Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)
https://www.quora.com/Why-do-people-use-gradient-boosted-decision-trees-to-do-feature-transform






Why is linearity/non-linearity important?
Most of our classification models try to find a single line that separates the two sets of point. I say that they find a line (but a line makes sense for 2 dimensional space), but in higher dimensional space, "a line" is referred to as a Hyperplane. But, for the moment, we will work with 2 dimensional spaces since they are easy to visualize and hence we can simply think that the classifiers try to find lines in this 2D space which will separate the set of points. Now, since the above set of points cannot be separated by a single line, which means most of our classifiers will not work on the above dataset.
How to solve?
There are two ways to solve:
- One way is to explicitly use non-linear classifiers. Non linear classifiers are classifiers that do not try to separate the set of points with a single line but uses either a non-linear separator or a set of linear separators (to make a piece-wise non-linear separator).
- Another way is to transform the input space in such a way that the non-linearity is eliminated and we get a linear feature space.
Second Method
Let us try to find a transformation for the given set of points such that the non linearity is removed. If we carefully see the set of points given to us, we would note that the the label is negative exactly when one of the dimension is negative. If both dimensions are positive or negative, the label given is positive. Therefore, let x=(x1,x2)x=(x1,x2) be a 2D point and let ff be a function that transforms this 2D point to another 2D point as follows: f(x)=(x1,x1x2)f(x)=(x1,x1x2). Let us see what happens to the set of points given to us, when we pass it through the above transformation:
【升维 超线性 分割类】
Oh look at that! Now the two sets of points can be separated by a line! This tells us that now, all our linear classification models will work on this transformed space.
Is it easy to find such transformations?
No, while we were lucky to find a transformation for the above case, in general, it is not so easy to find such a transformation. However, in the above case, I mapped the points from 2D to 2D, but one can map these 2D points to some higher dimensional space as well. There is a theorem called Cover's theorem which states that if you map the points to sufficiently large and high dimensional space, then with high probability, the non-linearity would be erased and that the points will be separated by a line in that high dimensional space.
Evaluating boosted decision trees for billions of users
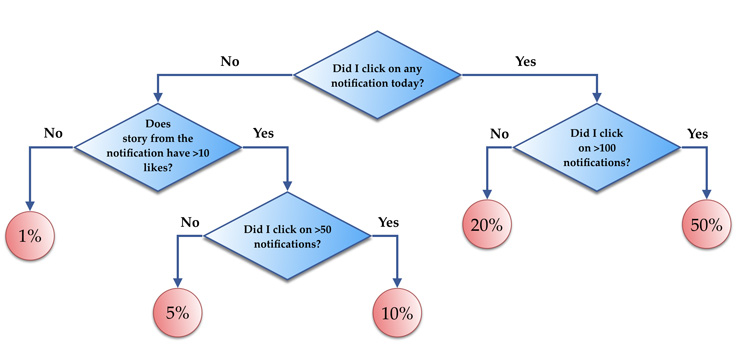
【Facebook点击预测 predicting the probability of clicking a notification】
We trained a boosted decision tree model for predicting the probability of clicking a notification using 256 trees, where each of the trees contains 32 leaves. Next, we compared the CPU usage for feature vector evaluations, where each batch was ranking 1,000 candidates on average. The batch size value N was tuned to be optimal based on the machine L1/L2 cache sizes. We saw the following performance improvements over the flat tree implementation:
- Plain compiled model: 2x improvement.
- Compiled model with annotations: 2.5x improvement.
- Compiled model with annotations, ranges and common/categorical features: 5x improvement.
The performance improvements were similar for different algorithm parameters (128 or 512 trees, 16 or 64 leaves).
Facebook's paper gives empirical results which show that stacking a logistic regression (LR) on top of gradient boosted decision trees (GBDT) beats just directly using the GBDT on their dataset. Let me try to provide some intuition on why that might be happening.
Facebook's paper gives empirical results which show that stacking a logistic regression (LR) on top of gradient boosted decision trees (GBDT) beats just directly using the GBDT on their dataset. Let me try to provide some intuition on why that might be happening.

First, let's assume that GBDT had learnt the weight of the tree TT to be WTWT. Let's also assume that the output of a single tree's leaf ll (say determined by averaging all training observations in that leaf) is PlPl. Also, let's assume l(x)l(x)to be an indicator variable which is 11 iff observation xx falls into region identified by leaf ll. We can then write:
GBDT(x)=GBDT(x)=∑TWT∗(∑l∈TPl∗l(x))∑TWT∗(∑l∈TPl∗l(x))
If we denote by T(l)T(l) the tree to which leaf ll belongs to, we can rewrite it as:
GBDT(x)=∑lWT(l)∗Pl∗l(x)GBDT(x)=∑lWT(l)∗Pl∗l(x)
If we use WlWl to denote WT(l)∗PlWT(l)∗Pl , we can rewrite the previous equation as:
GBDT(x)=∑lWl∗l(x)GBDT(x)=∑lWl∗l(x)
Also, by construction, a LR stacked on GBDT has following hypothesis:
Stacked(x)=∑lCl∗l(x)Stacked(x)=∑lCl∗l(x)
So both of these are doing a linear weighted sum on binary features derived based on inputs belonging to various leaves. So why is LR + GBDT better than just using GBDT alone?
【堆积LR + GBDT性能优于GBDT 】
LR is a convex optimization problem so it can actually choose the weights ClClof each feature optimally. In GBDT on the other hand, weights WlWl aren't guaranteed to be optimal. In fact, since Wl=WT(l)∗PlWl=WT(l)∗Pl and WT(l)WT(l) are chosen greedily (e.g using line search) and PlPl are chosen based only on the local neighborhood, it's quite conceivable that WlWl aren't globally optimal after all. So overall, stacked LR + GBDT will never perform worse than directly using GBDT and can actually outperform it for certain datasets.
