Python 【面试强化宝典】
四大数据类型的常用方法
- 列表常用方法
#1. append 用于在列表末尾追加新的对象
a = [1,2,3]
a.append(4) #the result : [1, 2, 3, 4]
#2. count 方法统计某个元素在列表中出现的次数
a = ['aa','bb','cc','aa','aa']
print(a.count('aa')) #the result : 3
#3. extend 方法可以在列表的末尾一次性追加另一个序列中的多个值
a = [1,2,3]
b = [4,5,6]
a.extend(b) #the result :[1, 2, 3, 4, 5, 6]
#4. index 函数用于从列表中找出某个值第一个匹配项的索引位置
a = [1,2,3,1]
print(a.index(1)) #the result : 0
#5. insert 方法用于将对象插入到列表中
a = [1,2,3]
a.insert(0,'aa') #the result : ['aa', 1, 2, 3]
#6. pop 方法会移除列表中的一个元素(默认是最后一个),并且返回该元素的值
a = [1,2,3]
a.pop() #the result : [1, 2] a.pop(0)
#7. remove 方法用于移除列表中某个值的第一个匹配项
a = ['aa','bb','cc','aa']
a.remove('aa') #the result : ['bb', 'cc', 'aa']
#8. reverse 方法将列表中的元素反向存放
a = ['a','b','c']
a.reverse() #the result : ['c', 'b', 'a']
#9. sort 方法用于在原位置对列表进行排序,意味着改变原来的列表,让其中的元素按一定顺序排列
a = ['a','b','c',1,2,3]
a.sort() #the result :[1, 2, 3, 'a', 'b', 'c']
#10. enumrate
li = [11,22,33]
for k,v in enumerate(li, 1):
print(k,v)
- 字符串常用方法
#1. find 方法可以在一个较长的字符串中查找子串,他返回子串所在位置的最左端索引,如果没有找到则返回-1
a = 'abcdefghijk'
print(a.find('abc')) #the result : 0
print(a.find('abc',10,100)) #the result : 11 指定查找的起始和结束查找位置
#2. join 方法是非常重要的字符串方法,他是 split 方法的逆方法,用来连接序列中的元素,并且需要被连接的元素都 必须是字符串。
a = ['','','']
print('+'.join(a)) #the result : 1+2+3
#3. split 方法,是一个非常重要的字符串,它是 join 的逆方法,用来将字符串分割成序列
print('1+2+3+4'.split('+')) #the result : ['1', '2', '3', '4']
#4. strip 方法返回去除首位空格(不包括内部)的字符串
print(" test test ".strip()) #the result :“test test”
#5. replace 方法返回某字符串所有匹配项均被替换之后得到字符串
print("This is a test".replace('is','is_test')) #the result : This_test is_test a test
- 字典常用方法
#1. clear 方法清除字典中所有的项,这是一个原地操作,所以无返回值(或则说返回 None)
d = {'name':"tom"}
d.clear() print(d) #the result : {}
#2. fromkeys 方法使用给定的键建立新的字典,每个键都对应一个默认的值 None
print({}.fromkeys(['name','age'])) #the result : {'age': None, 'name': None}
#3. get 方法是个更宽松的访问字典项的方法,如果试图访问字典中不存在的项时不会报错仅会 返回:None
d = {'Tom':8777,'Jack':8888,'Fly':6666}
print(d.get('Tom')) #the result : 8777
print(d.get('not_exist')) #the result : None
#4. for 循环字典的三种方法
d = {'Tom':8777,'Jack':8888,'Fly':6666}
for k,v in d.items():
print(k,v)
for k in d.values():
print(k)
for k in d.keys():
print(k) #5. pop 方法用于获得对应与给定键的值,然后将这个”键-值”对从字典中移除
d = {'Tom':8777,'Jack':8888,'Fly':6666}
v = d.pop('Tom')
print(v) #8777
#6. setdefault 方法在某种程度上类似于 get 方法,能够获得与给定键相关联的值,除此之外,setdefault 还能在字典 中不含有给定键的情况下设定相应的键值
d = {'Tom':8777,'Jack':8888,'Fly':6666}
d.setdefault('Tom') #the result : 8777
print(d.setdefault('Test')) #the result : None
print(d) #{'Fly': 6666, 'Jack': 8888, 'Tom': 8777, 'Test': None}
#7. update 方法可以利用一个字典项更新另一个字典,提供的字典中的项会被添加到旧的字典中,如有相同的键则会被 覆盖
d = {'Tom':8777,'Jack':8888,'Fly':6666}
a = {'Tom':110,'Test':119}
d.update(a) print(d) #the result :{'Fly': 6666, 'Test': 119, 'Jack': 8888, 'Tom': 110}
#8. 将两个列表组合成字典
keys = ['a', 'b']
values = [1, 2]
print(dict(zip(keys,values))) # {'a': 1, 'b': 2}
- 集合常用方法
list_1 = [1,2,3,4,5,1,2]
#1、去重(去除 list_1 中重复元素 1,2)
list_1 = set(list_1) #去重: {1, 2, 3, 4, 5}
print(list_1)
list_2 = set([4,5,6,7,8]) #2、交集(在 list_1 和 list_2 中都有的元素 4,5)
print(list_1.intersection(list_2)) #交集: {4, 5}
#3、并集(在 list_1 和 list_2 中的元素全部打印出来,重复元素仅打印一次)
print(list_1.union(list_2)) #并集: {1, 2, 3, 4, 5, 6, 7, 8}
#4、差集
print(list_1.difference(list_2)) #差集:在 list_1 中有在 list_2 中没有: {1, 2, 3}
print(list_2.difference(list_1)) #差集:在 list_1 中有在 list_2 中没有: {8, 6, 7}
三程三器
- 进程
- 进程定义
- 进程是资源分配最小单位
- 当一个可执行程序被系统执行(分配内存等资源)就变成了一个进程
- 进程定义拓展回答内容
- 程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,这种执行的程序就称之为进程
- 程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念
- 在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。
- 进程的出现让每个用户感觉到自己独享 CPU,因此,进程就是为了在 CPU 上实现多道编程而提出的。
- 进程之间有自己独立的内存,各进程之间不能相互访问 6. 创建一个新线程很简单,创建新进程需要对父进程进行复制
- 多道编程概念
- 多道编程: 在计算机内存中同时存放几道相互独立的程序,他们共享系统资源,相互穿插运行
- 单道编程: 计算机内存中只允许一个的程序运行
- 有了进程为什么还要线程?
- 进程优点
- 提供了多道编程,让我们感觉我们每个人都拥有自己的 CPU 和其他资源,可以提高计算机的利用率
- 进程的两个重要缺点
- a. 第一点:进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
- b. 第二点:进程在执行的过程中如果阻塞,即使进程中有些工作不依赖于输入的数据,也将无法执行(例如等待输入,整个进程就会挂起)。
- c. 例如,我们在使用 qq 聊天, qq 做为一个独立进程如果同一时间只能干一件事,那他如何实现在同一时刻 即能监听键盘输入、又能监听 其它人给你发的消息
- d. 你会说,操作系统不是有分时么?分时是指在不同进程间的分时呀
- e. 即操作系统处理一会你的 qq 任务,又切换到 word 文档任务上了,每个 cpu 时间片分给你的 qq 程序时,你的 qq 还是只能同时干一件 事呀
- 进程优点
- 进程间互相访问数据的四种方法
- 注:不同进程间内存是不共享的,所以互相之间不能访问对方数据
- 法 1: 利用 Queues 实现父进程到子进程(或子进程间)的数据传递
- 法 2: 使用管道 pipe 实现两个进程间数据传递
- 法 3: Managers 实现很多进程间数据共享
- 法 4:借助 redis 中间件进行数据共享
- 进程池
- 进程定义
from multiprocessing import Process,Pool
import time,os
def foo(i):
time.sleep(2)
print("in the process",os.getpid()) #打印子进程的 pid
return i+100 def call(arg):
print('-->exec done:',arg,os.getpid()) if __name__ == '__main__':
pool = Pool(3) #进程池最多允许 5 个进程放入进程池
print("主进程 pid:",os.getpid()) #打印父进程的 pid
for i in range(10):
#用法 1 callback 作用是指定只有当 Foo 运行结束后就执行 callback 调用的函数,父进程调用的 callback 函数
pool.apply_async(func=foo, args=(i,),callback=call)
#用法 2 串行 启动进程不在用 Process 而是直接用
pool.apply() # pool.apply(func=foo, args=(i,))
print('end')
pool.close() #关闭
pool pool.join() #进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭。
- 进程和程序的区别
- 程序只是一个普通文件,是一个机器代码指令和数据的集合,所以,程序是一个静态的实体
- 而进程是程序运行在数据集上的动态过程,进程是一个动态实体,它应创建而产生,应调度执行因等待资源或事件而被处于等待状态,因完成任务而被撤消
- 进程是系统进行资源分配和调度的一个独立单位
- 一个程序对应多个进程,一个进程为多个程序服务(两者之间是多对多的关系)
- 一个程序执行在不同的数据集上就成为不同的进程,可以用进程控制块来唯一地标识每个进程
- 进程和程序的区别
- 线程
- 线程是操作系统调度的最小单位
- 它被包含在进程之中,是进程中的实际运作单位
- 进程本身是无法自己执行的,要操作 cpu,必须创建一个线程,线程是一系列指令的集合
- 线程定义拓展回答内容
- 线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位
- 一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务
- 无论你启多少个线程,你有多少个 cpu, Python 在执行的时候会淡定的在同一时刻只允许一个线程运行
- 进程本身是无法自己执行的,要操作 cpu,必须创建一个线程,线程是一系列指令的集合
- 所有在同一个进程里的线程是共享同一块内存空间的,不同进程间内存空间不同
- 同一个进程中的各线程可以相互访问资源,线程可以操作同进程中的其他线程,但进程仅能操作子进程
- 两个进程想通信,必须要通过一个中间代理
- 对主线程的修改可能回影响其他子线程,对主进程修改不会影响其他进程因为进程间内存相互独立,但是同一进程下的线程共享内存
- 进程和线程的区别
- 进程包含线程
- 线程共享内存空间3、进程内存是独立的(不可互相访问)
- 进程可以生成子进程,子进程之间互相不能互相访问(相当于在父级进程克隆两个子进程)
- 在一个进程里面线程之间可以交流。两个进程想通信,必须通过一个中间代理来实现
- 创建新线程很简单,创建新进程需要对其父进程进行克隆。
- 一个线程可以控制或操作同一个进程里面的其它线程。但进程只能操作子进程。
- 父进程可以修改不影响子进程,但不能修改。
- 线程可以帮助应用程序同时做几件事
- for 循环同时启动多个线程
import threading
import time
def sayhi(num): #定义每个线程要运行的函数
print("running on number:%s" %num)
time.sleep(3)
for i in range(50):
t = threading.Thread(target=sayhi,args=('t-%s'%i,))
t.start()
- t.join(): 实现所有线程都执行结束后再执行主线程
import threading
import time
start_time = time.time()
def sayhi(num): #定义每个线程要运行的函数
print("running on number:%s" %num)
time.sleep(3)
t_objs = []
#将进程实例对象存储在这个列表中
for i in range(50):
t = threading.Thread(target=sayhi,args=('t-%s'%i,))
t.start()
#启动一个线程,程序不会阻塞
t_objs.append(t)
print(threading.active_count())
#打印当前活跃进程数量
for t in t_objs: #利用 for 循环等待上面 50 个进程全部结束
t.join()
#阻塞某个程序
print(threading.current_thread())
#打印执行这个命令进程
print("----------------all threads has finished.....")
