Sequence Models Week 2 Operations on word vectors
Operations on word vectors
Welcome to your first assignment of this week!
Because word embeddings are very computionally expensive to train, most ML practitioners will load a pre-trained set of embeddings.
After this assignment you will be able to:
- Load pre-trained word vectors, and measure similarity using cosine similarity
- Use word embeddings to solve word analogy problems such as Man is to Woman as King is to __.
- Modify word embeddings to reduce their gender bias
Let's get started! Run the following cell to load the packages you will need.
import numpy as np
from w2v_utils import *
Next, lets load the word vectors. For this assignment, we will use 50-dimensional GloVe vectors to represent words. Run the following cell to load the word_to_vec_map.
words, word_to_vec_map = read_glove_vecs('../../readonly/glove.6B.50d.txt')
You've loaded:
words: set of words in the vocabulary.word_to_vec_map: dictionary mapping words to their GloVe vector representation.
You've seen that one-hot vectors do not do a good job capturing what words are similar. GloVe vectors provide much more useful information about the meaning of individual words. Lets now see how you can use GloVe vectors to decide how similar two words are.
1 - Cosine similarity
To measure how similar two words are, we need a way to measure the degree of similarity between two embedding vectors for the two words. Given two vectors uu and vv, cosine similarity is defined as follows:
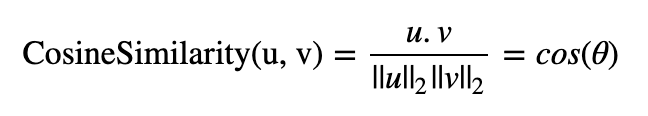
where u.vu.v is the dot product (or inner product) of two vectors, ||u||2||u||2 is the norm (or length) of the vector uu, and θθ is the angle between uu and vv. This similarity depends on the angle between uu and vv. If uu and vv are very similar, their cosine similarity will be close to 1; if they are dissimilar, the cosine similarity will take a smaller value.

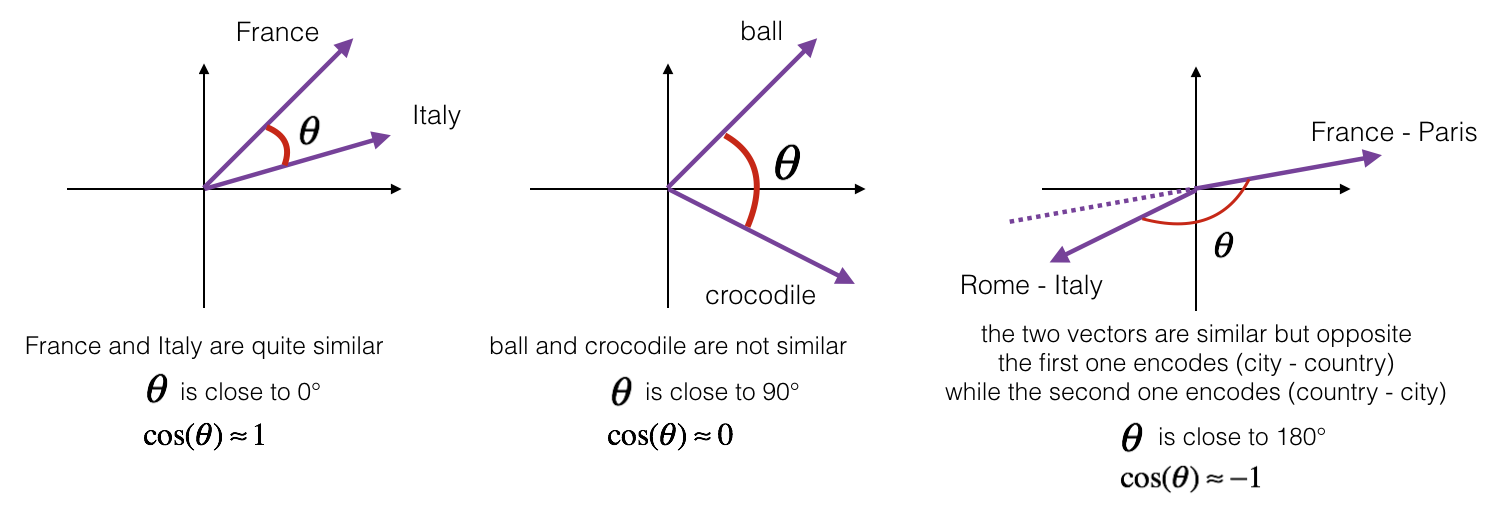 Figure 1: The cosine of the angle between two vectors is a measure of how similar they are
Figure 1: The cosine of the angle between two vectors is a measure of how similar they are
Exercise: Implement the function cosine_similarity() to evaluate similarity between word vectors.
