Neural Turing Machine - 神经图灵机
Neural Turing Machine - 神经图灵机
论文原文地址: http://arxiv.org/pdf/1410.5401.pdf
一般的神经网络不具有记忆功能,输出的结果只基于当前的输入;而LSTM网络的出现则让网络有了记忆:能够根据之前的输入给出当前的输出。但是,LSTM的记忆程度并不是那么理想,对于比较长的输入序列,LSTM的最终输出只与最后的几步输入有关,也就是long dependency问题,当然这个问题可以由注意力机制解决,然而却不能从根本上解决长期记忆的问题,原因是由于LSTM是假设在时间序列上的输入输出:由t-1时刻得到t时刻的输出,然后再循环输入t时刻的结果得到t+1时刻的输出,这样势必会使处于前面序列的输入被淹没,导致这部分记忆被“丢掉“。
神经图灵机通过引入外部记忆解决了这个问题。 举个简单的例子,我们人类在记忆一些事情的时候,除了用脑袋记,还会写在备忘录上,当我们想不起来的时候,就可以去翻阅备忘录,从而获得相关的记忆。神经图灵机模仿人类记忆的过程:其中的控制器(controller)相当于我们人类的大脑,用于把输入事物的特征提取出来;外部记忆(memory)相当于我们的备忘录,把事物的特征记录在上面,那么完整的过程就是:控制器将当前输入转化为特征,写入记忆,再读取与当前输入特征有关的记忆作为最后的输出。整个过程与图灵机的读写很像,只不过神经图灵机这里让所有的读写操作都可微分化,因此可以用神经网络误差后向传播的方式去训练模型。
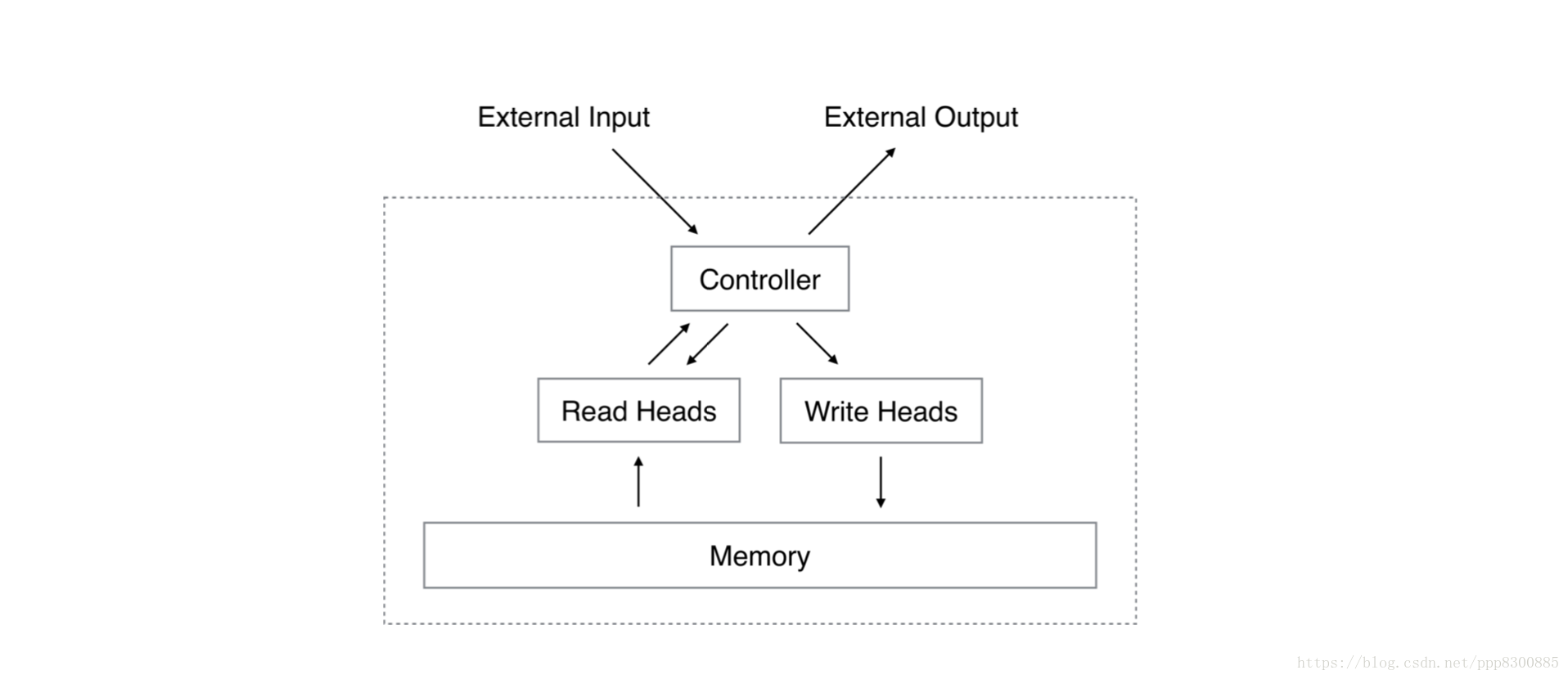
那么问题就来了,当获得一个输入的特征后,我们如何确定在记忆中储存的位置,而且如何从记忆中获取与当前输入相关的信息呢?这就是接下来要分析的神经图灵机主要工作。
Neural Turning Machine

1. 读记忆 (Read Heads)
我们把记忆看作是一个$N × M$的矩阵$M_t$,t表示当前时刻, 表示记忆会随着时间发生变化。我们的读过程就是生成一个定位权值向量$w_t$,长度为$N$,表示N个位置对应的记忆权值大小,最后读出的记忆向量$r_t$为:
$$r_t= \displaystyle\sum^N_i{w_t(i)M_t(i)}$$
其中权值向量的和为1: $\sum_i{W_t(i)}=1$,本质上是一个对N条记忆进行一个加权求和的思想。
2. 写记忆(Write Heads)
