序列比对之Biostrings包
基本概念
Biostrings包很重要的3个功能是进行Pairwise sequence alignment 和Multiple sequence alignment及 Pattern finding in a sequence
序列比对一般有2个过程:
1)构建计分矩阵公式(the scoring matrix formulation)
2)比对(alignment itself)
global alignment methods (全局比对):align every residue in the sequences ,例如Needleman-Wunsch algorithm.
local alignment technique(局部比对): align regions of high similarity in the sequences,例如Smith-Waterman algorithm
安装
if("Biostrings" %in% rownames(installed.packages()) == FALSE) {source("http://bioconductor.org/biocLite.R");biocLite("Biostrings")}
suppressMessages(library(Biostrings))
ls('package:Biostrings')
----------------Pairwise sequence alignment---------------
步骤:首先构建罚分规则,然后按照规则进行比对。用pairwiseAlignment()函数
举例1:核酸序列
(myScoringMat <- nucleotideSubstitutionMatrix(match = 1, mismatch = -1, baseOnly = TRUE))#构建罚分规则
gapOpen <- 2 #gap分为2
gapExtend <- 1 #延伸gap分为1 sequence1 <- "GAATTCGGCTA" #序列1
sequence2 <- "GATTACCTA" #序列2
myAlignment <- pairwiseAlignment(sequence1, sequence2,
substitutionMatrix = myScoringMat, gapOpening = gapOpen,
gapExtension = gapExtend, type="global", scoreOnly = FALSE) #进行比对
myAlignment

举例2:对蛋白序列进行比对
蛋白比对会更复杂,因此模型更多,
data(package="Biostrings") #查看所有数据集
data(BLOSUM62) #这里选择BLOSUM62数据
subMat <- "BLOSUM62" #赋值
gapOpen <- 2
gapExtend <- 1
sequence1 <- "PAWHEAE"
sequence2 <- "HEAGAWGHE"
myAlignProt <- pairwiseAlignment(sequence1, sequence2,
substitutionMatrix = subMat, gapOpening = gapOpen, gapExtension =
gapExtend, type="global", scoreOnly = FALSE) #全局比对
myAlignProt2 <- pairwiseAlignment(sequence1, sequence2,
substitutionMatrix = subMat, gapOpening = gapOpen, gapExtension =
gapExtend, type="local",scoreOnly = FALSE) ##局部比对
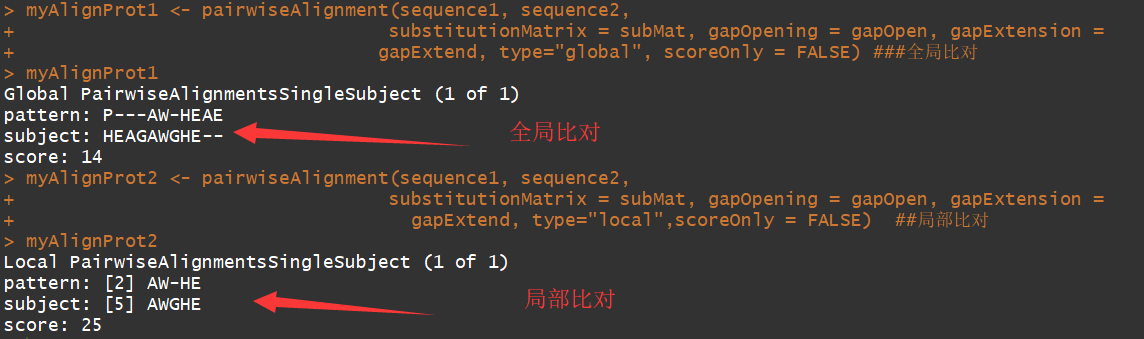
可以看到局部比对返回的是,高度相似的序列部分.
3)可视化,对于序列可以用最经典的对角线来可视化(以人和黑猩猩的hemoglobin beta为例)
library(seqinr) # 为了读取fasta序列
myseq <- read.fasta(file = "F:/R/Bioconductor/biostrings/prtein_example_seq.fas")
dotPlot(myseq[[1]], myseq[[2]], col=c("white", "red"), xlab="Human", ylab="Chimpanzee")

##########Multiple sequence alignment############
一般多序列比对可以用于进化分析
install.packages("muscle") #需要安装该包,因为该包在我的版本上没法安装,所以这里就不讲了
library(muscle)
######Phylogenetic analysis and tree plotting########
这里先不做分析
#########blast格式的解析######
install.packages("RFLPtools",dependencies=TRUE)
library(RFLPtools)
data(BLASTdata) #先查看数据集了解一下相关数据格式情况
head(BLASTdata)
colnames(BLASTdata)
DIR <- system.file("extdata", package = "RFLPtools") #用自带数据集
MyFile <- file.path(DIR, "BLASTexample.txt")
MyBLAST <- read.blast(file = MyFile)
mySimMat <- simMatrix(MyBLAST) #可以根据blast结果用来生成相似性矩阵,太厉害了
#########Pattern finding in a sequence######
library(Biostrings)
mynucleotide <- DNAString("aacataatgcagtagaacccatgagccc")
matchPattern(DNAString("ATG"), mynucleotide) #示例1
matchPattern("TAA", mynucleotide) #示例2
##以下函数可以用来寻找orf(需要修改)
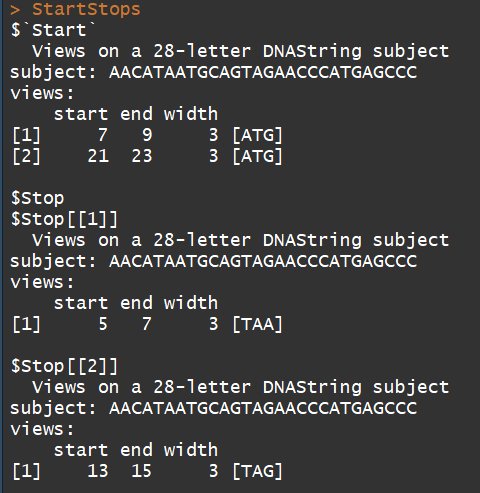
myCodonFinder <- function(sequence){
startCodon = DNAString("ATG") # 指定起始密码子
stopCodons = list("TAA", "TAG", "TGA") # 指定终止密码子
codonPosition = list() #initialize the output to be returned as a list
codonPosition$Start = matchPattern(startCodon, sequence) # search start codons
x=list()
for(i in 1:3){ # iterate over all stop codons
x[[i]]= matchPattern(DNAString(stopCodons[[i]]), sequence)
codonPosition$Stop=x
}
return(codonPosition) # returns results
}
StartStops <- myCodonFinder(mynucleotide)
序列比对之Biostrings包的更多相关文章
- Python_序列与映射的解包操作
解包就是把序列或映射中每个元素单独提取出来,序列解包的一种简单用法就是把首个或前几个元素与后面几个元素分别提取出来,例如: first, seconde, *rest = sequence 如果seq ...
