Impala和Hive的关系(详解)
Impala和Hive的关系
Impala是基于Hive的大数据实时分析查询引擎,直接使用Hive的元数据库Metadata,意味着impala元数据都存储在Hive的metastore中。并且impala兼容Hive的sql解析,实现了Hive的SQL语义的子集,功能还在不断的完善中。
与Hive的关系
Impala 与Hive都是构建在Hadoop之上的数据查询工具各有不同的侧重适应面,但从客户端使用来看Impala与Hive有很多的共同之处,如数据表元数 据、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储资源池等。Impala与Hive在Hadoop中的关系如下图所示。Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数 据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
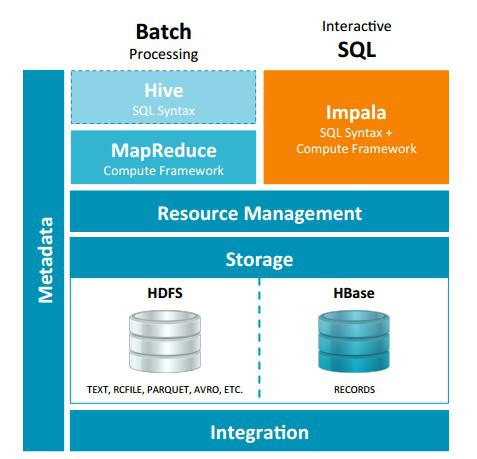
Impala相对于Hive所使用的优化技术
- 1、没有使用 MapReduce进行并行计算,虽然MapReduce是非常好的并行计算框架,但它更多的面向批处理模式,而不是面向交互式的SQL执行。与 MapReduce相比:Impala把整个查询分成一执行计划树,而不是一连串的MapReduce任务,在分发执行计划后,Impala使用拉式获取 数据的方式获取结果,把结果数据组成按执行树流式传递汇集,减少的了把中间结果写入磁盘的步骤,再从磁盘读取数据的开销。Impala使用服务的方式避免 每次执行查询都需要启动的开销,即相比Hive没了MapReduce启动时间。
- 2、使用LLVM产生运行代码,针对特定查询生成特定代码,同时使用Inline的方式减少函数调用的开销,加快执行效率。
- 3、充分利用可用的硬件指令(SSE4.2)。
- 4、更好的IO调度,Impala知道数据块所在的磁盘位置能够更好的利用多磁盘的优势,同时Impala支持直接数据块读取和本地代码计算checksum。
- 5、通过选择合适的数据存储格式可以得到最好的性能(Impala支持多种存储格式)。
- 6、最大使用内存,中间结果不写磁盘,及时通过网络以stream的方式传递。
Impala与Hive的异同
- 数据存储:使用相同的存储数据池都支持把数据存储于HDFS, HBase。
- 元数据:两者使用相同的元数据。
- SQL解释处理:比较相似都是通过词法分析生成执行计划。
执行计划:
- Hive: 依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…的模型。如果一个Query会 被编译成多轮MapReduce,则会有更多的写中间结果。由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
- Impala: 把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询,而不用像Hive那样把它组合成管道型的 map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
数据流:
- Hive: 采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
- Impala: 采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
内存使用:
- Hive: 在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
- Impala: 在遇到内存放不下数据时,当前版本1.0.1是直接返回错误,而不会利用外存,以后版本应该会进行改进。这使用得Impala目前处理Query会受到一 定的限制,最好还是与Hive配合使用。Impala在多个阶段之间利用网络传输数据,在执行过程不会有写磁盘的操作(insert除外)。
调度:
- Hive: 任务调度依赖于Hadoop的调度策略。
- Impala: 调度由自己完成,目前只有一种调度器simple-schedule,它会尽量满足数据的局部性,扫描数据的进程尽量靠近数据本身所在的物理机器。调度器 目前还比较简单,在SimpleScheduler::GetBackend中可以看到,现在还没有考虑负载,网络IO状况等因素进行调度。但目前 Impala已经有对执行过程的性能统计分析,应该以后版本会利用这些统计信息进行调度吧。
容错:
- Hive: 依赖于Hadoop的容错能力。
- Impala: 在查询过程中,没有容错逻辑,如果在执行过程中发生故障,则直接返回错误(这与Impala的设计有关,因为Impala定位于实时查询,一次查询失败, 再查一次就好了,再查一次的成本很低)。但从整体来看,Impala是能很好的容错,所有的Impalad是对等的结构,用户可以向任何一个 Impalad提交查询,如果一个Impalad失效,其上正在运行的所有Query都将失败,但用户可以重新提交查询由其它Impalad代替执行,不 会影响服务。对于State Store目前只有一个,但当State Store失效,也不会影响服务,每个Impalad都缓存了State Store的信息,只是不能再更新集群状态,有可能会把执行任务分配给已经失效的Impalad执行,导致本次Query失败。
适用面:
- Hive: 复杂的批处理查询任务,数据转换任务。
- Impala:实时数据分析,因为不支持UDF,能处理的问题域有一定的限制,与Hive配合使用,对Hive的结果数据集进行实时分析。
Impala 与Hive都是构建在Hadoop之上的数据查询工具,但是各有不同侧重,那么我们为什么要同时使用这两个工具呢?单独使用Hive或者Impala不可以吗?
一、介绍Impala和Hive
(1)Impala和Hive都是提供对HDFS/Hbase数据进行SQL查询的工具,Hive会转换成MapReduce,借助于YARN进行调度从而实现对HDFS的数据的访问,而Impala直接对HDFS进行数据查询。但是他们都是提供如下的标准SQL语句,在机身里运行。

