CNN-卷积层和池化层学习
卷积神经网络(CNN)由输入层、卷积层、激活函数、池化层、全连接层组成,即INPUT-CONV-RELU-POOL-FC
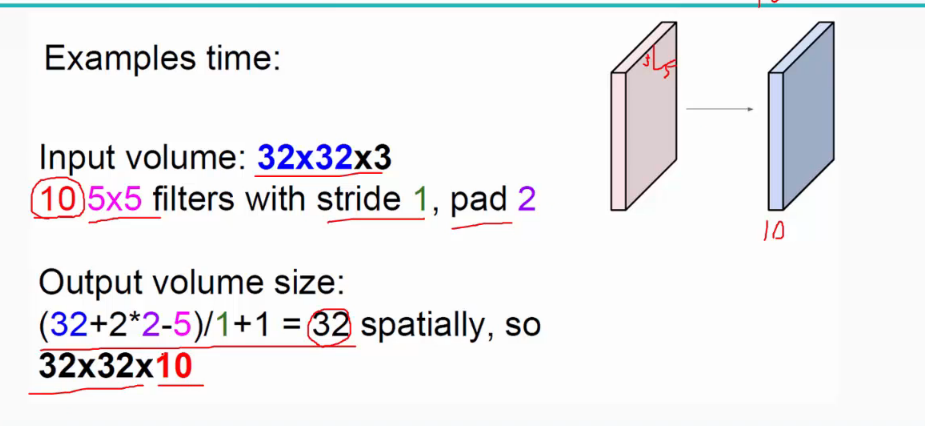
(1)卷积层:用它来进行特征提取,如下:
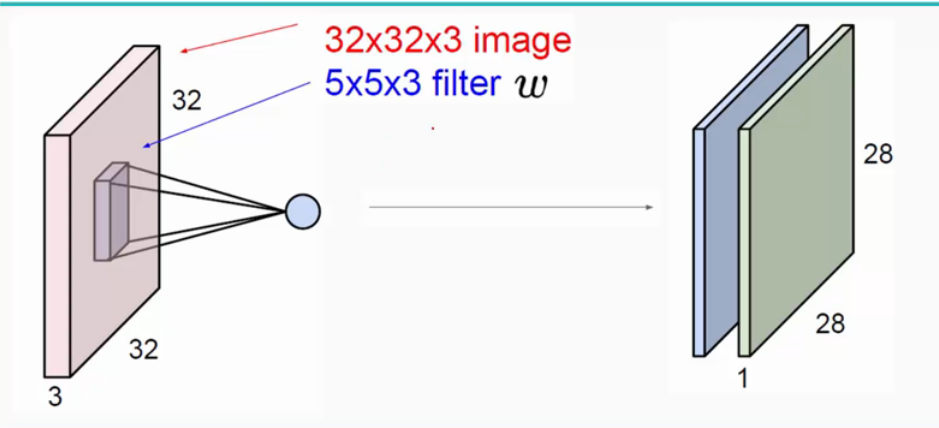
输入图像是32*32*3,3是它的深度(即R、G、B),卷积层是一个5*5*3的filter(感受野),这里注意:感受野的深度必须和输入图像的深度相同。通过一个filter与输入图像的卷积可以得到一个28*28*1的特征图,上图是用了两个filter得到了两个特征图;
我们通常会使用多层卷积层来得到更深层次的特征图。如下:

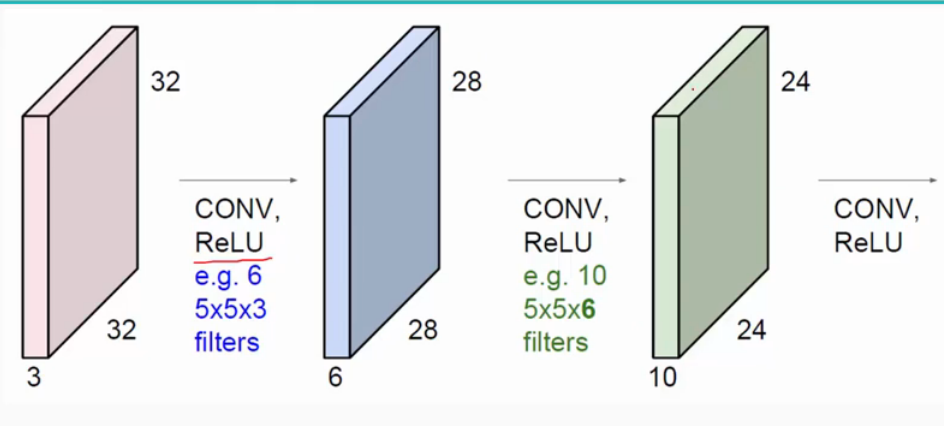
关于卷积的过程图解如下:
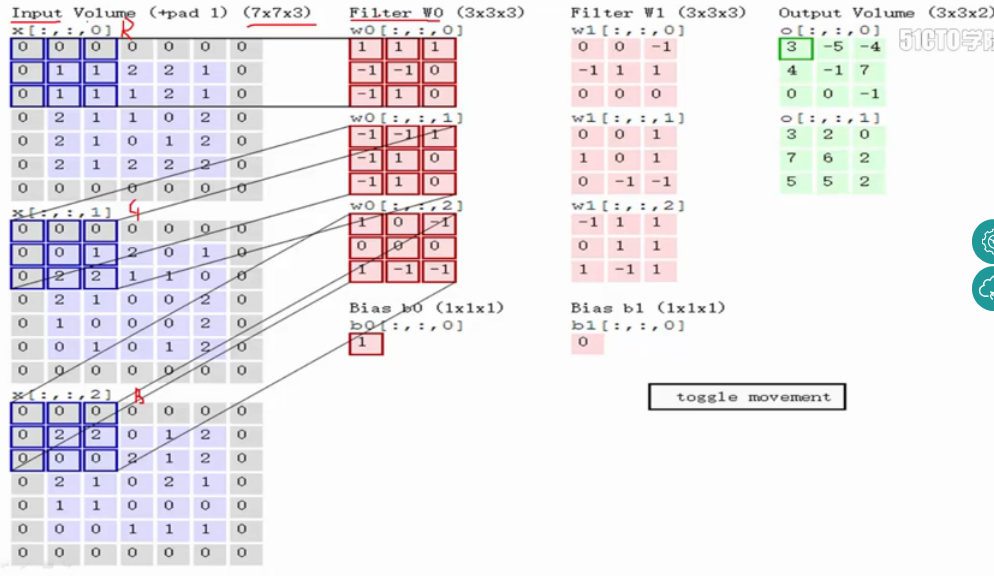
输入图像和filter的对应位置元素相乘再求和,最后再加上b,得到特征图。如图中所示,filter w0的第一层深度和输入图像的蓝色方框中对应元素相乘再求和得到0,其他两个深度得到2,0,则有0+2+0+1=3即图中右边特征图的第一个元素3.,卷积过后输入图像的蓝色方框再滑动,stride=2,如下:
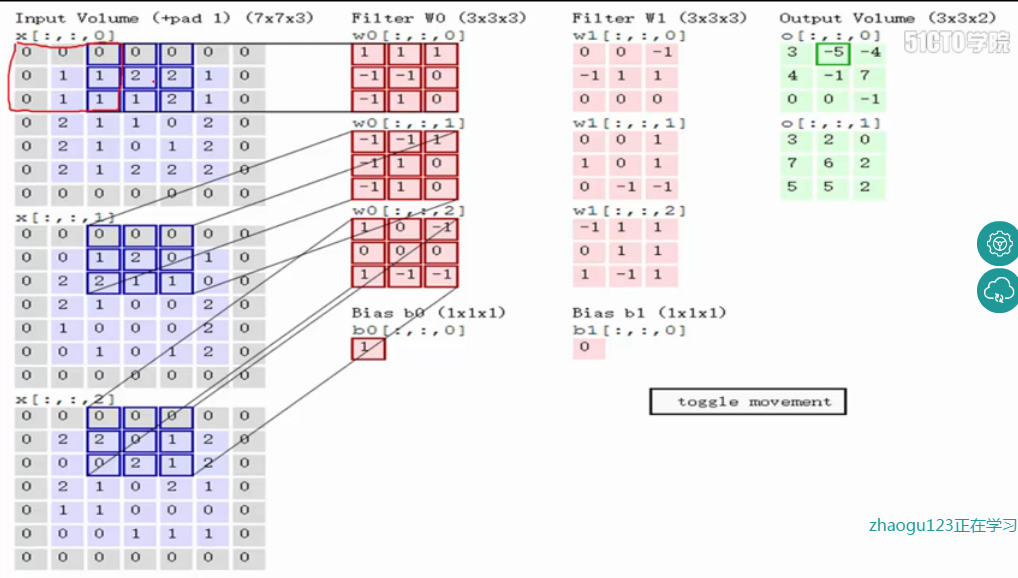
如上图,完成卷积,得到一个3*3*1的特征图;在这里还要注意一点,即zero pad项,即为图像加上一个边界,边界元素均为0.(对原输入无影响)一般有
F=3 => zero pad with 1
F=5 => zero pad with 2
F=7=> zero pad with 3,边界宽度是一个经验值,加上zero pad这一项是为了使输入图像和卷积后的特征图具有相同的维度,如:
输入为5*5*3,filter为3*3*3,在zero pad 为1,则加上zero pad后的输入图像为7*7*3,则卷积后的特征图大小为5*5*1((7-3)/1+1),与输入图像一样;
而关于特征图的大小计算方法具体如下:

卷积层还有一个特性就是“权值共享”原则。如下图:
如没有这个原则,则特征图由10个32*32*1的特征图组成,即每个特征图上有1024个神经元,每个神经元对应输入图像上一块5*5*3的区域,即一个神经元和输入图像的这块区域有75个连接,即75个权值参数,则共有75*1024*10=768000个权值参数,这是非常复