print(threading.active_count())
print('cost time:',time.time() - start_time)
- setDaemon(): 守护线程,主线程退出时,需要子线程随主线程退出
import threading
import time
start_time = time.time()
def sayhi(num): #定义每个线程要运行的函数
print("running on number:%s" %num)time.sleep(3)
for i in range(50):
t = threading.Thread(target=sayhi,args=('t-%s'%i,))
t.setDaemon(True)
#把当前线程变成守护线程,必须在 t.start()前设置
t.start()
#启动一个线程,程序不会阻塞
print('cost time:',time.time() - start_time)
- GIL 全局解释器锁:保证同一时间仅有一个线程对资源有操作权限
- 作用:在一个进程内,同一时刻只能有一个线程执行
- 说明:python 多线程中 GIL 锁只是在 CPU 操作时(如:计算)才是串行的,其他都是并行的,所以比串行快很
- 为了解决不同线程同时访问同一资源时,数据保护问题,而产生了 GIL
- GIL 在解释器的层面限制了程序在同一时间只有一个线程被 CPU 实际执行,而不管你的程序里实际开了多少条线程
- 为了解决这个问题,CPython 自己定义了一个全局解释器锁,同一时间仅仅有一个线程可以拿到这个数据
- python 之所以会产生这种不好的状况是因为 python 启用一个线程是调用操作系统原生线程,就是 C 接口
- 但是这仅仅是 CPython 这个版本的问题,在 PyPy,中就没有这种缺陷
- 线程锁
- 当一个线程对某个资源进行 CPU 计算的操作时加一个线程锁,只有当前线程计算完成主动释放锁,其他线程才能对其操作
- 这样就可以防止还未计算完成,释放 GIL 锁后其他线程对这个资源操作导致混乱问题
# 用户锁使用举例
import time
import threading
lock = threading.Lock()
#1 生成全局锁
def addNum():
global num
#2 在每个线程中都获取这个全局变量
print('--get num:',num )
time.sleep(1)
lock.acquire()
#3 修改数据前加锁
num
-= 1
#4 对此公共变量进行-1 操作
lock.release()
#5 修改后释放
- Semaphore(信号量)
- 互斥锁 同时只允许一个线程更改数据,而 Semaphore 是同时允许一定数量的线程更改数据
- 比如厕所有 3 个坑,那最多只允许 3 个人上厕所,后面的人只能等里面有人出来了才能再进去
- 作用就是同一时刻允许运行的线程数量
- 线程池实现并发
import requests
from concurrent.futures import ThreadPoolExecutor
def fetch_request(url):
result = requests.get(url)
print(result.text)
url_list = [
'https://www.baidu.com',
'https://www.google.com/',
#google 页面会卡住,知道页面超时后这个进程才结束'http://dig.chouti.com/',
#chouti 页面内容会直接返回,不会等待 Google 页面的返回
]
pool = ThreadPoolExecutor(10)
# 创建一个线程池,最多开 10 个线程
for url in url_list:
pool.submit(fetch_request,url)
# 去线程池中获取一个线程,线程去执行 fetch_request 方法
pool.shutdown(True)
# 主线程自己关闭,让子线程自己拿任务执行
- 协程
- 什么是协程(进入上一次调用的状态)
- 协程,又称微线程,纤程,协程是一种用户态的轻量级线程。
- 线程的切换会保存到 CPU 的栈里,协程拥有自己的寄存器上下文和栈,
- 协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈
- 协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态
- 协程最主要的作用是在单线程的条件下实现并发的效果,但实际上还是串行的(像 yield 一样)
- 什么是协程(进入上一次调用的状态)
- 协程缺点(无法利用多核资源)
- 协程的本质是个单线程,它不能同时将 单个 CPU 的多个核用上,协程需要和进程配合才能运行在多 CPU 上线程阻塞(Blocking)操作(如 IO时)会阻塞掉整个程序
- 协程缺点(无法利用多核资源)
- 协程为何能处理大并发 1:Greenlet 遇到 I/O 手动切换
- 协程之所以快是因为遇到 I/O 操作就切换(最后只有 CPU 运算)
- 这里先演示用 greenlet 实现手动的对各个协程之间切换
- 其实 Gevent 模块仅仅是对 greenlet 的再封装,将 I/O 间的手动切换变成自动切换
- 协程为何能处理大并发 1:Greenlet 遇到 I/O 手动切换
- 协程为何能处理大并发 2:Gevent 遇到 I/O 自动切换
- Gevent 是一个第三方库,可以轻松通过 gevent 实现并发同步或异步编程
- 在 gevent 中用到的主要模式是 Greenlet, 它是以 C 扩展模块形式接入 Python 的轻量级协程
- Greenlet 全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
- Gevent 原理是只要遇到 I/O 操作就会自动切换到下一个协程
- 协程为何能处理大并发 2:Gevent 遇到 I/O 自动切换
- 使用协程处理并发
# 注:Gevent 只用起一个线程,当请求发出去后 gevent 就不管,永远就只有一个线程工作,谁先回来先处理
import gevent
import requests
from gevent import monkey
monkey.patch_all()
# 这些请求谁先回来就先处理谁
def fetch_async(method, url, req_kwargs):
response = requests.request(method=method, url=url, **req_kwargs)
print(response.url, response.content)# ##### 发送请求 #####
gevent.joinall([
gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}),
gevent.spawn(fetch_async, method='get', url='https://www.google.com/', req_kwargs={}),
gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={}),
])
- sellect、poll、epoll
- select (能监控数量有限,不能告诉用户程序具体哪个连接有数据)
- select 目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点
- select 的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在 Linux 上一般为 1024
- select 监控 socket 连接时不能准确告诉用户是哪个,比如:现在用 socket 监控 10000 链接,如果其中有一个链接有数据了,select 就会告诉用户程序,你有 socket 来数据了,那样就只能自己循环 10000 次判断哪个活跃
- select (能监控数量有限,不能告诉用户程序具体哪个连接有数据)
- poll(和 select 一样,仅仅去除了最大监控数量)
- poll 和 select 在本质上没有多大差别,但是 poll 没有最大文件描述符数量的限制
- 可以理解为 poll 是一个过渡阶段,大家也都不用他
- poll(和 select 一样,仅仅去除了最大监控数量)
- epoll (不仅没有最大监控数量限制,还能告诉用户程序哪个连接有活跃)
- 注:epoll 被认为是 linux 下性能最好的多路 io 就绪通知方法
- epoll 直到 Linux2.6(centos6 以后)才出现了由内核直接支持
- Epoll 没有最大文件描述符数量限制
- epoll 最重要的优点是他可以直接告诉用户程序哪一个,比如现在用 epoll 去监控 10000 个 socket 链接,交给内核去监测,现在有一个连接有数据了,在有有一个连接有数据了,epoll 会直接高数用户程序哪个连接有数据了
- epoll (不仅没有最大监控数量限制,还能告诉用户程序哪个连接有活跃)
- epoll 能实现高并发原理
- epoll() 中内核则维护一个链表,epoll_wait 直接检查链表是不是空就知道是否有文件描述符准备好了。
- 在内核实现中 epoll 是根据每个 sockfd 上面的与设备驱动程序建立起来的回调函数实现的。
- 某个 sockfd 上的事件发生时,与它对应的回调函数就会被调用,把这个 sockfd 加入链表。
- epoll 上面链表中获取文件描述,这里使用内存映射(mmap)技术, 避免了复制大量文件描述符带来的开销
- 内存映射(mmap):内存映射文件,是由一个文件到一块内存的映射,将不必再对文件执行 I/O 操作
- epoll 能实现高并发原理
- 装饰器
- 装饰器定义
- 不能修改被装饰函数的源代码,不能修改被装饰函数的调用方式,为其他函数添加其他功能
- 装饰器定义
- 使用高阶函数模拟装饰器
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import time
def timer(func):
start_time = time.time()func()
print '函数执行时间为', time.time() - start_time
def test():
print '开始执行 test'
time.sleep(3)
print 'test 执行结束'
timer(test)
'''
开始执行 test
test 执行结束
函数执行时间为 3.00332999229
'''
- 计算运行时间装饰器
import time
def timer(func):
#timer(test1) func=test1
def deco(*args,**kwargs):
start_time = time.time()
func(*args,**kwargs)
#run test1
stop_time = time.time()
print("running time is %s"%(stop_time-start_time))
return deco
@timer
# test1=timer(test1)
def test1():
time.sleep(3)
print("in the test1")
test1()
- 装饰器使用场景
- 授权:装饰器能有助于检查某个人是否被授权去使用一个 web 应用的端点(endpoint)。它们被大量使用于 Flask 和 Django web 框架中
- 日志:在记录日志的地方添加装饰器
- 缓存:通过装饰器获取缓存中的值
- 装饰器使用场景
- 生成器
- 生成器定义
- 生成器可以理解为一种数据类型,这种数据类型自动实现了迭代器协议(其他数据类型需要调用自己的内置 iter 方法)
- 在 Python 中,一边循环,一边计算的机制,称为生成器。
- 生成器定义
- 生成器的作用
- 通过列表生成式,我们可以直接创建一个列表,但是,受到内存限制,列表容量肯定是有限的。
- 而且,创建一个包含 100 万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
- 所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?
- 这样就不必创建完整的 list,从而节省大量的空间。在 Python 中,这种一边循环一边计算的机制,称为生成器:generator。
- 生成器工作原理
- 生成器是这样一个函数,它记住上一次返回时在函数体中的位置。
- 对生成器函数的第二次(或第 n 次)调用跳转至该函数中间,而上次调用的所有局部变量都保持不变。
- 生成器不仅“记住”了它数据状态;生成器还“记住”了它在流控制构造中的位置。
- 生成器是一个函数,而且函数的参数都会保留。
- 迭代到下一次的调用时,所使用的参数都是第一次所保留下的,即是说,在整个所有函数调用的参数都是第一次所调用时保留的,而不是新创建的
- 生成器的作用
- yield 生成器运行机制
- 在 Python 中,yield 就是这样的一个生成器。
- 当你问生成器要一个数时,生成器会执行,直至出现 yield 语句,生成器把 yield 的参数给你,之后生成器就不会往下继续运行。
- 当你问他要下一个数时,他会从上次的状态开始运行,直至出现 yield 语句,把参数给你,之后停下。如此反复
- 在 python 中,当你定义一个函数,使用了 yield 关键字时,这个函数就是一个生成器
- 它的执行会和其他普通的函数有很多不同,函数返回的是一个对象,而不是你平常所用 return 语句那样,能得到结果值。如果想取得值,那得调用 next()函数
- 每当调用一次迭代器的 next 函数,生成器函数运行到 yield 之处,返回 yield 后面的值且在这个地方暂停,所有的状态都会被保持住,直到下次 next 函数被调用,或者碰到异常循环退出。
- yield 生成器运行机制
- yield 实现 fib 数
def fib(max_num):
a,b = 1,1
while a < max_num:
yield b
a,b=b,a+b
g = fib(10)
#生成一个生成器:[1,2, 3, 5, 8, 13]
print(g.__next__())
#第一次调用返回:1
print(list(g))
#把剩下元素变成列表:[2, 3, 5, 8, 13]
- 迭代器
- 迭代器定义
- 迭代器是访问集合内元素的方式,迭代器对象从集合的第一个元素开始访问,直到所有的元素都被访问一遍后结束
- 迭代器仅是一容器对象,它有两个基本方法
- next 方法:返回容器的下一个元素
- __iter__方法:返回迭代器自身
- 迭代器定义
a = iter([1,2,])
#生成一个迭代器
print(a.__next__())
print(a.__next__())
print(a.__next__())
#在这一步会引发
“StopIteration” 的异常
- 生成器和迭代器之间的区别
- 在使用生成器时,我们创建一个函数;在使用迭代器时,我们使用内置函数 iter()和 next()。 在生成器中,我们使用关键字‘yield’来每次生成/返回一个对象。
- 生成器中有多少‘yield’语句,你可以自定义。 每次‘yield’暂停循环时,生成器会保存本地变量的状态。而迭代器并不会使用局部变量,它只需要一个可迭代对象进行迭代。 使用类可以实现你自己的迭代器,但无法实现生成器。
- 生成器运行速度快,语法简洁,更简单。 迭代器更能节约内存。
- 生成器和迭代器之间的区别
Python 面向对象
- 面向对象三大特性: 封装,继承,多态
- 封装
- 在类中对数据的赋值、内部调用对外部用户是透明的
- 这使类变成了一个胶囊或容器,里面包含着类的数据和方法
- 作用:
- 防止数据被随意修改
- 使外部程序不需要关注对象内部的构造,只需要通过对外提供的接口进行直接访问
- Inheritance 继承(代码重用)
- 一个类可以派生出子类,在这个父类里定义的属性、方法自动被子类继承
- 比如 CS 中的警察和恐怖分子,可以将两个角色的相同点写到一个父类中,然后同时去继承它
- 使用经典类: Person.__init__(self,name,age) 并重写写父类 Person 的构造方法,实现,先覆盖,再继承,再重构
- Inheritance 继承(代码重用)
- Polymorphism 多态(接口重用)
- 多态是面向对象的重要特性,简单点说:“一个接口,多种实现”
- 指一个基类中派生出了不同的子类,且每个子类在继承同样的方法名的同时又对父类的方法做了不同的实现
- 这就是同一种事物表现出的多种形态
- 比如黄种人继承了人 talk 这个功能,但是他说的是中文,而美国人的 talk 是英文,但是他们是同样的 talk
- 作用:简单的讲就是允许父类调用子类的方法
- Polymorphism 多态(接口重用)
- 静态方法、类方法、属性方法、魔法方法
- 静态方法
- 作用:静态方法可以更好的组织代码,防止代码变大后变得比较混乱。
- 特性: 静态方法只是名义上归类管理,实际上在静态方法里访问不了类或则实例中的任何属性
- 静态方法使用场景:
- 我们要写一个只在类中运行而不在实例中运行的方法.
