MySQL字符集不一致导致性能下降25%,你敢信?
sysbench使用utf8mb4测试:
在进一步测试的时候,我修改了/usr/share/sysbench/oltp_common.lua脚本的如下部分,使之在建立数据库连接的时候执行"SET NAMES utf8mb4"(用途请参考https://dev.mysql.com/doc/refman/5.7/en/set-names.html),设置字符集为utf8mb4
function thread_init()
drv = sysbench.sql.driver()
con = drv:connect()
con:query("SET NAMES utf8mb4")
照这样设置之后,character_set_server && database characterset && table characterset && Client characterset 都是utf8mb4了。
测试结果显示,my_ismbchar_utf8mb4和my_charpos_mb还是会消耗掉10%以上的CPU资源。而且,只要是character_set_server || table characterset || Client characterset的任何一个使用utf8mb4字符集,都会导致这个问题。
使用utf8字符集进行测试,也有类似的问题,只不过消耗CPU资源较多的函数是my_ismbchar_utf8和my_charpos_mb。
所以我对这篇博客进行更正,结论是:不是因为character_set_server, table characterset, Client characterset字符集设置不一致导致性能差异,而是因为MySQL5.7在使用utf8/utf8mb4字符集的时候会有很高的额外开销。
但是,我们不能因为utf8有额外开销就不用它,对吧?毕竟latin1不支持中文……
因为MySQL8开始默认字符集变成了utf8mb4,所以我也对MySQL 8.0.19进行了测试,结果显示不存在这个问题;将字符集改成latin1进行测试,性能比utf8mb4并没有提升……
----------------------------------------------------分割线。以下是2020.3.15日的原文,原标题是《MySQL字符集不一致导致性能下降25%,你敢信?》。以上是更新/更正的内容----------------------------------------------------
故事是这样的:
我在对MySQL进行性能测试时,发现CPU使用率接近100%,其中80%us, 16%sys,3%wa,iostat发现磁盘iops2000以下,avgqu-sz不超过3,%util最高70%,看来瓶颈不在磁盘IO上面,而在CPU上。sys部分使用率有点高。
于是我果断使用perf top查看,赫然排在前面的2个,是my_ismbchar_utf8mb4和my_charpos_mb。
my_ismbchar_utf8mb4顾名思义,很明显是与字符集相关的;my_charpos_mb暂时不清楚。

经验告诉我,这很不正常!通常来说,消耗CPU最多的应该是数据页相关的操作才对啊。
我快速打开MySQL internal文档搜索,没找到有价值的信息。
哦,你想要知道这个故事的前情提要?抱歉,我刚刚只说了压测,按照国际惯例,我这就贴出环境和版本信息:
硬件:8核16GB,200GB SSD,腾讯云虚拟机
操作系统版本:CentOS release 6.9 (Final)
MySQL版本:5.7.-log MySQL Community Server (GPL),二进制方式安装
MySQL参数:innodb_buffer_pool_size = 10752M
innodb_flush_log_at_trx_commit =
sync_binlog =
character-set-server = utf8mb4
sysbench版本:1.0.
sysbench参数:sysbench /usr/share/sysbench/oltp_read_write.lua --tables= --table-size= --mysql-password=*** --mysql-user=root --mysql-socket=/usr/local/mysql5.7.28/mysql.sock --threads= --time= run
server的字符集是utf8mb4,接下来检查一下db和表的字符集吧:
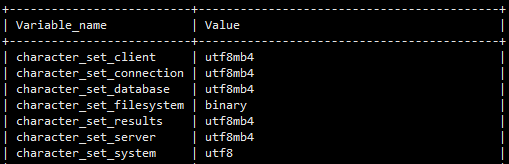


嗯嗯,看起来一切都是那么的正常……
server, DB, table的字符集都一致,现在只剩下sysbench的嫌疑最大!
可是,要怎么检查sysbench已经连接到MySQL的那些会话的字符集设置呢?
