Windows下安装CUDA8.0
在Win10下安装CUDA8.0,并使用VS2013测试;
机器配置:
Windows 10
VS 2013
CUDA8.0
CUDA 8.0:下载地址
CUDA其他版本:下载地址
1. 安装CUDA 8.0
双击安装下载的.exe文件,然后选择解压路径,如下图,解压到哪里无所谓,安装成功会自动删除;
解压完成后,得到如下图:
- 精简:安装所有CUDA模块,并覆盖掉当前的NVIDIA驱动程序;(说实话,容易出问题)
- 自定义:选择自己想要安装的模块,此处选择这里;
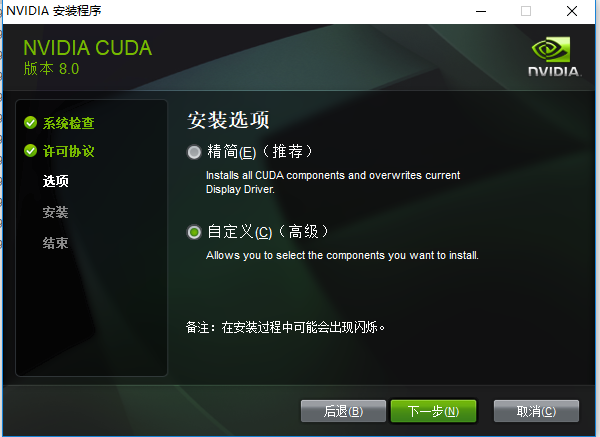
选择自定义后,出现下图所示:
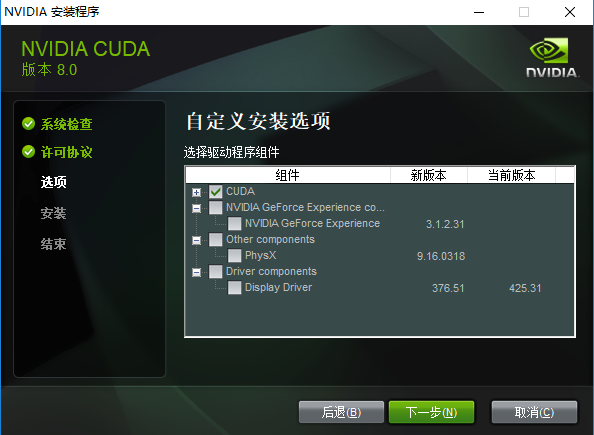
下面几个模块准确具体有什么用,不能100%确定,但能大概才出来:
- CUDA:这个是必须的,下面有CUDA Runntime、Samples一些东西;
- NVIDIA GeForce Experience:这个好像是为了更好的游戏体验,之前安装显卡驱动程序时也提示是否安装,果断拒绝了;
- Other components:这里的PhysX好像也是为了游戏体验来的;
- Driver components:这个就要慎重了,意思就是重新安装显卡驱动程序;如果之前已经成功安装驱动程序,这里就不用选了;如果之前没安装驱动程序,建议还是去官网上单独下载驱动程序进行安装吧;
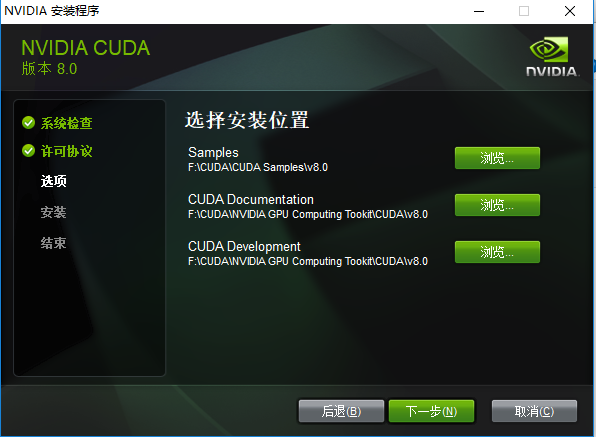
选择好需要安装的模块,就要选择安装路径了,我的选择如下图:
- 在如图所示位置建立相应文件夹,然后再指定安装路径;
安装成功后;Ctrl+R,打开cmd:
nvcc -V
输出版本信息,则表明安装成功;
配置环境变量
将F:\CUDA\NVIDIA GPU Computing Tookit\CUDA\v8.0\lib\x64添加的系统变量的path中;
