入门大数据---HDFS,Zookeeper,ZookeeperFailOverController(简称:ZKFC),JournalNode是什么?
HDFS介绍:
简述:
Hadoop Distributed File System(HDFS)是一种分布式文件系统,设计用于在商用硬件上运行。它与现有的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的差异很大。HDFS具有高度容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,适用于具有大型数据集的应用程序。HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。HDFS最初是作为Apache Nutch网络搜索引擎项目的基础设施而构建的。HDFS是Apache Hadoop Core项目的一部分。
主要成分:
HDFS主要由NameNode和DataNode组成。NameNode负责存储数据的元数据信息和数据的偏移量。DataNode负责存储数据。
数据进入先通过NameNode
NameNode在Hadoop1.x存在一个,在Hadoop2.x可以有两个了。推荐使用2.x,因为2.x相比1.x更能快速切换新的NameNode。
NameNode里面由EditLog和FsImage组成,EdtiLog记录的是操作日志,FsImage记录的所有文件的元数据(包括:文件大小,文件名称,创建时间等等)。另外FsImage还记录了文件的偏移量,不过这个偏移量是由DataNode做心跳机制反馈给NameNode的。当NameNode启动或者触发配置的检查点时,它会读取EditLog和FsImage,并使用EditLog应用到FsImage并加载到缓存,然后刷新EditLog。
我画了个交互图如下:

下面这则漫画摘自https://blog.csdn.net/hudiefenmu,他很形象的讲解了文件的写入原理,读取原理以及处理故障原理。
HDFS写数据原理:
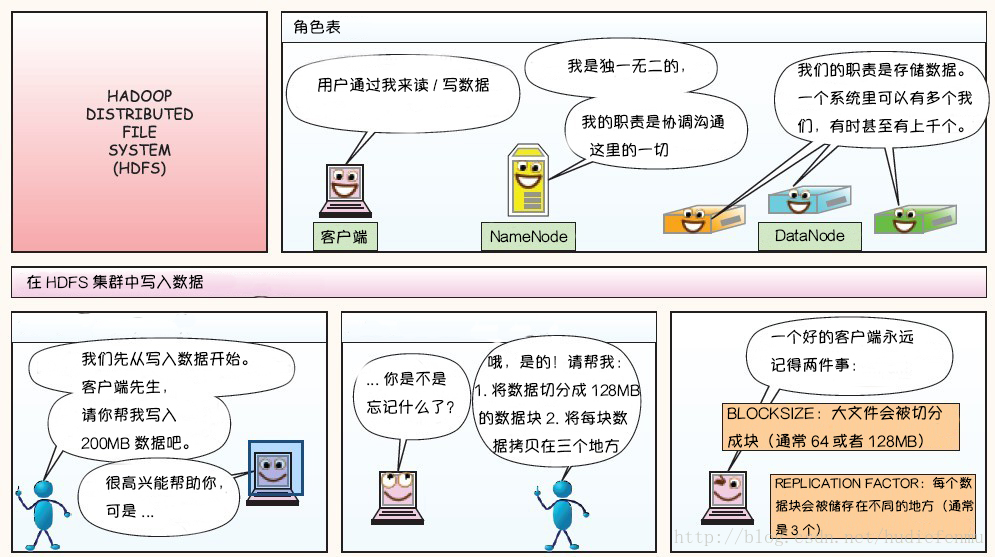
