drf-jwt的过滤,筛选,排序,分页组件
自定义drf-jwt配置
到rest_framework_jwt文件夹中的settings.py
from django.conf import settings
from rest_framework.settings import APISettings
USER_SETTINGS = getattr(settings, 'JWT_AUTH', None) #settings表示自己的settings文件配置中映射
自己的settings.py中,可以将rest_framework_jwt文件夹中的settings.py中的DEFAULT中的在settings.py中,方便后期导包使用,并且可以自定义
# 自定义 drf-jwt 配置
import datetime
JWT_AUTH = {
# user => payload
'JWT_PAYLOAD_HANDLER':
'rest_framework_jwt.utils.jwt_payload_handler',
# payload => token
'JWT_ENCODE_HANDLER':
'rest_framework_jwt.utils.jwt_encode_handler',
# token => payload
'JWT_DECODE_HANDLER':
'rest_framework_jwt.utils.jwt_decode_handler',
# token过期时间
'JWT_EXPIRATION_DELTA': datetime.timedelta(days=7),
# token刷新的过期时间
'JWT_REFRESH_EXPIRATION_DELTA': datetime.timedelta(days=7),
# 反爬小措施前缀
'JWT_AUTH_HEADER_PREFIX': 'JWT',
}
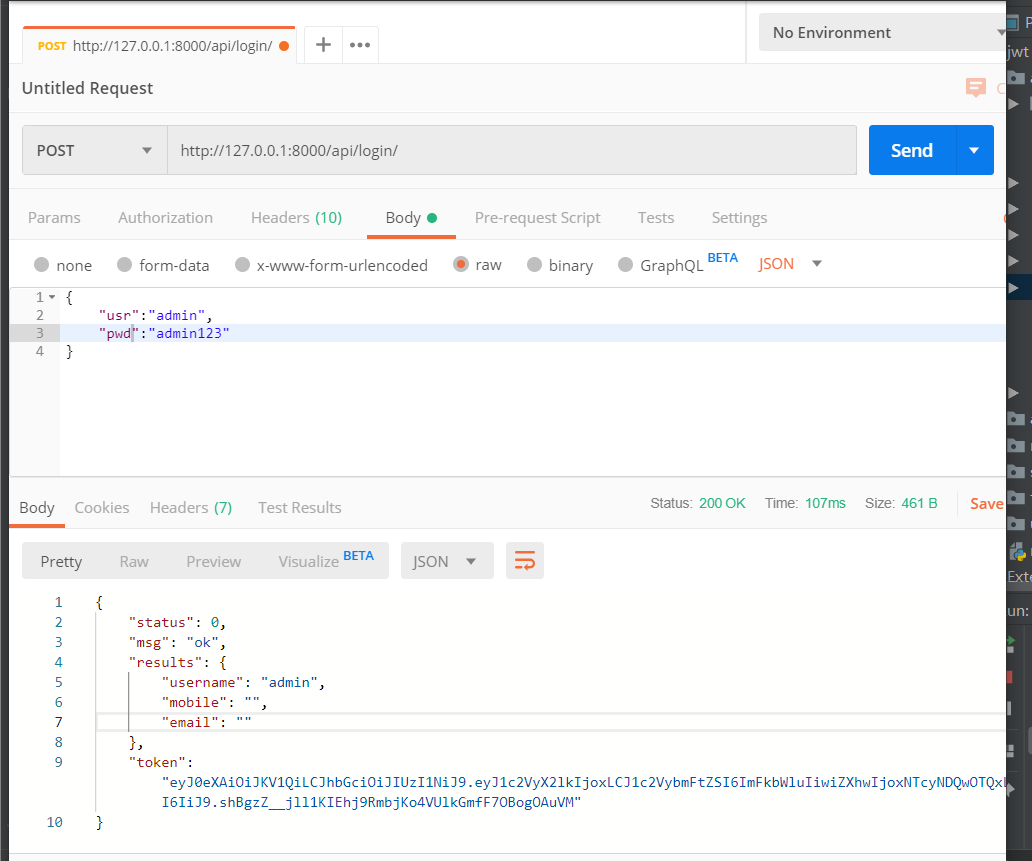
案例:实现多方式登陆签发token
urls.py
re_path(r'^login/$', views.LoginAPIView.as_view()),
models.py
from django.db import models
from django.contrib.auth.models import AbstractUser
class User(AbstractUser):
mobile = models.CharField(max_length=11, unique=True)
class Meta:
db_table = 'api_user'
verbose_name = '用户表'
verbose_name_plural = verbose_name
def __str__(self):
return self.username
serializers.py
from rest_framework import serializers
from . import models
import re
# 拿到前台token的两个函数: user => payload => token
# from rest_framework_jwt.settings import api_settings
# jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER
# jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
from rest_framework_jwt.serializers import jwt_payload_handler
from rest_framework_jwt.serializers import jwt_encode_handler
# 1) 前台提交多种登录信息都采用一个key,所以后台可以自定义反序列化字段进行对应
# 2) 序列化类要处理序列化与反序列化,要在fields中设置model绑定的Model类所有使用到的字段
# 3) 区分序列化字段与反序列化字段 read_only | write_only
# 4) 在自定义校验规则中(局部钩子、全局钩子)校验数据是否合法、确定登录的用户、根据用户签发token
# 5) 将登录的用户与签发的token保存在序列化类对象中
class UserModelSerializer(serializers.ModelSerializer):
# 自定义反序列字段:一定要设置write_only,只参与反序列化,不会与model类字段映射
usr = serializers.CharField(write_only=True)
