Elasticstack 5.1.2 集群日志系统部署及实践
Elasticstack 5.1.2 集群日志系统部署及实践
一、ELK Stack简介
ELK Stack 是Elasticsearch、Logstash、Kibana三个开源软件的组合,在实时数据检索和分析场合,三者通常是配合共用的。
可参考:https://www.elastic.co/products
二、Elasticstack重要组件
Elasticsearch: 准实时索引
Logtash: 收集数据,配置使用 Ruby DSL
Kibana 展示数据,查询聚合,生成报表
Kafka 消息队列,做为日志接入的缓冲区
三、Elasticstack工作流程
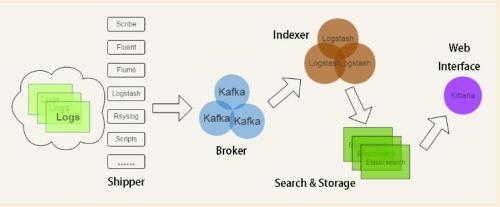
简要说明:
1)日志机器上部署logstash服务,用于监控并收集日志,然后,将收集到的日志发送到broker上。
2)Indexer会将这些日志收集到一起,统一发送到Elasticsearch上进行存储。
3)最后Kibana会将需要的数据进行展示,可以进行自定义搜索
四、环境准备
系统:centos 7.2
JDK: 1.8.0_111
filebeat: 5.1.2
logstash: 5.1.2
elasticsearch: 5.1.2 (注:ELK stack 5.1以上版本JDK必须是1.8以上)
kibana: 5.1.2
X-Pack:5.1
kafka: 2.11-0.10.1.0
测试服务器准备:
主机名称:node01 IP:192.168.2.14 职责:主机节点以及数据节点、kafka/logstash
主机名称:node02 IP: 192.168.2.15 职责:主机节点以及数据节点、kibana
主机名称:node03 IP: 192.168.2.17 职责:主机节点以及数据节点、Elasticstack-head插件
主机名称:test IP: 192.168.2.70 职责:客户端
注:分配内存建议大于2G
测试服务器设置:
配置hosts(/etc/hosts)
192.168.2.14 node01
192.168.2.15 node02
192.168.2.17 node03
关闭防火墙&Sellinux
配置yum源:
#yum -y install epel-release
时间同步:
#rpm -qa |grep chrony
配置时间同步源:# vi /etc/chrony.conf
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server 0.rhel.pool.ntp.org iburst
server 1.rhel.pool.ntp.org iburst
server 10.100.2.5 iburst
重启时间同步服务:# systemctl restart chronyd.service
node01和node02安装配置JDK:
#yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel #安装openjdk
1)标准方式配置环境变量:
vim /etc/profile
将下面的三行粘贴到 /etc/profile中:
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
2)保存关闭后,执行:source /etc/profile #让设置立即生效。
[root@~]# echo $JAVA_HOME
[root@ ~]# echo $CLASSPATH
[root@ ~]# echo $PATH
测试是否安装配置成功
# java -version
openjdk version "1.8.0_121"
OpenJDK Runtime Environment (build 1.8.0_121-b13)
OpenJDK 64-Bit Server VM (build 25.121-b13, mixed mode)
3)下载相应的组件到/home/soft
#wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.1.2.zip
#wget https://artifacts.elastic.co/downloads/kibana/kibana-5.1.2-linux-x86_64.tar.gz
#wget https://artifacts.elastic.co/downloads/logstash/logstash-5.1.2.zip
#wget http://apache.mirrors.lucidnetworks.net/kafka/0.10.1.0/kafka_2.11-0.10.1.0.tgz
五、node01节点安装部署elasticsearch
1、创建elk用户、组
[root@node01 soft]groupadd elk
[root@node01 soft]useradd -g elk elk
2、elasticsearch解压至/usr/local/目录下
[root@node01 soft]#unzip elasticsearch-5.1.2.zip -d /usr/local/
3、创建data/db和data/logs分别存储数据文件和日志文件
[root@node01 soft]# mkdir -pv /data/{db,logs}
4、授权data/db和data/logs、/usr/local/elasticsearch-5.1.2文件夹elk用户及用户组读取权限
[root@node01 soft]chown elk:elk /usr/local/elasticsearch-5.1.2 -R
[root@node01 soft]chown elk:elk /data/{db,logs} -R
5、编辑/usr/local/elasticsearch-5.1.2/config/elasticsearch.yml 修改为如下参数:
[root@node01 config]# vim elasticsearch.yml
cluster.name: ELKstack-5
node.name: node01
path.data: /data/db
path.logs: /data/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.2.14","192.168.2.15","192.168.2.17"]
discovery.zen.minimum_master_nodes: 2
xpack.security.enabled: false #关闭es认证 与kibana对应,不然后面安装x-pack需要用户名密码验证
注:
cluster.name: ELKstack-5 #集群的名字(可任意取名称)
node.name: node01 #换个节点名字
network.host: 0.0.0.0 #监听地址,0.0.0.0表示任意机器可以访问
http.port: 9200 #可默认
