入门大数据---Flink学习总括
第一节 初识 Flink
在数据激增的时代,催生出了一批计算框架。最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理。Flink相对前两个框架真正做到了高吞吐,低延迟,高性能。
1. Flink 是什么?
1) Flink 的发展历史
在 2010 年至 2014 年间,由柏林工业大学、柏林洪堡大学和哈索普拉特纳研究所联合发起名为“Stratosphere:Information Management on the Cloud”研究项目,该项目在当时的社区逐渐具有了一定的社区知名度。2014 年 4 月,Stratosphere 代码被贡献给 Apache软件基金会,成为Apache基金会孵化器项目。初期参与该项目的核心成员均是Stratosphere曾经的核心成员,之后团队的大部分创始成员离开学校,共同创办了一家名叫 Data Artisans的公司,其主要业务便是将 Stratosphere,也就是之后的 Flink 实现商业化。在项目孵化期间,项目 Stratosphere 改名为 Flink。Flink 在德语中是快速和灵敏的意思,用来体现流式数据处理器速度快和灵活性强等特点,同时使用棕红色松鼠图案作为 Flink 项目的 Logo,也是为了突出松鼠灵活快速的特点,由此,Flink 正式进入社区开发者的视线。
2014 年 12 月,该项目成为 Apache 软件基金会顶级项目,从 2015 年 9 月发布第一个稳定版本 0.9,到目前为止已经发布到 1.9 的版本,更多的社区开发成员逐步加入,现在 Flink在全球范围内拥有 350 多位开发人员,不断有新的特性发布。同时在全球范围内,越来越多的公司开始使用 Flink,在国内比较出名的互联网公司如阿里巴巴、美团、滴滴等,都在大规模使用 Flink 作为企业的分布式大数据处理引擎。
2) Flink 的定义
Flink是一个框架分布式处理引擎,用于在无边界和有边界流上进行有状态计算。它能运行在普通集群上,并能以内存速度和任意规模进行计算。
3) 有界流和无界流
任何类型的数据都可以形成一种事件流。比如浏览网站日志,呼叫记录,传感器采集,所有这些数据都形成一种流。
无界流:有定义流的开始,但没有定义流的结束。它们会无休止的产生数据。无界流数据必须持续处理,即数据被摄取后就需要立即处理。我们不能等到所有数据都到达再处理,因为输入是无界限的,在任何时候输入都不会完成。处理无界数据通常以特定顺序处理事件,例如事件发生的顺序,以便能推断结果的逻辑性。
有界流:有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
Apache Flink擅长处理无界和有界数据集。精确的时间控制和状态变化使得Flink的运行时能够处理任何无界流的应用。有界流则通过一些特殊固定大小的数据集特殊设计的算法和数据结构进行内部处理,产生了出色的性能。
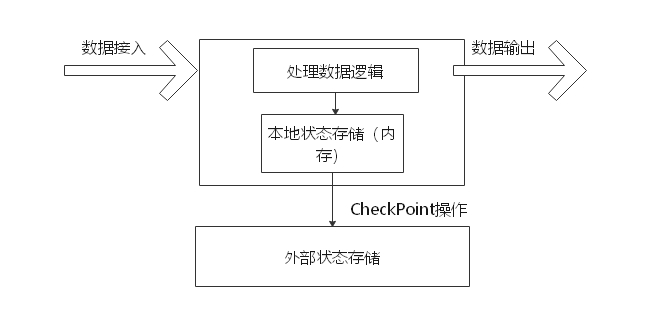
4) 有状态的计算架构
数据产生的本质,其实是一条条真实存在的事件按照时间顺序源源不断的产生,我们很难在数据产生的过程中进行计算并直接产生统计结果,因为这不仅对系统有非常高的要求,还必须要满足高性能、高吞吐、低延时等众多目标。而有状态流计算架构(如图所示)的提出,从一定程度上满足了企业的这种需求,企业基于实时的流式数据,维护所有计算过程的状态,所谓状态就是计算过程中产生的中间计算结果,每次计算新的数据进入到流式系统中都是基于中间状态结果的基础上进行运算,最终产生正确的统计结果。基于有状态计算的方式最大的优势是不需要将原始数据重新从外部存储中拿出来,从而进行全量计算,因为这种计算方式的代价可能是非常高的。从另一个角度讲,用户无须通过调度和协调各种批量计算工具,从数据仓库中获取数据统计结果,然后再落地存储,这些操作全部都可以基于流式计算完成,可以极大地减轻系统对其他框架的依赖,减少数据计算过程中的时间损耗以及硬件存储。
2. 为什么要使用 Flink
可以看出有状态流计算将会逐步成为企业作为构建数据平台的架构模式,而目前从社区来看,能够满足的只有 Apache Flink。Flink 通过实现 Google Dataflow 流式计算模型实现了高吞吐、低延迟、高性能兼具实时流式计算框架。同时 Flink 支持高度容错的状态管理,防止状态在计算过程中因为系统异常而出现丢失,Flink 周期性地通过分布式快照技术Checkpoints 实现状态的持久化维护,使得即使在系统停机或者异常的情况下都能计算出正确的结果。
自2019年1月起,阿里巴巴逐渐将内部维护的Blink回馈给Flink开源社区,目前贡献代码量已超过100万行。国内包括腾讯、百度、字节跳动等公司,国外包括Uber、Lyft、Netflix等公司都是Flink的使用者。


3. Flink 的应用场景
在实际生产的过程中,大量数据在不断地产生,例如金融交易数据、互联网订单数据、GPS 定位数据、传感器信号、移动终端产生的数据、通信信号数据等,以及我们熟悉的网络流量监控、服务器产生的日志数据,这些数据最大的共同点就是实时从不同的数据源中产生,然后再传输到下游的分析系统。针对这些数据类型主要包括实时智能推荐、复杂事件处理、实时欺诈检测、实时数仓与 ETL 类型、流数据分析类型、实时报表类型等实时业务场景,而Flink 对于这些类型的场景都有着非常好的支持。
(一)实时智能推荐
智能推荐会根据用户历史的购买行为,通过推荐算法训练模型,预测用户未来可能会购买的物品。对个人来说,推荐系统起着信息过滤的作用,对 Web/App 服务端来说,推荐系统起着满足用户个性化需求,提升用户满意度的作用。推荐系统本身也在飞速发展,除了算法越来越完善,对时延的要求也越来越苛刻和实时化。利用 Flink 流计算帮助用户构建更加实时的智能推荐系统,对用户行为指标进行实时计算,对模型进行实时更新,对用户指标进行实时预测,并将预测的信息推送给 Wep/App 端,帮助用户获取想要的商品信息,另一方面也帮助企业提升销售额,创造更大的商业价值。
(二)复杂事件处理
对于复杂事件处理,比较常见的案例主要集中于工业领域,例如对车载传感器、机械设备等实时故障检测,这些业务类型通常数据量都非常大,且对数据处理的时效性要求非常高。通过利用 Flink 提供的 CEP(复杂事件处理)进行事件模式的抽取,同时应用 Flink 的 Sql进行事件数据的转换,在流式系统中构建实时规则引擎,一旦事件触发报警规则,便立即将告警结果传输至下游通知系统,从而实现对设备故障快速预警监测,车辆状态监控等目的。
(三)实时欺诈检测
在金融领域的业务中,常常出现各种类型的欺诈行为,例如信用卡欺诈、信贷申请欺诈等,而如何保证用户和公司的资金安全,是来近年来许多金融公司及银行共同面对的挑战。随着不法分子欺诈手段的不断升级,传统的反欺诈手段已经不足以解决目前所面临的问题。以往可能需要几个小时才能通过交易数据计算出用户的行为指标,然后通过规则判别出具有欺诈行为嫌疑的用户,再进行案件调查处理,在这种情况下资金可能早已被不法分子转移,从而给企业和用户造成大量的经济损失。而运用 Flink 流式计算技术能够在毫秒内就完成对欺诈判断行为指标的计算,然后实时对交易流水进行规则判断或者模型预测,这样一旦检测出交易中存在欺诈嫌疑,则直接对交易进行实时拦截,避免因为处理不及时而导致的经济损失。
(四)实时数仓与 ETL
结合离线数仓,通过利用流计算诸多优势和 SQL 灵活的加工能力,对流式数据进行实时清洗、归并、结构化处理,为离线数仓进行补充和优化。另一方面结合实时数据 ETL 处理能力,利用有状态流式计算技术,可以尽可能降低企业由于在离线数据计算过程中调度逻辑的复杂度,高效快速地处理企业需要的统计结果,帮助企业更好地应用实时数据所分析出来的结果。
(五)流数据分析
实时计算各类数据指标,并利用实时结果及时调整在线系统相关策略,在各类内容投放、无线智能推送领域有大量的应用。流式计算技术将数据分析场景实时化,帮助企业做到实时化分析 Web 应用或者 App 应用的各项指标,包括 App 版本分布情况、Crash 检测和分布等,同时提供多维度用户行为分析,支持日志自主分析,助力开发者实现基于大数据技术的精细化运营、提升产品质量和体验、增强用户黏性。
(六)实时报表分析
实时报表分析是近年来很多公司采用的报表统计方案之一,其中最主要的应用便是实时大屏展示。利用流式计算实时得出的结果直接被推送到前端应用,实时显示出重要指标的变换情况。最典型的案例便是淘宝的双十一活动,每年双十一购物节,除疯狂购物外,最引人注目的就是天猫双十一大屏不停跳跃的成交总额。在整个计算链路中包括从天猫交易下单购买到数据采集、数据计算、数据校验,最终落到双十一大屏上展现的全链路时间压缩在 5秒以内,顶峰计算性能高达数三十万笔订单/秒,通过多条链路流计算备份确保万无一失。而在其他行业,企业也在构建自己的实时报表系统,让企业能够依托于自身的业务数据,快速提取出更多的数据价值,从而更好地服务于企业运行过程中。
4. Flink 的特点和优势
1) Flink的具体优势和特点有以下几点
(一)同时支持高吞吐、低延迟、高性能
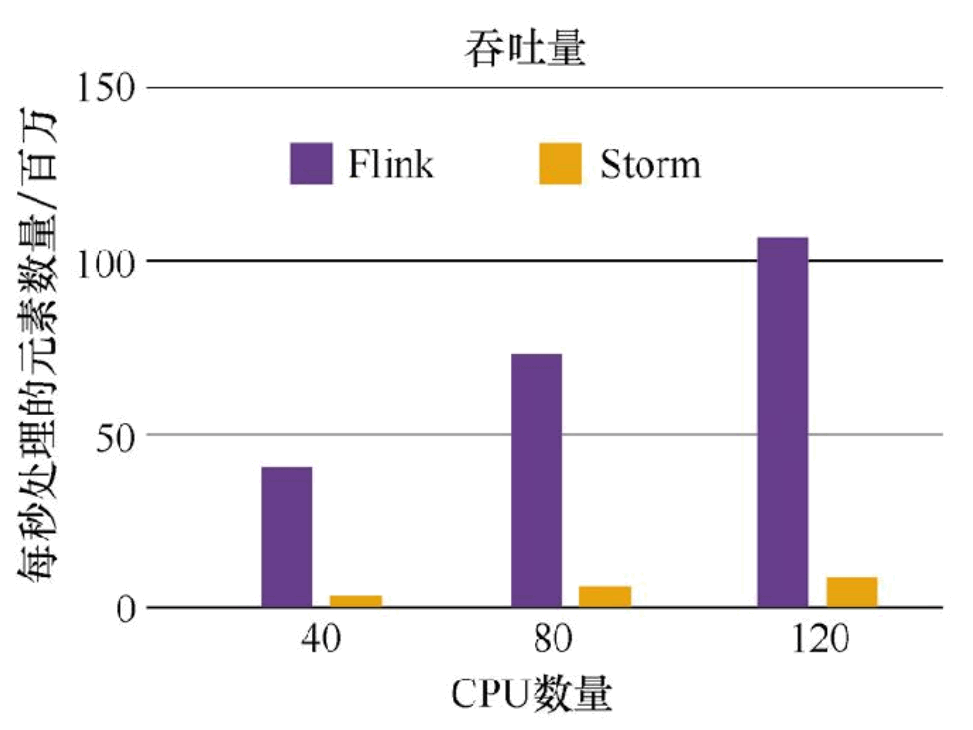
Flink 是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架。像 Apache Spark 也只能兼顾高吞吐和高性能特性,主要因为在Spark Streaming 流式计算中无法做到低延迟保障;而流式计算框架 Apache Storm 只能支持低延迟和高性能特性,但是无法满足高吞吐的要求。而满足高吞吐、低延迟、高性能这三个目标对分布式流式计算框架来说是非常重要的。
(二)支持事件时间(Event Time)概念
在流式计算领域中,窗口计算的地位举足轻重,但目前大多数框架窗口计算采用的都是系统时间(Process Time),也是事件传输到计算框架处理时,系统主机的当前时间。Flink 能够支持基于事件时间(Event Time)语义进行窗口计算,也就是使用事件产生的时间,这种基于事件驱动的机制使得事件即使乱序到达,流系统也能够计算出精确的结果,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。
(三)支持有状态计算
Flink 在 1.4 版本中实现了状态管理,所谓状态就是在流式计算过程中将算子的中间结果数据保存在内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果中计算当前的结果,从而无须每次都基于全部的原始数据来统计结果,这种方式极大地提升了系统的性能,并降低了数据计算过程的资源消耗。对于数据量大且运算逻辑非常复杂的流式计算场景,有状态计算发挥了非常重要的作用。
(四)支持高度灵活的窗口(Window)操作
在流处理应用中,数据是连续不断的,需要通过窗口的方式对流数据进行一定范围的聚合计算,例如统计在过去的 1 分钟内有多少用户点击某一网页,在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行再计算。Flink 将窗口划分为基于 Time、Count、Session,以及 Data-driven 等类型的窗口操作,窗口可以用灵活的触发条件定制化来达到对复杂的流传输模式的支持,用户可以定义不同的窗口触发机制来满足不同的需求。
(五)基于轻量级分布式快照(CheckPoint)实现的容错
Flink 能够分布式运行在上千个节点上,将一个大型计算任务的流程拆解成小的计算过程,然后将 tesk 分布到并行节点上进行处理。在任务执行过程中,能够自动发现事件处理过程中的错误而导致数据不一致的问题,比如:节点宕机、网路传输问题,或是由于用户因为升级或修复问题而导致计算服务重启等。在这些情况下,通过基于分布式快照技术的 Checkpoints,将执行过程中的状态信息进行持久化存储,一旦任务出现异常停止,Flink 就能够从 Checkpoints 中进行任务的自动恢复,以确保数据在处理过程中的一致性(Exactly-Once)。
(六)基于 JVM 实现独立的内存管理
内存管理是所有计算框架需要重点考虑的部分,尤其对于计算量比较大的计算场景,数据在内存中该如何进行管理显得至关重要。针对内存管理,Flink 实现了自身管理内存的机制,尽可能减少 JVM GC 对系统的影响。另外,Flink 通过序列化/反序列化方法将所有的数据对象转换成二进制在内存中存储,降低数据存储的大小的同时,能够更加有效地对内存空间进行利用,降低 GC 带来的性能下降或任务异常的风险,因此Flink 较其他分布式处理的框架会显得更加稳定,不会因为 JVM GC 等问题而影响整个应用的运行。
(七)Save Points(保存点)
对于 7*24 小时运行的流式应用,数据源源不断地接入,在一段时间内应用的终止有可能导致数据的丢失或者计算结果的不准确,例如进行集群版本的升级、停机运维操作等操作。值得一提的是,Flink 通过 Save Points 技术将任务执行的快照保存在存储介质上,当任务重启的时候可以直接从事先保存的 Save Points 恢复原有的计算状态,使得任务继续按照停机之前的状态运行,Save Points 技术可以让用户更好地管理和运维实时流式应用。
2) 流式计算框架的对比
Storm 是比较早的流式计算框架,后来又出现了 Spark Streaming 和 Trident,现在又出现了 Flink 这种优秀的实时计算框架,那么这几种计算框架到底有什么区别呢?
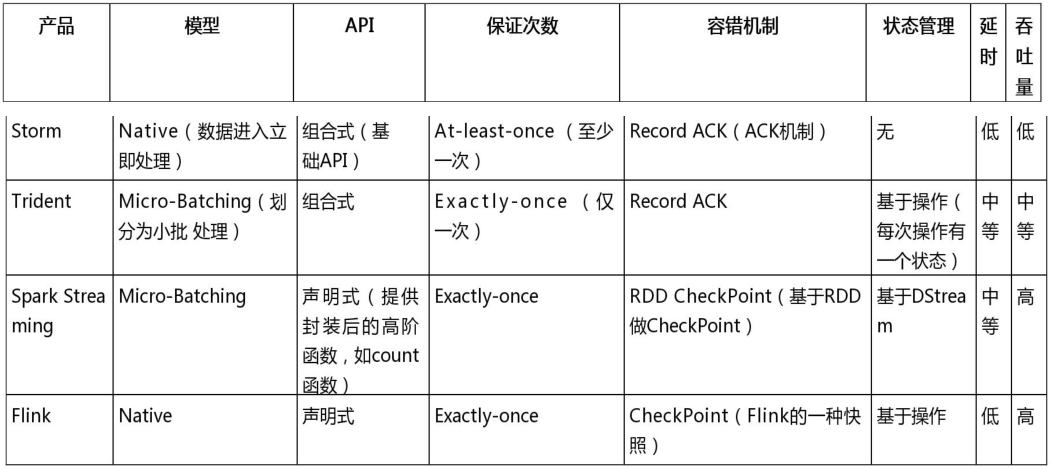
模型:Storm 和 Flink 是真正的一条一条处理数据;而 Trident(Storm 的封装框架)和 Spark Streaming 其实都是小批处理,一次处理一批数据(小批量)。
API :Storm 和 Trident 都使用基础 API 进行开发,比如实现一个简单的 sum 求和操作;而 Spark Streaming 和 Flink 中都提供封装后的高阶函数,可以直接拿来使用,这样就比较方便了。
保证次数:在数据处理方面,Storm 可以实现至少处理一次,但不能保证仅处理一次,这样就会导致数据重复处理问题,所以针对计数类的需求,可能会产生一些误差;Trident 通过事务可以保证对数据实现仅一次的处理,Spark Streaming 和 Flink 也是如此。
容错机制: :Storm和Trident可以通过ACK机制实现数据的容错机制,而Spark Streaming和 Flink 可以通过 CheckPoint 机制实现容错机制。
状态管理:Storm 中没有实现状态管理,Spark Streaming 实现了基于 DStream 的状态管理,而 Trident 和 Flink 实现了基于操作的状态管理。
**延时: ** :表示数据处理的延时情况,因此 Storm 和 Flink 接收到一条数据就处理一条数据,其数据处理的延时性是很低的;而 Trident 和 Spark Streaming 都是小型批处理,它们数据处理的延时性相对会偏高。
吞吐量:Storm 的吞吐量其实也不低,只是相对于其他几个框架而言较低;Trident 属于中等;而 Spark Streaming 和 Flink 的吞吐量是比较高的。
第二节 Flink 快速入门
1. Flink的开发环境
1) 开发工具
推荐使用Intellij IDEA
2) 配置依赖
开发Flink应用程序需要最低限度的API依赖。最低的依赖库包括:flnk-scala和flink-streaming-scala。大多数应用需要连接特定的连接器和其它类库,例如Kafka的连接器,TableAPI,CEP库等。这些不是Flink核心依赖的一部分,因此必须作为依赖手动添加到应用程序中。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
<scope>provided</scope>
</dependency>
需要打包的话,引入下面依赖:
<build>
<plugins>
<!--打包普通项目-->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id> <!-- this is used for inheritance merges -->
<phase>package</phase> <!-- 指定在打包节点执行jar包合并操作 -->
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<!--打包Scala项目-->
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<version>2.15.2</version>
<executions>
<execution>
<id>scala-compile-first</id>
<goals>
<goal>compile</goal>
</goals>
<configuration>
<includes>
<include>**/*.scala</include>
</includes>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
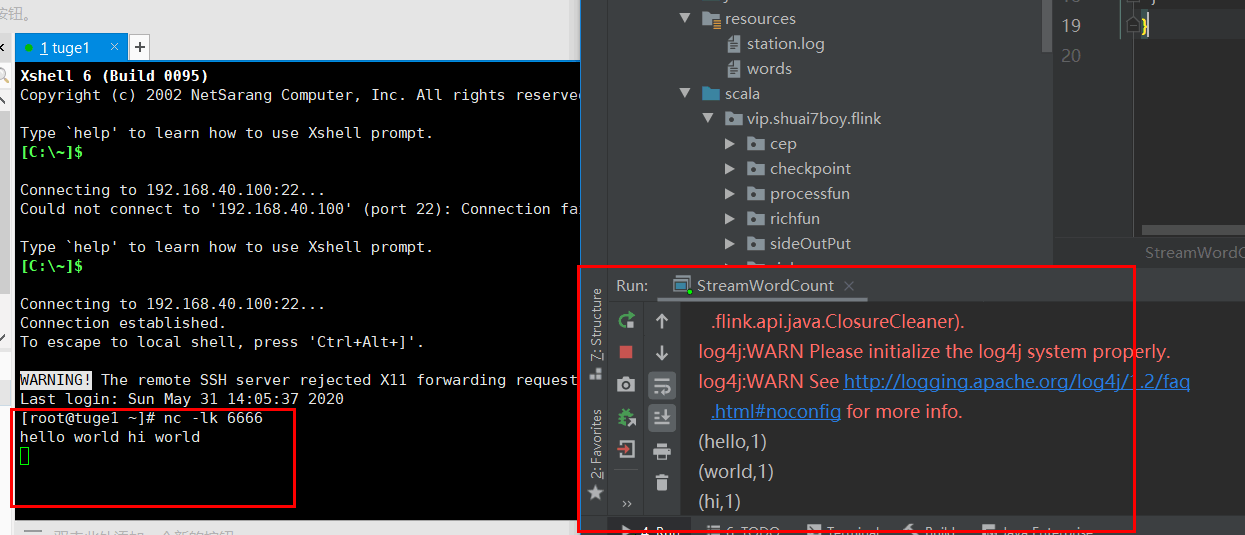
2. 第一个Flink流处理(Streaming)案例
需求:采用 Netcat 数据源发送数据,使用 Flink 统计每个单词的数量。
package vip.shuai7boy.flink.Test
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
object StreamWordCount {
def main(args: Array[String]): Unit = {
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
import org.apache.flink.api.scala._
val data = streamEnv.socketTextStream("tuge1", 6666)
val result = data.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
result.print()
streamEnv.execute("streamWordCont")
}
}
测试效果:
3. 第一个 Flink 批处理(Batch)
需求:读取本地数据文件,统计文件中每个单词出现的次数
package vip.shuai7boy.flink.Test
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment}
object BatchWordCount {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val dataUrl=getClass.getResource("words")
val data: DataSet[String] = env.readTextFile("./data/words")
import org.apache.flink.api.scala._
val result: AggregateDataSet[(String, Int)] = data.flatMap(_.split(" "))
.map((_, 1))
.groupBy(0)
.sum(1)
result.print()
}
}
第三节 Flink 的安装和部署
1.集群基本架构
Flink系统主要由两个组件组成JobManager和TaskManager,Flink架构也遵循Master-Slave架构设计原则,JobManager为Master节点,TaskManager为Worker(Slave)节点。所有组件之间的通信都借助于Akka Framework,包括任务的状态及Checkpoint触发等信息。
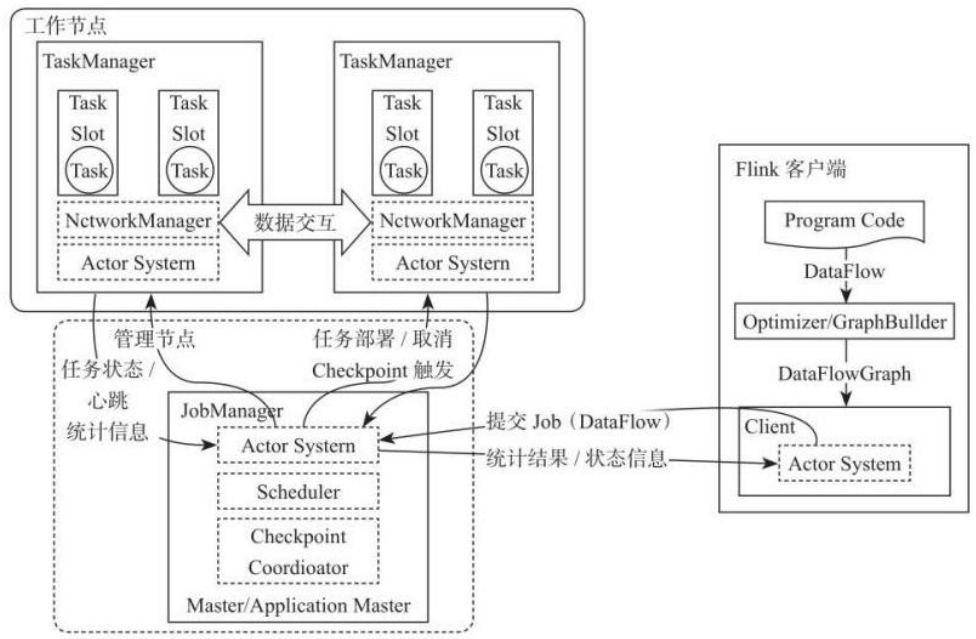
1) Client客户端
客户端负责将任务提交到集群,与 JobManager 构建 Akka 连接,然后将任务提交到JobManager,通过和 JobManager 之间进行交互获取任务执行状态。客户端提交任务可以采用 CLI 方式或者通过使用 Flink WebUI 提交,也可以在应用程序中指定 JobManager 的 RPC网络端口构建 ExecutionEnvironment 提交 Flink 应用。
2)JobManager
JobManager 负责整个 Flink 集群任务的调度以及资源的管理,从客户端中获取提交的应用,然后根据集群中 TaskManager 上 TaskSlot 的使用情况,为提交的应用分配相应的TaskSlots 资源并命令 TaskManger 启动从客户端中获取的应用。JobManager 相当于整个集群的 Master 节点,且整个集群中有且仅有一个活跃的 JobManager,负责整个集群的任务管理和资源管理。JobManager 和 TaskManager 之间通过 Actor System 进行通信,获取任务执行的情况并通过 Actor System 将应用的任务执行情况发送给客户端。同时在任务执行过程中,Flink JobManager 会触发 Checkpoints 操作,每个 TaskManager 节点收到 Checkpoint触发指令后,完成 Checkpoint 操作,所有的 Checkpoint 协调过程都是在 Flink JobManager中完成。当任务完成后,Flink 会将任务执行的信息反馈给客户端,并且释放掉 TaskManager中的资源以供下一次提交任务使用。
3) TaskManager
TaskManager 相当于整个集群的 Slave 节点,负责具体的任务执行和对应任务在每个节点上的资源申请与管理。客户端通过将编写好的 Flink 应用编译打包,提交到 JobManager,然后 JobManager 会根据已经注册在 JobManager 中 TaskManager 的资源情况,将任务分配给有资源的 TaskManager 节点,然后启动并运行任务。TaskManager 从 JobManager 接收需要部署的任务,然后使用 Slot 资源启动 Task,建立数据接入的网络连接,接收数据并开始数据处理。同时 TaskManager 之间的数据交互都是通过数据流的方式进行的。
可以看出,Flink 的任务运行其实是采用多线程的方式,这和 MapReduce 多 JVM 进程的方式有很大的区别 Fink 能够极大提高 CPU 使用效率,在多个任务和 Task 之间通过 TaskSlot方式共享系统资源,每个 TaskManager 中通过管理多个 TaskSlot 资源池进行对资源进行有效管理。
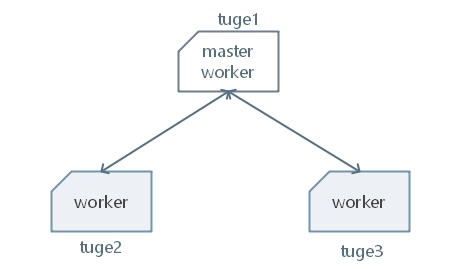
2. Standalone 集群安装和部署
Standalone 是 Flink 的独立部署模式,它不依赖其他平台。在使用这种模式搭建 Flink集群之前,需要先规划集群机器信息。在这里为了搭建一个标准的 Flink 集群,需要准备 3台 Linux 机器,如图下所示。
1)解压Flink的压缩包
[root@tuge1 flink]# tar -vf flink-1.10.1-bin-scala_2.12.tgz
2).修改配置文件
①进入到 conf 目录下,编辑 flink-conf.yaml 配置文件:

其中:taskmanager.numberOfTaskSlot 参数默认值为 1,修改成2。表示每一个TaskManager上有3个Slot。
②编辑 conf/slaves 配置文件
3).分发给另外两台服务器
[root@tuge1 flink]# scp -r flink-1.10.1 tuge2:`pwd`
[root@tuge1 flink]# scp -r flink-1.10.1 tuge3:`pwd`
4).启动Flink集群服务
[root@tuge1 flink-1.10.1]# bin/start-cluster.sh
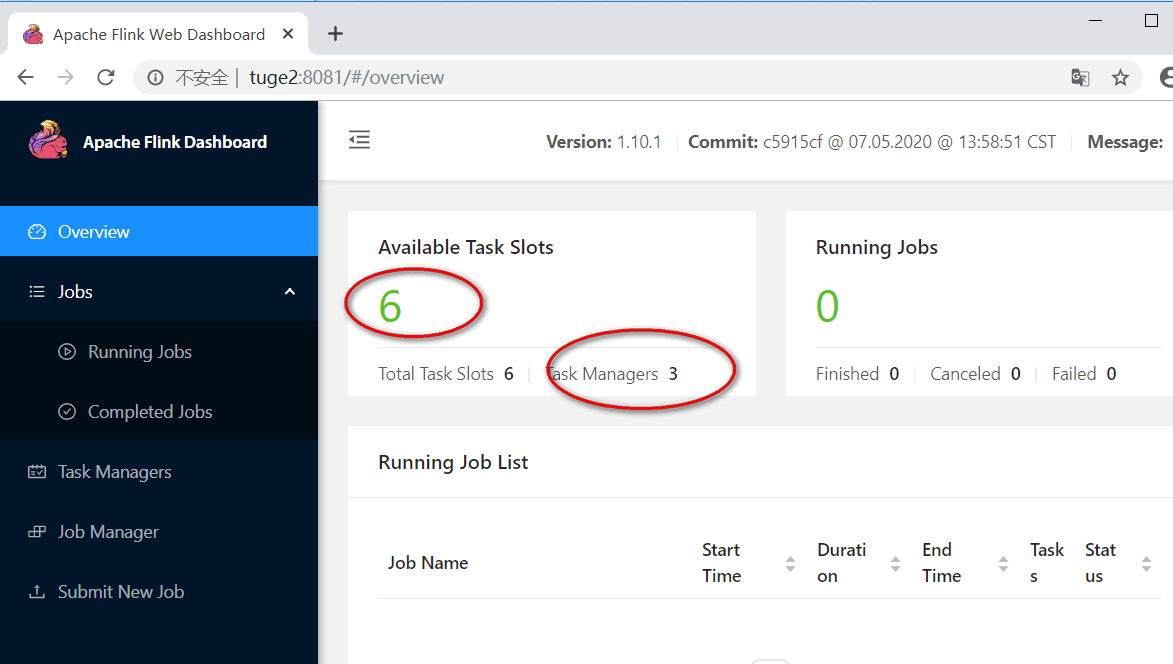
5) 访问 WebUI
6)通过命令提交job到集群
①把上一章节中第一个 Flink 流处理案例代码打包,并上传