神经图灵机的写过程参考了LSTM的门的概念:先用输入门决定增加的信息,再用遗忘门决定要丢弃的信息,最后用更新门加上增加的信息并减去丢弃的信息。具体来说,神经图灵机会生成一个擦除向量$e_t$ (erase vector) 和一个增加向量$a_t$ (add vector),长度都为$N$,向量中每个元素的值大小范围从0到1,表示要增加或者删除的信息。对于写记忆过程,神经图灵机首先执行一个擦除操作,擦除程度的大小同样由向量$w_t$决定:
$$M_t^′=M_{t-1}(i)(1-w_t(i)e_t(i))$$
这个操作表示从$t−1$时刻的记忆中丢弃了一些信息,若$w_t$和$e_t$同时为0,则表示记忆没有丢弃信息,当前记忆与$t−1$时刻保持不变。执行完擦除后,然后执行增加操作:
$$M_t(i)=M_t^,(i)+w_t(i)a_t(i)a$$
这步表示在丢弃一些信息后需要新增的信息,同样,若$w_t$和$a_t$都为0,表示当前记忆无新增,与擦除后的记忆保持一致。其中,$e_t$和$a_t$都是由控制器给出,而控制器基本上由神经网络实现,可以是LSTM,也可以是MLP。
由于整个过程都是都是矩阵的加减乘除,所有的读写操作都是可微分的,因此我们可以用梯度下降法训练整个参数模型。但是接下来,我们需要确定$w_t$定位向量,由于这个向量直接决定着当前输入与记忆的相关性,因此神经图灵机在生成$w_t$向量上做了很多工作。
3. 定位机制(Addressing Mechanism)
关于决定其相关性的方法有很多,主要分为两大类: 基于内容的(content-based)和基于位置的(location-based)。神经图灵机结合了这两个方法提出一个定位机制用于生成定位向量$w_t$,具体来说,先用基于内容的方法,再用基于位置的方法。
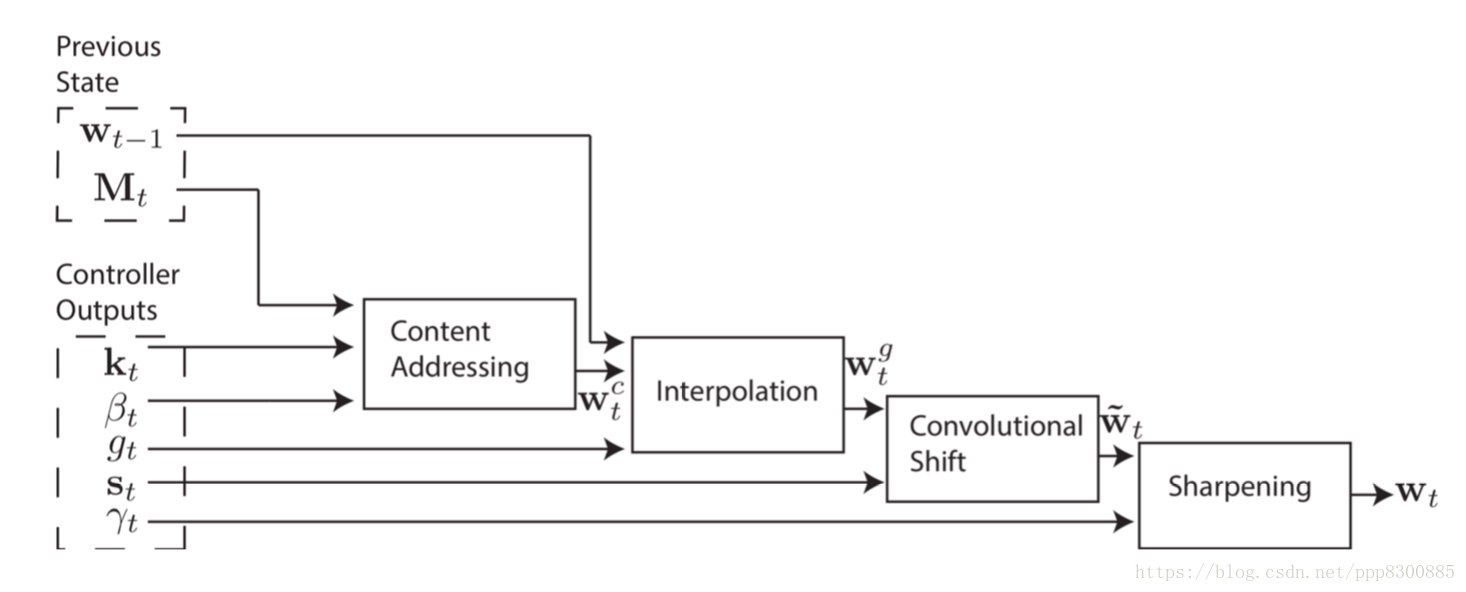
3.1 Content-based Addressing
基于内容的定位计算主要基于余弦相似度:首先控制器给出一个$k_t$向量作为查询的key,然后计算$k_t$与$M_t$中各个记忆向量的余弦相似度,最后经过一个softmax操作得到基于内容的定位向量$w_t^c$:
$$w_t^c(i)=\frac{exp(\beta_tK[k_t,M_t(i)])}{\sum_jexp(\beta_tK[k_t,M_t(j)}$$
其中$K[..,.]$是余弦相似度计算:
$$K[u,v]=\frac{u⋅v}{||u||⋅||u||}$$
3.2 Location-based Addressing
3.2.1. Interpolation(插值)