http.cors.enabled: true #head插件可以访问es
http.cors.allow-origin: "*"
discovery.zen.ping.unicast.hosts: 集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点
discovery.zen.minimum_master_nodes: 选举一个Master需要多少个节点(最少候选节点数),一般设置成 N/2 + 1,N是集群中节点的数量
xpack.security.enabled: false #关闭es认证 与kibana对应,禁用了认证功能,如果启用了认证,访问时需要指定用户名密码
6、根据elk运行环境,需要修改以下参数(修改参数以后建议重启机器)
1)[root@node01 config]# vim /etc/security/limits.conf #修改限制参数,允许elk用户访问mlockall
# allow user 'elk mlockall
elk soft memlock unlimited
elk hard memlock unlimited
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
2)[root@node01 config]# vim /etc/security/limits.d/20-nproc.conf #修改可打开的文件描述符的最大数(软限制)
修改如下内容:
* soft nproc 4096
#修改为
* soft nproc 2048
3)[root@node01 config]# vim /etc/sysctl.conf #限制一个进程可以拥有的VMA(虚拟内存区域)的数量
添加下面配置:
vm.max_map_count=655360
[root@node01 config]# sysctl -p #刷新修改参数使其生效
4)修改jvm空间分配,因为elasticsearch5.x默认分配jvm空间大小为2g
[root@node01 elasticsearch-5.1.2]# vim config/jvm.options
-Xms2g
-Xmx2g
修改为
[root@node01 elasticsearch-5.1.2]# vim config/jvm.options
-Xms512m
-Xmx512m
不然会报以下错误:
OpenJDK 64-Bit Server VM warning: INFO: os::commit_memory(0x000000008a660000, 1973026816, 0) failed; error='Cannot allocate memory' (errno=12)
#
# There is insufficient memory for the Java Runtime Environment to continue.
# Native memory allocation (mmap) failed to map 1973026816 bytes for committing reserved memory.
# An error report file with more information is saved as:
# /usr/local/elasticsearch-5.1.2/hs_err_pid11986.log
5)启动elasticsearch服务,注:elasticsearch默认不允许root用户启动服务,切换至普通用户启动
[root@node01 elasticsearch-5.1.2]#su - elk
[elk@node01 elasticsearch-5.1.2]$cd /usr/local/elasticsearch-5.1.2
[elk@node01 elasticsearch-5.1.2]$nohup ./bin/elasticsearch &
[elk@node01 elasticsearch-5.1.2]$./elasticsearch -d #ElasticSearch后端启动命令
注:停止服务(ps -ef |grep elasticsearch 、kill PID)
6)启动后查看进程是否监听端口9200/9300,并且浏览器访问http://192.168.2.14:9200/,是否正常输出es集群信息等
[root@node01 ~]# ss -tlnp |grep '9200'
LISTEN 0 128 :::9200 :::* users:(("java",pid=2288,fd=113)
[root@node01 ~]# curl http://192.168.2.14:9200
{
"name" : "node01",
"cluster_name" : "ELKstack-5",
"cluster_uuid" : "jZ53M8nuRgyAKqgQCDG4Rw",
"version" : {
"number" : "5.1.2",
"build_hash" : "c8c4c16",
"build_date" : "2017-01-11T20:18:39.146Z",
"build_snapshot" : false,
"lucene_version" : "6.3.0"
},
"tagline" : "You Know, for Search"
}
六、类似node01节点安装elasticsearch部署node02、node03节点
1、安装部署node02节点elasticsearch
1)编辑/usr/local/elasticsearch-5.1.2/config/elasticsearch.yml 修改为如下参数:
[root@node02 config]# vim elasticsearch.yml
cluster.name: ELKstack-5
node.name: node02
path.data: /data/db
path.logs: /data/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.2.14","192.168.2.15","192.168.2.17"]
discovery.zen.minimum_master_nodes: 2
xpack.security.enabled: false #关闭es认证 与kibana对应
注:其他配置部署同node01
2、安装部署node03节点elasticsearch
1)编辑/usr/local/elasticsearch-5.1.2/config/elasticsearch.yml 修改为如下参数:
[root@node02 config]# vim elasticsearch.yml
cluster.name: ELKstack-5
node.name: node03
path.data: /data/db
path.logs: /data/logs
bootstrap.memory_lock: true
