业务系统请求zabbix图表性能调优
性能调优实践
背景
用 vue.js 的框架 ant-design vue pro 实现的一个监控系统,后端用第三方开源组件 zabbix 提供监控数据采集,前端的展示中一个页面会同时请求 N 个图表,页面响应时间很慢,极端情况下甚至达到 10s , 用户体验很差,所以领导给了个小任务,优化整个页面的请求响应。
领导发现页面响应很慢,说了一句:“这些图表显示这么慢,应该一开始就想着优化的”,这里我觉得这个观点有待商榷,最近在读《重构》这本书,里面的一个观点我很认同:“做任何事情,先做出来,再优化”,这是一个应用面很广的策略,跟 Linux 的哲学之一“单个程序负责一个小功能”的组织模式,都有广泛用法;当工期有限的情况下,先把东西做出来(这里不光指代程序,而是任何产品或者其他交付物),再考虑优化它,因为有了产出物才会有后续的东西,而且任何人不可能一开始就把所有的情况和变化的需求考虑得面面俱到。Linux 哲学里的那句话同样可以用于人员组织、社会分工合作方面,专人专事,让专业人士来做(比如:黑人抬棺),效率不言而喻。
显示很慢的图如下:

问题分析
之前从来没有做过性能优化和分析,这次从零开始优化,需要自己认真分析排查,这个页面会请求同一个接口,不获取不同监控指标的图表数据,大概 10-20 个图表渲染,在排查之前想到可能的性能瓶颈:
- 前端页面优化不好(前端用的 axios.all 来发送多个并发请求,页面会在所有后端响应后才渲染,可能瓶颈在这里)
- 后端接口的并发没有优化过,可能性能瓶颈在这里
- zabbix 这个开源中间件的响应时间过慢,负载过高
- mysql 数据库引擎没有优化,造成性能过低
后端优化排查
作为全栈开发者,首先想到的是从后端服务开始优化,而没有优化经验怎么入手,当然是先找轮子了,Google 找了一下工具,有如下可用:
- 阿里的 Arthas java诊断工具
