开发实践丨昇腾CANN的推理应用开发体验
摘要:这是关于一次 Ascend 在线实验的记录,主要内容是通过网络模型加载、推理、结果输出的部署全流程展示,从而快速熟悉并掌握 ACL(Ascend Computing Language)基本开发流程。
本文分享自华为云社区《基于昇腾CANN的推理应用开发快速体验(Python)》,作者: Tianyi_Li 。
前情提要
这是关于一次 Ascend 在线实验的记录,主要内容是通过网络模型加载、推理、结果输出的部署全流程展示,从而快速熟悉并掌握 ACL(Ascend Computing Language)基本开发流程。
注意,为了保证学习和体验效果,用户应该具有以下知识储备:
1.熟练的Python语言编程能力
2.深度学习基础知识,理解神经网络模型输入输出数据结构
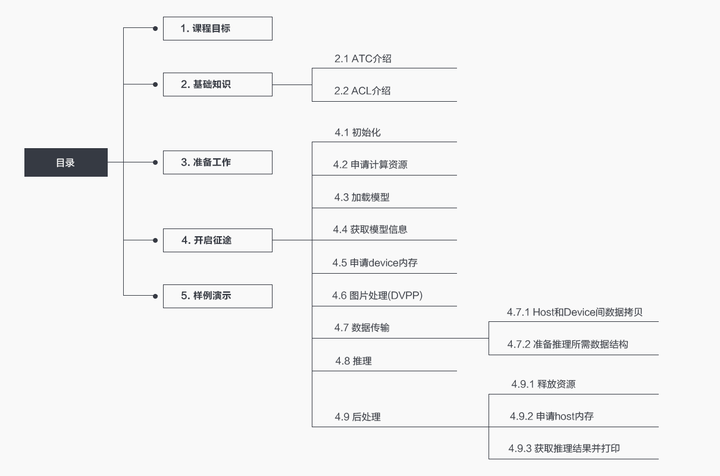
1. 目录
2. 最终目标

1.了解ACL的基本概念,清楚ACL具备哪些能力,能为我们做什么
2.了解ACL定义的编程模型,理解各类运行资源的概念及其相互关系
3.能够区分Host和Device的概念,并学会管理这两者各自的内存
4.加载一个离线模型进行推理,并为推理准备输入输出数据结构
3. 基础知识
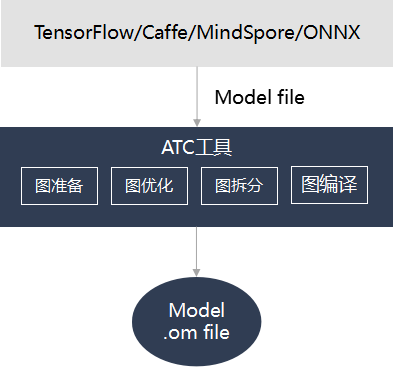
3.1 ATC介绍
ATC(Ascend Tensor Compiler)是华为昇腾软件栈提供的一个编译工具,它的主要功能是将基于开源框架的网络模型(如 Caffe、TensorFlow 等)以及单算子 Json 文件,转换成昇腾AI处理器支持的离线模型 Offline-Model 文件(简称OM文件)。在编译过程中,可以实现算子调度的优化、权值数据重排、内存使用优化等,并且可以脱离设备完成模型的预处理。更详细的ATC介绍,可参看官方文档 。
需要说明的是,理论上对于华为自研 AI 计算框架 MindSpore 的支持会更加友好。
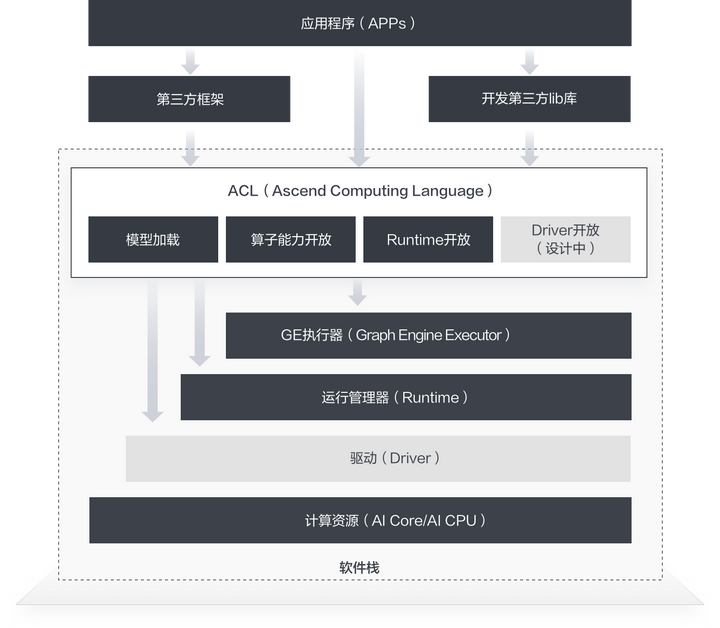
3.2 ACL介绍
对已训练好的权重文件,比如 Caffe框架下的 caffemodel, TensorFlow框架下得到的 checkpoint 或者 pb 文件,再经过 ATC 工具转换后得到的离线模型文件,ACL(Ascend Computing Language,昇腾计算语言)提供了一套用于在昇腾系列处理器上进行加速计算的API。基于这套API,您能够管理和使用昇腾软硬件计算资源,并进行机器学习相关计算。更详细的ACL介绍,可参看官方文档 。
最新版本支持 onnx 模型和 MindSpore 模型转换为离线模型文件,甚至可以直接通过MindSpore进行部署和推理。
当前 ACL 提供了 C/C++ 和 Python 编程接口,能够很方便的帮助开发者达成包括但不限于如下这些目标:
1.加载深度学习模型进行推理
2.加载单算子进行计算
3.图像、视频数据的预处理
4. 准备工作
最终结果是使用 Resnet50 对 3 张图片进行分类推理。为了达成这个结果,首先我们准备了如下两个素材:
- 三张待推理分类的图片数据,如:

- 使用ATC工具,将 tensorflow 的 googlenet.pb 模型转换成昇腾支持的om(offine-model) 文件。
推理后我们将打印每张图片置信度排前5位的标签及其置信度。
5. 开始
5.1 初始化
在开始调用ACL的任何接口之前,首先要做ACL的初始化。初始化的代码很简单,只有一行:
- acl.init(config_path)
这个接口调用会帮您准备好ACL的运行时环境。其中调用时传入的参数是一个配置文件在磁盘上的路径,这里暂时不必关注。
有初始化就有去初始化,在确定完成了ACL的所有调用之后,或者进程退出之前,要做去初始化操作,接口调用也十分简单:
- acl.finalize()
导入Python包:
- import argparse
- import numpy as np
- import struct
- import acl
- import os
- from PIL import Image
接口介绍:

函数示例:
- def init():
- ret = acl.init()
- check_ret("acl.init", ret)
5.2 申请计算资源
想要使用昇腾处理器提供的加速计算能力,需要对运行管理资源申请,包括Device、Context、Stream。且需要按顺序申请,主要涉及以下三个接口:
- acl.rt.set_device(device_id)
这个接口指定计算设备,告诉运行时环境我们想要用哪个设备,或者更具体一点,哪个芯片。但是要注意,芯片和我们在这里传入的编号之间并没有物理上的一一对应关系。
- acl.rt.create_context(device_id)
Context作为一个容器,管理了所有对象(包括Stream、Event、设备内存等)的生命周期。不同Context的Stream、不同Context的Event是完全隔离的,无法建立同步等待关系。个人理解为,如果计算资源足够的话,可以创建多个Context,分别运行不同的应用,来提高硬件利用率,而不用担心应用之间的互相干扰,类似于Docker。
- acl.rt.create_stream()
Stream用于维护一些异步操作的执行顺序,确保按照应用程序中的代码调用顺序在Device上执行。基于Stream的kernel执行和数据传输能够实现Host运算操作、Host与Device间的数据传输、Device内的运算并行。
接口介绍:



函数示例:
- import sys
- import os
- from IPython.core.interactiveshell import InteractiveShell
- InteractiveShell.ast_node_interactivity = "all"
- home_path = !echo ${HOME}
- sys.path.append(os.path.join(home_path[0] , "jupyter-notebook/"))
- print('System init success.')
- # atlas_utils是本团队基于pyACL封装好的一套工具库,如果您也想引用的话,请首先将
- # https://gitee.com/ascend/samples/tree/master/python/common/atlas_utils
- # 这个路径下的代码引入您的工程中
- from atlas_utils.acl_resource import AclResource
- from constants import *
- # 创建一个AclResource类的实例
- acl_resource = AclResource()
- #AscendCL资源初始化(封装版本)
- acl_resource.init()
- # 上方“init”方法具体实现(仅供参考)
- # 请阅读“init(self)”方法,观察初始化和运行时资源申请的详细操作步骤
- def init(self):
- """
- Init resource
- """
- print("init resource stage:")
- ret = acl.init()
- utils.check_ret("acl.init", ret)
- #指定用于运算的Device
- ret = acl.rt.set_device(self.device_id)
- utils.check_ret("acl.rt.set_device", ret)
- print("Set device n success.")
- #显式创建一个Context
- self.context, ret = acl.rt.create_context(self.device_id)
- utils.check_ret("acl.rt.create_context", ret)
- #创建一个Stream
- self.stream, ret = acl.rt.create_stream()
- utils.check_ret("acl.rt.create_stream", ret)
- #获取当前昇腾AI软件栈的运行模式
- #0:ACL_DEVICE,表示运行在Device的Control CPU上或开发者版上
- #1:ACL_HOST,表示运行在Host CPU上
- self.run_mode, ret = acl.rt.get_run_mode()
- utils.check_ret("acl.rt.get_run_mode", ret)
- print("Init resource success")
需要说明的是这里使用了 atlas_utils ,这是昇腾团队基于 pyACL 封装好的一套工具库,可以更加便捷的使用,但可能存在更新不及时的问题,也不易于优化提升,以及个人学习理解,建议能不用,则不用。
5.3 加载模型
既然要调用模型进行推理,首先当然是要把模型加载进来。ACL 提供了多种模型加载和内存管理方式,这里我们只选取其中相对简单的一种,即从磁盘上加载离线模型,并且加载后的模型内存由ACL自动管理:
- model_path = "./model/resnet50.om"; # 模型文件在磁盘上的路径
- model_id, ret = acl.mdl.load_from_file(model_path) # 加载模型
其中,model_id 是系统完成模型加载后生成的模型ID对应的指针对象,加载后生成的model_id,全局唯一。
记得这个“model_id”,后边我们使用模型进行推理,以及卸载模型的时候还要用到。
有加载自然就有卸载,模型卸载的接口比较简单:
- acl.mdl.unload(model_id)
至此,您脑海中应该有这样一个概念,即使用了任何的资源,加载了任何的素材,都要记得用完后销毁和卸载。这点对于使用 C/C++编程的同学应该很好理解。
接口介绍:

函数示例:
- def load_model(model_path):
- model_path = "./model/googlenet_yuv.om"
- model_id, ret = acl.mdl.load_from_file(model_path)
- check_ret("acl.mdl.load_from_file", ret)
- return model_id
5.4 获取模型信息
模型描述需要特殊的数据类型,使用以下函数来创建并获取该数据类型。
- acl.mdl.create_desc()
- acl.mdl.get_desc(model_desc, model_id)
获取到模型类型后,还需要根据该类型来获取模型的输入输出个数,调用函数如下:
- acl.mdl.get_num_inputs(model_desc)
- acl.mdl.get_num_outputs(model_desc)
接口介绍:

函数示例:
- def get_model_data(model_id):
- global model_desc
- model_desc = acl.mdl.create_desc()
- ret = acl.mdl.get_desc(model_desc, model_id)
- check_ret("acl.mdl.get_desc", ret)
- input_size = acl.mdl.get_num_inputs(model_desc)
- output_size = acl.mdl.get_num_outputs(model_desc)
- return input_size, output_size
5.5 申请device内存
要使用 NPU 进行加速计算,首先要申请能够被 NPU 直接访问到的专用内存。在讲解内存申请之前,首先我们要区分如下两个概念:
Host:Host指与Device相连接的X86服务器、ARM服务器,会利用Device提供的NN(Neural-Network )计算能力,完成业务。
Device:Device指安装了芯片的硬件设备,利用PCIe接口与Host侧连接,为Host提供NN计算能力。
简而言之,我们的数据需要先从Host侧进行加载,即读进Host侧内存,随后将其拷贝到Device侧内存,才能进行计算。计算后的结果还要传回Host侧才能进行使用。
申请Device侧内存:
- dev_ptr, ret = acl.rt.malloc(size, policy) # 申请device侧内存
其中,dev_ptr是device侧内存指针,size是device侧内存大小。
这里我们分配了跟Host侧同样大小的内存,准备用于在Device侧存放推理数据。本接口最后一个参数policy是内存分配规则。
- ACL_MEM_MALLOC_HUGE_FIRST ----- 优先申请大页内存,如果大页内存不够,则使用普通页的内存。
- ACL_MEM_MALLOC_HUGE_ONLY ----- 仅申请大页,如果大页内存不够,则返回错误。
- ACL_MEM_MALLOC_NORMAL_ONLY ----- 仅申请普通页。
使用完别忘了释放申请过的内存:acl.rt.malloc-> acl.rt.free,切记!!!
接口介绍:

函数示例:
- def gen_data_buffer(size, des):
- global model_desc
- func = buffer_method[des]
- for i in range(size):
- temp_buffer_size = acl.mdl.get_output_size_by_index(model_desc, i)
- temp_buffer, ret = acl.rt.malloc(temp_buffer_size,
- const.ACL_MEM_MALLOC_NORMAL_ONLY)
- check_ret("acl.rt.malloc", ret)
- if des == "in":
- input_data.append({"buffer": temp_buffer,
- "size": temp_buffer_size})
- elif des == "out":
- output_data.append({"buffer": temp_buffer,
- "size": temp_buffer_size})
- def malloc_device(input_num, output_num):
- gen_data_buffer(input_num, des="in")
- gen_data_buffer(output_num, des="out")
5.6 图片处理(DVPP)
数字视觉预处理模块(DVPP)作为昇腾AI软件栈中的编解码和图像转换模块,为神经网络发挥着预处理辅助功能。当来自系统内存和网络的视频或图像数据进入昇腾AI处理器的计算资源中运算之前,由于Davinci架构对输入数据有固定的格式要求,如果数据未满足架构规定的输入格式、分辨率等要求,就需要调用数字视觉处理模块进行格式的转换,才可以进行后续的神经网络计算步骤。
DVPP相关接口介绍:
读取、初始化图片:
- AclImage(image_file)
图片预处理:
- yuv_image=jpegd(image)
将输入图片缩放为输出尺寸:
- resized_image = _dvpp.resize(yuv_image, MODEL_WIDTH, MODEL_HEIGHT)
函数示例:
- def image_process_dvpp():
- global run_mode
- global images_list
- stream, ret = acl.rt.create_stream()
- check_ret("acl.rt.create_stream", ret)
- run_mode, ret = acl.rt.get_run_mode()
- check_ret("acl.rt.get_run_mode", ret)
- _dvpp = Dvpp(stream, run_mode)
- _dvpp.init_resource()
- IMG_EXT = ['.jpg', '.JPG', '.png', '.PNG', '.bmp', '.BMP', '.jpeg', '.JPEG']
- images_list = [os.path.join("./data", img)
- for img in os.listdir("./data")
- if os.path.splitext(img)[1] in IMG_EXT]
- img_list = []
- for image_file in images_list:
- image = AclImage(image_file)
- image_input = image.copy_to_dvpp()
- yuv_image = _dvpp.jpegd(image_input)
- resized_image = dvpp.resize(yuv_image,
- MODEL_WIDTH, MODEL_HEIGHT)
- img_list.append(resized_image)
- print("dvpp_process image: {} success".format(image_file))
- return img_list
5.7 数据传输
5.7.1 host传输数据至device
把数据从Host侧拷贝至Device侧:
- acl.rt.memcpy(dst, dest_max, src, count, direction)
参数的顺序是:目的内存地址,目的内存最大大小,源内存地址,拷贝长度,拷贝方向。
direction拷贝方向当前支持四种:
- ACL_MEMCPY_HOST_TO_HOST ----- host->host
- ACL_MEMCPY_HOST_TO_DEVICE ----- host->device
- ACL_MEMCPY_DEVICE_TO_HOST ----- device->host
- ACL_MEMCPY_DEVICE_TO_DEVICE ----- device->device
该步骤已在DVPP接口内自动完成。
接口介绍:


函数示例:
- def _data_interaction_in(dataset):
- global input_data
- temp_data_buffer = input_data
- for i in range(len(temp_data_buffer)):
- item = temp_data_buffer[i]
- ptr = acl.util.numpy_to_ptr(dataset)
- ret = acl.rt.memcpy(item["buffer"],
- item["size"],
- ptr,
- item["size"],
- ACL_MEMCPY_HOST_TO_DEVICE)
- check_ret("acl.rt.memcpy", ret)
5.7.2 准备推理所需数据结构
模型推理所需的输入输出数据,是通过一种特定的数据结构来组织的,这种数据结构叫“dataSet”,即所有的输入,组成了1个dateset,所有的输出组成了一个dataset。而对于很多模型来讲,输入其实不止一个,那么所有的输入集合叫“dataSet”,其中的每一个输入叫什么呢?
答案是“dataBuffer”。即一个模型的多个输入,每个输入是一个“dataBuffer”,所有的dataBuffer构成了一个“dataSet”。
下面我们从构建dataBuffer开始。
dataBuffer的创建很简单,还记得前边我们申请了Device侧的内存,并且把数据传过去了吗?现在要用到了。我们当时的device侧内存地址:data,这段内存的长度:size。使用上边两个对象来创建一个dataBuffer:
- acl.create_data_buffer(data, size)
现在,这个“buffer”就是我们的第一个输入了。
接口介绍:

函数示例:
- def create_buffer(dataset, type="in"):
- global input_data, output_data
- if type == "in":
- temp_dataset = input_data
- else:
- temp_dataset = output_data
- for i in range(len(temp_dataset)):
- item = temp_dataset[i]
- data = acl.create_data_buffer(item["buffer"], item["size"])
- if data is None:
- ret = acl.destroy_data_buffer(dataset)
- check_ret("acl.destroy_data_buffer", ret)
- _, ret = acl.mdl.add_dataset_buffer(dataset, data)
- if ret != ACL_ERROR_NONE:
- ret = acl.destroy_data_buffer(dataset)
- check_ret("acl.destroy_data_buffer", ret)
针对本实验所用到的 resnet50 模型,我们只需要一个输入即可,那现在有了dataBuffer,要如何构建dataSet呢?
很简单:
- acl.mdl.create_dataset()
dataset有了,下面就是向这个dataset中放置DataBuffer了:
- acl.mdl.add_dataset_buffer(dataset, data)
这样,我们在dataset中添加了一个databuffer,输入准备好了。
创建输出数据结构同理,当您拿到一个模型,您应该是清楚这个模型的输出数据结构的,根据其输出个数、每个输出占用内存的大小来申请相应的device内存、dataBuffer以及dataSet即可。
现在假设我们已经创建好了输出的dataset,其变量名称叫做:
outputDataSet
至此,我们准备好了推理所需的所有素材。
当然,将来用完之后别忘了销毁:
- acl.create_data_buffer-> acl.destory_data_buffer; acl.mdl.create_dataset-> acl.mdl.destroy_dataset
接口介绍:



函数实例:
- def _gen_dataset(type="in"):
- global load_input_dataset, load_output_dataset
- dataset = acl.mdl.create_dataset()
- if type == "in":
- load_input_dataset = dataset
- else:
- load_output_dataset = dataset
- create_buffer(dataset, type)
5.8 推理
所有素材准备好之后,模型推理已经是顺理成章的事情了,还记得我们的几个关键素材吗?
- model_id
- load_input_dataset
- load_output_dataset
最终的推理,其实只需要一行代码:
- ret = acl.mdl.execute(model_id, input, output)
这是个同步接口,线程会阻塞在这里直到推理结束。推理结束后就可以提取load_output_dataset中的数据进行使用了。
接口介绍:

函数示例:
- def inference(model_id, _input, _output):
- global load_input_dataset, load_output_dataset
- ret = acl.mdl.execute(model_id,
- load_input_dataset,
- load_output_dataset)
- check_ret("acl.mdl.execute", ret)
5.9 后处理
5.9.1释放资源
资源有申请就要有释放,调用以下接口释放之前申请的dataset和databuffer:
- ret = acl.mdl.destroy_dataset(dataset)
- ret = acl.destory_data_buffer(data_buffer)
接口介绍:

函数示例:
- def _destroy_data_set_buffer():
- global load_input_dataset, load_output_dataset
- for dataset in [load_input_dataset, load_output_dataset]:
- if not dataset:
- continue
- num = acl.mdl.get_dataset_num_buffers(dataset)
- for i in range(num):
- data_buf = acl.mdl.get_dataset_buffer(dataset, i)
- if data_buf:
- ret = acl.destroy_data_buffer(data_buf)
- check_ret("acl.destroy_data_buffer", ret)
- ret = acl.mdl.destroy_dataset(dataset)
- check_ret("acl.mdl.destroy_dataset", ret)
5.9.2 申请host内存
建立outputDataset的时候,您应该使用了device侧的内存,将这部分内存拷贝回host侧,即可直接使用了。
申请Host侧内存:
host_ptr是host侧内存指针,随后即可使用host_ptr指向的内存来暂存推理输入数据。把数据从device侧拷贝至host侧:
- ret = acl.rt.memcpy(dst, dest_max, src, count, direction)
参数的顺序是:目的内存地址,目的内存最大大小,源内存地址,拷贝长度,拷贝方向。(支持host->host, host->device, device->host, device->device四种,与申请device内存相同)
使用完别忘了释放申请过的内存:
- acl.rt.malloc_host-> acl.rt.free_host
接口介绍:

函数示例:
- def _data_interaction_out(dataset):
- global output_data
- temp_data_buffer = output_data
- if len(dataset) == 0:
- for item in output_data:
- temp, ret = acl.rt.malloc_host(item["size"])
- if ret != 0:
- raise Exception("can't malloc_host ret={}".format(ret))
- dataset.append({"size": item["size"], "buffer": temp})
- for i in range(len(temp_data_buffer)):
- item = temp_data_buffer[i]
- ptr = dataset[i]["buffer"]
- ret = acl.rt.memcpy(ptr,
- item["size"],
- item["buffer"],
- item["size"],
- ACL_MEMCPY_DEVICE_TO_HOST)
- check_ret("acl.rt.memcpy", ret)
5.9.3 获取推理结果并打印
将推理后的结果数据转换为numpy类型,然后按照图片分类置信度前五的顺序打印出来。
结果示例如下:

接口介绍:

函数示例:
- def print_result(result):
- global images_list, INDEX
- dataset = []
- for i in range(len(result)):
- temp = result[i]
- size = temp["size"]
- ptr = temp["buffer"]
- data = acl.util.ptr_to_numpy(ptr, (size,), 1)
- dataset.append(data)
- st = struct.unpack("1000f", bytearray(dataset[0]))
- vals = np.array(st).flatten()
- top_k = vals.argsort()[-1:-6:-1]
- print()
- print("======== image: {} =============".format(images_list[INDEX]))
- print("======== top5 inference results: =============")
- INDEX+=1
- for n in top_k:
- object_class = get_image_net_class(n)
- print("label:%d confidence: %f, class: %s" % (n, vals[n], object_class))
6. 完整样例演示
ACL完整程序示例:
- import argparse
- import numpy as np
- import struct
- import acl
- import os
- from PIL import Image
- import sys
- home_path = get_ipython().getoutput('echo ${HOME}')
- sys.path.append(os.path.join(home_path[0] , "jupyter-notebook/"))
- print('System init success.')
- from src.acl_dvpp import Dvpp
- import src.constants as const
- from src.acl_image import AclImage
- from src.image_net_classes import get_image_net_class
- WORK_DIR = os.getcwd()
- ACL_MEM_MALLOC_HUGE_FIRST = 0
- ACL_MEMCPY_HOST_TO_DEVICE = 1
- ACL_MEMCPY_DEVICE_TO_HOST = 2
- ACL_ERROR_NONE = 0
- MODEL_WIDTH = 224
- MODEL_HEIGHT = 224
- IMG_EXT = ['.jpg', '.JPG', '.png', '.PNG', '.bmp', '.BMP', '.jpeg', '.JPEG']
- ret = acl.init()
- # GLOBAL
- load_input_dataset = None
- load_output_dataset = None
- input_data = []
- output_data = []
- _output_info = []
- images_list = []
- model_desc = 0
- run_mode = 0
- INDEX = 0
- if WORK_DIR.find("src") == -1:
- MODEL_PATH = WORK_DIR + "/src/model/googlenet_yuv.om"
- DATA_PATH = WORK_DIR + "/src/data"
- else:
- MODEL_PATH = WORK_DIR + "/model/googlenet_yuv.om"
- DATA_PATH = WORK_DIR + "/data"
- buffer_method = {
- "in": acl.mdl.get_input_size_by_index,
- "out": acl.mdl.get_output_size_by_index
- }
- def check_ret(message, ret):
- if ret != ACL_ERROR_NONE:
- raise Exception("{} failed ret={}"
- .format(message, ret))
- def init():
- ret = acl.init()
- check_ret("acl.init", ret)
- print("init success")
- def allocate_res(device_id):
- ret = acl.rt.set_device(device_id)
- check_ret("acl.rt.set_device", ret)
- context, ret = acl.rt.create_context(device_id)
- check_ret("acl.rt.create_context", ret)
- print("allocate_res success")
- return context
- def load_model(model_path):
- model_id, ret = acl.mdl.load_from_file(model_path)
- check_ret("acl.mdl.load_from_file", ret)
- print("load_model success")
- return model_id
- def get_model_data(model_id):
- global model_desc
- model_desc = acl.mdl.create_desc()
- ret = acl.mdl.get_desc(model_desc, model_id)
- check_ret("acl.mdl.get_desc", ret)
- input_size = acl.mdl.get_num_inputs(model_desc)
- output_size = acl.mdl.get_num_outputs(model_desc)
- print("get_model_data success")
- return input_size, output_size
- def gen_data_buffer(num, des):
- global model_desc
- func = buffer_method[des]
- for i in range(num):
- #temp_buffer_size = (model_desc, i)
- temp_buffer_size = acl.mdl.get_output_size_by_index(model_desc, i)
- temp_buffer, ret = acl.rt.malloc(temp_buffer_size,
- const.ACL_MEM_MALLOC_NORMAL_ONLY)
- check_ret("acl.rt.malloc", ret)
- if des == "in":
- input_data.append({"buffer": temp_buffer,
- "size": temp_buffer_size})
- elif des == "out":
- output_data.append({"buffer": temp_buffer,
- "size": temp_buffer_size})
- def malloc_device(input_num, output_num):
- gen_data_buffer(input_num, des="in")
- gen_data_buffer(output_num, des="out")
- def image_process_dvpp(dvpp):
- global run_mode
- global images_list
- # _dvpp.init_resource()
- IMG_EXT = ['.jpg', '.JPG', '.png', '.PNG', '.bmp', '.BMP', '.jpeg', '.JPEG']
- images_list = [os.path.join(DATA_PATH, img)