②执行命令: 在执行命令之前先确保 nc -lk 6666 是否启动

其中-d 选项表示提交 job 之后,客户端结束并退出。之后输入测试数据
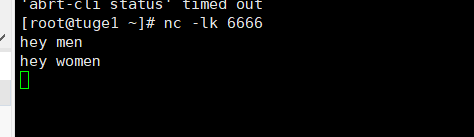
③查看 job 执行结果
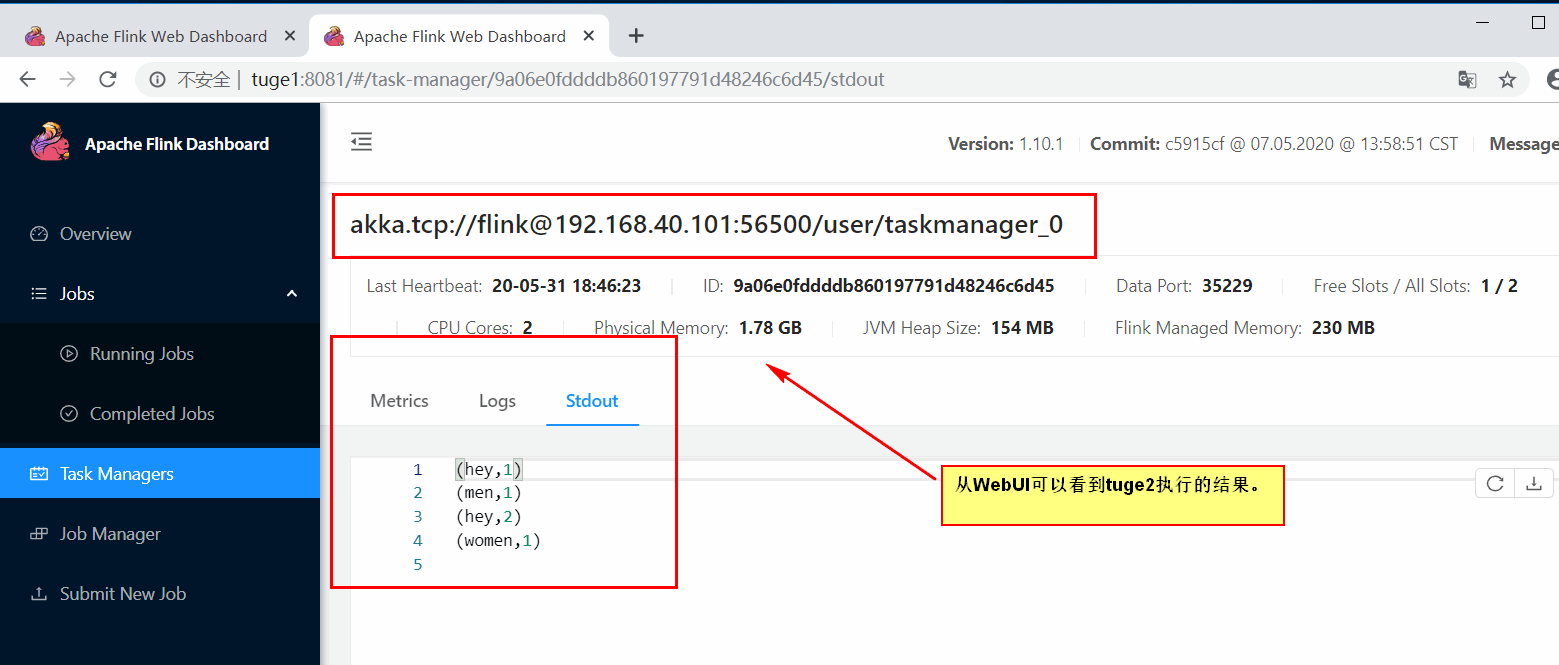
7) 通过 WebUI 提交 job 到集群
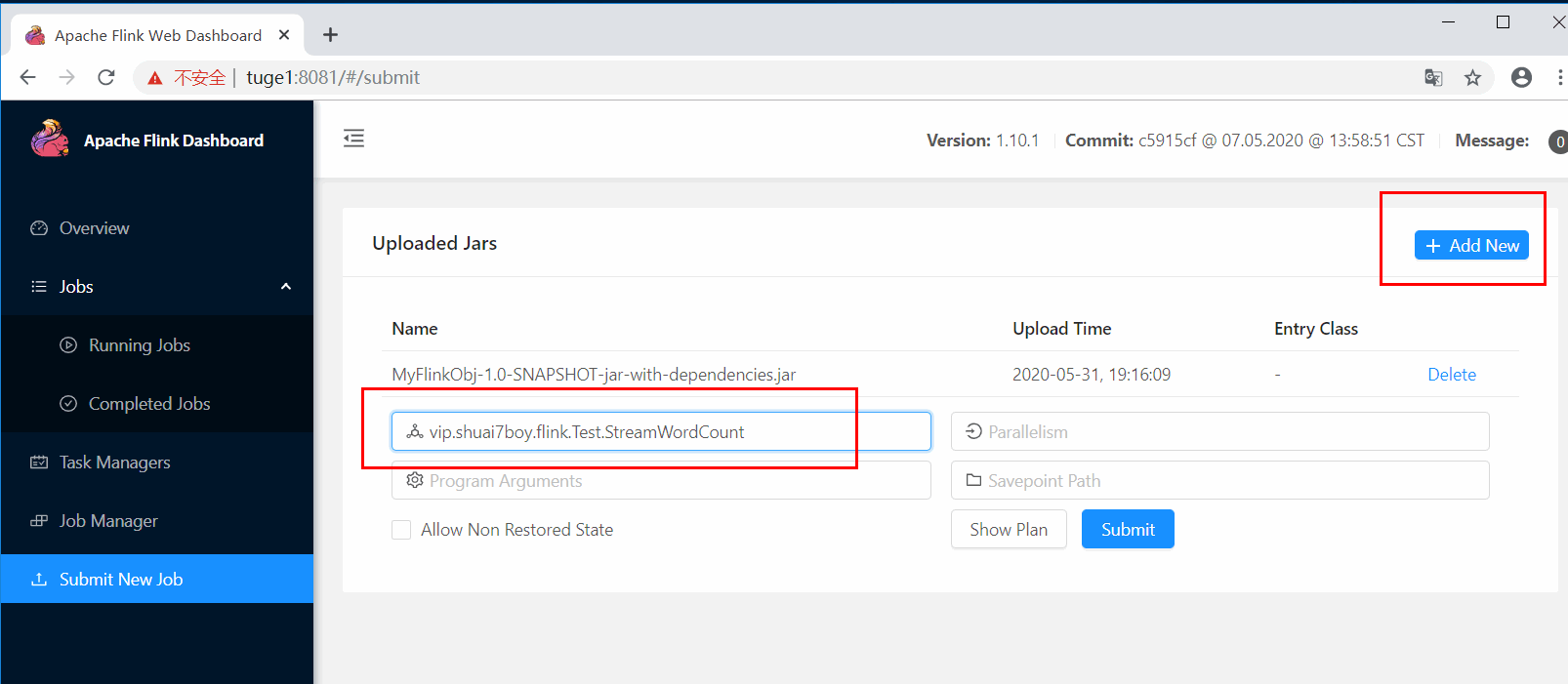
8)配置文件参数说明
下面针对 flink-conf.yaml 文件中的几个重要参数进行分析:
jobmanager.heap.size:JobManager 节点可用的内存大小。
taskmanager.heap.size:TaskManager 节点可用的内存大小。
taskmanager.numberOfTaskSlots:每台机器可用的 Slot 数量。
parallelism.default:默认情况下 Flink 任务的并行度。
上面参数中所说的 Slot 和 parallelism 的区别:
Slot 是静态的概念,是指 TaskManager 具有的并发执行能力。
parallelism 是动态的概念,是指程序运行时实际使用的并发能力。
设置合适的 parallelism 能提高运算效率。
3. Flink 提交到 Yarn
Flink on Yarn 模式的原理是依靠 YARN 来调度 Flink 任务,目前在企业中使用较多。这种模式的好处是可以充分利用集群资源,提高集群机器的利用率,并且只需要 1 套 Hadoop集群,就可以执行 MapReduce 和 Spark 任务,还可以执行 Flink 任务等,操作非常方便,不需要维护多套集群,运维方面也很轻松。Flink on Yarn 模式需要依赖 Hadoop 集群,并且Hadoop 的版本需要是 2.2 及以上。
Flink On Yarn 的内部实现原理:
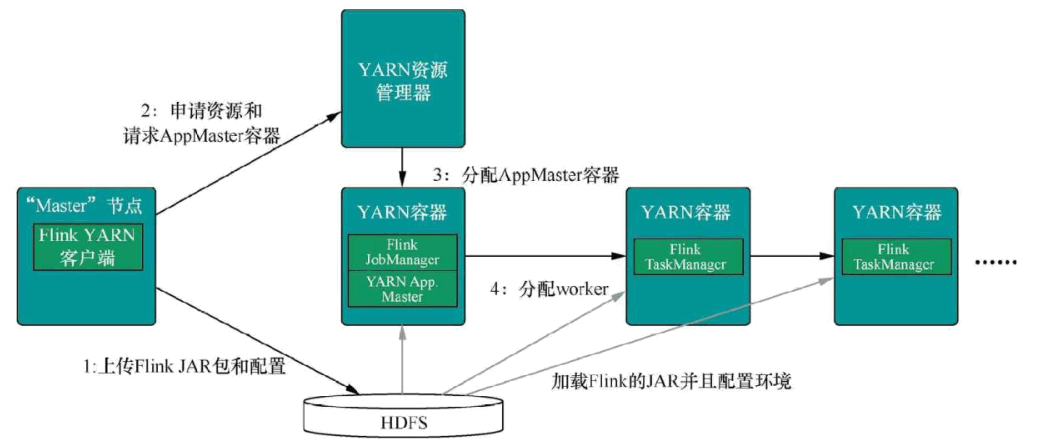
当启动一个新的 Flink YARN Client 会话时,客户端首先会检查所请求的资源(容器和内存)是否可用。之后,它会上传 Flink 配置和 JAR 文件到 HDFS。
客 户 端的 下 一 步是 请 求 一个 YARN 容 器 启动 ApplicationMaster 。 JobManager 和ApplicationMaster(AM)运行在同一个容器中,一旦它们成功地启动了,AM 就能够知道JobManager 的地址,它会为 TaskManager 生成一个新的 Flink 配置文件(这样它才能连上 JobManager),该文件也同样会被上传到 HDFS。另外,AM 容器还提供了 Flink 的Web 界面服务。
之后,AM 开始为 Flink 的 TaskManager 分配容器(Container),从 HDFS 下载 JAR 文件和修改过的配置文件。一旦这些步骤完成了,Flink 就安装完成并准备接受任务了。
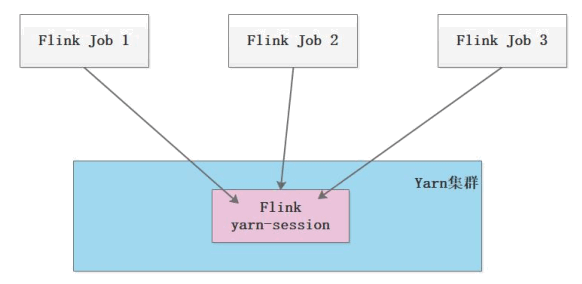
Flink n on n Yarn 模式在使用的时候又可以分为两种 :
第 1 种模式(Session-Cluster):是在 YARN 中提前初始化一个 Flink 集群(称为 Flinkyarn-session),开辟指定的资源,以后的 Flink 任务都提交到这里。这个 Flink 集群会常驻在 YARN 集群中,除非手工停止。这种方式创建的 Flink 集群会独占资源,不管有没有 Flink 任务在执行,YARN 上面的其他任务都无法使用这些资源。
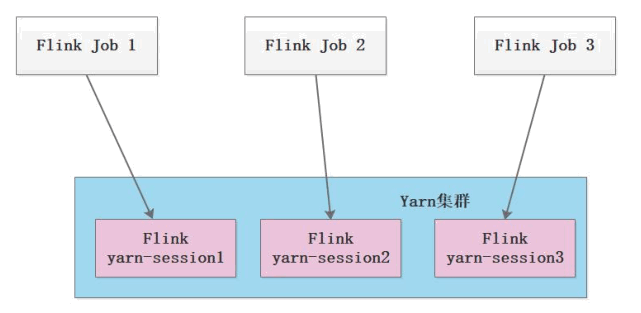
第 2 种模式(Per-Job-Cluster):每次提交 Flink 任务都会创建一个新的 Flink 集群,每个 Flink 任务之间相互独立、互不影响,管理方便。任务执行完成之后创建的 Flink集群也会消失,不会额外占用资源,按需使用,这使资源利用率达到最大,在工作中推荐使用这种模式。
注意:Flink on Yarn 还需要两个先决条件:
- 配置 Hadoop 的环境变量
- 下载 Flink 提交到 Hadoop 的连接器(jar 包),并把 jar 拷贝到 Flink 的 lib 目录下
1) Session-Cluster 模式
①先启动 Hadoop 集群,然后通过命令启动一个 Flink 的 yarn-session 集群:
bin/yarn-session.sh -n 3 -s 3 -nm bjsxt -d
其中 yarn-session.sh 后面支持多个参数。下面针对一些常见的参数进行讲解:
-n,--container 表示分配容器的数量(也就是 TaskManager 的数量)。
-D 动态属性。
-d,--detached 在后台独立运行。
-jm,--jobManagerMemory :设置 JobManager 的内存,单位是 MB。
-nm,--name:在 YARN 上为一个自定义的应用设置一个名字。
-q,--query:显示 YARN 中可用的资源(内存、cpu 核数)。
-qu,--queue :指定 YARN 队列。
-s,--slots :每个 TaskManager 使用的 Slot 数量。
-tm,--taskManagerMemory :每个 TaskManager 的内存,单位是 MB。
-z,--zookeeperNamespace :针对 HA 模式在 ZooKeeper 上创建 NameSpace。
-id,--applicationId :指定 YARN 集群上的任务 ID,附着到一个后台独立运行的 yarn session 中。
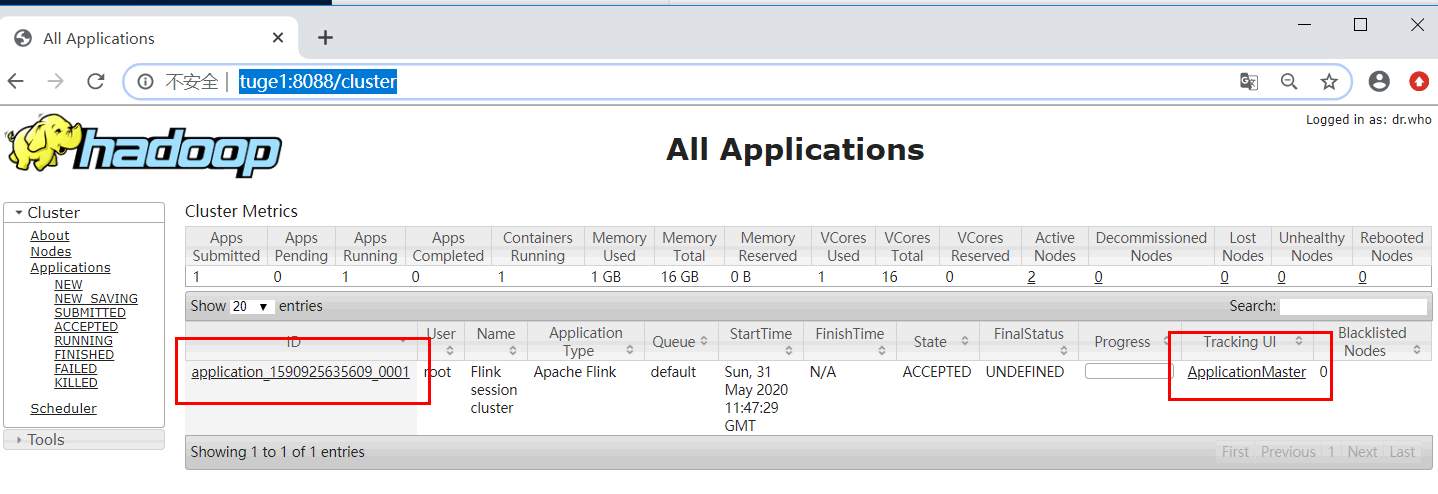
②查看 WebUI: 由于还没有提交 Flink job,所以都是 0
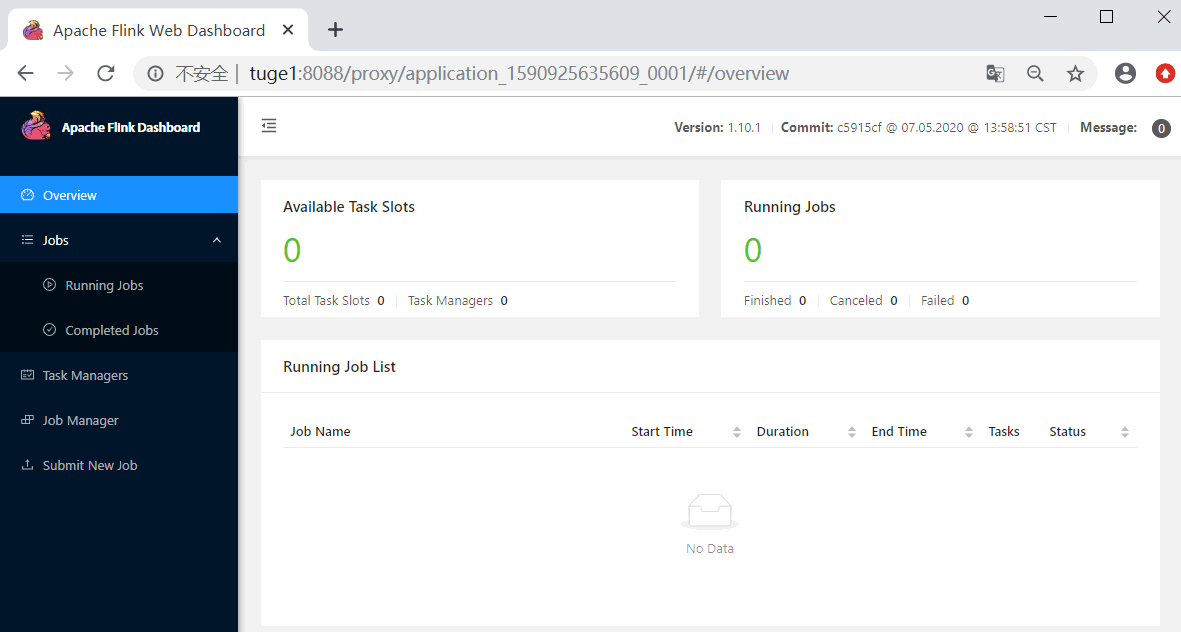
这个时候注意查看本地文件系统中有一个临时文件。有了这个文件可以提交 job 到 Yarn
③提交 Job : 由于有了之前的配置,所以自动会提交到 Yarn 中。
[root@tuge1 flink-1.10.1]# bin/flink run -c vip.shuai7boy.flink.Test.StreamWordCount /data/flinkdata/MyFlinkObj-1.0-SNAPSHOT-jar-with-dependencies.jar
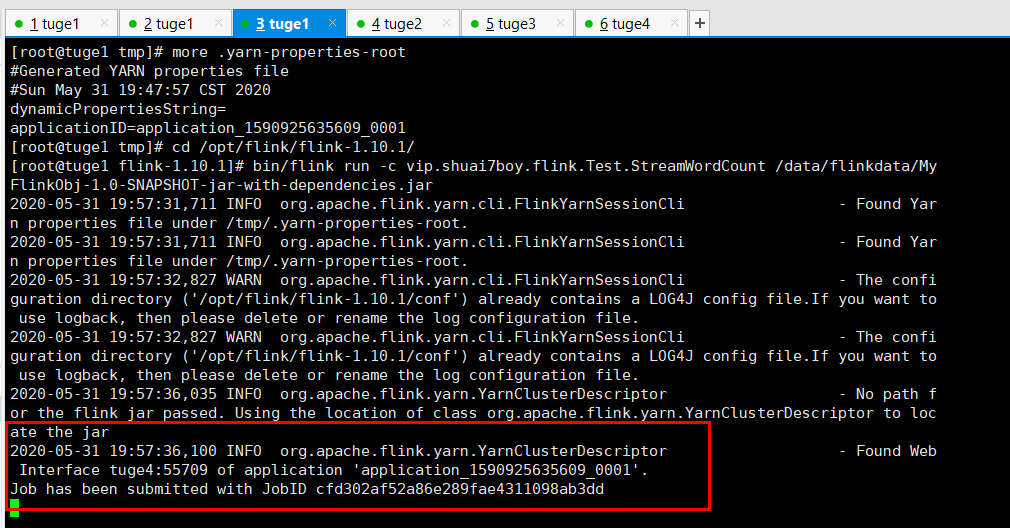
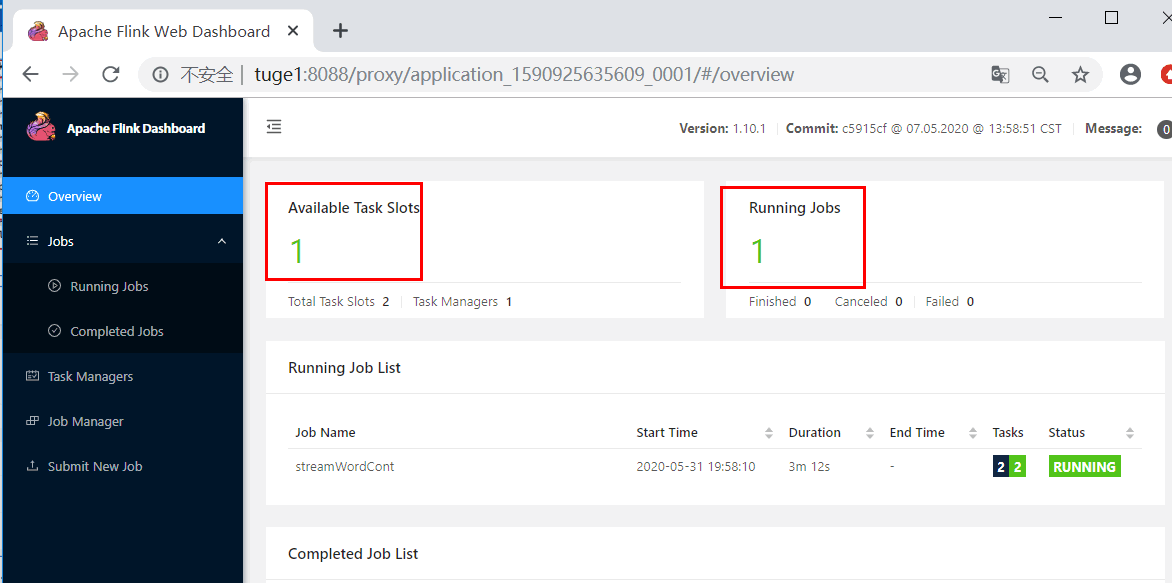
至此第一种模式全部完成。
2) Pre-Job-Cluster 模式
这种模式下不需要先启动 yarn-session。所以我们可以把前面启动的 yarn-session 集群先停止,停止的命令是:
yarn application -kill application_1590925635609_0001
确保 Hadoop 集群是健康的情况下直接提交 Job 命令:
bin/flink run -m yarn-cluster -c vip.shuai7boy.flink.Test.StreamWordCount /data/flinkdata/MyFlinkObj-1.0-SNAPSHOT-jar-with-dependencies.jar
可以看到一个全新的 yarn-session
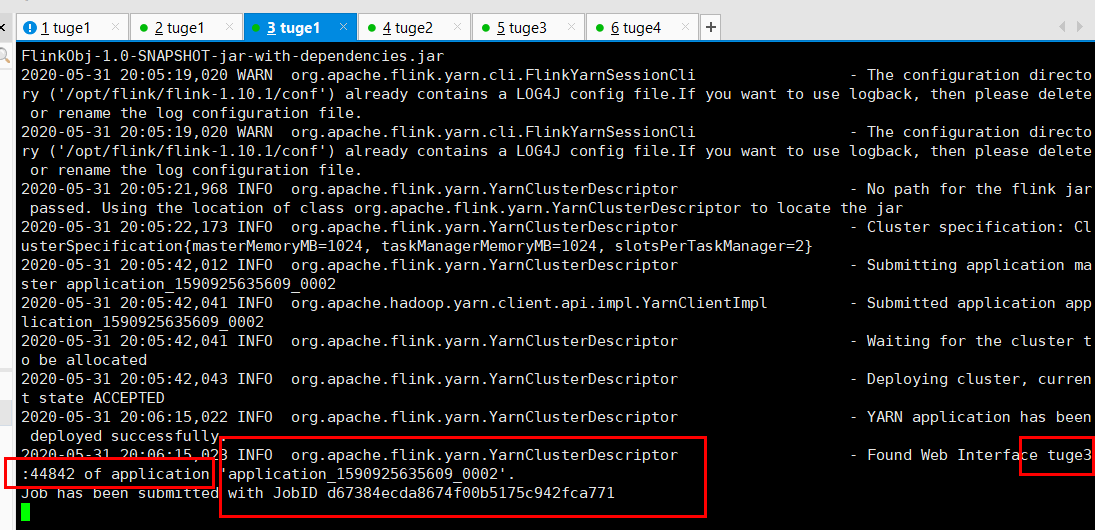
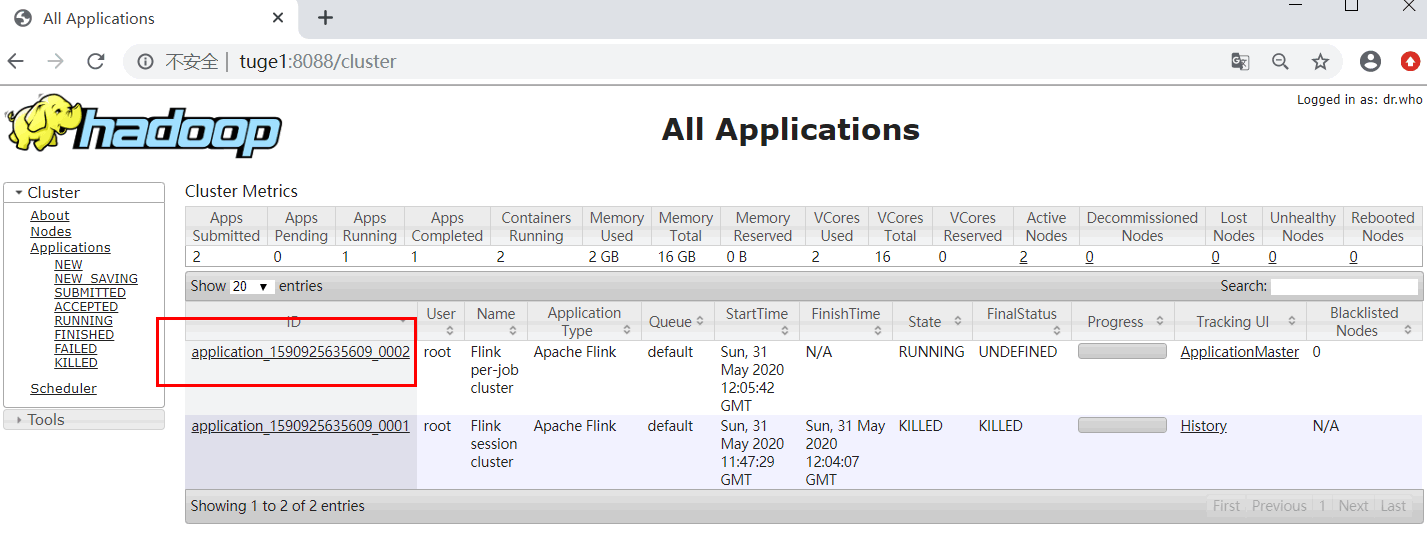
任务提交参数讲解:相对于Session-Cluster 参数而言,只是前面加了 y。
- -yn,--container 表示分配容器的数量,也就是 TaskManager 的数量。
- -d,--detached:设置在后台运行。
- -yjm,--jobManagerMemory:设置 JobManager 的内存,单位是 MB。
- -ytm,--taskManagerMemory:设置每个 TaskManager 的内存,单位是 MB。
- -ynm,--name:给当前 Flink application 在 Yarn 上指定名称。
- -yq,--query:显示 yarn 中可用的资源(内存、cpu 核数)
- -yqu,--queue :指定 yarn 资源队列
- -ys,--slots :每个 TaskManager 使用的 Slot 数量。
- -yz,--zookeeperNamespace:针对 HA 模式在 Zookeeper 上创建 NameSpace
- -yid,--applicationID : 指定 Yarn 集群上的任务 ID,附着到一个后台独立运行的 Yarn Session 中。
4. Flink 的 的 HA
默认情况下,每个 Flink 集群只有一个 JobManager,这将导致单点故障(SPOF),如果这个 JobManager 挂了,则不能提交新的任务,并且运行中的程序也会失败。使用JobManager HA,集群可以从 JobManager 故障中恢复,从而避免单点故障。用户可以在Standalone 或 Flink on Yarn 集群模式下配置 Flink 集群 HA(高可用性)。
Standalone 模式下,JobManager 的高可用性的基本思想是,任何时候都有一个 AliveJobManager 和多个 Standby JobManager。Standby JobManager 可以在 Alive JobManager挂掉的情况下接管集群成为 Alive JobManager,这样避免了单点故障,一旦某一个 StandbyJobManager 接管集群,程序就可以继续运行。Standby JobManagers 和 Alive JobManager实例之间没有明确区别,每个 JobManager 都可以成为 Alive 或 Standby。
1) Flink Standalone 集群的 HA 安装和配置
实现 HA 还需要依赖 ZooKeeper 和 HDFS,因此要有一个 ZooKeeper 集群和 Hadoop 集群,首先启动 Zookeeper 集群和 HDFS 集群。我分配了三台JobManager,如下表:
| tuge1 | tuge2 | tuge3 |
|---|---|---|
| JobManager | JobManager | JobManager |
| TaskManager | TaskManager | TaskManager |
①修改配置文件 conf/masters
②修改配置文件 conf/flink-conf.yaml
#要启用高可用,设置修改为zookeeper
high-availability: zookeeper
#Zookeeper的主机名和端口信息,多个参数之间用逗号隔开
high-availability.zookeeper.quorum:
tuge1:2181,tuge2:2181,tuge3:2181
# 建议指定HDFS的全路径。如果某个Flink节点没有配置HDFS的话,不指定HDFS的全路径
则无法识到,storageDir存储了恢复一个JobManager所需的所有元数据。
high-availability.storageDir: hdfs://tuge1:9000/flink/h
③把修改的配置文件拷贝其他服务器中
[root@tuge1 conf]# scp masters flink-conf.yaml tuge2:`pwd`
[root@tuge1 conf]# scp masters flink-conf.yaml tuge3:`pwd`
④启动集群
[root@tuge1 flink-1.10.1]# bin/start-cluster.sh
2)Flink On Yarn HA
正常基于 Yarn 提交 Flink 程序,无论是使用 yarn-session 模式还是 yarn-cluster 模式 , 基 于 yarn 运 行 后 的 application 只 要 kill 掉 对 应 的 Flink 集 群 进 程“YarnSessionClusterEntrypoint”后,基于 Yarn 的 Flink 任务就失败了,不会自动进行重试,所以基于 Yarn 运行 Flink 任务,也有必要搭建 HA,这里同样还是需要借助 zookeeper来完成,步骤如下:
①修改所有 Hadoop 节点的 yarn-site.xml
将所有 Hadoop 节点的 yarn-site.xml 中的提交应用程序最大尝试次数调大
#在每台hadoop节点yarn-site.xml中设置提交应用程序的最大尝试次数,建议不低于4,这里
重试指的是ApplicationMaster
<property>
<name>yarn.resourcemanager.am.max-attempts</name>
<value>4</value>
</property>
②启动 Hadoop 集群
启动 zookeeper,启动 Hadoop 集群。
③修改 Flink 对应 flink-conf.yaml 配置
#配置依赖zookeeper模式进行HA搭建
high-availability: zookeeper
#配置JobManager原数据存储路径
high-availability.storageDir: hdfs://hadoop101:9000/flink/yarnha/
#配置zookeeper集群节点
high-availability.zookeeper.quorum:
hadoop101:2181,hadoop102:2181,hadoop103:2181
#yarn停止一个application重试的次数
yarn.application-attempts: 10
④启动 yarn-session.sh 测试 HA: yarn-session.sh -n 2 ,也可以直接提交 Job启动之后,可以登录 yarn 中对应的 flink webui,如下图示:
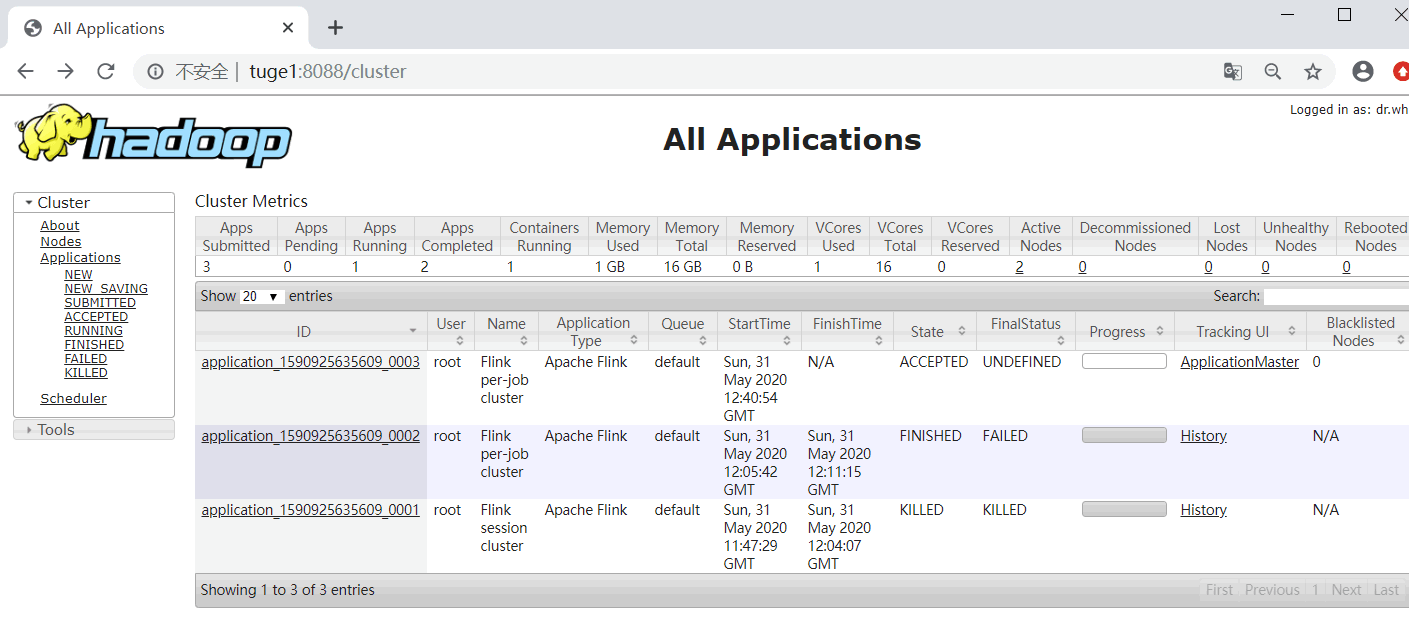
点击对应的 Tracking UI,进入 Flink 集群 UI:
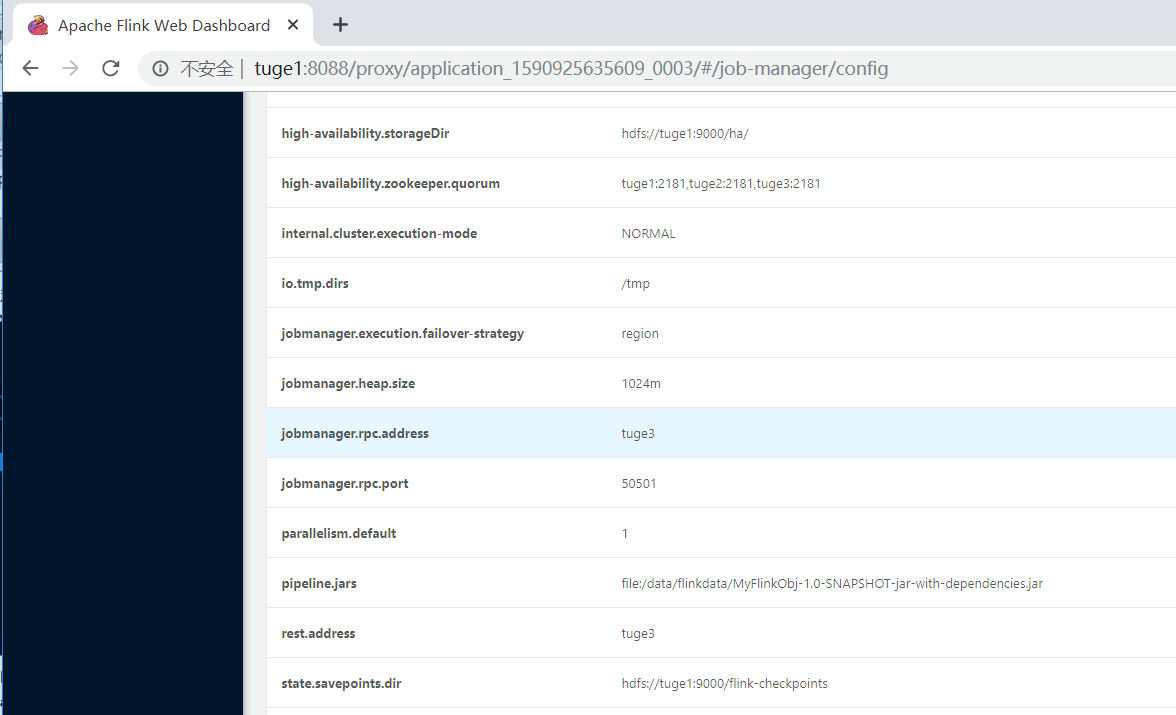
进入对应的节点,kill 掉对应的“YarnSessionClusterEntrypoint”进程。然后进入到 Yarn
中观察“applicationxxxx_0003”job 信息:
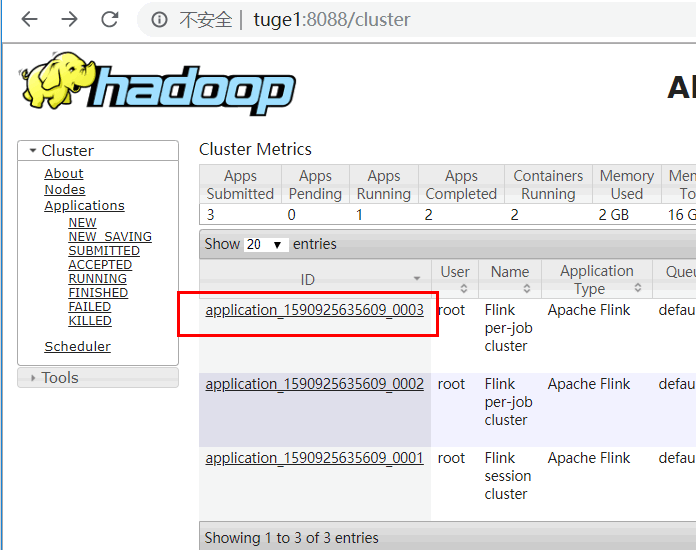
点击 job ID,发现会有对应的重试信息:
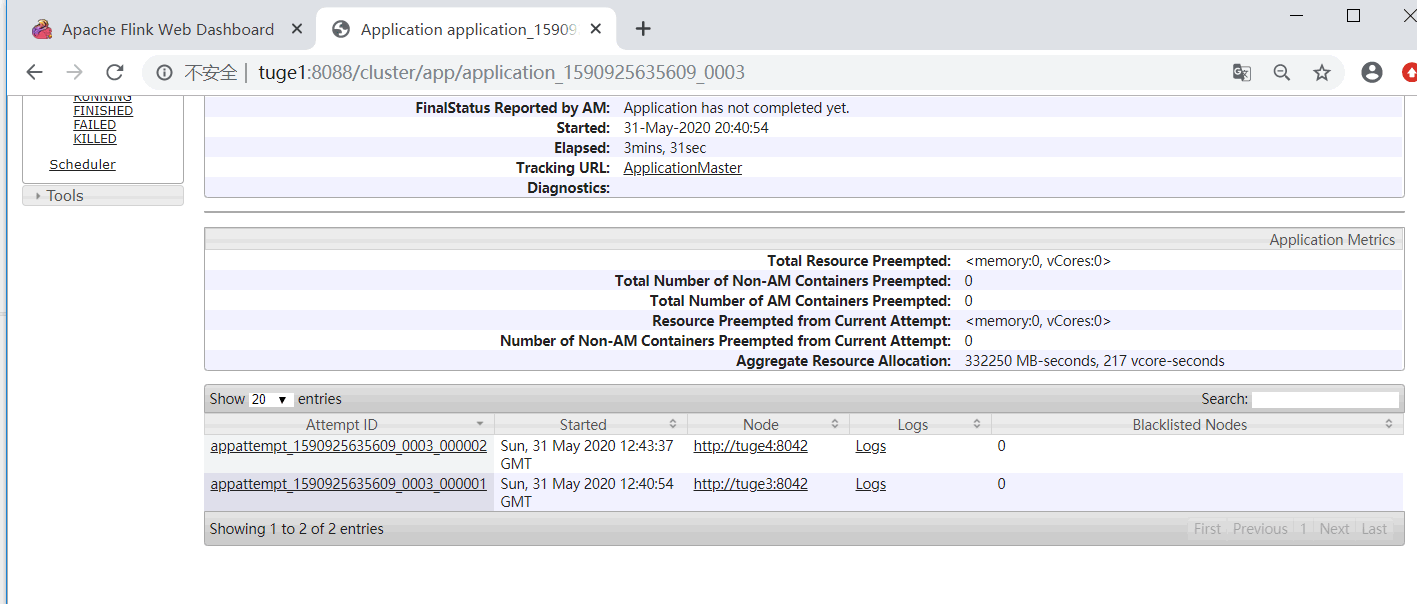
点击对应的“Tracking UI”进入到 Flink 集群 UI,查看新的 JobManager 节点由原来的tuge3 变成了 tuge4,说明 HA 起作用。

5. Flink 并行度和 Slot
Flink中每一个worker(TaskManager)都是一个JVM进程,它可能会在独立的线程(Slot)上执行一个或多个 subtask。Flink 的每个 TaskManager 为集群提供 Slot。Slot 的数量通常与每个 TaskManager 节点的可用 CPU 内核数成比例,一般情况下 Slot 的数量就是每个节点的 CPU 的核数。
Slot 的 数 量 由 集 群 中 flink-conf.yaml 配 置 文 件 中 设 置taskmanager.numberOfTaskSlots 的值为 3,这个值的大小建议和节点 CPU 的数量保持一致。

一个任务的并行度设置可以从 4 个层面指定:
- Operator Level(算子层面)。
- Execution Environment Level(执行环境层面)。
- Client Level(客户端层面)。
- System Level(系统层面)。
这 些 并 行 度 的 优 先 级 为 Operator Level>Execution Environment Level>Client
Level>System Level。
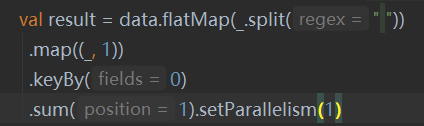
1) 并行度设置之 Operator Level
2) 并行度设置之 Execution Environment Level

3) 并并行度设置之 Client Level
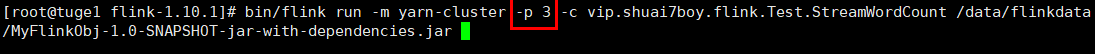
4) 并行度设置之 System Level

第四节 Flink 常用 API 详解
Flink 根据抽象程度分层,提供了三种不同的 API 和库。每一种 API 在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景。

