Inception系列
从GoogLeNet的Inceptionv1开始,发展了众多inception,如inception v2、v3、v4与Inception-ResNet-V2。
故事还是要从inception v1开始说起。
Inception v1
相比于GoogLeNet之前的众多卷积神经网络而言,inception v1采用在同一层中提取不同的特征(使用不同尺寸的卷积核),并提出了卷积核的并行合并(也称为Bottleneck layer),如下图
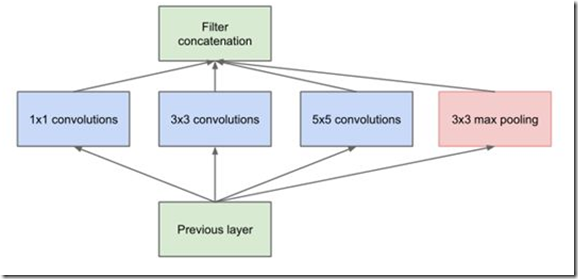
这样的结构主要有以下改进:
- 一层block就包含1x1卷积,3x3卷积,5x5卷积,3x3池化(使用这样的尺寸不是必需的,可以根据需要进行调整)。这样,网络中每一层都能学习到“稀疏”(3x3、5x5)或“不稀疏”(1x1)的特征,既增加了网络的宽度,也增加了网络对尺度的适应性;
- 通过deep concat在每个block后合成特征,获得非线性属性。
虽然这样提高了性能,但是网络的计算量实在是太大了,因此GoogLeNet借鉴了Network-in-Network的思想,使用1x1的卷积核实现降维操作,以此来减小网络的参数量(这里就不对两种结构的参数量进行定量比较了),如图所示。
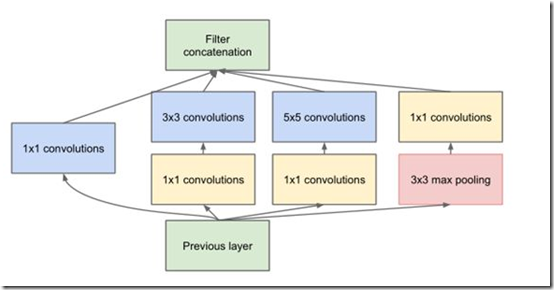
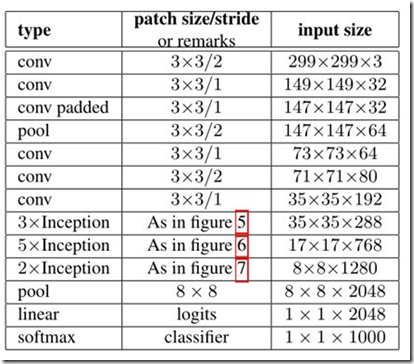
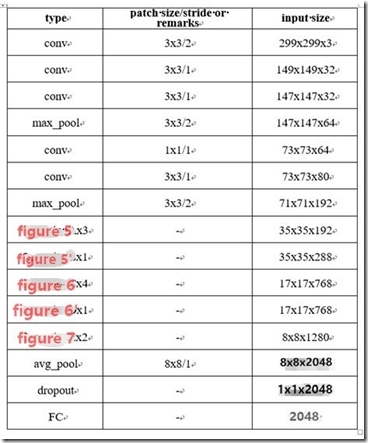
最后实现的inception v1网络是上图结构的顺序连接,其中不同inception模块之间使用2x2的最大池化进行下采样,如表所示。
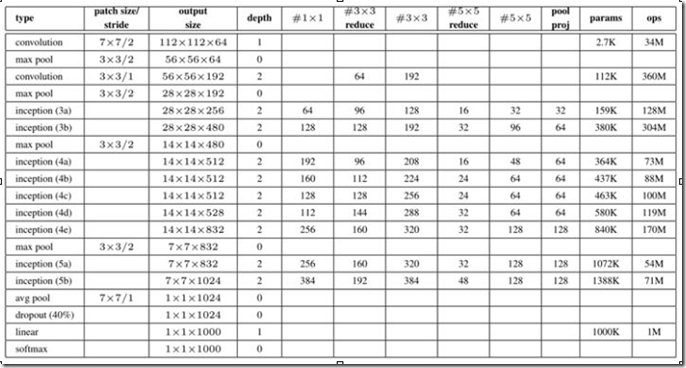
如表所示,实现的网络仍有一层全连接层,该层的设置是为了迁移学习的实现(下同)。