Reminder: The norm of uu is defined as:
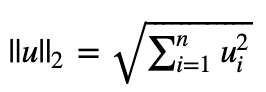
# GRADED FUNCTION: cosine_similarity
def cosine_similarity(u, v):
"""
Cosine similarity reflects the degree of similariy between u and v
Arguments:
u -- a word vector of shape (n,)
v -- a word vector of shape (n,)
Returns:
cosine_similarity -- the cosine similarity between u and v defined by the formula above.
""" distance = 0.0 ### START CODE HERE ###
# Compute the dot product between u and v (≈1 line)
dot = np.dot(u,v)
# Compute the L2 norm of u (≈1 line)
norm_u = np.sqrt(np.sum(u**2)) # Compute the L2 norm of v (≈1 line)
norm_v = np.sqrt(np.sum(v**2))
# Compute the cosine similarity defined by formula (1) (≈1 line)
cosine_similarity = (dot) / (norm_u * norm_v)
### END CODE HERE ### return cosine_similarity
father = word_to_vec_map["father"]
mother = word_to_vec_map["mother"]
ball = word_to_vec_map["ball"]
crocodile = word_to_vec_map["crocodile"]
france = word_to_vec_map["france"]
italy = word_to_vec_map["italy"]
paris = word_to_vec_map["paris"]
rome = word_to_vec_map["rome"]
print("cosine_similarity(father, mother) = ", cosine_similarity(father, mother))
print("cosine_similarity(ball, crocodile) = ",cosine_similarity(ball, crocodile))
print("cosine_similarity(france - paris, rome - italy) = ",cosine_similarity(france - paris, rome - italy))
cosine_similarity(father, mother) = 0.890903844289
cosine_similarity(ball, crocodile) = 0.274392462614
cosine_similarity(france - paris, rome - italy) = -0.675147930817
Expected Output:
| cosine_similarity(father, mother) = | 0.890903844289 |
| cosine_similarity(ball, crocodile) = | 0.274392462614 |
| cosine_similarity(france - paris, rome - italy) = | -0.675147930817 |
After you get the correct expected output, please feel free to modify the inputs and measure the cosine similarity between other pairs of words! Playing around the cosine similarity of other inputs will give you a better sense of how word vectors behave.
2 - Word analogy task
In the word analogy task, we complete the sentence "a is to b as c is to __". An example is 'man is to woman as king is to queen' . In detail, we are trying to find a word d, such that the associated word vectors ea,eb,ec,edea,eb,ec,ed are related in the following manner: eb−ea≈ed−eceb−ea≈ed−ec. We will measure the similarity between eb−eaeb−ea and ed−eced−ec using cosine similarity.
Exercise: Complete the code below to be able to perform word analogies!
father = word_to_vec_map["father"]
mother = word_to_vec_map["mother"]
ball = word_to_vec_map["ball"]
crocodile = word_to_vec_map["crocodile"]
france = word_to_vec_map["france"]
italy = word_to_vec_map["italy"]
paris = word_to_vec_map["paris"]
rome = word_to_vec_map["rome"]
print("cosine_similarity(father, mother) = ", cosine_similarity(father, mother))
print("cosine_similarity(ball, crocodile) = ",cosine_similarity(ball, crocodile))
print("cosine_similarity(france - paris, rome - italy) = ",cosine_similarity(france - paris, rome - italy))
triads_to_try = [('mother', 'grandmother', 'father'), ('girl', 'girlfriend', 'boy'), ('doctor', 'father', 'nurse'), ('small', 'smaller', 'big')]
for triad in triads_to_try:
print ('{} -> {} :: {} -> {}'.format( *triad, complete_analogy(*triad,word_to_vec_map)))
mother -> grandmother :: father -> commode #我自己重新改了几组数据来玩
girl -> girlfriend :: boy -> boyfriend
doctor -> father :: nurse -> married
small -> smaller :: big -> competitors
Expected Output:
| italy -> italian :: | spain -> spanish |
| india -> delhi :: | japan -> tokyo |
| man -> woman :: | boy -> girl |
| small -> smaller :: | large -> larger |
Once you get the correct expected output, please feel free to modify the input cells above to test your own analogies. Try to find some other analogy pairs that do work, but also find some where the algorithm doesn't give the right answer: For example, you can try small->smaller as big->?.