2. 安装CuDNN
下载对应CUDA 8.0版本的CuDNN:下载链接
(如果安装的是其他版本的CUDA,注意CuDNN的版本)
下载完成后,解压得到一个名为cuda的文件夹;将该文件夹下的文件复制到上一步安装的CUDA中;注意对应的文件夹;
./cuda/bin/**.dll 复制到 ./NVIDIA GPU Computing Tookit/CUDA/v8.0/bin/
./cuda/include/**.dll 复制到 ./NVIDIA GPU Computing Tookit/CUDA/v8.0/include/
./cuda/lib/x64/**.dll 复制到 ./NVIDIA GPU Computing Tookit/CUDA/v8.0/lib/x64/
安装完成;
3. 测试1
使用VS2013打开./cuda/v8.0/Samples_vs2013.sln;
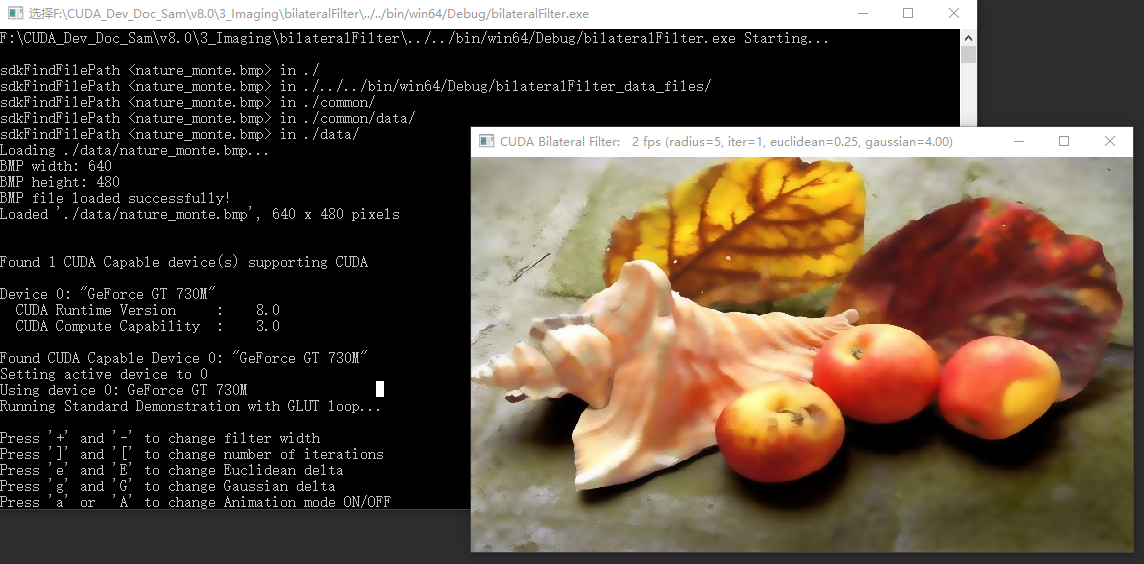
加载完成后,执行本地Windows编译,最后输出成功,见下图;
4. 测试2
在VS2013上配置CUDA;
4.1 新建项目并进行配置
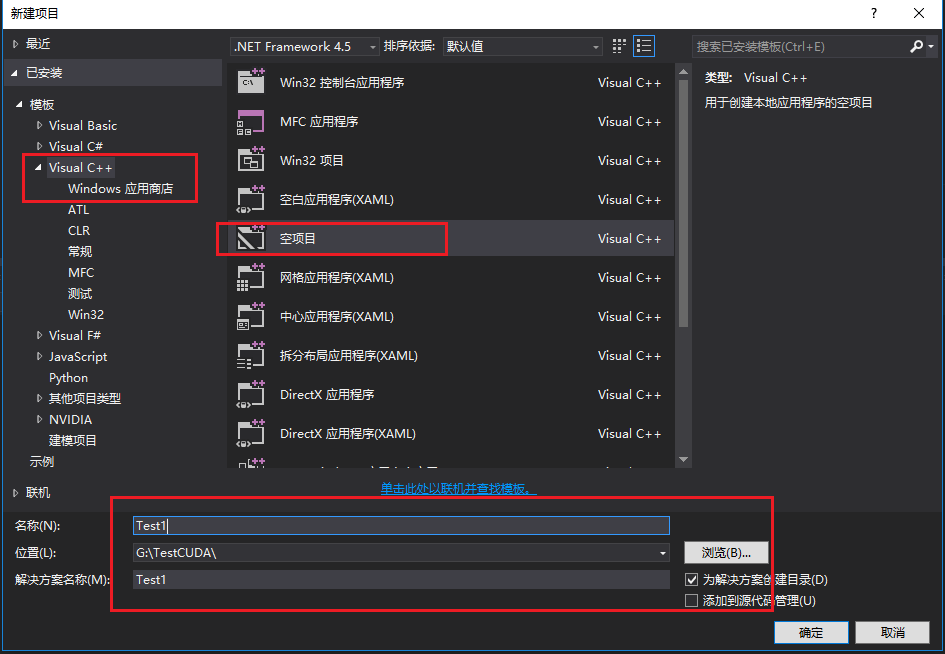
- 打开VS2013,新建空白项目,设置项目名称、位置信息,如下图;
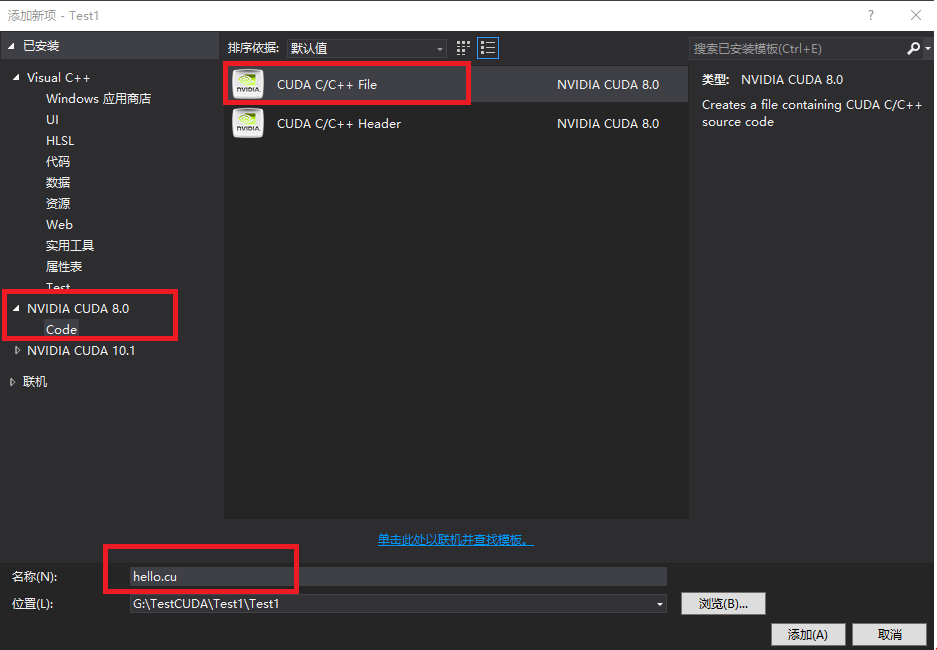
在源文件添加—>新建项—>NVIDIA CUDA 8.0—>CUDA C/C++ File,命名为hello.cu,如下图;
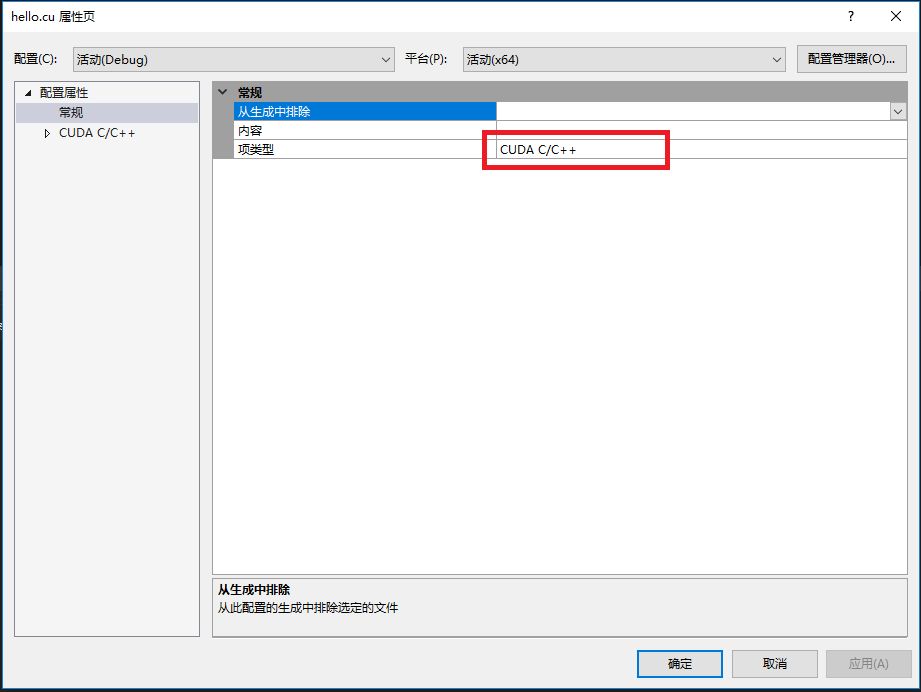
hello.cu右键—>属性—>配置属性—>常规—>项类型,配置如下图;
- 在项目上右键—>生成依赖项—>生成自定义—>选择CUDA 8.0,如下图;