pwd = serializers.CharField(write_only=True)
class Meta:
model = models.User
fields = ['usr', 'pwd', 'username', 'mobile', 'email']
# 系统校验规则
extra_kwargs = {
'username': {
'read_only': True
},
'mobile': {
'read_only': True
},
'email': {
'read_only': True
},
}
def validate(self, attrs):
usr = attrs.get('usr')
pwd = attrs.get('pwd')
# 多方式登录:各分支处理得到该方式下对应的用户
if re.match(r'.+@.+', usr):
user_query = models.User.objects.filter(email=usr)
elif re.match(r'1[3-9][0-9]{9}', usr):
user_query = models.User.objects.filter(mobile=usr)
else:
user_query = models.User.objects.filter(username=usr)
user_obj = user_query.first()
# 签发:得到登录用户,签发token并存储在实例化对象中
if user_obj and user_obj.check_password(pwd):
# 签发token,将token存放到 实例化类对象的token 名字中
payload = jwt_payload_handler(user_obj)
token = jwt_encode_handler(payload)
# 将当前用户与签发的token都保存在序列化对象中
self.user = user_obj
self.token = token
return attrs
raise serializers.ValidationError({'data': '数据有误'})
views.py
#实现多方式登陆签发token:账号、手机号、邮箱等登陆
# 1) 禁用认证与权限组件
# 2) 拿到前台登录信息,交给序列化类
# 3) 序列化类校验得到登录用户与token存放在序列化对象中
# 4) 取出登录用户与token返回给前台
import re
from . import serializers, models
from utils.response import APIResponse
from rest_framework_jwt.serializers import jwt_payload_handler
from rest_framework_jwt.serializers import jwt_encode_handler
class LoginAPIView(APIView):
# 1) 禁用认证与权限组件
authentication_classes = []
permission_classes = []
def post(self, request, *args, **kwargs):
# 2) 拿到前台登录信息,交给序列化类,规则:账号用usr传,密码用pwd传
user_ser = serializers.UserModelSerializer(data=request.data)
# 3) 序列化类校验得到登录用户与token存放在序列化对象中
user_ser.is_valid(raise_exception=True)
# 4) 取出登录用户与token返回给前台
return APIResponse(token=user_ser.token, results=serializers.UserModelSerializer(user_ser.user).data)
# "一根筋" 思考方式:所有逻辑都在视图类中处理
def my_post(self, request, *args, **kwargs):
usr = request.data.get('usr')
pwd = request.data.get('pwd')
if re.match(r'.+@.+', usr):
user_query = models.User.objects.filter(email=usr)
elif re.match(r'1[3-9][0-9]{9}', usr):