- OneAPM(链路追踪,类似于 skywalking 之类的工具,甚至可以监测我的 springboot项目)
- Oracle 的 Java Mission Control
- 淘宝的Tprofiler、Jprofiler
- MyBatis-Plus 性能分析插件(这里我的后端是 springboot + Mybatis-Plus , 这个插件可以帮助我分析 SQL 慢查询,打印出所有的查询语句)
询问了下同事,发现大家也没什么优化经验,所以我选用了之前了解了一点的 Arthas 工具作为诊断。
进入 Arthas 的官网,可以用它的在线教程快速入门(它是一个沙盒的 linux 环境,能够快速掌握 Arthas 的基础使用和概念),然后,知道使用方法后,把 Arthas 的 jar 包放到我的 centos 线上测试环境中(Arthas 本身也支持 windows 的,可以本地调试)
java -jar arthas-boot.jar
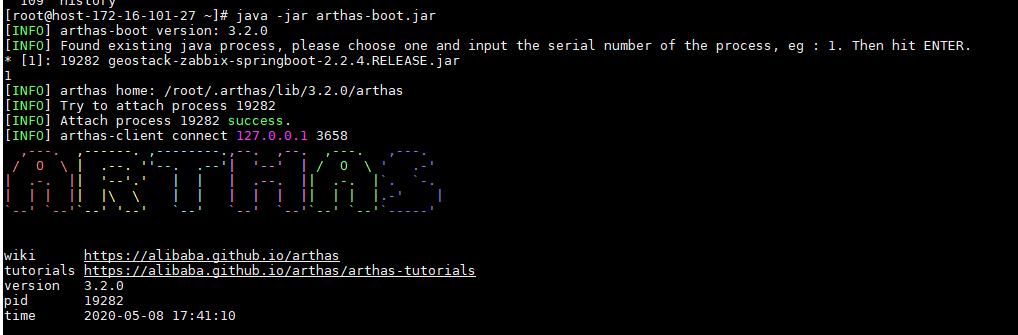
然后用 trace 命令来追踪某个方法调用链路上的耗时
trace xxxx.xxx xxx

此时,我们请求前端代码,就能在后台看到对这个调用方法的每一步的耗时了

此时,我们就可以去具体的代码分析耗时原因了,重复 trace 可以进一步精确定位哪个方法开销最大。
Arthas 还有很多非常强大的功能,对于 java 程序员非常友好,建议自行探索:
发现接口响应时间为 500 ms 后,感觉性能瓶颈可能不在后端(当然,这里肯定还有一定的优化空间,但是不是主要矛盾)
前端优化排查
发现后端接口响应时长没有那么夸张之后,把目光放到了前端上来,F12 打开了 chrome 浏览器的开发者工具后,发现几个问题:
- 同一个接口并发了很多次
- Stalled 和 Waiting(TTFB)很长