我的sysbench命令没有显式地指定字符集;show processlist没有character_set_client信息,information_schema库和mysql库里面也没有与character_set_client信息。
sysbench --help 也没有字符集相关的选项和参数;https://github.com/akopytov/sysbench/blob/master/src/drivers/mysql/drv_mysql.c sysbench源码中也没有字符集相关的设置。
看来,sysbench连接MySQL的字符集设置,应该默认是latin1,应该是这里的字符集设置不一致导致的。
BUT,对于技术问题,我不能光靠猜测啊!我一定要刨根问底,查它个水落石出……
源码:
吃CPU最多的是my_ismbchar_utf8mb4函数对吧?那就先到源码中搜它:
在strings/ctype-utf8.c 中定义的:
static uint
my_ismbchar_utf8mb4(const CHARSET_INFO *cs, const char *b, const char *e)
{
int res= my_valid_mbcharlen_utf8mb4(cs, (const uchar*)b, (const uchar*)e);
return (res > ) ? res : ;
}
它本身没有复杂的逻辑,只是调用了my_valid_mbcharlen_utf8mb4,然后对返回值res 进行判断,如果>1,就返回res,否则返回0。
行,那我再看看my_valid_mbcharlen_utf8mb4吧,
static int
my_valid_mbcharlen_utf8mb4(const CHARSET_INFO *cs __attribute__((unused)),
const uchar *s, const uchar *e)
{
uchar c; if (s >= e)
return MY_CS_TOOSMALL; c= s[];
if (c < 0xf0)
return my_valid_mbcharlen_utf8mb3(s, e); if (c < 0xf5)
{
if (s + > e) /* We need 4 characters */
return MY_CS_TOOSMALL4; /*
省略若干行……
*/ if (!(IS_CONTINUATION_BYTE(s[]) &&
IS_CONTINUATION_BYTE(s[]) &&
IS_CONTINUATION_BYTE(s[]) &&
(c >= 0xf1 || s[] >= 0x90) &&
(c <= 0xf3 || s[] <= 0x8F)))
return MY_CS_ILSEQ; return ;
} return MY_CS_ILSEQ;
}
这个函数对输入的字符进行比对,判断是utf8mb3还是utf8mb4。utf8mb3?以前没听说过啊!上知乎一搜,原来还有这么一段有趣的历史 ☜
不过,仅仅看这个函数的代码,是不会相信它居然会吃掉7%以上的CPU的。我也不信!
好吧,先做个perf record看看:
#第1步,查看mysqld进程的pid
ps -ef | grep mysqld
#第2步,将mysqld进程相关的cpu-clock事件及调用堆栈记录起来,默认保存在perf.data文件中
perf record -e cpu-clock -g -p
#第3步,用perf script工具对perf.data进行解析
perf script -i perf.data &> perf.unfold
#第4步,下载一个集漂亮、强大于一身的工具:
git clone https://github.com/brendangregg/FlameGraph.git #第5步:将perf.unfold中的符号进行折叠
./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
#第6步,生成火焰图
./FlameGraph/flamegraph.pl perf.folded > perf.svg