user_query = models.User.objects.filter(mobile=usr)
else:
user_query = models.User.objects.filter(username=usr)
user_obj = user_query.first()
if user_obj and user_obj.check_password(pwd):
payload = jwt_payload_handler(user_obj)
token = jwt_encode_handler(payload)
return APIResponse(results={'username': user_obj.username}, token=token)
return APIResponse(data_msg='不可控错误')
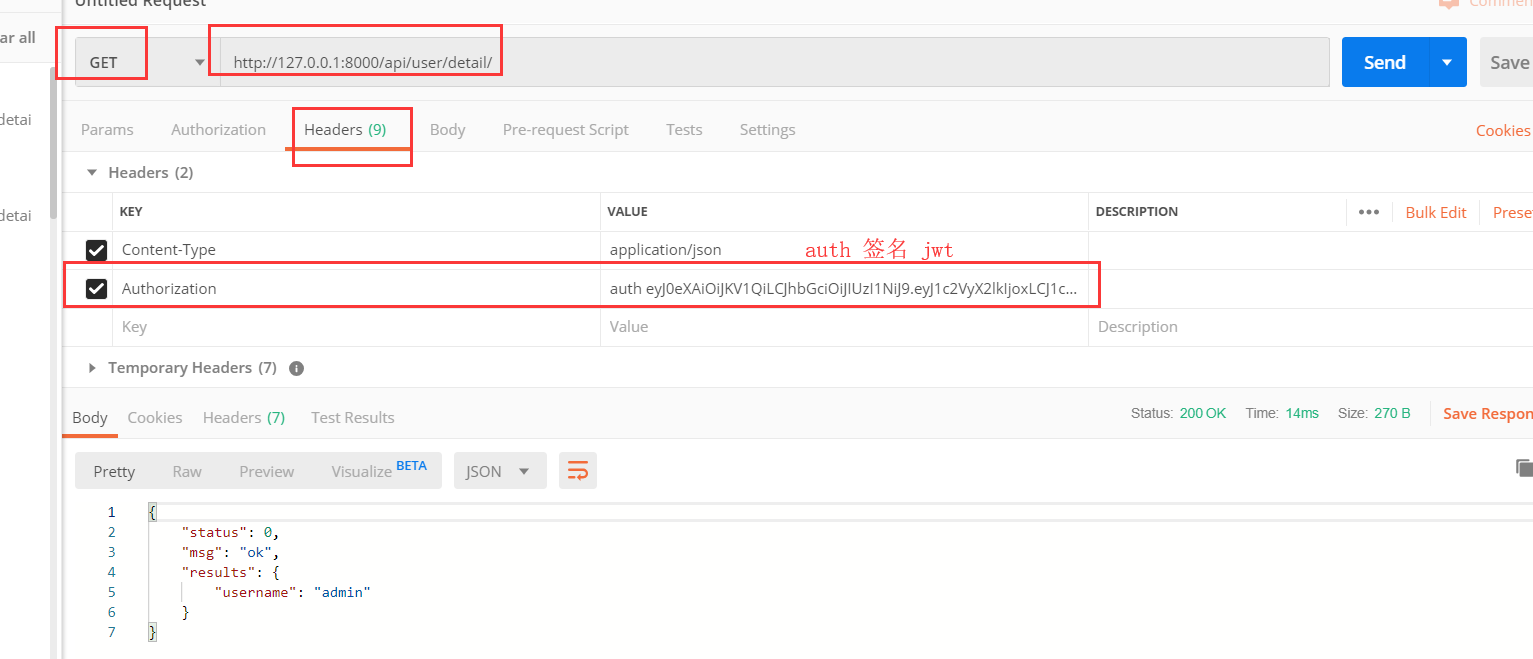
案例:自定义认证反爬规则的认证类
urls.py
re_path(r'^user/detail/$', views.UserDetail.as_view()),
authentications.py
import jwt
from rest_framework_jwt.authentication import BaseJSONWebTokenAuthentication
from rest_framework_jwt.authentication import jwt_decode_handler
from rest_framework.exceptions import AuthenticationFailed
class JWTAuthentication(BaseJSONWebTokenAuthentication):
def authenticate(self, request):
jwt_token = request.META.get('HTTP_AUTHORIZATION')
# 自定义校验规则:auth token jwt
token = self.parse_jwt_token(jwt_token)
if token is None:
return None
try:
# token => payload
payload = jwt_decode_handler(token)
except jwt.ExpiredSignature:
raise AuthenticationFailed('token已过期')
except:
raise AuthenticationFailed('非法用户')
# payload => user
user = self.authenticate_credentials(payload)
return (user, token)
# 自定义校验规则:auth token jwt,auth为前盐,jwt为后盐
def parse_jwt_token(self, jwt_token):
tokens = jwt_token.split()
if len(tokens) != 3 or tokens[0].lower() != 'auth' or tokens[2].lower() != 'jwt':
return None
return tokens[1]
views.py
from rest_framework.views import APIView
from utils.response import APIResponse
# 必须登录后才能访问 - 通过了认证权限组件
from rest_framework.permissions import IsAuthenticated
# 自定义jwt校验规则
from .authentications import JWTAuthentication
class UserDetail(APIView):
authentication_classes = [JWTAuthentication]
permission_classes = [IsAuthenticated]
def get(self, request, *args, **kwargs):
return APIResponse(results={'username': request.user.username})
测试
admin使用自定义User表:新增用户密码密文
admin.py
from django.contrib import admin
from . import models
# 自定义User表,admin后台管理,采用密文密码
from django.contrib.auth.admin import UserAdmin