杂的,因此卷积神经网络引入“权值”共享原则,即一个特征图上每个神经元对应的75个权值参数被每个神经元共享,这样则只需75*10=750个权值参数,而每个特征图的阈值也共享,即需要10个阈值,则总共需要750+10=760个参数。
补充:
(1)对于多通道图像做1*1卷积,其实就是将输入图像的每个通道乘以系数后加在一起,即相当于将原图中本来各个独立的通道“联通”在了一起;
池化层:对输入的特征图进行压缩,一方面使特征图变小,简化网络计算复杂度;一方面进行特征压缩,提取主要特征,如下:
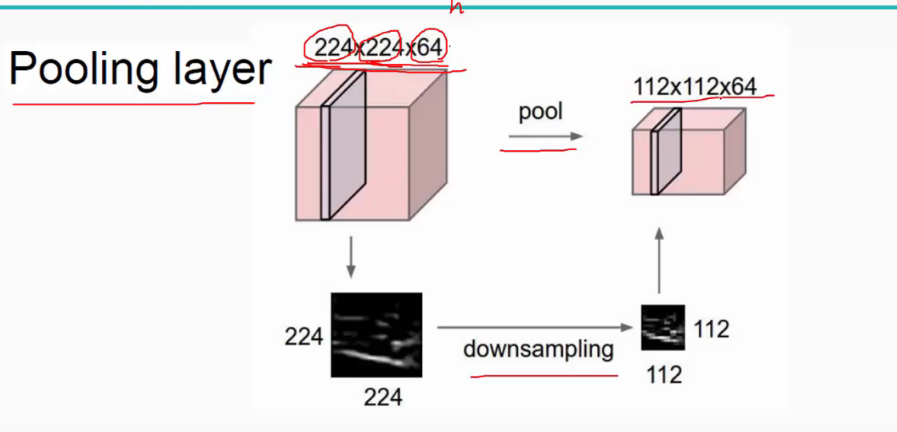
池化操作一般有两种,一种是Avy Pooling,一种是max Pooling,如下:
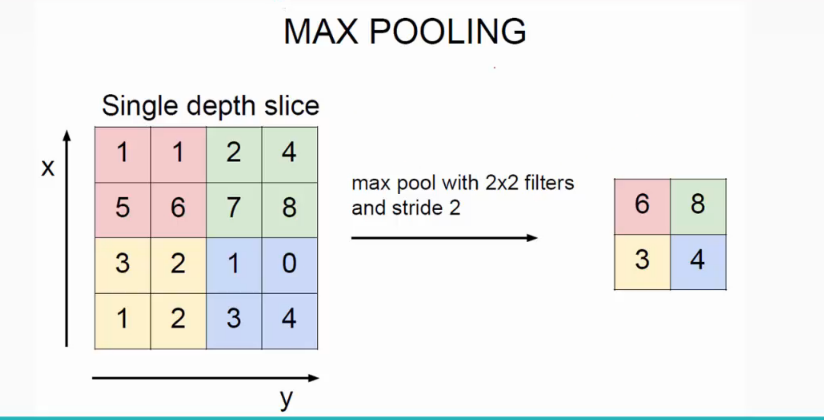
同样地采用一个2*2的filter,max pooling是在每一个区域中寻找最大值,这里的stride=2,最终在原特征图中提取主要特征得到右图。
(Avy pooling现在不怎么用了(其实就是平均池化层),方法是对每一个2*2的区域元素求和,再除以4,得到主要特征),而一般的filter取2*2,最大取3*3,stride取2,压缩为原来的1/4.