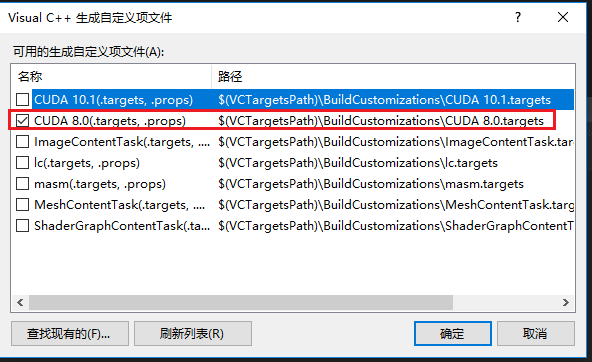
- 在项目上右键—>属性—>常规—>配置管理器—>活动解决方案平台(新建)—>键入或选择新平台(选择x64),如下图;
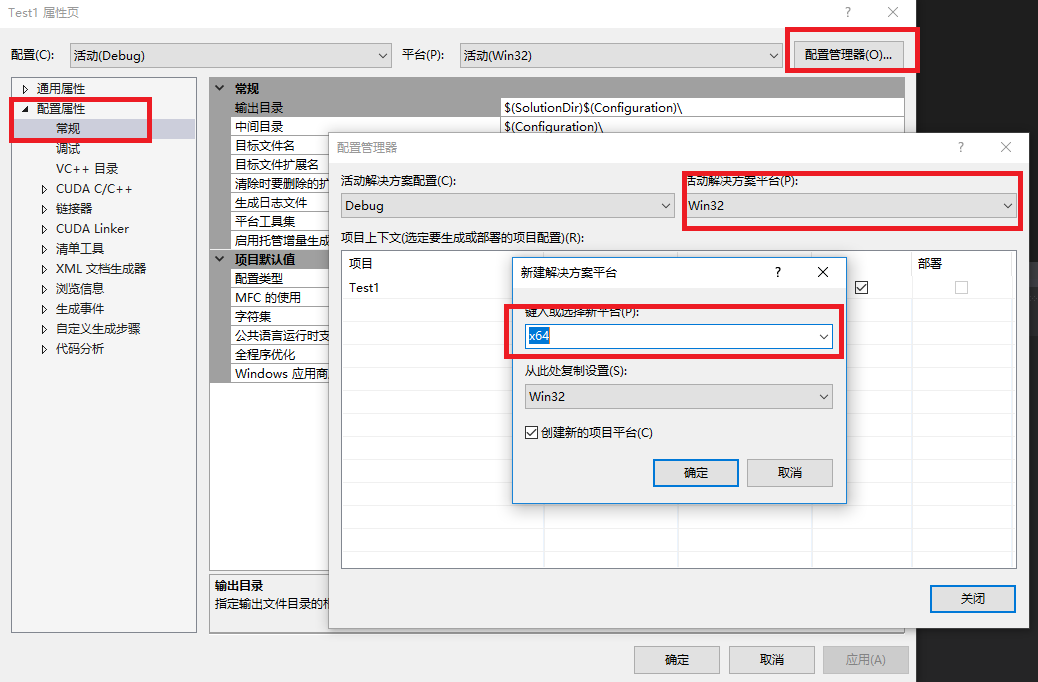
- 项目右键—>属性—>VC++目录—>包含目录,如下图,添加;
F:\CUDA\NVIDIA GPU Computing Tookit\CUDA\v8.0\include
- 项目右键—>属性—>VC++目录—>库目录,如下图,添加;
F:\CUDA\NVIDIA GPU Computing Tookit\CUDA\v8.0\lib\x64
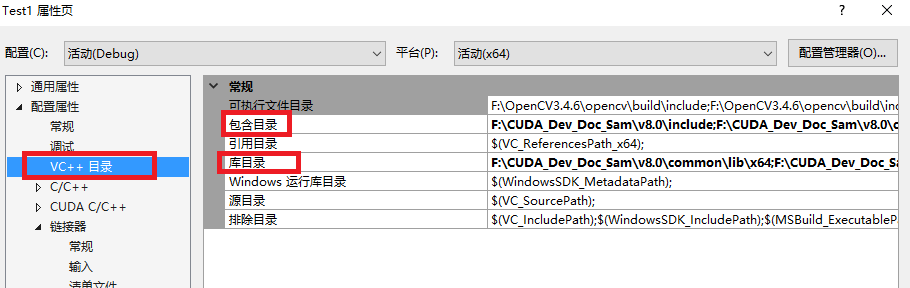
- 项目右键—>属性—>链接器—>常规,如下图,添加;
$(CUDA_PATH_V8_0)\lib\$(Platform)
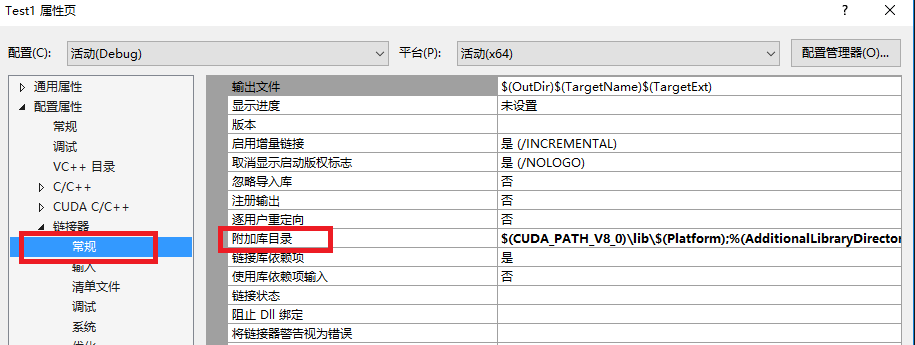
- 项目右键—>属性—>链接器—>输入—>附加依赖项,如下图,添加;
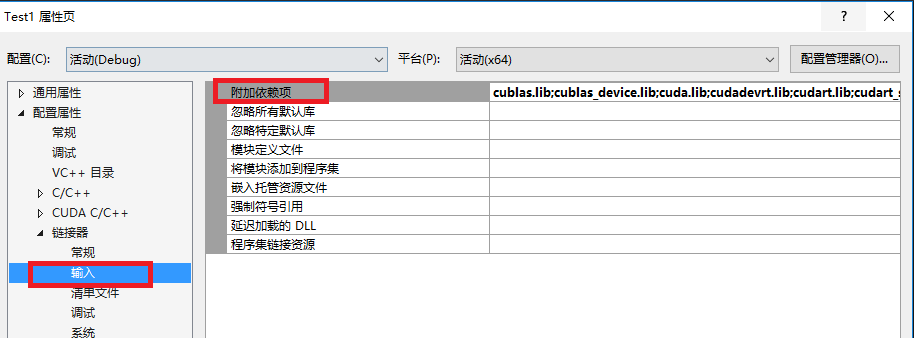
注意:不同版本的CUDA,下面的lib是不同的;当然,一个项目也不一定需要所有的lib;
具体有哪些lib,位于:F:\CUDA_Dev_Doc_Sam\v8.0\lib\x64;
cublas.lib
cublas_device.lib
cuda.lib
cudadevrt.lib
cudart.lib
cudart_static.lib
cudnn.lib
cufft.lib
cufftw.lib
curand.lib
cusolver.lib
cusparse.lib
nppc.lib
nppi.lib
nppial.lib
nppicc.lib