- 经常有一些跟类有关系的功能但在运行时又不需要实例和类参与的情况下需要用到静态方法.
- 比如更改环境变量或者修改其他类的属性等能用到静态方法.
- 这种情况可以直接用函数解决, 但这样同样会扩散类内部的代码,造成维护困难.
- 调用方式: 既可以被类直接调用,也可以通过实例调用
class Dog(object):
def __init__(self,name):
self.name = name
@staticmethod
def eat():
print("I am a static method")
d = Dog("ChenRonghua")
d.eat()
#方法 1:使用实例调用Dog.eat()
#方法 2:使用类直接调用
- 类方法
- 作用:无需实例化直接被类调用
- 特性: 类方法只能访问类变量,不能访问实例变量
- 类方法使用场景: 当我们还未创建实例,但是需要调用类中的方法
- 调用方式: 既可以被类直接调用,也可以通过实例调用
class Dog(object):
name = '类变量' #在这里如果不定义类变量仅定义实例变量依然报错
def __init__(self,name):
self.name = '实例变量'
self.name = name
@classmethod
def eat(self,food):
print("%s is eating %s"%(self.name,food))
Dog.eat('baozi')
#方法 1:使用类直接调用
d = Dog("ChenRonghua")
d.eat("包子")
#方法 2:使用实例 d 调用
- 属性方法
- 作用:属性方法把一个方法变成一个属性,隐藏了实现细节,调用时不必加括号直接 d.eat 即可调用 self.eat()方法
class Dog(object):
def __init__(self, name):
self.name = name
@property
def eat(self):
print(" %s is eating" % self.name)
d = Dog("ChenRonghua")
d.eat()
# 调用会出以下错误, 说 NoneType is not callable, 因为 eat 此时已经变成一个静态属性了,
# 不是方法了, 想调用已经不需要加()号了,直接 d.eat 就可以了
- 魔法方法
- type 生成类调用顺序
- __new__ : 先于__init__方法,每生成一个实例执行一次,__new__ 类方法创建实例对象
- __init__: __init__方法每生成一个实例就会执行一次,初始化实例对象
- __call__ :后与__init__方法,C()() 使用类再加一个括号调用, C 为类名称
- __del__:析构方法,删除无用的内存对象(当程序结束会自动自行析构方法)
- type 生成类调用顺序
- 类实例化时魔法方法调用顺序
class Student(object):
def __new__(cls, *args, **kwargs):
print('__new__')
return object.__new__(cls)
# 必须返回父类的__new__方法,否则不不执行__init__方法,无法创建实例def __init__(self,name):
print('__init__')
self.name = name
def __str__(self):
# 作用:打印实例时显示指定字符串,而不是内存地址
print('__str__')
return self.name
def __call__(self, *args, **kwargs):
# 当执行 C()(*args) 或者 s1(*args) 就会执行__call__
print('__call__',*args)
def __del__(self):
# 作用:清除无用的实例对内存的暂用
print('__del__')
#1、实例化时机会执行__new__、__init__
s1 = Student('tom')
#2、执行 实例() 就会执行__call__ 方法,并将参数传递给__call__函数
s1('call01')
#3、当打印实例时就会执行 __str__ 方法下返回的字符串(默认返回的实例地址)
print(s1)
#4、析构方法:当删除实例时就会调用 __del__ 方法
del s1
# 析构方法作用:在程序结束后会自动执行析构方法删除所有实例
# 但是在程序运行时有很多实例是无用的,但是 python 内存回收机制却不会自动删除他们,这样就浪费内存
# 我们可以执行 del s1 ,那么在程序运行时,python 内存回收机制会检测到这些实例时无用的,才会删除
# 其实我们执行 del s1,并没有回收内存,只不过是摘除门牌号,python 内存回收机制发现没有门牌号后会自动回收内存
- 反射: hasattr、getattr、setattr 和 delattr
- hasattr(ogj,name_str) 判断一个对象里是否有对应的字符串方法
class Dog(object):
def eat(self,food):
print("eat method!!!")
d = Dog()
#hasattr 判断对象 d 是否有 eat 方法,有返回 True,没有返回 False
print(hasattr(d,'eat'))
#True
print(hasattr(d,'cat'))
#False
- getattr(obj,name_str) 根据字符串去获取 obj 对象里的对应的方法的内存地址
class Dog(object):
def eat(self):
print("eat method!!!")
d = Dog()if hasattr(d,'eat'):
# hasattr 判断实例是否有 eat 方法
func = getattr(d, 'eat')
# getattr 获取实例 d 的 eat 方法内存地址
func()
# 执行实例 d 的 eat 方法
#运行结果:
eat method!!!
- 使用 stattr 给类实例对象动态添加一个新的方法
- delattr 删除实例属性
- 深浅拷贝
- 预备知识一——python 的变量及其存储
- python 的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的只本身
- 不管多么复杂的数据结构,浅拷贝都只会 copy 一层。
- 理解:两个人公用一张桌子,只要桌子不变,桌子上的菜发生了变化两个人是共同感受的。
- 预备知识一——python 的变量及其存储
- 浅 copy 与 deepcopy
- 浅 copy: 不管多么复杂的数据结构,浅拷贝都只会 copy 一层
- deepcopy : 深拷贝会完全复制原变量相关的所有数据,在内存中生成一套完全一样的内容,我们对这两个变量中任意一个修改都不会影响其他变量
- 浅 copy 与 deepcopy
import copy
sourceList = [1,2,3,[4,5,6]]
copyList = copy.copy(sourceList)
deepcopyList = copy.deepcopy(sourceList)
sourceList[3][0]=100
print(sourceList) # [1, 2, 3, [100, 5, 6]]
print(copyList) # [1, 2, 3, [100, 5, 6]]
print(deepcopyList) # [1, 2, 3, [4, 5, 6]]
- python 垃圾回收机制
- 引用计数
- 当一个对象的引用被创建或者复制时,对象的引用计数加 1;当一个对象的引用被销毁时,对象的引用计数减 1.
- 当对象的引用计数减少为 0 时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
- 引用计数
- 标记-清除
- 它分为两个阶段:第一阶段是标记阶段,GC 会把所有的活动对象打上标记,第二阶段是把那些没有标记的对象非活动对象进行回收。
- 对象之间通过引用(指针)连在一起,构成一个有向图3)从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象,根对象就是全局变量、调用栈、寄存器。
- 注:像是 PyIntObject、PyStringObject 这些不可变对象是不可能产生循环引用的,因为它们内部不可能持有其它对象的引用。
- 标记-清除
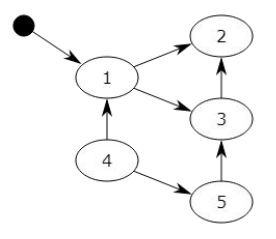
- 在上图中,可以从程序变量直接访问块 1,并且可以间接访问块 2 和 3,程序无法访问块 4 和 5
- 第一步将标记块 1,并记住块 2 和 3 以供稍后处理。
- 第二步将标记块 2,第三步将标记块 3,但不记得块 2,因为它已被标记。
- 扫描阶段将忽略块 1,2 和 3,因为它们已被标记,但会回收块 4 和 5。
- 分代回收
- 分代回收是建立在标记清除技术基础之上的,是一种以空间换时间的操作方式。
- Python 将内存分为了 3“代”,分别为年轻代(第 0 代)、中年代(第 1 代)、老年代(第 2 代)
- 他们对应的是 3 个链表,它们的垃圾收集频率与对象的存活时间的增大而减小。
- 新创建的对象都会分配在年轻代,年轻代链表的总数达到上限时,Python 垃圾收集机制就会被触发
- 把那些可以被回收的对象回收掉,而那些不会回收的对象就会被移到中年代去,依此类推
- 老年代中的对象是存活时间最久的对象,甚至是存活于整个系统的生命周期内。
- 上下文管理
- 什么是 with 语句
- with 是一种上下文管理协议,目的在于从流程图中把 try,except 和 finally 关键字和资源分配释放相关代码统统去掉,简化try….except….finlally 的处理流程。
- 所以使用 with 处理的对象必须有 enter()和 exit()这两个方法
- with 通过 enter 方法初始化(enter 方法在语句体执行之前进入运行)
- 然后在 exit 中做善后以及处理异常(exit()方法在语句体执行完毕退出后运行)
- 什么是 with 语句
- with 语句使用场景
- with 语句适用于对资源进行访问的场合,确保不管使用过程中是否发生异常都会执行必要的“清理”操作,释放资源
- 比如文件使用后自动关闭、线程中锁的自动获取和释放等。
- with 处理文件操作的实例
- with 语句使用场景
with open('/etc/passwd') as f:
for line in f:print(line)
# 这段代码的作用:打开一个文件,如果一切正常,把文件对象赋值给 f,然后用迭代器遍历文件中每一行,当完成时,关闭文件;
# 而无论在这段代码的任何地方,如果发生异常,此时文件仍会被关闭。
- 四大高阶函数
- lambda 基本使用
- lambda 只是一个表达式,函数体比 def 简单很多。
- lambda 的主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。
- lambda 表达式是起到一个函数速写的作用。允许在代码内嵌入一个函数的定义。
- 格式:lambda 的一般形式是关键字 lambda 后面跟一个或多个参数,紧跟一个冒号,之后是一个表达式。
- lambda 基本使用
f = lambda x,y,z:x+y+z
print(f(1,2,3))
#
my_lambda = lambda arg : arg + 1
print(my_lambda(10))
#
- 三元运算
- 三元运算格式: result=值 1 if x<y else 值 2if 条件成立 result=1,否则 result=2
- 作用:三元运算,又称三目运算,主要作用是减少代码量,是对简单的条件语句的缩写
- 三元运算
name = 'Tom' if 1 == 1 else 'fly'
print(name)
# 运行结果: Tom
f = lambda x:x if x % 2 != 0 else x + 100
print(f(10))
#
- filter()函数可以对序列做过滤处理
- 利用 filter、lambda 表达式 获取 l1 中元素小于 33 的所有元素 l1 = [11, 22, 33, 44, 55]
l1= [11,22,33,44,55]
a = filter(lambda x: x<33, l1)
print(list(a))
- Map 是对序列根据设定条件进行操作后返回他设置的是操作方法
# 利用 map,lambda 表达式将所有偶数元素加 100
l1= [11,22,33,44,55]
ret = map(lambda x:x if x % 2 != 0 else x + 100,l1)
print(list(ret))
# 运行结果: [11, 122, 33, 144, 55]
- reduce 函数使用 reduce 进行求和运算
- reduce()函数即为化简函数,它的执行过程为:每一次迭代,都将上一次的迭代结果与下一个元素一同传入二元 func 函数中去执行。
- 在 reduce()函数中,init 是可选的,如果指定,则作为第一次迭代的第一个元素使用,如果没有指定,就取 seq 中的第一个元素。
from functools import reduce
def f(x, y):
return x + y
print(reduce(f, [1, 3, 5, 7, 9])) #
# 1、先计算头两个元素:f(1, 3),结果为 4;
# 2、再把结果和第 3 个元素计算:f(4, 5),结果为 9;
# 3、再把结果和第 4 个元素计算:f(9, 7),结果为 16;
# 4、再把结果和第 5 个元素计算:f(16, 9),结果为 25;
# 5、由于没有更多的元素了,计算结束,返回结果 25。
print( reduce(lambda x, y: x + y, [1, 3, 5, 7, 9])
)
#
- sorted 函数
- sorted 对字典排序
d = {'k1':1, 'k3': 3, 'k2':2}
# d.items() = [('k1', 1), ('k3', 3), ('k2', 2)]
a = sorted(d.items(), key=lambda x: x[1])
print(a)
# [('k1', 1), ('k2', 2), ('k3', 3)]
MySQL 宝典
- MySQL 事物
- InnoDB 事务原理
- 事务(Transaction)是数据库区别于文件系统的重要特性之一,事务会把数据库从一种一致性状态转换为另一种一致性状态。
- 在数据库提交时,可以确保要么所有修改都已保存,要么所有修改都不保存。
- InnoDB 事务原理
- 事务的(ACID)特征
- 原子性(Atomicity):整个事物的所有操作要么全部提交成功,要么全部失败回滚(不会出现部分执行的情况)。
- 一致性(Consistency):几个并行执行的事务,其执行结果必须与按某一顺序串行执行的结果相一致。
- 隔离性(Isolation):事务的执行不受其他事务的干扰,事务执行的中间结果对其他事务必须是透明的。
- 持久性(Durability): 一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
- 事务的(ACID)特征
- 事物隔离级别
- 未提交读: 脏读(READ UNCOMMITTED)
- 事务 2 查询到的数据是事务 1 中修改但未提交的数据,但因为事务 1 回滚了数据
- 所以事务 2 查询的数据是不正确的,因此出现了脏读的问题。
- 提交读: 不可重复读(READ COMMITTED)
- 事务 2 执行 update 语句但未提交前,事务 1 的前两个 select 操作返回结果是相同的。
- 但事务 2 执行 commit 操作后,事务 1 的第三个 select 操作就读取到事务 2 对数据的改变。
- 导致与前两次 select 操作返回不同的数据,因此出现了不可重复读的问题。
- 可重复读: 幻读(REPEATABLE READ):这是 MySQL 的默认事务隔离级别
- 事务每开启一个实例,都会分配一个版本号给它,如果读取的数据行正在被其它事务执行 DELETE 或 UPDATE 操作(即该行上有排他锁)
- 这时该事物的读取操作不会等待行上的锁释放,而是根据版本号去读取行的快照数据(记录在 undo log 中)
