CNN demo (基于c ...
- 如何才能将Faster R-CNN训练起来?
如何才能将Faster R-CNN训练起来? 首先进入 Faster RCNN 的官网啦,即:https://github.com/rbgirshick/py-faster-rcnn#installa ...
- Fast RCNN 训练自己的数据集(3训练和检测)
转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https://github.com/YihangLou/fas ...
- python3 + Tensorflow + Faster R-CNN训练自己的数据
之前实现过faster rcnn, 但是因为各种原因,有需要实现一次,而且发现许多博客都不全面.现在发现了一个比较全面的博客.自己根据这篇博客实现的也比较顺利.在此记录一下(照搬). 原博客:http ...
- faster rcnn训练详解
http://blog.csdn.net/zy1034092330/article/details/62044941 py-faster-rcnn训练自己的数据:流程很详细并附代码 https://h ...
- caffe 用faster rcnn 训练自己的数据 遇到的问题
1 . 怎么处理那些pyx和.c .h文件 在lib下有一些文件为.pyx文件,遇到不能import可以cython 那个文件,然后把lib文件夹重新make一下. 遇到.c 和 .h一样的操作. 2 ...
随机推荐
- javascript中使用循环链表实现约瑟夫环问题
1.问题 传说在公元1 世纪的犹太战争中,犹太历史学家弗拉维奥·约瑟夫斯和他的40 个同胞被罗马士兵包围.犹太士兵决定宁可自杀也不做俘虏,于是商量出了一个自杀方案.他们围成一个圈,从一个人开始,数到第 ...
- 关于调试日志Log
__VA_ARGS__ 是一个可变参数的宏,这个可变参数的宏是新的C99规范中新增的,目前似乎只有gcc支持(VC6.0的编译器不支持).宏前面加上##的作用在于,当可变参数的个数为0时,这里的## ...
- HRV基础
Source: Mostly from wiki. Heart rate variability (HRV,心率变异性) is the physiological phenomenon of vari ...
- Web API删除JSON格式的文件记录
Insus.NET的系列Web Api学习文章,这篇算是计划中最后一篇了,删除JSON格式的文件记录.前一篇<Web Api其中的PUT功能演示>http://www.cnblogs.co ...
- jinja模版
实现不同机器的差异化配置 把apache监听的端口统一改为8080 把配置文件files/httpd.conf 文件做成模版 修改lamp.sl ...
- Android 编译命令 make j8 2>&1 | tee build.log 解释
在编译Android的时候,经常看到这样的命令 make -j8 2>&1 | tee build.log 其中 make 是编译命令, -j8 这里的 8 指的是线程数量,就是你要 ...
- 你真的熟悉background吗?
一两个月没更新博客了,因为放假刚在深圳找了实习,一直都比较忙碌,不过我觉得再忙,还是需要时间去沉淀一些东西,工作的时候别人看到的只是你有没有实现最终的结果,但自己是否思考,是否去总结,决定着你工作是否 ...
- javascript 中加’var‘和不加'var'的区别,你真的懂吗?
没看之前千万别说我是标题党,这个问题真的有好多淫都不懂!!! 大家都看了很多文章,都说避免隐式声明全局变量,就是说声明变量前必须加'var',那加了'var'和不加'var'到底有啥区别呢? 先来看一 ...
- 样条函数 -- spline function
一类分段(片)光滑.并且在各段交接处也有一定光滑性的函数.简称样条.样条一词来源于工程绘图人员为了将一些指定点连接成一条光顺曲线所使用的工具,即富有弹性的细木条或薄钢条.由这样的样条形成的曲线在连接点 ...
- viso图插入Word中大片空白解决办法
按住CTRL-->将鼠标指向绘图页边缘-->指针变为移动符号(双向箭头)-->按下左键修改绘图页大小.