Django之ORM配置与单表操作
ORM数据库操作流程:
1. 配置数据库(项目同名包中settings.py和__init__.py)
2. 定义类(app包中models.py),执行建表命令(Tools--->Run managy.py Task:makemigrations ---> migrate)
3. 视图(app包中views.py)中定义相关的函数数据库表操作语句
ORM数据库配置:
· 默认配置情况下,ORM使用jango自带的数据库db(在项目文件settings.py中默认配置项:DATABASES)
· 自定义数据库配置(推荐):
以Mysql为例:
修改项目文件settings.py文件中的DATABASES配置:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql', # 指定数据库引擎
'NAME': 'ormtest', # 指定数据库
'USER': "root", # 配置数据库用户名
'PASSWORD': '', # 配置数据库密码
'HOST': '127.0.0.1', # 配置数据库地址ip
'PORT': 3306, # 配置数据库端口port
# 'OPTIONS': {
# 'init_command': "SET default_storage_engine='INNODB'",
# 'init_command': "SET sql_mode='STRICT_TRANS_TABLES'", } #设置数据库的严格模式
}
}
打印orm翻译成的sql语句配置:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
配置项目同名的包中__init__.py文件:
import pymysql
pymysql.install_as_MySQLdb()
ORM的建表语句规则:
· 在app应用的models.py模块中定义类(必须继承models.Model)
· 类名对应表名,属性对应表字段(数据库中的实际表名:app应用名_类名(全小写),例如:app01_book)
· 属性调用models中不同的类方法(如:models.CharField())对表字段进行类型设置,字符串必须指定最大长度
· 在不设置id指定主键的情况下,orm会自动创建一个主键字段id,可以使用id或者pk来调用其值
· 约束条件和长度当成属性类型实例化类的参数,不指定null时默认为非空约束
定义类:app应用包中models.py
from django.db import models
class Book(models.Model):
# id=models.AutoField(primary_key=True) #不写会自动创建
name=models.CharField(max_length=32)
price=models.FloatField()
date=models.DateField()
publisher=models.CharField(max_length=32)
update_time=models.DateTimeField(auto_now=True)
执行创建命令:
工具栏Tools--->Run managy.py Task(或者Ctrl+alt+R)
>>>makemigrations
>>>migrate
ORM单表操作:
增:
单个插入:
(1)实例化对象,调用对象save方法
obj=models.Book(name="完美人生",price=10.00,date='2019-05-24',publisher='未来出版社')
obj.save() #就是pymysql的那个commit提交
(2)调用控制器objects的create方法(常用)
models.Book1.objects.create(name="完美人生",price=10.00,date='2019-05-24',publisher='未来出版社')
或(用**将字典打散,在前端发送来数据先用dic=request.POST.dict()直接转成dic字典)
book={'name':"完美人生",'price':10.00,'date':'2019-05-24','publisher':'未来出版社'}
models.Book.objects.create(**book)
其他插入:
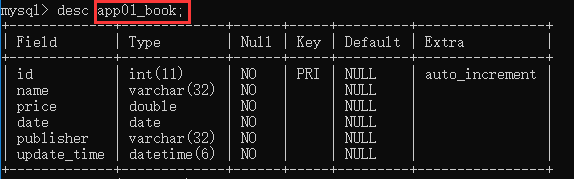
(1)批量插入:先实例化对象,存在一个列表,再调用控制器objects的bulk_create方法
li = []
book_li = [["书籍1", 12, '2019-05-01', '不详'],
["书籍2", 13, '2019-05-04', '不详'],
["书籍3", 13, '2019-05-04', '不详'],
["书籍4", 15, '2019-05-05', '不详']
]
for book in book_li:
book_obj = models.Book(name=book[0], price=book[1], date=book[2], publisher=book[3])
li.append(book_obj)
models.Book.objects.bulk_create(li)
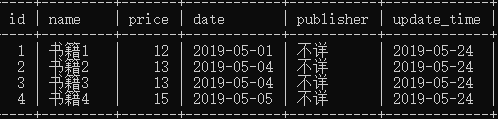
(2)更新或插入:调用控制器objects的update_or_create方法(先查有则更新无则追加)
models.Book.objects.update_or_create(
name="书籍1", #先用get查询(最多只能查到一条,否则报错),找到的更新,找不到追加本条信息
defaults={ #设置更新或者追加的值
"name":"书籍2"
}
)
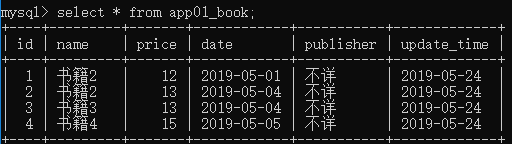
models.Book.objects.update_or_create(
name="书籍2",
defaults={
'price':14
}
)

删:(filter得到的query set和get得到的model对象均可调用delete方法)
models.Book.objects.filter(pk=1).delete()
或
models.Book.objects.get(pk=1).delete()
或
改:(只有filter得到的query set才可调用update方法)
models.Book.objects.filter(id=3).update(price=20)
查:
查所有(QuerySet):
ret =models.Book.objects.all()
print(ret)
查询结果为QuerySet:
<QuerySet [<Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>, <Book: Book object>]>
有且仅有一条(类对象):
ret=models.Book.objects.get(id=2) 只有一条正常显示
print(ret)
查询结果为类对象:
Book object
ret=models.Book.objects.get(id=2) 没有会报错

ret=models.Book.objects.get(name="书籍2") 超过一条报错

选择性查询(QuerySet):
ret=models.Book.objects.filter(name="书籍2")
print(ret)
查询结果QuerySet:
<QuerySet [<Book: Book object>, <Book: Book object>]>
filter选择性查询条件:
以下是常用的双下划线条件:
models.Book.objects.filter(price=10)#等于某个值
models.Book.objects.filter(price__gt=13)#大于某个值
models.Book.objects.filter(price__lt=13)#小于某个值
models.Book.objects.filter(price__in=[12,14,15])#在某几个元素中
models.Book.objects.filter(price__range=(11,15))#在某个范围内(前后包含)
models.Book.objects.filter(name__contains="书籍")#内容包括某个值
models.Book.objects.filter(name__icontains="pyhton")#内容包含某个值(加i不区分大小写)
models.Book.objects.filter(name__startswith="书籍")#以某个值开头
models.Book.objects.filter(name__istartswith="python")#以某个值开头(加i不区分大小写)
models.Book.objects.filter(date__year=2019,date__month=12,date__day=2)#年月日为某个值
查询API:
|
1 |
all() |
查询所有结果,结果是queryset类型 |
|
2 |
filter(**kwargs): |
· 它包含了与所给筛选条件相匹配的对象,结果也是queryset类型 · Book.objects.filter(title='linux',price=100) #里面的多个条件用逗号分开,并且这几个条件必须都成立,是and的关系 · queryset对象也可调用filter · 控制器可直接调用filter |
|
3 |
get(**kwargs) |
返回与所给筛选条件相匹配的对象,不是queryset类型,是行记录对象,返回结果有且只有一个, 如果符合筛选条件的对象超过一个或者没有都会抛出错误。捕获异常try。 Book.objects.get(id=1) |
|
4 |
exclude(**kwargs) |
· 排除的意思,它包含了与所给筛选条件不匹配的对象, · 直接用exclude,返回值是queryset类型 · Book.objects.exclude(id=6),返回id不等于6的所有的对象, · 或者在queryset基础上调用,Book.objects.all().exclude(id=6) |
|
5 |
order_by(*field) |
· queryset类型的数据来调用,对查询结果排序,默认是按照id来升序排列的,返回值还是queryset类型; · models.Book.objects.all().order_by('price','id') #直接写price,默认是按照price升序排列, · 按照字段降序排列,就写个负号就行了order_by('-price'), · order_by('price','id')是多条件排序,按照price进行升序,price相同的数据,按照id进行升序 |
|
6 |
reverse() |
queryset类型的数据来调用,对查询(order_by之后)结果反向排序,返回值还是queryset类型 |
|
7 |
count() |
queryset类型的数据来调用,返回数据库中匹配查询(QuerySet)的对象数量。 |
|
8 |
first() |
· queryset类型的数据来调用,返回第一条记录 · 控制器调用返回第一个对象 · Book.objects.all()[0] = Book.objects.all().first(),得到的都是model对象,不是queryset |
|
9 |
last() |
queryset类型的数据来调用,返回最后一条记录 |
|
10 |
exists() |
· queryset类型的数据来调用,如果QuerySet包含数据,就返回True,否则返回False; · 空的queryset类型数据也有布尔值True和False,但是一般不用查询的queryset结果直接来判断数据库里面是不是有数据,如果有大量的数据,你用它来判断,那么就需要查询出所有的数据,效率太差了,用count或者exits · 例:all_books = models.Book.objects.all().exists() #翻译成的sql是SELECT (1) AS `a` FROM `app01_book` LIMIT 1,就是通过limit 1,取一条来看看是不是有数据 |
|
11 |
values(*field) |
· 控制器调用 · queryset类型的数据来调用,返回一个ValueQuerySet——一个特殊的QuerySet, · 运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列, · 只要是返回的queryset类型,就可以继续链式调用queryset类型的其他的查找方法,其他方法也是一样的。 |
|
12 |
values_list(*field) |
它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 |
|
13 |
distinct() |
values和values_list得到的queryset类型的数据来调用,从返回结果中剔除重复纪录 |
Django之ORM配置与单表操作的更多相关文章
- web框架开发-Django模型层(1)之ORM简介和单表操作
ORM简介 不需要使用pymysql的硬编码方式,在py文件中写sql语句,提供更简便,更上层的接口,数据迁移方便(有转换的引擎,方便迁移到不同的数据库平台)…(很多优点),缺点,因为多了转换环节,效 ...