控制器生成一个阈值$g_t$对当前的内容定位向量$w_tc$与$t-1$时刻的定位向量$w_{t-1}$进行一个插值操作,插值的结果即为输出值$w_tg$:
$$w_tg=g_tw_tc+(1-g_t)w_{t-1}$$
这里的插值操作可以理解为LSTM的更新门,结合过去的$w$权值计算新的$w$
3.2.2. shift(偏移)
对于$w_tg$中的每个位置元素$w_tg(i)$ ,我们考虑它相邻的k个偏移元素,认为这k个元素与$w_tg(i)$相关,如当k=3时,三个相邻元素分别是:$w_tg(i)$本身和位置偏移为1的元素$w_tg(i-1)$和$w_tg(i+1)$,此时,我们希望新的位置为i的元素能包含这三个元素,因此用一个长度为3的偏移权值向量$s_t$来表示这三个元素的权重,然后权值求和得到输出值$w_t^′$:
$$w_t′(i)=\displaystyle\sum_{j=-1}{1}{w_t^g(i+j)s(j+1)}$$
这里的偏移操作在原文中用的是循环卷积(circular convolution)公式表示的,我们可以理解为把向量$w_t^g$首尾相连形成一个环状,然后在环中用$s_t$作为卷积核做一维卷积操作。本质上是假设当前元素与相邻的偏移元素相关。
3.2.3. Sharping(重塑)
当偏移操作中的权值比较平均的时候,上述的卷积操作会导致数据的分散(dispersion)和泄漏(leakage),就像把一个点的信息分散在三个点中,权值如果太平均会使三个点包含的值太模糊(个人理解),因此需要把权值大小的区别进行强化,也就是sharping。具体来说,控制器生成一个参数$\gamma_t>1$,然后对各个权值进行$\gamma_t$指数然后归一化:
$$w_t(i)=\frac{w_t′(i){\gamma_t}}{\sum_jw′_t(j){\gamma_t}}$$
最后我们得出了最终的$w_t$用于提取和储存记忆。
Pytorch实现
我将原代码中最重要的NTM模块单独取出,并增加了如何简单使用的代码,读者可以直接下载加入到自己的模型中使用,代码已经上传到我的Github,点击这里查看————》NTM代码
这里代码基于的是pytorch-ntm,代码写的相当工整,可读性很高,这里只分析一些重要的步骤:
读过程
读过程就是从控制器(LTSM)输出的值提取我们需要的k, beta, g, s, gama值,然后调用_address_memory获得当前的定位权值向量w, 再用矩阵乘法获得读过程的输出 :
def forward(self, embeddings, w_prev):
"""NTMReadHead forward function.