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["192.168.2.14","192.168.2.15","192.168.2.17"]
discovery.zen.minimum_master_nodes: 2
xpack.security.enabled: false #关闭es认证 与kibana对应
注:其他配置部署同node01
3、3个节点(node01,node02,node03)启动后,查看集群是否正常,节点是否正常
常用查询命令如下:
查看集群状态:curl -XGET http://localhost:9200/_cat/health?v
查看集群节点:curl -XGET http://localhost:9200/_cat/nodes?v
查询索引列表:curl -XGET http://localhost:9200/_cat/indices?v
创建索引:curl -XPUT http://localhost:9200/customer?pretty
查询索引:curl -XGET http://localhost:9200/customer/external/1?pretty
删除索引:curl -XDELETE http://localhost:9200/customer?pretty
[root@node01 ~]# curl -XGET http://localhost:9200/_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1486384674 20:37:54 ELKstack-5 green 3 3 0 0 0 0 0 0 - 100.0%
[root@node01 ~]# curl -XGET http://localhost:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
192.168.2.17 22 94 3 0.58 0.55 0.27 mdi * node03
192.168.2.15 22 93 0 0.59 0.60 0.29 mdi - node02
192.168.2.14 22 93 1 0.85 0.77 0.37 mdi - node01
七、node3(192.168.2.17)节点上安装head插件(由于elasticsearch5.0版本变化较大,目前elasticsearch5.0 暂时不支持直接安装)
1、在从github上面下载代码,因此先要安装git,授权文件和目录(777)
[root@node03 local]# yum install git
[root@node03 local]# git clone git://github.com/mobz/elasticsearch-head.git
[root@node03 local]# chmod 777 -R elasticsearch-head/*
2、下载Node.js,并解压,配置进环境变量
[root@node03 soft]# wget https://npm.taobao.org/mirrors/node/latest-v4.x/node-v4.6.1-linux-x64.tar.gz
[root@node03 soft]# tar -xvf node-v4.6.1-linux-x64.tar.gz #解压至当前目录
[root@node03 soft]#vim /etc/profile
添加如下: export PATH=/home/soft/node-v4.6.1-linux-x64/bin:$PATH
[root@node03 soft]#source /etc/profile #使配置文件生效。
3、在/usr/local/elasticsearch-head/目录下,进行npm install 使用node.js安装
[root@node03 elasticsearch-head]# npm install -g cnpm --registry=https://registry.npm.taobao.org
[root@node03 elasticsearch-head]# npm install grunt --save-dev
4、修改目录/usr/local/elasticsearch-head/Gruntfile.js
connect: {
server: {
options: {
port: 9100,
hostname: '0.0.0.0',
base: '.',
keepalive: true
}
}
}
增加hostname属性,设置为*或'0.0.0.0'
5、修改/usr/local/elasticsearch-5.1.2/config/elasticsearch.yml配置文件,增加一下配置,重新启动ES服务
# 以下两个为允许跨域,主要是5.1版本的head插件和以往安装的不一样
http.cors.enabled: true
http.cors.allow-origin: "*"
6、修改目录/usr/local/elasticsearch/plugins/head/_site/Gruntfile.js
connect: {
server: {
options: {
port: 9100,
hostname: '0.0.0.0',
base: '.',
keepalive: true
}
}
}
增加hostname属性,设置为*或'0.0.0.0'
7、修改/usr/local/elasticsearch-head/_site/app.js连接地址:
修改head的连接地址:
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://localhost:9200";
把localhost修改为es的服务器地址,如:
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://192.168.2.17:9200";
8、修改/usr/local/elasticsearch-5.1.2/config/elasticsearch.yml配置文件,增加一下配置,重新启动ES服务
# 以下两个为允许跨域,主要是5.1版本的head插件和以往安装的不一样
http.cors.enabled: true
http.cors.allow-origin: "*"
9、解决依赖并启动服务
执行npm install下载依赖的包:
[root@node03 elasticsearch-head]#npm install
[root@node03 elasticsearch-head]#./node_modules/grunt/bin/grunt serverb & #后台启动服务
测试访问:http://192.168.2.17:9100/
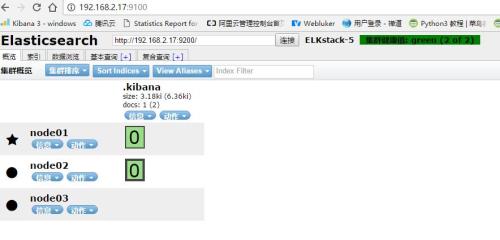
八、node2(192.168.2.15)节点上安装部署kibana
1、kibana解压至/usr/local/目录下