继续 Google ,搜索 同时发送多个请求造成 chrome stalled 时长过大(当然用英文关键词搜索),果然在 stackoverflow 发现了这个问题的解答,[https://stackoverflow.com/questions/27513994/chrome-stalls-when-making-multiple-requests-to-same-resource],里面提到了几种解决方式:
- 给 response header 增加
Cache-Control: no-cache, no-store,这个我在后端增加后没有效果,这里别人讨论的是浏览器的缓存机制造成请求过慢 - 给我们的请求 url 后面增加一个随机数,比如
?ran='+Math.random(),让请求不一致,达到欺骗浏览器,让它每次都发送一个新的请求,这个实验后也不能让响应时间变短
此时的我陷入了沉思,问题究竟处在哪里?同事提醒我一个规律,超过 6 个请求后,后面的都会开始有一串灰色的长耗时(就是我们看到的 stalled),另外一个同事说好像是 jquery 的限制还是怎样,继续搜索,发现这个是 浏览器对同一个域名的多并发请求个数的限制,参考博文:
发现了这个限制之后,我们把图表的请求个数限制在6个以内,跟之前相比页面渲染速度确实有明显提升,规避了请求数量过多造成 stalled 的问题,当然,这个只是一种解决方案,v2ex 上的同学有很多其他可参考的解决方式。
参考腾讯的蓝鲸监控里的图表绘制,它们采取了分页请求控制数量,尽量给客户展示少的图表,同时提供每页显示更多的选择(每页 4 个图表秒开,8个的时候就开始有 loading 的效果了)
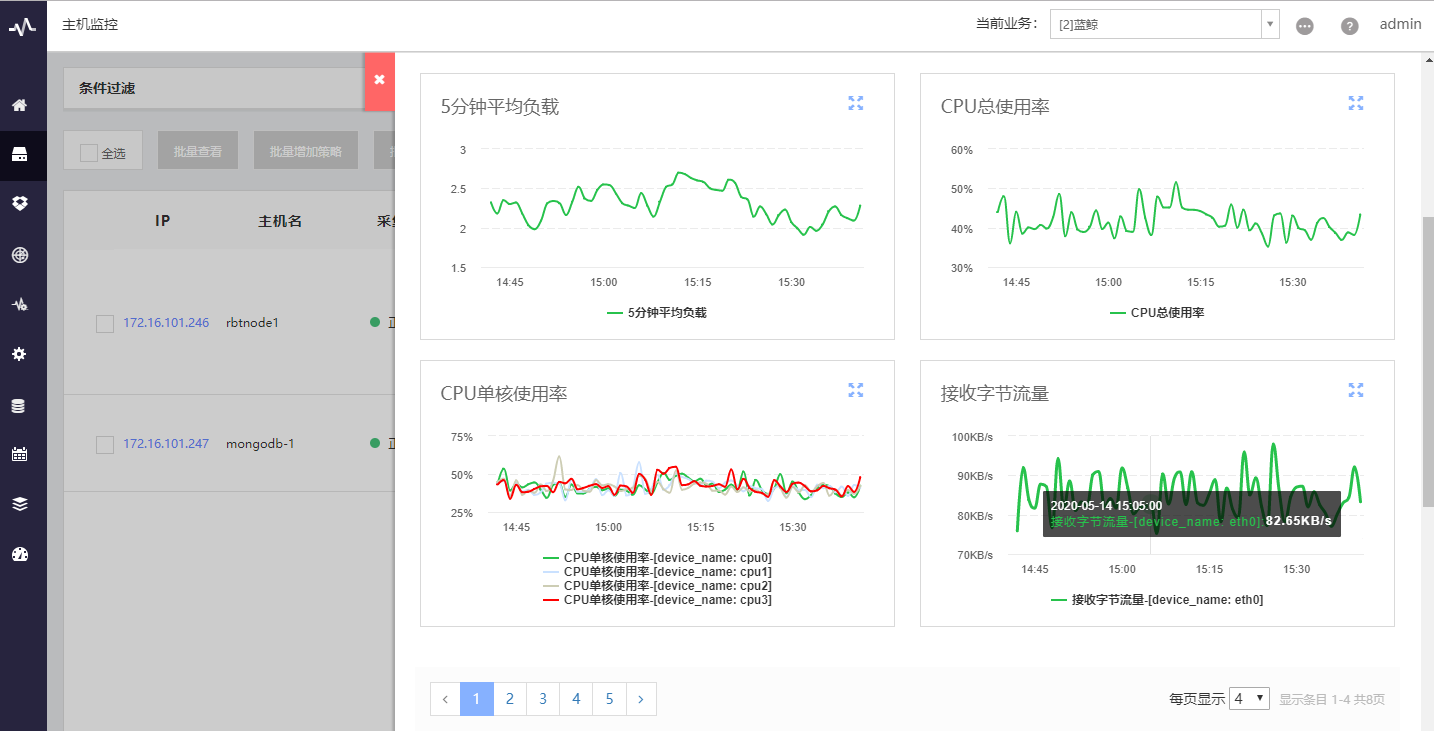
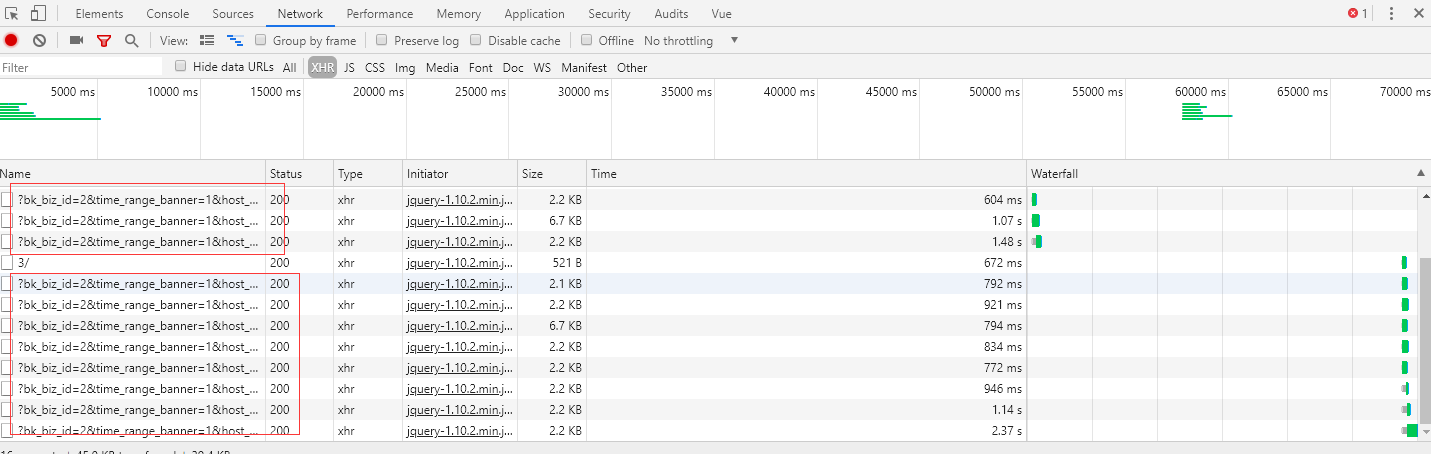
解决了前端超过 6 个请求的阻塞问题,问题到了有的请求 Waiting(TTFB)很长上来了,这又是个什么呢?搜索一番发现,这个是服务端的响应(看来后端还是很有优化空间的,参考博文:ttfb是什么)
