CS231n 斯坦福深度视觉识别课 学习笔记(完结)
第1章 CS231n课程介绍
---1.1 计算机视觉概述
- 这门课的主要内容是计算机视觉.它是一门需要涉及很多其他科目知识的学科.
- 视觉数据占据了互联网的绝大多数,但是它们很难利用.
---1.2 计算机视觉历史背景
- 为了获得一副3D图像,我们需要经历原始图像(端点,曲线,边缘)->2.5维草图(场景的不连续性)->3D图像几个过程.
- 70年代:每个对象由简单的几何图单位组成
- 80年代:如何识别由简单物体构成的视觉空间
- 如果目标识别太难了,应该先进行图像分割.
- 可以使用图片中的特征来进行图像识别.
- 图像特征的维度一般很高,因此算法很容易过拟合.
- ImageNet是一个很大的目标识别数据集,相关比赛往往使用top5标准来衡量.
---1.3 课程后勤
- 介绍了本门课的内容:图像识别,目标检测,风格迁移,如何从零开始构建CNN,以及tensorflow等框架的使用等.
- 深度学习流行的主要原因是计算能力的提高和数据量的增长.
第2章 图像分类
---2.1 图像分类-数据驱动方法
- 计算机存储图像的方式是二维或三维矩阵.一个物体与计算机实际看到的像素值之间的差距称为语义鸿沟.
- 一个具有鲁棒性的图像识别算法应该能从不同角度,光照条件,变形,遮挡,类内条件差异等条件下识别出物体类别.
- 边缘对于视觉识别是十分重要的.但是基于边缘的规则识别算法不是一种好方法.
- 数据驱动的分类方法是指:
- 收集具有标注的图片数据集(CIFAR10).
- 使用机器学习来训练分类器.
- 使用模型来预测新的图片.
- 最近邻(Nearest Neighbors)算法:
- 不进行训练,只是单纯地存储所有的数据集,然后对于要预测的图片,从数据集中找出与它最相似的图片的标签作为输出.
- 训练时间很短,预测时间很长.这与我们理想中的图像识别算法相反.
- 最近邻算法很容易出现误分类,因此出现了K近邻(K-Nearest Neighbors)算法:选出K个最近点,然后进行多数投票决定输出.
---2.2 图像分类-K近邻算法
- 距离函数是K近邻算法的关键.常用的有L1距离,L2距离等.通过不同的距离函数还可以将K近邻算法泛化到任何类型的数据上.
- K近邻算法中的K值和距离函数就是典型的超参数:需要人为设置,而不能由算法学习得到.选择超参数的常见作法就是将数据集分为训练集,验证集,测试集.使用验证集来选择超参数,并在测试集得到结果.如果数据集较小,还可以采用交叉验证的方法进行选择.
- 实际上K近邻算法很少在图像数据中应用,因为它预测时间很长,而且距离函数很难度量图像数据.
---2.3 图像分类-线性分类I
- 线性分类器是参数模型中最简单的例子.它实际上是关于输入数据x和权重W的函数,输出代表了预测的类别.
- 线性分类器实际上是用一个模版来匹配图像,所以它对于多模态类别的预测能力较差.另外从几何角度上看,线性分类器是用一个线性平面来将某一类别与其他类别划分开来,因此很难处理奇偶或多分类问题.
第3章 损失函数和优化
---3.1 损失函数
- 为了得到线性分类器的权重,引入了损失函数来定量地衡量权重的好坏.最小化损失函数的过程是一个优化过程.
- 损失函数就是一个关于预测值和真实值的函数.
- 多分类SVM
- 损失函数:如果真实分类的分数大于其他分数+边界(margin),则损失=0,否则损失=其他分数-真实分数+边界.边界的值可以任意选择,因为这个参数最终会消失.用公示表示为
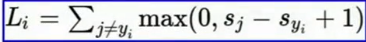 ,
,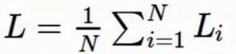 ,也称为hinge损失.
,也称为hinge损失. - 初次迭代时损失函数的值应该约为分类的数量减去1.
- 假如有一组W使得损失函数为0,那么2W的损失函数也应该为0.这就使得有无穷多组权重,分类器将无法抉择.因此需要加入超参数λR(W)作为正则化项,R(W)有L2范数,L1范数,弹性网络,最大规范等正则化选项.正则化的目的就是减轻模型复杂度.
- SVM只关心正确分类是否比其他分类高出一个边界.
- Softmax:
- 数据的softmax值是
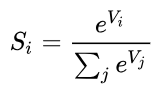
- 对应的损失函数值是
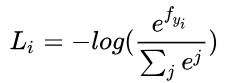 ,也称为交叉熵损失.
,也称为交叉熵损失. 初次迭代时损失函数的值应该约为log(C),C为分类数.
softmax会不断提高正确分类的概率分布.
---3.2 优化
- 优化的过程可以想象为在一座山中寻找山谷.
- 梯度下降法是最常用的优化方法.
- 负梯度方向是函数下降最快的方向.
- 首先随机初始化权重,然后计算梯度,接着朝梯度最小的方向前进一小步.
- 步长是一个超参数,最好在初始时选择较大步长,然后逐渐缩小.
- 随机梯度下降(SGD)只选取小批量(minibatch)数据进行估算,可以提升速度.
- 梯度可由解析梯度(先计算出梯度公式,再代入数值)和数值梯度(代入一个δ和数值计算)计算,数据维度高时前者速度较快.
- 图像分类直接输入原始像素值并不好,常用方式是计算图片的特征代表,然后将这些特征向量合在一起,传入线性分类器.常用的特征表示有颜色直方图,方向梯度直方图,词袋等.这种方式与神经网络有些相似,区别是我们的数据划分方式将由神经网络学习得到.
第4章 介绍神经网络
---4.1 反向传播
- 反向传播:
- 给定输入值后,进行前向传播,可以得到输出值.
- 反向传播实际上是链式法则的递归调用,逐层从后往前,可以求出输出值对每个输入的导数.
