使用Redis作为高速缓存
Redis适合哪些业务场景
常规业务系统的数据库访问中,读写操作的比例一般在7/3到9/1,也就是说读操作远多于写操作,因此高并发系统设计里,通过NoSQL技术将热点数据(短期内变动概率小的数据)放入内存以达到减轻DB压力,提升数据访问速度的目的,Redis和MongoDB是当下应用最广泛的NoSQL产品,当然如果系统里的写操作居多,也没有必要使用缓存,因此Redis主要用于解决访问性能和并发能力的问题。除了纯数据缓存的作用之外,得益于其超高速的响应能力,Redis也常用于提供分布式锁的解决方案。
哪些设计思路保证了Redis高性能
单个Redis server对请求的处理是基于单线程工作模型的,但由于是纯内存操作,并且单线程的工作模式避免了线程上下文切换带来的额外开销,同时使用NIO多路复用机制(单线程维护多个I/O socket的状态,socket event handler统一进行event分发,并通知到各个event listener),所以即使是单台Redis server的性能也是非常的快,可支持11万次/秒的SET操作,8.1万次/秒的GET操作。
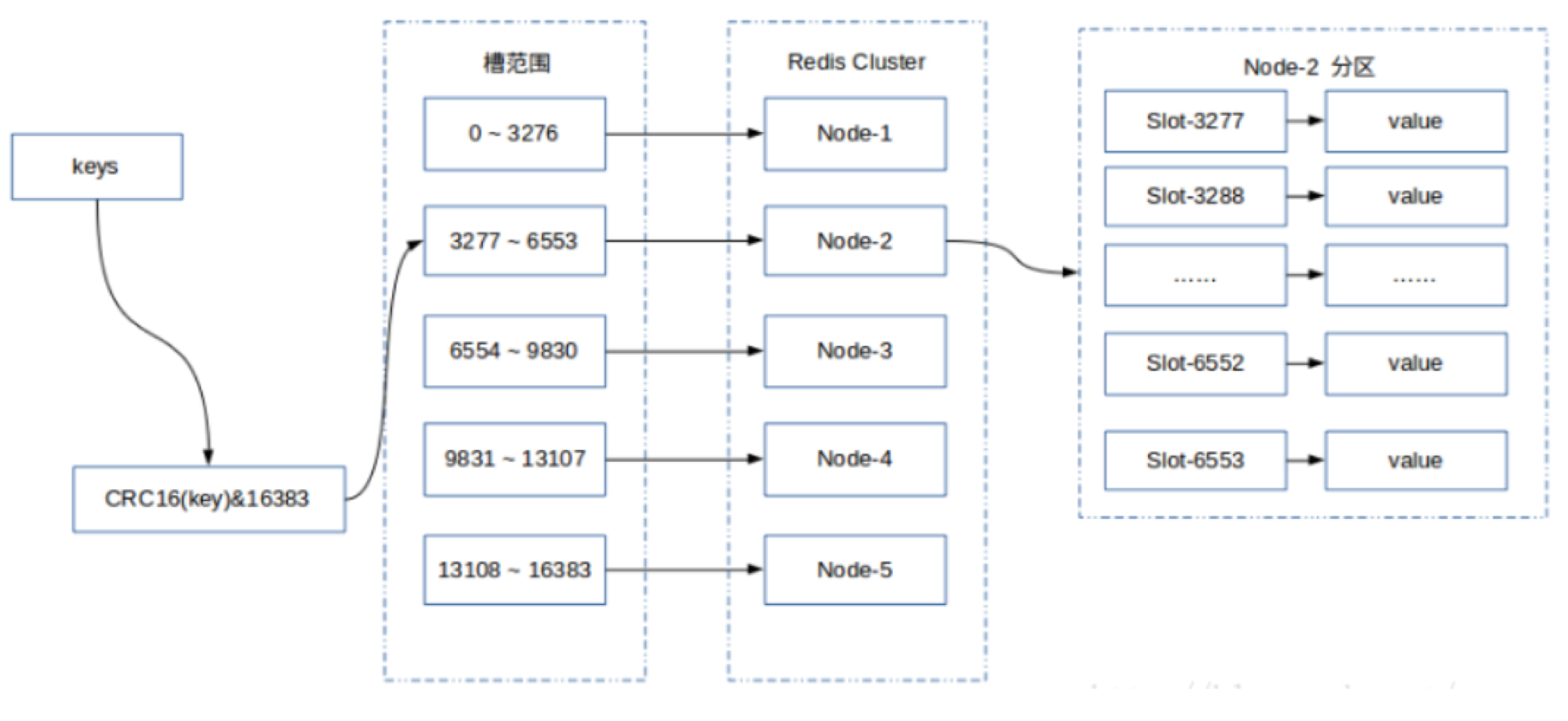
高并发系统里有时候单台Redis server不能满足性能需求,Redis 3.0之前的办法是Redis Sentinel,多个节点同时提供服务,并且每个节点都保存全量数据,Redis 3.0之后引入了Redis Cluster,通过数据分片(Data Sharding)在每个节点上只保留部分数据(总共有16384个slot)来实现高可用。
Redis Cluster采用无中心节点方式实现,客户端直接与redis集群的每个节点连接,客户请求到达节点之后,使用统一的哈希算法,CRC16(key)%16384,计算出key对应的slot,然后从Redis Cluster定位出具体的server,具体的data sharding,最终将数据返回给用户 。但由于Redis的事务仅能解决单台server上的ACID问题,对于多台server常见的问题是多个请求针对同一个key的操作一致性问题,需要结合Zookeeper使用分布式锁的机制解决一致性问题和顺序操作问题。
Redis支持动态添加和删除节点,动态迁移和再平衡slot,动态重新选举Leader并进行fail-over;每一个节点虽然只保存一部分的slot,但会保存一份相同的data sharding mapping table,这张表记录所有16384个slot的host分布位置,并且节点之间会定期同步更新这张表的信息,这样的设计可以保证Redis cluster内部节点之间只需要很少的信息就可以相互同步信息。客户端访问Redis Cluster的时候会指定集群内的一台host:port,如果操作的key不在当前的host上,则host会根据data sharding mapping table告诉客户端正确的host:port;如果访问的host:port下线了,则客户端的链接自动转移到对应的master或者slave节点。
Redis中各种数据类型的使用场景
Redis的数据存储主要通过key/value实现,key都是string类型,value则分不同的应用场景有五种类型定义:
#1 string类型:可以包含任何数据(jps图片或者经过序列化的对象,单个key最大可以存储512M的数据),具有全局统计功能的数据,如全局ID生成器、集群配置信息等;
#2 hash类型:用于存储对象结构的数据,多个field绑定到一个key上(对比使用string类型存储对象的优势在于hash类型可以直接update具体field的值而不影响其他field),如实现SSO,cookie为key,用户信息为value,并有指定过期时间;
#3 list类型:用于存储需要基于队列或者栈操作的系列数据,如消息队列;
#4 set类型:用于存储需要维护一个全局不重复的集合,如服务注册发现,可以实现全局去重的功能,如访问网页的独立IP,共同好友等;
#5 zset类型:用于存储需要维护一个全局不重复但有权重排序的列表可以使用SORTED SET,如积分排行榜、带权重的消息队列。
对上述的字段类型都可以进行的类似的操作,
设置一个值:[set|hmset|lpush|sadd] key value
获取一个值:[get|hget] key
删除一个值:[del|hdel] key
设置一个具有过期时间的值:[setex] key time value
如果值不存在就设置这个值:[setnx] key value
查找redis中的keys或者pattern:[keys/scan] key
判断一个值是否存在:[exists|hexists] key
给指定值设置过期时间:[expire] key seconds
将指定key的value加1|减1:[incr|decr] key
将一个key\value迁移到指定server:[migrate] host port key dest-db timeout [copy] [replace]
HyperLogLog用于做基数统计(基于set类型的封装,仅根据输入的独立元素个数进行统计,而不存储元素本身),可以保证在输入元素数量或者体积非常大的时候可以保证统计所需的空间固定为12kb(最大2^64个元素) 。
在指定的key中添加基数:[pfadd] key value
统计指定key中不同基数的个数:[pfcount] key
将sourceKey的技术合并到destKey的基数统计中:[pfmerge] destKey sourceKey
Pub/Sub用于做消息的发布订阅(基于list类型的封装,将消息封装成list的节点)。
创建一个信息接收channel:[subscribe] channel
向指定的channel发送一个信息:[publish] channel message
单个redis命令的执行具有原子性,对于多个命令而言redis提供基础事务机制,但是不保证多个命令执行的原子性,一个典型的redis事务如下:
开启一个事务:[multi]
之后可以计划多条redis命令,但并不会执行
提交并执行之前的所有命令:[exec]
开始执行之前计划的redis命令,如果其中某条命令执行失败并不会影响其他命令的执行
取消执行事务块内所有计划的redis命令:[discard]
监视一个或者多个key:[watch] key