(2)Apache Hive是MapReduce的高级抽象,使用HiveQL,Hive可以生成运行在Hadoop集群的MapReduce或Spark作业。Hive最初由Facebook大约在2007年开发,现在是Apache的开源项目。
Apache Impala是高性能的专用SQL引擎,使用Impala SQL,因为Impala无需借助任何的框架,直接实现对数据块的查询,所以查询延迟毫秒级。Impala受到Google的Dremel项目启发,2012年由Cloudera开发,现在是Apache开源项目。
二、Impala和Hive有什么不同?
(1)Hive有很多的特性:
1、对复杂数据类型(比如arrays和maps)和窗口分析更广泛的支持
2、高扩展性
3、通常用于批处理
(2)Impala更快
1、专业的SQL引擎,提供了5x到50x更好的性能
2、理想的交互式查询和数据分析工具
3、更多的特性正在添加进来
三、高级概述:

四、为什么要使用Hive和Impala?
1、为数据分析人员带来了海量数据分析能力,不需要软件开发经验,运用已掌握的SQL知识进行数据的分析。
2、比直接写MapReduce或Spark具有更好的生产力,5行HiveQL/Impala SQL等同于200行或更多的Java代码。
3、提供了与其他系统良好的互操作性,比如通过Java和外部脚本扩展,而且很多商业智能工具支持Hive和Impala。
五、Hive和Impala使用案例
(1)日志文件分析
日志是普遍的数据类型,是当下大数据时代重要的数据源,结构不固定,可以通过Flume和kafka将日志采集放到HDFS,然后分析日志的结构,根据日志的分隔符去建立一个表,接下来运用Hive和Impala 进行数据的分析。例如:

(2)情感分析
很多组织使用Hive或Impala来分析社交媒体覆盖情况。例如:

(3)商业智能
很多领先的BI工具支持Hive和Impala

Impala和Hive的关系(详解)的更多相关文章
- slf4j log4j logback关系详解和相关用法
slf4j log4j logback关系详解和相关用法 写java也有一段时间了,一直都有用slf4j log4j输出日志的习惯.但是始终都是抱着"拿来主义"的态度,复制粘贴下配 ...
- 【转】UML类图与类的关系详解
UML类图与类的关系详解 2011-04-21 来源:网络 在画类图的时候,理清类和类之间的关系是重点.类的关系有泛化(Generalization).实现(Realization).依赖(D ...
- UML类图与类的关系详解
摘自:http://www.uml.org.cn/oobject/201104212.asp UML类图与类的关系详解 2011-04-21 来源:网络 在画类图的时候,理清类和类之间的关系是重点.类 ...
- Hibernate中的多对多关系详解(3)
前面两节我们讲到了一对一的关系,一对多,多对一的关系,相对来说,是比较简单的,但有时,我们也会遇到多对多的关系,比如说:角色与权限的关系,就是典型的多对多的关系,因此,我有必要对这种关系详解,以便大家 ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- 大数据Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
微信公众号[程序员江湖] 作者黄小斜,斜杠青年,某985硕士,阿里 Java 研发工程师,于 2018 年秋招拿到 BAT 头条.网易.滴滴等 8 个大厂 offer,目前致力于分享这几年的学习经验. ...
- Hadoop核心架构HDFS+MapReduce+Hbase+Hive内部机理详解
转自:http://blog.csdn.net/iamdll/article/details/20998035 分类: 分布式 2014-03-11 10:31 156人阅读 评论(0) 收藏 举报 ...
- slf4j log4j logback log4j2关系详解和相关用法
来源:slf4j log4j logback关系详解和相关用法https://www.cnblogs.com/Sinte-Beuve/p/5758971.html The Simple Logging ...
- Hive的配置详解和日常维护
Hive的配置详解和日常维护 一.Hive的参数配置详解 1>.mapred.reduce.tasks 默认为-1.指定Hive作业的reduce task个数,如果保留默认值,则Hive 自 ...
随机推荐
- android极光杀掉程序收不到通知
http://docs.jpush.io/guideline/faq/#android 第三方系统收不到推送的消息 由于第三方 ROM 的管理软件需要用户手动操作 小米[MIUI] 自启动管理:需要把 ...
- 安装和卸载windows服务程序
安装window服务 安装命令:InstallUtil.exe MyServiceLog.exe InstallUtil存在路径为:C:\WINDOWS\Microsoft.NET\Framework ...
- 伪随机数生成算法-梅森旋转(Mersenne Twister/MT)
今天主要是来研究梅森旋转算法,它是用来产生伪随机数的,实际上产生伪随机数的方法有很多种,比如线性同余法, 平方取中法等等.但是这些方法产生的随机数质量往往不是很高,而今天介绍的梅森旋转算法可以产生高质 ...
- jqueryui和easyui区别
jQuery自带的一个可选UI库,但是非常可惜,一些关键的组件没有包含进去,如TreeView, DataGrid,还需要寻找第三方的插件. EasyUI是某公司开发的一套对私免费,对公收费的UI库, ...
- CodeForces 832B Petya and Exam
B. Petya and Exam time limit per test 2 seconds memory limit per test 256 megabytes input standard i ...
- opencv学习笔记——时间计算函数getTickCount()和getTickFrequency()
cv::getTickCount()可以用来测量一段代码的运行时间,这个函数返回从上次开机算起的时钟周期数. 由于我们需要的是某个代码段运行的毫秒数,因此还需要另一个函数cv::getTickFreq ...
- 2018牛客网暑期ACM多校训练营(第二场) J - farm - [随机数哈希+二维树状数组]
题目链接:https://www.nowcoder.com/acm/contest/140/J 时间限制:C/C++ 4秒,其他语言8秒 空间限制:C/C++ 262144K,其他语言524288K ...
- PAT-GPLT L2-027 - 名人堂与代金券 - [简单模拟]
题目链接:https://www.patest.cn/contests/gplt/L2-027 对于在中国大学MOOC(http://www.icourse163.org/)学习“数据结构”课程的学生 ...
- PDB、PD、PMP、RTB哪个更好?为品牌主解锁程序化购买的选择技巧
PDB.PD.PMP.RTB哪个更好?为品牌主解锁程序化购买的选择技巧 https://baijiahao.baidu.com/s?id=1620277114893208111&wfr=spi ...
- Crontab '2>&1 &' 含义
Crontab '2>&1 &' 含义 - dosttyy - 博客园 https://www.cnblogs.com/dosttyy/p/4810026.html