大数据Hadoop平台安装及Linux操作系统环境配置
配置 Linux 系统基础环境
查看服务器的IP地址

设置服务器的主机名称
hostnamectl set-hostname hadoop
hostname可查看
绑定主机名与IP 地址
vim /etc/hosts
写入:
ip hadoop #自己虚拟机ip和主机名
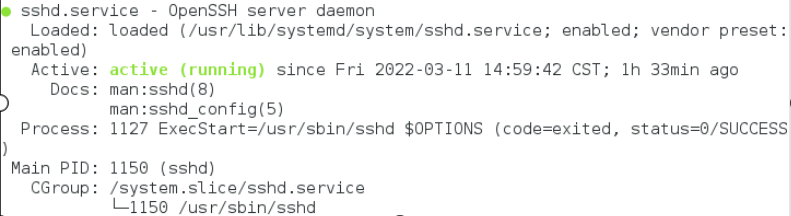
查看SSH 服务状态
- SSH 为 Secure Shell 的缩写,是专为远程登录会话和其他网络服务提供安
全性的协议。一般的用法是在本地计算机安装SSH客服端,在服务器端安装SSH
服务,然后本地计算机利用 SSH 协议远程登录服务器,对服务器进行管理。这
样可以非常方便地对多台服务器进行管理。同时在 Hadoop分布式环境下,集群
中的各个节点之间(节点可以看作是一台主机)需要使用SSH协议进行通信。因
此Linux系统必须安装并启用SSH服务。
命令:systemctl status sshd
关闭防火墙
- Hadoop可以使用Web页面进行管理,但需要关闭防火墙,否则打不开Web页
面。同时不关闭防火墙也会造成 Hadoop 后台运行脚本出现莫名其妙的错误。
关闭命令如下:

查看状态为:

- 看到inactive (dead)就表示防火墙已经关闭。不过这样设置后,Linux系
统如果重启,防火墙仍然会重新启动。执行如下命令可以永久关闭防火墙。

创建hadoop 用户

安装JAVA 环境
下载JDK 安装包
- JDK 安 装 包 需 要 在 Oracle 官 网 下 载 , 下 载 地 址 为 :
https://www.oracle.com/java /technologies /javase-jdk8-downloads.html,本教材采用的Hadoop 2.7.1所需要的JDK版本为JDK7以上,这里采用的安装包为jdk-8u152-linux-x64.tar.gz
卸载自带OpenJDK
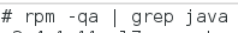
删除相关文件,键入命令
rpm -e --nodeps 安装包名称
查看删除结果再次键入命令 java -version 出现以下结果表示删除成功
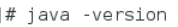

安装JDK
Hadoop 2.7.1 要求 JDK 的版本为 1.7 以上,这里安装的是 JDK1.8 版(即
JAVA 8)。
安装命令如下,将安装包解压到/usr/local/src目录下:
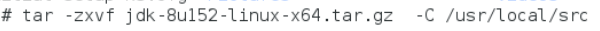
解压完成后,查看目录确认一下。可以看出 JDK 安在/usr/local/src/jdk1.8.0_152目录中。

设置 JAVA 环境变量
在Linux中设置环境变量的方法比较多,较常见的有两种:一是配置/etc/profile文件,配置结果对整个系统有效,系统所有用户都可以使用;二是配置~/bashrc文件,配置结果仅对当前用户有效。这里使用第一种方法。
在文件的最后增加如下两行:
进入vim /etc/profile,在文件结尾添加
# JAVA_HOME指向JAVA安装目录
执行source使设置生效:

- 检查JAVA是否可用
source /etc/profile
echo $JAVA_HOME
- 说明JAVA_HOME已指向JAVA安装目录。能够正常显示Java版本则说明JDK安装并配置成功。
安装Hadoop 软件
获取Hadoop 安装包
- Apache Hadoop 各 个 版 本 的 下 载 网 址 :
https://archive.apache.org/dist/hadoop /common/。本教材选用的事Hadoop2.7.1版本,安装包为hadoop-2.7.1.tar.gz。需要先下载Hadoop安装包,再上传到Linux系统的/opt/software目录。具体的方法见前一节“实验一 Linux操作系统环境设置”,这里就不再赘述。
安装Hadoop 软件
安装命令如下,将安装包解压到/usr/local/src/目录下:

- 解压完成后,查看目录确认一下。可以看出 Hadoop 安装在/usr/local/src/hadoop -2.7.1目录中

- 查看Hadoop目录,得知Hadoop目录内容如下:

- 其中:
bin:此目录中存放Hadoop、HDFS、YARN和MapReduce运行程序和管理软件。
etc:存放Hadoop配置文件。
include: 类似C语言的头文件
lib:本地库文件,支持对数据进行压缩和解压。
libexe:同lib
sbin:Hadoop集群启动、停止命令
share:说明文档、案例和依赖jar包。
配置 Hadoop 环境变量
和设置JAVA环境变量类似,修改/etc/profile文件。
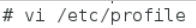
在文件的最后增加如下两行:
HADOOP_HOME指向 JAVA安装目录

执行source使用设置生效:

检查设置是否生效:

出现上述Hadoop帮助信息就说明Hadoop已经安装好了。
修改目录所有者和所有者组
上述安装完成的 Hadoop 软件只能让 root 用户使用,要让 hadoop 用户能够运行Hadoop软件,需要将目录/usr/local/src的所有者改为hadoop用户。

/usr/local/src目录的所有者已经改为hadoop了
安装单机版 Hadoop 系统
配置 Hadoop 配置文件
进入Hadoop目录

配置hadoop-env.sh文件,目的是告诉Hadoop系统JDK的安装目录

在文件中查找export JAVA_HOME这行,将其改为如下所示内容

这样就设置好Hadoop的本地模式,下面使用官方案例来测试Hadoop是否运
行正常。
测试 Hadoop 本地模式的运行
切换到hadoop 用户
- 使用hadoop这个用户来运行Hadoop软件

创建输入数据存放目录
- 将输入数据存放在~/input目录(hadoop用户主目录下的input目录中)

创建数据输入文件
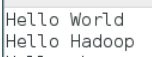
- 创建数据文件data.txt,将要测试的数据内容输入到data.txt文件中

- 输入如下内容,保存退出:
测试 MapReduce 运行
运行 WordCount 官方案例,统计 data.txt 文件中单词的出现频度。这个案例可以用来统计年度十大热销产品、年度风云人物、年度最热名词等。命令如下:

- 运行结果保存在~/output目录中,命令执行后查看结果:

- 文件_SUCCESS表示处理成功,处理的结果存放在part-r-00000文件中,查看该文件。

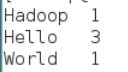
可以看出统计结果正确,说明 Hadoop 本地模式运行正常。读者可将这个运行结果与“3.2.3 MapReduce”中的WordCount案例运行过程进行对照,来加深对MapReduce框架的理解。
注意:输出目录不能事先创建,如果已经有 ~/output 目录,就要选择另外的输出目录,或者将 ~/output 目录先删除。删除命令如下所示。
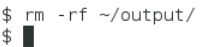
大数据Hadoop平台安装及Linux操作系统环境配置的更多相关文章
- OpenStack-Ocata版+CentOS7.6 云平台环境搭建 — 1.操作系统环境配置
1.OpenStack示例的架构介绍 1.1 各节点介绍 (1)控制节点(controller)控制节点(controller)上运行身份服务,镜像服务,计算节点管理,网络管理,各种网络代理和仪表板. ...
- 大数据Hadoop入门教程 | (二)Linux
使用finalShell可以提供文件目录图形化 完整Linux命令整理参考大佬博客:Linux常见文件管理命令 - Mr_Walker - 博客园 Linux文件系统基础知识 Linux文件系统概念 ...
- 大数据Hadoop学习之搭建hadoop平台(2.2)
关于大数据,一看就懂,一懂就懵. 一.概述 本文介绍如何搭建hadoop分布式集群环境,前面文章已经介绍了如何搭建hadoop单机环境和伪分布式环境,如需要,请参看:大数据Hadoop学习之搭建had ...
- CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 成都大数据Hadoop与Spark技术培训班
成都大数据Hadoop与Spark技术培训班 中国信息化培训中心特推出了大数据技术架构及应用实战课程培训班,通过专业的大数据Hadoop与Spark技术架构体系与业界真实案例来全面提升大数据工程师 ...
- 大数据计算平台Spark内核解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着 Spark在大数据计算领域的暂露头角,越来越多 ...
- 14周事情总结-机器人-大数据hadoop
14周随着考试的进行,其他该准备的事情也在并行的处理着,考试内容这里不赘述了 首先说下,关于机器人大赛的事情,受益颇多,机器人的制作需要机械和电控两方面 昨天参与舵机的测试,遇到的问题:舵机不动 排查 ...
- 大数据计算平台Spark内核全面解读
1.Spark介绍 Spark是起源于美国加州大学伯克利分校AMPLab的大数据计算平台,在2010年开源,目前是Apache软件基金会的顶级项目.随着Spark在大数据计算领域的暂露头角,越来越多的 ...
随机推荐
- 16.Nginx优化与防盗链
Nginx优化与防盗链 目录 Nginx优化与防盗链 隐藏版本号 修改用户与组 缓存时间 日志切割 小知识 连接超时 更改进程数 配置网页压缩 配置防盗链 配置防盗链 隐藏版本号 可以使用 Fiddl ...
- SAP Web Dynpro - 应用程序中的服务调用
您可以使用服务调用来调用Web Dynpro组件中的现有功能模块. 要创建服务呼叫,您可以使用Web Dynpro工具中易于使用的向导. 您可以在ABAP工作台中启动该向导以创建服务调用. 步骤1-选 ...
- LayUI+SSM实现一个简单的后台管理系统
该后台管理系统是用于管理视频网站数据的,目前分5个菜单项,这篇博客主要讲述[影片管理]的具体功能和实现 后台代码结构和[影片管理]的界面如下图 该界面分为上下2部分,[搜索条件]和[影片列表],2部分 ...
- QT与DoNet中单例模式的简单实现
由于使用场景的不同,单例模式的写法也有所区别. 目前接触到的,大多数都是多线程,大量数据处理,还要考虑灵活性,对原有类结构改动最小等因素,所以写法更是多种多样. QT个人较常用的一种写法:(两个文件: ...
- 简单性能测试:springboot-2.x vs actix-web-4.x benchmark
性能测试:springboot-2.x vs actix-web-4.x benchmark 转载请注明出处 https://www.cnblogs.com/funnyzpc/p/15956465.h ...
- 一文搞懂 Netty 发送数据全流程 | 你想知道的细节全在这里
欢迎关注公众号:bin的技术小屋,如果大家在看文章的时候发现图片加载不了,可以到公众号查看原文 本系列Netty源码解析文章基于 4.1.56.Final版本 在<Netty如何高效接收网络数据 ...
- 今天介绍一下自己的开源项目,一款以spring cloud alibaba为核心的微服务架构项目,为给企业与个人提供一个零开发基础的微服务架构。
LaoCat-Spring-Cloud-Scaffold 一款以spring cloud alibab 为核心的微服务框架,主要目标为了提升自己的相关技术,也为了给企业与个人提供一个零开发基础的微服务 ...
- idea 错误: 找不到或无法加载主类 xx.xxx.Application
原因module 里面缺少iml文件 生成iml文件方法二:(建议):刷新一下Maven Project就会自动生成.iml文件.点击下图红框标记的按钮即可 完成后就会自动生成.iml文件. 方法二: ...
- 华为云Stack南向开放框架,帮助生态伙伴高效入云
摘要:CloudBonder的生态社区通过一系列生态项目,解决提交叉组合.架构分层不清晰.运维界面不清晰等问题,简化对接流程,降低生态伙伴对接成本,缩短对接时间. 本文分享自华为云社区<[华为云 ...
- 树莓派Raspiberry 编译Linux实时内核PREEMPT-RT 实战
树莓派4B 实时内核(Preempt_RT)的配置和编译https://blog.csdn.net/zlp_zky/article/details/114994444 基本按照这个blog来操作. 几 ...