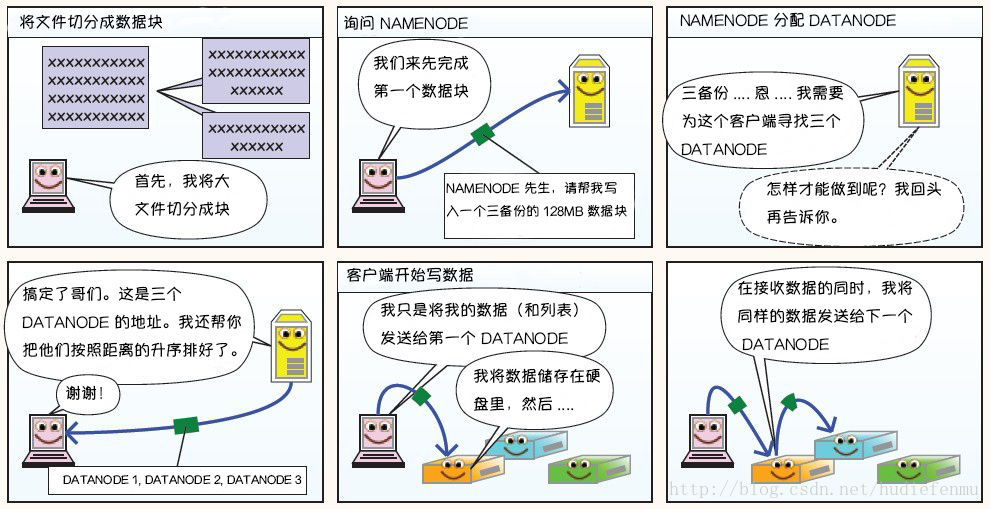
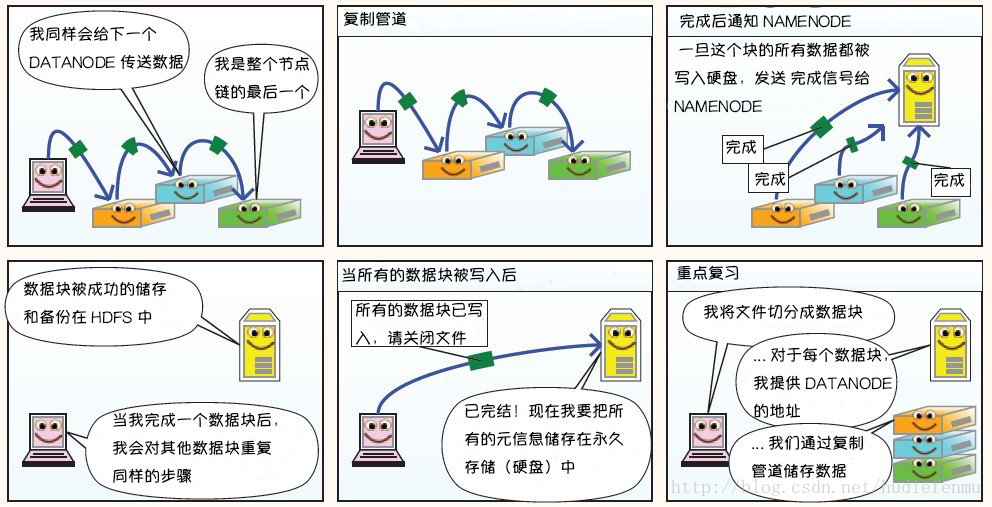
HDFS读数据原理:
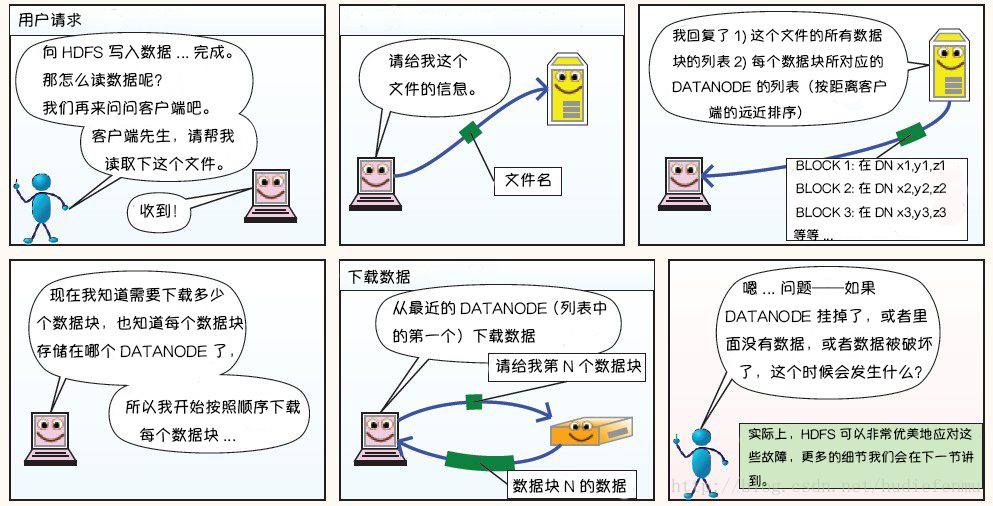
HDFS故障类型和其检测方法:
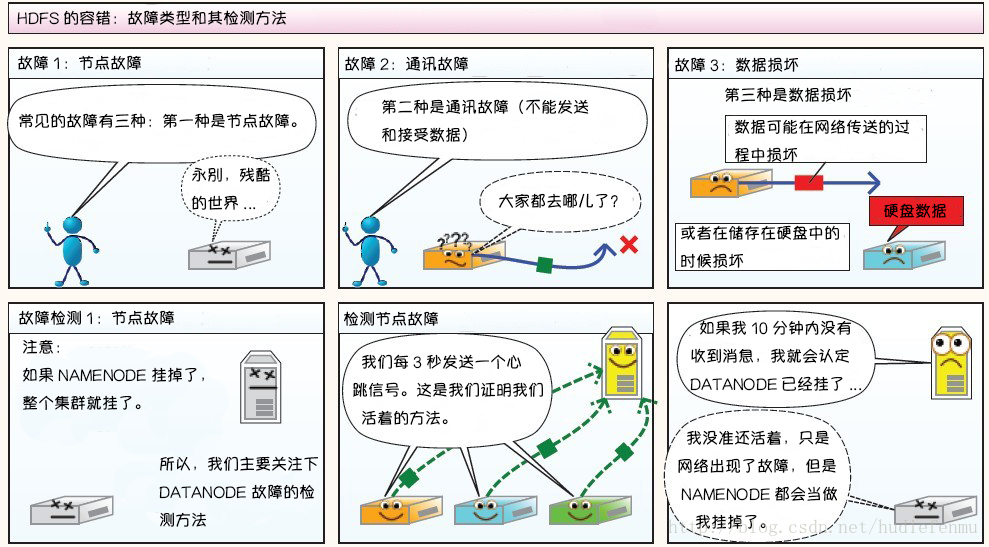
-读写故障的处理
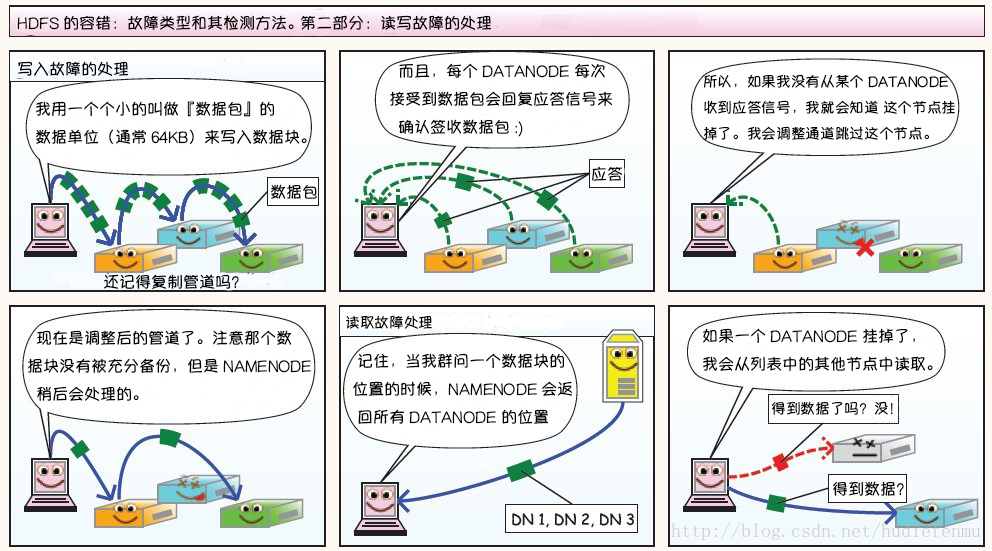
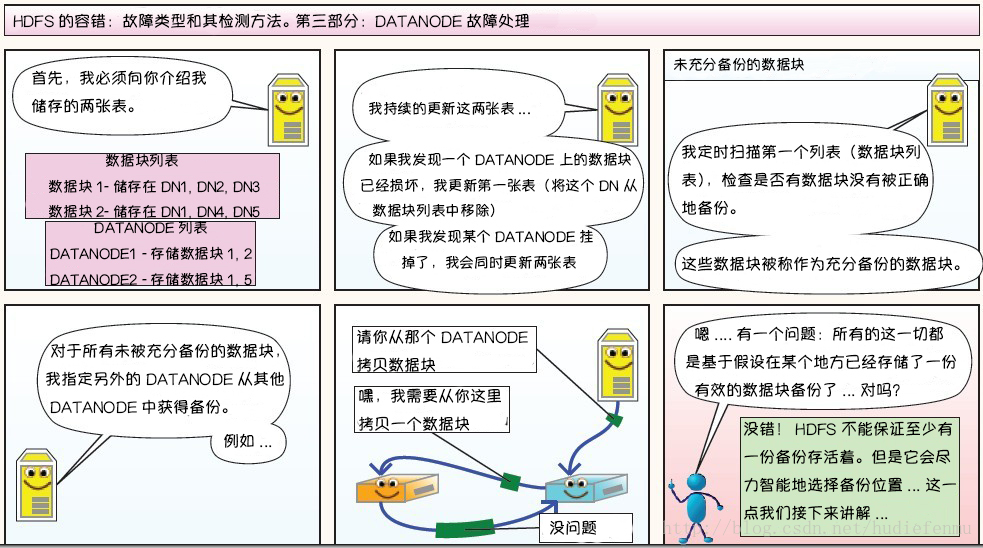
-DataNode故障处理
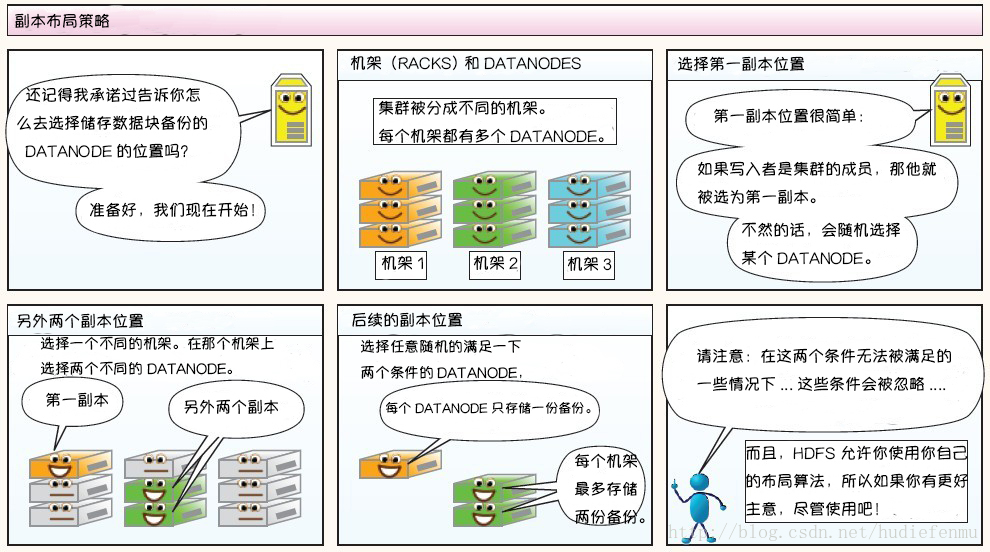
-副本布局策略
Quorum Journal Manager :
简述:
由于部署了两个NameNode,并且仅仅允许一台(ActiveNode)对外提供服务,另一台(StandByNode)在NameNode不可用的时候切换过去,这样就要保证StandBy数据是最新的。 