class MyUserAdmin(UserAdmin):
add_fieldsets = (
(None, {
'classes': ('wide',),
'fields': ('username', 'password1', 'password2', 'mobile', 'email'),
}),
)
admin.site.register(models.User, MyUserAdmin)
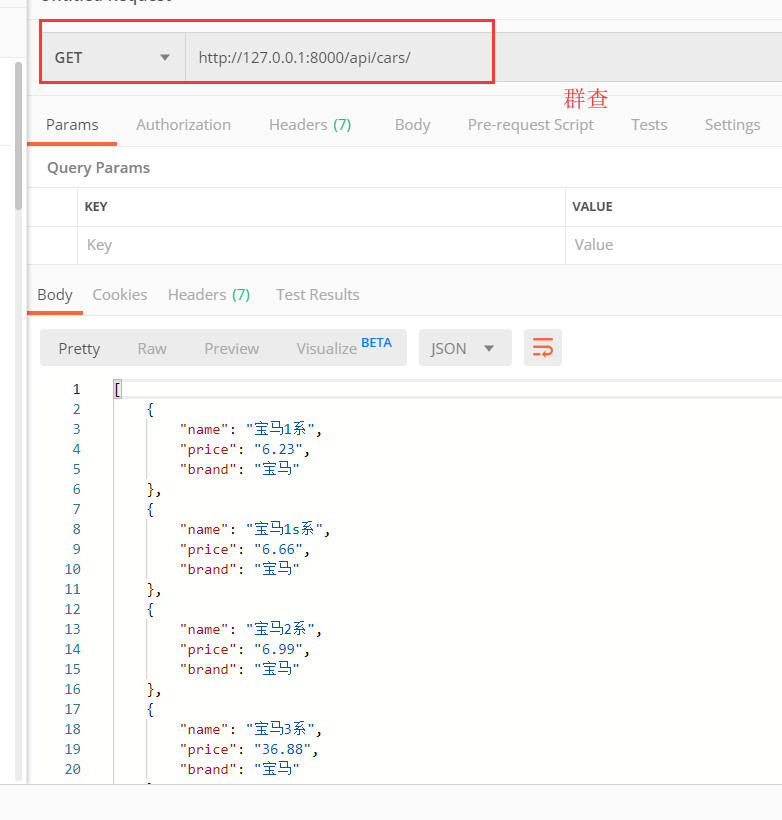
群查接口各种筛选组件数据准备
models.py
class Car(models.Model):
name = models.CharField(max_length=16, unique=True, verbose_name='车名')
price = models.DecimalField(max_digits=10, decimal_places=2, verbose_name='价格')
brand = models.CharField(max_length=16, verbose_name='品牌')
class Meta:
db_table = 'api_car'
verbose_name = '汽车表'
verbose_name_plural = verbose_name
def __str__(self):
return self.name
admin.py
admin.site.register(models.Car)
到后台录数据
serializers.py
class CarModelSerializer(serializers.ModelSerializer):
class Meta:
model = models.Car
fields = ['name', 'price', 'brand']
views.py
# Car的群查接口
from rest_framework.generics import ListAPIView
class CarListAPIView(ListAPIView):
queryset = models.Car.objects.all()
serializer_class = serializers.CarModelSerializer
urls.py
url(r'^cars/$', views.CarListAPIView.as_view()),
源码分析
get请求来-->ListAPIView-->get方法 -->1.父类 ListModelMixins中的list方法 -->ListAPIView父类GenericAPIView-->2.filter_querysert方法
filter_backends中存放过滤类们,可以自己写,也可以采用系统写好的过滤类
rest_framwork_jwt文件包-->filters.py
3.BaseFilterBackend(object) -->def filter_queryset
4.SearchFilter(BaseFilterBackend) -->def filter_queryset
5. OrderingFilter(BaseFilterBackend) -->def filter_queryset
1.父类 ListModelMixins中的list方法
class ListModelMixin(object):
"""
List a queryset.
"""
def list(self, request, *args, **kwargs):
#获取queryset对象,filter_queryset是过滤
queryset = self.filter_queryset(self.get_queryset())
#queryset是分页
page = self.paginate_queryset(queryset)
if page is not None:
#分页有结果,进行序列化
serializer = self.get_serializer(page, many=True)
#二次封装返回数据
return self.get_paginated_response(serializer.data)
#进行序列化,将序列化数据返回
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
2.filter_queryset
def filter_queryset(self, queryset):
#filter_backends过滤类们,产生的对象(过滤器)可以调用filter_queryset完成对数据的过滤,