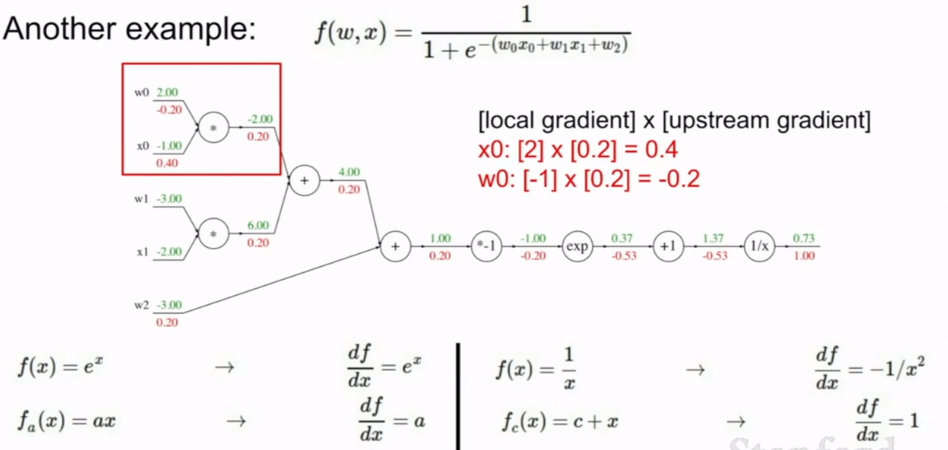
- 反向传播的连续节点可以任意组合,只要对这个整体求导即可.
- max门的后向传播与前向传播类似,它只将梯度传递给最大值对应的节点.
- 沿着梯度方向前进一个步长,就更新了权重.
---4.2 神经网络
- 通过不同的函数叠加,就可以使单层的线性分类器变为多层的神经网络乃至深度网络.
--- 作业2
Fully-Connectd Neural Nets:
- 将每一种层的类型通过前向传播和反向传播来实现模块化
- 全连接层前向传播:将输入x通过reshape展开后,和权重w点乘并加上偏差b.
- 全连接层后向传播:分别对wx+b求导,得到dx是上层梯度dout和权重w转置后的点乘,再通过reshape转换为x的shape.dw是x通过reshape展开后的转置和上层梯度dout的点乘,db就是上层梯度在纵轴方向上的和.
- relu层前向传播:使用np.maximum(0,x)求出x中的每个元素和0之间的最大值.
- relu层后向传播:对于大于0的输出值,相当于y=x,因此求导后就是自身.对于小于0的输出值,相当于y=0,因此求导后还是0.所以令dx=上层梯度dout,然后用dx[x<=0]=0来实现.
- 全连接层+relu层是常用组合
第5章 卷积神经网络
---5.1 历史
- 卷积神经网络就是拥有卷积层的神经网络.
---5.2 卷积和池化
- 全连接层的每一个结点都与上一层的所有结点相连.
- 卷积层:
- 可以保持空间结构
- 卷积层的权重叫做卷积核(滤波器,感受野),将卷积核在图像上滑动并计算每一次滑动的点积.滑动的步长是可以选择的.更大的步长意味着降采样.
- 卷积核的深度一般默认与输入图像相同.
- 实际应用中一般会在边角用零填充,这样可以保持全尺寸输出.
- 一般会用多个卷积核(2的次方).
- 滑动卷积核会造成输入和输出的尺寸不同.
- 在卷积层后一般会跟随一个激活层.
- 每几个卷积层之间会有一个池化层.
---5.3 视觉之外的卷积神经网络
- 池化层:
- 作用是使生成的表示更小且更容易控制.
- 池化层的步长一般设置为避免重叠,并且一般不使用零填充,因为目的是降采样.
- 最常见的方法是最大池化:取卷积核中的最大值.滤波器一般设置为2*2.
- 小尺寸卷积核和弃用池化是一种趋势.
第6章 训练神经网络(上)
---6.1 激活函数
- sigmoid:
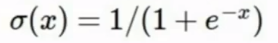
- 可以将数据压缩到[0,1]范围内.
- 看作神经元的饱和放电率.
- 神经元饱和(绝对值很大)时,由于sigmoid函数的导数为0,经过链式法则后梯度也将变为0,会造成梯度消失.
- 由于sigmoid函数不是以0为中心的,因此它不会改变输入值的正负.这意味着梯度下降法将进行得十分缓慢.(这也是我们要使用均值为0的数据的原因)
- tanh:
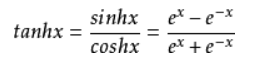
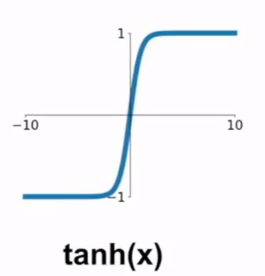
- 数据被压缩到[-1,1]范围内.
- 以0为中心,但是当输入饱和时仍会出现梯度消失.
- ReLU:

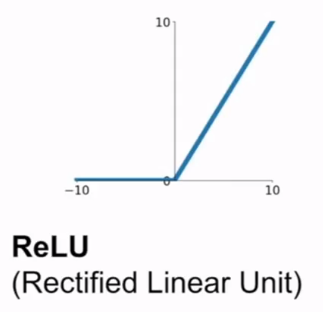
- 将负数变为0,正数保持不变.
- 不会在正的区域产生饱和现象.
- 计算速度快,因此收敛也很快.
- 比sigmoid函数更具有神经科学的相似性.
- 负的区域仍会饱和,并且导致梯度消失.这被称为dead ReLU.因此使用时一般用较小的正偏置进行初始化.
- Leaky ReLU:
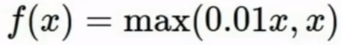

- 与ReLU的区别是负区域有一个微小的斜率.
- 输出均值接近0.
- 计算速度仍较快,并且不会发生饱和.
- ELU(Exponential Linear Units):
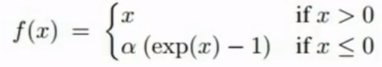
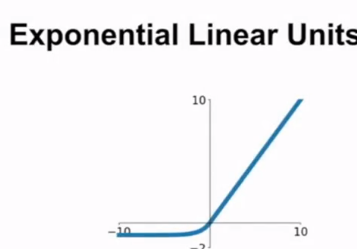
- 具有ReLU的优点.
- 输出的均值接近0.
- 负区域较容易饱和.
- Maxout:
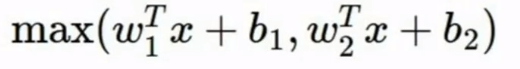
- 可以看做是ReLU和Leaky ReLU的泛化.
- 不会饱和也不会发生梯度消失.
- ReLU是较为通用的方法,Leaky ReLU/Maxout/ELU可以尝试使用,但它们更偏向于实验性.tanh也可以尝试.最好不要使用sigmoid.
- 数据预处理是一个重要环节.
- 零中心化(Zero-centered):
- X -= np.mean(X, axis=0)
- 目的的使输入数据有正有负,从而避免所有梯度的正负性相同.可以加快优化速度.
- 在图像处理中较常用.可以减去整张图像的均值图像(AlexNet),或者只减去单通道平均值(VGGNet).
