[hadoop读书笔记]译者序
一、并行数据库系统
新一代高性能的数据库系统,是在MPP和集群并行计算环境的基础上建立的数据库系统。
MPP:大规模并行处理计算机:Massive Parallel Processor。指的是一种处理机技术。由大量通用微处理器构成的多处理机系统,适合多指令流多数据流处理。这样的系统是由许多松耦合处理单元组成的,要注意的是这里指的是处理单元而不是处理器。每个单元内的CPU都有自己私有的资源,如总线、内存、硬盘等。在每个单元内都有操作系统和管理数据库的实例复本。这种结构最大的特点在于不共享资源。
并行数据库系统的目标是高性能(High Performance)和高可用性(High Availability),通过多个处理节点并行执行数据库任务,提高整个数据库系统的性能和可用性。
性能指标关注的是并行数据库系统的处理能力,具体的表现可以统一总结为数据库系统处理事务的响应时间。并行数据库系统的高性能可以从两个方面理解,一个是速度提升(SpeedUp),一个是范围提升(ScaleUp)。速度提升是指,通过并行处理,可以使用更少的时间完成两样多的数据库事务。范围提升是指,通过并行处理,在相同的处理时间内,可以完成更多的数据库事务。并行数据库系统基于多处理节点的物理结构,将数据库管理技术与并行处理技术有机结合,来实现系统的高性能。
可用性指标关注的是并行数据库系统的健壮性,也就是当并行处理节点中的一个节点或多个节点部分失效或完全失效时,整个系统对外持续响应的能力。高可用性可以同时在硬件和软件两个方面提供保障。在硬件方面,通过冗余的处理节点、存储设备、网络链路等硬件措施,可以保证当系统中某节点部分或完全失效时,其它的硬件设备可以接手其处理,对外提供持续服务。在软件方面,通过状态监控与跟踪、互相备份、日志等技术手段,可以保证当前系统中某节点部分或完全失效时,由它所进行的处理或由它所掌控的资源可以无损失或基本无损失地转移到其它节点,并由其它节点继续对外提供服务。
为了实现和保证高性能和高可用性,可扩充性也成为并行数据库系统的一个重要指标。可扩充性是指,并行数据库系统通过增加处理节点或者硬件资源(处理器、内存等),使其可以平滑地或线性地扩展其整体处理能力的特性。
二、并行数据库体系结构
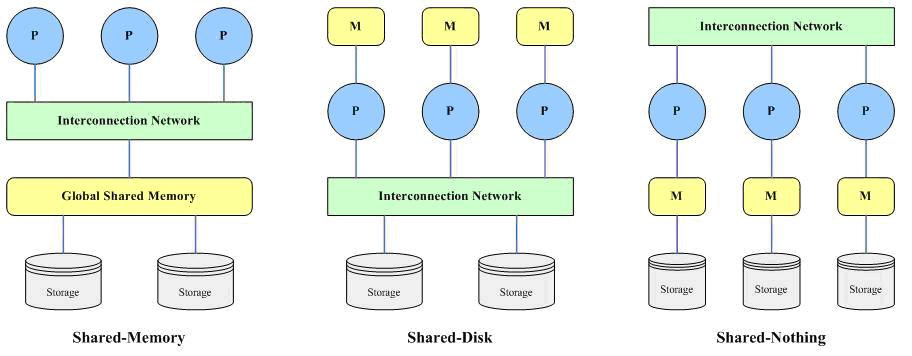
、共享内存(Shared-Memory)结构 该结构包括多个处理器、一个全局共享的内存(主存储器)和多个磁盘存储,各个处理器通过高速通讯网络(Interconnection Network)与共享内存连接,并均可直接访问系统中的一个、多个或全部的磁盘存储,在系统中,所有的内存和磁盘存储均由多个处理器共享。 ()提供多个数据库服务的处理器通过全局共享内存来交换消息和数据,通讯效率很高,查询内部和查询间的并行性的实现也均不需要额外的开销; ()数据库中的数据存储在多个磁盘存储上,并可以为所有处理器访问; ()在数据库软件的编制方面与单处理机的情形区别也不大。 这种结构由于使用了共享的内存,所以可以基于系统的实际负荷来动态地给系统中的各个处理器分配任务,从而可以很好地实现负荷均衡。 这种结构硬件资源之间的互连比较复杂,硬件成本较高;由于多个处理器共享内存,所以系统中的处理器数量的增加会导致严重的内存争用,因此系统中处理器的数量受到限制,系统的可扩充性较差;此外,由于共享内存的机制,会导致共享内存的任何错误将影响到系统中的全部处理器,使得系统的可用性表现得也不是很好;其实shared-Memory结构也就是SMP结构。 、共享磁盘(Shared-Disk)结构 该结构由多个具有独立内存(主存储器)的处理器和多个磁盘存储构成,各个处理器相互之间没有任何直接的信息和数据的交换,多个处理器和磁盘存储由高速通信网络连接,每个处理器都可以读写全部的磁盘存储。 这种结构常用于实现数据库集群,硬件成本低、可扩充性好、可用性强,且可很容易地从单处理器系统迁移,还可以容易地在多个处理器之间实现负载均衡。这也就是MPP结构系统。 缺点:
A. 这种结构的一个明显不足是多个处理器使用系统中的全部的磁盘存储,因此,当处理器增加时可能会导致磁盘争用而导致的性能问题。 B. 系统中的每一个处理器可以访问全部的磁盘存储,磁盘存储中的数据被复制到各个处理器各自的高速缓冲区中进行处理,这时会出现多个处理器同时对同一磁盘存储位置进行访问和修改,最终导致数据的一致性无法保障,因此,在结构中需要增加一个分布式缓存管理器来对各个处理器的并发访问进行全局控制与管理,这会带来额外的通信开销。Oracle的RAC就是样的结构 、无共享资源(Shared-Nothing)结构 该结构由多个完全独立的处理节点构成,每个处理节点具有自己独立的处理器、独立的内存(主存储器)和独立的磁盘存储,多个处理节点在处理器级由高速通信网络连接,系统中的各个处理器使用自己的内存独立地处理自己的数据。 这种结构中,每一个处理节点就是一个小型的数据库系统,多个节点一起构成整个的分布式的并行数据库系统。由于每个处理器使用自己的资源处理自己的数据,不存在内存和磁盘的争用,提高的整体性能。另外这种结构具有优良的可扩展性——只需增加额外的处理节点,就可以以接近线性的比例增加系统的处理能力。 这种结构中,由于数据是各个处理器私有的,因此系统中数据的分布就需要特殊的处理,以尽量保证系统中各个节点的负载基本平衡,但在目前的数据库领域,这个数据分布问题已经有比较合理的解决方案。 由于数据是分布在各个处理节点上的,因此,使用这种结构的并行数据库系统,在扩展时不可避免地会导致数据在整个系统范围内的重分布(Re-Distribution)问题。 目前,在并行数据库领域,Shared-Memory结构很少被使用了,Shared-Disk结构和Shared-Nothing结构则由于其各自的优势而得以应用和发展。Shared-Disk结构的典型代表是Oracle集群,Shared-Nothing结构的典型代表是Teradata,IBM DB2和MySQL的集群也使用了这种结构。
三、与分布式数据库/MapReduce有什么区别?分别适用于什么场景?
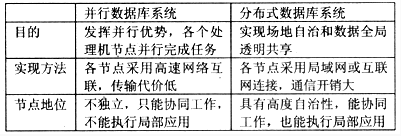
分布式数据库系统与并行数据库系统有许多相似点,如都有用网络连接各个数据处理结点的特点。网络中的所有结点构成一个逻辑上的统一整体,用户可以对各个结点上的数据进行透明存取等等。 并行数据库系统:通过并行实现各种数据操作,如数据载入、索引建立、数据查询等,可以提高系统的性能。 分布式数据库系统:数据分布存储于若干场地,并且每个场地由独立于其它场地的DBMS进行数据管理。 () 应用目标不同。并行数据库系统的目标是充分发挥并行计算机的优势,利用系统中的各个处理机结点并行完成数据库任务,提高数据库系统的整体性能。分布式数据库系统主要目的在于实现场地自治和数据的全局透明共享,而不要求利用网络中的各个结点来提高系统处理性能。
() 实现方式不同。在具体实现方法上,并行数据库系统与分布式数据库系统也有着较大的不同。在并行数据库系统中,为了充分利用各个结点的处理能力,各结点间可以采用高速网络连接。结点键的数据传输代价相对较低,当某些结点处于空闲状态时,可以将工作负载过大的结点上的部分任务通过高速网传送给空闲结点处理,从而实现系统的负载平衡。
但是在分布式数据库系统中,为了适应应用的需要,满足部门分布特点的需要,各结点间一般采用局域网或广域网相连,网络带宽较低,颠倒点的通信开销较大。因此,在查询处理时一般应尽量减少结点间的数据传输量。
() 各结点的地位不同。在并行数据库系统中,各结点是完全非独立的,不存在全局应用和局部应用的概念,在数据处理中只能发挥协同作用,而不能有局部应用。在分布式数据库系统中,各结点除了能通过网络协同完成全局事务外,各结点具有场地自治性,每个场地使独立的数据库系统。每个场地有自己的数据库、客户、CPU等资源,运行自己的DBMS,执行局部应用,具有高度的自治性。
总结:
[hadoop读书笔记]译者序的更多相关文章
- Hadoop读书笔记(二)HDFS的shell操作
Hadoop读书笔记(一)Hadoop介绍:http://blog.csdn.net/caicongyang/article/details/39898629 1.shell操作 1.1全部的HDFS ...