在之前的网络中,最后都有全连接层,经实验证明,全连接层并不是很必要的,因为可能会带来以下三点不便:
- 网络的输入需要固定
- 参数量多
- 易发生过拟合
实验证明,将其替换为平均池化层(或者1x1卷积层)不仅不影响精度,还可以减少。
Inception v2
在V1的基础之上主要做了以下改进:
(1) 使用BN层,将每一层的输出都规范化到一个N(0,1)的正态分布,这将有助于训练,因为下一层不必学习输入数据中的偏移,并且可以专注与如何更好地组合特征(也因为在v2里有较好的效果,BN层几乎是成了深度网络的必备);
(在Batch-normalized论文中只增加了BN层,而之后的Inception V3的论文提及到的inception v2还做了下面的优化)
(2)使用2个3x3的卷积代替梯度(特征图,下同)为35x35中的5x5的卷积,这样既可以获得相同的视野(经过2个3x3卷积得到的特征图大小等于1个5x5卷积得到的特征图),还具有更少的参数,还间接增加了网络的深度,如下图。(基于原则3)
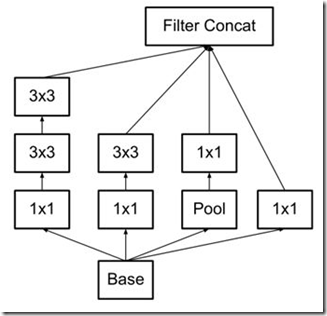 figure5
figure5
(3)3x3的卷积核表现的不错,那更小的卷积核是不是会更好呢?比如2x2。对此,v2在17x17的梯度中使用1*n和n*1这种非对称的卷积来代替n*n的对称卷积,既降低网络的参数,又增加了网络的深度(实验证明,该结构放于网络中部,取n=7,准确率更高),如下。(基于原则3)
 figure6
figure6 用2个3×1代替3×3
用2个3×1代替3×3
(4)在梯度为8x8时使用可以增加滤波器输出的模块(如下图),以此来产生高维的稀疏特征。(基于原则2)
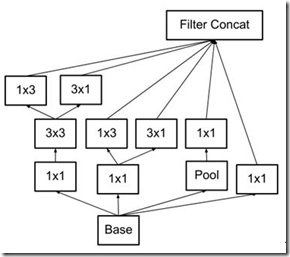 figure7
figure7
⑸ 输入从224x224变为229x229。
最后实现的Inception v2的结构如下表。