后端长响应排查
这个图表请求接口有的会特别慢,甚至有的会 2-3 秒,定位到问题出在跟三方组件 zabbix-server 的请求交互上,这是非常需要优化的,打开我们的 fiddle 抓包工具看请求:
fiddle 使用小技巧
控制面板-Internet 选项-连接-局域网设置-代理服务器(不勾选为 LAN 使用代理服务器)

设置地代码的代理端口为 8888 (fiddle 默认使用的就是 8888)
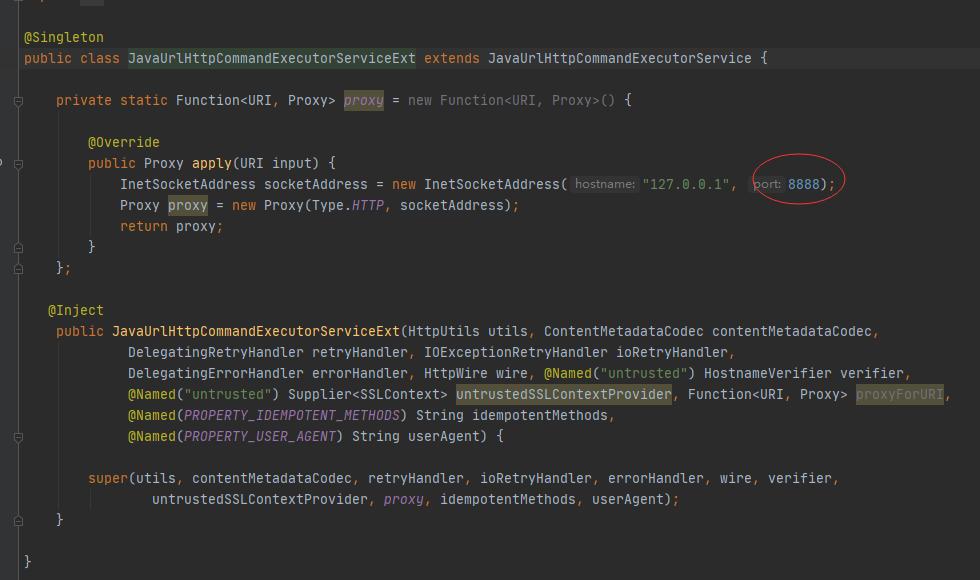
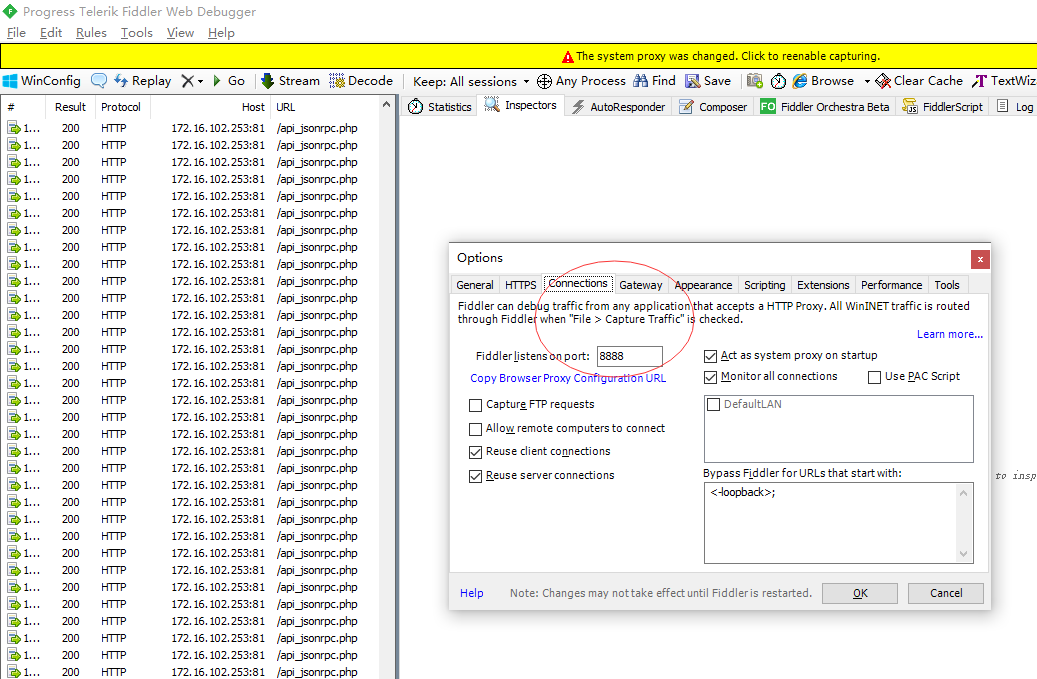
这样设置后,fiddle 就只会抓取我本地 idea 发送的请求了,过滤掉了浏览器里的干扰请求。
用 Fiddler 抓 Postman的模拟请求
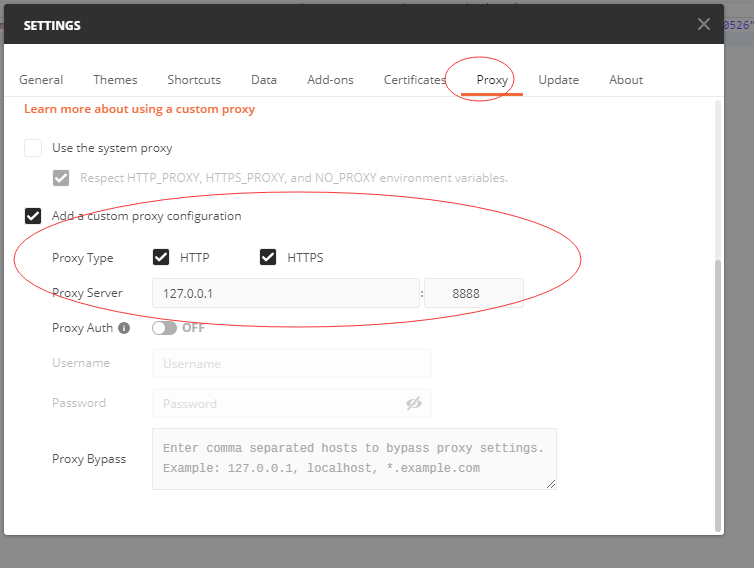
每个图表请求分三个:
- 登录 zabbix 获取 token
- 请求监控项
- 根据监控项获取图表
参考 zabbix 的官方文档,做了代码层面的优化:
- 出于性能考虑,缓存 token ,避免每次都登录请求一个新 token
- 检索监控项只检索你需要的属性(这一点比较好理解,zabbix 服务端我们用的 mysql 引擎,相当于只查询特定的字段,跟全表查性能肯定不一样)

后端优化还包括:用特定的监控项取代发现类型监控项(这个是发现磁盘接口过慢的原因,会发现 70 多个文件目录),请求某个主机的所有发现类型监控项写到我们的业务库(只请求一次)等;
zabbix server 优化
单个后端请求的瓶颈在于我们用 zabbix api 去请求 zabbix server 所返回的过程,所以,对zabbix server 本身的优化也是整个链路的重要方面。参考 zabbix 的官方文档后,有这样一些方面:
历史数据保存时间尽可能的小,这样数据库不会超负荷运行,查询的效率也更高
[https://www.zabbix.com/documentation/4.0/zh/manual/config/items/history_and_trends]调优zabbix的数据库引擎,这个是调优最重要的部分(由于没有 dba ,本人对数据库调优也不懂,这个暂时无法做到,搜索了下我们使用的 mysql 5.6 使用的是 InnoDB 引擎)
[https://www.zabbix.com/documentation/4.0/zh/manual/appendix/performance_tuning]
对于 zabbix 本身优化官方文档还没整个看一遍,等全部找一遍说不定能找到进一步压榨性能的方法~
总结
此次优化涉及了很多方面,前端、后端、服务器等,优化后的用户体验得到了提升,也遇到了一些坑,不断提高自己解决问题的能力,才是程序员的价值,共勉!
业务系统请求zabbix图表性能调优的更多相关文章
- 最全JVM与性能调优知识点总结,看看哪些是你还没掌握的?
前言 JVM调优是每个高级程序员的必修课,在本章中,我会从发展过程以及核心价值来剖析JVM的体系结构.为了让大家更好的理解JVM的工作机制, 我会在讲解完运行时数据区之后,再通过一个类的加载过程到这个 ...
- Java性能调优实战,覆盖80%以上调优场景
Java 性能调优对于每一个奋战在开发一线的技术人来说,随着系统访问量的增加.代码的臃肿,各种性能问题便会层出不穷. 日渐复杂的系统,错综复杂的性能调优,都对Java工程师的技术广度和技术深度提出了更 ...
- JVM 性能调优实战之:一次系统性能瓶颈的寻找过程
玩过性能优化的朋友都清楚,性能优化的关键并不在于怎么进行优化,而在于怎么找到当前系统的性能瓶颈.性能优化分为好几个层次,比如系统层次.算法层次.代码层次…JVM 的性能优化被认为是底层优化,门槛较高, ...
