MySQL单表查询(分组-筛选-过滤-去重-排序-分页-判断-正则)
一:单表查询
1.单表查询(前期准备)
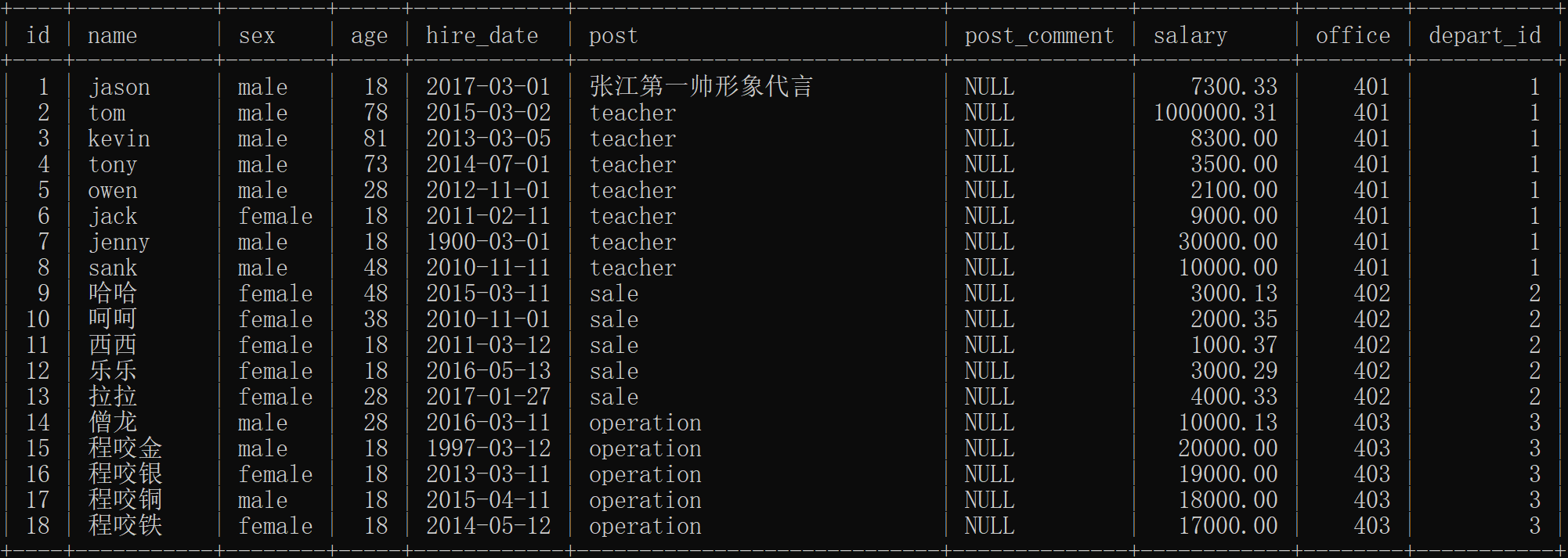
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
sex enum('male','female') not null default 'male', # 用户如不输入 默认男的
age int(3) unsigned not null default 28, # 用户如不输入 默认28
hire_date date not null, # 雇佣日期
post varchar(50), # 职业
post_comment varchar(100), # 员工描述
salary double(15,2), # 薪水
office int, #一个部门一个屋子
depart_id int # 编号
);
2.插入记录(写入数据)
- 三个部门:
教学,销售,运营
insert into emp(name,sex,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','张江第一帅形象代言',7300.33,401,1),
# 以下是教学部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),
#以下是销售部门
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('乐乐','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龙','male',28,'20160311','operation',10000.13,403,3),
#以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3);
3.查询关键字
select
控制查询表中的哪些字段对应的数据
from
控制查询的表
- 结合使用:
select * from t1;
作用:
查询t1表内所以记录
select name from t1;
作用:
查询t1表内name字段
二:查询关键字之where
关键字: where
作用:
其实就是对数据进行筛选
1.查询id大于等于3小于等于6的数据
select id,name from emp where id >= 3 and id <= 6;
select id,name from emp where id between 3 and 6; # 简写
between :选取介于两个值之间的数据范围内的值
2.查询薪资是20000或者18000或者17000的数据
select * from emp where salary = 20000 or salary = 18000 or salary = 17000;
select * from emp where salary in (20000,18000,17000); # 简写
3.模糊查询(like)
模糊查询
关键字 like
模糊查询应用场景:
当查询对象(名称不全)(数字不全)(不确定内容)时,可以使用模糊查询。
关键符号:
% : 匹配任意个数的任意字符
_ : 匹配单个 个数的任意字符
4.查询员工姓名中包含o字母的员工姓名和薪资
select name,salary from emp where name like '%o%';
5.查询员工姓名为四个字符组成的员工姓名和薪资
select name,salary from emp where name like '____';
select name,salary from emp where char_length(name) = 4;
6.查询id小于3或者大于6的数据
select * from emp where id not between 3 and 6;
7.查询薪资不在20000,18000,17000范围的数据
select * from emp where salary not in (20000,18000,17000);
8.(查询岗位描述为空的员工名与岗位名) 针对null不能用等号,只能用is(才能查询到)
select name,post from emp where post_comment = NULL; # 查询为空!
