[YOLO]《YOLO9000:Better, Faster, Stronger》笔记
一、简单介绍
YOLO9000(也叫YOLO v2),主要是在YOLO v1的基础上做了改进,而且效果还是比较显著的,在原论文中,作者提到的改进大致包括两个工作:
1、检测性能上的改进,提出了YOLO v2;
2、提出了检测与分类相结合的训练方法,使得YOLO v2能够检测超过9000类目标。
二、性能改进
YOLO v2相比于YOLO v1的改进以及带来的性能上的提升可以总结如下图所示:
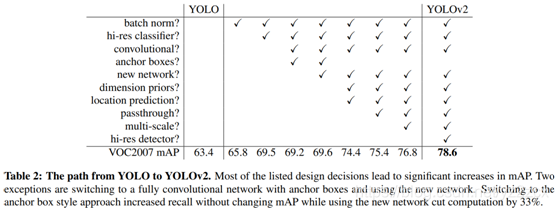

现在分别记录下各个改进方法:
1、Batch Normalization.
BN层是比较常见而且对于过拟合、模型的训练等问题都比较有成效的CNN的一种归一化操作,现在应该比较多的网络结构中都会用到。BN层的使用让YOLOv2相比较YOLOv1在mAP分数上提高了大约2个百分点的性能。
2、High Resolution Classifier
这一步其实是提高网络在分类预训练阶段的输入分辨率。在YOLOv1的时候,模型是先训练分类网络,再将模型转成检测网络,并且在分类训练阶段,模型的输入采用的是ImageNet常见的224*224的分辨率,在检测训练阶段才将输入的分辨率提高到448*448.
所以,在YOLOv2的改进中,在训练分类任务的阶段就直接采用了448*448来训练,这样的改进给YOLOv2带来了接近4个百分点的性能提升。
3、Convolutional With Anchor Boxes
YOLOv1是直接预测边界框的坐标等信息, Faster R-CNN采用的是手动设计anchor box,因此能够获取到的空间信息相对会比YOLOv1的丰富,因此在YOLOv2中作者也尝试借鉴anchor box的设计,为了引入anchor box的设计,YOLOv2去掉了全连接层和池化层,来提高输出的分辨率,同时将网络的输入分辨率从448*448改为416*416,这样做的目的是为了让后面产生的卷积特征图的宽高为基数,方便产生唯一的网格中心。
最后YOLOv2的输出分辨率为13*13,也就是相比于输入分辨率,降低了32倍。同时在预测上,坐标宽高的预测则是与anchor box相关的,而置信度和概率的预测则不变。
这一改进带来了召回率的提升(81%->88%),但是mAP分数则会下降(69.5% ->69.2)。
4、Dimension Clusters
既然引入anchor box是有一定效果的,那么就不要用手动了吧,因为手动设计的是固定的比例,如果能够预先找到比较合适的比例,那可能对于训练效果会更好吧。
因此论文中采用了K-means聚类来实现,采用的距离衡量是:

因为引入ancho box是希望在预测结果上能有一个更好的IOU分数。论文实验的K-means聚类算法在VOC数据集上得到的平均IOU分数表现如下:
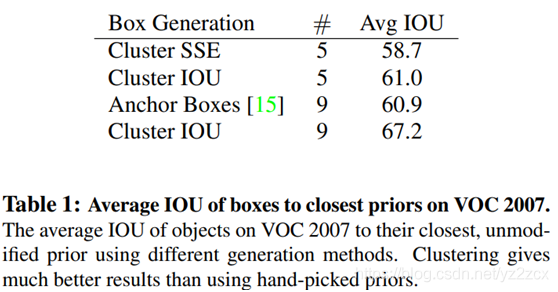
在VOC和COCO数据集上的聚类维度与IOU分数的趋势如下:

相对来说,采用9个anchor box的IOU分数是最高的。
5、Direct location prediction
当直接使用anchor box来训练YOLOde 时候,会出现一些不稳定的问题,特别是在训练的早期,而且这种不稳定大部分时候是由定位(x,y)的预测引起的,因此作者改用预测位置坐标的偏移量:
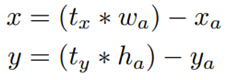
论文中的这个应该有误,后面两个减号应该是加号才对。其中(tx, ty)表示预测的结果,(x, y)表示实际的值,而带下标a的表示anchor box的相关值。但是这样的结果可能会引出另一个问题,这里没有对预测的偏移量做限制,也就是说预测到的值可能会非常大,预测位置可能是整幅图像中的任何位置。
所以对预测的值做了限制,改为预测相对于特定网格的偏移量:

其中,bx和by是相对于输入尺寸的坐标信息,bw和bh是相对于输入尺寸的宽高信息,后面的置信度就不变。而宽高之所以要取幂函数,是因为引入anchor box是借鉴了Faster-RCNN,其中的对于实际坐标和宽高转换为标签的操作如下:

这里关于前面的四个坐标大小的数值还有一些补充:
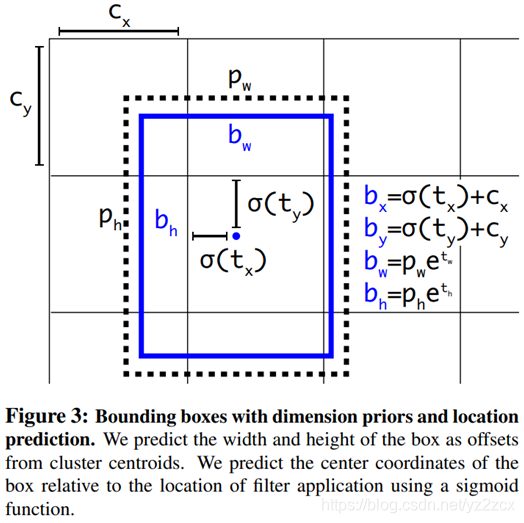
Cx和Cy是当前网格左上角相对于整幅图像左上角的距离,这里一般Cx和Cy取的整数1,也就是距离图像左上角有多少个网格距离。但是σ(tx)和σ(ty)表示的是预测的中心点与所在网格左上角的偏移量,所以实际上上式bx和by得到的是一个归一化后的数值,如果需要映射回模型输入尺寸的数值,则,上式bx和by应该表示为:
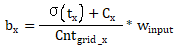

其中,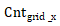 表示输入图像在X轴均分为多少网格,
表示输入图像在X轴均分为多少网格, 表示在y轴均分为多少网格,
表示在y轴均分为多少网格,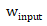 表示输入分辨率宽度,
表示输入分辨率宽度, 表示高度。
表示高度。
6、Fine-Grained Features
YOLO v2已经将图像划分为13*13个网格来做检测,这对于大目标的检测基本是很有效的,但是在小目标的检测上效果较差。Faster R-CNN和SSD在目标检测上都引入了多尺度特征图,因此YOLOv2再引入ResNet中的跳级连接的操作,将中间分辨率为26*26的特征图与最终的13*13的特征图进行拼接输出。在操作上,论文中将26*26*512的特征图转为13*13*2048的特征图,并于最后的13*13的特征图进行拼接。这样的操作取得了1%的提升。
7、Multi-Scale Training
在训练YOLOv2的时候,论文也引入了多尺度训练,也就是将输入的图像缩放到一系列分辨率,没训练10个batch,就随机换另一种分辨率的图像来训练,每种分辨率宽高都相差32个像素,分辨率范围为 。
。
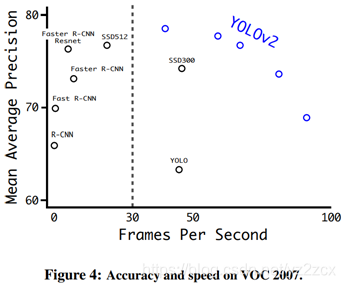
当分辨率取288 × 288的时候,YOLOv2在VOC数据集上基本能达到Fast R-CNN的mAP的性能下,速度有90fps;当取较大分辨率的时候,YOLOv2在VOC数据集上的mAP有78.6。
8、Further Experiments
YOLOv2除了在VOC数据集上做了实验,还在COCO数据集上做了实验。性能表现如下:


三、速度改进
很多目标检测的网络模型是基于VGG16来设计的,VGG16的卷积层对于输入分辨率为224*224的图像,需要大约306.9亿次浮点运算。
YOLO是基于GoogLeNet来设计的,比VGG16快,并且对于224*224的输入分辨率需要85.2亿次浮点运算,但是在ImageNet上,YOLO准确率(88%)就不如VGG16(90%)。
所以,YOLOv2借鉴VGG模型设计了Darknet19的基础网络,包含19层卷积层和5层池化层,并引入BN层和1*1卷积层,处理一张图像需要55.8亿次运算,在ImageNet数据集上top1准确率达到72.9%,top5达到91.2。

