BM25 调参调研
1. 搜索 ES 计算文本相似度用的 BM25,参数默认,不适合电商场景,可调整 BM25 参数使其适用于电商短文本场景
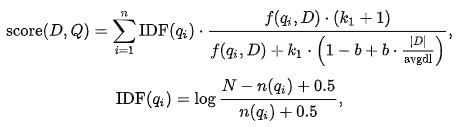
2. k1、b、tf、L、tfScore 的关系如下图红框内所示(注:这里的 tf 即上式中的 f(qi,D))。

3. k1 用来控制公式对词项频率 tf 的敏感程度。((k1 + 1) * tf) / (k1 + tf) 的上限是 (k1+1),也即饱和值。当 k1=0 时,不管 tf 如何变化,BM25 后一项都是 1;随着 k1 不断增大,虽然上限值依然是 (k1+1),但到达饱和的 tf 值也会越大;当 k1 无限大时,BM25 后一项就是原始的词项频率。一句话,k1 就是衡量高频 term 所在文档和低频 term 所在文档的相关性差异,在我们的场景下,term 频次并不重要,该值可以设小。ES 中默认 k1=1.2,可调整为 k1=0.3。
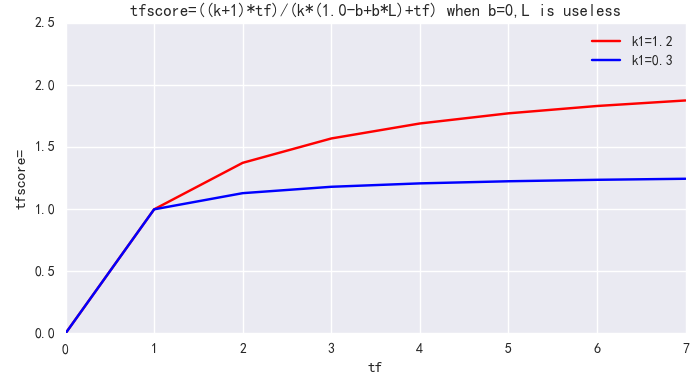
4. b 用来控制文档长度 L 对权值的惩罚程度。b=0,则文档长度对权值无影响,b=1,则文档长度对权值达到完全的惩罚作用。ES 中默认 b=0.75,可调整为 b=0.1。
5. IDF 一项无参可调,这里只说明一点,公式中当 n(q) 超过 N/2 非常大时,IDF 有得到负值的可能,Lucene’s BM25 实现时对 log 中的除式做了加 1 处理,Math.log(1 + (docCount - docFreq + 0.5D)/(docFreq + 0.5D)),使其永远大于 1,取 log 后就不会得到负值。
参考资料:
- https://www.elastic.co/guide/en/elasticsearch/reference/current/index-modules-similarity.html
- https://en.wikipedia.org/wiki/Okapi_BM25
- https://www.elastic.co/guide/en/elasticsearch/guide/current/pluggable-similarites.html
- https://www.elastic.co/guide/en/elasticsearch/guide/current/practical-scoring-function.html
- http://opensourceconnections.com/blog/2015/10/16/bm25-the-next-generation-of-lucene-relevation/
- 《信息检索导论》p160
BM25 调参调研的更多相关文章
- scikit-learn随机森林调参小结
在Bagging与随机森林算法原理小结中,我们对随机森林(Random Forest, 以下简称RF)的原理做了总结.本文就从实践的角度对RF做一个总结.重点讲述scikit-learn中RF的调参注 ...
- scikit-learn 梯度提升树(GBDT)调参小结
在梯度提升树(GBDT)原理小结中,我们对GBDT的原理做了总结,本文我们就从scikit-learn里GBDT的类库使用方法作一个总结,主要会关注调参中的一些要点. 1. scikit-learn ...
- word2vec参数调整 及lda调参
一.word2vec调参 ./word2vec -train resultbig.txt -output vectors.bin -cbow 0 -size 200 -window 5 -neg ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- 基于pytorch的CNN、LSTM神经网络模型调参小结
(Demo) 这是最近两个月来的一个小总结,实现的demo已经上传github,里面包含了CNN.LSTM.BiLSTM.GRU以及CNN与LSTM.BiLSTM的结合还有多层多通道CNN.LSTM. ...
- 漫谈PID——实现与调参
闲话: 作为一个控制专业的学生,说起PID,真是让我又爱又恨.甚至有时候会觉得我可能这辈子都学不会pid了,但是经过一段时间的反复琢磨,pid也不是很复杂.所以在看懂pid的基础上,写下这篇文章,方便 ...
- hyperopt自动调参
hyperopt自动调参 在传统机器学习和深度学习领域经常需要调参,调参有些是通过通过对数据和算法的理解进行的,这当然是上上策,但还有相当一部分属于"黑盒" hyperopt可以帮 ...
- 调参必备---GridSearch网格搜索
什么是Grid Search 网格搜索? Grid Search:一种调参手段:穷举搜索:在所有候选的参数选择中,通过循环遍历,尝试每一种可能性,表现最好的参数就是最终的结果.其原理就像是在数组里找最 ...
- random froest 调参
https://blog.csdn.net/wf592523813/article/details/86382037 https://blog.csdn.net/xiayto/article/deta ...
随机推荐
- angular.element 动态添加和删除元素
addClass()-为每个匹配的元素添加指定的样式类名after()-在匹配元素集合中的每个元素后面插入参数所指定的内容,作为其兄弟节点append()-在每个匹配元素里面的末尾处插入参数内容att ...
- [LeetCode] 133. Clone Graph_ Medium tag: BFS, DFS
Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. OJ's ...
- java实现Comparable接口和Comparator接口,并重写compareTo方法和compare方法
原文地址https://segmentfault.com/a/1190000005738975 实体类:java.lang.Comparable(接口) + comareTo(重写方法),业务排序类 ...
- 软件包管理:源码包管理-源码包与RPM包的区别
RPM会安装在默认位置,源码包会安装在指定位置. 绝大多数ROM包遵循此规范.写软件包是就固定好了. 主要影响体现在对服务的管理方法,服务的管理分三种:启动,重启动,停止. 启动时使用绝对路径来启动. ...
- python直接赋值、浅拷贝和深拷贝
# 解: # import copy # names1=['Amir','Barry','Cgakes','Dao',[11,22,33]] # names2=names1#直接赋值,指向同一个对象 ...
- 001-Two Sum
Given an array of integers, return indices of the two numbers such that they add up to a specific ta ...
- Object-C-NSFileManager
+(NSFileManager *)defaultManager;//获得文件管理对象 -(BOOL)createFileAtPath:(NSString *)path contents:(NSDat ...
- 结合ajax 的表单验证
浪费了我两天的时间 我也是醉了 html 结构 <!-- 密码修改 --> <div class="modal fade" id="operatePa ...
- 自动化持续集成Jenkins
自动化持续集成Jenkins 使用Jenkins配置自动化构建http://blog.csdn.net/littlechang/article/details/8642149 Jenkins入门总结h ...
- Python Web学习笔记之并发和并行的区别和实现
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行.你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发.你吃饭吃到一半,电话来了,你一边打 ...