表示在执行exec之前如果key被事务之前的命令修改,则当前事务被discard。
Redis数据过期策略和内存回收策略
针对已经过期的数据Redis采用定期删除和延迟删除结合的策略,但是两者都有缺陷;由于定期检查所有的key是否过期会带来性能问题,因此定期删除策略使用的是随机抽查,另外在操作Key前会判断是否已经过期,如过期则立即删除;这样的策略会导致一些已经过期的key还堆积在内存里,使得redis server内存占用率居高不下,因此需要结合redis.conf中的maxmemory-policy配置使用,也就是当redis server的内存不足以写入新数据时的内存回收策略,
#1 noeviction:表示直接报错;
#2 allkeys-lur:表示在所有keys中根据LRU删除key;
#3 allkeys-random:表示在所有keys中随机删除key;
#4 volatile-lru/volatile-random/volatile-ttl用于当redis server既充当cache又当DB的时候,表示在设置了expire date的keys中进行删除,ttl表示删除拥有更早过期时间的key。
解决Redis缓存穿透和缓存雪崩问题
缓存穿透和雪崩可以看做一个问题,只是严重程度不同;当一个请求到达redis之后发现没有对应的缓存数据,然后向DB发送数据请求,如果能获取到数据那问题就停留在了缓存穿透上,DB获取到的数据会缓存到redis上;如果DB中也没有对应的数据,并且当这样的请求达到一定数量级并且耗用完所有的DB资源,最终导致DB连接异常就出现了缓存雪崩问题。
解决缓存穿透问题的思路有下述几种,不管是否从DB中查找到对应的值(没有值就为null),都在redis中记录一条缓存记录;在Dao层维护一张BitMap,用bit记录对应的key是否有对应值,从而避免冗余的DB操作;后台线程专门用于更新即将过期的Redis数据,从而避免缓存穿透。
解决缓存雪崩问题的思路有下述几种,在DB Connection上添加互斥锁,这样当大量缓存请求失效的时候需要排队去DB请求数据;对设置了相同过期时间的数据设置一个随机值,避免数据集体失效;使用双缓存或者多层缓存策略,需要配合缓存预热。
使用Redis作为高速缓存的更多相关文章
- 在spring boot环境中使用fastjson + redis的高速缓存技术
因为项目需求,需要在spring boot环境中使用redis作数据缓存.之前的解决方案是参考的http://wiselyman.iteye.com/blog/2184884,具体使用的是Jackso ...
- 2016年5月11日摘自知乎的一些Redis大概了解
1. 知乎日报的基础数据和统计信息是用 Redis 存储的,这使得请求的平均响应时间能在 10ms 以下.其他数据仍然需要存放在另外的地方,其实完全用 Redis 也是可行的,主要的考量是内存占用.就 ...
- 【完结】利用 Composer 完善自己的 PHP 框架(三)——Redis 缓存
本教程示例代码见 https://github.com/johnlui/My-First-Framework-based-on-Composer 回顾 上两篇文章中我们完成了 View 视图加载类和 ...