- 这样,事务中的查询操作返回的都是同一版本下的数据,解决了不可重复读问题。
- 虽然该隔离级别下解决了不可重复读问题,但理论上会导致另一个问题:幻读(Phantom Read)。
- 一个事务在执行过程中,另一个事物对已有数据行的更改,MVCC 机制可保障该事物读取到的原有数据行的内容相同
- 但并不能阻止另一个事务插入新的数据行,这就会导致该事物中凭空多出数据行,像出现了幻读一样,这便是幻读问题。
- 可串行读(SERIALIZABLE)
- 这是事务的最高隔离级别,通过强制事务排序,使之不可能相互冲突,就是在每个读的数据行加上共享锁来实现
- 在该隔离级别下,可以解决前面出现的脏读、不可重复读和幻读问题,但也会导致大量的超时和锁竞争现象,一般不推荐使用
- 未提交读: 脏读(READ UNCOMMITTED)
- MySQL 中的锁
- 锁分类
- 按操作划分:DML 锁,DDL 锁
- 按锁的粒度划分:表级锁、行级锁、页级锁
- 按锁级别划分:共享锁、排他锁
- 按加锁方式划分:自动锁、显示锁
- 按使用方式划分:乐观锁、悲观锁
- 乐观锁实现方法
- 每次获取商品时,不对该商品加锁。
- 在更新数据的时候需要比较程序中的库存量与数据库中的库存量是否相等,如果相等则进行更新
- 反之程序重新获取库存量,再次进行比较,直到两个库存量的数值相等才进行数据更新。
#### 乐观锁实现加一操作代码
# 我们可以看到,只有当对数量-1 操作时才会加锁,只有当程序中值和数据库中的值相等时才正真执行。
'''
//不加锁
select id,name,stock where id=1;
//业务处理
begin;
update shop set stock=stock-1 where id=1 and stock=stock;
commit;
'''
- 悲观锁
- 每次获取商品时,对该商品加排他锁。
- 也就是在用户 A 获取获取 id=1 的商品信息时对该行记录加锁,期间其他用户阻塞等待访问该记录。
#### 悲观锁实现加一操作代码
# 我们可以看到,首先通过 begin 开启一个事物,在获得 shop 信息和修改数据的整个过程中都对数据加锁,
保证了数据的一致性。
'''
begin;
select id,name,stock as old_stock from shop
where id=1 for update;
update shop set stock=stock-1 where id=1 and stock=old_stock;
commit
'''
- 排它锁
- 排它锁又叫写锁,如果事务 T 对 A 加上排它锁,则其它事务都不能对 A 加任何类型的锁。获准排它锁的事务既能读数据,又能写数据。
- 用法 : SELECT … FOR UPDATE
- 共享锁(share lock)
- 共享锁又叫读锁,如果事务 T 对 A 加上共享锁,则其它事务只能对 A 再加共享锁,不能加其它锁。
- 获准共享锁的事务只能读数据,不能写数据。
- 用法: SELECT … LOCK IN SHARE MODE;
- MySQL 优化
- 字段设计优化适应遵循数据库三范式
- 引擎的选择适应选择 MyIsam & InnoDB
- 索引索引也会消耗内存空间,并不是越多越好。而且索引的种类都有各自的有点
- 查询缓存将 select 查询结果缓存起来,key 为 SQL 语句,value 为查询结果
- 分区
- 水平分割和垂直分割
- 集群
- SQL 语句
- 服务器的选择,选择配置较高的服务器
- 为什么要 MySQL 优化?
- 系统的吞吐量瓶颈往往出现在数据库的访问速度上
- 随着应用程序的运行,数据库的中的数据会越来越多,处理时间会相应变慢
- 为了避免慢查询的出现
- B-tree/B+tree
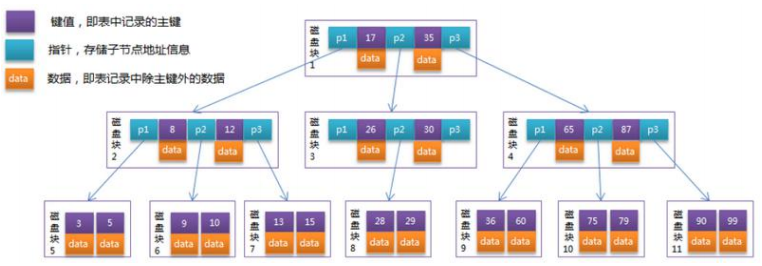
- 以一个 3 阶的 B-Tree 举例
- 每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。
- 两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。
- 以根节点为例,关键字为 17 和 35,P1 指针指向的子树的数据范围为小于 17,P2 指针指向的子树的数据范围为 17~35,P3 指针指向的子树的数据范围为大于 35。
- B-tree在每一个节点上都存储了数据,所以占用的空间比较大,导致存储减少。当存储量增大会导致B-tree的深度较大,从而增大了磁盘的I/O次数,影响了查询的效率。
'''模拟查找关键字 29 的过程:'''
# 根据根节点找到磁盘块 1,读入内存。【磁盘 I/O 操作第 1 次】
# 比较关键字 29 在区间(17,35),找到磁盘块 1 的指针 P2。
# 根据 P2 指针找到磁盘块 3,读入内存。【磁盘 I/O 操作第 2 次】
# 比较关键字 29 在区间(26,30),找到磁盘块 3 的指针 P2。
# 根据 P2 指针找到磁盘块 8,读入内存。【磁盘 I/O 操作第 3 次】
# 在磁盘块 8 中的关键字列表中找到关键字 29。
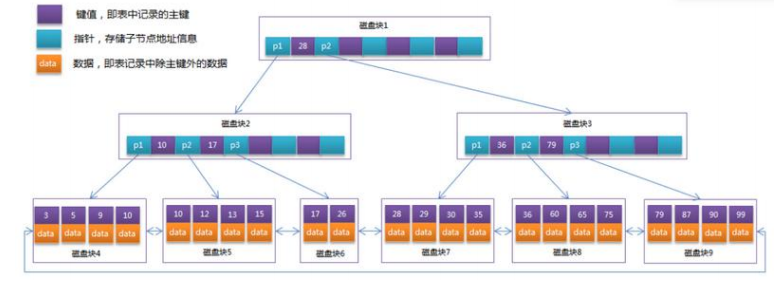
- B+tree(以每个节点可存 4 个建值及指针信息为例)
- B+Tree 的非叶子节点只存储键值信息,假设每个磁盘块能存储 4 个键值及指针信息
- 在 B+Tree 上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
- B+tree实在B-tree基础上进行了优化。更适合外部的存储结构,InnoDB存储引擎就是利用B+tree实现的索引原理。
- B+tree所有的数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储Key值信息,这样可以大大提高了每个叶节点的key值数量,降低了B+tree的高度,自然查询比较效率。
- MySQL 主从同步原理
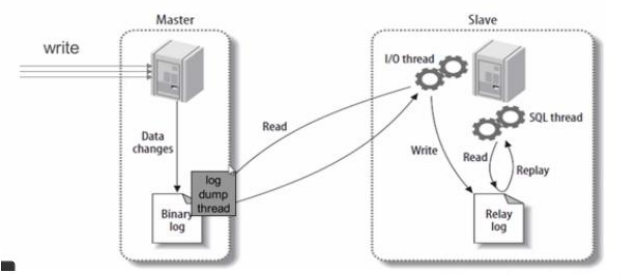
- master 服务器将数据的改变记录二进制 binlog 日志,当 master 上的数据发生改变时,则将其改变写入二进制日志中;
- slave 服务器会在一定时间间隔内对 master 二进制日志进行探测其是否发生改变,如果发生改变,则开始一个 I/OThread 请求 master二进制事件
- 同时主节点为每个 I/O 线程启动一个 dump 线程,用于向其发送二进制事件,并保存至从节点本地的中继日志中,从节点将启动 SQL 线程从中继日志中读取二进制日志,在本地重放,使得其数据和主节点的保持一致,最后 I/OThread 和 SQLThread 将进入睡眠状态,等待下一次被唤醒。
- MySQL-慢查询应用
- 场景需求
- 现我司发现,我司业务中部分接口相应极慢,用户甚至可以在等待过程中泡面,经由我司诸位人才讨论分析,需要使用 mysql 慢查询
- 定位有问题的 SQL 语句,请您为我司说明什么是 mysql 慢查询及如何开启慢查询、其详细配置和使用方法。
- 场景需求
- 参考答案
- MySQL 的慢查询,全名是慢查询日志,是 MySQL 提供的一种日志记录,用来记录在 MySQL 中响应时间超过阀值的语句。具体环境中,运行时间超过 long_query_time 值的 SQL 语句,则会被记录到慢查询日志中。long_query_time 的默认值为 10,意思是记录运行10 秒以上的语句。默认情况下,MySQL 数据库并不启动慢查询日志,需要手动来设置这个参数。
- 当然,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。此外,慢查询日志支持将日志记录写入文件和数据库表。
- MySQL 慢查询的相关参数解释:
- slow_query_log:是否开启慢查询日志,1 表示开启,0 表示关闭。
- log-slow-queries :旧版(5.6 以下版本)MySQL 数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
- slow-query-log-file:新版(5.6 及以上版本)MySQL 数据库慢查询日志存储路径。可以不设置该参数,系统则会默认给一个缺省的文件 host_name-slow.log
- long_query_time:慢查询阈值,当查询时间多于设定的阈值时,记录日志。
- log_queries_not_using_indexes:未使用索引的查询也被记录到慢查询日志中(可选项)。
- log_output:日志存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。log_output='TABLE'表示将日志存入数据库。那么如何进行慢查询日志的配置呢?默认情况下 slow_query_log 的值为 OFF,表示慢查询日志是禁用的,可以通过设置
- 参考答案
slow_query_log 的值来开启,如下所示:
show variables like '%slow_query_log%';
+----------------------+-----------------------------------------------+
| Variable_name | Value
|
+----------------------+-----------------------------------------------+
| slow_query_log | OFF
|
| slow_query_log_file | /home/WDPM/MysqlData/mysql/DB-Server-slow.log |
+----------------------+------------------------------------------------+
2 rows in set (0.00 sec)
- 使用 set global slow_query_log=1 开启了慢查询日志只对当前数据库生效,MySQL 重启后则会失效。如果要永久生效,就必须修改
- 配置文件 my.cnf(其它系统变量也是如此)
set global slow_query_log=1;
- my.cnf 要增加或修改参数 slow_query_log 和 slow_query_log_file,如下所示:
slow_query_log = 1
slow_query_log_file = /tmp/mysql_slow.log
- slow_query_log_file 这个参数用于指定慢查询日志的存放路径,缺省情况是 host_name-slow.log 文件。
show variables like 'slow_query_log_file';
+---------------------+-----------------------------------------------+
| Variable_name
| Value
|
+---------------------+-----------------------------------------------+
| slow_query_log_file | /home/WDPM/MysqlData/mysql/DB-Server-slow.log |
+---------------------+-----------------------------------------------+
1 row in set (0.00 sec)
- 开启了慢查询日志后,什么样的 SQL 才会记录到慢查询日志里面呢?这个是由参数 long_query_time 控制,默认情况下
long_query_time 的值为 10 秒,可以使用命令修改,也可以在 my.cnf 参数里面修改。
- 关于运行时间正好等于 long_query_time 的情况,并不会被记录下来;也就是说,在 mysql 源码里是判断大于 long_query_time,而非大于等于。
- 从 MySQL 5.1 开始,long_query_time 开始以微秒记录 SQL 语句运行时间,之前仅用秒为单位记录。如果记录到表里面,只会记录整数部分,不会记录微秒部分
- 注意,某些情况下当你使用局部设置的方式时可能会出现如下情况,来看下面:
show variables like 'long_query_time%';
# 查看当前 long_query_time 时间
+-----------------+-----------+
| Variable_name | Value
|
+-----------------+-----------+
| long_query_time | 10.000000 |
+-----------------+-----------+
set global long_query_time=4;
# 设置当前 long_query_time 时间
show variables like 'long_query_time';
# 再次查看 long_query_time 时间
- 如上所示,修改了变量 long_query_time,但是查询变量 long_query_time 的值还是 10,难道没有修改到呢?注意:使用命令 set
- global long_query_time=4 修改后,需要重新连接或新开一个会话才能看到修改值。用 show variables like 'long_query_time'查看只是当前会话的变量值。也可以不用重新连接会话,而是用 show global variables like 'long_query_time';。
- log_output 参数指定慢查询日志的存储方式:
- log_output='FILE'表示将日志存入文件,默认值也是'FILE'。
- log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到 mysql.slow_log 表中。同时也支持两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源。因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
show variables like '%log_output%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output
| FILE |
+---------------+-------+
set global log_output='TABLE';
show variables like '%log_output%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_output
| TABLE |
+---------------+-------+
select sleep(5) ;
+----------+
| sleep(5) |
+----------+
|
0 |
+----------+
- 当我们在上面执行了一次 sleep5 之后,这条操作将会被记录在慢查询日志中,我们来看看:
mysql> select * from mysql.slow_log;
+---------------------+---------------------------+------------+-----------+-----------+---------------+----+----------------+--------
---+-----------+-----------------+-----------+
| start_time
| user_host
| query_time | lock_time | rows_sent | rows_examined | db | last_insert_id | insert_id |
server_id | sql_text
| thread_id |
+---------------------+---------------------------+------------+-----------+-----------+---------------+----+----------------+--------
---+-----------+-----------------+-----------+