nppicom.lib
nppidei.lib
nppif.lib
nppig.lib
nppim.lib
nppist.lib
nppisu.lib
nppitc.lib
npps.lib
nvblas.lib
nvcuvid.lib
nvgraph.lib
nvml.lib
nvrtc.lib
OpenCL.lib
4.2 编译
在上面建的hello.cu文件中添加下面代码:
// CUDA runtime 库 + CUBLAS 库
#include <cuda_runtime.h>
#include <cublas_v2.h>
#include <device_launch_parameters.h>
#include <time.h>
#include <iostream>
# pragma warning (disable:4819)
using namespace std;
bool initDevice(void)
{
int cnt, i;
cudaGetDeviceCount(&cnt);
if (cnt < 0){
cout << "Can not find CUDA device" << endl;
return false;
}
for (i = 0; i < cnt; i++){
cudaDeviceProp porp;
if (cudaGetDeviceProperties(&porp, i) == cudaSuccess){
if (porp.major >= 1) {
break;
}
}
}
if (i == cnt){
cout << "< 1.0" << endl;
}
return true;
}
__global__ void kernel_compute(float *model, float *input, float *output)
{
int idx_x, idx_y;
idx_y = blockIdx.x;
idx_x = idx_y * blockDim.x + threadIdx.x;
float sum = 0;
for (int i = 0; i < 9; i++){
sum += input[idx_x] * model[i];
}
//printf("%3d %d %2.6f %2.6f\n", idx_x, idx_y, sum, input[idx_x]);
output[idx_x] = sum;
}
/*block ---> row*/
int buildMaps(float *model, float *input, float *output, int height, int width)
{
initDevice();
float *dev_m = NULL, *dev_i = NULL, *dev_o = NULL;
int size = height * width;
cudaMalloc((void **)&dev_m, 9 * sizeof(float));
cudaMalloc((void **)&dev_i, size * sizeof(float));
cudaMalloc((void **)&dev_o, size * sizeof(float));
cudaMemcpy(dev_m, model, 9 * sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_i, input, size * sizeof(float), cudaMemcpyHostToDevice);
dim3 grid(height, 1, 1);
dim3 block(width, 1, 1);
kernel_compute << <grid, block >> > (dev_m, dev_i, dev_o);