- 一般在训练集中计算出均值后,会将该均值应用到测试数据中.
- 归一化(Normalization):
- X /= np.std(X, axis=0)
- 使得所有特征处于一个范围内,贡献相同.
- 在图像处理中较少用,因为图像中的数值已经有一定范围限制.
- 权重初始化:
- 全零初始化会使所有的神经元将做相同的事情,称为参数对称.
- 如果使用较小的随机参数初始化,当网络较深时,所有的激活值都将趋向于0.
- 如果使用较大的随机参数初始化,会发生饱和.
- Xavier初始化是根据输入来得到初始化权重的一种方法.
---6.2 批量归一化
- 批量归一化(Batch Normalization)也就是BN操作,目的是让每个隐层节点的激活输入分布缩小到(-1,1).
- 假设有N个D维训练样本,我们将对每个维度独立计算经验均值和方差.
- 批量归一化层通常是在全连接层或卷积层之后插入的.
- 计算过程:
- 计算小批量均值:
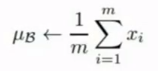
- 计算小批量方差:
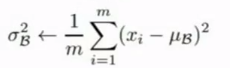
- 归一化:
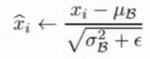
- 缩放和平移因子(由学习得到):
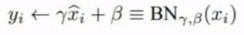
- 优点是缩小输入空间,从而降低调参难度.还可以防止梯度爆炸/消失,从而加速网络收敛.
- 在选取超参数时,可以用随机搜索或网格搜索.随机搜索的优点是可以对超参数空间覆盖的更好.

第7章 训练神经网络(下)
---7.1 更好的优化
- 零中心化,归一化等数据预处理的好处是可以使分类器对参数值中的小扰动不那么敏感.
- SGD的缺陷:
- 如果目标函数的梯度方向与最小值并不在一条线上,那么SGD将会呈"之"字形波动.
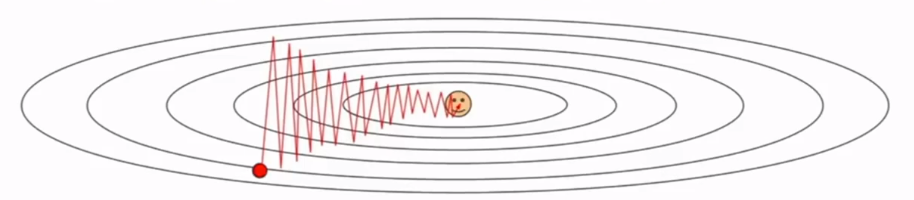
- 如果有目标函数存在鞍点(局部最小点),SGD将卡在里面或前进非常缓慢.
- SGD有随机性,所以噪点的存在会让SGD运行十分缓慢.
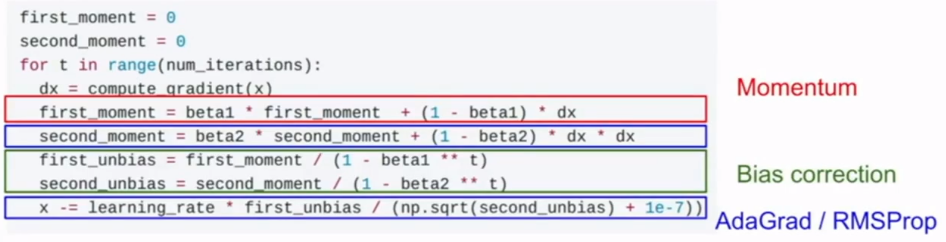
- 动量(Momentum)SGD:可以解决上述问题.也就是保持一个不随时间变化的速度,并且将梯度变化增加到这个速度上,然后在这个速度的方向上前进而不是在梯度方向前进.每一步都用摩擦系数和梯度来更新速度.速度可以初始化为0.

- Nesterov acceletared gradient(NAG):Momentum的改进.先在原速度方向上前进一步,计算此时的梯度后,回到原来的位置,结合这个梯度和原速度决定本次前进的方向.

- 上述两种方法对于极端极值点的效果可能一般,但事实是极端极值点意味着训练可能过拟合了,平滑极值点更具鲁棒性.
- AdaGrad:在训练时一直累积一个梯度平方项,用步长*梯度/梯度平方项来前进.它的效果是加速小梯度方向的学习速度,减小大梯度方向的学习速度.并且因为梯度单调递增,因此步长会越来越小,有利于接近极值点,但同时会带来鞍点的问题.式中的1e-7是为了除数不为0.

- RMSProp:是AdaGrad的改进.仍计算梯度平方项,但让它按一定衰减率指数下降,可以解决AdaGrad算法学习率下降过快的问题.

- Adam:可以看做是Momentum和RMSProp的结合.其中第一动量是速度,第二动量是梯度平方项.如果将第二动量初始化为0,那么一开始的步长会很大,因此需要加入偏置项,并使用动量的无偏估计来代替动量.
- 学习率是优化函数的一个重要超参数,推荐先使用较大的学习率,然后随着训练迭代逐渐减小.但是在刚建立模型时最好使用一个固定的学习率.
- 以上优化算法都是一阶逼近的,二阶逼近的缺陷是计算量太大.可以用拟牛顿法代替牛顿法,但它们在深度学习中的使用并不多,因为并没有太多处理随机的方法.
- Adam(beta1=0.9,beta2=0.999,学习率=1e-3或5e-4)是首选优化算法,但是如果问题并没有太多随机性,且能承受计算量的情况下(如风格迁移),可以尝试L-BFGS.
- 如果训练准确率已经很高,可以使用模型集成(Ensembles)来提高测试准确率.一种简单的集成方法是对不同独立模型的结果采用投票法或平均法.也可以使用一个模型在训练中多个不同时期的结果来进行集成.
---7.2 正则化
- 正则化是一种通过防止过拟合来提高单一模型表现的方法.一般是在损失函数中加入正则项来实现.
- 一般采用的正则化方法都是在训练时加入某种随机性,然后在测试时抵消掉它们,由此来抑制过拟合.比如batch normalization和dropout.
- Dropout:每一次前向传播时,随机将一部分神经元的激活函数置0(一般将置0率设为0.5).它可以看作是避免了特征间的相互适应来抑制过拟合,或者是单一模型的一种集成学习.一个问题是dropout中存在随机性,因此在测试时会采取乘以期望概率的形式来实现.由此产生的一种称为反转dropout的技巧,就是指在训练阶段将权重除以概率,这样在测试阶段就不用再乘以概率.

- 数据增强(Data Augmentation)是指在训练过程中以某种方式随机地转换图像(翻转,裁剪,色彩抖动)来增加随机性.