Congratulations!
You've come to the end of this assignment. Here are the main points you should remember:
- Cosine similarity a good way to compare similarity between pairs of word vectors. (Though L2 distance works too.)
- For NLP applications, using a pre-trained set of word vectors from the internet is often a good way to get started.
Even though you have finished the graded portions, we recommend you take a look too at the rest of this notebook.
Congratulations on finishing the graded portions of this notebook!
3 - Debiasing word vectors (OPTIONAL/UNGRADED)
In the following exercise, you will examine gender biases that can be reflected in a word embedding, and explore algorithms for reducing the bias. In addition to learning about the topic of debiasing, this exercise will also help hone your intuition about what word vectors are doing. This section involves a bit of linear algebra, though you can probably complete it even without being expert in linear algebra, and we encourage you to give it a shot. This portion of the notebook is optional and is not graded.
Lets first see how the GloVe word embeddings relate to gender. You will first compute a vector g=ewoman−emang=ewoman−eman, where ewomanewoman represents the word vector corresponding to the word woman, and emaneman corresponds to the word vector corresponding to the word man. The resulting vector gg roughly encodes the concept of "gender". (You might get a more accurate representation if you compute g1=emother−efatherg1=emother−efather, g2=egirl−eboyg2=egirl−eboy, etc. and average over them. But just using ewoman−emanewoman−eman will give good enough results for now.)
g = word_to_vec_map['woman'] - word_to_vec_map['man']
print(g)
[-0.087144 0.2182 -0.40986 -0.03922 -0.1032 0.94165
-0.06042 0.32988 0.46144 -0.35962 0.31102 -0.86824
0.96006 0.01073 0.24337 0.08193 -1.02722 -0.21122
0.695044 -0.00222 0.29106 0.5053 -0.099454 0.40445
0.30181 0.1355 -0.0606 -0.07131 -0.19245 -0.06115
-0.3204 0.07165 -0.13337 -0.25068714 -0.14293 -0.224957
-0.149 0.048882 0.12191 -0.27362 -0.165476 -0.20426
0.54376 -0.271425 -0.10245 -0.32108 0.2516 -0.33455
-0.04371 0.01258 ]
Now, you will consider the cosine similarity of different words with gg. Consider what a positive value of similarity means vs a negative cosine similarity.
print ('List of names and their similarities with constructed vector:')
# girls and boys name
name_list = ['john', 'marie', 'sophie', 'ronaldo', 'priya', 'rahul', 'danielle', 'reza', 'katy', 'yasmin']
for w in name_list:
print (w, cosine_similarity(word_to_vec_map[w], g))
List of names and their similarities with constructed vector:
john -0.23163356146
marie 0.315597935396
sophie 0.318687898594
ronaldo -0.312447968503
priya 0.17632041839
rahul -0.169154710392
danielle 0.243932992163
reza -0.079304296722
katy 0.283106865957
yasmin 0.233138577679
As you can see, female first names tend to have a positive cosine similarity with our constructed vector gg, while male first names tend to have a negative cosine similarity. This is not suprising, and the result seems acceptable.
But let's try with some other words.
print('Other words and their similarities:')
word_list = ['lipstick', 'guns', 'science', 'arts', 'literature', 'warrior','doctor', 'tree', 'receptionist',
'technology', 'fashion', 'teacher', 'engineer', 'pilot', 'computer', 'singer']
for w in word_list:
print (w, cosine_similarity(word_to_vec_map[w], g))
Other words and their similarities:
lipstick 0.276919162564
guns -0.18884855679
science -0.0608290654093
arts 0.00818931238588
literature 0.0647250443346
warrior -0.209201646411
doctor 0.118952894109
tree -0.0708939917548
receptionist 0.330779417506
technology -0.131937324476
fashion 0.0356389462577
teacher 0.179209234318
engineer -0.0803928049452
pilot 0.00107644989919
computer -0.103303588739
singer 0.185005181365
Do you notice anything surprising? It is astonishing how these results reflect certain unhealthy gender stereotypes. For example, "computer" is closer to "man" while "literature" is closer to "woman". Ouch!
