(数据科学学习手札86)全平台支持的pandas运算加速神器
本文示例代码已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
随着其功能的不断优化与扩充,pandas已然成为数据分析领域最受欢迎的工具之一,但其仍然有着一个不容忽视的短板——难以快速处理大型数据集,这是由于pandas中的工作流往往是建立在单进程的基础上,使得其只能利用单个处理器核心来实现各种计算操作,这就使得pandas在处理百万级、千万级甚至更大数据量时,出现了明显的性能瓶颈。
本文要介绍的工具modin就是一个致力于在改变代码量最少的前提下,调用起多核计算资源,对pandas的计算过程进行并行化改造的Python库,并且随着其近期的一系列内容更新,modin基于Dask开始对Windows系统同样进行了支持,使得我们只需要改变一行代码,就可以在所有平台上获得部分pandas功能可观的计算效率提升。
 图1
图1
2 基于modin的pandas运算加速
modin支持Windows、Linux以及Mac系统,其中Linux与Mac平台版本的modin工作时可基于并行运算框架Ray和Dask,而Windows平台版本目前只支持Dask作为计算后端(因为Ray没有Win版本),安装起来十分方便,可以用如下3种命令来安装具有不同后端的modin:
pip install modin[dask] # 安装dask后端
pip install modin[ray] # 安装ray后端(windows不支持)
pip install modin[all] # 推荐方式,自动安装当前系统支持的所有后端
本文在Win10系统上演示modin的功能,执行命令:
pip install modin[all]
成功安装modin+dask之后,在使用modin时,只需要将我们习惯的import pandas as pd变更为import modin.pandas as pd即可,接下来我们来看一下在一些常见功能上,pandasVSmodin性能差异情况,首先我们分别使用pandas和modin读入一个大小为1.1G的csv文件esea_master_dmg_demos.part1.csv,来自kaggle(https://www.kaggle.com/skihikingkevin/csgo-matchmaking-damage/data),记录了关于热门游戏CS:GO的一些玩家行为数据,因为体积过大,请感兴趣的读者朋友自行去下载:
 图2
图2
为了区分他们,在导入时暂时将modin.pandas命名为mpd:
 图3
图3
可以看到因为是Win平台,所以使用的计算后端为Dask,首先我们来分别读入文件查看耗时:
 图4
图4
借助jupyter notebook记录计算时间的插件,可以看到原生的pandas耗时14.8秒,而modin只用了5.32秒,接着我们再来试试concat操作:
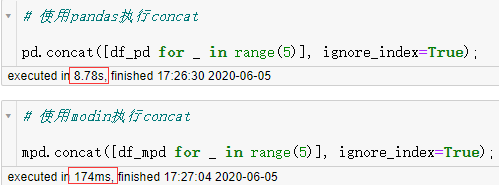 图5
图5
可以看到在pandas花了8.78秒才完成任务的情况下,modin仅用了0.174秒,取得了惊人的效率提升。接下来我们再来执行常见的检查每列缺失情况的任务:
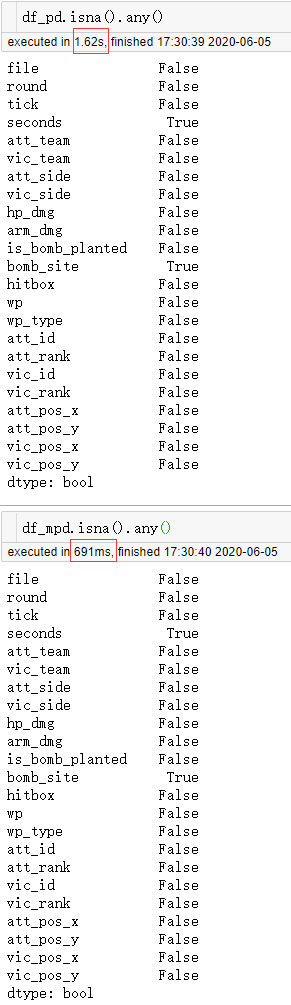 图6
图6
这时耗时差距虽然不如concat操作时那么巨大,也是比较可观的,但是modin毕竟是一个处理快速开发迭代阶段的工具,其针对pandas的并行化改造尚未覆盖全部的功能,譬如分组聚合功能。对于这部分功能,modin会在执行代码时检查自己是否支持,对于尚未支持的功能modin会自动切换到pandas单核后端来执行运算,但由于modin中组织数据的形式与pandas不相同,所以中间需要经历转换:
 图7
图7
这种时候modin的运算反而会比pandas慢很多:
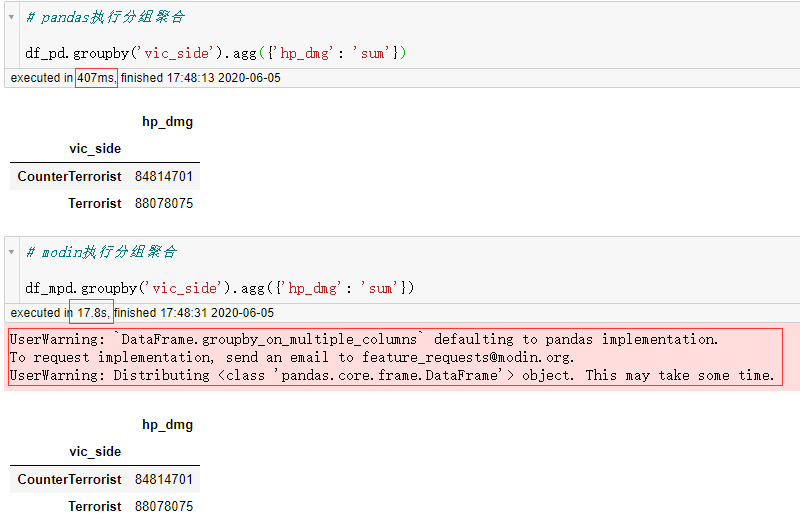 图8
图8
因此我对modin持有的态度是在处理大型数据集时,部分应用场景可以用其替换pandas,即其已经完成可靠并行化改造的pandas功能,你可以在官网对应界面(https://modin.readthedocs.io/en/latest/supported_apis/index.html )查看其已经支持及尚未良好支持的功能,,因为modin还处于快速开发阶段,很多目前无法支持的功能也许未来不久就会被加入modin:
 图9
图9
以上就是本文的全部内容,如有疑问欢迎在评论区与我讨论。
(数据科学学习手札86)全平台支持的pandas运算加速神器的更多相关文章
- (数据科学学习手札72)用pdpipe搭建pandas数据分析流水线
1 简介 在数据分析任务中,从原始数据读入,到最后分析结果出炉,中间绝大部分时间都是在对数据进行一步又一步的加工规整,以流水线(pipeline)的方式完成此过程更有利于梳理分析脉络,也更有利于查错改 ...
- (数据科学学习手札134)pyjanitor:为pandas补充更多功能
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 pandas发展了如此多年,所包含的功能已 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札75)基于geopandas的空间数据分析——坐标参考系篇
本文对应代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一篇文章中我们对geopandas中的数据结 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
随机推荐
- mybatis 插入数据返回ID
hibernate中插入数据后会返回插入的数据的ID,mybatis要使用此功能需要在配置文件中显示声明两个属性即可:
- 【Effective Java】第二章-创建和销毁对象——1.考虑用静态工厂方法代替构造器
静态工厂方法的优点: 可以赋予一个具有明确含义的名称 可以复用唯一实例,不必每次新建 可以返回原实例类型的子类对象 可以在返回泛型实例时更加简洁 缺点: 类如果不含有共有的或者受保护的构造器,就不能被 ...
- Navicat15 for Mysql激活教程
1.下载Navicat Premium Navicat15链接:http://www.navicat.com.cn/download/navicat-premium,选择相应版本,这里选择window ...
- Django模板之模板标签
标签比变量更加复杂:一些在输出中创建文本,一些通过循环或逻辑来控制流程,一些加载其后的变量将使用到的额外信息到模版中. 一些标签需要开始和结束标签 (例如:{% tag %} ...标签 内容 ... ...
- OGG应用进程abend报错无法insert虚拟列
环境11.2.0.4 linux6.9 RAC2节点,ogg版本Version 12.2.0.1.160823 OGGCORE_OGGADP.12.2.0.1.0_PLATFORMS_161019.1 ...
- PAT-1057 Stack (树状数组 + 二分查找)
1057. Stack Stack is one of the most fundamental data structures, which is based on the principle of ...
- Nginx301重定向
1)301重定向,把blog.moonsbird.com和moonsbirl.com合并,并把之前的域名也一并合并. 有两种实现方法,第一种方法是判断nginx核心变量host(老版本是http_ho ...
- 关于 conda中的 lxml 无法导入 etree 问题
找到你conda的安装目录下\Lib\site-packages下的两个文件夹lxml和lxml-4.3.4.dist-info,将这两个文件夹删除. 执行命令pip install lxml 重新安 ...
- eatwhatApp开发实战(十一)
之前我们实现了点击item项跳转activity,接下来我们再其基础上添加参数的传递. 在MainActivity里面的onItemClick()中: String name = shopList.g ...
- [PHP学习教程 - 心得]001.偷龙转凤技巧10则(Remember Tips)
引言:PHP当中的一些猬锁技巧,比较基础,想起就发贴总结一下,老鸟换个姿势飘过去就是. [技巧]应该属于“方法”的一个范畴,主要指对一种生活或工作方法的熟练和灵活运用.[五笔]RFAG. 话不多说,下 ...