- DropConnect和dropout类似,区别是它将权重矩阵的一些值置0.
- 部分最大池化(Fractional Max Pooling)是指在池化层中随机池化部分区域.
- 随机深度(Stochastic Depth)是指在训练时随机丢弃一些层,只用部分层.然后在测试时使用全部的网络.
- 大多数情况下单独使用batch normalization就足够了,如果仍存在过拟合的情况,可以尝试dropout或其他方法.
---7.3 迁移学习
- 迁移学习(Transfer Learning)是另一种抑制因为数据不够而产生的过拟合的方法.
- 基本思想是先在大数据集上训练出一个神经网络,然后将这个神经网络的最后一层重新在小数据集上进行训练.

- 目前大部分的计算机视觉任务都采用在ImageNet等大数据集上进行训练的预训练集,然后再精调网络或重新初始化部分网络的方式进行.
第8章 深度学习软件
---8.1 Caffe,Torch,Theano,TensorFlow,Keras,PyTorch等
- CPU vs GPU:NVIDIA的GPU在深度学习中占主导地位.GPU有更多的核,因此更适合并行计算任务,比如矩阵乘法和卷积.一般建议使用NVIDIA的CUDA和CUDNN库来进行运算.
- 深度学习框架的优点:
- 轻松地构建一个庞大的计算图
- 轻松地计算计算图中的梯度
- 在GPU上高效地运行

- tensorflow中的计算一般分为两个阶段,上半部分是定义计算图,然后是运行计算图:
- 使用tf.placeholder()建立输入槽用于输入常量,tf.Variable()用于输入变量(如权重).变量可以存在计算图中,避免了每次都需要从内存中读取.变量需要声明初始化.
- 建立激活函数,预测值,损失函数的表达式来完善计算图.
- 使用optimizer=tf.train.GradientDescentOptimizier(learning_rate)来构建一个优化器.
- 使用updates=optimizer.minimize(loss)来让tensorflow更新梯度.(这两步相当于使用tf.gradients()计算反向传播中的梯度,设定learning_rate,用assign()函数来表示权重更新的表达式.注意即使我们不需要输出梯度,但也要在run的参数中加入梯度,否则tensorflow不会更新梯度.这里可以使用tf.group()的小技巧,将需要更新但不需要返回的值放入group中)
- 使用with tf.Session() as sess:来建立会话.
- 使用sess.run(tf.global_variables_initializer())来初始化全局参数.
- 向会话中加入常量的具体数据.
- 使用sess.run()来运行计算图.
- 循环sess.run,即可实现学习.
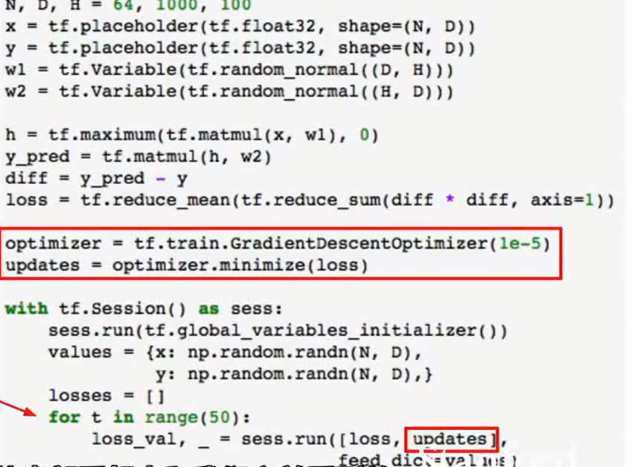
- 上例是tensorflow的一个非常简单的实例.实际上可以使用多种高级库来进行权重初始化,激活函数的选择等等操作.Keras就是其中一个著名的高级库.
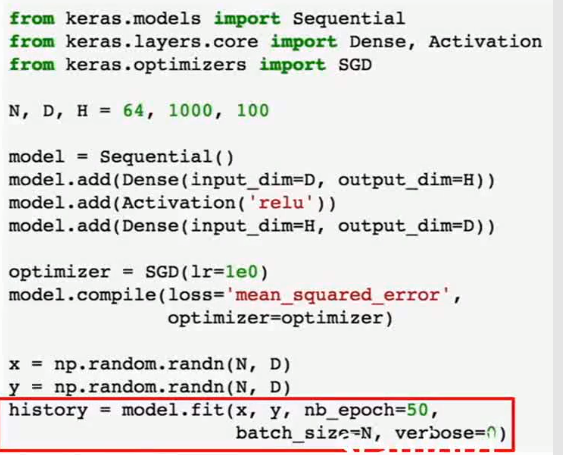
- Tensorflow采用静态计算图,而PyTorch采用动态计算图.前者的优势是可以复用很多次,并且可以在磁盘中序列化.后者的优势是可以很方便地进行条件选择和循环.
第9章 CNN架构
---9.1 AlexNet,VGG,GoogLeNet,ResNet等
- AlexNet:ImageNet比赛中第一个基于深度学习的图像识别网络框架

- ZFNet:改进了AlexNet的超参数
- VGGNet:更深的网络(16或19层),保持小的卷积核(3*3,多层小卷积核和单层大卷积核有一样的感受野,但加深了网络的深度,可以进行更多非线性操作)
- GoogleNet:更深的网络(22层),使用inception模块(对进入相同层的相同输入并行应用不同类别的滤波操作,使用零填充保持尺寸一致,瓶颈层加速计算,然后串行输出它们),没有全连接层.
- ResNet:152层的残差网络.普通网络可能出现网络更深表现却更差的情况,因为深层网络更难优化.ResNet的解决方案是让每层都学习一些所需函数的底层映射,并尝试拟合残差映射.同样会使用瓶颈层来加速运算.
第10章 循环神经网络
---10.1 RNN,LSTM,GRU
- 相比CNN的输入有着固定的尺寸,RNN可以实现一对多,多对一,多对多的模型,输入和输出都可以是可变长度.