We'll see below how to reduce the bias of these vectors, using an algorithm due to Boliukbasi et al., 2016. Note that some word pairs such as "actor"/"actress" or "grandmother"/"grandfather" should remain gender specific, while other words such as "receptionist" or "technology" should be neutralized, i.e. not be gender-related. You will have to treat these two type of words differently when debiasing.
3.1 - Neutralize bias for non-gender specific words
The figure below should help you visualize what neutralizing does. If you're using a 50-dimensional word embedding, the 50 dimensional space can be split into two parts: The bias-direction gg, and the remaining 49 dimensions, which we'll call g⊥g⊥. In linear algebra, we say that the 49 dimensional g⊥g⊥ is perpendicular (or "orthogonal") to gg, meaning it is at 90 degrees to gg. The neutralization step takes a vector such as ereceptionistereceptionist and zeros out the component in the direction of gg, giving us edebiasedreceptionistereceptionistdebiased.
Even though g⊥g⊥ is 49 dimensional, given the limitations of what we can draw on a screen, we illustrate it using a 1 dimensional axis below.

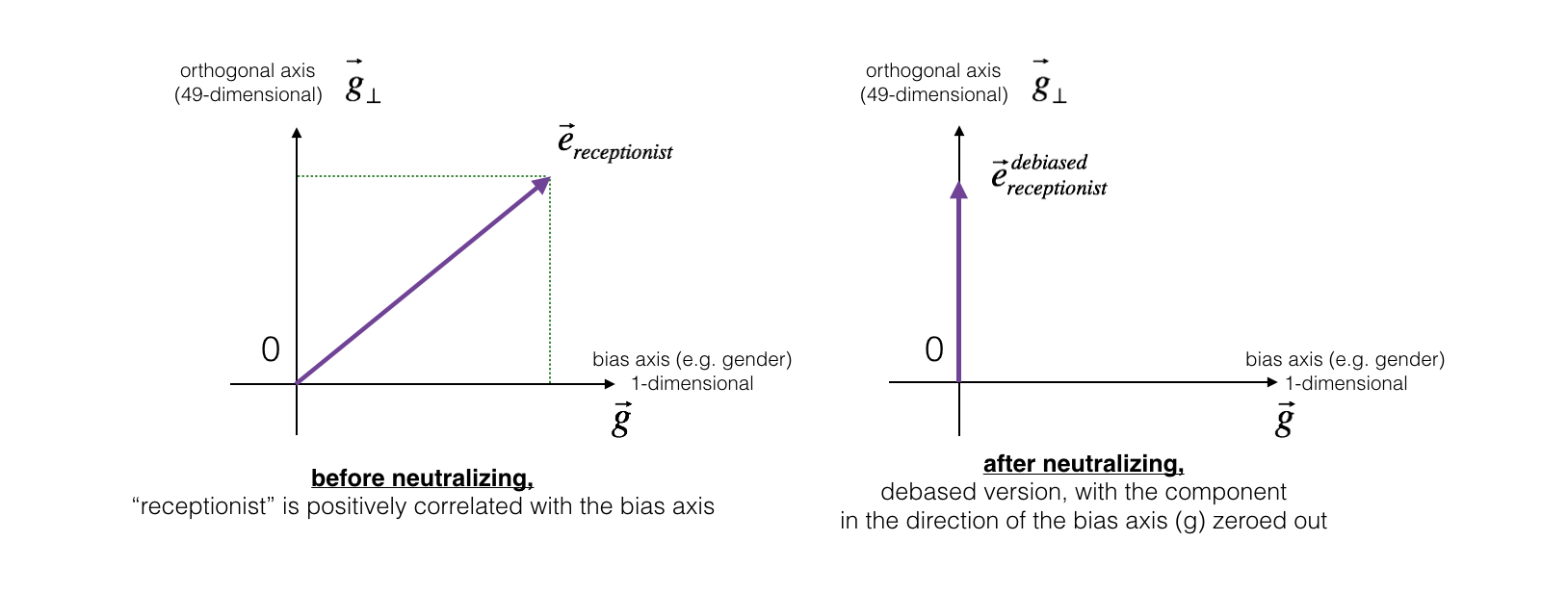 Figure 2: The word vector for "receptionist" represented before and after applying the neutralize operation.
Figure 2: The word vector for "receptionist" represented before and after applying the neutralize operation.