经过网络的改进,inception v2得到更低的识别误差率,与其他网络识别误差率对比如表所示。
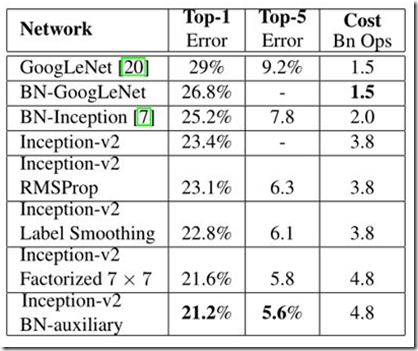
如表,inception v2相比inception v1在imagenet的数据集上,识别误差率由29%降为23.4%。
Inception v3
inception模块之间特征图的缩小,主要有下面两种方式:
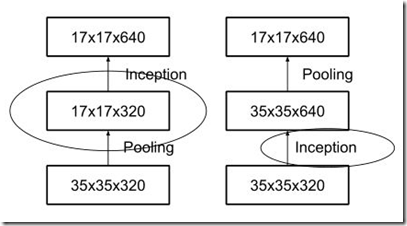
右图是先进行inception操作,再进行池化来下采样,但是这样参数量明显多于左图(比较方式同前文的降维后inception模块),因此v2采用的是左图的方式,即在不同的inception之间(35/17/8的梯度)采用池化来进行下采样。
但是,左图这种操作会造成表达瓶颈问题,也就是说特征图的大小不应该出现急剧的衰减(只经过一层就骤降)。如果出现急剧缩减,将会丢失大量的信息,对模型的训练造成困难。(上文提到的原则1)
因此,在2015年12月提出的Inception V3结构借鉴inception的结构设计了采用一种并行的降维结构,如下图:
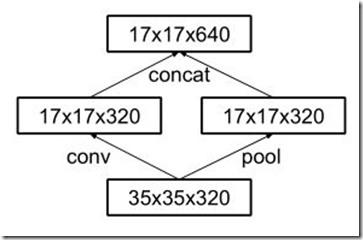
具体来说,就是在35/17/8之间分别采用下面这两种方式来实现特征图尺寸的缩小,如下图:
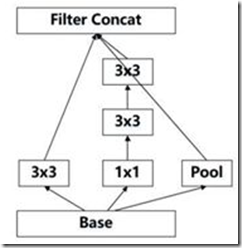 figure 5' 35/17之间的特征图尺寸减小
figure 5' 35/17之间的特征图尺寸减小
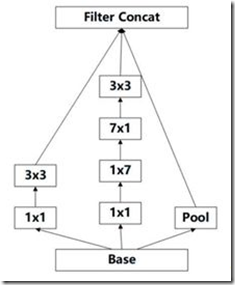 figure 6' 17/8之间的特征图尺寸缩小
figure 6' 17/8之间的特征图尺寸缩小
这样就得到Inception v3的网络结构,如表所示。