- JVM 性能调优实战之:使用阿里开源工具 TProfiler 在海量业务代码中精确定位性能代码
本文是<JVM 性能调优实战之:一次系统性能瓶颈的寻找过程> 的后续篇,该篇介绍了如何使用 JDK 自身提供的工具进行 JVM 调优将 TPS 由 2.5 提升到 20 (提升了 7 倍) ...
- 盘点linux系统中的12条性能调优命令。
导读 性能调优一直是运维工程师最重要的工作之一,如果您所在的生产环境中遇到了系统响应速度慢,硬盘IO吞吐量异常,数据处理速度低于预期值的情况,又或者如CPU.内存.硬盘.网络等系统资源长期处于耗尽的状 ...
- 使用阿里开源工具 TProfiler 在海量业务代码中精确定位性能代码 (jvm性能调优)
技术交流群:233513714 本文是<JVM 性能调优实战之:一次系统性能瓶颈的寻找过程> 的后续篇,该篇介绍了如何使用 JDK 自身提供的工具进行 JVM 调优将 TPS 由 2.5 ...
- 盘点linux操作系统中的10条性能调优命令,一文搞懂Linux系统调优
原文链接:猛戳这里 性能调优一直是运维工程师最重要的工作之一,如果您所在的生产环境中遇到了系统响应速度慢,硬盘IO吞吐量异常,数据处理速度低于预期值的情况,又或者如CPU.内存.硬盘.网络等系统资源长 ...
- 性能调优之Java系统级性能监控及优化
性能调优之Java系统级性能监控及优化 对于性能调优而言,通常我们需要经过以下三个步骤:1,性能监控:2,性能剖析:3,性能调优 性能调优:通过分析影响Application性能问题根源,进行优化 ...
- Java生鲜电商平台-API请求性能调优与性能监控
Java生鲜电商平台-API请求性能调优与性能监控 背景 在做性能分析时,API的执行时间是一个显著的指标,这里使用SpringBoot AOP的方式,通过对接口添加简单注解的方式来打印API的执行时 ...
随机推荐
- 浅析CAS与AtomicInteger原子类
一:CAS简介 CAS:Compare And Swap(字面意思是比较与交换),JUC包中大量使用到了CAS,比如我们的atomic包下的原子类就是基于CAS来实现.区别于悲观锁synchroniz ...
- 前端学习笔记-H5
H5常用标签及其属性: <a>标签做超链接: <p>段落标签,自带段间距和换行样式: <div>块标签,表示一块内容,没有具体语意,区别与p标签,块与块间没有间距: ...
- wechall前十题
今天开始打一打wechall 累了打wechall,不累的时候开始打buu 第一题:Get Sourced 查看源代码即可,拉到底部 第二题:Stegano 属于misc的范畴,直接下载下来,然后no ...
- 编码理解的漫漫长路(Unicode、GBK、ISO)
Ø 那么现在开始康康都有哪些编码方式 1. ASCII
- CVE 2019-0708 漏洞复现+
PART 1 参考链接:https://blog.csdn.net/qq_42184699/article/details/90754333 漏洞介绍: 当未经身份验证的攻击者使用 RDP 连接到目标 ...
- Category、load、initialize 源码讲解
今天深圳天气有暴风雨,没有事情干,趁着周末和平常晚上写一篇关于Category知识的梳理!可能针对平常只会知道些category基本结论知道的人有些帮助,写这篇博客会按照下面的目录结合实例以及Cate ...
- 如何给 Inno Setup 生成的安装包添加版本信息
使用 Inno 已有的函数 GetFileVersion 获取 EXE 文件的版本 #define ApplicationName 'Application Name' #define Applica ...
- 每天认识几个HTTP 响应码
HTTP 响应状态代码指示特定 HTTP 请求是否已成功完成. 1xx信息响应 1xx 的响应结果表明接收的请求正在处理 2xx成功响应 2XX 的响应结果表明请求被正常处理了 3xx重定向 3xx ...
- shell基础知识DAY2
1.管道符(|):把一个命令的输出,把输出的内容传递给管道符后面命令的输入.如:ls -l | grep "^[^d]".2.jobs作业控制,后台运行bg PID,前台运行fg ...
- pfSense®2.4.4发布后,原pfSense 黄金会员的服务将免费使用!
2018年7月16日,Doug McIntire 从即将发布的pfSense®2.4.4开始,之前在"pfSense Gold"下提供的所有服务都将继续,但所有pfSense用户都 ...