- Django之模型层(单表操作)
一.ORM简介 MVC和MTV框架中包含一个重要部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库. ORM是‘对象-关系- ...
- Django基础(3)----模型层-单表操作,多表创建
昨日内容回顾: 1. {% include '' %} 2. extend base.html: <html> ..... ..... ..... {% block content%} { ...
- Django 学习 之ORM简介与单表操作
一.ORM简介 1.ORM概念 对象关系映射(Object Relational Mapping,简称ORM). 简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到 ...
- Hibernate原理、配置及单表操作
一.Hibernate的配置文档 其中:hbm2ddl.auto中的create表示每次修改数据的时候都会删除原有的表,生成新的表结构,原有的数据不再存在:update表示在原有数据的基础上进行更新, ...
- Django中ORM简介与单表数据操作
一. ORM简介 概念:.ORM框架是用于实现面向对象编程语言种不同类型系统的数据之间的转换 构建模型的步骤:重点 (1).配置目标数据库信息,在seting.py中设置数据库信息 DATABASE ...
- ORM 简介 单表操作
cls超 Django基础五之django模型层(一)单表操作 本节目录 一 ORM简介 二 单表操作 三xxx 一 ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型 ...
- 单表操作ORM
博客园 首页 新随笔 联系 管理 订阅 随笔- 0 文章- 339 评论- 29 Django基础五之django模型层(一)单表操作 本节目录 一 ORM简介 二 单表操作 三 章节作业 ...
- day 69 Django基础五之django模型层(一)单表操作
Django基础五之django模型层(一)单表操作 本节目录 一 ORM简介 二 单表操作 三 章节作业 四 xxx 一 ORM简介 MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现 ...
随机推荐
- 点击表头取下标&js时间转时间戳
1.Date.parse(new Date("2017-7-31")); 2.$("th").eq(this.cellIndex); // 3.end($ar ...
- web.config 301
<?xml version="1.0" encoding="UTF-8"?> <configuration> <system.we ...
- 2019-2020-1 20199328《Linux内核原理与分析》第十一周作业
预备实验部分 2019/11/27 10:17:34 下载安装后的界面,如图1 出现vulnerable字样,发现了shellshock漏洞,如图2 实验部分 2019/11/27 10:26:48 ...
- javescrip内嵌样式与外联样式怎么做?
对于前端初学者,个人JS样式常用的有两种:内嵌样式 ,外联样式:下面通过一个简单的鼠标点击出现设定的验证数字为例进行演示: 先看下效果: 鼠标点击前效果: 鼠标点击后效果: 图中的这个ojbk是我js ...
- 国际站中国区,孟买上Redis 4.0 集群版
信息摘要: 国际站中国区,孟买上线Redis 4.0 集群版适用客户: 所有用户版本/规格功能: redis 4.0 集群版产品文档: https://www.alibabacloud.com/hel ...
- 《WCF技术内幕》翻译3:第1部分_第1章_蓝月亮:普遍需求和普遍概念
第一部分:WCF介绍 章节目录: 第1章:蓝月亮 第2章:面向服务 第3章:消息交换模式.拓扑和编排 第4章:WCF 101 第1章:蓝月亮 商业和市场对软件系统新 ...
- cookie ,session 和localStorage的区别详解
2019独角兽企业重金招聘Python工程师标准>>> cookie ,session 和localStorage的区别详解 博客分类: js 当你在浏览网站的时候,WEB 服务器会 ...
- 3DMAX导出到Unity坐标轴转换问题
这是我在3dmax中创建的1cm*1cm*1cm的立方体,右图为3dmax中的坐标系 当我们把这个立方体导入到unity中发现x轴意外的扭转了90度 为了解决这个问题,你需要对模型做出修正 1.选 ...
- DeepWalk论文精读:(1)解决问题&相关工作
模块1 1. 研究背景 随着互联网的发展,社交网络逐渐复杂化.多元化.在一个社交网络中,充斥着不同类型的用户,用户间产生各式各样的互动联系,形成大小不一的社群.为了对社交网络进行研究分析,需要将网络中 ...
- Codeforces 1291 Round #616 (Div. 2) C. Mind Control(超级详细)
C. Mind Control You and your n−1 friends have found an array of integers a1,a2,-,an. You have decide ...