select name,post from emp where post_comment is NULL;
select name,post from emp where post_comment is not NULL;
三:查询关键字之group by分组
1.什么是分组?
按照某个指定的条件将单个单个的数据分为一个个整体
- 分组
咱班按照座位横向分组
咱班按照年龄分组
咱班按照省份分组
2.应用场景
求每个部门的平均薪资
求每个国家的人均GDP
求男女平均薪资
3.如何对数据进行分组?
关键字 group by 条件
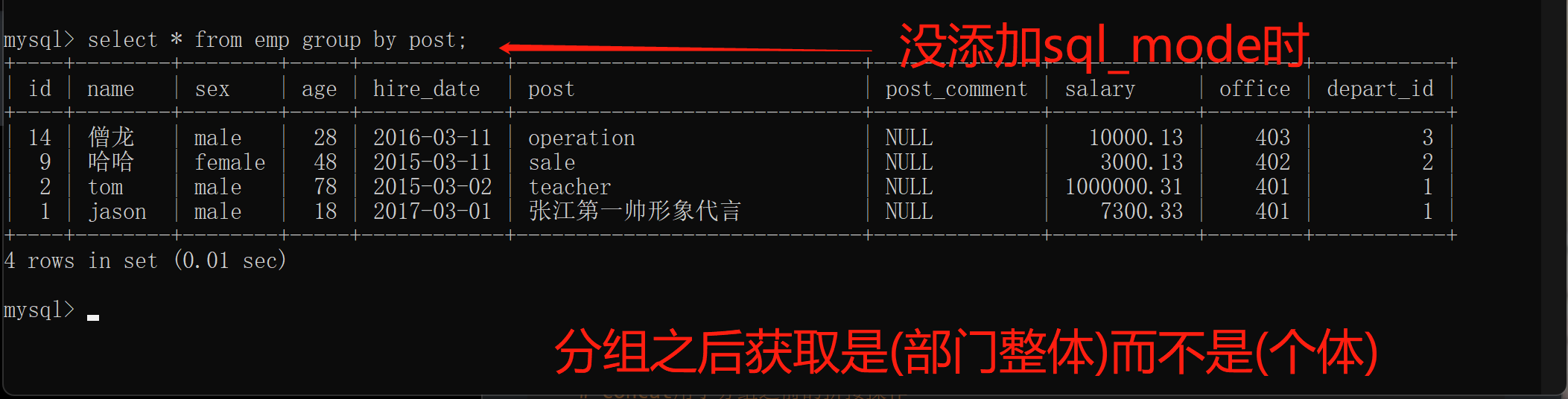
4.实现分组
分组之后不再以单个个体为研究对象 也无法直接再获取单个个体的数据
研究对象应该是分组的整体
解析:
分组之后获取是(部门整体)而不是(个体)
分组之后默认只能直接获取到分组的依据 其他字段数据无法直接获取
解析:
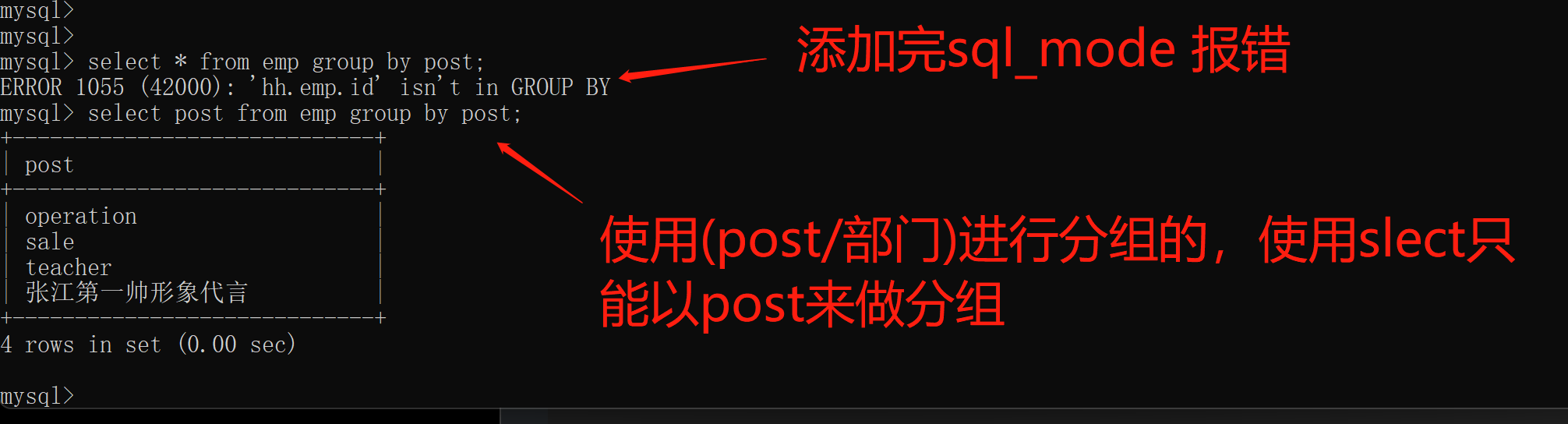
使用(post/部门)进行分组的,使用slect只能以post来做分组
如果需要实现上述要求 还是修改sql_mode
set global sql_mode='only_full_group_by';
修改完后重新登录MySQL
exit
注意:
分组之后默认只能直接获取到分组的依据 其他字段数据无法直接获取
5.聚合函数
max() : 求最大值
min() : 求最小值
sum() : 求合
count() : 计数
avg() : 平均值
# 上述聚合函数都是在分组之后使用 用于操作整体数据
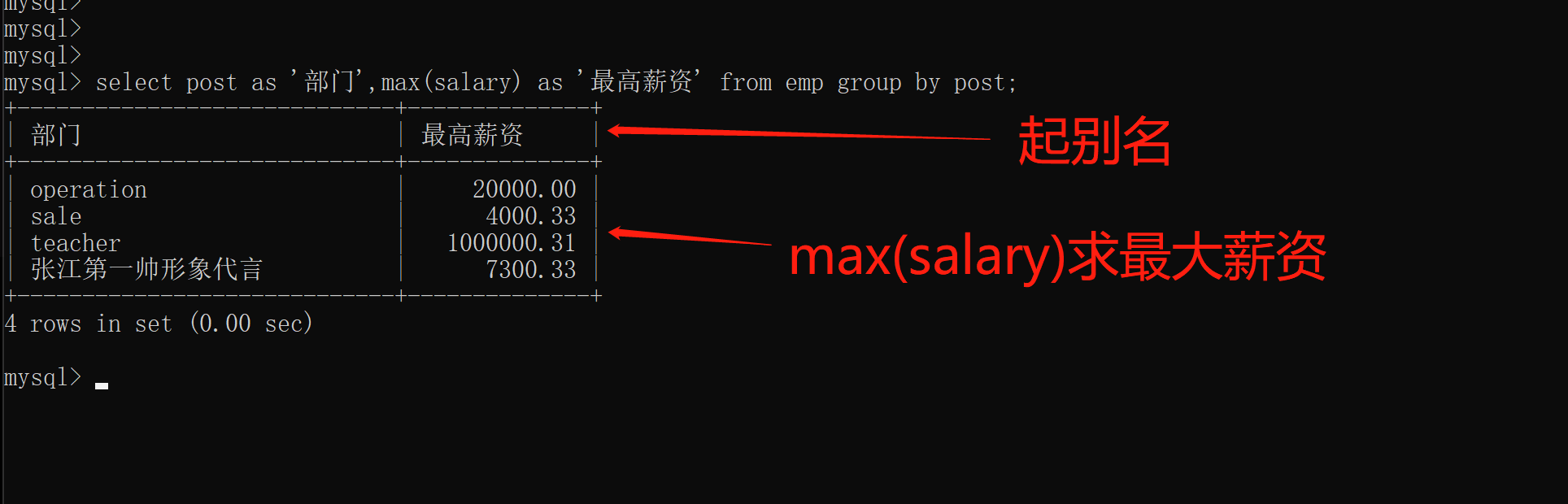
6.as语法(起别名)
as语法在查看结果的时候可以给字段起别名
格式:
select post as '部门',max(salary) as '最高薪资' from emp group by post;