效果就是这样的↓ 可以看出,my_ismbchar_utf8mb4占比确实最高,达到了7.47%
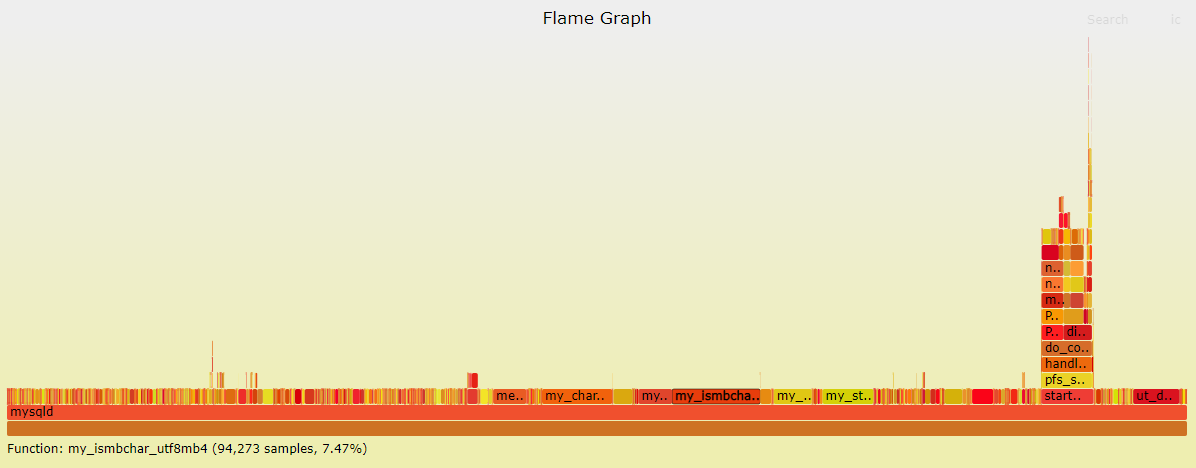
去跟踪调用堆栈,可以发现是在sql\sql_lex.cc中的get_text()函数中,调用了宏use_mb和my_ismbchar来检查字符集。
这2个宏同样都是调用ismbchar() - detects whether the given string is a multi-byte sequence。 utf8mb4中的mb,全称就是multi-byte
static char *get_text(Lex_input_stream *lip, int pre_skip, int post_skip)
{
uchar c,sep;
uint found_escape=;
const CHARSET_INFO *cs= lip->m_thd->charset(); lip->tok_bitmap= ;
sep= lip->yyGetLast(); // String should end with this
while (! lip->eof())
{
c= lip->yyGet();
lip->tok_bitmap|= c;
{
int l;
if (use_mb(cs) &&
(l = my_ismbchar(cs,
lip->get_ptr() -,
lip->get_end_of_query()))) {
lip->skip_binary(l-);
continue;
}
}
if (c == '\\' &&
!(lip->m_thd->variables.sql_mode & MODE_NO_BACKSLASH_ESCAPES))
{ // Escaped character
found_escape=;
if (lip->eof())
return ;
lip->yySkip();
}
// 省略若干行……
}
return ; // unexpected end of query
}
解决方法:
上面说了一大通,可能有点云里雾里,抱歉哈,我能力有限,不能把它解释得更通俗一些。
简而言之,就是证明了确实是字符集不一致,导致MySQL在语法解析的时候,对每一个用户输入的字符(MySQL关键字除外),都要进行若干次字符集检查,所以才会发生my_ismbchar_utf8mb4吃掉很多CPU资源这样一个故事 。
要解决就很简单啦:保持character_set_server && database characterset && table characterset && Client characterset一致!
我就是因为忽略了sysbench的字符集设置,所以才把自己给坑了。
既然sysbench没有提供字符集相关的选项和参数,那我就把MySQL的字符集统一成latin1来测吧(也可以去修改sysbench的mysql driver源码,让它支持设置字符集,但是我不擅长C……)
最后总结:
调整字符集之前,QPS最高只能压到73797,统一字符集之后,QPS达到了98272。 73797/98272*100%=75.09%

再来看看TPS,调整字符集之前,TPS最高只能压到3689,统一字符集之后,TPS达到了3689。 73797/4913*100%=75.08%
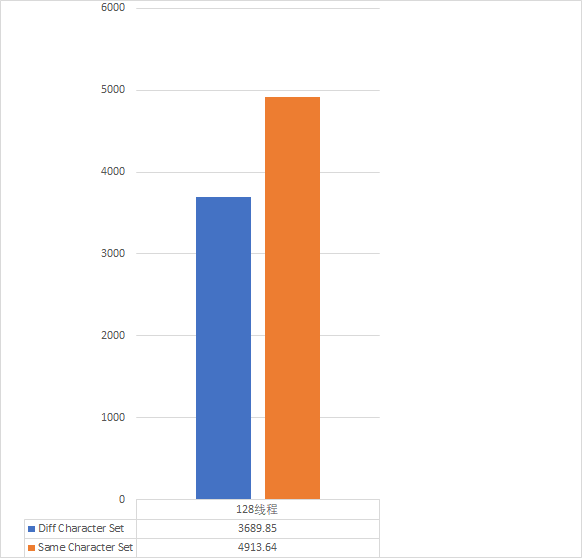
多么痛的领悟……
MySQL字符集不一致导致性能下降25%,你敢信?的更多相关文章
- MySQL字符集不一致导致查询SQL性能问题
今天做了一个MySQL数据库中的SQL优化. 结论是关联字段字符集不同,导致索引不可用. 查询的SQL如下: select `Alias`.`Grade`, `Alias`.`id`, `Alias` ...
- (转)一个MySQL 5.7 分区表性能下降的案例分析
一个MySQL 5.7 分区表性能下降的案例分析 原文:http://www.talkwithtrend.com/Article/216803 前言 希望通过本文,使MySQL5.7.18的使用者知晓 ...
- Optional 的使用会导致性能下降吗?