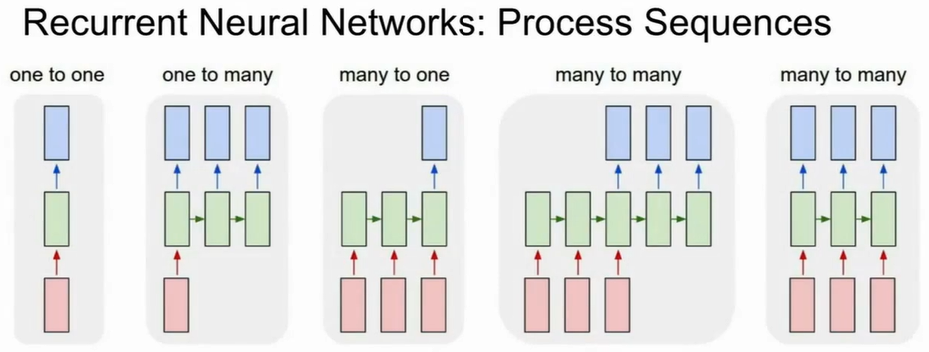
- 每个RNN网络都有一个循环核心单元,它把x作为输入传入RNN的内部隐藏态(internal hidden state),它在每次读取新的输入时更新,然后将结果反馈至模型.
- 多对多的RNN一般在每个时间步都将进行输出.注意这里的权重矩阵是不变的,最终的梯度和损失是所有时间步下计算出的梯度之和以及损失之和.
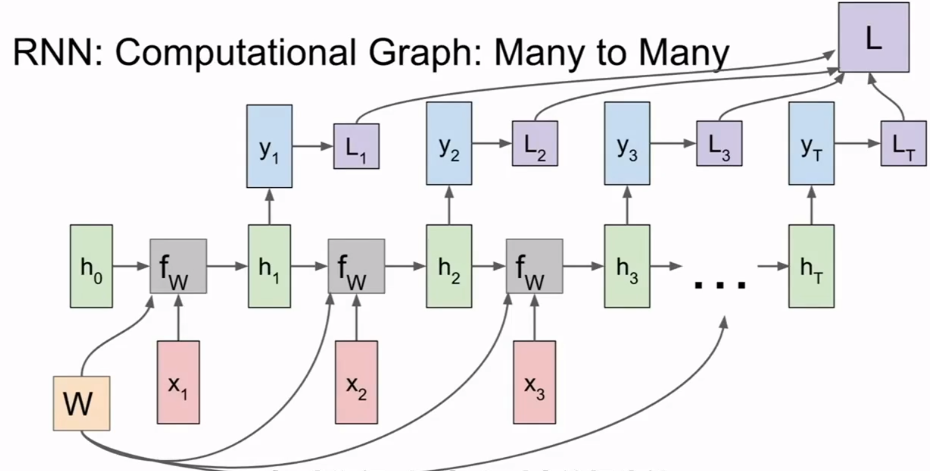
- 多对一的RNN会根据最终的隐层状态做出决策.
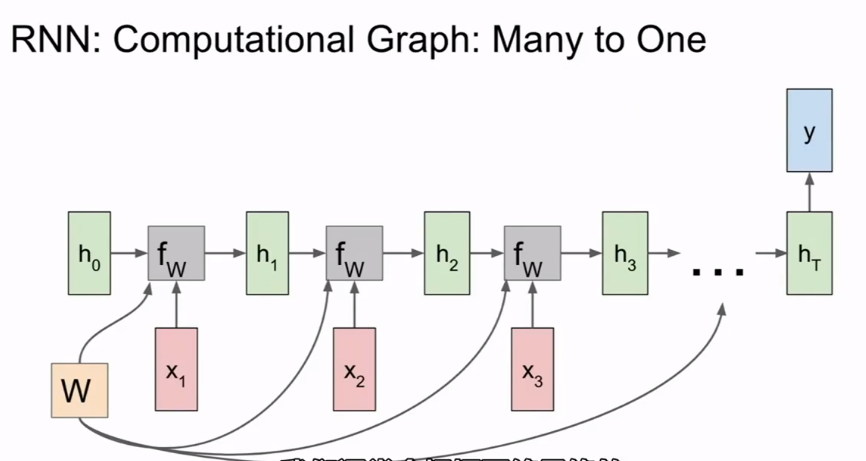
- 一对多的RNN则接收固定长的输入项,然后输出不定长的输出项.
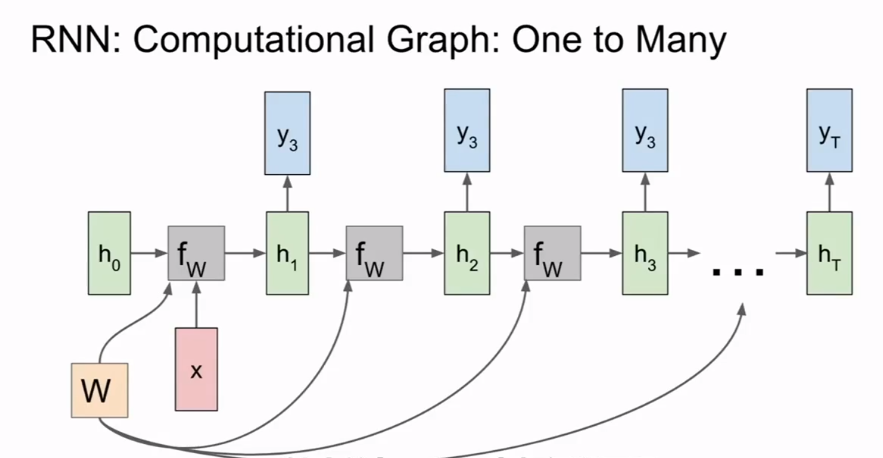
- 机器翻译之类的任务则需要一个多对一的RNN x加上一个一对多的RNN,类似编码器与解码器.
---10.2 语言模型
- 单词一般用独热编码向量表示.针对字符级的语言模型,我们可以用不同的单词去训练一个RNN网络,这样它将会学习到一个字符之后最可能出现地其他字符是什么.
- 沿时间的截断反向传播是指前向计算若干步子序列的损失值,然后沿着这个子序列反向传播,并计算梯度更新参数.
---10.3 图像标注,视觉问答,Soft attention模型
- 图像标注(Image Captioning)输入一个图像,输出自然语言的图像语义信息.它是由CNN和RNN组合而成的.COCO是最大的图像标注数据集.
- 注意力模型是指在生成与图像对应的文字时,可以允许模型将注意力放到图像的不同部分.也就是CNN在图像中每一个特殊的地方都用一个向量表示,当模型向前传递时会产生一个分布,对应图像的不同位置.
- 视觉问答(Visual Question Answering)输入一张图像和一段自然语言的提问(一般直接将图像向量和问题向量连接起来),输出一些自然语言的答案.它同样是由CNN和RNN连接而成的.
- 一般RNN在反向传播时会不断乘以相同的权重矩阵,因此容易发生梯度爆炸或梯度消失.
- 梯度截断是防止梯度爆炸的一种方法:如果梯度的L2范式大于某个阈值,就将梯度乘上阈值除以梯度的L2范式来减小梯度.