省略as:
select post '部门',max(salary) '最高薪资' from emp group by post;
注意:
as可以省略但是为了语义更加明确建议不要省略
四:分组实战案例
1.获取每个部门的最大薪资
select post '部门',max(salary) '最高薪资' from emp group by post;
获取每个部门的最低薪资
select post '部门',min(salary) '最低薪资' from emp group by post;
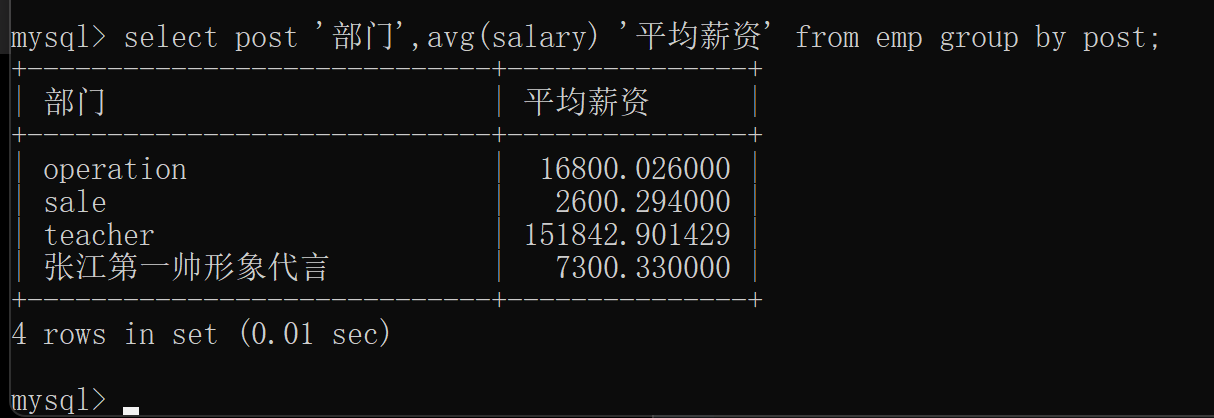
统计每个部门的平均薪资(平均薪资不客观 客观表现(中位数))
select post '部门',avg(salary) '平均薪资' from emp group by post;
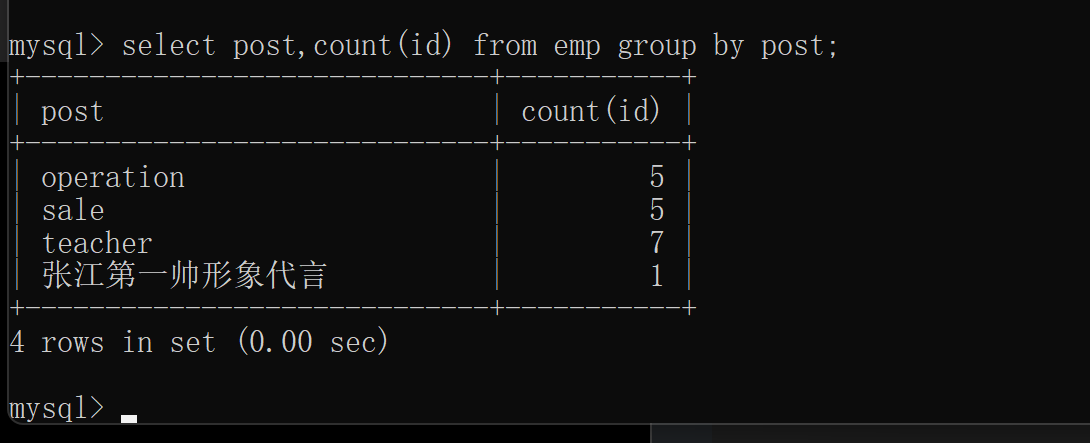
