Spark中groupBy groupByKey reduceByKey的区别
groupBy
和SQL中groupby一样,只是后面必须结合聚合函数使用才可以。
例如:
hour.filter($"version".isin(version: _*)).groupBy($"version").agg(countDistinct($"id"), count($"id")).show()
groupByKey
对Key-Value形式的RDD的操作。
例如(取自link):
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2)
val b = a.keyBy(_.length)//给value加上key,key为对应string的长度
b.groupByKey.collect
//结果 Array((4,ArrayBuffer(lion)), (6,ArrayBuffer(spider)), (3,ArrayBuffer(dog, cat)), (5,ArrayBuffer(tiger, eagle)))
reduceByKey
与groupByKey功能一样,只是实现不一样。本函数会先在每个分区聚合然后再进行总的统计,如图:
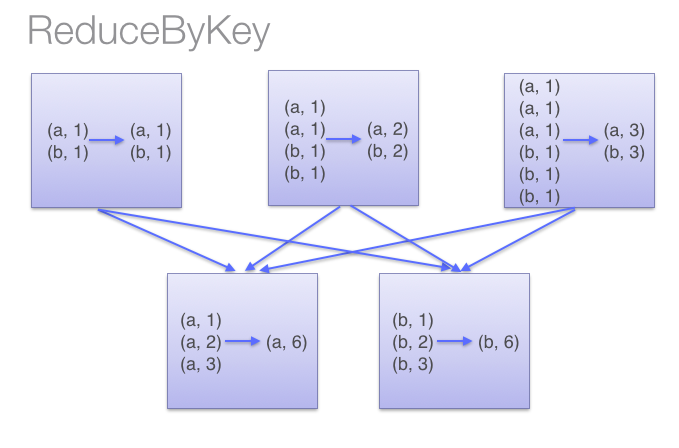
而groupByKey则是
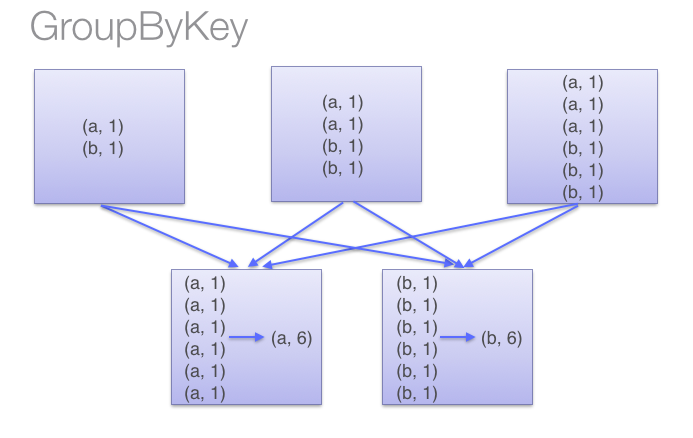
因此,本函数比groupByKey节省了传播的开销,尽量少用groupByKey
参考
- https://www.iteblog.com/archives/1357.html
- http://blog.csdn.net/guotong1988/article/details/50556871
- http://blog.cheyo.net/178.html
Spark中groupBy groupByKey reduceByKey的区别的更多相关文章
- [Spark RDD_add_1] groupByKey & reduceBykey 的区别
[groupByKey & reduceBykey 的区别] 在都能实现相同功能的情况下优先使用 reduceBykey Combine 是为了减少网络负载 1. groupByKey 是没有 ...
- Spark中ml和mllib的区别
转载自:https://vimsky.com/article/3403.html Spark中ml和mllib的主要区别和联系如下: ml和mllib都是Spark中的机器学习库,目前常用的机器学习功 ...
- 015 在Spark中关于groupByKey与reduceByKey的区别
1.groupByKey的源代码 2.groupByKey的使用缺点 不使用groupByKey的主要原因:在大规模的数据下,数据分布不均匀的情况下,可能导致OOM 3.reduceByKey的源代码 ...
- spark中map与flatMap的区别
作为spark初学者对,一直对map与flatMap两个函数比较难以理解,这几天看了和写了不少例子,终于把它们搞清楚了 两者的区别主要在于action后得到的值 例子: import org.apac ...
- Spark中cache和persist的区别
cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间. cache和persist的区别 基于Spark 1.6.1 的源码,可 ...
- Spark中repartition和partitionBy的区别
repartition 和 partitionBy 都是对数据进行重新分区,默认都是使用 HashPartitioner,区别在于partitionBy 只能用于 PairRDD,但是当它们同时都用于 ...
- spark中产生shuffle的算子
Spark中产生shuffle的算子 作用 算子名 能否替换,由谁替换 去重 distinct() 不能 聚合 reduceByKey() groupByKey groupBy() groupByKe ...
- Spark程序使用groupByKey后数据存入HBase出现重复的现象
最近在一个项目中做数据的分类存储,在spark中使用groupByKey后存入HBase,发现数据出现双份( 所有记录的 rowKey 是随机 唯一的 ) .经过不断的测试,发现是spark的运行参 ...
- Spark 中 GroupByKey 相对于 combineByKey, reduceByKey, foldByKey 的优缺点
避免使用GroupByKey 我们看一下两种计算word counts 的方法,一个使用reduceByKey,另一个使用 groupByKey: val words = Array("on ...
随机推荐
- 进阶之路(基础篇) - 012 Arduino IDE 添加DHT11传感器第三方库的方法
由于Arduino本身没有DHT 11温湿度传感器的的头文件,单有第三方的库可以给我门使用.方法如下: Step 1:下载地址:https://pan.baidu.com/s/1qYfdBJ2#lis ...
- fedora国内源常见配置
yum install yum-fastestmirror3.rpmfusion源 rpm -ivh http://download1.rpmfusion.org/free/fedora/rpmfus ...
- Nginx对某个目录或整个网站进行登录认证的方法
比如要对 网站目录下的 test 文件夹 进行加密认证 首先需要在opt 的主目录中 /opt/ 创建一个新文件 htpasswd此文件的书写格式是用户名:密码每行一个账户并且 密码必须使用函数 cr ...
- SpringBoot配置属性之Security
SpringBoot配置属性系列 SpringBoot配置属性之MVC SpringBoot配置属性之Server SpringBoot配置属性之DataSource SpringBoot配置属性之N ...
- SqlServer2005 海量数据 数据表分区解决难题
超大型数据库的大小常常达到数百GB,有时甚至要用TB来计算.而单表的数据量往往会达到上亿的记录,并且记录数会随着时间而增长.这不但影响着数据库的运行效率,也增大数据库的维护难度.除了表的数据量外,对表 ...
- 【IL】IL指令详解
名称 说明 Add 将两个值相加并将结果推送到计算堆栈上. Add.Ovf 将两个整数相加,执行溢出检查,并且将结果推送到计算堆栈上. Add.Ovf.Un 将两个无符号整数值相加,执行溢出检查,并且 ...
- Git 打标签(分布式版本控制系统)
前言 像其他版本控制系统(VCS)一样,Git 可以给历史中的某一个提交打上标签,以示重要.比较有代表性的是人们会使用这个功能来标记发布结点(v1.0 等等). 1.列出标签 在 Git 中列出已有的 ...
- 【C语言】字符串常量与指针
- hadoop相关内容
数据库导出到hadoop http://www.ibm.com/developerworks/cn/data/library/techarticle/dm-1212liuqy/ http://www. ...
- ggplot2-设置坐标轴
本文更新地址:http://blog.csdn.net/tanzuozhev/article/details/51107583 本文在 http://www.cookbook-r.com/Graphs ...