Exercise: Implement neutralize() to remove the bias of words such as "receptionist" or "scientist". Given an input embedding ee, you can use the following formulas to compute edebiasededebiased:
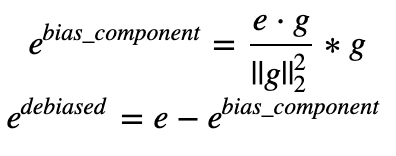
If you are an expert in linear algebra, you may recognize ebias_componentebias_component as the projection of ee onto the direction gg. If you're not an expert in linear algebra, don't worry about this.
def neutralize(word, g, word_to_vec_map):
"""
Removes the bias of "word" by projecting it on the space orthogonal to the bias axis.
This function ensures that gender neutral words are zero in the gender subspace.
Arguments:
word -- string indicating the word to debias
g -- numpy-array of shape (50,), corresponding to the bias axis (such as gender)
word_to_vec_map -- dictionary mapping words to their corresponding vectors.
Returns:
e_debiased -- neutralized word vector representation of the input "word"
""" ### START CODE HERE ###
# Select word vector representation of "word". Use word_to_vec_map. (≈ 1 line)
e = word_to_vec_map[word] # Compute e_biascomponent using the formula give above. (≈ 1 line)
e_biascomponent = np.dot(e,g) / np.sum(g*g) * g # Neutralize e by substracting e_biascomponent from it
# e_debiased should be equal to its orthogonal projection. (≈ 1 line)
e_debiased = e - e_biascomponent
### END CODE HERE ### return e_debiased
e = "receptionist"
print("cosine similarity between " + e + " and g, before neutralizing: ", cosine_similarity(word_to_vec_map["receptionist"], g))
e_debiased = neutralize("receptionist", g, word_to_vec_map)
print("cosine similarity between " + e + " and g, after neutralizing: ", cosine_similarity(e_debiased, g))
cosine similarity between receptionist and g, before neutralizing: 0.330779417506