1、Training for classification.
在标准ImageNet 1000类的分类任务中, Darknet19采用SGD训练了160次,其中学习率0.1,学习率采用多项式衰减,衰减率为4的幂,权重衰减为0.0005,动量衰减为0.9。训练的输入分辨率为224*224。
然后改用448*448训练了10次,学习率为0.001,最终,top1准确率为76.5%,top5准确率为93.3%。
2、Training for detection
训练好分类网络之后,YOLOv2将训练好的分类模型改为检测模型,将最后一层的卷积层去掉,在最后的1*1卷积层之后连3层1024个3*3卷积核的卷积层。检测模型训练了160次,学习率为0.001,在第10、60和90个回合的时候进行衰减,每次学习率衰减都是除以对应回合数。SGD的权重衰减为0.0005,动量为0.9。
四、Stronger改进
这一部分主要是为了检测更多的目标而进行的,但是一般的目标检测数据库都是有固定的检测类别,所以这一部分主要是为了解决模型用一个数据集只能检测该数据集标注的类别数而提出的。但是个人感觉这一部分不是太有必要,扩展到9000多个类,通用性很强,但是针对性可能就容易减弱,论文中也提到了,YOLO9000在检测156个目标的任务中mAP只有19.7,因此这一部分我也没有太详细研究。暂时略过吧。
五、参考
[1] 论文:https://arxiv.org/pdf/1612.08242.pdf
[YOLO]《YOLO9000:Better, Faster, Stronger》笔记的更多相关文章
- 深度学习论文翻译解析(一):YOLOv3: An Incremental Improvement
论文标题: YOLOv3: An Incremental Improvement 论文作者: Joseph Redmon Ali Farhadi YOLO官网:YOLO: Real-Time Obje ...
- [YOLO]《YOLOv3: An Incremental Improvement》笔记
相比较于前两篇论文,个人感觉YOLO3作者有点来搞笑的!!!虽然加了一些新的点子进来,但是,论文的开头是这样的: 简单理解就是作者花了很多时间玩Twitter去了,所以没有做啥研究!!!! 然后: 你 ...
- 论文阅读笔记三十二:YOLOv3: An Incremental Improvement
论文源址:https://pjreddie.com/media/files/papers/YOLOv3.pdf 代码:https://github.com/qqwweee/keras-yolo3 摘要 ...
- 目标检测(七)YOLOv3: An Incremental Improvement
项目地址 Abstract 该技术报告主要介绍了作者对 YOLOv1 的一系列改进措施(注意:不是对YOLOv2,但是借鉴了YOLOv2中的部分改进措施).虽然改进后的网络较YOLOv1大一些,但是检 ...
- 目标检测:YOLO(v1 to v3)——学习笔记
前段时间看了YOLO的论文,打算用YOLO模型做一个迁移学习,看看能不能用于项目中去.但在实践过程中感觉到对于YOLO的一些细节和技巧还是没有很好的理解,现学习其他人的博客总结(所有参考连接都附于最后 ...
- 从YOLOv1到YOLOv3,目标检测的进化之路
https://blog.csdn.net/guleileo/article/details/80581858 本文来自 CSDN 网站,作者 EasonApp. 作者专栏: http://dwz.c ...
- YOLO v1到YOLO v4(下)
YOLO v1到YOLO v4(下) Faster YOLO使用的是GoogleLeNet,比VGG-16快,YOLO完成一次前向过程只用8.52 billion 运算,而VGG-16要30.69bi ...
- 检测算法简介及其原理——fast R-CNN,faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- 论文笔记:目标检测算法(R-CNN,Fast R-CNN,Faster R-CNN,FPN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的视觉任务大多数考虑使用SIFT和HOG特征,而近年来CNN和ImageNet的出现使得图像分类问题取得重大突破,那么这方面的 ...
随机推荐
- 「JLOI2011」飞行路线
前言 看到好多大佬都在跑分层图最短路,\(\text{DP}\) 解法的我瑟瑟发抖... 题目描述 给定一张 \(N\) 个点(点编号从 \(0\) 到 \(N-1\)),\(M\) 条边的无向带权图 ...
- HTML<video></video>视频无法自动播放
1.video 标签属性 src: 设置显示视频路径 controls: 显示控制栏 loop: 控制视频循环播放 autoplay: 自动播放 muted:设置静音播放 2.解决视频或音频标签自动播 ...
- thinkphp5.1 源码阅读
传送地址:https://github.com/cshaptx4869/tp5.1-code-read 包含: 自动加载 容器 配置文件 钩子 门面
- C 语言入门---第六章 C语言数组
数组就是一些列具有相同类型的数据的集合,这些数据在内存中一次挨着存放,彼此之间没有缝隙. 我们可以将二维数组看作一个Excel表格,有行有列,length1 表示行数,length2 表示列数,要在二 ...
- 第3节 storm高级应用:4、5、ack机制,以及其验证超时
4. 消息不丢失机制 4.1.ack是什么 ack 机制是storm整个技术体系中非常闪亮的一个创新点. 通过Ack机制,spout发送出去的每一条消息,都可以确定是被成功处理或失败处理, 从而可以 ...
- Vue - 路由守卫使用
import Vue from 'vue' import VueRouter from 'vue-router' import Home from '../views/Home.vue' Vue.us ...
- [Codeforces #615 div3]1294E Obtain a Permutation
Before the Beginniing 本文为 Clouder 原创文章,原文链接为Click,转载时请将本段放在文章开头显眼处.如进行了二次创作,请明确标明. 由本人转载于博客园. 题意分析 C ...
- 导弹拦截p1020(LIS问题)
题目描述(题目链接:https://www.luogu.org/problem/P1020) 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统.但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够 ...
- 5.3 Nginx 动静分离
Server 脚本片段 server { listen ; server_name ccserver1; #charset koi8-r; access_log logs/host.access.lo ...
- CSS -- 盒子模型 margin 的特点
margin在使用过程中具有如下的两个特点: 1.垂直外边距塌陷 --给子元素设置margin-top的时候,如果父元素也随着margin-top改变位置 解决方式: 给父元素设置边框 给父元素设置o ...