| 2016-06-16 17:37:53 | root[root] @ localhost [] | 00:00:03 | 00:00:00 |1 |0 ||0 |0 |1 |
select sleep(3) |5 |
| 2016-06-16 21:45:23 | root[root] @ localhost [] | 00:00:05 | 00:00:00 |1 |0 ||0 |0 |1 |
select sleep(5) |2 |
+---------------------+---------------------------+------------+-----------+-----------+---------------+----+----------------+--------
---+-----------+-----------------+-----------+
- 一些其他慢查询配置选项如下。
- log-queries-not-using-indexes 该系统变量指定未使用索引的查询也被记录到慢查询日志中,调优的话,建议开启这个选项。另外,
- 开启了这个参数,其实使用 full index scan 的 SQL 也会被记录到慢查询日志。
set global log_queries_not_using_indexes=1;
# 开启该选项
- log_slow_admin_statements 这个系统变量表示,是否将慢管理语句例如 ANALYZE TABLE 和 ALTER TABLE 等记入慢查询日志
- slow_queries 如果你想查询有多少条慢查询记录,可以使用 slow _queries 系统变量。
mysql> show global status like '%Slow_queries%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Slow_queries | 2104 |
+---------------+-------+
1 row in set (0.00 sec)
- MySQL-主从一致校验
- 场景需求
- 2020 年春,由我司开发的考试系统项目,经过不懈的运营努力,用户群体每日以指数倍激增,现考虑到数据库的安全可靠和访问性能问题,决定在业务中集成部署 Mysql 主从复制以实现读写分离等功能;巧的是,在想要进行主从复制操作前,我们的主要业务数据库已经工作了一段时间,现在要添加一台新的从数据库进行主从复制,通过一位发量稀少同事的一番操作,两台主机已经成功部署好了主从复制,但是我们该如何检测主从服务器的数据是否一致,如果不一致怎么同步数据?
- 参考答案
- 我们可以通过采用 pt-table-checksum 工具来检查主从的一致性,以下是具体流程。
- 工具安装
[root@MySQL-01 ~]# wget http://www.percona.com/get/percona-toolkit.tar.gz
- 安装所需依赖
[root@MySQL-01 ~]# yum install perl perl-devel perl-Time-HiRes perl-DBI perl-DBD-MySQL
perl-Compress-Raw-Bzip2
perl-Compress-Raw-Zlib
perl-Digest
perl-Digest-MD5
perl-IO-Compress
perl-IO-Socket-IP
perl-IO-Socket-SSL
perl-Mozilla-CA
perl-Net-Daemon
perl-Net-LibIDN
perl-Net-SSLeay
...
- 安装工具
[root@MySQL-01 ~]# tar zxf percona-toolkit-2.2.13.tar.gz
[root@MySQL-01 ~]# cd percona-toolkit-2.2.13
[root@MySQL-01 ~]# perl Makefile.PL
[root@MySQL-01 ~]# make && make install
- 在进行主从校验之前,我们首先需要对主从库进行授权,来看看如何来做吧
- 主库授权
root@node1 12:28: [pt_check]> GRANT CREATE,INSERT,SELECT,DELETE,UPDATE,LOCK
TABLES,PROCESS,SUPER,REPLICATION SLAVE ON *.* TO 'root'@'47.97.218.145' IDENTIFIED BY
'';
Query OK, 0 rows affected (0.00 sec)
root@node1 12:29: [pt_check]> flush privileges;
Query OK, 0 rows affected (0.00 sec)
root@node1 12:29: [pt_check]> select Host,User from mysql.user;+----------------+---------------+
| Host| User|
+---------------------+--------------------+
| localhost| root|
| localhost| mysql.session |
| localhost| mysql.sys|
| 172.16.156.%| rep|
| %| java|
| 192.168.1.101| ptuser|
+----------------------+---------------------+
- 从库授权
MariaDB [(none)]> GRANT SELECT, PROCESS, SUPER, REPLICATION SLAVE ON *.* TO
'root'@'9.106.84.122' IDENTIFIED BY '';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> flush privileges;
Query OK, 0 rows affected (0.00 sec)
- 授权到主从两个数据库之后呢,我们就可以开开心心的,进行主从数据一致性的校验。且看下面
- pt-table-checksum 是通过在主(master)上通过执行校验的查询对复制的一致性进行检查,对比主从的校验值,从而产生结果。
- DSN 指向的是主的地址,该工具的退出状态不为零,如果发现有任何差别,或者如果出现任何警告或错误,可以查看官方资料。
# 现在有一主库,数据如下:
mysql> select * from yayun.t1;
+----+-------+
| id | name |
+----+-------+
| 1 | yayun|
| 2 | atlas |
| 3 | mysql |
+----+-------+
3 rows in set (0.00 sec)
# 主库有三条数据
- 而从库的数据于主库是不一致的,我们来欣赏下从库不一致的数据:
mysql> select * from yayun.t1;
+----+----------+
| id | name |
+----+----------+
| 1 | yayun |
| 2 | atlas |
| 3 | mysql |
| 4 | dengyy |
| 5 | love sql |
+----+----------+
5 rows in set (0.00 sec)
# 从库有五条数据,多了俩条不一样的:4、5
- 接下来,我们通过工具进行检测
[root@MySQL-01 ~]# pt-table-checksum --nocheck-binlog-format
--nocheck-replication-filters --replicate=pt.checksums --databases test -u'root' -p''
-h127.0.0.1 -P3306
- 命令会展示如下的结果
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
04-13T15:59:31 0 1 3 1 0 0.080 yayun.t1
- 其中如上表所示的结果中,各字段解释如下
TS # 完成检查的时间
ERRORS # 检查时候发生错误和警告的数量
DIFFS # 0 表示一致,1 表示不一致
ROWS # 表的行数
CHUNKS # 被划分到表中的块的数目
SKIPPED # 由于错误或警告或过大,则跳过块的数目
TIME # 执行的时间
TABLE # 被检查的表名
- 清晰的看到,当主从之间数据不一致时,进行一致性检查看到的结果 DIFF 为 1。此时代表一致性是错误的。
- 上面命令的各参数的意思在这里也做好事做到底来解释一下:
--nocheck-replication-filters: # 不检查复制过滤器,建议启用。后面可以用--databases 来指定需要检查的数据库。
--no-check-binlog-format:# 不检查复制的 binlog 模式,要是 binlog 模式是 ROW,则会报错。
--replicate-check-only :# 只显示不同步的信息。
--replicate=:# 把 checksum 的信息写入到指定表中,建议直接写到被检查的数据库当中。
--databases=:# 指定需要被检查的数据库,多个则用逗号隔开。
--tables=:# 指定需要被检查的表,多个用逗号隔开
h=127.0.0.1:# Master 的地址
u=root:# 用户名
p=123456:# 密码
P=3306:# 端口
- 通过 DIFFS 是 1 就可以看出主从的表数据不一致。怎么不一致呢? 通过指定—replicate=yayun.checksums 参数,就说明把检查信息都写到了 checksums 表中。
- 进入 SLAVE 相应的库中查看 checksums 表的信息:
mysql> select * from checksums\G
*************************** 1. row ***************************
db: yayun
tbl: t1
chunk: 1
chunk_time: 0.010735
chunk_index: NULL
lower_boundary: NULL
upper_boundary: NULL
this_crc: babf1dc0#slave
this_cnt: 5#slave
master_crc: 8727436a#master
master_cnt: 3#master
# 可以发现表 t1 中从库比主库多 2 条记录
ts: 2014-04-13 16:05:16
1 row in set (0.00 sec)
- 通过上面找到了这些不一致的数据表,如何同步数据呢?即如何修复 MySQL 主从不一致的数据,让他们保持一致性呢?利用另外一个工具 pt-table-sync。
- 这个命令的使用很简单,他的语法是这个:pt-table-sync [OPTIONS] DSN [DSN]。pt-table-sync,高效的同步 MySQL 表之间的数据,他可以做单向和双向同步的表数据;他可以同步单个表,也可以同步整个库。
- 它不同步表结构、索引、或任何其他模式对象。所以在修复一致性之前需要保证他们表存在。
- 接着上面的复制情况,主和从的 t1 表数据不一致,需要修复,首先执行:
[root@MySQL-01 ~]# pt-table-sync --replicate=pt.checksums
h=47.97.218.145,u=root,p=123456 h=39.106.84.122,u=root,p=123456 --print
DELETE FROM `yayun`.`t1` WHERE `id`='' LIMIT 1 /*percona-toolkit src_db:yayun src_tbl:t1
src_dsn:h=127.0.0.1,p=...,u=root dst_db:yayun dst_tbl:t1 dst_dsn:h=192.168.0.20,p=...,u=root
lock:1 transaction:1 changing_src:yayun.checksums replicate:yayun.checksums bidirectional:0
pid:2190 user:root host:MySQL-01*/;
DELETE FROM `yayun`.`t1` WHERE `id`='' LIMIT 1 /*percona-toolkit src_db:yayun src_tbl:t1
src_dsn:h=127.0.0.1,p=...,u=root dst_db:yayun dst_tbl:t1 dst_dsn:h=192.168.0.20,p=...,u=root
lock:1 transaction:1 changing_src:yayun.checksums replicate:yayun.checksums bidirectional:0
pid:2190 user:root host:MySQL-01*/;
- 参数的意义:
--replicate= : # 指定通过 pt-table-checksum 得到的表,这 2 个工具差不多都会一直用。
--databases= : # 指定执行同步的数据库,多个用逗号隔开。
--tables= :# 指定执行同步的表,多个用逗号隔开。
--sync-to-master :# 指定一个 DSN,即从的 IP,他会通过 show processlist 或 show slave status 去
自动的找主。
h=127.0.0.1:# 服务器地址,命令里有 2 个 ip,第一次出现的是 Master 的地址,第 2 次是 Slave 的地址。
u=root:# 帐号。
p=123456:# 密码。
--print:# 打印,但不执行命令。
--execute:# 执行命令。
- 命令介绍完了,一起解释下执行的效果:通过(--print)打印出来了修复数据的 sql 语句,可以手动
- 的去从行执行,让他们数据保持一致性。那能否直接执行?当然可以,通过(--execute):
[root@MySQL-01 ~]# pt-table-sync --replicate=pt.checksums
h=47.97.218.145,u=root,p=123456
h=39.106.84.122,u=root,p=123456 --execute
- 没发现任何异常,然后检查主从数据的一致性:
[root@MySQL-01 ~]# pt-table-checksum --nocheck-binlog-format --nocheck-plan
--nocheck-replication-filters --replicate=pt.checksums --set-vars
innodb_lock_wait_timeout=120 --databases test -u'root' -p'' -h47.97.218.145 -P3306
TS ERRORS DIFFS ROWS CHUNKS SKIPPED TIME TABLE
04-13T16:27:28 0 0 3 1 0 0.097 yayun.t1
- 再来看看对应的数据库吧:
# 主库
mysql> select * from t1;
+----+-------+
| id | name |
+----+-------+
| 1 | yayun |
| 2 | atlas |
| 3 | mysql |
+----+-------+
3 rows in set (0.00 sec)
mysql>
# 从库会丢失掉之前多余的两条数据
mysql> select * from t1;
+----+-------+
| id | name |
+----+-------+
| 1 | yayun |
| 2 | atlas |
| 3 | mysql |
+----+-------+
3 rows in set (0.00 sec)
- OK,数据已经保持一致了。
- 建议还是用—print 打印出来的好,这样就可以知道那些数据有问题,可以人为的干预下。不然直接执行了,
- 出现问题之后更不好处理。总之还是在处理之前做好数据的备份工作。
- 注意:要是表中没有唯一索引或则主键则会报错。
Can't make changes on the master because no unique index exists at
/usr/local/bin/pt-table-sync line 10591.