[root@node02 soft]# tar -xvf kibana-5.1.2-linux-x86_64.tar.gz -C /usr/local/
2、修改/usr/local/kibana-5.1.2-linux-x86_64/config/kibana.yml配置文件,如下:并启动kibana服务
[root@node02 soft]#vim /usr/local/kibana-5.1.2-linux-x86_64/config/kibana.yml
server.port: 5601
server.host: "192.168.2.15"
elasticsearch_url: "http://192.168.2.15:9200"
xpack.security.enabled: false #关闭认证,为后面kibana增加x-pack组件免去用户名密码认证
[root@node02 kibana-5.1.2-linux-x86_64]# bin/kibana > /var/log/kibana.log 2>&1 & #启动服务
九、配置客户端test节点(192.168.2.70)
1、安装配置JDK(同node01~node03,这里不再阐述)
2、拷贝logstash至客户端,并解压至/usr/local/目录下
[root@node02 config]# scp /home/soft/logstash-5.1.2.zip root@192.168.2.70:/home/soft/
[root@test soft]#unzip logstash-5.1.2.zip -d /usr/local/
3、编辑logstash服务管理脚本(配置路径可根据实际情况修改)
[root@test logstash-5.1.2]# mkdir logs etc #创建目录logs,etc
[root@test logstash-5.1.2]# vim /etc/init.d/logstash
[root@test logstash-5.1.2]# chmod +x /etc/init.d/logstash #添加权限
脚本如下:
#!/bin/bash
#chkconfig: 2345 55 24
#description: logstash service manager
#auto: Maoqiu Guo
FILE='/usr/local/logstash-5.1.2/etc/*.conf' #logstash配置文件
LOGBIN='/usr/local/logstash-5.1.2/bin/logstash agent --verbose --config' #指定logstash配置文件的命令
LOCK='/usr/local/logstash-5.1.2/locks' #用锁文件配合服务启动与关闭
LOGLOG='--log /usr/local/logstash-5.1.2/logs/stdou.log' #日志
START() {
if [ -f $LOCK ];then
echo -e "Logstash is already \033[32mrunning\033[0m, do nothing."
else
echo -e "Start logstash service.\033[32mdone\033[m"
nohup ${LOGBIN} ${FILE} ${LOGLOG} &
touch $LOCK
fi
}
STOP() {
if [ ! -f $LOCK ];then
echo -e "Logstash is already stop, do nothing."
else
echo -e "Stop logstash serivce \033[32mdone\033[m"
rm -rf $LOCK
ps -ef | greplogstash | grep -v "grep" | awk '{print $2}' | xargskill -s 9 >/dev/null
fi
}
STATUS() {
psaux | greplogstash | grep -v "grep" >/dev/null
if [ -f $LOCK ] && [ $? -eq 0 ]; then
echo -e "Logstash is: \033[32mrunning\033[0m..."
else
echo -e "Logstash is: \033[31mstopped\033[0m..."
fi
}
TEST(){
${LOGBIN} ${FILE} --configtest
}
case "$1" in
start)
START
;;
stop)
STOP
;;
status)
STATUS
;;
restart)
STOP
sleep 2
START
;;
test)
TEST
;;
*)
echo "Usage: /etc/init.d/logstash (test|start|stop|status|restart)"
;;
esac
4、Logstash 向es集群写数据,并测试
1)、在/usr/local/logstash-5.1.2/etc/目录下编写一个logstash配置文件logstash.conf
[root@test etc]# cat logstash.conf
input { #数据的输入从标准输入
stdin {}
}
output { #数据的输出我们指向了es集群
elasticsearch {
hosts => ["192.168.2.14:9200","192.168.2.15:9200",192.168.2.17:9200"]#es主机的ip及端口
}
}
[root@test etc]# /usr/local/logstash-5.1.2/bin/logstash -f logstash.conf -t #查看配置是否正常
Sending Logstash's logs to /usr/local/logstash-5.1.2/logs which is now configured via log4j2.properties
Configuration OK
2)测试数据ES,修改logstash.conf配置文件,把messages输出到日志中,启动logstash服务
[root@test etc]# cat logstash.conf
input {#这里的输入使用的文件,即日志文件messsages
file {
path => "/var/log/messages"#这是日志文件的绝对路径
start_position => "beginning"#这个表示从messages的第一行读取,即文件开始处
}
}
output {#输出到es
elasticsearch {
hosts => ["192.168.2.14:9200","192.168.2.15:9200",192.168.2.17:9200"]
index => "messages-%{+YYYY-MM}"#这里将按照这个索引格式来创建索引
}
}
[root@test etc]# /usr/local/logstash-5.1.2/bin/logstash -f logstash.conf 或[root@test etc]# /etc/init.d/logstash start