cudaMemcpy(output, dev_o, size * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}
新建main.cpp文件;
#include <iostream>
#include <Windows.h>
#include <stdlib.h>
#include <time.h>
using namespace std;
extern int buildMaps(float *model, float *input, float *output, int height, int width);
void show(float *ptr, int height, int width, char *str)
{
cout << str << " : " << endl;
for (int h = 0; h < height; h++){
for (int w = 0; w < width; w++){
int cnt = h * width + w;
printf("%5.5f ", ptr[cnt]);
}
cout << endl;
}
}
#define width 5
#define size (width * width)
int main()
{
float *model = (float *)malloc(9 * sizeof(float));
float *input = (float *)malloc(size * sizeof(float));
float *output = (float *)malloc(size * sizeof(float));
if (!model || !input || !output){
std::cout << "Malloc Error" << endl;
exit(-1);
}
for (int i = 0; i < 9; i++){
model[i] = (float)(i);
}
srand((unsigned)time(0));
for (long long int i = 0; i < size; i++){
input[i] = ((rand() % 100) * 1.f) / (rand() % 100 + 1);
}
buildMaps((float *)model, (float *)input, output, width, width);
show(model, 3, 3, "model");
show(input, width, width, "input");
show(output, width, width, "output");
int a;
cin >> a;
}
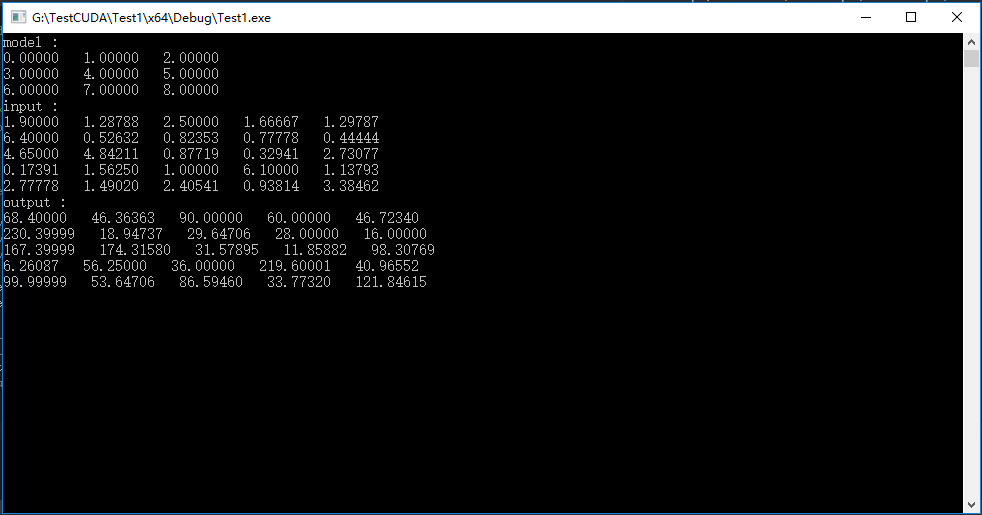
编译,输出结果为:
Windows下安装CUDA8.0的更多相关文章
- Ubuntu下安装CUDA8.0及nvidia驱动
参考:https://blog.csdn.net/qq_35379989/article/details/80147630 cuda的历史版本下载地址:https://developer.nvidia ...
- ubuntu16.04下安装cuda8.0
一.首先安装NVIDIA显卡驱动 通过NVIDIA-Linux-x86_64-367.44.run文件安装. 1. 添加 PPA. sudo add-apt-repository ppa:graphi ...
- Ubuntu16.04下安装CUDA8.0和tensorflow
GPU版的Tensorflow无疑是深度学习的一大神器,当然caffe之类的框架也可以用GPU来加速训练. 注意:以下安装默认为python2.7 1. 安装依赖包 $ sudo apt-get in ...