- 最后,这些工具很给力,工作中常常在使用。注意使用该工具需要授权,一般 SELECT, PROCESS, SUPER, REPLICATION SLAVE 等权限就已经足够了。
- MySQL-基于 Docker 的主从复制
- 场景需求
- 今天老板要求 docker 搭建 mysql 主从同步,头皮发麻,无从下手,要求:使用 docker,并说明使用 docker 搭建得好处,实现原理,搭建具体过程。
- 参考答案
- 好处:
- 一台服务器可以运行多个 docker 容器。
- docker 容器之间相互独立,互不冲突。
- docker 使用步骤简便。
- 具体实现步骤
- 首先基于 docker 拉取 mysql 镜像
docker pull mysql:5.7
- 使用下载好的镜像,启动主从两个容器
docker run -p 3339:3306 --name mymysql –e MYSQL_ROOT_PASSWORD=123456 -d
mysql:5.7 # 主
docker run -p 3340:3306 --name mymysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:5.7
# 从
- 配置主从
docker exec -it 627a2368c865 /bin/bash # 进入容器,627a2368c865 是容器的 id,而
mysql-master 是容器的名称
apt-get update
apt-get install vim # 在容器中手动安装 vim
- vi my.cnf,进入/etc/mysql 目录下,对 my.cnf 进行编辑
[mysqld]
server-id = 100
log-bin = mysql-bin
service mysql restart # 重启 mysql
docker start mysql-master # 启动容器
- 创建主从所需权限用户
CREATE USER 'slave'@'%' IDENTIFIED BY '' # 创建用户
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'slave'@'%' # 设置权限
- 配置从数据库
[mysqld]
server-id = 101
service mysql restart # 重启 mysql
docker start mysql-master # 启动容器
change master to master_host='172.17.0.2', master_user='slave',
master_password='', master_port=3306, master_log_file='mysql-bin.000001',
master_log_pos= 254, master_connect_retry=30;
- 这里需要注意的是,有两个参数来自于主库,可以通过主库中运行 show master status 查看得到,分别是 master_log_file 以及
- master_log_pos。
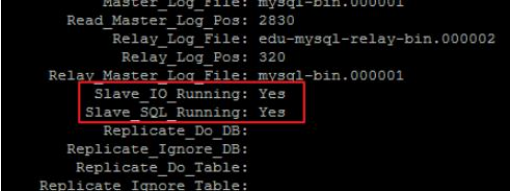
- 最终在从库执行 show slave status 查看从库状态即可。看到 IO 与 SQL 线程处于活跃状态即为正常。
Redis 宝典
- redis 的五大数据类型实现原理
- redis 中所有数据结构都以唯一的 key 字符串作为名称,然后通过这个唯一的 key 来获取对应的 value
- 不同的数据类型数据结构差异就在于 value 的结构不一样
- 字符串(string)
- value 的数据结构(数组)
- 字符串 value 数据结构类似于数组,采用与分配容易空间来减少内存频繁分配
- 当字符串长度小于 1M 时,扩容就是加倍现有空间
- 如果字符串长度操作 1M 时,扩容时最多扩容 1M 空间,字符串最大长度为 512M
- 字符串的使用场景(缓存)
- 字符串一个常见的用途是缓存用户信息,我们将用户信息使用 JSON 序列化成字符串
- 取用户信息时会经过一次反序列化的过程
- value 的数据结构(数组)
- list(列表)
- value 的数据结构(双向链表)
- 列表的数据结构是双向链表,这意味着插入和删除的时间复杂度是 0(1),索引的时间复杂度位 0(n)
- 当列表弹出最后一个元素后,该数据结构会被自动删除,内存被回手
- 列表的使用场景(队列、栈)
- value 的数据结构(双向链表)
- hash(字典)
- value 的数据结构(HashMap)
- redis 中的字典也是 HashMap(数组+列表)的二维结构
- 不同的是 redis 的字典的值只能是字符串
- hash 的使用场景(缓存)
- hash 可以用来缓存用户信息,与字符串一次性全部序列化整个对象不同,hash 可以对每个字段进行单独存储
- 这样可以部分获取用户信息,节约网络流量
- hash 也有缺点,hash 结构的存储消耗要高于单个字符串
- value 的数据结构(HashMap)
- redis 事
- redis 事物介绍
- redis 事物是可以一次执行多个命令,本质是一组命令的集合。
- 一个事务中的所有命令都会序列化,按顺序串行化的执行而不会被其他命令插入
- 作用:一个队列中,一次性、顺序性、排他性的执行一系列命令
- redis 事物基本使用
- 下面指令演示了一个完整的事物过程,所有指令在 exec 前不执行,而是缓存在服务器的一个事物队列中
- 服务器一旦收到 exec 指令才开始执行事物队列,执行完毕后一次性返回所有结果
- 因为 redis 是单线程的,所以不必担心自己在执行队列是被打断,可以保证这样的“原子性”
- 注:redis 事物在遇到指令失败后,后面的指令会继续执行
- mysql 的 rollback 与 redis 的 discard 的区别:
- mysql 回滚为 sql 全部成功才执行,一条 sql 失败则全部失败,执行 rollback 后所有语句造成的影响消失
- redis 的 discard 只是结束本次事务,正确命令造成的影响仍然还在.
- redis 事物介绍
> multi(开始一个 redis 事物)
incr books
incr books
> exec (执行事物)
> discard (丢弃事物)
- watch 指令
- watch 其实就是 redis 提供的一种乐观锁,可以解决并发修改问题
- watch 会在事物开始前盯住一个或多个关键变量,当服务器收到 exec 指令要顺序执行缓存中的事物队列时
- redis 会检查关键变量自 watch 后是否被修改(包括当前事物所在的客户端)
- 如果关键变量被人改动过,exec 指令就会返回 null 回复告知客户端事物执行失败,这个时候客户端会选择重试
- 注:redis 禁用在 multi 和 exec 之间执行 watch 指令,必须在 multi 之前盯住关键变量,否则会出错
- redis 分布式锁
- redis 事物
- 严格意义来讲,Redis 的事务和我们理解的传统数据库(如 mysql)的事务是不一样的;
- Redis 的事务实质上是命令的集合,在一个事务中要么所有命令都被执行,要么所有命令都不执行。
- 需要注意的是:
- Redis 的事务没有关系数据库事务提供的回滚(rollback),所以开发者必须在事务执行失败后进行后续的处理;
- 如果在一个事务中的命令出现错误,那么所有的命令都不会执行;
- 如果在一个事务中出现运行错误,那么正确的命令会被执行。
- redis 原子操作
- 原子操作是指不会被线程调度机制打断的操作
- 这种操作一旦开始,就会一直运行到结束,中间不会切换任何进程
- 分布式锁
- 分布式锁本质是占一个坑,当别的进程也要来占坑时发现已经被占,就会放弃或者稍后重试
- 占坑一般使用 setnx(set if not exists)指令,只允许一个客户端占坑
- 先来先占,用完了在调用 del 指令释放坑
- redis 事物
> setnx lock:codehole true
.... do something critical ....
> del lock:codehole
- 但是这样有一个问题,如果逻辑执行到中间出现异常,可能导致 del 指令没有被调用,这样就会陷入死锁,锁永远无法释放
- 为了解决死锁问题,我们拿到锁时可以加上一个 expire 过期时间,这样即使出现异常,当到达过期时间也会自动释放锁> setnx lock:codehole true
> expire lock:codehole 5
.... do something critical ....