- 防止梯度消失的一种办法是换一种RNN结构.
- LSTM(长短期记忆网络)被设计用来缓解梯度消失和梯度爆炸问题.
- 每个时间步中都维持两个隐藏状态,一个是类似RNN中的隐藏状态(ht),一个是单元状态(ct).
- 将上一时间步的隐藏状态和当前的输入堆叠在一起,乘上一个权重矩阵w,得到四个不同的门向量ifog(input gate表示要接受多少新的输入信息,forget gate表示要遗忘多少之前的单元记忆,output gate表示要展现多少信息给外部,gate gate表示有多少信息要写到输入单元中).ifo门都使用sigmoid激活函数,含义是0丢弃全部,1接受全部.而g门使用tanh激活函数,含义是单元状态最多自增或自减1.
- 更新隐藏状态和单元状态.
- LSTM反向传播的优点在于f门进行的是矩阵元素相乘,而且每个f门都不同,因此不容易发生梯度爆炸或消失.这是一种利用加法连接和乘法门来管理梯度流的概念.
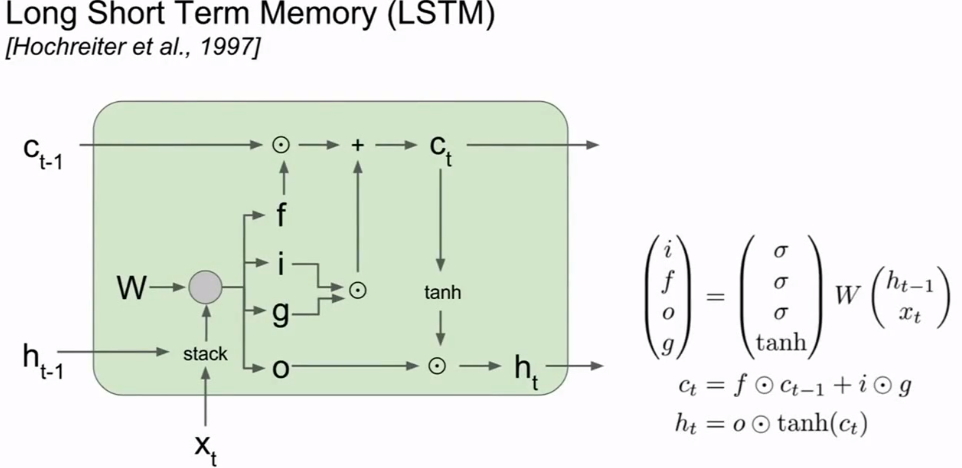
- GRU(门控循环单元)也是一种类似LSTM的结构.
第11章 图像识别和分割
---11.1 分割
- 语义分割(Semantic Segmentation)是指输入图像,并对图像中的每个像素进行分类.语义分割并不区分同类目标.
- 滑动窗口是一种方案,但复杂度太高,一般不使用.
- 全连接卷积网络和补零法(使图像尺寸不会被改变)是另一种方案,但是需要的层数太多.
- 一般会在前半部分使用卷积结合下采样(池化或跨卷积),然后在后半部分使用上采样(去池化,转置卷积,一般和池化过程对称)来恢复图像的清晰度.
---11.2 定位
- 定位(Classification plus Localization)是指预测分类,并找到一个边界包裹该物体.
- 一般用卷积网络处理输入图像,得到一些向量,并由这些向量得到分类概率.同时有另一个全连接层从这些向量输出四个数字,代表边界框坐标.有两组损失函数,一组用softmax计算分类得分,另一种计算预测坐标的准确率(如L1损失,L2损失),因此需要对它们加权求和来做反向传播.
- 一种技巧是冻结网络,分开训练这两个网络直到收敛,然后再调试整个系统.
- 这种网络同样可以用于姿态估计(Human Pose Estimation).例如用14个关节点来定义人的姿态,网络将输出14个坐标.
---11.3 识别
- 对象识别(Object Detection)是指根据输入的图像确认分类,并标注边界框.它与定位的区别是输入图像中物体的个数是不确定的,因此需要预测的参数数量也不确定.
- 滑动窗口(Sliding Window)将输入对象切分为小块,然后将它输入到卷积网络中,输入对应分类结果(如果没有分类目标,则属于背景).它的缺陷是窗口的大小和位置难以抉择.
- R-CNN采用信号处理,图像处理等方法来建立候选清单,然后将图像切分为上千个候选区域(Region Proposals),再对这些区域应用卷积网络.候选区域可能有不同的尺寸,因此在传入网络前需要将它们切分至固定尺寸.最后使用SVM分类,同时有一个用于预测边界的补偿值,所以这是一个多任务损失.它的缺陷是仍需要传入大量候选区域,并且这些候选区域是由固定算法得到的,无法学习参数.
- Fast R-CNN通过卷积网络得到图像的高分辨率特征映射,切分图像的像素,基于备选区域投影到卷积特征映射,从中提取属于备选区域的卷积块.然后用兴趣区域池化层(ROI pooling layer)来使卷积块变为固定尺寸,输入全连接层进行分类.同样有一个多任务损失,需要基于全局反向传播同时学习.它可以重复运用卷积计算,因此时间主要消耗在寻找备选区域.
- Faster R-CNN让卷积网络去预测备选区域,其余与Fast R-CNN相同.神经网络同时处理四件事:
- 备选区域是否是待识别物体
- 校正包围盒
- 最终物体识别的损失
- 最终包围盒补偿的损失
- YOLO(You Only Look Once)和SSD(Single Shot Detection)这类模型的思想是利用大型卷积网络当成回归问题处理.将输入图像分为网格,每个网格都有一系列的基本边界框.对每个网格和每个基本边界框预测边界框偏移和目标对应类别的分数.
- 物体分割(Instance Segmentation)是给定一张输入图像,预测出图像中每个物体的具体像素.
- Mask R-CNN将整张输入图像送入卷积网络和训练好的候选框生成网络,然后将候选框投射到卷积特征图上,然后产生两个分支,一个预测出分类类别分数和边界框的坐标,另一个是一个语义分割的微型网络.

第12章 可视化和理解卷积神经网络
---12.1 特征可视化,倒置,对抗样本
- 对第一层卷积层可视化,得到的特征图像一般是不同颜色,不同角度的有向边.但是对较深的卷积层可视化得到的图像则没有明显含义.
- 降维(如t-SNE,PCA)可以将高维特征映射为二维图像.
- 排除实验用平均像素遮挡图像中的一部分,然后观察图像分类概率的变化值,得到概率热力图.由此可以判断图像中的哪些部分对分类起关键作用.