3)验证插件head和kibana是否从ES集群接收到数据并展示
head插件看到相关索引http://192.168.2.17:9100/
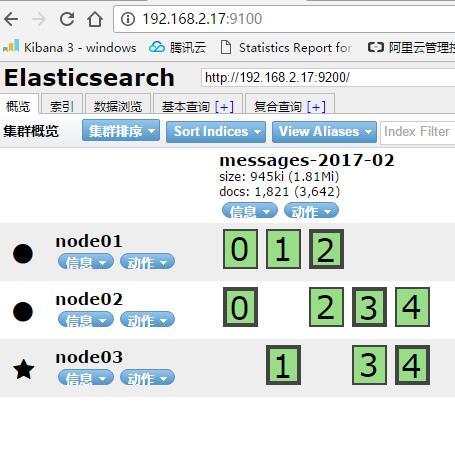
kibana根据中相关索引,新建图片http://192.168.2.15:5601/
九、安装部署Kafka消息队列
1、Kafka是一个分布式、可分区、可复制的消息系统, 在Kafka集群中,没有『中心主节点』的概念,集群中所有的服务器都是对等的,因此可以在不做任何配置更改的情况下对服务器进行添加和删除,同样的消息生产者和消费都也能做到随意重启和机器的上下线。
2、Kafka相关概念
kafka核心组件工作流程
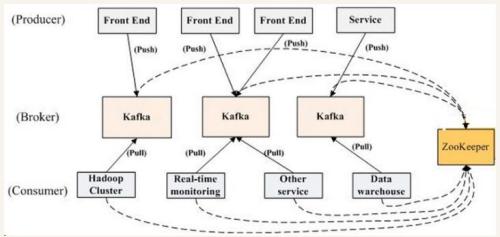
Consumer:用于从Broker中取出/消费Message
Producer:用于往Broker中发送/生产Message
Broker:Kafka中使用Broker来接受Producer和Consumer的请求,并把Message持久化到本地磁盘。每个Cluster当中会选举出一个Broker来担任Controller,负责处理Partition的Leader选举,协调Partition迁移等工作
以上组件在分布式环境下均可以是多个,支持故障转移。同时ZooKeeper仅和broker和consumer相关。broker的设计是无状态的,消费的状态信息依靠消费者自己维护,通过一个offset偏移量。client和server之间通信采用TCP协议。
发布消息通常有两种模式:队列模式(queuing)和发布-订阅模式(publish-subscribe)。队列模式中,consumers 可以同时从服务端读取消息,每个消息只被其中一个 consumer 读到;发布-订阅模式中消息被广播到所有的 consumer 中。更常见的是,每个 topic 都有若干数量的 consumer 组,每个组都是一个逻辑上的『订阅者』,为了容错和更好的稳定性,每个组由若干 consumer 组成。这其实就是一个发布-订阅模式,只不过订阅者是个组而不是单个 consumer。
3、kafka的Topic与Partition工作流程
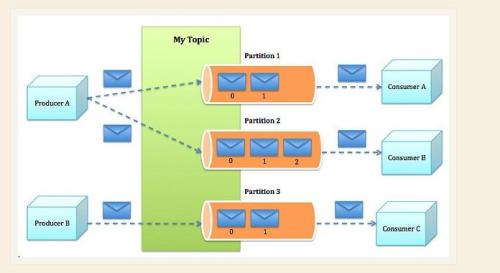
消息是按照主题来提交到Partition当中的。Partition当中的消息是有序的,consumer从一个有序的分区消息队列中顺序获取消息。相关名次定义如下:
Topic:用于划分Message的逻辑概念,一个Topic可以分布在多个Broker上
Partition:是Kafka中横向扩展和一切并行化的基础,每个Topic都至少被切分为1个Partition
offset:消息在Partition中的编号,编号顺序不跨Partition
分区目的:Kafka中采用分区的设计有几个目的。一是可以处理更多的消息,不受单台服务器的限制。Topic拥有多个分区意味着它可以不受限的处理更多的数据。第二,分区可以作为并行处理的单元
offset:由消费者控制offset,因此分区本身所在broker是无状态的。消费者可以自由控制offset,很灵活
同个分区内有序消费:每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分配了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的
4、node01节点(192.168.2.14)上安装部署kafka(这里测试zookeeper没有集群,实际生产环境建议使用集群)
注:安装配置JDK环境这里省略,类同node01等节点
1)kafka解压至/usr/local/目录下,并创建链接kafka
[root@node01 soft]# tar -xvf kafka_2.11-0.10.1.0.tgz -C /usr/local/
[root@node01 soft]# cd /usr/local/
[root@node01 local]# ln -sv kafka_2.11-0.10.1.0 kafka
2)创建zookeeper存储目录,修改/usr/local/kafka/config/目录下zookeeper.propertie配置文件
[root@node01 local]# mkdir /data/zookeeper
[root@node01 local]#vim /usr/local/kafka/config/zookeeper.propertie
修改配置如下:
dataDir=/data/zookeeper
# the port at which the clients will connect
tickTime=2000 #维持心跳的时间间隔
initLimit=20
syncLimit=10
注:如果zookeeper集群的话,必须标识再配置文件server.2,server.*不同名称并且在/data/zookeeper目录下创建myid文件,里面的内容为数字,用于标识主机,如果这个文件没有的话,zookeeper是没法启动的
如:[root@kafka1 ~]# echo 2 > /data/zookeeper/myid
3)修改kafka配置/usr/local/kafka/config/目录下server.properties文件
broker.id=0 # 唯一,填数字,如果是集群该值必须不同如:2、3、4
listeners=PLAINTEXT://:9092 #监听端口
advertised.listeners=PLAINTEXT://192.168.2.14:9092 # 唯一,填服务器IP
log.dir=/data/kafka-logs # 该目录可以不用提前创建,在启动时自己会创建
zookeeper.connect=192.168.2.14:2181 #这个就是zookeeper的ip及端口
num.partitions=16 # 需要配置较大 分片影响读写速度
log.dirs=/data/kafka-logs # 数据目录也要单独配置磁盘较大的地方
log.retention.hours=168 # 时间按需求保留过期时间 避免磁盘满
4)启动kafka和zookeeper服务(先要启动zookeeper再启动kafka,如果是zookeeper集群如是)
[root@kafka1 ~]# /usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties & #zookeeper启动命令
注:/usr/local/kafka/bin/zookeeper-server-stop.sh #暂停服务
[root@node01 config]# ss -tlnp |grep '2181' #启动正常
LISTEN 0 50 :::2181 :::* users:(("java",pid=3118,fd=88))