ProcessFunction 是 Flink 所提供最底层接口。ProcessFunction 可以处理一或两条输入数据流中的单个事件或者归入一个特定窗口内的多个事件。它提供了对于时间和状态的细粒度控制。开发者可以在其中任意地修改状态,也能够注册定时器用以在未来的某一时刻触发回调函数。因此,你可以利用 ProcessFunction 实现许多有状态的事件驱动应用所需要的基于单个事件的复杂业务逻辑。
DataStream API 为许多通用的流处理操作提供了处理原语。这些操作包括窗口、逐条记录的转换操作,在处理事件时进行外部数据库查询等。DataStream API 支持 Java 和Scala 语言,预先定义了例如 map()、reduce()、aggregate() 等函数。你可以通过扩展实现预定义接口或使用 Java、Scala 的 lambda 表达式实现自定义的函数。
SQL & Table API:Flink 支持两种关系型的 API,Table API 和 SQL。这两个 API 都是批处理和流处理统一的 API,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型 API 会以相同的语义执行查询,并产生相同的结果。Table API 和 SQL借助了 Apache Calcite 来进行查询的解析,校验以及优化。它们可以与 DataStream 和DataSet API 无缝集成,并支持用户自定义的标量函数,聚合函数以及表值函数。
另外 Flink 具有数个适用于常见数据处理应用场景的扩展库。
复杂事件处理(CEP):模式检测是事件流处理中的一个非常常见的用例。Flink 的 CEP库提供了 API,使用户能够以例如正则表达式或状态机的方式指定事件模式。CEP 库与Flink 的 DataStream API 集成,以便在 DataStream 上评估模式。CEP 库的应用包括网络入侵检测,业务流程监控和欺诈检测。
DataSet API:DataSet API 是 Flink 用于批处理应用程序的核心 API。DataSet API 所提供的基础算子包括 map、reduce、(outer) join、co-group、iterate 等。所有算子都有相应的算法和数据结构支持,对内存中的序列化数据进行操作。如果数据大小超过预留内存,则过量数据将存储到磁盘。Flink 的 DataSet API 的数据处理算法借鉴了传统数据库算法的实现,例如混合散列连接(hybrid hash-join)和外部归并排序(external merge-sort)。
Gelly: Gelly 是一个可扩展的图形处理和分析库。Gelly 是在 DataSet API 之上实现的,并与 DataSet API 集成。因此,它能够受益于其可扩展且健壮的操作符。Gelly 提供了内置算法,如 label propagation、triangle enumeration 和 page rank 算法,也提供了一个简化自定义图算法实现的 Graph API。
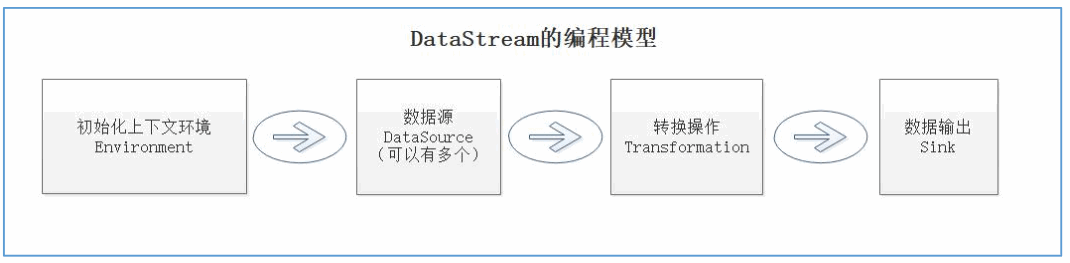
1.DataStream的编程模型
DataStream 的编程模型包括四个部分:Environment,DataSource,Transformation,Sink。
2. Flink 的 的 DataSource 数据源
1) 基于文件的 Source
读取本地文件系统的数据,前面的案例已经讲过了。本课程主要讲基于 HDFS 文件系统的Source。首先需要配置 Hadoop 的依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
读取 HDFS 上的文件:
package vip.shuai7boy.flink.source
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
/**
* 从 HDFS读取内容
*/
object HDFSFileSource {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
environment.setParallelism(1)
//
import org.apache.flink.streaming.api.scala._
val stream = environment.readTextFile("hdfs://tuge2:9000/FlinkDataTest/words")
val result: DataStream[(String, Int)] = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
result.print()
environment.execute("FileSourceTest")
}
}
2) 基于集合的 Source
package vip.shuai7boy.flink.source
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* 从集合读取内容
*/
object CollectionSource {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
environment.setParallelism(1)
import org.apache.flink.api.scala._
val data = environment.fromCollection(Array("hello", "world", "hello", "hi"))
data.print()
environment.execute("collectionSource")
}
}
3) 基于 Kafka 的 的 Source
首 先 需 要 配 置 Kafka 连 接 器 的 依 赖 ,
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.12</artifactId>
<version>1.10.1</version>
</dependency>
①第一种:读取 Kafka 中的普通数据(String)
package vip.shuai7boy.flink.source
import java.util.Properties
import akka.remote.serialization.StringSerializer
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.codehaus.jackson.map.deser.std.StringDeserializer
/**
* 从Kafka读取数据并计算WordCont
*/
object KafkaSourceByString {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
environment.setParallelism(1)
import org.apache.flink.streaming.api.scala._
val properties = new Properties()
properties.setProperty("bootstrap.servers", "tuge1:9092")
properties.setProperty("group.id", "fink01")
properties.setProperty("key.deserializer", classOf[StringSerializer].getName)
properties.setProperty("value.deserializer", classOf[StringDeserializer].getName)
properties.setProperty("auto.offset.reset", "latest")
val stream = environment.addSource(new FlinkKafkaConsumer[String]("wordsTopic", new SimpleStringSchema(),
properties))
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
result.print()
environment.execute()
}
}
②第二种:读取Kafka中KeyValue数据
package vip.shuai7boy.flink.source
import java.util.Properties
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.codehaus.jackson.map.deser.std.StringDeserializer
import org.apache.flink.streaming.api.scala._
/**
* 从Kafka获取key-value类型的数据
*/
object KafkaSourceByKeyValue {
def main(args: Array[String]): Unit = {
//初始化Flink上下文环境
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
environment.setParallelism(1)
val proc = new Properties()
proc.setProperty("group.id", "flink2")
proc.setProperty("bootstrap.servers", "tuge1:9092")
proc.setProperty("name.deserializer", classOf[StringDeserializer].getName)
proc.setProperty("value.deserializer", classOf[StringDeserializer].getName)
proc.setProperty("auto.offset.reset", "latest")
//构建Kafka数据源
val stream = environment.addSource(new FlinkKafkaConsumer[(String, String)]("wordsTopic", new
KafkaDeserializationSchema[(String, String)] {
override def isEndOfStream(t: (String, String)): Boolean = false
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
if (consumerRecord != null) {
var key = "null"
var value = "null"
if (consumerRecord.key() != null) {
key = new String(consumerRecord.key(), "UTF-8")
}
if (consumerRecord.value() != null) {
value = new String(consumerRecord.value(), "UTF-8")
}
(key, value)
} else { //如果数据为空,则返回null数组
(null, null)
}
}
override def getProducedType: TypeInformation[(String, String)] = createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}, proc).setStartFromEarliest())
//打印数据
stream.print()
//执行
environment.execute()
}
}
4) 自定义 Source
当然也可以自定义数据源,有两种方式实现:
通过实现 SourceFunction 接口来自定义无并行度(也就是并行度只能为 1)的 Source。
通过实现 ParallelSourceFunction 接口或者继承 RichParallelSourceFunction 来自定义有并行度的数据源。
拿SourceFunction举例:
package vip.shuai7boy.flink.source import org.apache.flink.streaming.api.functions.source.SourceFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import vip.shuai7boy.flink.StationLog import scala.util.Random /**
* 自定义Soruce源
* 通过实现SourceFunction接口来实现自定义或无并行度的Source
* 通过实现ParalleSourceFunction接口或者继承RichParalleSourceFunction来自定义并行度数据源
*/ object CustomerSource {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.streaming.api.scala._
val stream = env.addSource(new MyCustomerSource)
stream.print()
env.execute()
} class MyCustomerSource extends SourceFunction[StationLog] {
//是否终止数据流标记
var flag = true; /**
* 启动一个source
* 大部分情况下,都需要在这个run里面实现一个循环,这样就产生数据了
*
* @param sourceContext
*/
override def run(sourceContext: SourceFunction.SourceContext[StationLog]): Unit = {
val random = new Random()
var types = Array("fail", "busy", "barring", "success")
while (flag) { //如果没有终止,继续获取数据
1.to(5).map(i => {
var callOut = "1860000%04d".format(random.nextInt(10000)) //%04d是随机生成4位数字
var callIn = "1890000%04d".format(random.nextInt(10000))
new StationLog("station_" + random.nextInt(10), callOut, callIn, types(random.nextInt(4
)), System.currentTimeMillis(), 0) }).foreach(sourceContext.collect(_))
Thread.sleep(2000) //每发送一次休息两秒 }
} /**
* 终止流数据
*/
override def cancel(): Unit = flag = false } }
3. Flink的Sink数据目标
Flink 针对 DataStream 提供了大量的已经实现的数据目标(Sink),包括文件、Kafka、Redis、HDFS、Elasticsearch 等等。
1) 基于 HDFS 的 的 Sink
Streaming File Sink 能把数据写入 HDFS 中,还可以支持分桶写入,每一个分桶就对应 HDFS 中的一个目录。默认按照小时来分桶,在一个桶内部,会进一步将输出基于滚动策略切分成更小的文件。这有助于防止桶文件变得过大。滚动策略也是可以配置的,默认 策略会根据文件大小和超时时间来滚动文件,超时时间是指没有新数据写入部分文件(partfile)的时间。
package vip.shuai7boy.flink.sink
import java.util.concurrent.TimeUnit
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* 基于HDFS的Sink
*/
object HDFSFileSink {
def main(args: Array[String]): Unit = {
//构建Flink上下文
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.streaming.api.scala._
//读取数据
val data = env.readTextFile("./data/words")
//构建Kafka Sink
val outPutPath = "hdfs://tuge2:9000/FlinkDataTest"
val sink = StreamingFileSink.forRowFormat(new Path(outPutPath), new SimpleStringEncoder[String]("UTF-8"))
.withRollingPolicy(
DefaultRollingPolicy.builder()
.withInactivityInterval(TimeUnit.MINUTES.toMinutes(1)) //文件不活动
.withRolloverInterval(TimeUnit.MINUTES.toMinutes(5)) //每隔5分钟生成一个文件
.withMaxPartSize(1024 * 1024 * 1024) //文件最大大小为1G
.build()
).build()
data.addSink(sink)
env.execute()
}
}
2) 基于 Redis 的 的 Sink
Flink 除了内置的连接器外,还有一些额外的连接器通过 Apache Bahir 发布,包括:
- Apache ActiveMQ (source/sink)
- Apache Flume (sink)
- Redis (sink)
- Akka (sink)
- Netty (source)
这里我用 Redis 来举例,首先需要配置 Redis 连接器的依赖:
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
<version>1.0</version>
</dependency>
接下来我们可以把 WordCount 的结果写入 Redis 中:
package vip.shuai7boy.flink.sink
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.redis.RedisSink
import org.apache.flink.streaming.connectors.redis.common.config.{FlinkJedisConfigBase, FlinkJedisPoolConfig}
import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper}
/**
* 将计算结果存入Redis
*/
object RedisSink {
def main(args: Array[String]): Unit = {
//构建Flink环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.streaming.api.scala._
//从Socket获取数据
val stream = env.socketTextStream("tuge2", 8888)
//计算wordcount
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
//构建Redis配置
val redisConfig = new FlinkJedisPoolConfig.Builder().setDatabase(0).setHost("tuge1").setPort(6379).build()
result.print()
//将结果存入Redis
result.addSink(new RedisSink[(String, Int)](redisConfig, new RedisMapper[(String, Int)] {
override def getCommandDescription: RedisCommandDescription = new RedisCommandDescription(RedisCommand.HSET, "t_wc")
override def getKeyFromData(t: (String, Int)): String = t._1 //单词
override def getValueFromData(t: (String, Int)): String = t._2 + "" //单词出现的次数
}))
env.execute()
}
}
3) 基于 Kafka 的 的 Sink
将 WordCout 的结果写入 Kafka演示:
package vip.shuai7boy.flink.sink
import java.lang
import java.util.Properties
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.kafka.clients.producer.ProducerRecord
/**
* Kafka作为SInk第二种(将Key,Value写入Kafka)
*
* 在控制台消费命令: $ ./bin/kafka-console-consumer.sh --bootstrap-server tuge1:9092 --topic t_topic --from-beginning
* --property print-key=true
*/
object KafkaSinkByKeyValue {
def main(args: Array[String]): Unit = {
//定义Flink Streaming上下文环境
val streamEnv: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1) //默认情况下每个任务的并行度为1
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取netcat流中数据 (实时流)
val stream1: DataStream[String] =
streamEnv.socketTextStream("tuge1", 6666)
//转换计算
val result = stream1.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
//Kafka生产者的配置
val props = new Properties()
props.setProperty("bootstrap.servers", "tuge1:9092")
//数据写入Kafka,并且是KeyValue格式的数据
val kafkaSink = new FlinkKafkaProducer[(String, Int)]("t_topic", new
KafkaSerializationSchema[(String, Int)] {
override def serialize(element: (String, Int), timestamp: lang.Long) = {
new
ProducerRecord("t_topic", element._1.getBytes, (element._2 + "").getBytes())
}
}, props, FlinkKafkaProducer.Semantic.EXACTLY_ONCE)
result.addSink(kafkaSink) //EXACTLY_ONCE 精确一次
//执行
streamEnv.execute()
}
}
4)自定义的 Sink
当然你可以自己定义 Sink,有两种实现方式:1、实现 SinkFunction 接口。2、实现RichSinkFunction 类。后者增加了生命周期的管理功能。比如需要在 Sink 初始化的时候创建连接对象,则最好使用第二种。
案例需求:把 StationLog 对象写入 Mysql 数据库中。
添加mysql依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
package vip.shuai7boy.flink.sink
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import vip.shuai7boy.flink.StationLog
/**
* 自定义Sink实现
* 自定义Sink 继承SinkFunction或RichSinkFunction即可
* (将数据写入MySql)
*/
object CustomJdbcSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.api.scala._
val stream = env.readTextFile(getClass.getResource("/words").getPath)
val data = stream.map(line => {
val lineWord = line.split(" ")
new Person(lineWord(0).toInt, lineWord(1).toString, lineWord(2).toInt)
})
data.addSink(new MyCustomSink)
env.execute("person_sink")
print("执行完毕!")
}
//自定义一个Sink写入MySql
class MyCustomSink extends RichSinkFunction[Person] {
var conn: Connection = _
var pres: PreparedStatement = _
override def invoke(per: Person, context: SinkFunction.Context[_]): Unit = {
pres.setInt(1, per.id)
pres.setString(2, per.name)
pres.setInt(3, per.age)
pres.execute()
}
override def open(parameters: Configuration): Unit = {
conn = DriverManager.getConnection("jdbc:mysql://tuge1:3306/test?characterEncoding=utf-8&userUnicode=true",
"root",
"123456")
pres = conn.prepareStatement("insert into Person(Id,`Name`,Age) values(?,?,?)")
}
override def close(): Unit = {
pres.close()
conn.close()
}
}
case class Person(id: Int, name: String, age: Int)
}
4. DataStream转换算子
即通过从一个或多个 DataStream 生成新的 DataStream 的过程被称为 Transformation操作。在转换过程中,每种操作类型被定义为不同的 Operator,Flink 程序能够将多个Transformation 组成一个 DataFlow 的拓扑。
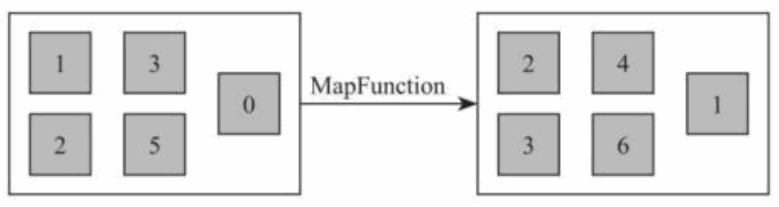
1) Map [DataStream->DataStream]
调 用 用 户 定 义 的 MapFunction 对 DataStream[T] 数 据 进 行 处 理 , 形 成 新 的DataStream[T],其中数据格式可能会发生变化,常用作对数据集内数据的清洗和转换。例如将输入数据集中的每个数值全部加 1 处理,并且将数据输出到下游数据集。
2) FlatMap [DataStream->DataStream]
该算子主要应用处理输入一个元素产生一个或者多个元素的计算场景,比较常见的是在经典例子 WordCount 中,将每一行的文本数据切割,生成单词序列如在图所示,对于输入DataStream[String]通过 FlatMap 函数进行处理,字符串数字按逗号切割,然后形成新的整数数据集。