cosine similarity between receptionist and g, after neutralizing: -4.08872263257e-17
Expected Output: The second result is essentially 0, up to numerical roundof (on the order of 10−1710−17).
| cosine similarity between receptionist and g, before neutralizing: : | 0.330779417506 |
| cosine similarity between receptionist and g, after neutralizing: : | -3.26732746085e-17 |
3.2 - Equalization algorithm for gender-specific words
Next, lets see how debiasing can also be applied to word pairs such as "actress" and "actor." Equalization is applied to pairs of words that you might want to have differ only through the gender property. As a concrete example, suppose that "actress" is closer to "babysit" than "actor." By applying neutralizing to "babysit" we can reduce the gender-stereotype associated with babysitting. But this still does not guarantee that "actor" and "actress" are equidistant from "babysit." The equalization algorithm takes care of this.
The key idea behind equalization is to make sure that a particular pair of words are equi-distant from the 49-dimensional g⊥g⊥. The equalization step also ensures that the two equalized steps are now the same distance from edebiasedreceptionistereceptionistdebiased, or from any other work that has been neutralized. In pictures, this is how equalization works:
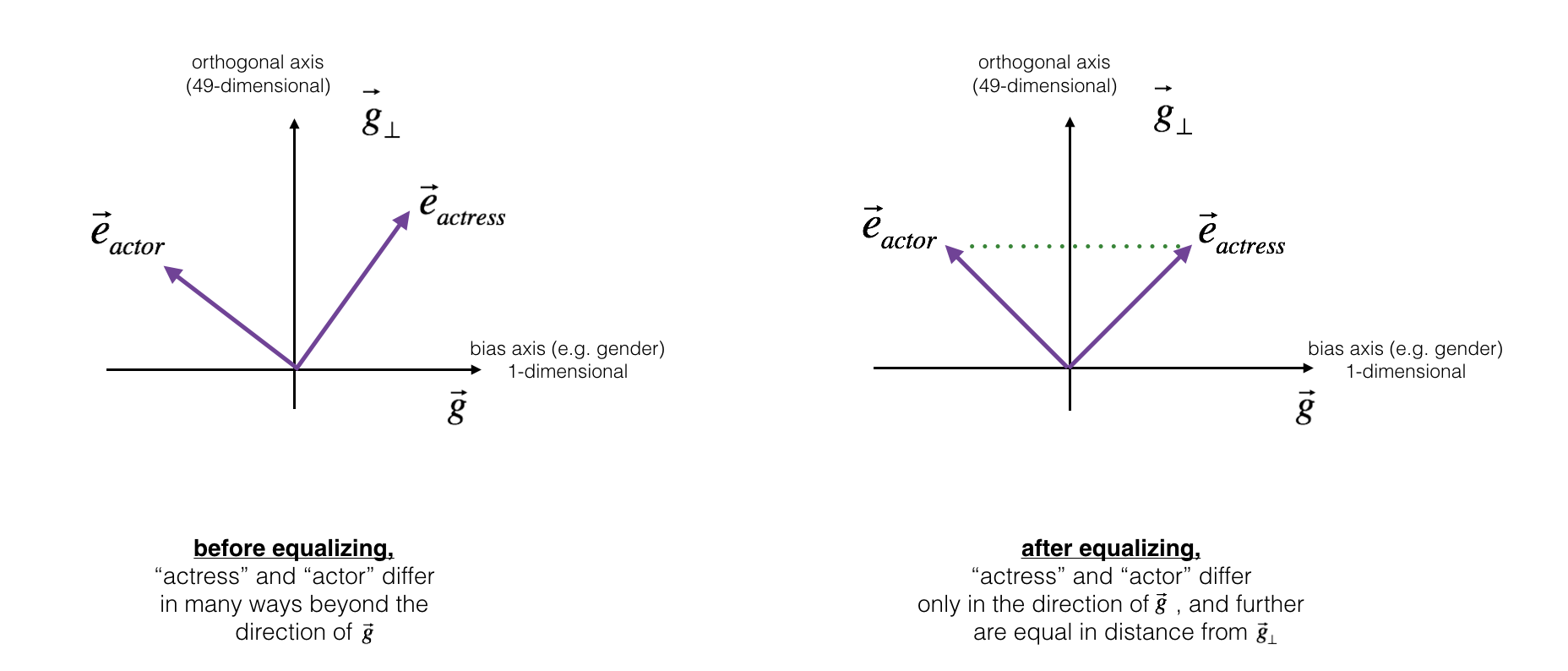

The derivation of the linear algebra to do this is a bit more complex. (See Bolukbasi et al., 2016 for details.) But the key equations are:
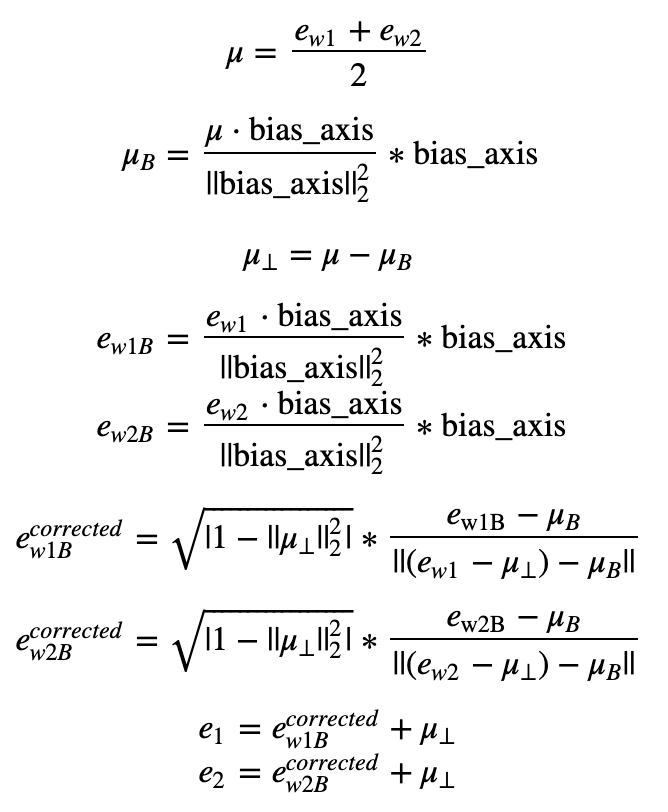
Exercise: Implement the function below. Use the equations above to get the final equalized version of the pair of words. Good luck!
def equalize(pair, bias_axis, word_to_vec_map):
"""
Debias gender specific words by following the equalize method described in the figure above.