- Ubuntu14.04下安装Cuda8.0
https://blog.csdn.net/sinat_19628145/article/details/60475696 https://developer.nvidia.com/cuda-down ...
- Ubuntu 14.04下安装CUDA8.0
配置环境如下: 系统:Ubuntu14.04 64bit 显卡:Nvidia K620M 显卡驱动:Nvidia-Linux-x86_64-375.66.run CUDA8.0 + cudnn8.0 ...
- windows下安装mysql8.0压缩版
下面总结下安装过程: 首先解压下载好的压缩版本. 将解压后mysql的bin文件目录配置系统环境path变量中 使用cmd打开命令窗口,输入mysqld --initialize命令初始化 ...
- 在Windows下安装Elasticsearch5.0
1.准备工作 安装和配置Java环境 2.下载 地址:https://www.elastic.co/downloads/elasticsearch 老版本:https://www.elastic.co ...
- windows下安装mysql-8.0.18-winx64
1.下载安装包 安装包现在地址: https://dev.mysql.com/downloads/mysql/ 2.解压缩至安装目录 解压缩下载之后的zip,我这里使用的安装路径为: C:\Progr ...
- windows下安装Mongodb_4.0.6最新版及常用命令
今天下载了最新版Mongodb进行安装,发现相比较于以前,方便了很多,直接下载: 一.下载地址:https://www.mongodb.com/download-center/enterprise 二 ...
随机推荐
- 【题解】 P1092虫食算
[题解]P1092 虫食算 老题了,很经典. 用到了一些搜索套路. 可行性剪枝,劣者靠后,随机化,\(etc......\) 搜索设参也很有技巧,设一个\(adjustment\)参数可以很方便地在两 ...
- cordova 插件创建
peng@PENG-PC /E/_My_File_____/_work/MyCode/myCode/cordova-workspace/plugman-test/ABCD $ npm install ...
- 链表的C++实现
有的时候,处于内存中的数据并非连续的.那么这时候.我们就须要在数据结构中加入一个属性.这个属性会记录以下一个数据的地址.有了这个地址之后.全部的数据就像一条链子一样串起来了,那么这个地址属性就起到 ...
- STL容器元素应满足的条件
要使用C++中的标准模板库中的容器,其元素要满足以下三个条件: 元素必须可以通过copy构造函数进行复制,且二者进行相等测试返回true. 元素必须可以通过赋值操作符完成赋值操作. 元素必须可以通过析 ...
- C# nunit 单元测试
1. 引包 nunit.framework.dll
- <关于J2EE环境的搭建>在Fedora21下的Tomcat,Mysql,jdk以及Intellij的搭建过程
题外话:一开始很不情愿写这种没有技术含量的博文,但是网上对于fedora21下的整个J2EE环境的搭建过程的文章实在是少之又少,那我就破个例吧:-p (一)JDK的下载及环境变量的设置 如果你对JDK ...
- linux应用之jdk环境的安装(centos)
一.yum安装 1.执行:yum search jdk 已加载插件:fastestmirror, securityLoading mirror speeds from cached hostfile ...
- hihocoder1075【开锁魔法】
hihocoder1075[开锁魔法] 题意是给你一个 \(1-n\) 的置换,求选 \(k\) 个可以遍历所有点的概率. 题目可以换个模型:有 \(n\) 个球,有 \(cnt\) 种不同的颜色,求 ...
- Unity-2017.3官方实例教程Space-Shooter(一)
由于初学Unity,写下此文作为笔记,文中难免会有疏漏,不当之处还望指正. Unity-2017.3官方实例教程Space-Shooter(二) 章节列表: 一.从Asset Store中下载资源并导 ...
- BZOJ-3626:LCA(离线+树链剖分)
Description 给出一个n个节点的有根树(编号为0到n-1,根节点为0).一个点的深度定义为这个节点到根的距离+1.设dep[i]表示点i的深度,LCA(i,j)表示i与j的最近公共祖先.有q ...