- Hadoop读书笔记(四)HDFS体系结构
Hadoop读书笔记(一)Hadoop介绍:http://blog.csdn.net/caicongyang/article/details/39898629 Hadoop读书笔记(二)HDFS的sh ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入hive
安装hive 1.下载hive-2.1.1(搭配hadoop版本为2.7.3) 2.解压到文件夹下 /wdcloud/app/hive-2.1.1 3.配置环境变量 4.在mysql上创建元数据库hi ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 将mysq数据导入HBASE
导入命令 sqoop import --connect jdbc:mysql://192.168.200.250:3306/sqoop --table widgets --hbase-create-t ...
- [hadoop读书笔记] 第十五章 sqoop1.4.6小实验 - 数据在mysq和hdfs之间的相互转换
P573 从mysql导入数据到hdfs 第一步:在mysql中创建待导入的数据 1.创建数据库并允许所有用户访问该数据库 mysql -h 192.168.200.250 -u root -p CR ...
- [hadoop读书笔记] 第十章 管理Hadoop集群
P375 Hadoop管理工具 dfsadmin - 查询HDFS状态信息,管理HDFS. bin/hadoop dfsadmin -help 查询HDFS基本信息 fsck - 检查HDFS中文件的 ...
- [hadoop读书笔记] 第九章 构建Hadoop集群
P322 运行datanode和tasktracker的典型机器配置(2010年) 处理器:两个四核2-2.5GHz CPU 内存:16-46GN ECC RAM 磁盘存储器:4*1TB SATA 磁 ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
- [hadoop读书笔记] 第四章 Hadoop I/O操作
P92 压缩 P102 序列化 序列化:将结构化对象转为字节流便于在网上传输或写到磁盘进行永久性存储的过程 用于进程之间的通信或者数据的永久存储 反序列化:将字节流转为结构化对象的逆过程 Hadoop ...
随机推荐
- Atitit 图像处理之编程之类库调用的接口api cli gui ws rest attilax大总结.docx
Atitit 图像处理之编程之类库调用的接口api cli gui ws rest attilax大总结.docx 1. 为什么需要接口调用??1 1.1. 为了方便集成复用模块类库1 1.2. 嫁 ...
- Java中使用Oracle的客户端 load data和sqlldr命令执行数据导入到数据库中
Windows环境下测试代码: import java.io.BufferedReader; import java.io.File; import java.io.FileNotFoundExcep ...
- KVM虚拟机安装报错 KVM is not available
在linux系统上使用kvm安装系统时,如果你的cpu不支持虚拟化技术那么可能会报以下错误: Warning:KVM is not available. This may mean the KVM p ...
- (原创)C++11改进我们的程序之move和完美转发
本次要讲的是右值引用相关的几个函数:std::move, std::forward和成员的emplace_back,通过这些函数我们可以避免不必要的拷贝,提高程序性能.move是将对象的状态或者所有权 ...
- (原创)C++11改进我们的程序之右值引用
本次主要讲c++11中的右值引用,后面还会讲到右值引用如何结合std::move优化我们的程序. c++11增加了一个新的类型,称作右值引用(R-value reference),标记为T & ...
- Standard C 之 math.h和float.h
对于C Standard Library 可以参考:http://www.acm.uiuc.edu/webmonkeys/book/c_guide/ 或者 http://www.cplusplus.c ...
- bash shell(5):if,else,while大小比较
1.if :else 语句 .if的单分支语法格式: if 条件判断;then 语句1 语句2 …… else 语句1 语句2 …… fi .if的多分支语法格式: if 条件判断:then 语句1 ...
- 安装Python2.7出现configure: error: no acceptable C compiler found in $PATH错误
安装Python2.7出现configure: error: no acceptable C compiler found in $PATH错误 安装步骤: 安装依赖 yum groupinstall ...
- Zookeeper session超时
1.会话概述 在ZooKeeper中,客户端和服务端建立连接后,会话随之建立,生成一个全局唯一的会话ID(Session ID).服务器和客户端之间维持的是一个长连接,在SESSION_TIMEOUT ...
- Linux LVM 总结
LVM全称是Logical Volume Manager. 它主要是实现硬盘容量的动态扩展. 一般用于存储数据量无法预估的场景, 例如Linux的根目录用lvm存储. LVM创建过程一般是这样的 1. ...