注意:这里的pooling操作是特征图缩小,有可能影响网络的准确度,因此可以通过增加特征图的深度来弥补(这里的深度变为原来的2倍)。
全连接层:连接所有的特征,将输出值送给分类器(如softmax分类器)。
总的一个结构大致如下:
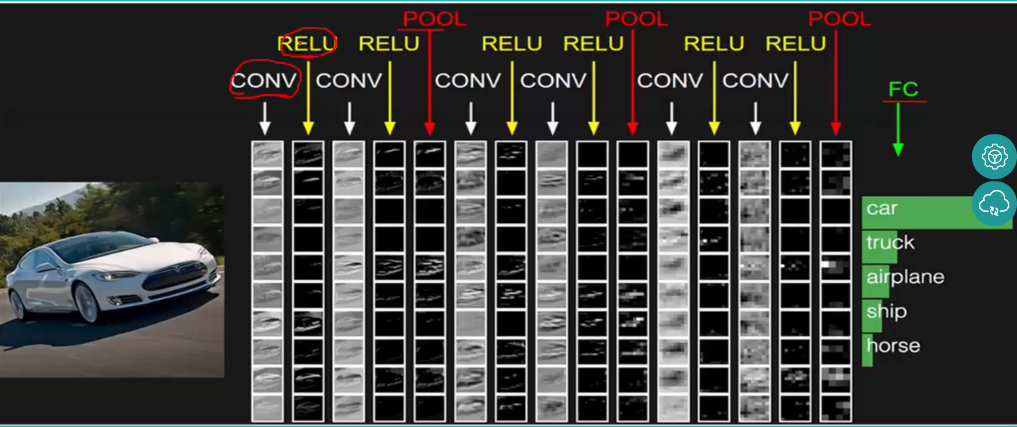
另外:CNN网络中前几层的卷积层参数量占比小,计算量占比大;而后面的全连接层正好相反,大部分CNN网络都具有这个特点。因此我们在进行计算加速优化时,重点放在卷积层;进行参数优化、权值裁剪时,重点放在全连接层。
CNN-卷积层和池化层学习的更多相关文章
- 基于深度学习和迁移学习的识花实践——利用 VGG16 的深度网络结构中的五轮卷积网络层和池化层,对每张图片得到一个 4096 维的特征向量,然后我们直接用这个特征向量替代原来的图片,再加若干层全连接的神经网络,对花朵数据集进行训练(属于模型迁移)
基于深度学习和迁移学习的识花实践(转) 深度学习是人工智能领域近年来最火热的话题之一,但是对于个人来说,以往想要玩转深度学习除了要具备高超的编程技巧,还需要有海量的数据和强劲的硬件.不过 Tens ...
- tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图
tensorflow CNN 卷积神经网络中的卷积层和池化层的代码和效果图 因为很多 demo 都比较复杂,专门抽出这两个函数,写的 demo. 更多教程:http://www.tensorflown ...