- 显著图(Saliency Map)对每个像素做轻微扰动,然后计算像素对分类预测概率的影响,从而得到哪些像素是影响分类的关键部分.
- 梯度上升(Gradient Ascent)修正训练的神经网络的权重,并改变图像的某些像素,来最大化某些中间神经元和类的分值.为了让生成图像符合自然图像,需要加入正则项(图像的L2范数,高斯模糊处理).
---12.2 DeepDream和风格迁移
- 提取输入图像,通过神经网络运行到某一层,使得该层的梯度等于激活值,然后反向传播到图像.这样就放大了神经网络在图像中检测到的特征.
- 特征反演(Feature Inversion)通过神经网络运行一张图像,记录其中一个特征值,然后根据它的特征表示重构该图像.
- 纹理合成(Texture Synthesis)给定一些纹理的输入图像块,输出更大块的纹理图像.神经网络的纹理合成方法是将纹理输入神经网络,输出一个H*W的C维特征.然后选取输入特征的两个不同列得到C*C的矩阵,反映了哪些特征倾向于在空间的不同位置一起激活.
- 风格迁移(Neural Style Transfer)选用艺术画作进行纹理合成,再使用特征反演生成具有艺术风格的图像.
第13章 生成模型
---13.1 Pixel RNN/CNN
- 生成模型是指在给定训练数据下从相同的数据分布中生成新的样本.它可以解决密度估计问题.
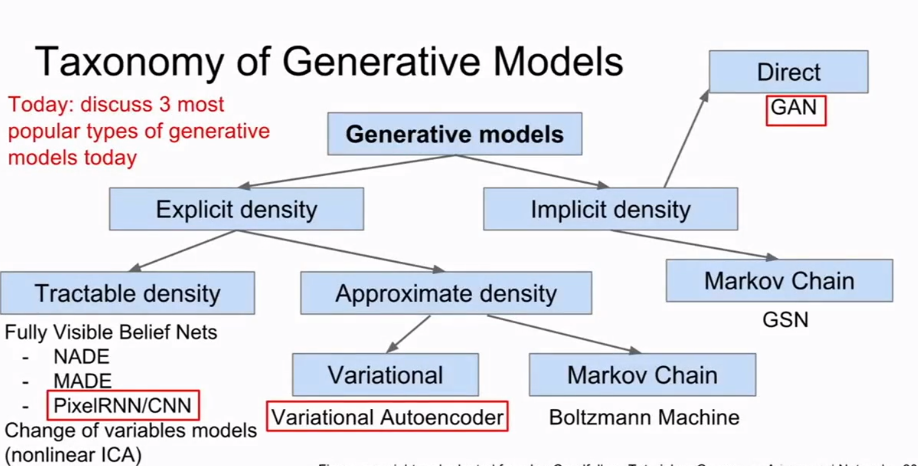
- Pixle RNN/CNN属于全可见信念网络.它对一个密度分布显式建模.使用链式法则来将似然分解为一维分布的乘积,然后只要在该定义下最大化训练数据的似然即可训练模型.

- 用神经网络来表达概率分布函数p(xi),其中xi的顺序由像素扩散的顺序决定,并传入LSTM/CNN中.训练图片的每个像素值可以充当训练标签,所以可以使用softmax函数进行训练.
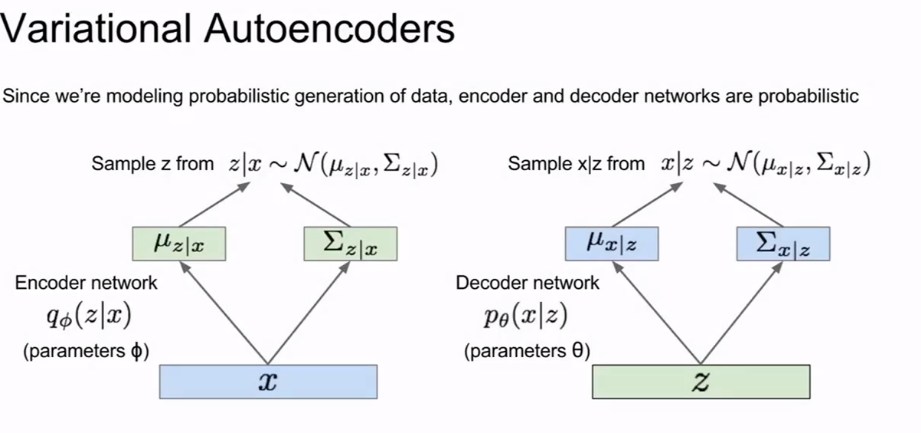
---13.2 变分自编码器
- 自动编码器(Autoencoders)是一种无监督学习方法,将输入数据通过编码器生成一些特征.编码器的映射函数一般是ReLU+CNN.生成的特征一般比输入数据的维度小,所以这是一种生成重要特征的降维方法.利用生成的特征和解码器(解卷积网络)输出与输入数据维度相同的数据,并利用L2损失函数来计算原数据和生成数据之间的误差.训练好模型后去掉解码器,就可以有一个用于生成重要特征的模型.
- 变分自编码器定义一个不易处理的密度函数,通过附加的隐变量z对其建模.它通过向自动编码器中加入随机因子从而生成新数据,自动编码器生成的特征就是隐变量z.首先选一个简单的关于z的先验分布,然后用神经网络计算条件概率p(x|z),并用解码器生成图像.直接计算数据的最大似然很难,所以使用一个额外的编码器来给出条件概率.
---13.3 生成式对抗网络
- 生成式对抗网络(Generative Adversarial Networks)采用博弈论的方法,从一个简单分布中采样(如随机噪声),然后用神经网络学习从简单分布到想要的分布的一个变换.
- 把训练过程看作两个玩家博弈的过程,生成器网络试图生成图像来骗过判别器网络,判别器网络试图把真假图片区分开来.
- 优化目标是使判别器的目标函数尽可能大,生成器的目标函数尽可能小.首先对判别器进行梯度上升,从而学习thetad来最大化.接着对生成器进行梯度下降,从而学习thetag来最小化.但这种方法的生成器目标函数效果不好,因为它的梯度和自身效果成正比,所以一开始训练会很困难.因此采用相反的想法,转而用梯度上升最大化生成器网络的目标函数的相反值,训练过程将交替进行.

第14章 深度增强学习
---14.1 策略梯度,硬注意
- 强化学习(Reinforcement Learning)有一个代理和一个环境,环境赋予代理一个状态,代理将采取行动,环境将回馈一个奖励.这一过程将一直进行下去,直到环境给出终端状态.这可以作用于游戏或棋类AI.
