20.Scrapy日常练手
1.创建爬虫项目:
scrapy startproject tutorial
2.创建 spider
cd tutorial
scrapy genspider quotes quotes.toscrape.com
如下图:
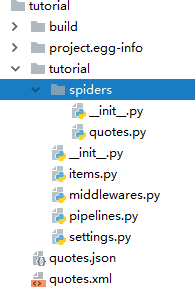
3.
quotes.py
___________________________________________________________________________
# -*- coding: utf-8 -*-
import scrapy
from tutorial.items import TutorialItem
import logging
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/'] def parse(self, response):
quotes=response.css('.quote')
for quote in quotes: item=TutorialItem()
#内容
item['text']=quote.css('.text::text').extract_first() #作者
item['author']=quote.css('.author::text').extract_first() #标签
item['tags']=quote.css('.tags .tag::text').extract_first() yield item #下一页
next=response.css('.pager .next a::attr("href")').extract_first()
url=response.urljoin(next)
yield scrapy.Request(url=url,callback=self.parse)
items.py
________________________________________________________________________
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class TutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() text=scrapy.Field()
author=scrapy.Field()
tags=scrapy.Field()
piplines.py
_________________________________________________________________________
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
from scrapy.exceptions import DropItem import pymysql class TutorialPipeline(object):
# def __init__(self):
# self.limit=50
# def process_item(self, item, spider):
# if item['text']:
# if len(item['text'])>self.limit:
# item['text']=item['text'][0:self.limit].rstrip()+'...'
# return item
# else:
# return DropItem('Missing Text')
def __init__(self):
pass
def open_spider(self, spider):
self.my_conn = pymysql.connect(
host = '192.168.113.129',
port = 3306,
database = 'datas',
user = 'root',
password = '',
charset = 'utf8'
)
self.my_cursor = self.my_conn.cursor() def process_item(self,item, spider): dict(item)
insert_sql = "insert into quotes(author,tags,text) values(%s,%s,%s)"
self.my_cursor.execute(insert_sql,[item['author'],item['tags'],item['text']])
return item
def close_spider(self, spider):
self.my_conn.commit() self.my_cursor.close() self.my_conn.close()
setting.py
___________________________________________________________________________
# Obey robots.txt rules
ROBOTSTXT_OBEY = True ITEM_PIPELINES = {
'tutorial.pipelines.TutorialPipeline': 200,
}
代码配置完: 保存文件格式
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.csv
20.Scrapy日常练手的更多相关文章
- 整理了适合新手的20个Python练手小程序
100个Python练手小程序,学习python的很好的资料,覆盖了python中的每一部分,可以边学习边练习,更容易掌握python. 本文附带基础视频教程:私信回复[基础]就可以获取的 [程序1] ...
- 20个Java练手项目,献给嗜学如狂的人
给大家推荐一条由浅入深的JAVA学习路径,首先完成 Java基础.JDK.JDBC.正则表达式等基础实验,然后进阶到 J2SE 和 SSH 框架学习.最后再通过有趣的练手项目进行巩固. JAVA基础 ...
- 10个Python基础练习项目,你可能不会想到练手教程还这么有趣
美国20世纪最重要的实用主义哲学家约翰·杜威提出一个学习方法,叫做:Learning By Doing,在实践中精进.胡适.陶行知.张伯苓.蒋梦麟等都曾是他的学生,杜威的哲学也影响了蔡元培.晏阳初等人 ...
- Python练手项目:20行爬取全王者全英雄皮肤
引言 王者荣耀大家都玩过吧,没玩过的也应该听说过,作为时下最火的手机MOBA游戏,咳咳,好像跑题了.我们今天的重点是爬取王者荣耀所有英雄的所有皮肤,而且仅仅使用20行Python代码即可完成. ...
- 70个Python练手项目列表(都有完整教程)
前言: 不管学习那门语言都希望能做出实际的东西来,这个实际的东西当然就是项目啦,不用多说大家都知道学编程语言一定要做项目才行. 这里整理了70个Python实战项目列表,都有完整且详细的教程,你可以从 ...
- webpack练手项目之easySlide(三):commonChunks(转)
Hello,大家好. 在之前两篇文章中: webpack练手项目之easySlide(一):初探webpack webpack练手项目之easySlide(二):代码分割 与大家分享了webpack的 ...
- webpack练手项目之easySlide(二):代码分割(转)
在上一篇 webpack练手项目之easySlide(一):初探webpack 中我们一起为大家介绍了webpack的基本用法,使用webpack对前端代码进行模块化打包. 但是乍一看webpack ...
- webpack练手项目之easySlide(一):初探webpack (转)
最近在学习webpack,正好拿了之前做的一个小组件,图片轮播来做了下练手,让我们一起来初步感受下webpack的神奇魅力. webpack是一个前端的打包管理工具,大家可以前往:http:/ ...
- NYOJ 323 Drainage Ditches 网络流 FF 练手
Drainage Ditches 时间限制:1000 ms | 内存限制:65535 KB 难度:4 描述 Every time it rains on Farmer John's fields, ...
随机推荐
- BZOJ5091: [Lydsy1711月赛]摘苹果【期望DP】
Description 小Q的工作是采摘花园里的苹果.在花园中有n棵苹果树以及m条双向道路,苹果树编号依次为1到n,每条道路的两 端连接着两棵不同的苹果树.假设第i棵苹果树连接着d_i条道路.小Q将会 ...
- BZOJ4310: 跳蚤 【后缀数组+二分】
Description 很久很久以前,森林里住着一群跳蚤.一天,跳蚤国王得到了一个神秘的字符串,它想进行研究.首先,他会把串 分成不超过 k 个子串,然后对于每个子串 S,他会从S的所有子串中选择字典 ...
- Codeup1085: 阶乘的和
题目描述 有些数可以表示成若干个不同阶乘的和.例如,9=1!+2!+3!.小明对这些数很感兴趣,所以他给你一个正整数n,想让你告诉他这个数是否可以表示成若干个不同阶乘的和. 输入 输入包含多组测试数据 ...
- Hibernate4获取sessionFactory
/** * Location of hibernate.cfg.xml file. * Location should be on the classpath as Hibernate uses * ...
- mongo dos操作
https://www.cnblogs.com/beileixinqing/p/8241822.html 基础1 https://blog.csdn.net/superjunjin/article/d ...
- 系统有专门画图的api
- java 的关键字 native
native native 关键字说明其修饰的方法是一个原生态方法,方法对应的实现不是在当前文件,而是在用其他语言(如C和C++)实现的文件中.Java语言本身不能对操作系统底层进行访问和操作,但是可 ...
- JavaScriptSerializer类 对象序列化为JSON,JSON反序列化为对象 。
JavaScriptSerializer 类由异步通信层内部使用,用于序列化和反序列化在浏览器和 Web 服务器之间传递的数据.说白了就是能够直接将一个C#对象传送到前台页面成为javascript对 ...
- redux学习与使用
Redux: 主要概念Action,reducer,store,state 原理:dispatch ({ type:action, preload: { val } } ) --->reduce ...
- Android getprop setprop watchprops用法
转载请注明出处:https://www.cnblogs.com/lialong1st/p/10172973.html 在安卓系统中,当你写了一个脚本,已经添加到开机启动 init.rc 中,即使脚本中 ...