> del lock:codehole
- 这样又有一个问题,setnx 和 expire 是两条指令而不是原子指令,如果两条指令之间进程挂掉依然会出现死锁
- 为了治理上面乱象,在 redis 2.8 中加入了 set 指令的扩展参数,使 setnx 和 expire 指令可以一起执行
> set lock:codehole true ex 5 nx
''' do something '''
> del lock:codehole
- 布隆过滤器
- 布隆过滤器是什么?(判断某个 key 一定不存在)
- 本质上布隆过滤器是一种数据结构,比较巧妙的概率型数据结构
- 特点是高效地插入和查询,可以用来告诉你 “某样东西一定不存在或者可能存在”。
- 相比于传统的 List、Set、Map 等数据结构,它更高效、占用空间更少,但是缺点是其返回的结果是概率性的,而不是确切的。
- 使用:
- 布隆过滤器在 NoSQL 数据库领域中应用的非常广泛
- 当用户来查询某一个 row 时,可以先通过内存中的布隆过滤器过滤掉大量不存在的 row 请求,然后去再磁盘进行查询
- 布隆过滤器说某个值不存在时,那肯定就是不存在,可以显著降低数据库 IO 请求数量
- 应用场景
- 场景 1(给用户推荐新闻)
- 当用户看过的新闻,肯定会被过滤掉,对于没有看多的新闻,可能会过滤极少的一部分(误判)。
- 这样可以完全保证推送给用户的新闻都是无重复的。
- 场景 2(爬虫 url 去重)
- 在爬虫系统中,我们需要对 url 去重,已经爬取的页面不再爬取
- 当 url 高达几千万时,如果一个集合去装下这些 URL 地址非常浪费空间
- 使用布隆过滤器可以大幅降低去重存储消耗,只不过也会使爬虫系统错过少量页面
- 布隆过滤器原理
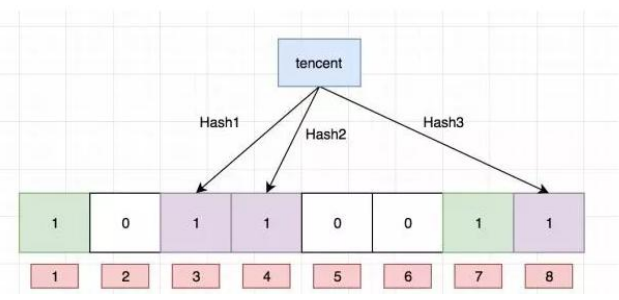
- 每个布隆过滤器对应到 Redis 的数据结构是一个大型的数组和几个不一样的无偏 hash 函数
- 如下图:f、g、h 就是这样的 hash 函数(无偏差指让 hash 映射到数组的位置比较随机)
- 添加:值到布隆过滤器
- 向布隆过滤器添加 key,会使用 f、g、h hash 函数对 key 算出一个整数索引,然后对长度取余
- 每个 hash 函数都会算出一个不同的位置,把算出的位置都设置成 1 就完成了布隆过滤器添加过程
- 查询:布隆过滤器值
- 当查询某个 key 时,先用 hash 函数算出一个整数索引,然后对长度取余
- 当你有一个不为 1 时肯定不存在这个 key,当全部都为 1 时可能有这个 key
- 这样内存中的布隆过滤器过滤掉大量不存在的 row 请求,然后去再磁盘进行查询,减少 IO 操作
- 删除:不支持
- 目前我们知道布隆过滤器可以支持 add 和 isExist 操作
- 如何解决这个问题,答案是计数删除,但是计数删除需要存储一个数值,而不是原先的 bit 位,会增大占用的内存大小。
- 增加一个值就是将对应索引槽上存储的值加一,删除则是减一,判断是否存在则是看值是否大于 0。
- 布隆过滤器是什么?(判断某个 key 一定不存在)
- redis 雪崩&穿透&击穿
- 缓存穿透
- 定义:
- 缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,接着查询数据库也无法查询出结果,
- 虽然也不会写入到缓存中,但是这将会导致每个查询都会去请求数据库,造成缓存穿透;
- 解决方法 :布隆过滤
- 对所有可能查询的参数以 hash 形式存储,在控制层先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
- 缓存雪崩
- 定义:
- 缓存雪崩是指,由于缓存层承载着大量请求,有效的保护了存储层,但是如果缓存层由于某些原因整体不能提供服务
- 于是所有的请求都会达到存储层,存储层的调用量会暴增,造成存储层也会挂掉的情况。
- 解决方法:
- 保证缓存层服务高可用性:比如 Redis Sentinel 和 Redis Cluster 都实现了高可用
- 依赖隔离组件为后端限流并降级:比如对某个 key 只允许一个线程查询数据和写缓存,其他线程等待。
- 缓存击穿
- 定义:
- 缓存击穿,就是说某个 key 非常热点,访问非常频繁,处于集中式高并发访问的情况
- 当这个 key 在失效的瞬间,大量的请求就击穿了缓存,直接请求数据库,就像是在一道屏障上凿开了一个洞。
- 解决方法:解决方式也很简单,可以将热点数据设置为永远不过期;
- 或者基于 redis or zookeeper 实现互斥锁,等待第一个请求构建完缓存之后,再释放锁,进而其它请求才能通过该 key 访问数据
- 缓存穿透
- 主从同步
- CPA 原理
- CPA 原理是分布式存储理论的基石: C(一致性);A(可用性); P(分区容忍性);
- 当主从网络无法连通时,修改操作无法同步到节点,所以“一致性”无法满足
- 除非我们牺牲“可用性”,也就是暂停分布式节点服务,不再提供修改数据功能,知道网络恢复
- 一句话概括 CAP: 当网络分区发生时,一致性 和 可用性 两难全
- redis 主从同步介绍
- 和 MySQL 主从复制的原因一样,Redis 虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。
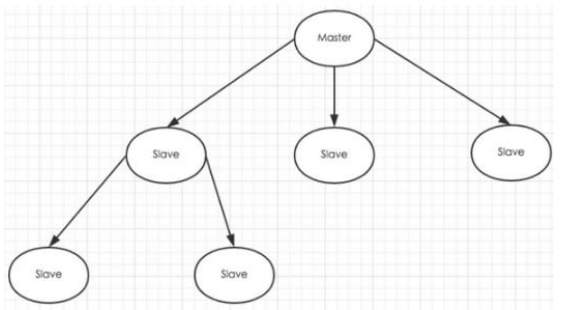
- 为了分担读压力,Redis 支持主从复制,Redis 的主从结构可以采用一主多从或者级联结构。
- Redis 主从复制可以根据是否是全量分为全量同步和增量同步。
- 注:redis 主节点 Master 挂掉时,运维让从节点 Slave 接管(redis 主从默认无法自动切换,需要运维手动切换)
- CPA 原理
- 全量同步(快照同步)
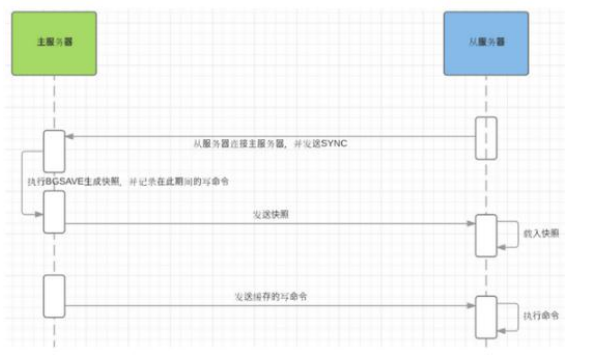
- 注:Redis 全量复制一般发生在 Slave 初始化阶段,这时 Slave 需要将 Master 上的所有数据都复制一份。具体步骤如下:
- 从服务器连接主服务器,发送 SYNC 命令;
- 主服务器接收到 SYNC 命名后,开始执行 BGSAVE 命令生成 RDB 文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器 BGSAVE 执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令;
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
- 完成上面几个步骤后就完成了从服务器数据初始化的所有操作,从服务器此时可以接收来自用户的读请求。
- 增量同步
- 主节点会将那些对自己状态产生修改性影响的指令记录在本地内存 buffer 中,然后异步将 buffer 中指令同步到从节点
- 从节点一边执行同步指令达到主节点状态,一边向主节点反馈自己同步到哪里(偏移量)
- 当网络状态不好时,从节点无法和主节点进行同步,当网络恢复时需要进行快照同步
- Redis 主从同步策略
- 主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。
- 当然,如果有需要,slave 在任何时候都可以发起全量同步。
- redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
- 注意点
- 如果多个 Slave 断线了,需要重启的时候,因为只要 Slave 启动,就会发送 sync 请求和主机全量同步,当多个同时出现的时候,可能会导致 Master IO 剧增宕机。
- 哨兵模式----sentinel
- sentinel 作用
- 当用 Redis 做主从方案时,假如 master 宕机,Redis 本身无法自动进行主备切换
- 而 Redis-sentinel 本身也是一个独立运行的进程,它能监控多个 master-slave 集群,发现 master 宕机后能进行自动切换。
- sentinel 原理
- sentinel 负责持续监控主节点的健康,当主节挂掉时,自动选择一个最优的从节点切换成主节点
- 从节点来连接集群时会首先连接 sentinel,通过 sentinel 来查询主节点的地址
- 当主节点发生故障时,sentinel 会将最新的主节点地址告诉客户端,可以实现无需重启自动切换 redis
- Sentinel 支持集群
- 只使用单个 sentinel 进程来监控 redis 集群是不可靠的,当 sentinel 进程宕掉后 sentinel 本身也有单点问题
- 如果有多个 sentinel,redis 的客户端可以随意地连接任意一个 sentinel 来获得关于 redis 集群中的信息。
- Sentinel 版本
- Sentinel 当前稳定版本称为 Sentinel 2,Redis2.8 和 Redis3.0 附带稳定的哨兵版本
- 安装完 redis-3.2.8 后,redis-3.2.8/src/redis-sentinel 启动程序 redis-3.2.8/sentinel.conf 是配置文件。
- 运行 sentinel 两种方式(效果相同)
- 法 1:redis-sentinel /path/to/sentinel.conf
- 法 2:redis-server /path/to/sentinel.conf --sentinel
- 以上两种方式,都必须指定一个 sentinel 的配置文件 sentinel.conf,如果不指定,将无法启动 sentinel。
- sentinel 默认监听 26379 端口,所以运行前必须确定该端口没有被别的进程占用。
- sentinel.conf 配置文件说明
- 配置文件只需要配置 master 的信息就好啦,不用配置 slave 的信息,因为 slave 能够被自动检测到
- 需要注意的是,配置文件在 sentinel 运行期间是会被动态修改的,例如当发生主备切换时候,配置文件中的 master 会被修改为另外一个slave。
- 这样,之后 sentinel 如果重启时,就可以根据这个配置来恢复其之前所监控的 redis 集群的状态。
# sentinel.conf 配置说明
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 60000
sentinel failover-timeout mymaster 180000
sentinel parallel-syncs mymaster 1
- 配置传播
- 一旦一个 sentinel 成功地对一个 master 进行了 failover,它将会把关于 master 的最新配置通过广播形式通知其它 sentinel,其它的sentinel 则更新对应 master 的配置。
- 一个 faiover 要想被成功实行,sentinel 必须能够向选为 master 的 slave 发送 SLAVE OF NO ONE 命令,然后能够通过 INFO 命令看到新 master 的配置信息。
- 当将一个 slave 选举为 master 并发送 SLAVE OF NO ONE`后,即使其它的 slave 还没针对新 master 重新配置自己,failover 也被认为是成功了的。
- 因为每一个配置都有一个版本号,所以以版本号最大的那个为标准:
- 假设有一个名为 mymaster 的地址为 192.168.1.50:6379。
- 一开始,集群中所有的 sentinel 都知道这个地址,于是为 mymaster 的配置打上版本号 1。
- 一段时候后 mymaster 死了,有一个 sentinel 被授权用版本号 2 对其进行 failover。
- 如果 failover 成功了,假设地址改为了 192.168.1.50:9000,此时配置的版本号为 2
- 进行 failover 的 sentinel 会将新配置广播给其他的 sentinel,发现新配置的版本号为 2 时,版本号变大了,说明配置更新了,于是 就会采用最新的版本号为 2 的配置。
- codis 集群
- 为什么会出现 codis
- 在大数据高并发场景下,单个 redis 实例往往会无法应对
- 首先 redis 内存不易过大,内存太大会导致 rdb 文件过大,导致主从同步时间过长
- 其次在 CPU 利用率中上,单个 redis 实例只能利用单核,数据量太大,压力就会特别大
- 什么是 codis
- codis 是 redis 集群解决方案之一,codis 是 GO 语言开发的代理中间件
- 当客户端向 codis 发送指令时,codis 负责将指令转发给后面的 redis 实例来执行,并将返回结果转发给客户端
- codis 部署方案
- 单个 codis 代理支撑的 QPS 比较有限,通过启动多个 codis 代理可以显著增加整体 QPS
- 多 codis 还能起到容灾功能,挂掉一个 codis 代理还有很多 codis 代理可以继续服务
- codis 分片的原理
- codis 负责将特定 key 转发到特定 redis 实例,codis 默认将所有 key 划分为 1024 个槽位
- 首先会对客户端传来的 key 进行 crc32 计算 hash 值,然后将 hash 后的整数值对 1024 进行取模,这个余数就是对应的 key 槽位
- 每个槽位都会唯一映射到后面的多个 redis 实例之一,codis 会在内存中维护槽位和 redis 实例的映射关系
- 这样有了上面 key 对应的槽位,那么它应该转发到那个 redis 实例就很明确了
- 槽位数量默认是 1024,如果集群中节点较多,建议将这个数值大一些,比如 2048,4096
- 不同 codis 槽位如何同步
- 如果 codis 槽位值存在内存中,那么不同的 codis 实例间的槽位关系得不到同步
- 所以 codis 还需要一个分布式配置存储的数据库专门来持久化槽位关系
- codis 将槽位关系存储在 zookeeper 中,并且提供一个 dashboard 可以来观察和修改槽位关系
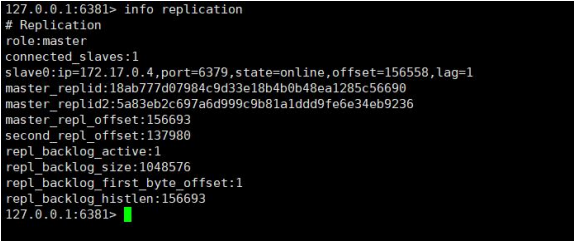
- 进入从库发现 6380 之前的角色是 slave,现在已经是 master 了。也就是成功了。
- 常见数据结构
- 栈
- 栈的定义:栈是一种数据集合,可以理解为只能在一端进行插入或删除操作的列表
- 栈的特点:后进先出(last-in, first-out)
- 队列定义
- 队列是一个数据集合,仅允许在列表的一端进行插入,另一端进行删除
- 插入的一端称为队尾(rear),插入动作叫进队或入队
- 进行删除的一端称为对头(front),删除动作称为出队
- 队列性质:先进先出(First-in, First-out)
- 双向队列:队列的两端都允许进行进队和出队操作
- 链表
- 链表中每个元素都是一个对象,每个对象称为一个节点,包含有数据域 key 和指向下一节点的指针 next,通过各个节点间的相互连接,最终串联成一个链表
- 数组
- 所谓数组,就是相同数据类型的元素按一定顺序排列的集合
- 在 Java 等其他语言中并不是所有的数据都能存储到数组中,只有相同类型的数据才可以一起存储到数组中。
- 因为数组在存储数据时是按顺序存储的,存储数据的内存也是连续的,所以他的特点就是寻址读取数据比较容易,插入和删除比较困难
- 字典对象实现原理
- 哈希表 (hash tables)
- 哈希表(也叫散列表),根据关键值对(Key-value)而直接进行访问的数据结构。
- 它通过把 key 和 value 映射到表中一个位置来访问记录,这种查询速度非常快,更新也快。
- 而这个映射函数叫做哈希函数,存放值的数组叫做哈希表。
- 通过把每个对象的关键字 k 作为自变量,通过一个哈希函数 h(k),将 k 映射到下标 h(k)处,并将此对象存储在这个位置。
- 具体操作过程
- 数据添加:把 key 通过哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将 value 存储在以该数字为下标的数组空间里。
- 数据查询:再次使用哈希函数将 key 转换为对应的数组下标,并定位到数组的位置获取 value。
- {“name”:”zhangsan”,”age”:26} 字典如何存储的呢?
