mysql 8.0.28 查询语句执行顺序实测结果
TL;NRs
根据实测结果,MySQL8.0.28 中 SQL 语句的执行顺序为:
(8) SELECT
(5) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(4) ON <join_condition>
(2) WHERE <where_condition>
(6) GROUP BY <group_by_list>
(7) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
引言
关于 SQL 语句的执行顺序,常见的是以下版本。然而该版本却与实测结果不符。
(7) SELECT
(8) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(6) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
MySQL 可以通过 EXPLAIN ANALYZE sql_statement 显示真实的执行过程。那么可以通过一个复杂的语句完成测试。
准备数据
准备三个表 t1, t2, t3, 其中数据分别为:
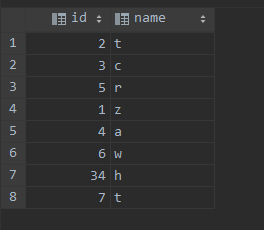
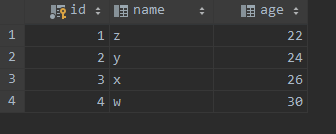

测试
执行以下语句
EXPLAIN ANALYZE
SELECT
DISTINCT COUNT(p.id) AS cnt, COUNT(e.id) AS nn
FROM t1 p
LEFT JOIN t2 q ON p.id > q.id
INNER JOIN t2 w ON q.id < w.id
RIGHT JOIN t3 e ON w.id = e.id
WHERE p.id < 10
GROUP BY p.id
HAVING cnt > 3
ORDER BY cnt DESC, nn DESC
LIMIT 1;
结果为:
-> Limit: 10 row(s) (actual time=0.394..0.395 rows=1 loops=1)
-> Sort with duplicate removal: cnt DESC, nn DESC (actual time=0.393..0.394 rows=1 loops=1)
-> Filter: (cnt > 3) (actual time=0.372..0.374 rows=5 loops=1)
-> Table scan on <temporary> (actual time=0.001..0.001 rows=6 loops=1)
-> Aggregate using temporary table (actual time=0.370..0.372 rows=6 loops=1)
-> Inner hash join (e.id = w.id) (cost=4.73 rows=3) (actual time=0.314..0.324 rows=32 loops=1)
-> Table scan on e (cost=0.13 rows=5) (actual time=0.008..0.016 rows=5 loops=1)
-> Hash
-> Filter: (q.id < w.id) (cost=3.15 rows=3) (actual time=0.265..0.282 rows=32 loops=1)
-> Inner hash join (no condition) (cost=3.15 rows=3) (actual time=0.259..0.271 rows=72 loops=1)
-> Covering index scan on w using PRIMARY (cost=0.13 rows=3) (actual time=0.007..0.010 rows=4 loops=1)
-> Hash
-> Nested loop inner join (cost=2.10 rows=3) (actual time=0.084..0.232 rows=18 loops=1)
-> Filter: (p.id < 10) (cost=1.05 rows=3) (actual time=0.036..0.051 rows=7 loops=1)
-> Table scan on p (cost=1.05 rows=8) (actual time=0.034..0.046 rows=8 loops=1)
-> Filter: (p.id > q.id) (cost=0.13 rows=1) (actual time=0.021..0.025 rows=3 loops=7)
-> Covering index range scan on q (re-planned for each iteration) (cost=0.13 rows=3) (actual time=0.021..0.024 rows=3 loops=7)
结果分析
这是一个调用栈,还原其执行过程为:
筛选 LIMIT 10 {
排序 ORDER BY cnt DESC, nn DESC {
调用 HAVING cnt > 3 过滤器 {
读取临时聚合表 {
聚合 {
第三次联结 RIGHT JOIN t3 e ON w.id = e.id {
扫描表 e ;
第二次联结 INNER JOIN t2 w ON q.id < w.id {
扫描表 w {
使用主键扫描
得到 4 行
}
第一次联结 t1 p LEFT JOIN t2 q ON p.id > q.id {
扫描表 p {
使用 WHERE p.id < 10 过滤器
共 8 行,返回 7 行
}
循环扫描表 q {
7 次循环 {
使用过滤器 ON p.id > q.id
}
}
执行哈希,共 21 行,返回 18 行
}
执行全连接,获得 4 * 18 = 72 行
执行 ON q.id < w.id 过滤器,剩余 32 行
}
执行相等联结 e.id = w.id, 返回 32 行
}
完成所有的联结,获得 32 行
进行聚合 GROUP BY p.id 获得 6 行
}
读取临时聚合表,获得 6 行
}
执行过滤,剩余 5 行
}
去重,剩余 2 行
排序
返回 1 行
}
输出前 1 项
}
可以看到:
- 首先进行表的扫描,也就是所谓的 FROM 第一
- 有主键的表会使用主键索引
- 有索引的表会使用索引
- 有多个表需要扫描时,根据 SQL 语句进行倒序执行
- WHERE 会在表的扫描过程中执行,也就是 WHERE 第二
- 读取到表后,会执行连接
- 有多个联结时,同样是倒序执行
- 首先执行全连接,也就是 JOIN 第三
- 全连接完成后会马上执行 ON 的过滤,也就是 ON 第四
- 完成连接后,会执行去重,也就是 DISTINCT 第五
- 完成去重后,会进行上一层的连接
- 所有连接都完成后,会执行聚合,也就是 GROUP BY 第六
- 聚合完成后,会执行一次扫描,也就是 SELECT 第七
- 扫描结束后,会执行 HAVING 过滤,也就是 HAVING 第八
- 完成过滤后,会进行排序,也就是 ORDER BY 第九
- 最后进行 LIMIT 的限制,也就是 LIMIT 第十
- 需要注意的是,LIMIT 的参数在 sort 函数的返回结果中就已经起作用,合理推测是使用的堆排序
结论
根据实测结果,MySQL8.0.28 中 SQL 语句的执行顺序为:
(8) SELECT
(5) DISTINCT <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(4) ON <join_condition>
(2) WHERE <where_condition>
(6) GROUP BY <group_by_list>
(7) HAVING <having_condition>
(9) ORDER BY <order_by_condition>
(10) LIMIT <limit_number>
mysql 8.0.28 查询语句执行顺序实测结果的更多相关文章
- python 3 mysql sql逻辑查询语句执行顺序
python 3 mysql sql逻辑查询语句执行顺序 一 .SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_t ...