Arguments:
pair -- pair of strings of gender specific words to debias, e.g. ("actress", "actor")
bias_axis -- numpy-array of shape (50,), vector corresponding to the bias axis, e.g. gender
word_to_vec_map -- dictionary mapping words to their corresponding vectors
Returns
e_1 -- word vector corresponding to the first word
e_2 -- word vector corresponding to the second word
""" #测试手写二范数和函数算得是否一样, 结果相同
print(np.sum(bias_axis**2))
print(np.linalg.norm(bias_axis, ord=2)**2) ### START CODE HERE ###
# Step 1: Select word vector representation of "word". Use word_to_vec_map. (≈ 2 lines)
w1, w2 = pair
e_w1, e_w2 = word_to_vec_map[w1], word_to_vec_map[w2] # Step 2: Compute the mean of e_w1 and e_w2 (≈ 1 line)
mu = (e_w1 + e_w2) / 2 # Step 3: Compute the projections of mu over the bias axis and the orthogonal axis (≈ 2 lines)
mu_B = np.dot(mu, bias_axis) / np.sum(bias_axis**2) * bias_axis
mu_orth = mu - mu_B
# Step 4: Use equations (7) and (8) to compute e_w1B and e_w2B (≈2 lines)
e_w1B = np.dot(e_w1, bias_axis) / np.sum(bias_axis**2) * bias_axis
e_w2B = np.dot(e_w2, bias_axis) / np.sum(bias_axis**2) * bias_axis # Step 5: Adjust the Bias part of e_w1B and e_w2B using the formulas (9) and (10) given above (≈2 lines)
corrected_e_w1B = np.sqrt(np.fabs(1-np.sum(mu_orth**2))) * (e_w1B - mu_B) / np.linalg.norm((e_w1-mu_orth)-mu_B)
corrected_e_w2B = np.sqrt(np.fabs(1-np.sum(mu_orth**2))) * (e_w2B - mu_B) / np.linalg.norm((e_w2-mu_orth)-mu_B)
# Step 6: Debias by equalizing e1 and e2 to the sum of their corrected projections (≈2 lines)
e1 = corrected_e_w1B + mu_orth
e2 = corrected_e_w2B + mu_orth ### END CODE HERE ### return e1, e2
print("cosine similarities before equalizing:")
print("cosine_similarity(word_to_vec_map[\"man\"], gender) = ", cosine_similarity(word_to_vec_map["man"], g))
print("cosine_similarity(word_to_vec_map[\"woman\"], gender) = ", cosine_similarity(word_to_vec_map["woman"], g))
print()
e1, e2 = equalize(("man", "woman"), g, word_to_vec_map)
print("cosine similarities after equalizing:")
print("cosine_similarity(e1, gender) = ", cosine_similarity(e1, g))
print("cosine_similarity(e2, gender) = ", cosine_similarity(e2, g))
cosine similarities before equalizing:
cosine_similarity(word_to_vec_map["man"], gender) = -0.117110957653
cosine_similarity(word_to_vec_map["woman"], gender) = 0.356666188463 6.77364951592
6.77364951592
cosine similarities after equalizing:
cosine_similarity(e1, gender) = -0.700436428931
cosine_similarity(e2, gender) = 0.700436428931
Expected Output:
cosine similarities before equalizing:
| cosine_similarity(word_to_vec_map["man"], gender) = | -0.117110957653 |
| cosine_similarity(word_to_vec_map["woman"], gender) = | 0.356666188463 |
cosine similarities after equalizing:
| cosine_similarity(u1, gender) = | -0.700436428931 |
| cosine_similarity(u2, gender) = | 0.700436428931 |
Please feel free to play with the input words in the cell above, to apply equalization to other pairs of words.
These debiasing algorithms are very helpful for reducing bias, but are not perfect and do not eliminate all traces of bias. For example, one weakness of this implementation was that the bias direction gg was defined using only the pair of words woman and man. As discussed earlier, if gg were defined by computing g1=ewoman−emang1=ewoman−eman; g2=emother−efatherg2=emother−efather; g3=egirl−eboyg3=egirl−eboy; and so on and averaging over them, you would obtain a better estimate of the "gender" dimension in the 50 dimensional word embedding space. Feel free to play with such variants as well.
Congratulations
You have come to the end of this notebook, and have seen a lot of the ways that word vectors can be used as well as modified.
Congratulations on finishing this notebook!