:param embeddings: input representation of the controller.
:param w_prev: previous step state
"""
o = self.fc_read(embeddings)
k, beta, g, s, gama = _split_cols(o, self.read_lengths)
# Read from memory
w = self._address_memory(k, beta, g, s, gama, w_prev)
r = self.memory.read(w)
return r, w
def read(self, w):
"""Read from memory (according to section 3.1)."""
return torch.matmul(w.unsqueeze(1), self.memory).squeeze(1)
写过程
写过程同样是获得定位机制需要的k,beta, g, s, gama以及需要擦除的向量e和增加的向量a,然后调用_address_memory获得定位向量w,然后根据e和a计算得出最后的写入向量 :
def forward(self, embeddings, w_prev):
"""NTMWriteHead forward function.
:param embeddings: input representation of the controller.
:param w_prev: previous step state
"""
o = self.fc_write(embeddings)
k, beta, g, s, gama, e, a = _split_cols(o, self.write_lengths)
# e should be in [0, 1]
e = F.sigmoid(e)
# Write to memory
w = self._address_memory(k, beta, g, s, gama, w_prev)
self.memory.write(w, e, a)
return w
def write(self, w, e, a):
"""write to memory (according to section 3.2)."""
self.prev_mem = self.memory
self.memory = Variable(torch.Tensor(self.batch_size, self.N, self.M))
erase = torch.matmul(w.unsqueeze(-1), e.unsqueeze(1))
add = torch.matmul(w.unsqueeze(-1), a.unsqueeze(1))
self.memory = self.prev_mem * (1 - erase) + add
Addressing Mechanism
定位机制的计算非常直观,首先_similarity方法计算余弦相似读获得wc,然后调用_interpolate与过去的w_prev进行插值操作,接着_shift偏移操作,这里实际上调用的是_convolve循环卷积方法,最后进行_sharpen操作获得最终的w :
def address(self, k, beta, g, s, gama, w_prev):
# Content focus
wc = self._similarity(k, beta)
# Location focus
wg = self._interpolate(w_prev, wc, g)
w1 = self._shift(wg, s)
w = self._sharpen(w1, gama)
return w
def _similarity(self, k, beta):
k = k.view(self.batch_size, 1, -1)
w = F.softmax(beta * F.cosine_similarity(self.memory + 1e-16, k + 1e-16, dim=-1), dim=1)
return w
def _interpolate(self, w_prev, wc, g):
return g * wc + (1 - g) * w_prev
def _shift(self, wg, s):
result = Variable(torch.zeros(wg.size()))
for b in range(self.batch_size):
result[b] = _convolve(wg[b], s[b])
return result
def _sharpen(self, w1, gamma):
w = w1 ** gamma
w = torch.div(w, torch.sum(w, dim=1).view(-1, 1) + 1e-16)
return w
def _convolve(w, s):
"""Circular convolution implementation."""
assert s.size(0) == 3
t = torch.cat([w[-1:], w, w[:1]])
c = F.conv1d(t.view(1, 1, -1), s.view(1, 1, -1)).view(-1)
return c
训练过程
首先输入一系列的数据,每次输入一个样本,都先后进行读和写过程,然后在不给定输入的情况下,获得一系列输出值,每次获得一个输出值时,同样先后进行着读和写过程;只不过输出的时候控制器接受的是0向量,而输入数据的时候控制器接受的是样本x值。我们可以根据输出的值与样本label的差距计算loss,对于copy任务来说,输入样本和label都是样本本身,损失可以使用binary entropy loss,最后梯度下降法更新整合模型参数:
def train_batch(net, criterion, optimizer, X, Y):
"""Trains a single batch."""