- 比如字典{“name”:”zhangsan”,”age”:26},那么他们的字典 key 为 name、age,假如哈希函数 h(“name”) = 1、h(“age”)=3,
- 那么对应字典的 key 就会存储在列表对应下标的位置,[None, “zhangsan”, None, 26
- 解决 hash 冲突

- 二分法查找
l = list(range(1,101))
def bin_search(data_set,val):
low = 0
high = len(data_set) - 1
while low <= high:
mid = (low+high)//2
if data_set[mid] == val:
return mid
elif data_set[mid] < val:
low = mid + 1
else:
high = mid - 1
return
n = bin_search(l,11)
print(n) # 返回结果是: 10
- 冒泡法排序
- 原理:拿自己与上面一个比较,如果上面一个比自己小就将自己和上面一个调换位置,依次再与上面一个比较,第一轮结束后最上面那个一 定是最大的数
#! /usr/bin/env pythonf
# -*- coding: utf-8 -*-
def bubble_sort(li):
for i in range(len(li)-1):
for j in range(len(li)-i-1):
if li[j] > li[j+1]:
li[j],li[j+1]=li[j+1],li[j]
li = [1,5,2,6,3,7,4,8,9,0]
bubble_sort(li)
print(li) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- 快排
#! /usr/bin/env python
# -*- coding: utf-8 -*-
def quick(list):
if len(list) < 2:
return list tmp = list[0] # 临时变量 可以取随机值
left = [x for x in list[1:] if x <= tmp] # 左列表
right = [x for x in list[1:] if x > tmp] # 右列表
return quick(left) + [tmp] + quick(right) li = [4,3,7,5,8,2]
print quick(li) # [2, 3, 4, 5, 7, 8]
#### 对[4,3,7,5,8,2]排序
'''
[3, 2] + [4] + [7, 5, 8] # tmp = [4]
[2] + [3] + [4] + [7, 5, 8] # tmp = [3] 此时对[3, 2]这个列表进行排序
[2] + [3] + [4] + [5] + [7] + [8] # tmp = [7] 此时对[7, 5, 8]这个列表进行排序 '''
# 注:快排代码实现(类似于二叉树 递归调用)----右手左手一个慢动作,右手左手一个慢动作重播

- 递归斐波那契
def fun(i):
if i == 0:
return 0
elif i == 1:
return 1
else:
return fun(i-2) + fei(i-1)
if __name__ == '__main__':
for i in range(10):
print(fun(i),end=" ")
- 青蛙跳台阶
# 一只青蛙一次可以跳上 1 级台阶,也可以跳上 2 级……它也可以跳上 n 级。求该青蛙跳上一个 n 级的台阶
总共有多少种跳法。
fib = lambda n: n if n < 2 else 2 * fib(n - 1)
- Linux-supervisor
- 场景需求
- 我司运营部门日常工作需要处理大量数据和报表,我司拟开发内部 OA 系统提高各部门工作效率。现项目内设备扫描功能使用了 celery做的任务队列,进行异步扫描,同时又使用到 Flower 来监控任务队列。为了方便管理,在项目中使用了 Supervisor 来管理进程数据。请实现使用 supervisor 进行任务管理
- 参考答案
- Supervisor 是用 Python 开发的一个 client/server 服务,是 Linux/Unix 系统下的一个进程管理工具,不支持 Windows 系统。它可以很方便的监听、启动、停止、重启一个或多个进程。用 Supervisor 管理的进程,当一个进程意外被杀死,supervisort 监听到进程死后,会自动将它重新拉起,很方便的做到进程自动恢复的功能,不再需要自己写 shell 脚本来控制。
- 不使用守护进程会出现的三个问题:
- ASP.NET Core 应用程序运行在 shell 之中,如果关闭 shell 则会发现 ASP.NET Core 程序被关闭,从而导致应用无法访问,这种情况当然是我们不想遇到的,而且生产环境对这种情况是零容忍的。
- 如果 ASP.NET Core 进程意外终止那么需要人为连进 shell 进行再次启动,往往这种操作都不够及时。
- 如果服务器宕机或需要重启,我们则还是需要连入 shell 进行启动。
- 为了解决这些问题,我们需要有一个程序来监听 ASP.NET Core 应用程序的状况。并在应用程序停止运行的时候立即重新启动
# 编辑进程管理配置文件
[root@sandboxmp ~]$ touch /etc/supervisord.d/celery_worker.ini
[root@sandboxmp ~]$ vim /etc/supervisord.d/celery_worker.ini
# 将以下内容写入配置文件保存并退出
[program:celery-worker]
command=/root/.virtualenvs/sandboxMP/bin/celery worker -A sandboxMP -l INFO
directory=/opt/app/sandboxMP
environment=PATH="/root/.virtualenvs/sandboxMP/bin/"
stdout_logfile=/opt/app/sandboxMP/slogs/celery_worker.log
stderr_logfile=/opt/app/sandboxMP/slogs/celery_worker.log
autostart=true
autorestart=true
priority=901
[program:celery-flower]
command=/root/.virtualenvs/sandboxMP/bin/celery flower --broker=redis://localhost:6379/0
directory=/opt/app/sandboxMP
environment=PATH="/root/.virtualenvs/sandboxMP/bin/"
stdout_logfile=/opt/app/sandboxMP/slogs/celery_flower.log
stderr_logfile=/opt/app/sandboxMP/slogs/celery_flower.logautostart=true
autorestart=true
priority=900
systemctl start supervisord # 启动 supervisord
systemctl enable supervisord # 加到开机启动
- linux 常见文件和目录管理命令(文档中列举了 19 个最常见的)
1、系统命令 runlevel # 查看当前的运行级别
systemctl status firewalld # 开启网络服务功能
stop # 关闭
restart # 重启
reload # 重载
reboot # 重启
halt # 关机
poweroff # 关机 2、查看文件常用指令
cat # 在命令提示符下查看文件内容
more # 在命令提示符中分页查看文件内容
less # 命令行中查看文件可以上下翻页反复浏览
head # 命令行中查看文件头几行
tail # 命令行中查看文件尾几行
wc # 统计文件的单词数 行数等信息 3、目录管理常用指令
pwd # 查看你当前所在的目录
cd # 切换目录
ls # 查看显示目录的内容
du # 统计目录和文件空间的占用情况
mkdir # 创建新目录
rmdir # 删除空目录
touch # 创建文件
rm # 删除文件
ln # 创建硬链接
ln -s # 创建软链接
cp # 复制文件或目录
mv # 移动文件或目录
which # 查看 linux 命令所在的目录 复制代码 4、账号与权限
'''1.组管理'''
groupadd group_name # 创建一个新用户组
groupdel group_name # 删除一个用户组
groupmod -n new_group_name old_group_name # 重命名一个用户组
'''2.用户管理'''
useradd zhangsan # 创建账户张三
passwd zhangsan # 给用户设置密码
userdel -r zhangsan # 删除张三及他的宿主目录
'''3.用户组管理'''
gpasswd -a zhangsan root # 将张三用户加入 root 组
groups zhangsan # 确认 zhangsan 用户在 root 组
gpasswd -d lisi root # 将李 zhangsan 户从 root 组中删除
'''4.权限管理'''
chown -R zhangsan /aaa # 将文件夹/aaa 的多有者修改为 zhangsan
chown root:root /aaa # 将/aaa 文件夹的属主和属组都改成 root
chmod 777 /aaa # 给文件夹文件/aaa 设置权限为 777
Python 【面试强化宝典】的更多相关文章
- 《Java程序员面试笔试宝典》终于在万众期待中出版啦~
<Java程序员面试笔试宝典>终于在万众期待中出版啦~它是知名畅销书<程序员面试笔试宝典>的姊妹篇,而定价只要48元哦,恰逢求职季节,希望本书的出版能够让更多的求职者能够走进理 ...
- 程序员求职之道(《程序员面试笔试宝典》)之求职有用网站及QQ群一览表
技术学习网站 www.csdn.com www.iteye.com www.51cto.com http://www.cnblogs.com/ http://oj.leetcode.com/ http ...
- 《Java程序猿面试笔试宝典》之Java与C/C++有什么异同
Java与C++都是面向对象语言,都使用了面向对象思想(比如封装.继承.多态等),因为面向对象有很多非常好的特性(继承.组合等),使得二者都有非常好的可重用性. 须要注意的是,二者并不是全然一样,以下 ...
- Python面试真题答案或案例
Python面试真题答案或案例如下: 请等待. #coding=utf-8 #1.一行代码实现1--100之和 print(sum(range(1,101))) #2.如何在一个函数内部修改全局变量 ...
- 新书出版 |《Oracle程序员面试笔试宝典》
新书出版 |<Oracle程序员面试笔试宝典> <Oracle程序员面试笔试宝典> 丛书[数据库 面试 笔试宝典]已在京东.淘宝和天猫预售,一共 5 本,目前市场上已有4本,丛 ...
- Python面试 【315+道题】
Python面试 [315+道题] 第一部分 Python基础篇(80题) 为什么学习Python? 因为看到python的发展趋势,觉得需要与时俱进,第一点,python开发速度极快,能快速完成一个 ...
- 10个Python面试常问的问题
概述 Python是个非常受欢迎的编程语言,随着近些年机器学习.云计算等技术的发展,Python的职位需求越来越高.下面我收集了10个Python面试官经常问的问题,供大家参考学习. 类继承 有如下的 ...
- Python面试基础篇
1. 为什什么学习Python? Life is short, You need Python 2. 通过什什么途径学习的Python? pass 3. Python和Java.PHP.C.C#.C+ ...
- 《Java程序猿面试笔试宝典》之组合与继承有什么差别
组合和继承是面向对象中两种代码复用的方式. 组合是指在新类里面创建原有类的对象,反复利用已有类的功能.继承是面向对象的主要特性之中的一个,它同意设计人员依据其他类的实现来定义一个类的实现. 组合和继承 ...
随机推荐
- 运行redis数据库
启动redis服务器:redis-server /usr/local/redis-5.0.5/etc/redis.conf 关闭: redis-cli shutdown启动客户端:进入bin文件夹,输 ...
- Pytest系列(2) - assert断言详细使用
如果你还想从头学起Pytest,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1690628.html 前言 与unittest不同,py ...
- MATLAB 随机过程基本理论
一.平稳随机过程 1.严平稳随机过程 clc clear n=0:1000; x=randn(1,1001); subplot(211),plot(n,x); xlabel('n');ylabel(' ...
- 用c#每日更换“必应背景图片”为“桌面壁纸”
必应每天都会更换背景图片,都非常漂亮,有的时候还十分惊艳,同时还会根据每个地区的特色不同应用不同的图片. 下面用c#抓取必应每天的背景图片,并实现桌面壁纸的每天自动切换 实现思路 1.通过获取&quo ...
- 汇编学习-三(VB)
闲来无事做了一下160个crackme,因为是VB程序,所以将得到的一点心得记录如下(OD加载注释) push eax ; Andréna.004018A8 call dword ptr ds:[&l ...
- A换算时间(只想开学)HDU 6556
题目链接 思路如下 把时间转化为 24小时制下进行考虑,首先我们要明白(在24小时制下):12 点表示是下午PM ,而 24点表示的是明天的 0点(12小时制下),这两个地方需要特殊考虑 题解如下 # ...
- XXE白盒审计 PHP
XXE与XML注入的区别 https://www.cnblogs.com/websecurity-study/p/11348913.html XXE又分为内部实体和外部实体.我简单区分为内部实体就是自 ...
- 《Java基础复习》-控制执行流程
最近任务太多了,肝哭我了,boom 参考书目:Thinking in Java <Java基础复习>-控制执行流程 Java使用了C的所有流程控制语句 涉及关键字:if-else.whil ...
- dict字典的用法
在用dict遇到了一些困难,记一下. 代码1: books={"倚天屠龙记":{"id":1,"price":100}, "好吗好 ...
- RHCS概述
RHCS概述 创建RHCS集群环境 创建高可用Apache服务 1 创建RHCS集群环境 1.1 问题 准备四台KVM虚拟机,其三台作为集群节点,一台安装luci并配置iSCSI存储服务,实现如下功能 ...