#self.filter_backends点击 filter_backends=api_settings.DEFAULT_FILTER_BACKENDS,可以在视图类中局部配置,也可以在settings文件中全局配置,
for backend in list(self.filter_backends):
#queryset是所有群查的结果,得到的还是queryset, backend()调用类,self是视图类对象,filter_queryset(self.request, queryset, self)把queryset进行遍历再做筛选,再产生一个子的queryset
queryset = backend().filter_queryset(self.request, queryset, self)
return queryset
3.BaseFilterBackend
#谁也不继承
class BaseFilterBackend(object):
"""
A base class from which all filter backend classes should inherit.
"""
def filter_queryset(self, request, queryset, view):
"""
Return a filtered queryset.
"""
#抛异常
raise NotImplementedError(".filter_queryset() must be overridden.")
4.SearchFilter
#SearchFilter继承(BaseFilterBackend)
class SearchFilter(BaseFilterBackend):
def filter_queryset(self, request, queryset, view):
#点击get_search_fields , return getattr(view, 'search_fields', None)从views.py视图中反射'search_fields',所以我们要自己提供
search_fields = self.get_search_fields(view, request)
#点击.get_search_terms
#注释:查询接口带有search=..
"""
Search terms are set by a ?search=... query parameter,
and may be comma and/or whitespace delimited.
"""
search_terms = self.get_search_terms(request)
if not search_fields or not search_terms:
return queryset
orm_lookups = [
self.construct_search(six.text_type(search_field))
for search_field in search_fields
]
base = queryset
conditions = []
for search_term in search_terms:
queries = [
models.Q(**{orm_lookup: search_term})
for orm_lookup in orm_lookups
]
conditions.append(reduce(operator.or_, queries))
queryset = queryset.filter(reduce(operator.and_, conditions))
if self.must_call_distinct(queryset, search_fields):
# Filtering against a many-to-many field requires us to
# call queryset.distinct() in order to avoid duplicate items
# in the resulting queryset.
# We try to avoid this if possible, for performance reasons.
#去重的操作
queryset = distinct(queryset, base)
#返回queryset
return queryset
class OrderingFilter(BaseFilterBackend):
#点击get_ordering
#注释:接口带有 ?ordering=...