- ubuntu之路——day17.3 简单的CNN和CNN的常用结构池化层
来看上图的简单CNN: 从39x39x3的原始图像 不填充且步长为1的情况下经过3x3的10个filter卷积后 得到了 37x37x10的数据 不填充且步长为2的情况下经过5x5的20个filter ...
- CNN卷积神经网络的卷积层、池化层的输出维度计算公式
卷积层Conv的输入:高为h.宽为w,卷积核的长宽均为kernel,填充为pad,步长为Stride(长宽可不同,分别计算即可),则卷积层的输出维度为: 其中上开下闭开中括号表示向下取整. MaxPo ...
- 【python实现卷积神经网络】池化层实现
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 『TensorFlow』卷积层、池化层详解
一.前向计算和反向传播数学过程讲解
- Python3 卷积神经网络卷积层,池化层,全连接层前馈实现
# -*- coding: utf-8 -*- """ Created on Sun Mar 4 09:21:41 2018 @author: markli " ...
- Keras深度神经网络算法模型构建【输入层、卷积层、池化层】
一.输入层 1.用途 构建深度神经网络输入层,确定输入数据的类型和样式. 2.应用代码 input_data = Input(name='the_input', shape=(1600, 200, 1 ...
- 吴裕雄 python 神经网络——TensorFlow训练神经网络:卷积层、池化层样例
import numpy as np import tensorflow as tf M = np.array([ [[1],[-1],[0]], [[-1],[2],[1]], [[0],[2],[ ...
随机推荐
- 【BZOJ-3681】Arietta 网络流 + 线段树合并
3681: Arietta Time Limit: 20 Sec Memory Limit: 64 MBSubmit: 182 Solved: 70[Submit][Status][Discuss ...
- Codeforces 749E Gosha is hunting 二分+DP
很神奇的一题 看完题解不由惊叹 题意:$n$个神奇宝贝 $a$个普通球 $b$个高级球 普通球抓住$i$神奇宝贝的概率为$u[i]$ 高级球为$p[i]$ 一起用为$u[i]+p[i]-u[i]*p[ ...
- Token以及签名signature的设计与实现
LZ第一次给app写开放接口,把自己处理Token的实现记录下来,目的是如果以后遇到好的实现,能在此基础上改进.这一版写法非常粗糙,写出来就是让大家批评的,多多指教,感谢大家. 当初设计这块想达到的效 ...
- 【来龙去脉系列】深入理解DIP、IoC、DI以及IoC容器
摘要 面向对象设计(OOD)有助于我们开发出高性能.易扩展以及易复用的程序.其中,OOD有一个重要的思想那就是依赖倒置原则(DIP),并由此引申出IoC.DI以及Ioc容器等概念.通过本文我们将一起学 ...
- 使用GIT进行源码管理——GIT托管服务2018
我曾经介绍过几个在线的GIT托管服务,然而时过境迁,发生了不少变化,便写了此文章,在新的一年重新更新一下: 国外托管网站: 国外托管网站比起国内的来相对靠谱点,但一个主要缺点是网速较慢,并且可能在 ...
- 恶意软件正在利用SSLserver窃取用户个人信息!
安全套接层协议(SSL)及安全传输层协议(TLS)旨在提供一个安全.加密的client和server之间的连接网络.为进一步进行身份验证和加密,server必须提供证书,从而直接有效地证明其身份. 使 ...
- ASIHTTPRequest学习笔记
1.creating requestsrequest分为同步和异步两种.不同之处在于开始request的函数:[request startSynchronous];[request startAsyn ...
- fastjson的日期格式化
//SerializerFeature.WriteDateUseDateFormat 使用日期字段格式序列化(2017-01-01),而不是用时间戳表示日期 JSON.toJSONString(dat ...
- Quartz:不要重复造轮子,一款企业级任务调度框架。
背景 第一次遇到定时执行某些任务的需求时,很多朋友可能设计了一个小类库,这个类图提高了一个接口,然后由调度器调度所有注册的接口类型,我就是其中之一,随着接触的开源项目越来越多,我的某些开发习惯受到了影 ...
- Vector HashMap List 存取数据速度
数组大小:40000List_List:0.0045List :0.0818List_HashMap:0.0072HashMap :0.0517List_Vector:0.0037Vector :0. ...