- 马尔可夫决策过程(Markov Decision Process)是强化学习问题的数学表达.它满足马尔可夫性:当前状态完全刻画了世界的状态.它由S(所有可能状态的集合),A(所有行动的集合),R(奖励的分布函数),P(下一个状态的转移概率分布)和γ(奖励因子)定义.它的工作方式是令初始时间步t=0,环境从初始状态分布p(s)中采样,并将一些初始状态设为0,然后开始以下循环:
- 代理选择一个动作.
- 环境从该状态和动作获得奖励.
- 抽样下一个状态.
- 代理收到奖励,进入下一状态.
- 基于上述循环,目标就是找到一个最佳策略(指定了每个状态下要采取的行动),使得奖励之和最大.因为MDP中含有随机性,所以要最大化预期奖励之和.
- 任何状态下的价值函数(Value function)都是从状态s的决策到现在的决策之后的期望累积奖励.任何状态行动组的Q值函数(Q-value function)遵守在状态s下采取行动a的期望累积奖励.
- Bellman等式意味着给定任何状态动作组s和a,这一对的价值就是回馈r加上最终进入的任何状态动作组s'和a'的价值.它的问题在于必须计算每一个状态动作组,这是一个巨大的状态空间,因此不可行.
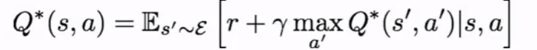
---14.2 Q-Learning,Actor-Critic算法
- 使用深度神经网络来估计动作值函数,这称作深度强化学习.
- 决策梯度是指对策略参数进行梯度评估.
- 将深度强化学习和决策梯度结合,就得到了Actor-Critic算法.
第15章 深度学习的方法及硬件
第16章 对抗样本和对抗训练
CS231n 斯坦福深度视觉识别课 学习笔记(完结)的更多相关文章
- JavaEE精英进阶课学习笔记《博学谷》
JavaEE精英进阶课学习笔记<博学谷> 第1章 亿可控系统分析与设计 学习目标 了解物联网应用领域及发展现状 能够说出亿可控的核心功能 能够画出亿可控的系统架构图 能够完成亿可控环境的准 ...
- Keras学习笔记(完结)
使用Keras中文文档学习 基本概念 Keras的核心数据结构是模型,也就是一种组织网络层的方式,最主要的是序贯模型(Sequential).创建好一个模型后就可以用add()向里面添加层.模型搭建完 ...
- 《C语言深度剖析》学习笔记----C语言中的符号
本节主要讲C语言中的各种符号,包括注释符.单引号双信号以及逻辑运算符等. 一.注释符 注释符号和注释在程序的预编译期就已经被解决了,在预编译期间,编译器会将注释符号和注释符号之间的部分简单的替换成为空 ...
- Linux第二节课学习笔记
虚拟机不一定要安装12版本,但仅有12版本支持RHCE模拟考试环境,激活码可以百度. 在创建新的虚拟机过程中,安装客户机操作系统时需要选择稍后安装操作系统,否则会默认最小化安装导致后面课上很多命令不能 ...
- 学通javaweb 24堂课 学习笔记
17.01:简单配置控制器 1.一个controller protected ModelAndView handleRequestInternal(HttpServletRequest request ...
- Linux第十一节课学习笔记
区域就是firewalld预先准备了几套防火墙策略集合(策略模板),用户可以根据生产场景的不同而选择合适的策略集合,从而实现防火墙策略之间的快速切换. RUNTIME模式:当前生效,重启失效:PERM ...
- Linux第十节课学习笔记
部署LVM三步: 1.pv:使设备支持LVM: 2.vg:对支持LVM的设备进行整合: 3.lv:将整合的空间进行切割. 每个基本单元PE的大小为4M,分配空间必须是4M的整数倍.可以容量或基本单元个 ...
- Linux第九节课学习笔记
fdisk可添加.删除.转换分区. 创建主分区:n-p-w:扩展分区:n-e:逻辑分区:n-l. SWAP分区专用格式化命令mkswap,专用挂载命令swapon. 磁盘容量配额中,硬限制必须,软限制 ...
- Linux第八节课学习笔记
su命令可以切换用户身份,一般不用,而是用sudo. visudo命令中可执行命令列表不用ALL,我们可以先使用whereis命令找出命令所对应的保存路径,然后把配置文件第99行的用户权限参数修改成对 ...
随机推荐
- Codeforces Beta Round #95 (Div. 2) C. The World is a Theatre 组合数学
C. The World is a Theatre There are n boys and m girls attending a theatre club. To set a play " ...
- pandas 处理数据中NaN数据
使用dropna()函数去掉NaN的行或列 import pandas as pd import pickle import numpy as np dates = pd.date_range() d ...
- Could not find a package configuration file provided by 'ecl_threads' ,.................couldn't find required component 'ecl_threads'
sudo apt-get install ros-kinetic-ecl-threads
- ORACLE 多表查询优化收集整理
搞WEB的离不开数据库,在一个层面上,对数据库的熟练程度决定了很多的事情. 本文就大家都纠结的ORACLE多表查询的性能问题给出一系列个优化方法,那这些都是项目中长期用到的,所以很熟,很熟,已经成为习 ...
- 设置网站URL启动
当新建一个MVC WEB程序 当你打开一个视图按F5运行 这时候并且不能政策运行会出现与个错误 无法找到资源. 这时候站点的默认设置是 把这个个默认设置更改成 红色框框的地方为修改点 你以为这样就完了 ...
- MongoDB(课时15 数据排序)
3.4.2.10 数据排序 在MongoDB里数据排序操作使用“sort()”函数,在进行排序的时候可以有两个顺序:升序(1),降序(-1). 范例:排序 db.students.find().sor ...
- django字段的参数
所有的模型字段都可以接收一定数量的参数,比如CharField至少需要一个max_length参数.下面的这些参数是所有字段都可以使用的,并且是可选的. null 该值为True时,Django在数据 ...
- Spring web flow的意义
为什么要使用Spring web flow呢? 这里需要强调的一点就是,但凡一个技术的出现和流行,必有其适用的环境和存在的意义. Spring web flow加强了中央集权,这个该怎么理解呢?以往我 ...
- ES curl bulk 导入数据
比如我们现在有这样一个文件,data.json: { " } } { "field1" : "value1" } 它的第一行定义了_index,_ty ...
- node -- hapi 学习
node learning 学习node,是为了后续项目可以正常开展,现在写个项目,若不是连接后台,请求数据,一切都不叫着项目了.正好借助掘金的小册,来推进学习 学习资料 YouTube 1 掘金 h ...