val resultStream[String] = dataStream.flatMap { str => str.split(" ") }
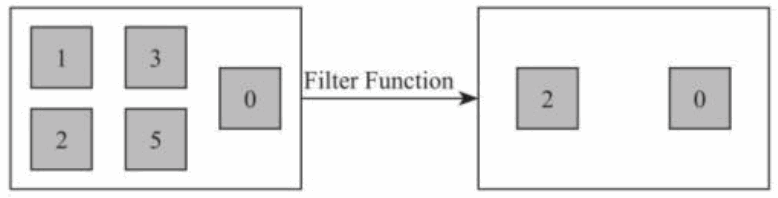
3) Filter [DataStream->DataStream]
该算子将按照条件对输入数据集进行筛选操作,将符合条件的数据集输出,将不符合条件的数据过滤掉。如下图所示将输入数据集中偶数过滤出来,奇数从数据集中去除。
//通过通配符
val filter:DataStream[Int] = dataStream.filter { _ % 2 == 0 }
//或者指定运算表达式
val filter:DataStream[Int] = dataStream.filter { x => x % 2 == 0 }
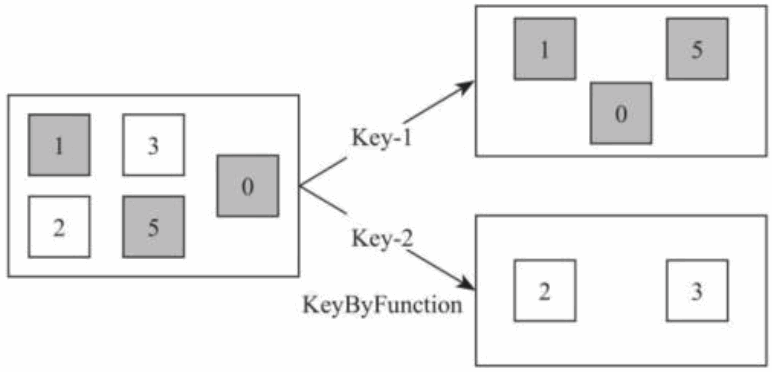
4) KeyBy [DataStream->KeyedStream]
该算子根据指定的 Key 将输入的 DataStream[T]数据格式转换为 KeyedStream[T],也就是在数据集中执行 Partition 操作,将相同的 Key 值的数据放置在相同的分区中。如下图所示,将白色方块和灰色方块通过颜色的 Key 值重新分区,将数据集分为具有灰色方块的数据集
将数据集中第一个参数作为 Key,对数据集进行 KeyBy 函数操作,形成根据 id 分区的KeyedStream 数据集。其中 keyBy 方法输入为 DataStream[T]数据集。
val dataStream = env.fromElements((1, 5),(2, 2),(2, 4),(1, 3))
//指定第一个字段为分区Key
val keyedStream: KeyedStream[(String,Int), Tuple] = dataStream.keyBy(0)
5) Reduce [KeyedStream->DataStream]
该算子和 MapReduce 中 Reduce 原理基本一致,主要目的是将输入的 KeyedStream 通过传 入 的 用 户 自 定 义 的 ReduceFunction 滚 动 地 进 行 数 据 聚 合 处 理 , 其 中 定 义 的ReduceFunciton 必须满足运算结合律和交换律。如下代码对传入 keyedStream 数据集中相同的 key 值的数据独立进行求和运算,得到每个 key 所对应的求和值。
val dataStream = env.fromElements(("a", 3), ("d", 4), ("c", 2), ("c",5), ("a", 5))
//指定第一个字段为分区Key
val keyedStream: KeyedStream[(String,Int), Tuple] = dataStream.keyBy(0)
/滚动对第二个字段进行reduce相加求和
val reduceStream = keyedStream.reduce { (t1, t2) =>
(t1._1, t1._2 + t2._2)
}
6) Aggregations[KeyedStream->DataStream]
Aggregations 是 KeyedDataStream 接口提供的聚合算子,根据指定的字段进行聚合操作,滚动地产生一系列数据聚合结果。其实是将 Reduce 算子中的函数进行了封装,封装的聚合操作有sum,min,minBy,max,maxBy 等,这样就不需要用户自己定义 Reduce 函数。如下代码所示,指定数据集中第一个字段作为 key,用第二个字段作为累加字段,然后滚动地对第二个字段的数值进行累加并输出。
/指定第一个字段为分区Key
val keyedStream: KeyedStream[(Int, Int), Tuple] = dataStream.keyBy(0)
//对第二个字段进行sum统计
val sumStream: DataStream[(Int, Int)] = keyedStream.sum(1)
//输出计算结果
sumStream.print()
7) Union[DataStream ->DataStream]
Union 算子主要是将两个或者多个输入的数据集合并成一个数据集,需要保证两个数据集的格式一致,输出的数据集的格式和输入的数据集格式保持一致,如图所示,将灰色方块数据集和黑色方块数据集合并成一个大的数据集。
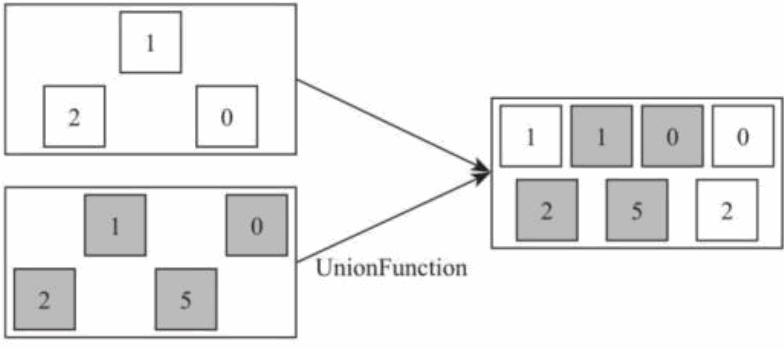
//创建不同的数据集
val dataStream1: DataStream[(String, Int)] = env.fromElements(("a", 3), ("d", 4), ("c",
2), ("c", 5), ("a", 5))
val dataStream2: DataStream[(String, Int)] = env.fromElements(("d", 1), ("s", 2), ("a",
4), ("e", 5), ("a", 6))
val dataStream3: DataStream[(String, Int)] = env.fromElements(("a", 2), ("d", 1), ("s",
2), ("c", 3), ("b", 1))
//合并两个DataStream数据集
val unionStream = dataStream1.union(dataStream_02)
//合并多个DataStream数据集
val allUnionStream = dataStream1.union(dataStream2, dataStream3)
8) Connect CoMap ,CoFlatMap[DataStream ->ConnectedStream->DataStream]
Connect 算子主要是为了合并两种或者多种不同数据类型的数据集,合并后会保留原来数据集的数据类型。例如:dataStream1 数据集为(String, Int)元祖类型,dataStream2数据集为 Int 类型,通过 connect 连接算子将两个不同数据类型的流结合在一起,形成格式为 ConnectedStreams 的数据集,其内部数据为[(String, Int), Int]的混合数据类型,保留了两个原始数据集的数据类型。
//创建不同数据类型的数据集
val dataStream1: DataStream[(String, Int)] = env.fromElements(("a", 3), ("d", 4), ("c",
2), ("c", 5), ("a", 5))
val dataStream2: DataStream[Int] = env.fromElements(1, 2, 4, 5, 6)
//连接两个DataStream数据集
val connectedStream: ConnectedStreams[(String, Int), Int] =
dataStream1.connect(dataStream2)
需要注意的是,对于 ConnectedStreams 类型的数据集不能直接进行类似 Print()的操作,需要再转换成 DataStream 类型数据集,在 Flink 中 ConnectedStreams 提供的 map()方法和 flatMap()
package vip.shuai7boy.flink.suanzi
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//使用Connect聚合两个集合
object ConnectSZ {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
import org.apache.flink.streaming.api.scala._
val stream1: DataStream[(String, Int)] = env.fromElements(("张三", 33), ("李四", 44))
val stream2: DataStream[String] = env.fromElements("李四", "赵六")
val conStream = stream1.connect(stream2)
val result = conStream.flatMap(
f => {
(f._1 + "_" + f._2).split("_")
},
f => {
f.split(",")
}
)
result.print()
env.execute("打印姓名")
}
}
PS;Union和Connect区别
- Union 之前两个流的类型必须是一样,Connect 可以不一样,在之后的 coMap 中再去调整成为一样的。
- Connect 只能操作两个流,Union 可以操作多个。
9) Split 和 和 select [DataStream->SplitStream->DataStream]
Split 算子是将一个 DataStream 数据集按照条件进行拆分,形成两个数据集的过程,也是 union 算子的逆向实现。每个接入的数据都会被路由到一个或者多个输出数据集中。如下图所示,将输入数据集根据颜色切分成两个数据集。
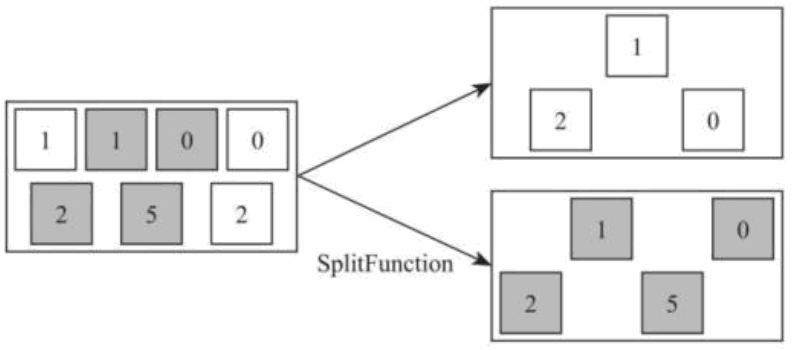
在使用 split 函数中,需要定义 split 函数中的切分逻辑,通过调用 split 函数,然后指定条件判断函数,如下面的代码所示:将根据第二个字段的奇偶性将数据集标记出来,如果是偶数则标记为 even,如果是奇数则标记为 odd,然后通过集合将标记返回,最终生成格式 SplitStream 的数据集。
//创建数据集
val dataStream1: DataStream[(String, Int)] = env.fromElements(("a", 3), ("d", 4), ("c",
2), ("c", 5), ("a", 5))
//合并两个DataStream数据集
val splitedStream: SplitStream[(String, Int)] = dataStream1.split(t => if (t._2 % 2 == 0)
Seq("even") else Seq("odd"))
split 函数本身只是对输入数据集进行标记,并没有将数据集真正的实现切分,因此需要借助 Select 函数根据标记将数据切分成不同的数据集。如下代码所示,通过调用SplitStream 数据集的 select()方法,传入前面已经标记好的标签信息,然后将符合条件的数据筛选出来,形成新的数据集。
//筛选出偶数数据集
val evenStream: DataStream[(String, Int)] = splitedStream.select("even")
//筛选出奇数数据集
val oddStream: DataStream[(String, Int)] = splitedStream.select("odd")
//筛选出奇数和偶数数据集
val allStream: DataStream[(String, Int)] = splitedStream.select("even", "odd")
5. 函数类和富函数类
前面学过的所有算子几乎都可以自定义一个函数类、富函数类作为参数。因为 Flink暴露了者两种函数类的接口,常见的函数接口有:
MapFunction
FlatMapFunction
ReduceFunction
。。。
富函数接口它其他常规函数接口的不同在于:可以获取运行环境的上下文,在上下文环境中可以管理状态(State 在下一章节中提到),并拥有一些生命周期方法,所以可以实现更复杂的功能。富函数的接口有:
RichMapFunction
RichFlatMapFunction
RichFilterFunction
。。。
1)普通函数类举例:按照指定的时间格式输出每个通话的拨号时间和结束时间。数据如下:
station_2,18600003532,18900008128,success,1577080459130,10
station_2,18600003532,18900008128,success,1577080466130,15
station_8,18600007699,18900003716,barring,1577080459130,0
station_0,18600003502,18900009859,fail,1577080459130,0
station_0,18600003502,18900009859,success,1577080468130,0
package vip.shuai7boy.flink.richfun
import java.text.SimpleDateFormat
import org.apache.flink.api.common.functions.MapFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import vip.shuai7boy.flink.StationLog
/**
* 普通函数类举例
*/
object FunctionClassTransformation {
def main(args: Array[String]): Unit = {
//初始化上下文环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取文件数据
val data = env.readTextFile(getClass.getResource("/station.log").getPath).map(line => {
val arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//定义时间输出格式
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
//过滤掉那些通话成功的
data.filter(_.callType.equals("success"))
.map(new CallMapFunction(format))
.print()
}
//自定义函数的类
class CallMapFunction(format: SimpleDateFormat) extends MapFunction[StationLog, String] {
override def map(t: StationLog): String = {
val startTime = t.callTime
val endTime = t.callTime + t.duration * 1000
"基站ID:" + t.sid + ",呼叫号码:" + t.callOut + ",被叫号码:" + t.callIn + ",呼叫时间:" + format.format(t.callTime) + ",结束时间:" + format.format(endTime)
}
}
}
2)富函数类举例:
package vip.shuai7boy.flink.richfun
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import vip.shuai7boy.flink.StationLog
/**
* 富函数类定义
*/
object RichFunctionClassTransformation {
def main(args: Array[String]): Unit = {
//构建Flink流式数据上下文执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度为1
env.setParallelism(1)
//设置隐式转换
import org.apache.flink.streaming.api.scala._
//获取通话成功的数据
val data = env.readTextFile(getClass.getResource("/station.log").getPath).filter(_.split(",")(3).equals("success"))
.map(line => {
val arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
data.map(new CallRichMapFunction)
.print()
env.execute()
}
}
class CallRichMapFunction() extends RichMapFunction[StationLog, StationLog] {
var conn: Connection = _
var pre: PreparedStatement = _
override def open(parameters: Configuration): Unit = {
Class.forName("com.mysql.jdbc.Driver")
conn = DriverManager.getConnection("jdbc:mysql://tuge1:3306/test", "root", "123456")
pre = conn.prepareStatement("select `Name` from Person where id=?")
}
override def close(): Unit = {
pre.close()
conn.close()
}
override def map(in: StationLog): StationLog = {
pre.setInt(1, 1) //注意设置mysql时,index是从1开始的
val result = pre.executeQuery()
if (result.next()) {
in.callIn = result.getString(1)
}
in
}
}
6. 底层 ProcessFunctionAPI
ProcessFunction 是一个低层次的流处理操作,允许返回所有 Stream 的基础构建模块:
访问 Event 本身数据(比如:Event 的时间,Event 的当前 Key 等)
管理状态 State(仅在 Keyed Stream 中)
管理定时器 Timer(包括:注册定时器,删除定时器等)
总而言之,ProcessFunction 是 Flink 最底层的 API,也是功能最强大的。
例如:监控每一个手机,如果在 5 秒内呼叫它的通话都是失败的,发出警告信息。
package vip.shuai7boy.flink.processfun import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.streaming.api.functions.KeyedProcessFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.util.Collector
import vip.shuai7boy.flink.StationLog /**
* 监控每一个手机号,如果在8秒内呼叫它的通话都是失败的,则发出报警信息
* 如果在8秒内有一条不是失败的,则不发送
*/
object TestProcessFunction { def main(args: Array[String]): Unit = {
//初始化Flink Streaming上下文环境
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
streamEnv.setParallelism(1)
import org.apache.flink.streaming.api.scala._
//获取数据
val data = streamEnv.socketTextStream("tuge1", 6666).filter(_.split(",").length >= 6)
.map(line => {
var arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//处理数据
data.keyBy(_.callIn)
.process(new MonitorCallFail())
.print()
streamEnv.execute() } } //监控逻辑
class MonitorCallFail() extends KeyedProcessFunction[String, StationLog, String] {
//使用一个状态记录时间
lazy val timeState: ValueState[Long] = getRuntimeContext.getState(new ValueStateDescriptor[Long]("time",
classOf[Long])) override def processElement(i: StationLog, context: KeyedProcessFunction[String, StationLog, String]#Context,
collector: Collector[String]): Unit = {
//从状态中获取时间
val time = timeState.value() //记录时间
if (time.toLong == 0 && i.callType.equals("fail")) {
val procTime = context.timerService().currentProcessingTime()
val onTime = procTime + 8 * 1000L //设置8秒后触发
context.timerService().registerProcessingTimeTimer(onTime) //更新处理时间
timeState.update(onTime)
}
if (time.toLong != 0 && i.callType.equals("success")) { //如果在8秒内有成功的,则清空处理时间
context.timerService().deleteProcessingTimeTimer(time)
timeState.clear()
}
} override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, StationLog, String]#OnTimerContext,
out: Collector[String]): Unit = {
var infoStr = "手机号:" + ctx.getCurrentKey + ",时间:" + timestamp
out.collect(infoStr)
timeState.clear()
}
}
7. 侧输出流 Side Output
在 flink 处理数据流时,我们经常会遇到这样的情况:在处理一个数据源时,往往需要将该源中的不同类型的数据做分割处理,如果使用 filter 算子对数据源进行筛选分割的话,势必会造成数据流的多次复制,造成不必要的性能浪费;flink 中的侧输出就是将数据流进行分割,而不对流进行复制的一种分流机制。flink 的侧输出的另一个作用就是对延时迟到的数据进行处理,这样就可以不必丢弃迟到的数据。在后面的章节中会讲到!
案例:根据基站的日志,请把呼叫成功的 Stream(主流)和不成功的 Stream(侧流)分别输出。
package vip.shuai7boy.flink.sideOutPut
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala.{OutputTag, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
import vip.shuai7boy.flink.StationLog
/**
* 测流输出流Demo
* 将呼叫成功的主流输出,不成功的测流输出
*/
object TestSideOutputStream {
//导入隐式转换
import org.apache.flink.streaming.api.scala._
private val notSuccessTag: OutputTag[StationLog] = new OutputTag[StationLog]("not-successTag")
def main(args: Array[String]): Unit = {
//初始化上下文环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//读取文件数据
val data = env.readTextFile(getClass.getResource("/station.log").getPath).map(line => {
val arr = line.split(",")
new StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
val result = data.process(new CreateSideOutputStream(notSuccessTag))
val sideOutPut = result.getSideOutput(notSuccessTag) //根据主流来获取测流
result.print("主流") //得到主流数据
sideOutPut.print("测流") //得到测流数据
env.execute() //执行
}
class CreateSideOutputStream(tag: OutputTag[StationLog]) extends ProcessFunction[StationLog, StationLog] {
override def processElement(i: StationLog, context: ProcessFunction[StationLog, StationLog]#Context,
collector: Collector[StationLog]): Unit = {
if (i.callType.equals("success")) {
collector.collect(i)
} else {
context.output(tag, i)
}
}
}
}
第五节 Flink State 管理与恢复
Flink 是一个默认就有状态的分析引擎,前面的 WordCount 案例可以做到单词的数量的累加,其实是因为在内存中保证了每个单词的出现的次数,这些数据其实就是状态数据。但是如果一个 Task 在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。从容错和消息处理的语义(At -least-once 和 Exactly-once)上来说,Flink引入了 State 和 CheckPoint。
- State 一般指一个具体的 Task/Operator 的状态,State 数据默认保存在 Java 的堆内存中。
- CheckPoint(可以理解为 CheckPoint 是把 State 数据持久化存储了)则表示了一个Flink Job 在一个特定时刻的一份全局状态快照,即包含了所有 Task/Operator 的状态。
1. 常用 State
Flink 有两种常见的 State 类型,分别是:
- keyed State(键控状态)
- Operator State(算子状态)
1) Keyed State (键控状态)
Keyed State:顾名思义就是基于 KeyedStream 上的状态,这个状态是跟特定的 Key 绑定的。KeyedStream 流上的每一个 Key,都对应一个 State。Flink 针对 Keyed State 提供了以下可以保存 State 的数据结构:
- ValueState: 保存一个可以更新和检索的值(如上所述,每个值都对应到当前的输入数据的 key,因此算子接收到的每个 key 都可能对应一个值)。 这个值可以通过update(T) 进行更新,通过 T value() 进行检索。
- ListState: 保存一个元素的列表。可以往这个列表中追加数据,并在当前的列表上进行检索。可以通过 add(T) 或者 addAll(List) 进行添加元素,通过 Iterableget() 获得整个列表。还可以通过 update(List) 覆盖当前的列表。
- MapState<UK, UV>: 维护了一个映射列表。 你可以添加键值对到状态中,也可以获得反映当前所有映射的迭代器。使用 put(UK,UV) 或者 putAll(Map<UK,UV>) 添加映射。使用 get(UK) 检索特定 key。 使用 entries(),keys() 和 values() 分别检索映射、键和值的可迭代视图。
2) Operator State(算子状态)
Operator State 与 Key 无关,而是与 Operator 绑定,整个 Operator 只对应一个 State。比如:Flink 中的 Kafka Connector 就使用了 Operator State,它会在每个 Connector 实例中,保存该实例消费 Topic 的所有(partition, offset)映射。
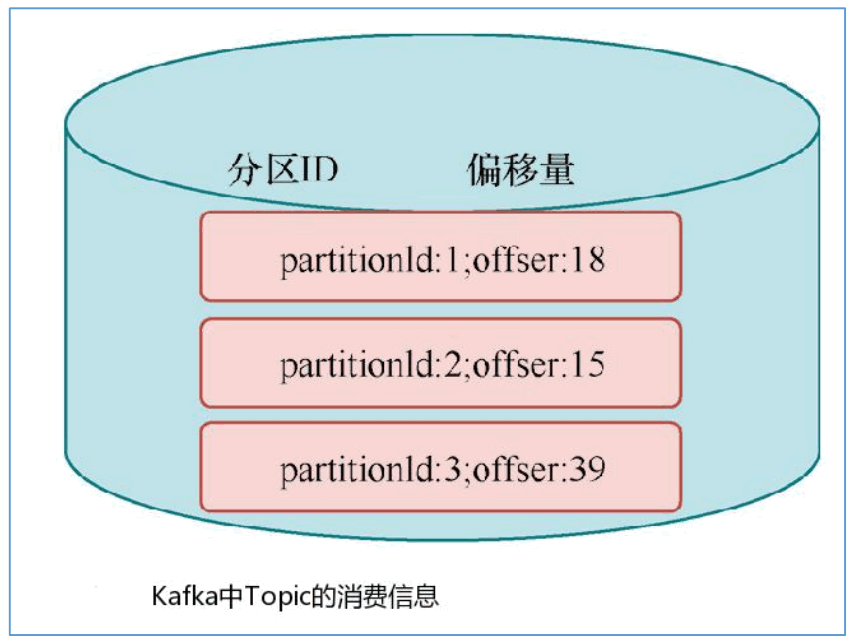
3) Keyed State 案例
第一种实现:
package vip.shuai7boy.flink.state
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.util.Collector
import vip.shuai7boy.flink.StationLog
/**
* 统计每隔手机的呼叫时间间隔,并输出
* 第一种方法通过定义一个类实现 键控
*/
/**
* 状态分为了 键控状态(keyed)和算子状态(operator state)
* 监控状态分为:ValueState,ListState,MapState
*/
object StateCallInterval1 {
def main(args: Array[String]): Unit = {
//初始化Flink Streaming(流计算)上下文环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取文件数据
val data = env.readTextFile(getClass.getResource("/station.log").getPath)
.map(line => {
val arr = line.split("',")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
data.keyBy(_.callIn)
.flatMap(new CallIntervalFunction())
.print()
}
class CallIntervalFunction() extends RichFlatMapFunction[StationLog, (String, Long)] {
//定义一个保存前一条呼叫数据的对象
private var preData: ValueState[StationLog] = _
override def open(parameters: Configuration): Unit = {
val stateDescriptor = new ValueStateDescriptor[StationLog]("preState", classOf[StationLog])
preData = getRuntimeContext.getState(stateDescriptor)
}
override def flatMap(in: StationLog, collector: Collector[(String, Long)]): Unit = {
var pre: StationLog = preData.value()
if (pre == null) {
preData.update(in)
} else { //如果
val interval = in.callTime - pre.callTime
collector.collect((in.callIn, interval))
}
}
}
}
第二种实现:
package vip.shuai7boy.flink.state
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import vip.shuai7boy.flink.StationLog
/**
* 统计每隔手机的呼叫时间间隔,并输出
* 第二种方法通过mapWithState实现
*/
object StateCallInterval2 {
def main(args: Array[String]): Unit = {
//初始化Flink Streaming(流计算)上下文环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取文件数据
val data = env.readTextFile(getClass.getResource("/station.log").getPath)
.map(line => {
val arr = line.split("',")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
data.keyBy(_.callIn) //按照呼叫手机号分组
.mapWithState[(String, Long), StationLog] {
case (in: StationLog, None) => ((in.callIn, 0), Some(in))
case (in: StationLog, pre: Some[StationLog]) => {
var interval = in.callTime - pre.get.callTime
((in.callIn, interval), Some(in))
}
}
}
}
第三种实现:
package vip.shuai7boy.flink.state
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment}
import vip.shuai7boy.flink.StationLog
/**
* 统计每个手机的呼叫时间间隔,并输出
* 第三种方法通过flatMapWithState实现
*/
object StateCallInterval3 {
//初始化Flink Streaming(流计算)上下文环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取文件数据
val data = env.readTextFile(getClass.getResource("/station.log").getPath)
.map(line => {
val arr = line.split("',")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
data.keyBy(_.callIn)
.flatMapWithState[(String, Long), StationLog] {
case (in: StationLog, None) => (List.empty, Some(in))
case (in: StationLog, pre: Some[StationLog]) => {
var internal = in.callTime - pre.get.callTime
(List((in.callIn, internal)), Some(in))
}
}.print()
//执行
env.execute()
}
2. CheckPoint
当程序出现问题需要恢复 Sate 数据的时候,只有程序提供支持才可以实现 State 的容错。State 的容错需要依靠 CheckPoint 机制,这样才可以保证 Exactly-once 这种语义,但是注意,它只能保证Flink系统内的Exactly-once,比如Flink内置支持的算子。针对Source和 Sink 组件,如果想要保证 Exactly-once 的话,则这些组件本身应支持这种语义。
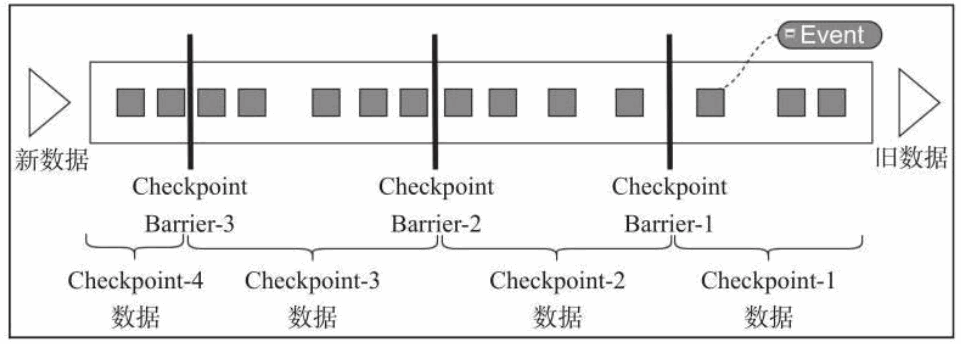
1) CheckPoint 原理
Flink 中基于异步轻量级的分布式快照技术提供了 Checkpoints 容错机制,分布式快照可以将同一时间点 Task/Operator 的状态数据全局统一快照处理,包括前面提到的 KeyedState 和 Operator State。Flink 会在输入的数据集上间隔性地生成 checkpoint barrier,通过栅栏(barrier)将间隔时间段内的数据划分到相应的 checkpoint 中。如下图:
从检查点(CheckPoint)恢复如下图:
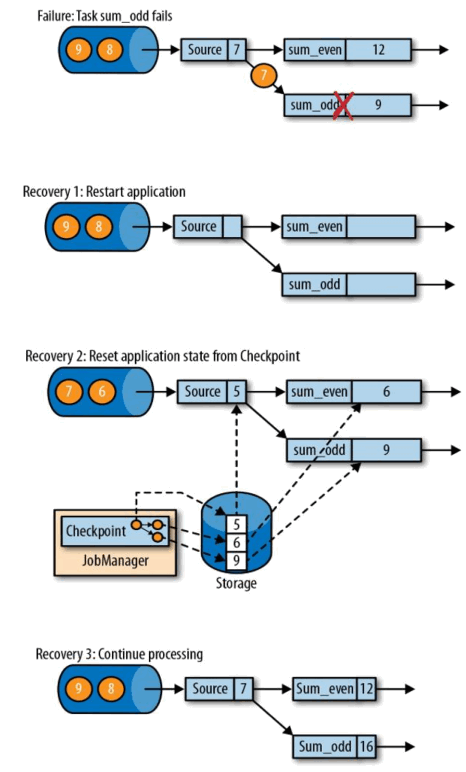
2) CheckPoint 参数设置
默认情况下 Flink 不开启检查点的,用户需要在程序中通过调用方法配置和开启检查点,另外还可以调整其他相关参数:
Checkpoint 开启和时间间隔指定:
开启检查点并且指定检查点时间间隔为 1000ms,根据实际情况自行选择,如果状态比较大,则建议适当增加该值。
streamEnv.enableCheckpointing(1000);
exactly-ance 和 at-least-once 语义选择:
选择 exactly-once 语义保证整个应用内端到端的数据一致性,这种情况比较适合于数据要求比较高,不允许出现丢数据或者数据重复,与此同时,Flink 的性能也相对较弱,而at-least-once 语义更适合于时廷和吞吐量要求非常高但对数据的一致性要求不高的场景如 下 通 过 setCheckpointingMode() 方 法 来 设 定 语 义 模 式 , 默 认 情 况 下 使 用 的 是exactly-once 模式。
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACT
LY_ONCE);//或者
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.AT_LE
AST_ONCE)
Checkpoint 超时时间:
超时时间指定了每次 Checkpoint 执行过程中的上限时间范围,一旦 Checkpoint 执行时间超过该阈值,Flink 将会中断 Checkpoint 过程,并按照超时处理。该指标可以通过setCheckpointTimeout 方法设定,默认为 10 分钟。
streamEnv.getCheckpointConfig.setCheckpointTimeout(50000)
检查点之间最小时间间隔:
该参数主要目的是设定两个 Checkpoint 之间的最小时间间隔,防止出现例如状态数据过大而导致 Checkpoint 执行时间过长,从而导致 Checkpoint 积压过多,最终 Flink 应用密集地触发 Checkpoint 操作,会占用了大量计算资源而影响到整个应用的性能。
streamEnv.getCheckpointConfig.setMinPauseBetweenCheckpoints(600)
最大并行执行的检查点数量:
通过setMaxConcurrentCheckpoints()方法设定能够最大同时执行的Checkpoint数量。在默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时触发多个Checkpoint,进而提升 Checkpoint 整体的效率。
streamEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
是否删除 Checkpoint 中保存的数据:
设置为 RETAIN_ON_CANCELLATION:表示一旦 Flink 处理程序被 cancel 后,会保留CheckPoint 数据,以便根据实际需要恢复到指定的 CheckPoint。
设置为 DELETE_ON_CANCELLATION:表示一旦 Flink 处理程序被 cancel 后,会删除CheckPoint 数据,只有 Job 执行失败的时候才会保存 CheckPoint。
//删除
streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckp
ointCleanup.DELETE_ON_CANCELLATION)
//保留
streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckp
ointCleanup.RETAIN_ON_CANCELLATION)
TolerableCheckpointFailureNumber:
设置可以容忍的检查的失败数,超过这个数量则系统自动关闭和停止任务。
streamEnv.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)
3. 保存机制 StateBackend(状态后端)
默认情况下,State 会保存在 TaskManager 的内存中,CheckPoint 会存储在 JobManager的内存中。State 和 CheckPoint 的存储位置取决于 StateBackend 的配置。Flink 一共提供了 3 种 StateBackend 。 包 括 基 于 内 存 的 MemoryStateBackend 、 基 于 文 件 系 统 的FsStateBackend,以及基于 RockDB 作为存储介质的 RocksDBState-Backend。
1) MemoryStateBackend
基于内存的状态管理具有非常快速和高效的特点,但也具有非常多的限制,最主要的就是内存的容量限制,一旦存储的状态数据过多就会导致系统内存溢出等问题,从而影响整个应用的正常运行。同时如果机器出现问题,整个主机内存中的状态数据都会丢失,进而无法恢复任务中的状态数据。因此从数据安全的角度建议用户尽可能地避免在生产环境中使用MemoryStateBackend。
streamEnv.setStateBackend(new MemoryStateBackend(10*1024*1024))
2) FsStateBackend
和MemoryStateBackend有所不同,FsStateBackend是基于文件系统的一种状态管理器,这里的文件系统可以是本地文件系统,也可以是 HDFS 分布式文件系统。FsStateBackend 更适合任务状态非常大的情况,例如应用中含有时间范围非常长的窗口计算,或 Key/valueState 状态数据量非常大的场景。
streamEnv.setStateBackend(new
FsStateBackend("hdfs://tuge1:9000/checkpoint/cp1"))
3) RocksDBStateBackend
RocksDBStateBackend是Flink中内置的第三方状态管理器,和前面的状态管理器不同,RocksDBStateBackend 需要单独引入相关的依赖包到工程中。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.12</artifactId>
<version>1.10.1</version>
</dependency>
RocksDBStateBackend 采用异步的方式进行状态数据的 Snapshot,任务中的状态数据首先被写入本地 RockDB 中,这样在 RockDB 仅会存储正在进行计算的热数据,而需要进行CheckPoint 的时候,会把本地的数据直接复制到远端的 FileSystem 中。
与 FsStateBackend 相比,RocksDBStateBackend 在性能上要比 FsStateBackend 高一些,主要是因为借助于 RocksDB 在本地存储了最新热数据,然后通过异步的方式再同步到文件系统中,但 RocksDBStateBackend 和 MemoryStateBackend 相比性能就会较弱一些。RocksDB克服了 State 受内存限制的缺点,同时又能够持久化到远端文件系统中,推荐在生产中使用。
streamEnv.setStateBackend(
new RocksDBStateBackend ("hdfs://tuge1:9000/checkpoint/cp2"))
4) 全局配置 StateBackend
以上的代码都是单 job 配置状态后端,也可以全局配置状态后端,需要修改flink-conf.yaml 配置文件:
state.backend: filesystem
其中:
filesystem 表示使用 FsStateBackend,
jobmanager 表示使用 MemoryStateBackend,
rocksdb 表示使用 RocksDBStateBackend。
state.checkpoints.dir: hdfs://tuge1:9000/checkpoints
默认情况下,如果设置了 CheckPoint 选项,则 Flink 只保留最近成功生成的 1 个CheckPoint,而当 Flink 程序失败时,可以通过最近的 CheckPoint 来进行恢复。但是,如果希望保留多个 CheckPoint,并能够根据实际需要选择其中一个进行恢复,就会更加灵活。添加如下配置,指定最多可以保存的 CheckPoint 的个数。
state.checkpoints.num-retained: 2
4. CheckPoint案例
案例:设置 HDFS 文件系统的状态后端,取消 Job 之后再次恢复 Job。
package vip.shuai7boy.flink.checkpoint
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* WordCount 状态保存 Demo
*/
object CheckpointOnFsBackend {
def main(args: Array[String]): Unit = {
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
//开启检查点,并设置检查点时间间隔为5000ms
streamEnv.enableCheckpointing(5000)
//将状态持久化到HDFS
streamEnv.setStateBackend(new FsStateBackend("hdfs://tuge1:9000/checkpoint/cp1"))
//设置数据只读取一次
streamEnv.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
//设置超时时间为5000ms
streamEnv.getCheckpointConfig.setCheckpointTimeout(5000)
//设置Flink处理程序被取消后保留Checkpoint数据
streamEnv.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//设置checkpoing并行度为1
streamEnv.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
//设置可以忍受的最大checkpoint失败次数,超过这个次数将会关闭和停止任务
streamEnv.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)
//设置并行度为1
streamEnv.setParallelism(1)
import org.apache.flink.streaming.api.scala._
//读取数据得到DataStream
val stream = streamEnv.socketTextStream("tuge1", 6666)
stream.flatMap(_.split(" ")).map((_, 1)).keyBy(0).sum(1).print()
streamEnv.execute("wc") //启动流式计算
}
}
打包在服务器上执行
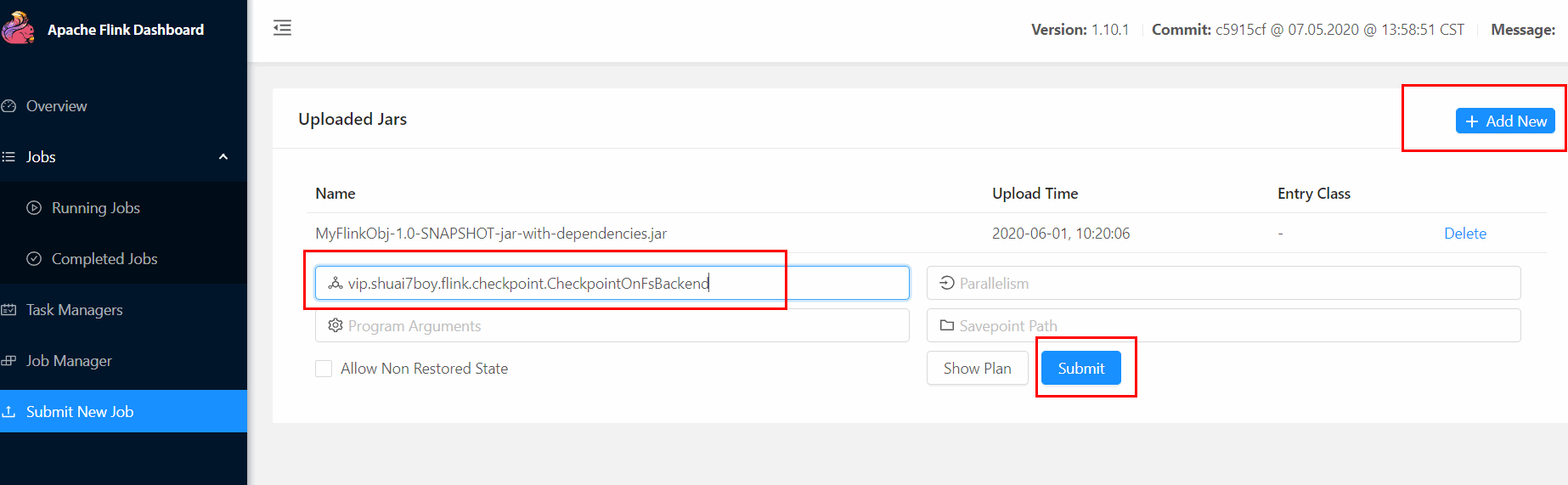
输入数据查看结果:
hello world
hello ammy
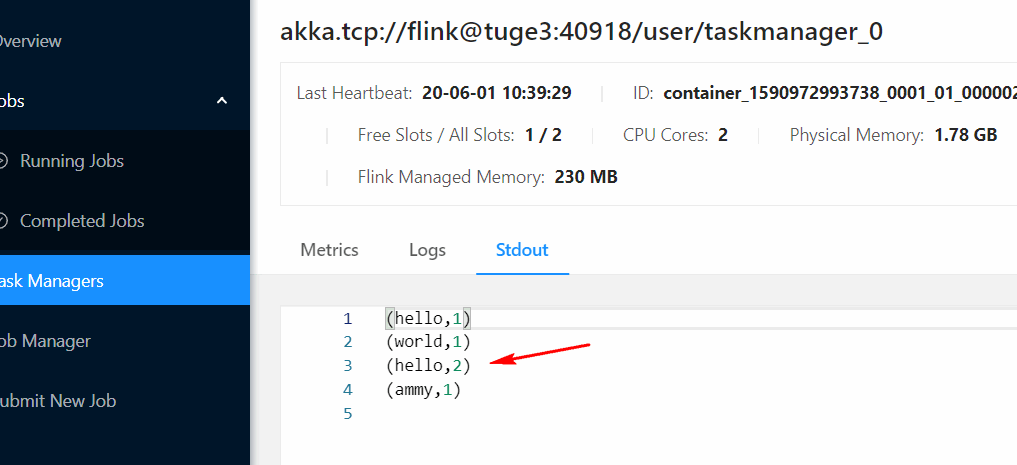
注意一下hello的值,然后这个时候取消掉任务
这个时候浏览hdfs目录,可以看到检查点信息:
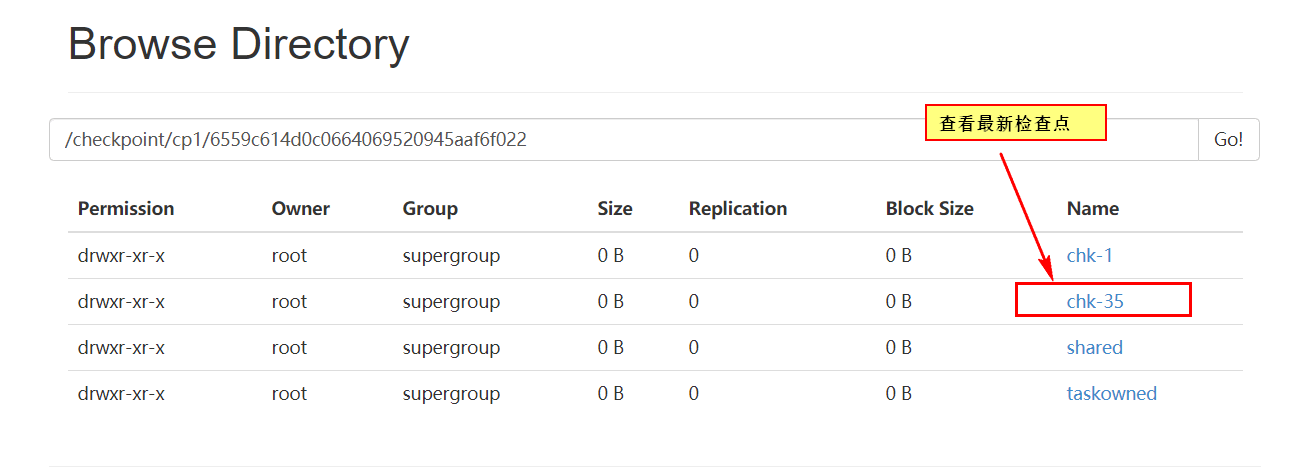
使用命令通过检查点重启任务(注意这个命令必须在FlinkYarnSessionCli(客户端)节点执行):
bin/flink run -d -s hdfs://tuge1:9000/checkpoint/cp1/6559c614d0c0664069520945aaf6f022/chk-35 -c vip.shuai7boy.flink.checkpoint.CheckpointOnFsBackend /data/flinkdata/MyFlinkObj-1.0-SNAPSHOT-jar-with-dependencies.jar
然后输入数据,查看执行结果:
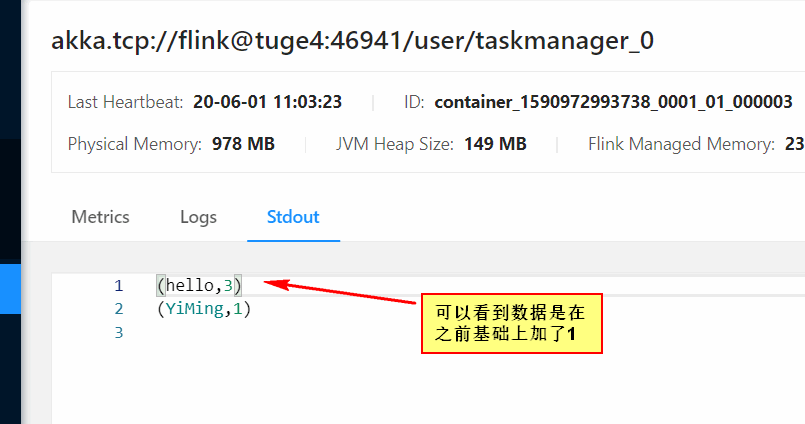
这个时候可以看到检查点成功记录了取消任务之前的状态。
5. SavePoint
Savepoints 是检查点的一种特殊实现,底层实现其实也是使用 Checkpoints 的机制。Savepoints 是用户以手工命令的方式触发 Checkpoint,并将结果持久化到指定的存储路径中,其主要目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况,从而无法实现从端到端的 Excatly-Once 语义保证。
1) 配置 Savepoints 的存储路径
在 flink-conf.yaml 中配置 SavePoint 存储的位置,设置后,如果要创建指定 Job 的SavePoint,可以不用在手动执行命令时指定 SavePoint 的位置。
state.savepoints.dir: hdfs:/tuge1:9000/savepoints
2) 在代码中设置算子 ID
为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,强烈推荐程序员通过手动给算子赋予 ID,这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。而这些自动生成的 ID 依赖于程序的结构,并且对代码的更改是很敏感的。因此,强烈建议用户手动设置 ID。
package vip.shuai7boy.flink.checkpoint
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
/**
* SavePoint是Checkpoint的特殊实现,它允许我们手动保存
* 使用场景:升级服务器之前我们手动保存,然后停掉服务
*/
object TestSavepoints {
def main(args: Array[String]): Unit = {
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度为1,也就是同时只能有一个TaskManager去执行本程序
streamEnv.setParallelism(1)
import org.apache.flink.streaming.api.scala._
//读取数据得到DataStream
val stream: DataStream[String] = streamEnv.socketTextStream("tuge1", 6666).uid("mySource-001")
stream.flatMap(_.split(" "))
.uid("mySplit-001")
.map((_, 1))
.uid("myMap-001")
.keyBy(0)
.sum(1)
.uid("mySum-001")
.print()
streamEnv.execute()
}
}
3) 触发 SavePoint
//先启动Job
[root@tuge1 bin]# ./flink run -c com.bjsxt.flink.state.TestSavepoints -d
/home/Flink-Demo-1.0-SNAPSHOT.jar
//再取消Job ,触发SavePoint
[root@tuge1 bin]# ./flink savepoint 6ecb8cfda5a5200016ca6b01260b94ce
[root@tuge1 bin]# ./flink cancel 6ecb8cfda5a5200016ca6b01260b94ce
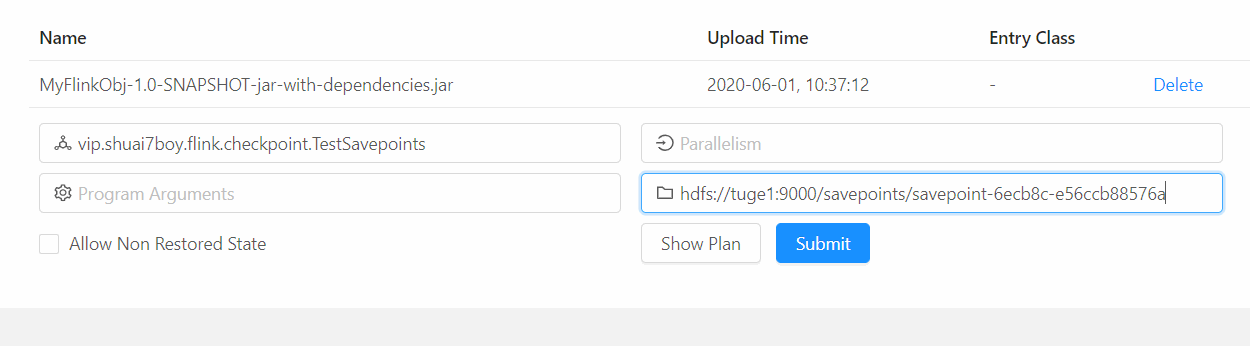
4) 从 从 SavePoint 启动 Job
[root@tuge1 bin]# ./flink run -s
hdfs://tuge1:9000/savepoints/savepoint-6ecb8c-e56ccb88576a -c
vip.shuai7boy.flink.checkpoint.TestSavepoints -d /data/flinkdata/MyFlinkObj-1.0-SNAPSHOT-jar-with-dependencies.jar
也可以通过 Web UI 启动 Job:
第六节 Flink Window(窗口)详解
Windows 计算是流式计算中非常常用的数据计算方式之一,通过按照固定时间或长度将数据流切分成不同的窗口,然后对数据进行相应的聚合运算,从而得到一定时间范围内的统计结果。例如统计最近 5 分钟内某基站的呼叫数,此时基站的数据在不断地产生,但是通过5 分钟的窗口将数据限定在固定时间范围内,就可以对该范围内的有界数据执行聚合处理,得出最近 5 分钟的基站的呼叫数量。
1. Window 分类
1) Global Window和Keyed Window
在运用窗口计算时,Flink根据上游数据集是否为KeyedStream类型,对应的Windows 也会有所不同。
- Keyed Window:上游数据集如果是 KeyedStream 类型,则调用 DataStream API 的 window()方法,数据会根据 Key 在不同的 Task 实例中并行分别计算,最后得出针对每个 Key 统计的结果。
- Global Window:如果是 Non-Keyed 类型,则调用 WindowsAll()方法,所有的数据都会在窗口算子中由到一个 Task 中计算,并得到全局统计结果。
//读取文件数据
val data = streamEnv.readTextFile(getClass.getResource("/station.log").getPath)
.map(line=>{
var arr =line.split(",")
new
StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.to
Long)
})
//Global Window
data.windowAll(自定义的WindowAssigner)
//Keyed Window
data.keyBy(_.sid)
.window(自定义的WindowAssigner)
2) Time Window和Count Window
基于业务数据的方面考虑,Flink 又支持两种类型的窗口,一种是基于时间的窗口叫Time Window。还有一种基于输入数据数量的窗口叫 Count Window。
3) Time Window (时间窗口)
根据不同的业务场景,Time Window 也可以分为三种类型,分别是滚动窗口(TumblingWindow)、滑动窗口(Sliding Window)和会话窗口(Session Window)
滚动窗口(Tumbling Window)
滚动窗口是根据固定时间进行切分,且窗口和窗口之间的元素互不重叠。这种类型的窗口的最大特点是比较简单。只需要指定一个窗口长度(window size)。
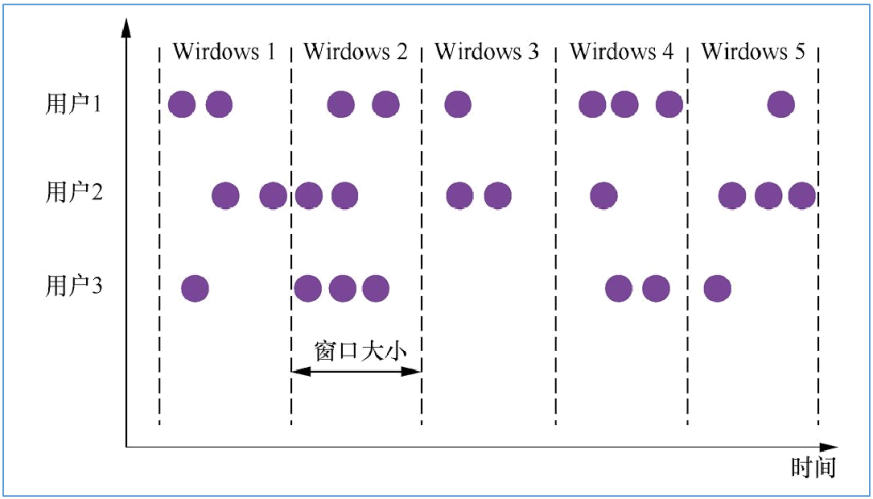
//每隔5秒统计每个基站的日志数量
data.map(stationLog=>((stationLog.sid,1)))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
//.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.sum(1) //聚合
其中时间间隔可以是 Time.milliseconds(x)、Time.seconds(x)或 Time.minutes(x)。
滑动窗口(Sliding Window)
滑动窗口也是一种比较常见的窗口类型,其特点是在滚动窗口基础之上增加了窗口滑动时间(Slide Time),且允许窗口数据发生重叠。当 Windows size 固定之后,窗口并不像滚动窗口按照 Windows Size 向前移动,而是根据设定的 Slide Time 向前滑动。窗口之间的数据重叠大小根据 Windows size 和 Slide time 决定,当 Slide time 小于 Windows size便会发生窗口重叠,Slide size 大于 Windows size 就会出现窗口不连续,数据可能不能在任何一个窗口内计算,Slide size 和 Windows size 相等时,Sliding Windows 其实就是Tumbling Windows。
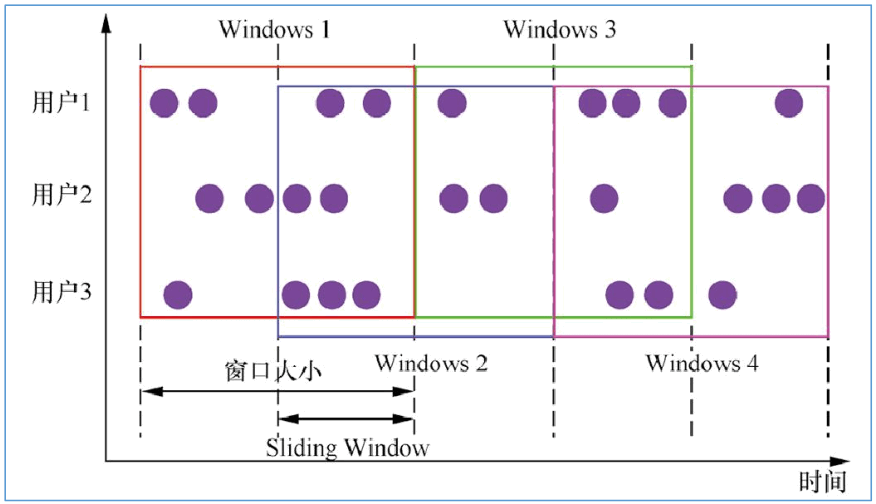
//每隔3秒计算最近5秒内,每个基站的日志数量
data.map(stationLog=>((stationLog.sid,1)))
.keyBy(_._1)
.timeWindow(Time.seconds(5),Time.seconds(3))
//.window(SlidingEventTimeWindows.of(Time.seconds(5),Time.seconds(3)))
.sum(1)
会话窗口(Session Window)
会话窗口(Session Windows)主要是将某段时间内活跃度较高的数据聚合成一个窗口进行计算,窗口的触发的条件是 Session Gap,是指在规定的时间内如果没有数据活跃接入,则认为窗口结束,然后触发窗口计算结果。需要注意的是如果数据一直不间断地进入窗口,也会导致窗口始终不触发的情况。与滑动窗口、滚动窗口不同的是,Session Windows 不需要有固定 windows size 和 slide time,只需要定义 session gap,来规定不活跃数据的时间上限即可。