optimizer.zero_grad()
inp_seq_len = X.size(0)
outp_seq_len, batch_size, _ = Y.size()
# New sequence
net.init_sequence(batch_size)
# Feed the sequence + delimiter
for i in range(inp_seq_len):
net(X[i])
# Read the output (no input given)
y_out = Variable(torch.zeros(Y.size()))
for i in range(outp_seq_len):
y_out[i], _ = net()
loss = criterion(y_out, Y)
loss.backward()
clip_grads(net)
optimizer.step()
y_out_binarized = y_out.clone().data
y_out_binarized.apply_(lambda x: 0 if x < 0.5 else 1)
# The cost is the number of error bits per sequence
cost = torch.sum(torch.abs(y_out_binarized - Y.data))
return loss.data[0], cost / batch_size
# 每次调用net(x)或者net()获得输出值的forward方法
def forward(self, x, prev_state):
"""NTM forward function.
:param x: input vector (batch_size x num_inputs)
:param prev_state: The previous state of the NTM
"""
# Unpack the previous state
prev_reads, prev_controller_state, prev_heads_states = prev_state
# Use the controller to get an embeddings
inp = torch.cat([x] + prev_reads, dim=1)
controller_outp, controller_state = self.controller(inp, prev_controller_state)
# Read/Write from the list of heads
reads = []
heads_states = []
for head, prev_head_state in zip(self.heads, prev_heads_states):
if head.is_read_head():
r, head_state = head(controller_outp, prev_head_state)
reads += [r]
else:
head_state = head(controller_outp, prev_head_state)
heads_states += [head_state]
# Generate Output
inp2 = torch.cat([controller_outp] + reads, dim=1)
o = F.sigmoid(self.fc(inp2))
# Pack the current state
state = (reads, controller_state, heads_states)
return o, state
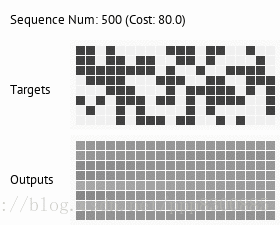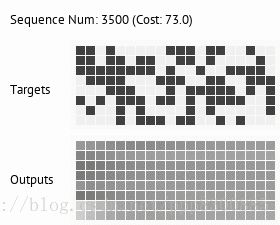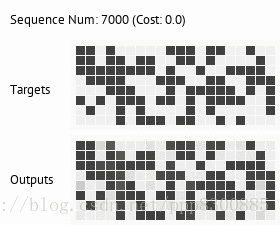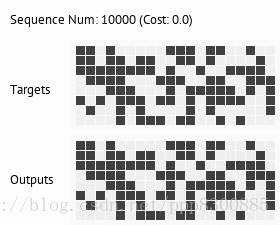
关于训练结果,可以去github里看,目前只有copy和deepcopy两个任务,应该是分开训练,但是按照前面分析的,神经图灵机应该是可以先后训练多个任务,并且保持新的任务不会覆盖旧的任务,从理论上分析,如果让记忆矩阵非常大,那么就可以把每个任务储存到记忆中不同的块中,保持记忆矩阵的稀疏性,是可以做到任务间不互相干涉,因此让模型达到能学习多个任务的能力。谷歌16年在Nature中提出的DNC其实也就是神经图灵机,论文里介绍了一些现在神经图灵机可以完成的通用任务,想了解神经图灵机具体应用的可以去看看。下面放出论文地址和代码地址:
神经图灵机(NTM):https://arxiv.org/abs/1410.5401
————————————————
版权声明:本文为CSDN博主「ppp8300885」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/ppp8300885/article/details/80383246
Neural Turing Machine - 神经图灵机的更多相关文章
- 短文对话的神经反应机 -- Neural Responding Machine for Short-Text Conversation学习笔记
最近学习了一篇ACL会议上的文章,讲的是做一个短文对话的神经反映机, 原文: 会议:ACL(2015) 文章条目: Lifeng Shang, Zhengdong Lu, Hang Li: Ne ...
- Neural Turing Machines-NTM系列(一)简述
Neural Turing Machines-NTM系列(一)简述 NTM是一种使用Neural Network为基础来实现传统图灵机的理论计算模型.利用该模型.能够通过训练的方式让系统"学 ...