#Ordering is set by a comma delimited ?ordering=... query parameter.
def filter_queryset(self, request, queryset, view):
#这些方法点不了,都是在 OrderingFilter类中自己找
#get_ordering调用了remove_invalid_fields方法-->get_valid_fields-->
#从视图类中反射ordering_field(默认赋值为None)
ordering = self.get_ordering(request, queryset, view)
if ordering:
return queryset.order_by(*ordering)
return queryset
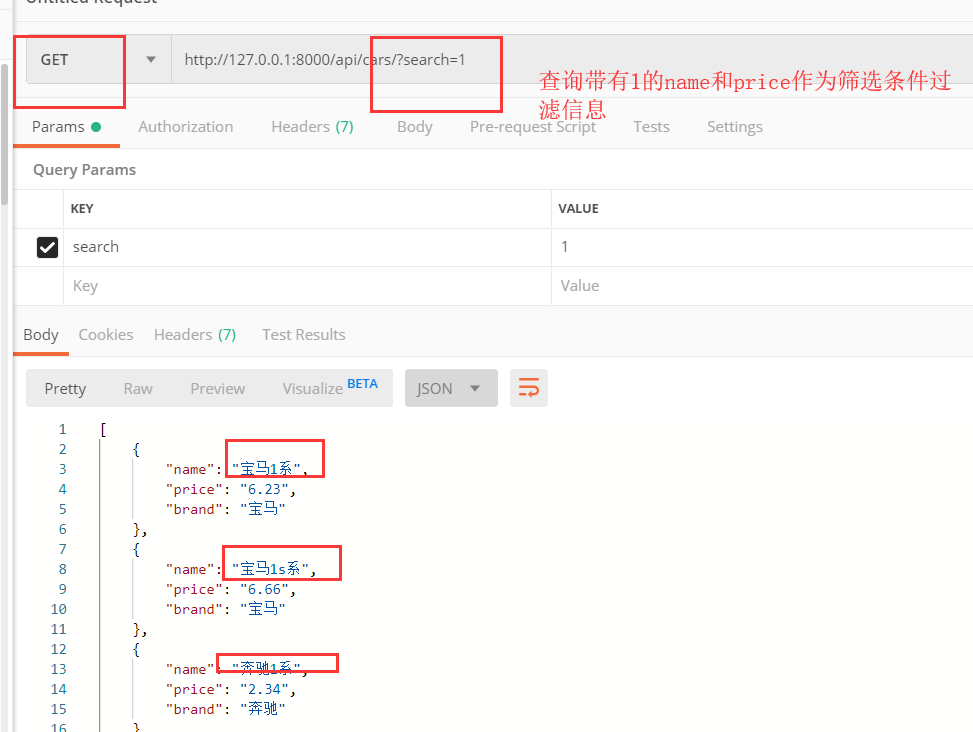
drf搜索过滤组件
views.py
from rest_framework.generics import ListAPIView
# 第一步:drf的SearchFilter - 搜索过滤
from rest_framework.filters import SearchFilter
class CarListAPIView(ListAPIView):
queryset = models.Car.objects.all()
serializer_class = serializers.CarModelSerializer
# 第二步:局部配置 过滤类 们(全局配置用DEFAULT_FILTER_BACKENDS)
#SearchFilter,使用这个类接口访问的时候就是用?search=..
#?search=1,数字;?search=马,中文,?search=1s,字母,筛选的条件啥都行
filter_backends = [SearchFilter]
# 第三步:SearchFilter过滤类依赖的过滤条件 => 接口:/cars/?search=...
search_fields = ['name', 'price'] #根据字段做筛选条件可以是一个,也可以是多个
# eg:/cars/?search=1,name和price中包含1的数据都会被查询出

drf排序过滤组件
views.py
from rest_framework.generics import ListAPIView
# 第一步:drf的OrderingFilter - 排序过滤
from rest_framework.filters import OrderingFilter
class CarListAPIView(ListAPIView):
queryset = models.Car.objects.all()
serializer_class = serializers.CarModelSerializer
# 第二步:局部配置 过滤类 们(全局配置用DEFAULT_FILTER_BACKENDS)
filter_backends = [OrderingFilter]