/3秒内如果没有数据进入,则计算每个基站的日志数量
data.map(stationLog=>((stationLog.sid,1)))
.keyBy(_._1)
.window(EventTimeSessionWindows.withGap(Time.seconds(3)))
.sum(1)
Count Window(数量窗口)
Count Window 也有滚动窗口、滑动窗口等。由于使用比较少,这里不再讲解。
2. Window 的 的 API
在以后的实际案例中 Keyed Window 使用最多,所以我们需要掌握 Keyed Window 的算子,在每个窗口算子中包含了 Windows Assigner、Windows Trigger(窗口触发器)、Evictor(数据剔除器)、Lateness(时延设定)、Output Tag(输出标签)以及 Windows Funciton等组成部分,其中 Windows Assigner 和 Windows Funciton 是所有窗口算子必须指定的属性,其余的属性都是根据实际情况选择指定。
stream.keyBy(...) // 是Keyed类型数据集
.window(...) //指定窗口分配器类型
[.trigger(...)] //指定触发器类型(可选)
[.evictor(...)] //指定evictor或者不指定(可选)
[.allowedLateness(...)] //指定是否延迟处理数据(可选)
[.sideOutputLateData(...)] //指定Output Lag(可选)
.reduce/aggregate/fold/apply() //指定窗口计算函数
[.getSideOutput(...)] //根据Tag输出数据(可选)
- Windows Assigner:指定窗口的类型,定义如何将数据流分配到一个或多个窗口;
- Windows Trigger:指定窗口触发的时机,定义窗口满足什么样的条件触发计算;
- Evictor:用于数据剔除;
- allowedLateness:标记是否处理迟到数据,当迟到数据到达窗口中是否触发计算;
- Output Tag:标记输出标签,然后在通过 getSideOutput 将窗口中的数据根据标签输出;
- Windows Funciton:定义窗口上数据处理的逻辑,例如对数据进行 sum 操作。
3. 窗口聚合函数
如果定义了 Window Assigner 之后,下一步就可以定义窗口内数据的计算逻辑,这也就是 Window Function 的定义。Flink 中提供了三种类型的 Window Function,分别为ReduceFunction、AggregateFunction 以及 ProcessWindowFunction,(sum 和 max)等。
按照计算原理的不同可以分为两大类:
- 一类是增量聚合函数:对应有 ReduceFunction、AggregateFunction;
- 另一类是全量窗口函数,对应有 ProcessWindowFunction(还有 WindowFunction)。增量聚合函数计算性能较高,占用存储空间少,主要因为基于中间状态的计算结果,窗口中只维护中间结果状态值,不需要缓存原始数据。而全量窗口函数使用的代价相对较高,性能比较弱,主要因为此时算子需要对所有属于该窗口的接入数据进行缓存,然后等到窗口触发的时候,对所有的原始数据进行汇总计算。
1) ReduceFunction
ReduceFunction 定义了对输入的两个相同类型的数据元素按照指定的计算方法进行聚合的逻辑,然后输出类型相同的一个结果元素。
//每隔5秒统计每个基站的日志数量
data.map(stationLog=>((stationLog.sid,1)))
.keyBy(_._1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce((v1,v2)=>(v1._1,v1._2+v2._2))
2) AggregateFunction
和 ReduceFunction 相似,AggregateFunction 也是基于中间状态计算结果的增量计算函数,但 AggregateFunction 在窗口计算上更加通用。AggregateFunction 接口相对ReduceFunction 更加灵活,实现复杂度也相对较高。AggregateFunction 接口中定义了三个需要复写的方法,其中 add()定义数据的添加逻辑,getResult 定义了根据 accumulator 计算结果的逻辑,merge 方法定义合并 accumulator 的逻辑。
//统计每个基站每隔5秒的日志增量
stream.map(log => (log.sid, 1))
.keyBy(_._1)
.timeWindow(Time.seconds(5)) //开窗,滑动窗口
.aggregate(new MyAggregateFunction, new MyWindowFunction)
.print()
/**
* 里面的add方法,是来一条数据执行一次,getResult 在窗口结束的时候执行一次
* 参数分为是:进入数据类型,中间处理类型,最终结果类型
*/
class MyAggregateFunction extends AggregateFunction[(String, Int), Long, Long] {
override def createAccumulator(): Long = 0 //初始化一个累加器,开始的时候为0
override def add(value: (String, Int), accumulator: Long): Long = accumulator + value._2
override def getResult(accumulator: Long): Long = accumulator
override def merge(a: Long, b: Long): Long = a + b
}
3) ProcessWindowFunction
前面提到的 ReduceFunction 和 AggregateFunction 都是基于中间状态实现增量计算的窗口函数,虽然已经满足绝大多数场景,但在某些情况下,统计更复杂的指标可能需要依赖于窗口中所有的数据元素,或需要操作窗口中的状态数据和窗口元数据,这时就需要使用到ProcessWindowsFunction,ProcessWindowsFunction 能够更加灵活地支持基于窗口全部数据元素的结果计算,例如对整个窗口数据排序取 TopN,这样的需要就必须使用ProcessWindowFunction。
//每隔5秒统计每个基站的日志数量
data.map(stationLog=>((stationLog.sid,1)))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.process(new
ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String,
Int)], out: Collector[(String, Int)]): Unit = {
println("-------")
out.collect((key,elements.size))
}
})
.print()
第七节 Flink Time 详解
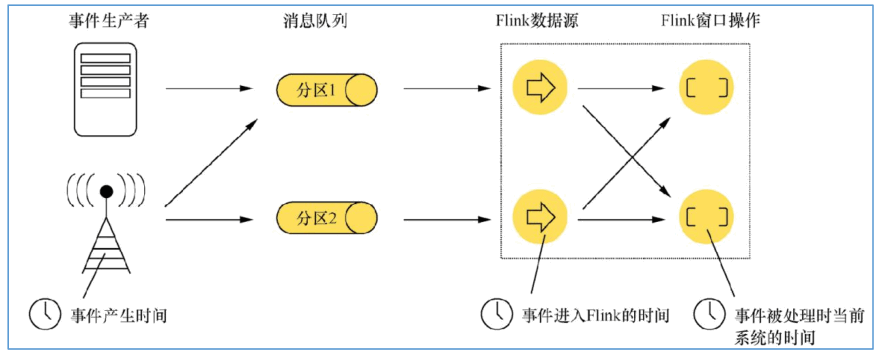
对于流式数据处理,最大的特点是数据上具有时间的属性特征,Flimk 根据时间产生的位置不同,将时间区分为三种时间语义,分别为事件生成时间(Event Time)、事件接入时间(Ingestion Time)和事件处理时间(Processing Time)。
- Event Time:事件产生的时间,它通常由事件中的时间戳描述。
- Ingestion Time:事件进入 Flink 的时间。
- Processing Time:事件被处理时当前系统的时间。
1. 时间语义 Time
数据从终端产生,或者从系统中产生的过程中生成的时间为事件生成时间,当数据经过消息中间件传入到 Flink 系统中,在 DataSource 中接入的时候会生成事件接入时间,当数据在 Flink 系统中通过各个算子实例执行转换操作的过程中,算子实例所在系统的时间为数据处理时间。Flink 已经支持这三种类型时间概念,用户能够根据需要选择时间类型作为对流式数据的依据,这种情况极大地增强了对事件数据处理的灵活性和准确性。
1) 设置时间语义
在 Flink 中默认情况下使用是 Process Time 时间语义,如果用户选择使用 Event Time或 者 Ingestion Time 语 义 , 则 需 要 在 创 建 的 StreamExecutionEnvironment 中 调 用setStreamTimeCharacteristic() 方 法 设 定 系 统 的 时 间 概 念 , 如 下 代 码 使 用TimeCharacteristic.EventTime 作为系统的时间语义:
//设置使用EventTime
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//设置使用IngestionTime
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
注意:但是上面的代码还没有指定具体的时间到底是哪个字段,所以后面还有代码需要设置!
2. WaterMark水位线
在使用 EventTime 处理 Stream 数据的时候会遇到数据乱序的问题,流处理从 Event(事件)产生,流经 Source,再到 Operator,这中间需要一定的时间。虽然大部分情况下,传输到 Operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络延迟等原因而导致乱序的产生,特别是使用 Kafka 的时候,多个分区之间的数据无法保证有序。因此,在进行 Window 计算的时候,不能无限期地等下去,必须要有个机制来保证在特定的时间后,必须触发 Window 进行计算,这个特别的机制就是 Watermark(水位线)。Watermark 是用于处理乱序事件的。
1) Watermark原理
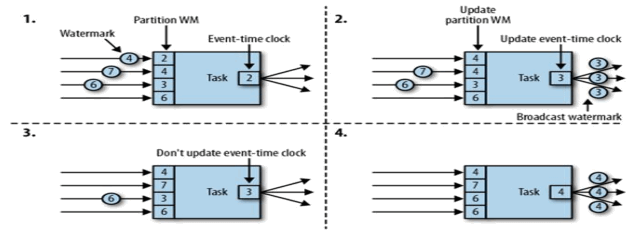
在 Flink 的窗口处理过程中,如果确定全部数据到达,就可以对 Window 的所有数据做窗口计算操作(如汇总、分组等),如果数据没有全部到达,则继续等待该窗口中的数据全部到达才开始处理。这种情况下就需要用到水位线(WaterMarks)机制,它能够衡量数据处理进度(表达数据到达的完整性),保证事件数据(全部)到达 Flink 系统,或者在乱序及延迟到达时,也能够像预期一样计算出正确并且连续的结果。当任何 Event 进入到 Flink系统时,会根据当前最大事件时间产生 Watermarks 时间戳。
那么 Flink 是怎么计算 Watermak 的值呢?
Watermark = = 进入 k Flink 的最大的事件时间( mxtEventTime )— — 指定的延迟时间(t )
那么有 Watermark 的 Window 是怎么触发窗口函数的呢?
如果有窗口的停止时间等于或者小 当时的 warkmark,那么这个窗口被触发执行。
注意:Watermark 本质可以理解成一个延迟触发机制。
Watermark 的使用存在三种情况:
本来就有序的 Stream 中的 Watermark
如果数据元素的事件时间是有序的,Watermark 时间戳会随着数据元素的事件时间按顺序生成,此时水位线的变化和事件时间保持一直(因为既然是有序的时间,就不需要设置延迟了,那么 t 就是 0。所以 watermark=maxtime-0 = maxtime),也就是理想状态下的水位线。当 Watermark 时间大于 Windows 结束时间就会触发对 Windows 的数据计算,以此类推,下一个 Window 也是一样。

乱序事件中的 Watermark
现实情况下数据元素往往并不是按照其产生顺序接入到 Flink 系统中进行处理,而频繁出现乱序或迟到的情况,这种情况就需要使用 Watermarks 来应对。比如下图,设置延迟时间 t 为 2