而JournalManager就是接受ActiveNode的变动日志,然后StandBy节点读取同步更新数据。
结合上面的NameNode我画了个图如下:
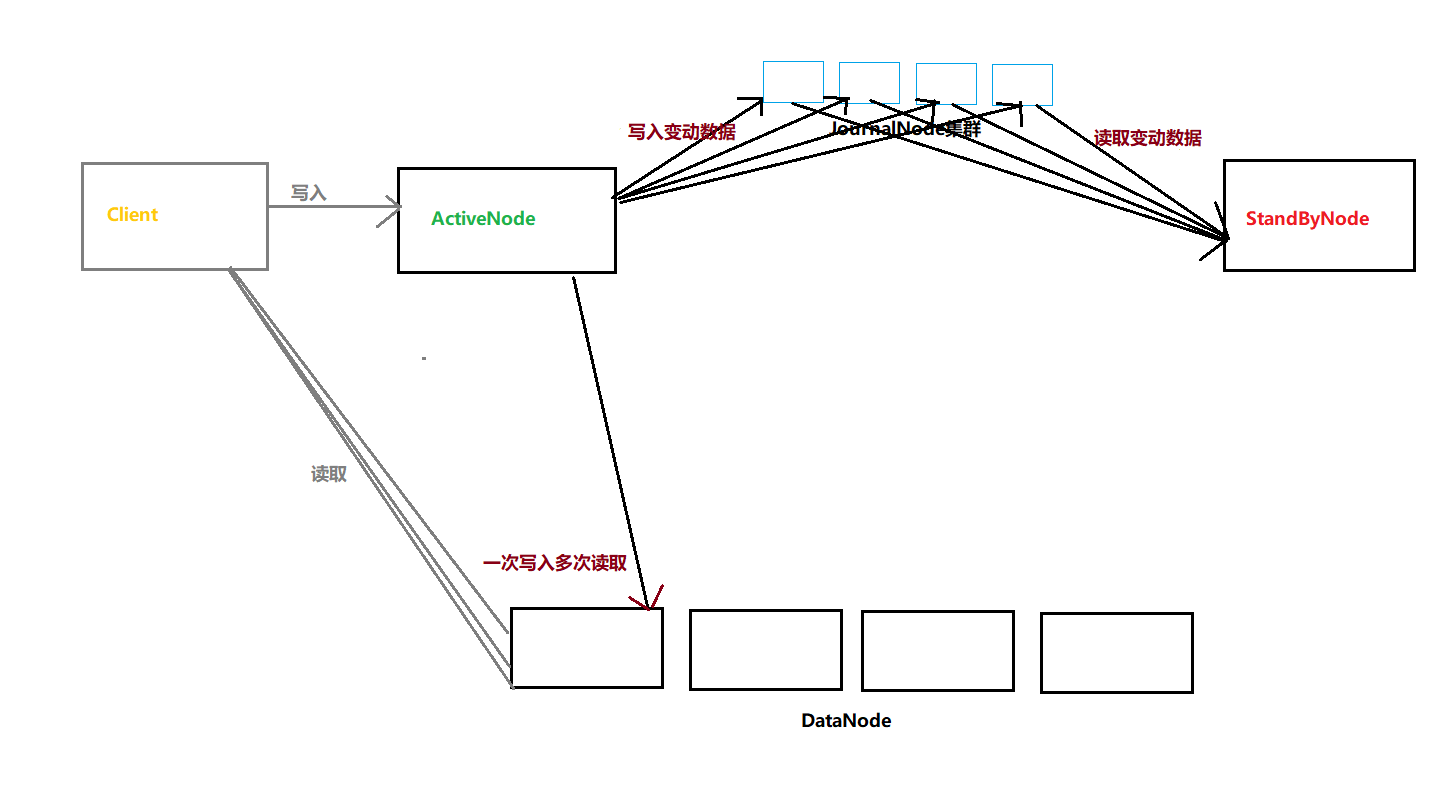
Zookeeper和ZookeeperFailOverController介绍:
简述:
Zookeeper简称ZK,ZookeeperFailOverController简称ZKFC
上面使用JournalManager遇到故障的时候需要手动切换NameNode节点,这样处理会很不及时,所以必须想个办法自动切换,这样就有了Zookeeper,然后配套的出现了ZKFC,ZKFC和NameNode是一一对应的,它是一个守护进程,它负责和ZK通信,并且时刻检查NameNode的健康状况。它通过不断的ping,如果能ping通,则说明节点是健康的。然后ZKFC会和ZK保持一个持久通话,及Session对话,并且ActiveNode在ZK里面记录了一个"锁",这样就会Prevent其它节点成为ActiveNode,当会话丢失时,ZKFC会发通知给ZK,同时删掉"锁",这个时候其它NameNode会去争抢并建立新的“锁”,这个过程叫ZKFC的选举。
结合上面简要图如下:

入门大数据---HDFS,Zookeeper,ZookeeperFailOverController(简称:ZKFC),JournalNode是什么?的更多相关文章
- 入门大数据---基于Zookeeper搭建Kafka高可用集群
一.Zookeeper集群搭建 为保证集群高可用,Zookeeper 集群的节点数最好是奇数,最少有三个节点,所以这里搭建一个三个节点的集群. 1.1 下载 & 解压 下载对应版本 Zooke ...
- 入门大数据---基于Zookeeper搭建Spark高可用集群
一.集群规划 这里搭建一个 3 节点的 Spark 集群,其中三台主机上均部署 Worker 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop0 ...