# 第三步:OrderingFilter过滤类依赖的过滤条件 => 接口:/cars/?ordering=...
ordering_fields = ['pk', 'price']
# eg:/cars/?ordering=-price,pk,先按price降序,如果出现price相同,再按pk升序
drf基础分页组件
pahenations.py
from rest_framework.pagination import PageNumberPagination
# 3) drf的分页类 - 自定义
from . import pagenations
class MyPageNumberPagination(PageNumberPagination):
# ?page=页码
page_query_param = 'page'
# ?page=页面 下默认一页显示的条数
page_size = 3
# ?page=页面&page_size=条数 用户自定义一页显示的条数
page_size_query_param = 'page_size'
# 用户自定义一页显示的条数最大限制:数值超过5也只显示5条
max_page_size = 5
views.py
from rest_framework.generics import ListAPIView
class CarListAPIView(ListAPIView):
# 如果queryset没有过滤条件,就必须 .all(),不然分页会出问题
#点击ListAPIView-->走父类 GenericAPIView-->get_querset方法:判断是否是queryset,如果不是就返回queryset,如果是queryset对象就点all()
#models.Car.objects 打印出来是Manager
#models.Car.objects.filter(pk_gt=1) 打印出来是queryset
#models.Car.objects.all() 打印出来也是queryset
#from django.db.models.manager import Manager
#点击Manager
#class Manager(BaseManager.from_queryset(QuerySet)):
#pass
#继承了BaseManager.from_queryset(QuerySet)返回的类就是Queryset
#models.Car.object还是属于Manager,只是跟queryset有密切关系
#所以它不满足queryset的判断,并且无法遍历所获取的数据
queryset = models.Car.objects.all()
serializer_class = serializers.CarModelSerializer
# 分页组件 - 给视图类配置分页类即可 - 分页类需要自定义,继承drf提供的分页类即可
pagination_class = pagenations.MyPageNumberPagination
分页器源码分析
rest_framwoek_jwt文件夹-->pagination.py
1.BasePagination(object)
2.CursorPagination(BasePagination) 游标,加密分页
3.LimitOffsetPagination(BasePagination) 偏移分页
4. PageNumberPagination(BasePagination) 基础分页
1.父类 ListModelMixins中的list方法
class ListModelMixin(object):
"""
List a queryset.
"""
def list(self, request, *args, **kwargs):
#获取queryset对象,filter_queryset是过滤
queryset = self.filter_queryset(self.get_queryset())
#queryset是分页, paginate_queryset在GenericAPIView中找到-->self.paginator-->self.pagination_class--> pagination_class = api_settings.DEFAULT_PAGINATION_CLASS
page = self.paginate_queryset(queryset)
if page is not None:
#分页有结果,进行序列化
serializer = self.get_serializer(page, many=True)
#二次封装返回数据
return self.get_paginated_response(serializer.data)
#进行序列化,将序列化数据返回
serializer = self.get_serializer(queryset, many=True)
return Response(serializer.data)
代码详见:
E:\ten_django\page
drf-jwt的过滤,筛选,排序,分页组件的更多相关文章
- drf_jwt手动签发与校验-drf小组件:过滤-筛选-排序-分页
签发token 源码的入口:完成token签发的view类里面封装的方法. 源码中在请求token的时候只有post请求方法,主要分析一下源码中的post方法的实现. settings源码: 总结: ...
- DRF框架(八)——drf-jwt手动签发与校验、搜索过滤组件、排序过滤组件、基础分页组件
自定义drf-jwt手动签发和校验 签发token源码入口 前提:给一个局部禁用了所有 认证与权限 的视图类发送用户信息得到token,其实就是登录接口,不然进不了登录页面 获取提交的username ...
- drf框架 - 过滤组件 | 分页组件 | 过滤器插件
drf框架 接口过滤条件 群查接口各种筛选组件数据准备 models.py class Car(models.Model): name = models.CharField(max_length=16 ...