[root@node01 config]# nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties &
#kafka启动的命令
或
#/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties > /dev/null &
注:/usr/local/kafka/bin/kafka-server-stop.sh #暂停服务
5)kafka创建一个主题
[root@node01 kafka]#bin/kafka-topics.sh --create --zookeeper 192.168.2.14:2181 --replication-factor 1 --partitions 1 --topic linuxtest
#注意:factor大小不能超过broker数
[root@node01 kafka]# bin/kafka-topics.sh --list --zookeeper 192.168.2.14:2181 #查看主题
linuxtest
[root@node01 kafka]#bin/kafka-topics.sh --describe --zookeeper 192.168.2.14:2181 --topic linuxtest
Topic:linuxtestPartitionCount:1ReplicationFactor:1Configs:
Topic: linuxtestPartition: 0Leader: 0Replicas: 0Isr: 0
6)发送消息,这里使用的是生产者角色
[root@node01 kafka]#bin/kafka-console-producer.sh --broker-list 192.168.2.14:9092 --topic linuxtest
This is a messages
welcometo kafka
7)接收消息,这里使用的是消费者角色
[root@node01 kafka]#bin/kafka-console-consumer.sh --zookeeper 192.168.2.14:2181 --topic linuxtest --from-beginning
This is a messages
welcometo kafka
5、修改客户端test节点logstash.conf配置文件,输出改到kafka上面,将数据写入到kafka中,重启logstash服务
[root@test etc]# cat logstash.conf
input { #这里的输入还是定义的是从日志文件输入
file {
type => "message"
path => "/var/log/messages"
start_position => "beginning"
}
}
output {
#stdout { codec => rubydebug } #这是标准输出到终端,可以用于调试看有没有输出,注意输出的方向可以有多个
kafka { #输出到kafka
bootstrap_servers => "192.168.2.14:9092" #他们就是生产者
topic_id => "linux-messages" #这个将作为主题的名称,将会自动创建
compression_type => "snappy" #压缩类型
}
}
[root@test etc]#/usr/local/logstash-5.1.2/bin/logstash -f logstash.conf > /dev/null &
6、从kafka中读取数据后输出到ES机器,node01安装部署Logstash,安装步骤不再赘述;注意这里的日志主题名称“linuxtest”,并启动服务
[root@node01 etc]# more logstash.conf
input {
kafka {
zk_connect => "192.168.2.14:2181" #消费者们
topic_id => "linuxtest"
codec => plain
reset_beginning => false
consumer_threads => 5
decorate_events => true
}
}
output {
elasticsearch {
hosts => ["192.168.2.14:9200","192.168.2.15:9200","192.168.2.17:9200"]
index => "linux-messages-%{+YYYY-MM}"
}
}
[root@node01 etc]# /usr/local/logstash/bin/logstash -f logstash.conf > /dev/null & #启动服务
7、验证在test客户端上写入测试内容
[root@webserver1etc]# echo "test-linux-messages到es集群!!!" >> /var/log/messages
#启动logstash,让其读取messages中的内容
十、安装部署X-Pack(需付费X-Pack License(可注册1年免费 License))
1、x-pack是elasticsearch的一个扩展包,将安全,警告,监视,图形和报告功能捆绑在一个易于安装的软件包中,虽然x-pack被设计为一个无缝的工作,但是你可以轻松的启用或者关闭一些功能。
注:以下为license 注册信息
curl -XPUT -u elastic:password 'http://<host>:<port>/_xpack/license' -d @license.json
@license.json 申请得到的json文件,复制文件中的所有内容,粘贴在此。
如果提示需要acknowledge,则设置为true
curl -XPUT -u elastic:password 'http://<host>:<port>/_xpack/license?acknowledge=true' -d @license.json
查看安装结果信息
curl -XGET -u elastic:password 'http://<host>:<port>/_license'
不同版本功能
https://www.elastic.co/subscriptions
X-Pack监控组件使您能够通过Kibana轻松监控Elasticsearch。 您可以实时查看集群运行状况和性能,以及分析过去的集群,索引和节点指标。 此外,您可以监控Kibana本身的性能。在群集上安装X-Pack时,监视代理会在每个节点上运行,以从Elasticsearch收集索引指标。 通过在Kibana中安装X-Pack,您可以通过一组专用仪表板查看监视数据。
x-pack安装之后有一个超级用户elastic ,其默认的密码是changeme,拥有对所有索引和数据的控制权,可以使用该用户创建和修改其他用户,当然这里可以通过kibana的web界面进行用户和用户组的管理。
X-pack的elk之间的数据传递保护,如:安装完x-pack之后,我们就可以用我们所创建的用户来保护elk之间的数据传递.