- mysql第四篇--SQL逻辑查询语句执行顺序
mysql第四篇--SQL逻辑查询语句执行顺序 一.SQL语句定义顺序 SELECT DISTINCT <select_list> FROM <left_table> < ...
- SQL逻辑查询语句执行顺序 需要重新整理
一.SQL语句定义顺序 1 2 3 4 5 6 7 8 9 10 SELECT DISTINCT <select_list> FROM <left_table> <joi ...
- SQL学习笔记四(补充-1-1)之MySQL单表查询补充部分:SQL逻辑查询语句执行顺序
阅读目录 一 SELECT语句关键字的定义顺序 二 SELECT语句关键字的执行顺序 三 准备表和数据 四 准备SQL逻辑查询测试语句 五 执行顺序分析 一 SELECT语句关键字的定义顺序 SELE ...
- mysql五补充部分:SQL逻辑查询语句执行顺序
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
- mysql 逻辑查询语句执行顺序
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
- Mysql补充部分:SQL逻辑查询语句执行顺序
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
- 45、SQL逻辑查询语句执行顺序
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
- 第四篇:记录相关操作 SQL逻辑查询语句执行顺序
http://www.cnblogs.com/linhaifeng/articles/7372774.html 一 SELECT语句关键字的定义顺序 SELECT DISTINCT <selec ...
随机推荐
- vue项目|在弹窗中引入uchart图表子组件不显示
为了解决uchart作为子组件在主组件里引用但不显示的情况,(同样适用于弹窗之中)目前有三种方法. 1-解决方式 1>如果你使用的uchart子组件是从官方拿的例子:进入到uchart子组件将o ...
- 记一次前端CryptoJS AES解密
1.背景 业务需求,需要联动多个平台,涉及到各平台的模拟登录. 已知加密前明文且正常登录.(无验证码要求) 某平台验证验证方式为.\login接口POST一串json字符串 { "accou ...
- AR Engine运动跟踪能力,高精度实现沉浸式AR体验
随着电子产品的普遍应用,AR技术也开始广泛普及,在游戏.电商.家装等领域都有涉及.比如,在室内设计时,我们可以通过AR技术在实际场景中进行虚拟软装的搭配,运用华为AR Engine运动跟踪能力在实际应 ...
- 【转载】浅谈大规模k8s集群关于events的那些坑
原文链接:一流铲屎官二流程序员[浅谈大规模k8s集群关于events的那些坑] 背景 随着k8s集群规模的增加,集群内的object数量也与日俱增,那么events的数量也会伴随其大量增加,那么当用户 ...
- .NET中的 Count()、Count、Length 有什么不同
更新记录 2022年4月16日:本文迁移自Panda666原博客,原发布时间:2021年7月15日. Count().Count.Length,都用于获得序列长度或者说元素的个数,但它们有什么明确的区 ...
- 打通web的三维国产引擎!老子云AMRT,够牛!
AMRT(Auto Mobile Reality Technology)指的是自动化移动现实技术,它是老子云3D模型自动轻量化引擎及轻量化模型格式.模型展示框架.API/SDK的统称.3D研发技术其中 ...
- sublime_text 3安装Emmet时出现PyV8警告
使用Emmet是需要在PyV8依赖下才可以的.1. 下面是下载网址:PyV8下载地址 下载自己系统版本的压缩包,然后解压,自己创建一个名为PyV8文件夹.将解压后的文件放入该文件夹里. 打开首选项里的 ...
- SprinigBoot自定义Starter
自定义Starter 是什么 starter可以理解是一组封装好的依赖包,包含需要的组件和组件所需的依赖包,使得使用者不需要再关注组件的依赖问题 所以一个staerter包含 提供一个autoconf ...
- SAP Html viewer
1 *&---------------------------------------------------------------------* 2 *& Report RSDEM ...
- centos7.6部署DRBD提示“no resources defined!
环境准备: node1(主节点)IP: 192.168.26.30 主机名:node1node2(从节点)IP: 192.168.26.31 主机名:node2 1.关闭防火墙和selinux #se ...