并行数据流中的 Watermark
在多并行度的情况下,Watermark 会有一个对齐机制,这个对齐机制会取所有 Channel中最小的 Watermark。
2) 引入Watermark和EventTime
有序数据流中引入 Watermark 和 EventTime
对于有序的数据,代码比较简洁,主要需要从源 Event 中抽取 EventTime。
//读取文件数据
val data = streamEnv.socketTextStream("hadoop101",8888)
.map(line=>{
var arr =line.split(",")
new
StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.to
Long)
})
//根据EventTime有序的数据流
data.assignAscendingTimestamps(_.callTime)
//StationLog对象中抽取EventTime就是callTime属性
乱序序数据流中引入 Watermark 和 EventTime
对于乱序数据流,有两种常见的引入方法:周期性和间断性。
With Periodic(周期性的) Watermark
周期性地生成 Watermark 的生成,默认是 100ms。每隔 N 毫秒自动向流里注入一个Watermark,时间间隔由 streamEnv.getConfig.setAutoWatermarkInterval()决定。最简单的写法如下:
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
import org.apache.flink.streaming.api.scala._
val stream = env.socketTextStream("tuge1", 6666)
//读取文件数据
val data = stream.map(line => {
val arr = line.split(",")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
}) //第一种设置方法
//如果EventTime是乱序的,则考虑设置一个延迟时间
//这里设置的延迟时间为3秒
data.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(3)) {
override def extractTimestamp(t: StationLog): Long = t.callTime
})
//第二种设置方法 (自定义设置)
//data.assignTimestampsAndWatermarks(new MyCustomerPeriodicWaterMark(3000L)) } class MyCustomerPeriodicWaterMark(delay: Long) extends AssignerWithPeriodicWatermarks[StationLog] {
var maxTime: Long = 0 override def getCurrentWatermark: Watermark = {
new watermark.Watermark(maxTime - delay)
} override def extractTimestamp(element: StationLog, l: Long): Long = {
maxTime = maxTime.max(element.callTime) //通过比较找出最大时间
element.callTime
}
}
With Punctuated(间断性的) Watermark
间断性的生成 Watermark 一般是基于某些事件触发 Watermark 的生成和发送,比如:在我们的基站数据中,有一个基站的 CallTime 总是没有按照顺序传入,其他基站的时间都是正常的,那我们需要对这个基站来专门生成 Watermark。
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
import org.apache.flink.streaming.api.scala._
val stream = env.socketTextStream("tuge1", 6666)
//读取文件数据
val data = stream.map(line => {
val arr = line.split(",")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
}) //只有station_1的EventTime是无序的,所有只需要针对station_1做处理
//当前代码设置station_1基站的延迟时间为3秒
data.assignTimestampsAndWatermarks(new MyCustomerPunctuatedWaterMark(3000L)) } class MyCustomerPunctuatedWaterMark(delay: Long) extends AssignerWithPunctuatedWatermarks[StationLog] {
var maxTime: Long = 0 override def checkAndGetNextWatermark(element: StationLog, l: Long): Watermark = {
if (element.sid.equals("station_1")) {
maxTime = maxTime.max(element.callTime)
new Watermark(maxTime - delay)
} else {
return null
} } override def extractTimestamp(element: StationLog, l: Long): Long = { element.callTime //抽取eventtime的值
}
}
3) Watermark案例
需求:每隔 5 秒中统计一下最近 10 秒内每个基站中通话时间最长的一次通话发生的呼叫时间、主叫号码,被叫号码,通话时长。并且还得告诉我到底是哪个时间范围(10 秒)内的。
注意:基站日志数据传入的时候是无序的,通过观察发现时间最多延迟了 3 秒。
/**
* WaterMark案例
* 每隔5秒中统计一下最近10秒内每个基站中通话时间最长的一次通话发生的
* 呼叫时间、主叫号码,被叫号码,通话时长。
* 并且还得告诉我到底是哪个时间范围(10秒)内的。
*
*/
object WaterMarkCase {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //设置以EventTime时间作为延迟处理
env.setParallelism(1)
import org.apache.flink.streaming.api.scala._
val stream = env.socketTextStream("tuge1", 6666)
//读取文件数据
val data = stream.map(line => {
val arr = line.split(",")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(3)) {
//引入Watermark数据延迟处理机制
override def extractTimestamp(element: StationLog): Long = element.callTime
})
data.keyBy(_.sid)
.timeWindow(Time.seconds(10), Time.seconds(5))
.reduce(new MaxTimeReduce, new ReturnMaxTime)
.print()
env.execute()
}
class MaxTimeReduce extends ReduceFunction[StationLog] {
override def reduce(t: StationLog, t1: StationLog): StationLog = {
//通话时间比较
if (t.duration > t1.duration) t else t1
}
}
//将上一个方法比较的最后结果传入进行打印
class ReturnMaxTime extends WindowFunction[StationLog, String, String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[StationLog], out: Collector[String]): Unit = {
var sb = new StringBuilder
sb.append("窗口范围是:").append(window.getStart).append("----").append(window.getEnd)
sb.append("\n")
sb.append("通话日志:").append(input.iterator.next())
out.collect(sb.toString())
}
}
}
3.Window的allowedLateness
基于 Event-Time 的窗口处理流式数据,虽然提供了 Watermark 机制,却只能在一定程度上解决了数据乱序的问题。但在某些情况下数据可能延时会非常严重,即使通过Watermark 机制也无法等到数据全部进入窗口再进行处理。Flink 中默认会将这些迟到的数据做丢弃处理,但是有些时候用户希望即使数据延迟到达的情况下,也能够正常按照流程处理并输出结果,此时就需要使用 Allowed Lateness 机制来对迟到的数据进行额外的处理。
通常情况下用户虽然希望对迟到的数据进行窗口计算,但并不想将结果混入正常的计算流程中,例如用户大屏数据展示系统,即使正常的窗口中没有将迟到的数据进行统计,但为了保证页面数据显示的连续性,后来接入到系统中迟到数据所统计出来的结果不希望显示在屏幕上,而是将延时数据和结果存储到数据库中,便于后期对延时数据进行分析。对于这种情况需要借助 Side Output 来处理,通过使用 sideOutputLateData(OutputTag)来标记迟到数据计算的结果,然后使用 getSideOutput(lateOutputTag)从窗口结果中获取lateOutputTag 标签对应的数据,之后转成独立的 DataStream 数据集进行处理,创建late-data 的 OutputTag,再通过该标签从窗口结果中将迟到数据筛选出来。
注意:如果有 k Watermark 同时也有 d Allowed Lateness是:k watermark < < w end-of-window + +
案例:每隔 5 秒统计最近 10 秒,每个基站的呼叫数量。要求:
1、每个基站的数据会存在乱序
2、大多数数据延迟 2 秒到,但是有些数据迟到时间比较长
3、迟到时间超过两秒的数据不能丢弃,放入侧流
package vip.shuai7boy.flink.time
import org.apache.flink.api.common.functions.AggregateFunction
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import vip.shuai7boy.flink.StationLog
/**
* 针对数据迟到比较长的数据进行处理
* 案例:
* 每隔5秒统计最近10秒 每个基站的呼叫数量
* 1.每个基站的数据基本乱序
* 2.大多迟到两秒,某些迟到比较长
* 3.迟到超过两秒的数据不要丢弃,放入测流
*/
object LataDataOnWindow {
def main(args: Array[String]): Unit = {
//初始化Flink Streaming(流计算)上下文环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
//读取文件数据
val data = env.socketTextStream("tuge1", 6666)
.map(line => {
val arr = line.split(",")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(2)) { //引入WaterMark
override def extractTimestamp(element: StationLog): Long = element.callTime
})
val lateTag = new OutputTag[StationLog]("late")
val result = data.keyBy(_.sid)
.timeWindow(Time.seconds(10), Time.seconds(5))
//注意:只要符合watermark < end-of-window + allowedLateness之内到达的数
//据,都会被再次触发窗口的计算
//超出之外的数据会被放到测流
.allowedLateness(Time.seconds(4)) //允许数据迟到4秒
.sideOutputLateData(lateTag)
.aggregate(new CallTimeAggregate, new ResultCallInfo)
result.getSideOutput(lateTag).print("迟到数据")
result.print("没迟到数据")
env.execute("每隔5秒统计最近10秒 每个基站的呼叫数量")
}
class CallTimeAggregate extends AggregateFunction[StationLog, Long, Long] {
override def createAccumulator(): Long = 0
override def add(in: StationLog, acc: Long): Long = acc + 1
override def getResult(acc: Long): Long = acc
override def merge(acc: Long, acc1: Long): Long = acc + acc1
}
class ResultCallInfo extends WindowFunction[Long, String, String, TimeWindow] {
override def apply(key: String, window: TimeWindow, input: Iterable[Long], out: Collector[String]): Unit = {
var sb = new StringBuilder
sb.append("窗口间隔是:").append(window.getStart).append("---").append(window.getEnd)
sb.append("\n")
sb.append("当前基站是:").append(key)
sb.append("呼叫数量:").append(input.iterator.next())
out.collect(sb.toString())
}
}
}
第八节 TableAPI和Flink SQL
在Flink1.8架构里,如果用户需要流计算,批处理的场景下,用户需要维护两套业务代码,开发人员也要维护两套技术栈,非常不方便。Flink很早就设想将批数据看成一个有界流数据,将批处理看成流计算的一个特例,从而实现流批统一,阿里巴巴的Blink团队在这方面做了大量的工作,已经实现了Table API&Sql层的流批统一。阿里巴巴已经将Blink开源回馈给Blink社区。

1. 开发环境构建
从1.9及以后,Table 模块迎来了核心架构的升级,引入了阿里巴巴 Blink 团队贡献的诸多功能,取名叫: Blink Planner。在使用 Table API 和 SQL 开发 Flink 应用之前,通过添加 Maven 的依赖配置到项目中,在本地工程中引入相应的依赖库,库中包含了 TableAPI 和 SQL 接口。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>1.10.1</version>
</dependency>
2. TableEnvironment
和 DataStream API 一样,Table API 和 SQL 中具有相同的基本编程模型。首先需要构建对应的 TableEnviroment 创建关系型编程环境,才能够在程序中使用 Table API 和 SQL来编写应用程序,另外 Table API 和 SQL 接口可以在应用中同时使用,Flink SQL 基于 ApacheCalcite 框架实现了 SQL 标准协议,是构建在 Table API 之上的更高级接口。
首先需要在环境中创建 TableEnvironment 对象,TableEnvironment 中提供了注册内部表、执行 Flink SQL 语句、注册自定义函数等功能。根据应用类型的不同,TableEnvironment创建方式也有所不同,但是都是通过调用 create()方法创建。
流计算环境下创建 TableEnviroment:
//初始化Flink的Streaming(流计算)上下文执行环境
val streamEnv: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
//初始化Table API的上下文环境
val tableEvn =StreamTableEnvironment.create(streamEnv)
在 Flink1.9 之后由于引入了 Blink Planner,还可以为:
val bsSettings =
EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val bsTableEnv = StreamTableEnvironment.create(streamEnv, bsSettings)
注意:Flink 社区完整保留原有 Flink Planner (Old Planner),同时又引入了新的Blink Planner,用户可以自行选择使用 Old Planner 还是 Blink Planner。官方推荐暂时使用 Old Planner。
3. Table API
在 Flink 中创建一张表有两种方法:
- 从一个文件中导入表结构(Structure)(常用于批计算)(静态)
- 从 DataStream 或者 DataSet 转换成 Table (动态)
1) 创建 Table
Table API 中已经提供了 TableSource 从外部系统获取数据,例如常见的数据库、文件系统和 Kafka 消息队列等外部系统。
从文件中创建 Table(静态表)
Flink 允许用户从本地或者分布式文件系统中读取和写入数据,在 Table API 中可以通过 CsvTableSource 类来创建,只需指定相应的参数即可。但是文件格式必须是 CSV 格式的。其 他 文 件 格 式 也 支 持 ( 在 Flink 还 有 Connector 的 来 支 持 其 他 格 式 或 者 自 定 义TableSource)。
//创建CSV格式的TableSource
val fileSource = new CsvTableSource("/station.log",
Array[String]("f1","f2","f3","f4","f5","f6"),
Array(Types.STRING,Types.STRING,Types.STRING,Types.STRING,Types.LONG,T
ypes.LONG))
//注册Table,表名为t_log
tableEvn.registerTableSource("t_log",fileSource)
//转换成Table对象,并打印表结构
tableEvn.scan("t_log").printSchema()
注意:本案例的最后面不要 streamEnv.execute()
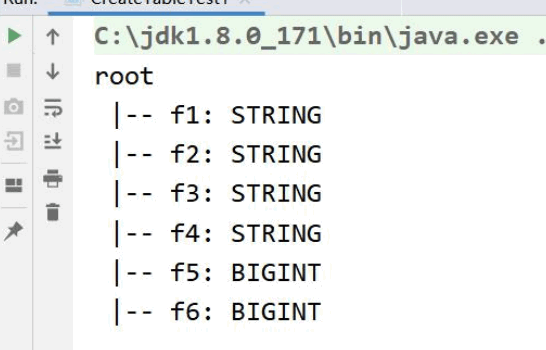
从 DataStream 中创建 Table(动态表)
前面已经知道 Table API 是构建在 DataStream API 和 DataSet API 之上的一层更高级的抽象,因此用户可以灵活地使用 Table API 将 Table 转换成 DataStream 或 DataSet 数据集,也可以将 DataSteam 或 DataSet 数据集转换成 Table,这和 Spark 中的 DataFrame 和 RDD的关系类似。
//读取数据
val data = streamEnv.readTextFile(getClass.getResource("/station.log").getPath)
// val data = streamEnv.socketTextStream("tuge1",8888)
.map(line=>{
var arr =line.split(",")
new
StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.to
Long)
})
//吧DataStream对象变成一个Table
tableEvn.registerDataStream("t_station_log",data) //注册表
val table: Table = tableEvn.scan("t_station_log")
table.printSchema() //打印表结构
streamEnv.execute()
还可以用第二种,如果纯粹使用Table API推荐使用第二种,如果使用SQL推荐第一种。
//读取数据
val data = streamEnv.readTextFile(getClass.getResource("/station.log").getPath)
// val data = streamEnv.socketTextStream("hadoop101",8888)
.map(line=>{
var arr =line.split(",")
new
StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.to
Long)
})
//吧DataStream对象变成一个Table
val table: Table = tableEvn.fromDataStream(data) //直接变成table对象
table.printSchema() //打印表结构
streamEnv.execute()
2) 修改 Table 中字段名
Flink 支持把自定义 POJOs 类的所有 case 类的属性名字变成字段名,也可以通过基于字段偏移位置和字段名称两种方式重新修改:
//导入table库中的隐式转换
import org.apache.flink.table.api.scala._
// 基于位置重新指定字段名称为"field1", "field2", "field3"
val table = tStreamEnv.fromDataStream(stream, 'field1, 'field2, 'field3)
// 将DataStream转换成Table,并且将字段名称重新成别名
val table: Table = tStreamEnv.fromDataStream(stream, 'rowtime as 'newTime, 'id as
'newId,'variable as 'newVariable)
注意:要导入隐式转换。如果使用as修改字段,必须修改表中所有字段。
3) 查询和过滤
在 Table 对象上使用 select 操作符查询需要获取的指定字段,也可以使用 filter 或where 方法过滤字段和检索条件,将需要的数据检索出来。
//查询Table
val table = tableEnv.fromDataStream(stream)
// tableEnv.toAppendStream[Row](
// table.select('sid,'callIn,'callType)
// ).print()
//过滤Table
// tableEnv.toAppendStream[Row](
// table.filter('callType==="success")
// // table.where('callType==="success")
// ).print()
其中 toAppendStream 函数是吧 Table 对象转换成 DataStream 对象。
4)分组聚合
//分组聚合(toRetractStream相对上面的toAppendStream多了一些true,false状态记录)
// tableEnv.toRetractStream[Row](
// table.groupBy('sid)
// .select('sid, 'sid.count as 'logCount)
// ).filter(_._1==true).print()
5) UDF 自定义的函数
用户可以在 Table API 中自定义函数类,常见的抽象类和接口是:
- ScalarFunction
- TableFunction
- AggregateFunction
- TableAggregateFunction
案例:使用 Table 完成基于流的 WordCount
package vip.shuai7boy.flink.tabelApiAndSql
import org.apache.flink.api.common.typeinfo.{TypeInformation, Types}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.table.functions.TableFunction
import org.apache.flink.types.Row
/**
* 用户自定义函数
* 可以在Table API中自定义函数,常见的抽象类和接口是:
* ScalarFunciton
* TableFunction\
* AggregateFunction
* TableAggregateFunction
*/
object TableAPITest {
def main(args: Array[String]): Unit = {
//创建Stream Flink环境
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
//创建Table API环境
val strEnvSet = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv = StreamTableEnvironment.create(streamEnv, strEnvSet)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
//从socket获取数据源
val stream = streamEnv.socketTextStream("tuge1", 6666)
//将DataStream转换为Table
val table = tableEnv.fromDataStream(stream, 'words)
val my_flat = new MyFlatMapFunction
val table1 = table.flatMap(my_flat('words)).as('word, 'count)
.groupBy('word)
.select('word, 'count.count as 'c)
tableEnv.toRetractStream[Row](table1).filter(_._1 == true).print()
streamEnv.execute("wc_defined")
}
//自定义UDF
class MyFlatMapFunction extends TableFunction[Row] {
override def getResultType: TypeInformation[Row] = {
Types.ROW(Types.STRING, Types.INT)
}
//函数主体
def eval(str: String) = {
str.split(" ").foreach(line => {
var row = new Row(2)
row.setField(0, line)
row.setField(1, 1)
collect(row)
}
)
}
}
}
6) Window
Flink 支持 ProcessTime、EventTime 和 IngestionTime 三种时间概念,针对每种时间概念,Flink Table API 中使用 Schema 中单独的字段来表示时间属性,当时间字段被指定后,就可以在基于时间的操作算子中使用相应的时间属性。
在 Table API 中通过使用.rowtime 来定义 EventTime 字段,在 ProcessTime 时间字段名后使用.proctime 后缀来指定 ProcessTime 时间属性。
案例:统计最近 5 秒钟,每个基站的呼叫数量
package vip.shuai7boy.flink.tabelApiAndSql
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.types.Row
import vip.shuai7boy.flink.StationLog
/**
* SQL中滚动窗口
*/
object SqlTumpWindow {
def main(args: Array[String]): Unit = {
//初始化环境
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
val setting = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv = StreamTableEnvironment.create(streamEnv, setting)
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(1)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
//读取数据
val stream = streamEnv.socketTextStream("tuge1", 6666)
.map(line => {
val arr = line.split(",")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
.assignTimestampsAndWatermarks( //引入Watermark
new
BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(2)) { //延迟2秒
override def extractTimestamp(element: StationLog) = {
element.callTime
}
})
//滚动窗口,窗口大小为5秒,需求:统计每5秒内,每个基站的成功通话时长总和
tableEnv.registerDataStream("t_station_log", stream, 'sid, 'callOut, 'callIn, 'callType, 'callTime.rowtime, 'duration)
var result = tableEnv.sqlQuery(
"select sid ,sum(duration) from t_station_log where callType='success' group by tumble(callTime,interval '5' second),sid"
)
tableEnv.toRetractStream[Row](result)
.filter(_._1 == true)
.print()
tableEnv.execute("sql_api")
}
}
上面的案例是滚动窗口,如果是滑动窗口也是一样,代码如下:
//滑动窗口,窗口大小为:10秒,滑动步长为5秒 :第一种写法
table.window(Slide over 10.second every 5.second on 'callTime as 'window)
//滑动窗口第二种写法
table.window(Slide.over("10.second").every("5.second").on("callTime").as("window"))
4. Flink 的 的 SQL 使用
SQL 作为 Flink 中提供的接口之一,占据着非常重要的地位,主要是因为 SQL 具有灵活和丰富的语法,能够应用于大部分的计算场景。Flink SQL 底层使用 Apache Calcite 框架,将标准的 Flink SQL 语句解析并转换成底层的算子处理逻辑,并在转换过程中基于语法规则层面进行性能优化,比如谓词下推等。另外用户在使用 SQL 编写 Flink 应用时,能够屏蔽底层技术细节,能够更加方便且高效地通过SQL语句来构建Flink应用。Flink SQL构建在TableAPI 之上,并含盖了大部分的 Table API 功能特性。同时 Flink SQL 可以和 Table API 混用,Flink 最终会在整体上将代码合并在同一套代码逻辑中。
1) 执行 SQL
以下通过实例来了解 Flink SQL 整体的使用方式。
案例:统计每个基站通话成功的通话时长总和。
package vip.shuai7boy.flink.tabelApiAndSql
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.EnvironmentSettings
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.types.Row
import vip.shuai7boy.flink.StationLog
/**
* 使用SQL操作Flink
* 统计每个基站的日志数量1
*/
object SqlTest1 {
def main(args: Array[String]): Unit = {
//初始化环境
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
val setting = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv = StreamTableEnvironment.create(streamEnv, setting)
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(1)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
//读取数据
val stream = streamEnv.socketTextStream("tuge1", 6666)
.map(line => {
val arr = line.split(",")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//统计每个基站的日志数量
val table = tableEnv.fromDataStream(stream)
val result = tableEnv.sqlQuery(s"select sid,count(*) from $table where callType='success' group by sid")
tableEnv.toRetractStream[Row](result).filter(_._1 == true).print()
tableEnv.execute("sql")
}
}
另外可以有第二种写法:
//第二种sql调用方式
tableEvn.registerDataStream("t_station_log",data)
val result: Table = tableEvn.sqlQuery("select sid ,sum(duration) as sd from
t_station_log where callType='success' group by sid")
tableEvn.toRetractStream[Row](result)
.filter(_._1==true)
.print()
2) SQL 中的 Window
Flink SQL 也支持三种窗口类型,分别为 Tumble Windows、HOP Windows 和 SessionWindows,其中 HOP Windows 对应 Table API 中的 Sliding Window,同时每种窗口分别有相应的使用场景和方法。
案例:统计最近5秒钟,每个基站的呼叫数量:
package vip.shuai7boy.flink.tabelApiAndSql.window
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.{EnvironmentSettings, Slide, Tumble}
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.types.Row
import vip.shuai7boy.flink.StationLog
/**
* 使用SQL实现滚动窗口
* 统计最近5秒钟,每个基站的呼叫数量
*
*/
object TableAPITest {
def main(args: Array[String]): Unit = {
//初始化环境
val streamEnv = StreamExecutionEnvironment.getExecutionEnvironment
val setting = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build()
val tableEnv = StreamTableEnvironment.create(streamEnv, setting)
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(1)
//导入隐式转换
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
//读取数据
val stream = streamEnv.socketTextStream("tuge1", 6666)
.map(line => {
val arr = line.split(",")
StationLog(arr(0).trim, arr(1).trim, arr(2).trim, arr(3).trim, arr(4).trim.toLong, arr(5).trim.toLong)
})
//设置water mark
.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.seconds(3)) {
override def extractTimestamp(element: StationLog): Long = element.callTime
})
val table = tableEnv.fromDataStream(stream, 'sid, 'callOut, 'callIn, 'callType, 'callTime.rowtime)
//滚动窗口第一种
// val result = table.window(Tumble over 5.second on 'callTime as 'window)
//滚动窗口第二种
val result = table.window(Tumble.over("5.second").on("callTime").as("window"))
.groupBy('window, 'sid)
.select('sid, 'window.start, 'window.end, 'window.rowtime, 'sid.count)
//滑动窗口第一种
//table.window(Slide over.10.second every 5.second on 'callTime as 'window)
//滑动窗口第二种
// table.window(Slide.over("10.second").every("5.second").on("callTime").as("window"))
tableEnv.toRetractStream[Row](result).print()
tableEnv.execute("sql")
}
}
第九节 Flink 的复杂事件处理 CEP
复杂事件处理(CEP)是一种基于流处理的技术,将系统数据看作不同类型的事件,通过分析事件之间的关系,建立不同的事件关系序列库,并利用过滤、关联、聚合等技术,最终由简单事件产生高级事件,并通过模式规则的方式对重要信息进行跟踪和分析,从实时数据中发掘有价值的信息。复杂事件处理主要应用于防范网络欺诈、设备故障检测、风险规避和智能营销等领域。Flink 基于 DataStrem API 提供了 FlinkCEP 组件栈,专门用于对复杂事件的处理,帮助用户从流式数据中发掘有价值的信息。
1.CEP相关概念
1) 配置依赖
在使用 FlinkCEP 组件之前,需要将 FlinkCEP 的依赖库引入项目工程中。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep-scala_2.12</artifactId>
<version>1.10.0</version>
</dependency>
2) 事件定义
简单事件:简单事件存在于现实场景中,主要的特点为处理单一事件,事件的定义可以直接观察出来,处理过程中无须关注多个事件之间的关系,能够通过简单的数据处理手段将结果计算出来。
复杂事件:相对于简单事件,复杂事件处理的不仅是单一的事件,也处理由多个事件组成的复合事件。复杂事件处理监测分析事件流(Event Streaming),当特定事件发生时来触发某些动作。
复杂事件中事件与事件之间包含多种类型关系,常见的有时序关系、聚合关系、层次关系、依赖关系及因果关系等。
2. Pattern API
FlinkCEP 中提供了 Pattern API 用于对输入流数据的复杂事件规则定义,并从事件流中抽取事件结果。包含四个步骤:
- 输入事件流的创建
- Pattern 的定义
- Pattern 应用在事件流上检测
- 选取结果
1) 模式定义
定义 Pattern 可以是单次执行模式,也可以是循环执行模式。单次执行模式一次只接受一个事件,循环执行模式可以接收一个或者多个事件。通常情况下,可以通过指定循环次数将单次执行模式变为循环执行模式。每种模式能够将多个条件组合应用到同一事件之上,条件组合可以通过 where 方法进行叠加。每个 Pattern 都是通过 begin 方法定义的:
val start = Pattern.begin[Event]("start_pattern")
下一步通过 Pattern.where()方法在 Pattern 上指定 Condition,只有当 Condition 满足之后,当前的 Pattern 才会接受事件。
start.where(_.getCallType == "success")
1.设置循环次数
对于已经创建好的 Pattern,可以指定循环次数,形成循环执行的 Pattern。
times:可以通过 times 指定固定的循环执行次数。
/指定循环触发4次
start.times(4);
//可以执行触发次数范围,让循环执行次数在该范围之内
start.times(2, 4);
optional:也可以通过 optional 关键字指定要么不触发要么触发指定的次数。
start.times(4).optional();
start.times(2, 4).optional();
greedy:可以通过 greedy 将 Pattern 标记为贪婪模式,在 Pattern 匹配成功的前提下,会尽可能多地触发。
//触发2、3、4次,尽可能重复执行
start.times(2, 4).greedy();
//触发0、2、3、4次,尽可能重复执行
start.times(2, 4).optional().greedy();
// 触发一次或者多次
start.oneOrMore();
//触发一次或者多次,尽可能重复执行
start.oneOrMore().greedy();
// 触发0次或者多次
start.oneOrMore().optional();
// 触发0次或者多次,尽可能重复执行
start.oneOrMore().optional().greedy();
timesOrMor:通过 timesOrMore 方法可以指定触发固定次数以上,例如执行两次以上。
// 触发两次或者多次
start.timesOrMore(2);
// 触发两次或者多次,尽可能重复执行
start.timesOrMore(2).greedy();
// 不触发或者触发两次以上,尽可能重复执行
start.timesOrMore(2).optional().greedy();
2.定义条件
每个模式都需要指定触发条件,作为事件进入到该模式是否接受的判断依据,当事件中的数值满足了条件时,便进行下一步操作。在 FlinkCFP 中通过 pattern.where()、pattern.or()及 pattern.until()方法来为 Pattern 指定条件,且 Pattern 条件有 SimpleConditions 及 Combining Conditions 等类型。
简单条件:Simple Condition 继承于 Iterative Condition 类,其主要根据事件中的字段信息进行判断,决定是否接受该事件。
// 把通话成功的事件挑选出来
start.where(_.getCallType == "success")
组合条件:组合条件是将简单条件进行合并,通常情况下也可以使用 where 方法进行条件的组合,默认每个条件通过 AND 逻辑相连。如果需要使用 OR 逻辑,直接使用 or 方法连接条件即可。
// 把通话成功,或者通话时长大于10秒的事件挑选出来
val start = Pattern.begin[StationLog]("start_pattern")
.where(_.callType=="success")
.or(_.duration>10)
终止条件:如果程序中使用了 oneOrMore 或者 oneOrMore().optional()方法,则必须指定终止条件,否则模式中的规则会一直循环下去,如下终止条件通过 until()方法指定。
pattern.oneOrMore.until(_.callOut.startsWith("186"))
3.模式序列
将相互独立的模式进行组合然后形成模式序列。模式序列基本的编写方式和独立模式一致,各个模式之间通过邻近条件进行连接即可,其中有严格邻近、宽松邻近、非确定宽松邻近三种邻近连接条件。
严格邻近:严格邻近条件中,需要所有的事件都按照顺序满足模式条件,不允许忽略任意不满足的模式。
val strict: Pattern[Event] = start.next("middle").where(...)
宽松邻近:在宽松邻近条件下,会忽略没有成功匹配模式条件,并不会像严格邻近要求得那么高,可以简单理解为 OR 的逻辑关系。
val relaxed: Pattern[Event, _] = start.followedBy("middle").where(...)
非确定宽松邻近:和宽松邻近条件相比,非确定宽松邻近条件指在模式匹配过程中可以忽略已经匹配的条件。
val nonDetermin: Pattern[Event, _] = start.followedByAny("middle").where(...)
除以上模式序列外,还可以定义“不希望出现某种近邻关系”:
.notNext() —— 不想让某个事件严格紧邻前一个事件发生
.notFollowedBy() —— 不想让某个事件在两个事件之间发生
注意:
1、所有模式序列必须以 .begin() 开始
2、模式序列不能以 .notFollowedBy() 结束
3、“not” 类型的模式不能被 optional 所修饰
4、此外,还可以为模式指定时间约束,用来要求在多长时间内匹配有效//指定模式在10秒内有效
pattern.within(Time.seconds(10));
2) 模式检测
调用 CEP.pattern(),给定输入流和模式,就能得到一个 PatternStream
//cep 做模式检测
val patternStream = CEP.pattern[EventLog](dataStream.keyBy(_.id),pattern)
3) 选择结果
得到 PatternStream 类型的数据集后,接下来数据获取都基于 PatternStream 进行。该数据集中包含了所有的匹配事件。目前在 FlinkCEP 中提供 select 和 flatSelect 两种方法从 PatternStream 提取事件结果事件。
1.通过 Select Funciton 抽取正常事件
可以通过在 PatternStream 的 Select 方法中传入自定义 Select Funciton 完成对匹配事件的转换与输出。其中 Select Funciton 的输入参数为 Map[String, Iterable[IN]],Map中的 key 为模式序列中的 Pattern 名称,Value 为对应 Pattern 所接受的事件集合,格式为输入事件的数据类型。
def selectFunction(pattern : Map[String, Iterable[IN]]): OUT = {
//获取pattern中的startEvent
val startEvent = pattern.get("start_pattern").get.next
//获取Pattern中middleEvent
val middleEvent = pattern.get("middle").get.next
//返回结果
OUT(startEvent, middleEvent)
}
2.通过 Flat Select Funciton 抽取正常事件
Flat Select Funciton 和 Select Function 相似,不过 Flat Select Funciton 在每次调用可以返回任意数量的结果。因为 Flat Select Funciton 使用 Collector 作为返回结果的容器,可以将需要输出的事件都放置在 Collector 中返回。
def flatSelectFn(pattern : Map[String, Iterable[IN]], collector :
Collector[OUT]) = {
//获取pattern中startEvent
val startEvent = pattern.get("start_pattern").get.next
//获取Pattern中middleEvent
val middleEvent = pattern.get("middle").get.next
//并根据startEvent的Value数量进行返回
for (i <- 0 to startEvent.getValue) {
collector.collect(OUT(startEvent, middleEvent))
}}
3.通过 Select Funciton 抽取超时事件
如果模式中有 within(time),那么就很有可能有超时的数据存在,通过 PatternStream.Select 方法分别获取超时事件和正常事件。首先需要创建 OutputTag 来标记超时事件,然后在 PatternStream.select 方法中使用 OutputTag,就可以将超时事件从 PatternStream中抽取出来。
// 通过CEP.pattern方法创建PatternStream
val patternStream: PatternStream[Event] = CEP.pattern(input, pattern)
//创建OutputTag,并命名为timeout-output
val timeoutTag = OutputTag[String]("timeout-output")
//调用PatternStream select()并指定timeoutTag
val result: SingleOutputStreamOperator[NormalEvent] =
patternStream.select(timeoutTag){
//超时事件获取
(pattern: Map[String, Iterable[Event]], timestamp: Long) =>
TimeoutEvent()//返回异常事件
} {
//正常事件获取
pattern: Map[String, Iterable[Event]] =>
NormalEvent()//返回正常事件
}
//调用getSideOutput方法,并指定timeoutTag将超时事件输出
val timeoutResult: DataStream[TimeoutEvent] =
result.getSideOutput(timeoutTag)
4) 案例
需求:从一堆的登录日志中,匹配一个恶意登录的模式(如果一个用户连续失败三次,则是恶意登录),从而找到哪些用户名是恶意登录。
package vip.shuai7boy.flink.cep
import java.util
import org.apache.flink.cep.PatternSelectFunction
import org.apache.flink.cep.scala.{CEP, PatternStream}
import org.apache.flink.cep.scala.pattern.Pattern
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
/**
* 登陆告警系统
* 从一堆日志中找到恶意登陆的用户(在10秒内登陆失败3次视为恶意登陆)
*/
case class EventLog(id: Long, userName: String, eventType: String, eventTime: Long)
object EventLog {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
import org.apache.flink.streaming.api.scala._
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream: DataStream[EventLog] = streamEnv.fromCollection(List(
new EventLog(1, "张三", "fail", 1574840003),
new EventLog(1, "张三", "fail", 1574840004),
new EventLog(1, "张三", "fail", 1574840005),
new EventLog(2, "李四", "fail", 1574840006),
new EventLog(2, "李四", "sucess", 1574840007),
new EventLog(1, "张三", "fail", 1574840008)
)).assignAscendingTimestamps(_.eventTime * 1000)
stream.print("input data")
//定义模式
val pattern1 = Pattern.begin[EventLog]("begin").where(_.eventType == "fail")
.next("next1").where(_.eventType == "fail")
.next("next2").where(_.eventType == "fail")
.within(Time.seconds(10))
//cep做模式检测
val patternStream:PatternStream[EventLog] = CEP.pattern(stream, pattern1)
//输出结果
val result = patternStream.select(new PatternSelectFunction[EventLog, String] {
override def select(map: util.Map[String, util.List[EventLog]]): String = {
val iter = map.keySet().iterator()
val e1 = map.get(iter.next()).iterator().next()
val e2 = map.get(iter.next()).iterator().next()
val e3 = map.get(iter.next()).iterator().next()
"id为:" + e1.id + ",名称为:" + e1.userName + "的用户,异常登陆时间:" + e1.eventTime + "--" + e2.eventTime + "--" +
e3.eventTime
}
})
result.print("异常信息:")
streamEnv.execute("异常登陆检测!")
}
}
第十节 Flink 性能优化
对于构建好的 Flink 集群,如何能够有效地进行集群以及任务方面的监控与优化是非常重要的,尤其对于 7*24 小时运行的生产环境。重点介绍 Checkpointing 的监控。然后通过分析各种监控指标帮助用户更好地对 Flink 应用进行性能优化,以提高 Flink 任务执行的数据处理性能和效率。
1. Checkpoint 页面监控与优化
Flink Web 页面中也提供了针对 Job Checkpointing 相关的监控信息,Checkpointing监控页面中共有 Overview、History、Summary 和 Configuration 四个页签,分别对Checkpointing 从不同的角度进行了监控,每个页面中都包含了与 Checkpointing 相关的指标。
1) Overview页签
Overview 页签中宏观地记录了 Flink 应用中 Checkpoints 的数量以及 Checkpoint 的最新记录,包括失败和完成的 Checkpoints 记录。
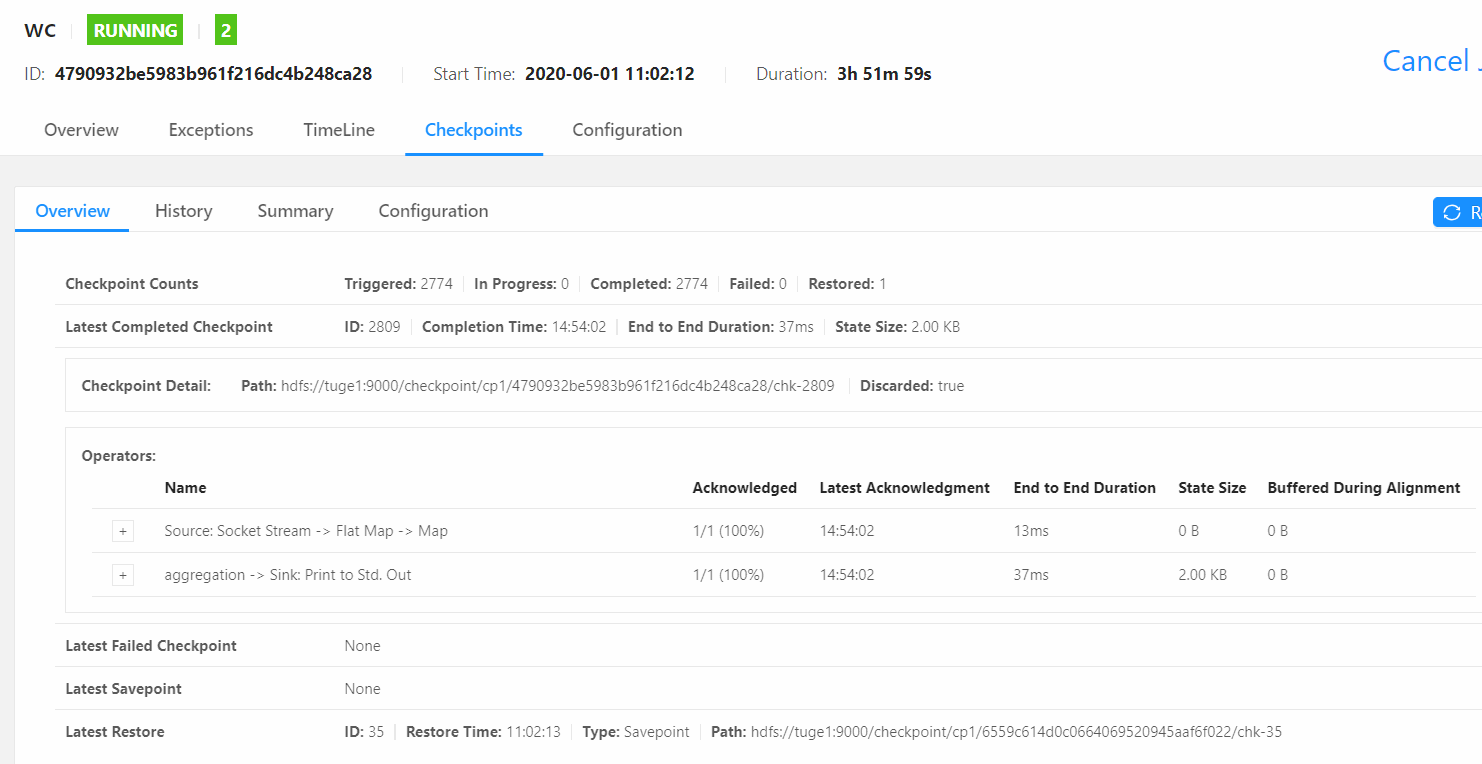
- Checkpoint Counts:包含了触发、进行中、完成、失败、重置等 Checkpoint 状态数量统计。
- Latest Completed Checkpoint:记录了最近一次完成的 Checkpoint 信息,包括结束时间,端到端时长,状态大小等。
- Latest Failed Checkpoint:记录了最近一次失败的 Checkpoint 信息。
- Latest Savepoint:记录了最近一次 Savepoint 触发的信息。
- Latest Restore:记录了最近一次重置操作的信息,包括从 Checkpoint 和 Savepoint两种数据中重置恢复任务。
2) Configuration页签
Configuration 页签中包含 Checkpoints 中所有的基本配置,具体的配置解释如下:

- Checkpointing Mode:标记 Checkpointing 是 Exactly Once 还是 At Least Once 的模式。
- Interval: Checkpointing 触 发 的 时 间 间 隔 , 时 间 间 隔 越 小 意 味 着 越 频 繁 的Checkpointing。
- Timeout: Checkpointing 触发超时时间,超过指定时间 JobManager 会取消当次Checkpointing,并重新启动新的 Checkpointing。
- Minimum Pause Between Checkpoints:配置两个 Checkpoints 之间最短时间间隔,当上一次 Checkpointing 结束后,需要等待该时间间隔才能触发下一次 Checkpoints,避免触发过多的 Checkpoints 导致系统资源被消耗。
- Persist Checkpoints Externally:如果开启 Checkpoints,数据将同时写到外部持久化存储中。
2. Flink内存优化
在大数据领域,大多数开源框架(Hadoop、Spark、Storm)都是基于 JVM 运行,但是JVM 的内存管理机制往往存在着诸多类似 OutOfMemoryError 的问题,主要是因为创建过多的对象实例而超过 JVM 的最大堆内存限制,却没有被有效回收掉,这在很大程度上影响了系统的稳定性,尤其对于大数据应用,面对大量的数据对象产生,仅仅靠 JVM 所提供的各种垃圾回收机制很难解决内存溢出的问题。在开源框架中有很多框架都实现了自己的内存管理,例如 Apache Spark 的 Tungsten 项目,在一定程度上减轻了框架对 JVM 垃圾回收机制的依赖,从而更好地使用 JVM 来处理大规模数据集。
Flink 也基于 JVM 实现了自己的内存管理,将 JVM 根据内存区分为 Unmanned Heap、FlinkManaged Heap、Network Buffers 三个区域。在 Flink 内部对 Flink Managed Heap 进行管理,在启动集群的过程中直接将堆内存初始化成 Memory Pages Pool,也就是将内存全部以二进制数组的方式占用,形成虚拟内存使用空间。新创建的对象都是以序列化成二进制数据的方式存储在内存页面池中,当完成计算后数据对象 Flink 就会将 Page 置空,而不是通过JVM 进行垃圾回收,保证数据对象的创建永远不会超过 JVM 堆内存大小,也有效地避免了因为频繁 GC 导致的系统稳定性问题。
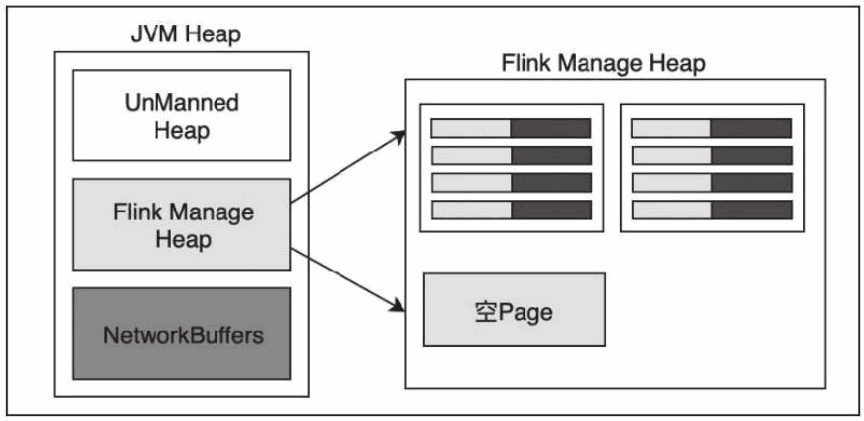
1) JobManager配置
JobManager 在 Flink 系统中主要承担管理集群资源、接收任务、调度 Task、收集任务状态以及管理 TaskManager 的功能,JobManager 本身并不直接参与数据的计算过程中,因此 JobManager 的内存配置项不是特别多,只要指定 JobManager 堆内存大小即可。
jobmanager.heap.size:设定JobManager堆内存大小,默认为1024MB。
2) TaskManager配置
TaskManager作为Flink集群中的工作节点,所有任务的计算逻辑均执行在TaskManager之上,因此对 TaskManager 内存配置显得尤为重要,可以通过以下参数配置对 TaskManager进行优化和调整。对应的官方文档是:
- taskmanager.heap.size:设定 TaskManager 堆内存大小,默认值为 1024M,如果在 Yarn的集群中,TaskManager 取决于 Yarn 分配给 TaskManager Container 的内存大小,且arn 环境下一般会减掉一部分内存用于 Container 的容错。
- taskmanager.jvm-exit-on-oom:设定 TaskManager 是否会因为 JVM 发生内存溢出而停止,默认为 false,当 TaskManager 发生内存溢出时,也不会导致 TaskManager 停止。
- taskmanager.memory.size:设定 TaskManager 内存大小,默认为 0,如果不设定该值将会使用 taskmanager.memory.fraction 作为内存分配依据。
- taskmanager.memory.fraction:设定 TaskManager 堆中去除 Network Buffers 内存后的内存分配比例。该内存主要用于 TaskManager 任务排序、缓存中间结果等操作。例如,如果设定为 0.8,则代表 TaskManager 保留 80%内存用于中间结果数据的缓存,剩下 20%的 内 存 用 于 创 建 用 户 定 义 函 数 中 的 数 据 对 象 存 储 。 注 意 , 该 参 数 只 有 在taskmanager.memory.size 不设定的情况下才生效。
- taskmanager.memory.off-heap:设置是否开启堆外内存供 Managed Memory 或者Network Buffers 使用。
- taskmanager.memory.preallocate:设置是否在启动 TaskManager 过程中直接分配TaskManager 管理内存。
- taskmanager.numberOfTaskSlots:每个 TaskManager 分配的 slot 数量。
3. Flink的网络缓存优化
Flink 将 JVM 堆内存切分为三个部分,其中一部分为 Network Buffers 内存。NetworkBuffers 内存是 Flink 数据交互层的关键内存资源,主要目的是缓存分布式数据处理过程中的输入数据。。通常情况下,比较大的 Network Buffers 意味着更高的吞吐量。如果系统出现“Insufficient number of network buffers”的错误,一般是因为 Network Buffers配置过低导致,因此,在这种情况下需要适当调整 TaskManager 上 Network Buffers 的内存大小,以使得系统能够达到相对较高的吞吐量。
目前 Flink 能够调整 Network Buffer 内存大小的方式有两种:一种是通过直接指定Network Buffers 内存数量的方式,另外一种是通过配置内存比例的方式
1) 设定 Network Buffer 内存数量(过时了)
2) 设定 Network 内存比例
从 1.3 版本开始,Flink 就提供了通过指定内存比例的方式设置 Network Buffer 内存大小。
- taskmanager.network.memory.fraction: JVM 中用于 Network Buffers 的内存比例。
- taskmanager.network.memory.min: 最小的 Network Buffers 内存大小,默认为 64MB。
- taskmanager.network.memory.max: 最大的 Network Buffers 内存大小,默认 1GB。
- taskmanager.memory.segment-size: 内存管理器和 Network 栈使用的 Buffer 大小,默认为 32KB。
入门大数据---Flink学习总括的更多相关文章
- 入门大数据---Flink核心概念综述
一.Flink 简介 Apache Flink 诞生于柏林工业大学的一个研究性项目,原名 StratoSphere .2014 年,由 StratoSphere 项目孵化出 Flink,并于同年捐赠 ...
- 入门大数据---Flink开发环境搭建
一.安装 Scala 插件 Flink 分别提供了基于 Java 语言和 Scala 语言的 API ,如果想要使用 Scala 语言来开发 Flink 程序,可以通过在 IDEA 中安装 Scala ...
- 入门大数据---Scala学习
Scala是什么? Scala是一种基于函数式编程和面向对象的高级语言.它开发了Spark等大型应用.它和Java有效集成,底层也是支持JVM的. 它有六大特性: 无缝JAVA互操作 Scala在JV ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- 布客·ApacheCN 编程/后端/大数据/人工智能学习资源 2020.11
公告 我们始终与所有创作者站在一起,为创作自由而战.我们还会提供一切必要的技术支持. 我们全力支持科研开源(DOCX)计划.希望大家了解这个倡议,把这个倡议与自己的兴趣点结合,做点力所能及的事情. 我 ...
- 布客·ApacheCN 编程/后端/大数据/人工智能学习资源 2020.9
公告 ApacheCN 项目的最终目标:五年内备份并翻译 Github 上的所有教程(其实快被我们啃完了,剩下的不多了). 警告各位培训班:对 ApacheCN 宣传文章的举报,也将视为对 Apach ...
- 布客·ApacheCN 编程/后端/大数据/人工智能学习资源 2020.7
公告 我们的群共享文件有备份到 IPFS 的计划,具体时间待定. 我们的机器学习群(915394271)正式改名为财务提升群,望悉知. 请关注我们的公众号"ApacheCN",回复 ...
- 布客·ApacheCN 编程/后端/大数据/人工智能学习资源 2020.6
公告 我们的群共享文件有备份到 IPFS 的计划,具体时间待定. 我们的机器学习群(915394271)正式改名为财务提升群,望悉知. 请关注我们的公众号"ApacheCN",回复 ...
- Spark大数据的学习历程
Spark主要的编程语言是Scala,选择Scala是因为它的简洁性(Scala可以很方便在交互式下使用)和性能(JVM上的静态强类型语言).Spark支持Java编程,但对于使用Java就没有了Sp ...
随机推荐
- ES6-常用四种数组
1.map 1.1 个人理解 映射 一个对一个 例如:[45,57,138]与[{name:'blue',level:0},{name:'zhangsan',level:99},{name:'lisi ...
- Java实现 LeetCode 805 数组的均值分割 (DFS+分析题)
805. 数组的均值分割 给定的整数数组 A ,我们要将 A数组 中的每个元素移动到 B数组 或者 C数组中.(B数组和C数组在开始的时候都为空) 返回true ,当且仅当在我们的完成这样的移动后,可 ...
- Java实现蓝桥杯历届试题格子刷油漆
问题描述 X国的一段古城墙的顶端可以看成 2*N个格子组成的矩形(如下图所示),现需要把这些格子刷上保护漆. 你可以从任意一个格子刷起,刷完一格,可以移动到和它相邻的格子(对角相邻也算数),但不能移动 ...
- Java实现 LeetCode 220 存在重复元素 III(三)
220. 存在重复元素 III 给定一个整数数组,判断数组中是否有两个不同的索引 i 和 j,使得 nums [i] 和 nums [j] 的差的绝对值最大为 t,并且 i 和 j 之间的差的绝对值最 ...
- Java实现 洛谷 P1487 陶陶摘苹果(升级版)
题目描述 又是一年秋季时,陶陶家的苹果树结了n个果子.陶陶又跑去摘苹果,这次她有一个a公分的椅子.当他手够不着时,他会站到椅子上再试试. 这次与NOIp2005普及组第一题不同的是:陶陶之前搬凳子,力 ...
- java实现数字黑洞
任意一个 5 位数,比如:34256,把它的各位数字打乱,重新排列,可以得到 一个最大的数:65432,一个最小的数 23456. 求这两个数字的差,得:41976,把这个数字再次重复上述过程(如果不 ...
- java实现拍7游戏
** 拍7游戏** 许多人都曾经玩过"拍七"游戏.规则是:大家依次从1开始顺序数数,数到含有7或7的倍数的要拍手或其它规定的方式表示越过(比如:7,14,17等都不能数出),下一人 ...
- JS变量小总
变量分类:1.栈内存(stack)和堆内存(heap)2.基本类型和引用类型 #栈内存(stack) 一般为静态分配内存,其分配的内存系统自动释放. #堆内存(heap) 一般为动态分配内存,其分配的 ...
- c 到 c++
目录: 1.引用相关 2.const关键字 3.动态内存分配 1.引用相关: /* 概念:某个变量的引用等价于这个变量的别名 格式:类型名 & 引用名 = 某变量名 作用: 1. ...
- Swagger使用的时候报错:Failed to load API definition
NuGet添加Swashbuckle.AspNetCore,在Startup.cs添加和启用中间件Swagger public void ConfigureServices(IServiceColle ...