几天前,我在论坛上发了一篇关于Optional 的文章.其中一条评论是一个非常好的问题: Optional 的使用会导致性能下降吗? 答案是: 是的,它会的.但是你应该担心吗? 使用Optional的 ...
- MySQL 5.7 分区表性能下降的案例分析
转载自:https://mp.weixin.qq.com/s/K3RpSBAIWFwGCIWyfF0QPA 前言:希望通过本文,使MySQL5.7.18的使用者知晓分区表使用中存在的陷阱,避免在该版本 ...
- 一个MySQL 5.7 分区表性能下降的案例分析
告知MySQL5.7.18的使用者分区表使用中存在的陷阱,避免在该版本上继续踩坑.同时通过对源码的讲解,升级MySQL5.7.18时分区表性能下降的根本原因,向MySQL源码爱好者展示分区表实现中锁的 ...
- jvm的代码缓存耗尽导致性能下降
在没遇到这个问题之前,我对JVM的解释模式与编译模式的代码性能相差有多大,是没有感觉的,只是觉得编译模式会比解释模式性能好那么一点点吧. 但是经历过这次以后,让我对JVM的即时编译产生了兴趣.先来看看 ...
- MySQL编码不一致导致查询结果为空
升级数据库后(5.1到8.0),发现一个奇怪的问题,某些页面在升级前可以正常查询,但升级后什么也查不出来了,有时候还会查出错误的结果.经过一整天的排查,终于发现由两个原因导致,现记录如下. 第一是数据 ...
- MySQL字符集不一致的解决办法总结
用SHOW CREATE TABLE table_name;可以看出具体的字符集设置. 错误代码: Illegal mix of collations (utf8mb4_unicode_ci,IMPL ...
- Oracle迁移到MySQL性能下降的注意点(转)
背景:最近有较多的客户系统由原来由Oracle改造到MySQL后出现了性能问题CPU 100%,或是后台的CRM系统复杂SQL在业务高峰的时候出现堆积导致业务故障.在我的记忆里面淘宝最初从Oracle ...
随机推荐
- sqlite基础API
/* 打开/创建数据库文件 * 如果数据库文件不存在就创建数据库文件. * 数据库操作句柄保存在第二个参数中. * 第一个参数:文件路径及其文件名 * 第二个参数:sqlite3操作句柄 * 返回值: ...
- 微信小程序开发-易源API的调用
起因:在开发一款旅游类微信小程序时,需要接入大量的景点信息,此时可以选择自己新建数据库导入数据并读取,但是对于我来说,因为只有一个人,数据库还涉及到需要维护方面,选择调用已有API. 过程:首先查阅微 ...
- getline的使用
函数定义: getline(istream &in, string &s) 作用: 在C++中用 string 类型进行终端输入字符串时,解决无法输入带有空格的字符串的问题. 功能: ...
- 吴裕雄--天生自然操作系统操作笔记:window10显示隐藏文件夹
基于安全考虑,操作系统会隐藏一些文件和文件夹,防止误删除操作.但有可能是个别人为了隐藏一些私密数据,也同样采取隐藏的方式.
- [洛谷P4782] [模板] 2-SAT 问题
NOIp后第一篇题解. NOIp我考的很凉啊...... 题目传送门 之前讲过怎么判断2-SAT是否存在解. 至于如何构造一组解: 我们想到对tarjan缩点后的图进行拓扑排序. 那么对于代表0状态的 ...
- C语言学习笔记之字符串拼接的2种方法——strcat、sprintf
本文为原创文章,转载请标明出处 1. 使用strcat进行字符串拼接 #include <stdio.h> #include <stdlib.h> #include <s ...
- 分布式事物-2pc和3pc区别
参考地址: https://www.cnblogs.com/bangerlee/p/5268485.html, 感谢原作者 http://blog.51cto.com/11821908/2058651 ...
- Flash Builder 使用
1. 解决编译慢的问题:用记事本打开安装目录下的 FlashBuilder.ini ,将里面设置的容量都扩大一半,如-Xms256m改为 -Xms512m,另外几项类似修改: 定位到相应版本的sdks ...
- 吴裕雄--天生自然 R语言开发学习:分类(续一)
#-----------------------------------------------------------------------------# # R in Action (2nd e ...
- maven创建Java项目命令
1.maven创建普通Java项目的命令 mvn archetype:create -DgroupId=packageName -DartifactId=projectName 2.maven创建Ja ...