- asp.net core 排序过滤分页组件:sieve(1)
使用asp.net core开发时避免不了要用一个合适的分页组件来让前端获取分页数据.github上面有一个开源的分页组件在这方面很适合我的使用,于是我把他的文档翻译一下,随后会分析它里面的源码.这是 ...
- DRF内置过滤组件与排序组件结合使用
DRF内置过滤组件Filtering DRF提供了内置过滤组件Filtering,可以结合url路径的改变获取想要的数据,当然用户不可能在url访问路径中自己设置过滤条件,肯定是后端开发人员将前端页面 ...
- DRF 过滤排序分页异常处理
DRF 中如何使用过滤,排序,分页,以及报错了如何处理?10分钟get了~
- drf偏移分页组件-游标分页-自定义过滤器-过滤器插件django-filter
drf偏移分页组件 LimitOffsetPagination 源码分析:获取参数 pahenations.py from rest_framework.pagination import Limit ...
- drf--搜索、过滤、排序组件
目录 drf--搜索.过滤.排序组件 过滤 DjangoFilterBackend 自定义过滤器django-filter模块 自定义过滤类 搜索SearchFilter 排序OrderingFilt ...
- DRF框架(九)——drf偏移分页组件、drf游标分页组件(了解)、自定义过滤器、过滤器插件django-filter
drf偏移分页组件 paginations.py from rest_framework.pagination import LimitOffsetPagination class MyLimitOf ...
随机推荐
- Android studio常用快捷键与设置
1.格式化代码: 命令 快捷键 将代码合并成一行 Ctrl + Shift + J 格式化 Ctrl+Alt+L 2.API函数参数提示:双击选中所要提示的函数,再按F2即可显示函数的使用方法. 3. ...
- nginx增加访问验证
使用OpenSSL实用程序创建密码文件 如果您的服务器上安装了OpenSSL,则可以创建没有附加软件包的密码文件.我们将在/ etc / nginx配置目录中创建一个名为.htpasswd的隐藏文件来 ...
- 修改 Cucumber HTML 报告
后台服务是 JSON-RPC 风格的,所以 Scenario 都是这样的 Scenario: login successful When I set request body from "f ...
- 黑客必学之“网页木马webshell”
摘要: 这节课,我们来了解一下网页的木马,首先我们了解网页木马之前,先来了解一下什么是一句话木马.小马和大马.什么是webshell首先简单说一下webshell,webshell简单来说就是黑客植入 ...
- 一文看懂js中元素的客户区大小(clientWidth,clientHeight)
元素的客户区 元素的客户区大小,指的是元素内容及其内边距所占据的空间大小. 相关属性如下: 1. clientWidth:元素内容区宽度+元素左右内边距 2. clientHeight:元素内容区高度 ...
- CSS-水平居中、垂直居中、水平垂直居中
1.水平居中 水平居中可分为行内元素水平居中和块级元素水平居中 1.1 行内元素水平居中 这里行内元素是指文本text.图像img.按钮超链接等,只需给父元素设置text-align:center即可 ...
- 初窥Mybatis初始化
引言 这篇文章呢,主要是讲Mybtais的两种方式的源码剖析:传统方式以及Mapper代理方式,初次探索Mybatis源码,希望大佬勿喷并且指正错误,谢谢! 个人博客:www.fqcoder.cn 一 ...
- python装饰器之函数作用域
1.函数作用域LEGB L:local函数内部作用域 E:enclosing函数内部与内嵌函数之间 G:global全局作用域 B:build-in内置作用域 passline = 60 def fu ...
- 【已解决】HDFS节点已经启动,但不能访问50070 ?
问题描述 通过start-dfs.sh启动了三个节点 但无法通过IP访问50070端口 问题分析 1.可能是防火墙没关,被拦截了 果然,防火墙没关 再将防火墙设为开机不启动 systemctl dis ...
- 单片机基础——使用GPIO输出点亮一个LED灯
1. 准备工作 硬件准备 开发板首先需要准备一个小熊派IoT开发板,并通过USB线与电脑连接. 软件准备 需要安装好Keil - MDK及芯片对应的包,以便编译和下载生成的代码,可参考MDK安装教程 ...