But there is another really important advantage of using the stacked model.
Facebook's paper also shows that data freshness is a very important factor for them and that prediction accuracy degrades as the delay between training and test set increases. It's unrealistic/costly to do online training of GBDT whereas online LR is much easier to do. By stacking an online LR over periodically computed batch GBDT, they are able to retain much of the benefits of online training in a pretty cheap way.
Overall, it's a pretty clever idea that works really well in real-world.
Facebook Gradient boosting 梯度提升 separate the positive and negative labeled points using a single line 梯度提升决策树 Gradient Boosted Decision Trees (GBDT)的更多相关文章
- CatBoost使用GPU实现决策树的快速梯度提升CatBoost Enables Fast Gradient Boosting on Decision Trees Using GPUs
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)https://study.163.com/course/introduction.htm?courseId=1005269003&ut ...
- How to Configure the Gradient Boosting Algorithm
How to Configure the Gradient Boosting Algorithm by Jason Brownlee on September 12, 2016 in XGBoost ...
- 梯度提升树 Gradient Boosting Decision Tree
Adaboost + CART 用 CART 决策树来作为 Adaboost 的基础学习器 但是问题在于,需要把决策树改成能接收带权样本输入的版本.(need: weighted DTree(D, u ...
- Ensemble Learning 之 Gradient Boosting 与 GBDT
之前一篇写了关于基于权重的 Boosting 方法 Adaboost,本文主要讲述 Boosting 的另一种形式 Gradient Boosting ,在 Adaboost 中样本权重随着分类正确与 ...
- Gradient Boosting Decision Tree学习
Gradient Boosting Decision Tree,即梯度提升树,简称GBDT,也叫GBRT(Gradient Boosting Regression Tree),也称为Multiple ...
- GBDT(Gradient Boosting Decision Tree) 没有实现仅仅有原理
阿弥陀佛.好久没写文章,实在是受不了了.特来填坑,近期实习了(ting)解(shuo)到(le)非常多工业界经常使用的算法.诸如GBDT,CRF,topic model的一些算 ...
- 集成学习之Boosting —— Gradient Boosting原理
集成学习之Boosting -- AdaBoost原理 集成学习之Boosting -- AdaBoost实现 集成学习之Boosting -- Gradient Boosting原理 集成学习之Bo ...
- Gradient Boosting算法简介
最近项目中涉及基于Gradient Boosting Regression 算法拟合时间序列曲线的内容,利用python机器学习包 scikit-learn 中的GradientBoostingReg ...
- 论文笔记:LightGBM: A Highly Efficient Gradient Boosting Decision Tree
引言 GBDT已经有了比较成熟的应用,例如XGBoost和pGBRT,但是在特征维度很高数据量很大的时候依然不够快.一个主要的原因是,对于每个特征,他们都需要遍历每一条数据,对每一个可能的分割点去计算 ...
随机推荐
- JavaScript的Object
题目 var foo = new Object(); var bar = new Object(); var map = new Object(); map[foo] = "foo" ...
- POJ 1703 Find them, Catch them 并查集的应用
题意:城市中有两个帮派,输入中有情报和询问.情报会告知哪两个人是对立帮派中的人.询问会问具体某两个人的关系. 思路:并查集的应用.首先,将每一个情报中的两人加入并查集,在询问时先判断一下两人是否在一个 ...
- 2016集训测试赛(十九)Problem A: 24点大师
Solution 这到题目有意思. 首先题目描述给我们提供了一种非常管用的模型. 按照题目的方法, 我们可以轻松用暴力解决20+的问题; 关键在于如何构造更大的情况: 我们发现 \[ [(n + n) ...
- mysql事物中行锁与表锁
事物与锁 什么叫不支持事物: 首先要了解数据库里的事务是什么意思.事务在计算机数据库里 :在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit).在关系数据库中,一个事务可以 ...
- static再次深入理解
在java中,栈中存放的是用来保存方法运行时状态的栈帧,存储了局部变量表,操作数栈等,而方法区存放的是已加载的类的基本信息.常量.静态变量等.
- 【spring boot logback】日志logback 生成日志文件在本项目下,而不在指定的日志文件目录下/指定日志文件到达最大值后不按照配置进行切割
原本的日志文件配置如下: <?xml version="1.0" encoding="UTF-8"?> <configuration scan ...
- 人生中的那口井 z
有两个和尚住在隔壁,每天都会在同一时间下山去溪边挑水,不知不觉己经过了五年. 突然有一天,左边这座山的和尚没有下山挑水,过了一个星期,还是没有下山挑水. 直到过了一个月,右边那座山的和尚很担心就去探望 ...
- c# winform 最小化到托盘
STEP1.添加托盘图标控件NotifyIcon(直接从工具箱中拖动添加即可) STEP2.添加(重写)窗口尺寸变动函数Form1_Resize private void Main_SizeChang ...
- java.sql.Timestamp类型
如果想向数据库中插入日期时间的话,可以用java.sql.Timestamp类 一个与 java.util.Date类有关的瘦包装器 (thin wrapper),它允许 JDBC API 将该类标识 ...
- MATLAB基础操作符与数据格式显示
1.冒号":" 基本使用如下: X=1:10:表示生成向量[1,2,3,4,5,6,7,8,9,10] X=J:i:k ;表示向量[j,j+i,j+2i,...,k]; A(:,j ...