- 2020/4/26 大数据的zookeeper分布式安装
大数据的zookeeper分布式安装 **** 前面的文章已经提到Hadoop的伪分布式安装.现在就在原有的基础上安装zookeeper. 首先启动Hadoop平台 [root@master ~]# ...
- 大数据之 ZooKeeper原理及其在Hadoop和HBase中的应用
ZooKeeper是一个开源的分布式协调服务,由雅虎创建,是Google Chubby的开源实现.分布式应用程序可以基于ZooKeeper实现诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知. ...
- 大数据-hdfs技术
hadoop 理论基础:GFS----HDFS:MapReduce---MapReduce:BigTable----HBase 项目网址:http://hadoop.apache.org/ 下载路径: ...
- 入门大数据---HDFS-HA搭建
一.简述 上一篇了解了Zookeeper和HDFS的一些概念,今天就带大家从头到尾搭建一下,其中遇到的一些坑也顺便记录下. 1.1 搭建的拓扑图如下: 1.2 部署环境:Centos3.1,java1 ...
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 【大数据】Zookeeper学习笔记
第1章 Zookeeper入门 1.1 概述 Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目. 1.2 特点 1.3 数据结构 1.4 应用场景 提供的服务包括:统 ...
- 入门大数据---Hadoop是什么?
简单概括:Hadoop是由Apache组织使用Java语言开发的一款应对大数据存储和计算的分布式开源框架. Hadoop的起源 2003-2004年,Google公布了部分GFS和MapReduce思 ...
随机推荐
- 学习使用pyquery解析器爬小说
一.背景:个人喜欢在网上看小说,但是,在浏览器中阅读小说不是很方便,喜欢找到小说的txt版下载到手机上阅读,但是有些小说不太好找txt版本,考虑自己从网页上爬一爬,自己搞定小说的txt版本.正好学习一 ...
- Keycloak快速上手指南,只需10分钟即可接入Spring Boot/Vue前后端分离应用实现SSO单点登录
登录及身份认证是现代web应用最基本的功能之一,对于企业内部的系统,多个系统往往希望有一套SSO服务对企业用户的登录及身份认证进行统一的管理,提升用户同时使用多个系统的体验,Keycloak正是为此种 ...
- Chisel3 - util - MixedVec
https://mp.weixin.qq.com/s/mO648yx4_ZRedXSWX4Gj2g 可以容纳不同类型的变量的向量. 参考链接: https://github.com/freec ...
- Java实现 LeetCode 645 错误的集合(暴力)
645. 错误的集合 集合 S 包含从1到 n 的整数.不幸的是,因为数据错误,导致集合里面某一个元素复制了成了集合里面的另外一个元素的值,导致集合丢失了一个整数并且有一个元素重复. 给定一个数组 n ...
- Java实现 LeetCode 623 在二叉树中增加一行(遍历树)
623. 在二叉树中增加一行 给定一个二叉树,根节点为第1层,深度为 1.在其第 d 层追加一行值为 v 的节点. 添加规则:给定一个深度值 d (正整数),针对深度为 d-1 层的每一非空节点 N, ...
- Java实现 LeetCode 502 IPO(LeetCode:我疯起来连自己都卖)
502. IPO 假设 力扣(LeetCode)即将开始其 IPO.为了以更高的价格将股票卖给风险投资公司,力扣 希望在 IPO 之前开展一些项目以增加其资本. 由于资源有限,它只能在 IPO 之前完 ...
- java实现和为定值的两个数
1 问题描述 输入一个整数数组和一个整数,在数组中查找两个数,满足他们的和正好是输入的那个整数.如果有多对数的和等于输入的整数,输出任意一对即可.例如,如果输入数组[1,2,4,5,7,11,15]和 ...
- 循序渐进VUE+Element 前端应用开发(9)--- 界面语言国际化的处理
我们开发的系统,一般可以不用考虑语言国际化的问题,大多数系统一般是给本国人使用的,而且直接使用中文开发界面会更加迅速 一些,不过框架最好能够支持国际化的处理,以便在需要的时候,可以花点时间来实现多语言 ...
- PyQt5 模块modules
The QtCore module contains the core non-GUI functionality. This module is used for working with time ...
- Asp.Net Core入门之自定义服务注册
谈到服务注册,首先我们先了解一下服务注册时使用的三种方式,也代表了不同的服务生命周期: AddTransient AddScoped AddSingleton AddSingleton生命周期最长,其 ...