经过优化后的inception v3网络与其他网络识别误差率对比如表所示。
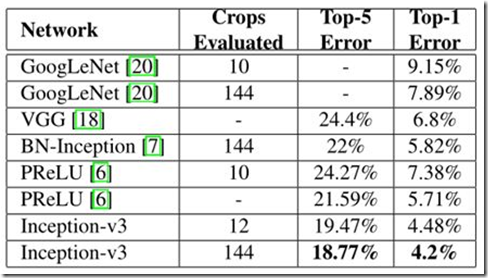
如表所示,在144x144的输入上,inception v3的识别错误率由v1的7.89%降为了4.2%。
此外,文章还提到了中间辅助层,即在网络中部再增加一个输出层。实验发现,中间辅助层在训练前期影响不大,而在训练后期却可以提高精度,相当于正则项。
Inception V4
其实,做到现在,inception模块感觉已经做的差不多了,再做下去准确率应该也不会有大的改变。但是谷歌这帮人还是不放弃,非要把一个东西做到极致,改变不了inception模块,就改变其他的。
因此,作者Christian Szegedy设计了inception v4的网络,将原来卷积、池化的顺次连接(网络的前几层)替换为stem模块,来获得更深的网络结构。stem模块结构如下
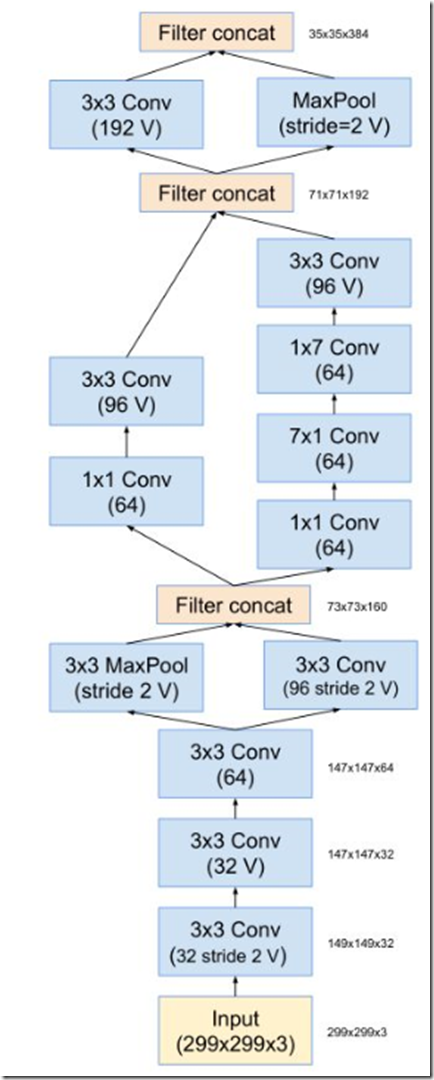 stem模块
stem模块
stem之后的,同v3,是inception模块和reduction模块,如下图

inception v4 中的inception模块(分别为inception A inception B inception C)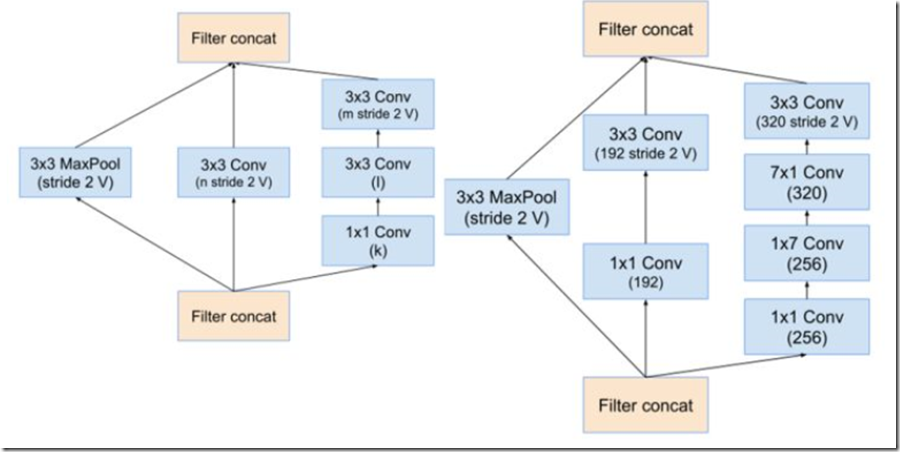
inception v4中的reduction模块(分别为reduction A reduction B)
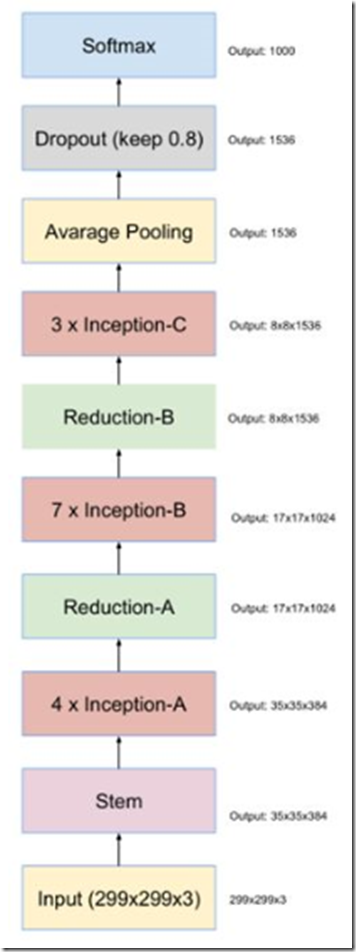
最终得到的inception v4结构如下图。
Inception-ResNet-v2
ResNet(该网络介绍见卷积神经网络结构简述(三)残差系列网络)的结构既可以加速训练,还可以提升性能(防止梯度弥散);Inception模块可以在同一层上获得稀疏或非稀疏的特征。有没有可能将两者进行优势互补呢?