- for img in os.listdir(DATA_PATH)
- if os.path.splitext(img)[1] in IMG_EXT]
- img_list = []
- for image_file in images_list:
- #读入图片
- image = AclImage(image_file)
- image_input = image.copy_to_dvpp()
- #对图片预处理
- yuv_image = dvpp.jpegd(image_input)
- resized_image = dvpp.resize(yuv_image,
- MODEL_WIDTH, MODEL_HEIGHT)
- img_list.append(resized_image)
- print("dvpp_process image: {} success".format(image_file))
- return img_list
- def _data_interaction_in(dataset):
- global input_data
- temp_data_buffer = input_data
- for i in range(len(temp_data_buffer)):
- item = temp_data_buffer[i]
- ptr = acl.util.numpy_to_ptr(dataset)
- ret = acl.rt.memcpy(item["buffer"],
- item["size"],
- ptr,
- item["size"],
- ACL_MEMCPY_HOST_TO_DEVICE)
- check_ret("acl.rt.memcpy", ret)
- print("data_interaction_in success")
- def create_buffer(dataset, type="in"):
- global input_data, output_data
- if type == "in":
- temp_dataset = input_data
- else:
- temp_dataset = output_data
- for i in range(len(temp_dataset)):
- item = temp_dataset[i]
- data = acl.create_data_buffer(item["buffer"], item["size"])
- if data is None:
- ret = acl.destroy_data_buffer(dataset)
- check_ret("acl.destroy_data_buffer", ret)
- _, ret = acl.mdl.add_dataset_buffer(dataset, data)
- if ret != ACL_ERROR_NONE:
- ret = acl.destroy_data_buffer(dataset)
- check_ret("acl.destroy_data_buffer", ret)
- #print("create data_buffer {} success".format(type))
- def _gen_dataset(type="in"):
- global load_input_dataset, load_output_dataset
- dataset = acl.mdl.create_dataset()
- #print("create data_set {} success".format(type))
- if type == "in":
- load_input_dataset = dataset
- else:
- load_output_dataset = dataset
- create_buffer(dataset, type)
- def inference(model_id, _input, _output):
- global load_input_dataset, load_output_dataset
- ret = acl.mdl.execute(model_id,
- load_input_dataset,
- load_output_dataset)
- check_ret("acl.mdl.execute", ret)
- def _destroy_data_set_buffer():
- global load_input_dataset, load_output_dataset
- for dataset in [load_input_dataset, load_output_dataset]:
- if not dataset:
- continue
- num = acl.mdl.get_dataset_num_buffers(dataset)
- for i in range(num):
- data_buf = acl.mdl.get_dataset_buffer(dataset, i)
- if data_buf:
- ret = acl.destroy_data_buffer(data_buf)
- check_ret("acl.destroy_data_buffer", ret)
- ret = acl.mdl.destroy_dataset(dataset)
- check_ret("acl.mdl.destroy_dataset", ret)
- def _data_interaction_out(dataset):
- global output_data
- temp_data_buffer = output_data
- if len(dataset) == 0:
- for item in output_data:
- temp, ret = acl.rt.malloc_host(item["size"])
- if ret != 0:
- raise Exception("can't malloc_host ret={}".format(ret))
- dataset.append({"size": item["size"], "buffer": temp})
- for i in range(len(temp_data_buffer)):
- item = temp_data_buffer[i]
- ptr = dataset[i]["buffer"]
- ret = acl.rt.memcpy(ptr,
- item["size"],
- item["buffer"],
- item["size"],
- ACL_MEMCPY_DEVICE_TO_HOST)
- check_ret("acl.rt.memcpy", ret)
- def print_result(result):
- global images_list, INDEX
- dataset = []
- for i in range(len(result)):
- temp = result[i]
- size = temp["size"]
- ptr = temp["buffer"]
- data = acl.util.ptr_to_numpy(ptr, (size,), 1)
- dataset.append(data)
- st = struct.unpack("1000f", bytearray(dataset[0]))
- vals = np.array(st).flatten()
- top_k = vals.argsort()[-1:-6:-1]
- print()
- print("======== image: {} =============".format(images_list[INDEX]))
- print("======== top5 inference results: =============")
- INDEX+=1
- for n in top_k:
- object_class = get_image_net_class(n)
- print("label:%d confidence: %f, class: %s" % (n, vals[n], object_class))
- def release(model_id, context):
- global input_data, output_data
- ret = acl.mdl.unload(model_id)
- check_ret("acl.mdl.unload", ret)
- while input_data:
- item = input_data.pop()
- ret = acl.rt.free(item["buffer"])
- check_ret("acl.rt.free", ret)
- while output_data:
- item = output_data.pop()
- ret = acl.rt.free(item["buffer"])
- check_ret("acl.rt.free", ret)
- if context:
- ret = acl.rt.destroy_context(context)
- check_ret("acl.rt.destroy_context", ret)
- context = None
- ret = acl.rt.reset_device(0)
- check_ret("acl.rt.reset_device", ret)
- print('release source success')
- def main():
- global input_data
- #init()
- context = allocate_res(0)
- model_id = load_model(MODEL_PATH)
- input_num, output_num = get_model_data(model_id)
- malloc_device(input_num, output_num)
- dvpp = Dvpp()
- img_list = image_process_dvpp(dvpp)
- for image in img_list:
- image_data = {"buffer":image.data(), "size":image.size}
- input_data[0] = image_data
- _gen_dataset("in")
- _gen_dataset("out")
- inference(model_id, load_input_dataset, load_output_dataset)
- _destroy_data_set_buffer()
- res = []
- _data_interaction_out(res)
- print_result(res)
- release(model_id,context)
- if __name__ == '__main__':
- main()
更多有关ACL的介绍,请详见官方参考文档 。
开发实践丨昇腾CANN的推理应用开发体验的更多相关文章
- WePY - 小程序敏捷开发实践丨掘金开发者大会
声明:内容转载他处,如有侵权,可协商下架 本主题虽然在其它地方讲了很多次,但还是有非常多新内容.因为很多东西正在做或者想要做.本次分享主要分为以下几个部分: WePY 的介绍 WePY 的用户 上面展 ...
- 开发实践丨用小熊派STM32开发板模拟自动售货机
摘要:本文内容是讲述用小熊派开发板模拟自动售货机,基于论坛提供的工程代码,通过云端开发和设备终端开发,实现终端数据在的华为云平台显示. 本文内容是讲述用小熊派开发板模拟自动售货机,基于论坛提供的工程代 ...
- 一键抠除路人甲,昇腾CANN带你识破神秘的“AI消除术”
摘要:都说人工智能改变了生活,你感觉到了么?AI的魔力就在你抠去路人甲的一瞬间来到了你身边.今天就跟大家聊聊--神秘的"AI消除术". 引语 旅途归来,重温美好却被秀丽河山前的路人 ...
- ASP.NET MVC5 网站开发实践(二) Member区域–管理列表、回复及删除
本来想接着上次把这篇写完的,没想到后来工作的一些事落下了,放假了赶紧补上. 目录: ASP.NET MVC5 网站开发实践 - 概述 ASP.NET MVC5 网站开发实践(一) - 项目框架 ASP ...
- ASP.NET MVC5 网站开发实践(二) Member区域–我的咨询列表及添加咨询
上次把咨询的架构搭好了,现在分两次来完成咨询:1.用户部分,2管理部分.这次实现用户部分,包含两个功能,查看我的咨询和进行咨询. 目录: ASP.NET MVC5 网站开发实践 - 概述 ASP.NE ...
- ASP.NET MVC5 网站开发实践(二) Member区域 - 咨询管理的架构
咨询.留言.投诉等功能是网站应具备的基本功能,可以加强管理员与用户的交流,在上次完成文章部分后,这次开始做Member区域的咨询功能(留言.投诉都是咨询).咨询跟文章非常相似,而且内容更少.更简单. ...
- ASP.NET MVC5 网站开发实践(二) Member区域 - 修改及删除文章
上次做了显示文章列表,再实现修改和删除文章这部分内容就结束了,这次内容比较简单,由于做过了添加文章,修改文章非常类似,就是多了一个TryUpdateModel部分更新模型数据. 目录: ASP.N ...
- ASP.NET MVC5 网站开发实践(二) Member区域 - 全部文章列表
显示文章列表分两块,管理员可以显示全部文章列表,一般用户只显示自己的文章列表.文章列表的显示采用easyui-datagrid.后台需要与之对应的action返回json类型数据 目录 ASP.N ...
- ASP.NET MVC5 网站开发实践(二) Member区域 - 添加文章
上次把架构做好了,这次做添加文章.添加文章涉及附件的上传管理及富文本编辑器的使用,早添加文章时一并实现. 要点: 富文本编辑器采用KindEditor.功能很强大,国人开发,LGPL开源,自己人的好东 ...
随机推荐
- gcc和g++是什么,有什么区别?
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 素材来源:C语言中文网 编辑整理:strongerHua ...
- 百度3D离线地图开发,3D离线地图开发,百度地图离线开发
3D离线地图介绍(3D离线采用矢量数据作为地图基础,可保持地图数据最新) 一.开发中引用3D离线地图(可独立部署通过内外IP+端口进行访问,也可拷贝js库文件到项目中通过绝对路径访问) 1).离线AP ...
- 手脱MoleBox(2.3.3-2.6.4)
1.查壳 2.找到OEP 对第二个Call使用ESP定律,再跳转后的位置进入第一个Call,这里就是OEP了,在这里直接dump的话会失败,那是因为MoleBox壳对IAT进行二次跳转,我们先在OEP ...
- KMP算法学习以及小结(好马不吃回头草系列)
首先请允许我对KMP算法的三位创始人Knuth,Morris,Pratt致敬,这三位优秀的算法科学家发明的这种匹配模式可以大大避免重复遍历的情况,从而使得字符串的匹配的速度更快,效率更高. 首先引入对 ...
- C# 编写一个简单易用的 Windows 截屏增强工具
半年前我开源了 DreamScene2 一个小而快并且功能强大的 Windows 动态桌面软件.有很多的人喜欢,这使我有了继续做开源的信心.这是我的第二个开源作品 ScreenshotEx 一个简单易 ...
- extcon驱动及其在USB驱动中的应用
extcon,是External Connector的简称,用于抽象外部连接器,比如说Audio Jack.USB MicroB/TypeC接口等.它的原型是Android的switch-class驱 ...
- 不可不知的 MySQL 升级利器及 5.7 升级到 8.0 的注意事项
数据库升级,是一项让人喜忧参半的工程.喜的是,通过升级,可以享受新版本带来的新特性及性能提升.忧的是,新版本可能与老的版本不兼容,不兼容主要体现在以下三方面: 语法不兼容. 语义不兼容.同一个SQL, ...
- 『忘了再学』Shell基础 — 14、环境变量(二)
目录 1.PS1变量的作用 2.PS1变量的查看 2.PS1可以支持的选项 3.PS1环境变量的配置 4.总结 提示: 在Linux系统中,环境变量分为两种.一种是用户自定义的环境变量,另一种是系统自 ...
- 1.还不会部署高可用的kubernetes集群?看我手把手教你使用二进制部署v1.23.6的K8S集群实践(上)
公众号关注「WeiyiGeek」 设为「特别关注」,每天带你玩转网络安全运维.应用开发.物联网IOT学习! 本章目录: 0x00 前言简述 0x01 环境准备 主机规划 软件版本 网络规划 0x02 ...
- 个人冲刺(四阶段)——体温上报app(一阶段)
任务:完成了后台数据库的类模块 MyDBHelper.java package com.example.helloworld; import android.content.Context; impo ...