如下:
1)kibana<——>elasticsearch
在kibana.yml文件中配置:
elasticsearch.username: “elastic”
elasticsearch.password: “changeme”
2)logstash<——>elasticsearch
在自己写的配置文件中定义
input {
stdin{}
beats{
port => 5044
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
user => elastic #必须有对应的用户/密码
password => changeme
}
stdout{
codec=>rubydebug
}
}
注:这里如果不进行相关配置的话,elk之间的数据传递就会出现问题
2、在各个ES集群节点/usr/local/elasticsearch-5.1.2/目录下以及kibana(本示例kibana在node02上)的/usr/local/kibana-5.1.2-linux-x86_64/
目录下安装X-Pack,并重启Kibana
[root@node01 elasticsearch-5.1.2]# bin/elasticsearch-plugin install x-pack
[root@node02 elasticsearch-5.1.2]# bin/elasticsearch-plugin install x-pack
[root@node03 elasticsearch-5.1.2]# bin/elasticsearch-plugin install x-pack
[root@node02 kibana-5.1.2-linux-x86_64]# bin/kibana-plugin install x-pack
[root@node02 kibana-5.1.2-linux-x86_64]# bin/kibana > /var/log/kibana.log 2>&1 & #kill进程后启动服务
注:卸载x-pack组件,#bin/elasticsearch-plugin remove x-pack
页面访问:http://192.168.2.15:5601,可以查看多了Monitoring选项,更多资料请参考官网
官方文档:https://www.elastic.co/guide/index.html
elasticsearch 权威指南:http://www.learnes.net/
ELK stack 权威指南:http://kibana.logstash.es/content/logstash/
ELK 开发指南:https://endymecy.gitbooks.io/elasticsearch-guide-chinese/content/index.html
****************************************************************************************************
常见问题总结:
#Java HotSpot(TM) 64-Bit Server VM warning: INFO: os::commit_memory(0x0000000085330000, 2060255232, 0) failed; error='Cannot allocate memory' (errno=12)
由于elasticsearch5.x默认分配jvm空间大小为2g,修改jvm空间分配
# vim config/jvm.options
-Xms2g
-Xmx2g
修改为
# vim config/jvm.options
-Xms512m
-Xmx512m
#max file descriptors [65535] for elasticsearch process is too low, increase to at least [65536]
ulimit -SHn 65536
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
#max number of threads [1024] for user [elasticsearch] is too low, increase to at least [2048]
修改 /etc/security/limits.d/90-nproc.conf
* soft nproc 1024
* soft nproc 2048
#max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
修改/etc/sysctl.conf配置文件,
cat /etc/sysctl.conf | grep vm.max_map_count
vm.max_map_count=262144
如果不存在则添加
echo "vm.max_map_count=262144" >>/etc/sysctl.conf
本文出自 “一万小时定律” 博客,请务必保留此出处http://daisywei.blog.51cto.com/7837970/1896347
Elasticstack 5.1.2 集群日志系统部署及实践的更多相关文章
- vivo 容器集群监控系统架构与实践
vivo 互联网服务器团队-YuanPeng 一.概述 从容器技术的推广以及 Kubernetes成为容器调度管理领域的事实标准开始,云原生的理念和技术架构体系逐渐在生产环境中得到了越来越广泛的应用实 ...
- ELK+Kafka集群日志分析系统
ELK+Kafka集群分析系统部署 因为是自己本地写好的word文档复制进来的.格式有些出入还望体谅.如有错误请回复.谢谢! 一. 系统介绍 2 二. 版本说明 3 三. 服务部署 3 1) JDK部 ...