Christian Szegedy等人将两个模块的优势进行了结合,设计出了Inception-ResNet网络。
(inception-resnet有v1和v2两个版本,v2表现更好且更复杂,这里只介绍了v2)
inception-resnet的成功,主要是它的inception-resnet模块。
inception-resnet v2中的Inception-resnet模块如下图
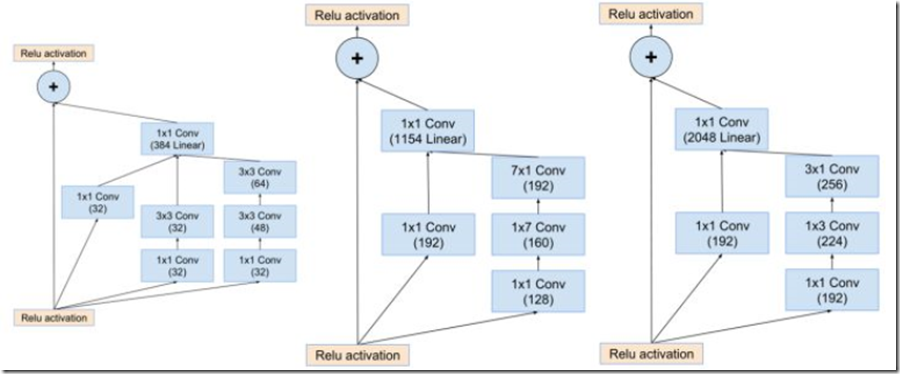
Inception-resnet模块(分别为inception-resnet-A inception-resnet-B inception-resnet-C)
Inception-resnet模块之间特征图尺寸的减小如下图。(类似于inception v4)

inception-resnet-v2中的reduction模块(分别为reduction A reduction B)
最终得到的Inception-ResNet-v2网络结构如图(stem模块同inception v4)。
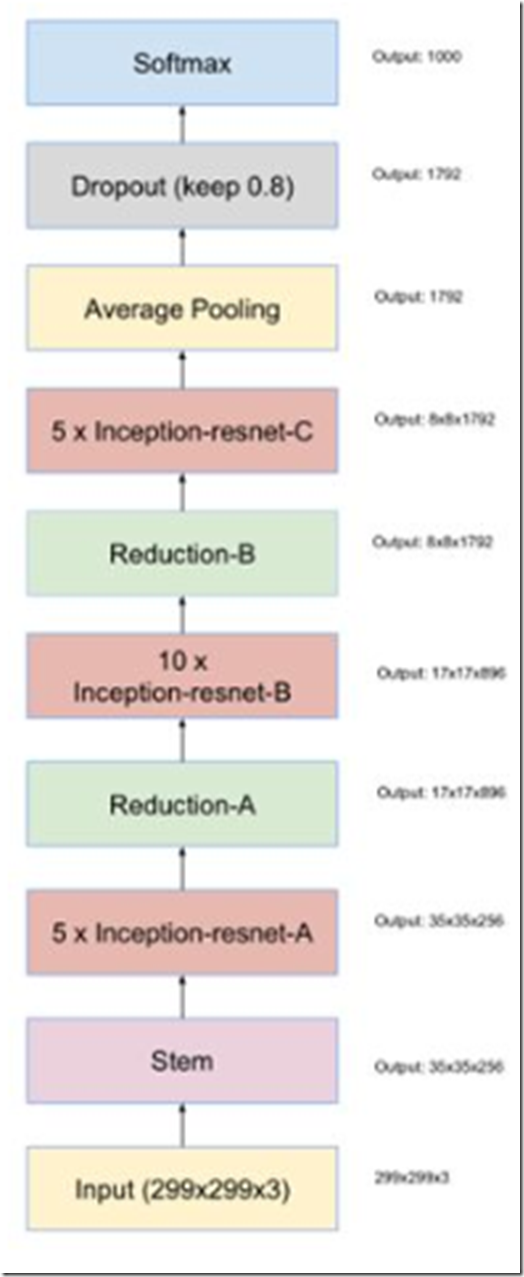
经过这两种网络的改进,使得模型对图像识别的错误率进一步得到了降低。Inception、resnet网络结果对比如表所示。

如表,Inception V4与Inception-ResNet-v2网络较之前的网络,误差率均有所下降。
Inception系列的更多相关文章
- 『高性能模型』卷积复杂度以及Inception系列
转载自知乎:卷积神经网络的复杂度分析 之前的Inception学习博客: 『TensorFlow』读书笔记_Inception_V3_上 『TensorFlow』读书笔记_Inception_V3_下 ...
- 网络结构解读之inception系列五:Inception V4
网络结构解读之inception系列五:Inception V4 在残差逐渐当道时,google开始研究inception和残差网络的性能差异以及结合的可能性,并且给出了实验结构. 本文思想阐述不多, ...