- Python 序列与映射的解包操作
解包就是把序列或映射中每个元素单独提取出来,序列解包的一种简单用法就是把首个或前几个元素与后面几个元素分别提取出来,例如: first, seconde, *rest = sequence 如果seq ...
- Python 序列与映射的解包操作-乾颐堂
解包就是把序列或映射中每个元素单独提取出来,序列解包的一种简单用法就是把首个或前几个元素与后面几个元素分别提取出来,例如: first, seconde, *rest = sequence 如果seq ...
- python基础之打/解包及运算符与控制流程
python基础之打/解包及运算符与控制流程 python中的解压缩(即序列类型的打包和解包) python提供了两个设计元祖和其他序列类型的处理的便利,也就是自动打包与自动解包功能,比如: data ...
- Oracle学习笔记一 初识Oracle
数据库简介 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库.SQL 是 Structured Query Language(结构化查询语言)的首字母缩写词. 定义 数据库,简单来 ...
- Makefile <网络转载>
陈皓 (CSDN)概述——什 么是makefile?或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了这个工作,但我觉得要作一个好的和 professional的 ...
- oracle 体系结构
oracle 体系结构 数据库的体系结构是指数据库的组成.工作过程与原理,以及数据在数据库中的组织与管理机制. 1. oracle工作原理: 1).在数据库服务器上启动Oracle实例:2).应用程序 ...
- Navicat for Oracle实现连接Oracle
不知道为什么,从一开始,我就不喜欢Oracle,名字好听,功能强大,但总感觉"高不可攀";或许是因为我觉得其他的数据库就可以解决数据问题,不太了解Oracle的优势:而且它长得也不 ...
- 三、oracle 体系结构
1.oracle内存由SGA+PGA所构成 2.oracle数据库体系结构数据库的体系结构是指数据库的组成.工作过程与原理,以及数据在数据库中的组织与管理机制. oracle工作原理: 1).在数据库 ...
随机推荐
- ios之runloop笔记
网上关于runloop的文章不计其数,再此,贴个自认为讲的比较简单明了的文章 http://www.jianshu.com/p/536184bfd163 个人理解: ios的runloop应该是类似于 ...
- 未来的趋势发展 802.11v网络协议解析
目前的无线网络中,一个基站通常与拥有最强信号的接入点联系在一起.但是,这个接入点也许过载了.在802.11v标准中,包括了一个指令,接入点能够使用这个指令要求一个基站报告它支持的无线电信道.传输的功率 ...
- 学习URL地址(待整理)
编程开发教程:http://www.runoob.com/ ElasticSearch教程:https://es.xiaoleilu.com/index.html 设计模式:http://www.cn ...
- 向Nexus仓库推送/使用各种组件
1.Nuget仓库 使用NuGetPackageExplorer打包制作自己的nupkg https://github.com/NuGetPackageExplorer/NuGetPackageExp ...
- 解决WPF两个图片控件显示相同图片因线程占用,其中一个显示不全的问题
在做项目的过程中遇到这样一个问题,下面提出一种解决方法,主要思想是图片的Copy,如还有其他方法,欢迎交流. 在前端图片控件绑定显示时,使用转换器进行转义绑定 (1)转换器: public cla ...
- 【POJ】2420 A Star not a Tree?(模拟退火)
题目 传送门:QWQ 分析 军训完状态不好QwQ,做不动难题,于是就学了下模拟退火. 之前一直以为是个非常nb的东西,主要原因可能是差不多省选前我试着学一下但是根本看不懂? 骗分利器,但据说由于调参困 ...
- C# webbrowser实现百度知道团队邀请助手!
[百度知道团队邀请助手] 是您快速提高百度知道团队成员数和团队排名的利器! 主要功能: 1.运用C#自带的webbrowser自动登录百度: 2.自动采集请在C#.Net分类排名下的所有用户,邀请这些 ...
- Spark数据本地性
1.文件系统本地性 第一次运行时数据不在内存中,需要从HDFS上取,任务最好运行在数据所在的节点上: 2.内存本地性 第二次运行,数据已经在内存中,所有任务最好运行在该数据所在内存的节点上: 3.LR ...
- 为solr增加用户验证
添加此功能主要是为了增加solr服务器的安全性,不能随便让人访问. 1. 在tomcat的F:\Tomcat 6.0.26_solr\conf\tomcat-users.xml添加用户角色并 ...
- UVA196
#include<stdio.h> #include<iostream> #include <strstream> using namespace std; #de ...