References:
- The debiasing algorithm is from Bolukbasi et al., 2016, Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings
- The GloVe word embeddings were due to Jeffrey Pennington, Richard Socher, and Christopher D. Manning. (https://nlp.stanford.edu/projects/glove/)
Sequence Models Week 2 Operations on word vectors的更多相关文章
- 课程五(Sequence Models),第二 周(Natural Language Processing & Word Embeddings) —— 1.Programming assignments:Operations on word vectors - Debiasing
Operations on word vectors Welcome to your first assignment of this week! Because word embeddings ar ...
- [C5W2] Sequence Models - Natural Language Processing and Word Embeddings
第二周 自然语言处理与词嵌入(Natural Language Processing and Word Embeddings) 词汇表征(Word Representation) 上周我们学习了 RN ...
- Coursera, Deep Learning 5, Sequence Models, week2, Natural Language Processing & Word Embeddings
Word embeding 给word 加feature,用来区分word 之间的不同,或者识别word之间的相似性. 用于学习 Embeding matrix E 的数据集非常大,比如 1B - 1 ...
- 吴恩达《深度学习》-课后测验-第五门课 序列模型(Sequence Models)-Week 2: Natural Language Processing and Word Embeddings (第二周测验:自然语言处理与词嵌入)
Week 2 Quiz: Natural Language Processing and Word Embeddings (第二周测验:自然语言处理与词嵌入) 1.Suppose you learn ...
- 课程五(Sequence Models),第二 周(Natural Language Processing & Word Embeddings) —— 0.Practice questions:Natural Language Processing & Word Embeddings
[解释] The dimension of word vectors is usually smaller than the size of the vocabulary. Most common s ...
- Sequence Models 笔记(二)
2 Natural Language Processing & Word Embeddings 2.1 Word Representation(单词表达) vocabulary,每个单词可以使 ...
- Sequence Models
Sequence Models This is the fifth and final course of the deep learning specialization at Coursera w ...
- [C7] Andrew Ng - Sequence Models
About this Course This course will teach you how to build models for natural language, audio, and ot ...
- Coursera, Deep Learning 5, Sequence Models, week3, Sequence models & Attention mechanism
Sequence to Sequence models basic sequence-to-sequence model: basic image-to-sequence or called imag ...
随机推荐
- SpringBoot邮件推送功能
鞠躬,道歉 抱歉,迟到了近一年的更新,这一年挺忙的,发生了很多事情,就厚脸皮拖更了,抱歉. 现在状态回来了,打算分享下近期学到的东西,这一年期间学到的东西可能会随意更新,其实也就是玩了下C# + un ...
- 小程序包大小超过2M的解决方法
小程序的包被限制在2M以下, 超出的时候点击预览, 发现报错: Error: 代码包大小为 3701 kb,上限为 2048 kb,请删除文件后重试 1. 优化代码, 删除掉不用的代码 2. 图片压缩 ...
- Windows上设置Sass
现在有很多信息在预处理器上浮动.大部分信息都面向Mac用户,所以在这篇文章中,我提供了一个非常简单的指南,帮助基于Windows的开发人员快速启动并运行Sass(我选择的预处理器). 本文是在此博客上 ...
- 零距离初体验uboot
一.uboot配置编译步骤 1.开发板光盘的BSP 2.复制到虚拟机,tar -jxvf qt_x210v3_130807.tar.bz2 3.配置:make x210_sd_config 4.出现C ...
- Centos 7 安装与卸载MYSQL5.7
先介绍卸载防止重装 yum方式 查看yum是否安装过mysqlyum list installed mysql*如或显示了列表,说明系统中有MySQL yum卸载 根据列表上的名字 yum remov ...
- python基础学习(一)
一,Python介绍 1,python的出生与应用 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆(中文名字:龟叔)为了在阿姆斯特丹打 ...
- java csv文件写入
List<String> list_code = null; 方案1 控制字符集: BufferedWriter bw=new BufferedWriter(new OutputStrea ...
- 使用 HTML5 视频事件
转自:http://msdn.microsoft.com/zh-cn/library/hh924822(v=vs.85).aspx 为什么要使用事件? HTML5 视频对象提供了很多事件,这些事件可以 ...
- 20170430深圳Meetup
一.类似于淘宝网,可以连续选择多个商品筛选条件,这多个参数如何传递到后台,进行数据交互? 方案一: def index // 给view提供多个参数 @param1 = ... @param2 = . ...
- 【Leetcode】交替打印FooBar
[问题]我们提供一个类: class FooBar { public void foo() { ; i < n; i++) { print("foo"); } } publi ...