- elk + filebeat,6.3.2版本简单搭建,实现我们自己的集中式日志系统
前言 刚从事开发那段时间不习惯输出日志,认为那是无用功,徒增代码量,总认为自己的代码无懈可击:老大的叮嘱.强调也都视为耳旁风,最终导致的结果是我加班排查问题,花的时间还挺长的,要复现问题.排查问题等, ...
- 集中式日志系统 ELK 协议栈详解
简介 在我们日常生活中,我们经常需要回顾以前发生的一些事情:或者,当出现了一些问题的时候,可以从某些地方去查找原因,寻找发生问题的痕迹.无可避免需要用到文字的.图像的等等不同形式的记录.用计算机的术语 ...
- Oracle归档日志所在目录时间不对&&Oracle集群日志时间显示错误
Oracle归档日志所在目录时间不对&&Oracle集群日志时间显示错误 前言 这个问题在18年的时候遇到了,基本不注意并且集群或者数据库运行正常是很难注意到的. 忘记当时怎么发现的了 ...
- Kubernetes 集群日志 和 EFK 架构日志方案
目录 第一部分:Kubernetes 日志 Kubernetes Logging 是如何工作的 Kubernetes Pod 日志存储位置 Kubelet Logs Kubernetes 容器日志格式 ...
- 集群监控系统Ganglia应用案例
集群监控系统Ganglia应用案例 --我们把集群系统投入生产环境后,这时就需要一套可视化的工具来监视集群系统,这将有助于我们迅速地了解机群的整体配置情况,准确地把握机群各个监控节点的信息,全面地察看 ...
- weblogic11g 安装集群 —— win2003 系统、单台主机
weblogic11g 安装集群 —— win2003 系统.单台主机 注意:此为weblogic11g 在win2003系统下(一台主机)的安装集群,linux.hpux.aix及多个主机下原理一 ...
- ElasticSearch+Logstash+Filebeat+Kibana集群日志管理分析平台搭建
一.ELK搜索引擎原理介绍 在使用搜索引擎是你可能会觉得很简单方便,只需要在搜索栏输入想要的关键字就能显示出想要的结果.但在这简单的操作背后是搜索引擎复杂的逻辑和许多组件协同工作的结果. 搜索引擎的组 ...
随机推荐
- mysql主从备份及原理分析
一.mysql主从备份(复制)的基本原理mysql支持单向.异步复制,复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器.mysql复制基于主服务器在二进制日志中跟踪所有对数据库的更 ...
- 用GibbsLDA做Topic Modeling
http://weblab.com.cityu.edu.hk/blog/luheng/2011/06/24/%E7%94%A8gibbslda%E5%81%9Atopic-modeling/#comm ...
- Java-JUC(九):使用Lock替换synchronized,使用Condition的await,singal,singalall替换object的wait,notify,notifyall实现线程间的通信
Condition: condition接口描述了可能会与锁有关的条件变量.这些用法上与使用object.wait访问隐式监视器类似,但提供了更强大的功能.需要特别指出的是,单个lock可能与多个Co ...
- 转: gcc 指定运行时动态库路径
gcc 指定运行时动态库路径 Leave a reply 由于种种原因,Linux 下写 c 代码时要用到一些外部库(不属于标准C的库),可是由于没有权限,无法将这写库安装到系统目录,只好安装用户目录 ...
- Dubbo框架应用之(三)--Zookeeper注冊中心、管理控制台的安装及解说
我是在linux下使用dubbo-2.3.3以上版本号的zookeeper注冊中心客户端. Zookeeper是Apache Hadoop的子项目,强度相对较好,建议生产环境使用该注冊中心. Dubb ...
- [React] Use React.ReactNode for the children prop in React TypeScript components and Render Props
Because @types/react has to expose all its internal types, there can be a lot of confusion over how ...
- 浅谈压缩感知(十四):傅里叶矩阵与小波变换矩阵的MATLAB实现
主要内容: 傅里叶矩阵及其MATLAB实现 小波变换矩阵及其MATLAB实现 傅里叶矩阵及其MATLAB实现 傅里叶矩阵的定义:(来源: http://mathworld.wolfram.com/F ...
- Android Studio 之 Launch AVD 时" Intel HAXM is required to run this AVD, VT-x is disabled in BIOS; "
问题描述:Launch AVD 时弹窗信息" Intel HAXM is required to run this AVD, VT-x is disabled in BIOS; " ...
- Yahoo邮箱最后登录,成为历史!
- Linux中Centos7下安装Mysql(更名为Mariadb)
一.安装: yum install mariadb-server mariadb 二.启动服务: systemctl start mariadb 三.配置大小写敏感问题.和字符为utf8: vim / ...