15,scrapy中selenium的应用
引入
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器进行url请求发送则会加载出对应的动态加载的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
1,案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链接进入对应页面时,会发现当前页面展示的新闻数据是被动态加载出来的。需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的数据。
2,selenium在scrapy中使用的原理分析:
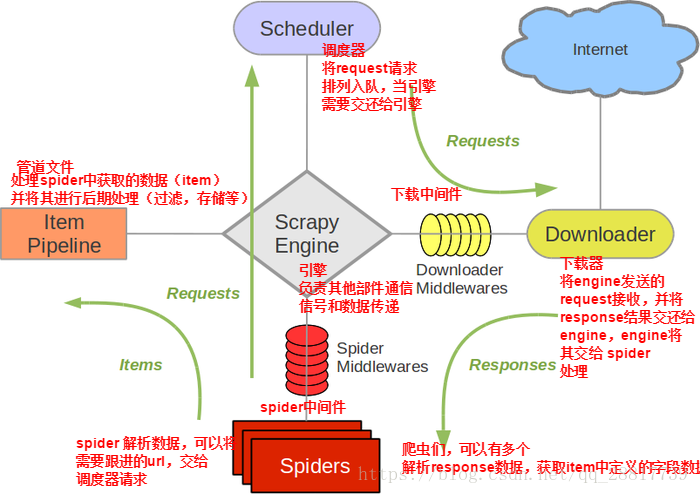
当引擎将国内板块url对应的请求提交给下载器后,下载进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接收到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获得动态数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,且对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3,selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件中的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启中间件
4,代码展示:
创建项目:
scrapy startproject wangyi
cd wangyi
scrapy genspider wangyinews http://war.163.com scrapy crawl wangyinews 完成代码编写后运行项目
- 爬虫文件:
# -*- coding: utf-8 -*-
import scrapy
from selenium import webdriver class WangyinewsSpider(scrapy.Spider):
name = 'wangyinews'
# allowed_domains = ['http://war.163.com/']
start_urls = ['http://war.163.com/'] def __init__(self):
self.bro = webdriver.Chrome(executable_path=r'E:\Google\Google\Chrome\Application\chromedriver.exe') def parse(self, response):
div_list = response.xpath('//div[@class="data_row news_article clearfix "]')
for div in div_list:
title = div.xpath('.//div[@class="news_title"]/h3/a/text()').extract_first()
print(title) def closed(self, spider):
print('关闭浏览器对象!')
self.bro.quit()
- 中间件文件(只需要修改下载中间件的process_response函数)
from time import sleep
from scrapy import signals
from scrapy.http import HtmlResponse def process_response(self, request, response, spider):
print('即将返回一个新的响应对象!!!')
bro = spider.bro
bro.get(url=request.url)
sleep(3)
page_text = bro.page_source
sleep(3)
return HtmlResponse(url=spider.bro.current_url,body=page_text, encoding='utf-8', request=request)
- setting文件
DOWNLOADER_MIDDLEWARES = {
'wangyi.middlewares.WangyiDownloaderMiddleware': 543,
}
15,scrapy中selenium的应用的更多相关文章
- 15.scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中 selenium(中间件) + 语言处理 +mysql
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- 14 Scrapy中selenium的应用
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好 那么如何集成selenium到scrapy中呢? 因为每一次request的请求都要经过中间件,所以写在中间件中最为合适 from se ...
- 在Scrapy中使用selenium
在scrapy中使用selenium 在scrapy中需要获取动态加载的数据的时候,可以在下载中间件中使用selenium 编码步骤: 在爬虫文件中导入webdrvier类 在爬虫文件的爬虫类的构造方 ...
- selenium在scrapy中的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
随机推荐
- 【转】Linq 语法
Join操作符 适用场景:在我们表关系中有一对一关系,一对多关系,多对多关系等.对各个表之间的关系,就用这些实现对多个表的操作. 说明:在Join操作中,分别为Join(Join查询), Select ...
- 【迷你微信】基于MINA、Hibernate、Spring、Protobuf的即时聊天系统:5.技术简介之Hibernate
目录 序言 配置 hibernate.cfg.xml配置文件 加载hibernate.cfg.html配置文件并获取Session 对象的注解配置 增删改查 具体的增删改查代码 数据库操作的封装 连接 ...
- springMvc-视图模型封装及注解参数
1.视图模型封装,ModelAndView可以向页面返回视图的同时吧模型也传入页面 2.注解参数,springMvc很好的地方在于简单,高效,@RequestParam注解能非常好的取得页面参数 代码 ...
- UOJ#130 【NOI2015】荷马史诗 K叉哈夫曼树
[NOI2015]荷马史诗 链接:http://uoj.ac/problem/130 因为不能有前缀关系,所以单词均为叶子节点,就是K叉哈夫曼树.第一问直接求解,第二问即第二关键字为树的高度. #in ...
- SwiftHN阅读器应用IOS源码
SwiftHN是用Swift语言编写的Hacker News阅读器,同时采用了iOS 8最新的API. <ignore_js_op> <ignore_js_op> 详细说明:h ...
- constraint的一些用法总结
主要就是增加约束的 以下几种约束 .并 一一列举: 1.主键约束: 要对一个列加主键约束的话,这列就必须要满足的条件就是分空 因为主键约束:就是对一个列进行了约束,约束为(非空.不重复) 以下是代码 ...
- Linux运维必会的实战编程笔试题(19题)
以下Linux运维笔试面试编程题,汇总整理自老男孩.马哥等培训机构,由运维派根据实战需求,略有调整: 企业面试题1:(生产实战案例):监控MySQL主从同步是否异常,如果异常,则发送短信或者邮件给管理 ...
- Mybatis-动态 SQL语句
if标签 判断语句,用户单条件分支判断 where标签 为了简化上面where 1=1的条件拼装,我们可以采用标签来简化开发 同 foreach标签 场景:传入多个 id 查询用户信息 标签用于遍历集 ...
- 第九章 利用DOM脚本检索,替换,设置,追加样式信息
我们浏览器里看到的网页是由以下三层信息构成的一个共同体: -结构层,由HTML或XHTML之类的标记语言负责去搭建文档的结构. -表示层,由CSS负责设置文档的呈现效果. -行为层,由JavaScri ...
- Activiti学习记录(三)
1.流程变量 1.1 流程图 流程变量在整个工作流中扮演很重要的作用.例如:请假流程中有请假天数.请假原因等一些参数都为流程变量的范围.流程变量的作用域范围是只对应一个流程实例.也就是说各个流程实例的 ...