- 网络结构解读之inception系列四:Inception V3
网络结构解读之inception系列四:Inception V3 Inception V3根据前面两篇结构的经验和新设计的结构的实验,总结了一套可借鉴的网络结构设计的原则.理解这些原则的背后隐藏的 ...
- 网络结构解读之inception系列三:BN-Inception(Inception V2)
网络结构解读之inception系列三:BN-Inception(Inception V2) BN的出现大大解决了训练收敛问题.作者主要围绕归一化的操作做了一系列优化思路的阐述,值得细看. Batch ...
- 网络结构解读之inception系列二:GoogLeNet(Inception V1)
网络结构解读之inception系列二:GoogLeNet(Inception V1) inception系列的开山之作,有网络结构设计的初期思考. Going deeper with convolu ...
- 网络结构解读之inception系列一:Network in Network
网络结构解读之inception系列一:Network in Network 网上有很多的网络结构解读,之前也是看他人博客的介绍,但当自己看论文的时候,发现存在很多的细节和动机解读,而这部分能加深 ...
- Inception系列理解
博客:博客园 | CSDN | blog 写在前面 Inception 家族成员:Inception-V1(GoogLeNet).BN-Inception.Inception-V2.Inception ...
- Inception系列之Inception_v1
目前,神经网络模型为了得到更好的效果,越来越深和越来越宽的模型被提出.然而这样会带来以下几个问题: 1)参数量,计算量越来越大,在有限内存和算力的设备上,其应用也就越难以落地. 2)对于一些数据集较少 ...
- 深度卷积网络-Inception系列
目录 1. Inception V1 1.1 Inception module 2. Inception V2 3. Inception V3 4. Inception V4, Inception-R ...
随机推荐
- 页面调用Iframe中数据
<iframe src="html的路径(至于MVC中cshtml直接路径好像是不行的,得使用action进行请求出来的路径)" id="iframechild&q ...
- php 原生文件下载
1.整个网页的html界面源码下载: xiazai.php <html> <head> <meta charset ="utf-8"> < ...
- 【本周主题】第一期:JavaScript单线程与异步
相信下边这个图一定都不陌生,本周就围绕这张图深入了解下js代码执行时的来龙去脉. 一.JavaScript是单线程的 2018-11-19 21:21:21 周一 js本质是单线程的.这一特性是jav ...
- m个苹果放入n个篮子
题目 :X个相同的苹果放入Y个篮子,(1)篮子可以为空 ,篮子不同. 放法有C(X+Y-1,Y-1 );// (2)篮子不可以为空,篮子不同.放法有C(X-1,Y-1) //插挡板法 分析有了这个组合 ...
- Android studio修改字体(font)大小(size)
Android Studio 默认编辑器(Editor)的方案(Scheme)是无法修改字体的, 可以Save as, 保存为新的方案(Scheme), 然后更改字体大小; 位置: File-> ...
- VMware ESXI5.5 Memories limits resolved soluation.
在使用VMware ESXI5.5 的时候提示内存限制了,在网上找的了解决方案: 如下文: 1. Boot from VMware ESXi 5.5; 2. wait "Welcome to ...
- wireshark 表达式备忘录
参考资料: https://blog.csdn.net/wojiaopanpan/article/details/69944970 wireshark分两种表达式,一种是捕获表达式,这个是在捕获时用的 ...
- Struts2之命名空间与Action的三种创建方式
看到上面的标题,相信大家已经知道我们接下来要探讨的知识了,一共两点:1.package命名空间设置:2.三种Action的创建方式.下面我们开始本篇的内容: 首先我们聊一聊命名空间的知识,namesp ...
- NET中的设计模式---单件模式
如众所知,单件模式做为<Gof 23中设计模式>之一,其意图仅允许单件类的一个实例存在(扩展单件模式不在此文范围内),并提供全局的访问方法.UML类图如下. http://csharpin ...
- H3C系列之三层交换机dhcp功能的开启
环境介绍>>>>>>>>>>>>>>>>>>>>交换机名牌:H3C交换机类型:三 ...