- Phrase-Based & Neural Unsupervised Machine Translation基于短语非监督机器翻译
1. 前言 本文介绍一种无监督的机器翻译的模型.无监督机器翻译最早是<UNSUPERVISED NEURAL MACHINE TRANSLATION>提出.这个模型主要的特点,无需使用平行 ...
- 神经网络图灵机(Neural Turing Machines, NTM)
近期,Google Deep Mind团队提出了一个机器学习模型,并起了一个特别高大上的名字:神经网络图灵机,我为大家翻译了这篇文章,翻译得不是特别好,有些语句没读明白,欢迎大家批评指正 原论文出处 ...
- 图灵机(Turing Machine)
图灵机,又称图灵计算.图灵计算机,是由数学家阿兰·麦席森·图灵(1912-1954)提出的一种抽象计算模型,即将人们使用纸笔进行数学运算的过程进行抽象,由一个虚拟的机器替代人们进行数学运算. 所谓的图 ...
- AI人工智能专业词汇集
作为最早关注人工智能技术的媒体,机器之心在编译国外技术博客.论文.专家观点等内容上已经积累了超过两年多的经验.期间,从无到有,机器之心的编译团队一直在积累专业词汇.虽然有很多的文章因为专业性我们没能尽 ...
- 【机器学习笔记】循环神经网络RNN
1. 从一个栗子开始 - Slot Filling 比如在一个订票系统上,我们的输入 "Arrive Taipei on November 2nd" 这样一个序列,我们设置几个槽位 ...
- 【机器学习Machine Learning】资料大全
昨天总结了深度学习的资料,今天把机器学习的资料也总结一下(友情提示:有些网站需要"科学上网"^_^) 推荐几本好书: 1.Pattern Recognition and Machi ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料【转】
转自:机器学习(Machine Learning)&深度学习(Deep Learning)资料 <Brief History of Machine Learning> 介绍:这是一 ...
随机推荐
- mysql统计指定数据库的各表的条数
mysql统计指定数据库的各表的条数 SELECT table_schema,table_name,table_rows,CREATE_TIME FROM TABLES WHERE TABLE_SCH ...
- SpringBoot 1.5.x 集成 Quartz 任务调度框架
Quartz 有分 内存方式 和 数据库方式 内存方式任务信息保存在内存中, 停机会丢失, 需手动重新执行, 数据库方式: 任务信息保存在数据库中, 重点是支持集群. 内存方式 RAMJobStore ...
- 文件操作符|-e|-M|-s|-A|_|-r -w $filename|stat|localtime|&|>>|<<
TTY:终端是一种字符型设备,它有多种类型,通常使用tty 来简称各种类型的终端设备 #!/usr/bin/perl use strict; use warnings; print "exi ...
- [JSOI2019]神经网络(树形DP+容斥+生成函数)
首先可以把题目转化一下:把树拆成若干条链,每条链的颜色为其所在的树的颜色,然后排放所有的链成环,求使得相邻位置颜色不同的排列方案数. 然后本题分为两个部分:将一棵树分为1~n条不相交的链的方案数:将这 ...
- (一)Thread的run() 和 start() 方法
Java多线程在实际开发中会遇到很多问题,对于这种争抢CPU时间片段的选手,我们或许有很多困惑,捉摸不透.即便如此,它也是可以被我们控制的. 最近在看Java多线程的书籍,里面有好多我曾经不怎么注意的 ...
- 吴裕雄--天生自然C语言开发:文件读写
#include <stdio.h> int main() { FILE *fp = NULL; fp = fopen("/tmp/test.txt", "w ...
- 《ECMAScript 6 入门教程 - 阮一峰著》学习笔记
在刷LeetCode的过程中看到很多新的语法糖,系统学习一下以便代码更加规范,美观,健壮.
- 记一次关于JDBCUtils工具类的编写
jdbc.properties数据库配置的属性文件内容如下 jdbc.driver=com.mysql.jdbc.Driver jdbc.url=jdbc:mysql://localhost/xxxx ...
- 进程异常行为-反弹Shell攻击,KILL多个进程
进程异常行为-反弹Shell攻击 父进程名称:bash 进程名称:bash 进程名称:/usr/bin/bash 进程id:23,077 命令行参数:sh -c /bin/bash -i >&a ...
- UML Learning
在建筑业中,建模是一项经过检验并被广泛接受的工程技术,建立房屋和大厦的建筑模型,能帮助用户得到实际建筑物的印象.在软件建模中也具有同样的作用,建模提供了系统的蓝图. 建模是为了能够更好地理解正在开发的 ...