- 摘抄自知乎的redis相关
1.知乎日报的基础数据和统计信息是用 Redis 存储的,这使得请求的平均响应时间能在 10ms 以下.其他数据仍然需要存放在另外的地方,其实完全用 Redis 也是可行的,主要的考量是内存占用.就使 ...
- Redis - NoSQL数据库技术(一)
NoSQL入门概述(一) 作者 : Stanley 罗昊 [转载请注明出处和署名,谢谢!] 什么是NoSQL NoSQL(NoSQL - Not Only SQL),意“不仅仅是SQL”: 泛指非关系 ...
- 分布式之redis核心知识盘点?
考虑到绝大部分写业务的程序员,在实际开发中使用redis的时候,只会setvalue和getvalue两个操作,对redis整体缺乏一个认知.又恰逢博主某个同事下周要去培训redis,所以博主斗胆以r ...
- 构建自己的PHP框架(Redis)
完整项目地址:https://github.com/Evai/Aier Redis 简介 'Redis' 是一个高性能的 'key-value' 数据库,其 'value' 支持 'String'.' ...
- Redis入门(二)-Redis能够做什么
引言 在上篇文章中,我们讲述了Redis的基本知识让读者对Redis有了基本的了解.那么这一节我们就来看一下Redis究竟能做什么. 上一节我们提到了Redis可用作数据库,高速缓存和消息队列代理.这 ...
- springboot(七).springboot整合jedis实现redis缓存
我们在使用springboot搭建微服务的时候,在很多时候还是需要redis的高速缓存来缓存一些数据,存储一些高频率访问的数据,如果直接使用redis的话又比较麻烦,在这里,我们使用jedis来实现r ...
随机推荐
- 黑马MySQL数据库学习day02 表数据CRUD 约束CRUD
/* 基础查询练习: 1.字段列表查询 当查询全部字段时,一种简便方式,使用*代替全部字段(企业中不推荐使用) 2.去除重复行 DISTINCT,注意修饰的是行,也就是整个字段列表,而不是单个字段. ...
- java关于方法参数传递的相关问题讨论
我们知道,java中定义变量的目的有两个: 1.防止被垃圾回收机制回收,毕竟如果没有明确指向真实物理内存的'代号'很大可能会被java垃圾回收机制当作垃圾回收. 2.便于引用,方便处理. packag ...
- flask环境安装
virtualenv venv #创建venv .venv/bin/activate #进入venv venv/bin/pip install flask venv/bin/pip install f ...
- C#静态类、静态构造函数,类与结构体的比较
一.静态类 静态类是不能实例化的,我们直接使用它的属性与方法,静态类最大的特点就是共享. 探究 public static class StaticTestClass{ public stati ...
- python虚拟环境四
python虚拟环境管理器 我们在使用python虚拟环境的时候,最好安装一个虚拟环境管理器,这样我们就能很方便的管理python的 虚拟环境,而python的虚拟环境管理工具包就是virtualen ...
- EM算法(徐亦达)笔记
- tera term 的一个命令解析脚本
;用虚拟串口虚拟2个串口,tera term使用串口2 ;设置串口2 波特率 115200,超时500ms;如果收到串口发来OK则回复SUCCESS;如果收到ERROR则回复faile;若超时则发送t ...
- 安装gnvm (windows下nodejs版本管理工具)
一些写在前面的话,为什么装这个?前两天看avalon视频的时候,里面有介绍去哪儿的前端构建工具fekit.我这人吧,好奇心特别强,就打算安装用用看.在安装时它提示要求node版本0.8.x,所以我选择 ...
- awk一些简单命令
最简单地说, AWK 是一种用于处理文本的编程语言工具.AWK 在很多方面类似于 shell 编程语言,尽管 AWK 具有完全属于其本身的语法. 尽管操作可能会很复杂,但命令的语法始终是: awk ' ...
- 我的NopCommerce之旅(2): 系统环境及技术分析
一.系统环境 IIS7.0 or above ASP.NET 4.5(MVC 5.0) .NET Framework 4.5.1 or above VS 2012 or above 二.架构设计 Pl ...