2.统计每个部门的人数
select post,count(id) from emp group by post;
count(id) : count()只是计数 不是针对括号内的id字段
3.获取每个部门的员工姓名(拼接)
select post,group_concat(name) from emp group by post;

获取每个部门的员工姓名(分组之后拼接)
select post,group_concat(name,'|',salary) from emp group by post;
group_concat 用于分组之后获取分组以外的字段数据并支持拼接(间接拿)

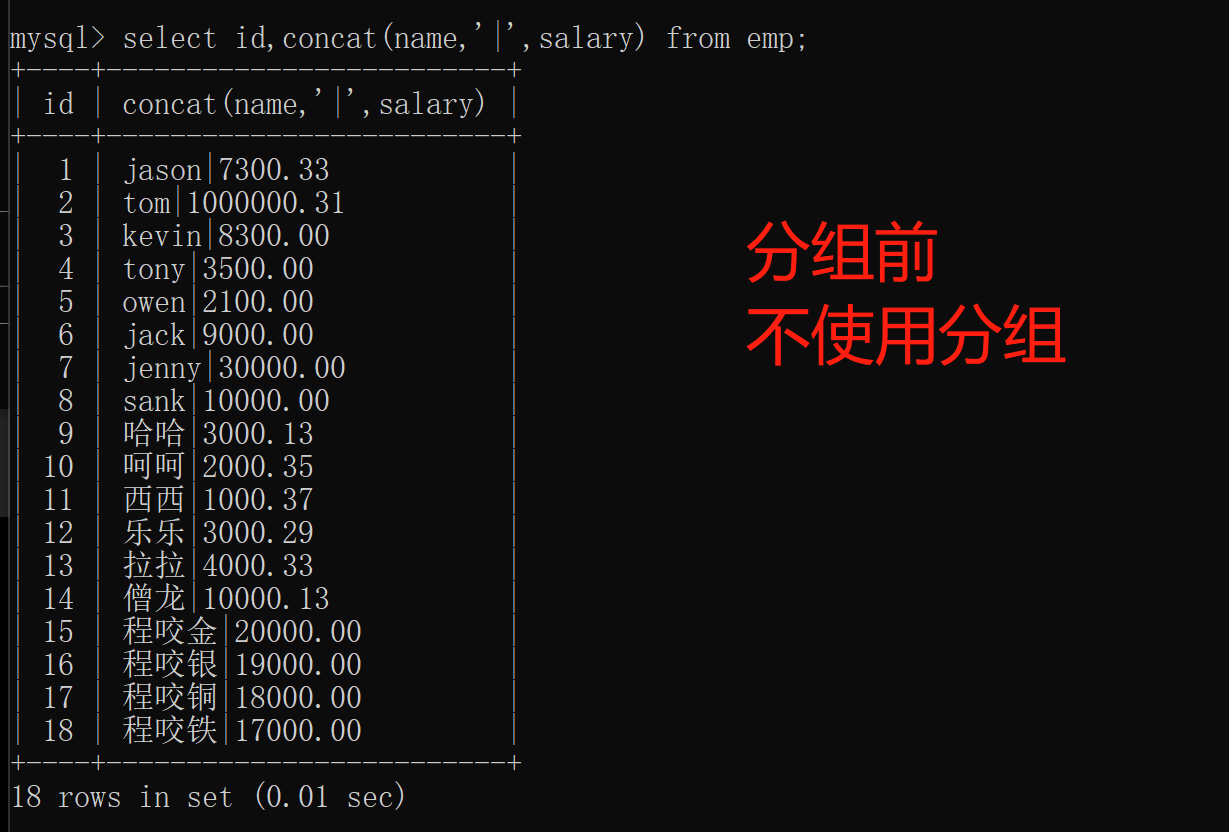
获取员工姓名(分组之前拼接)
select id,concat(name,'|',salary) from emp;
concat 用于分组之前的拼接操作
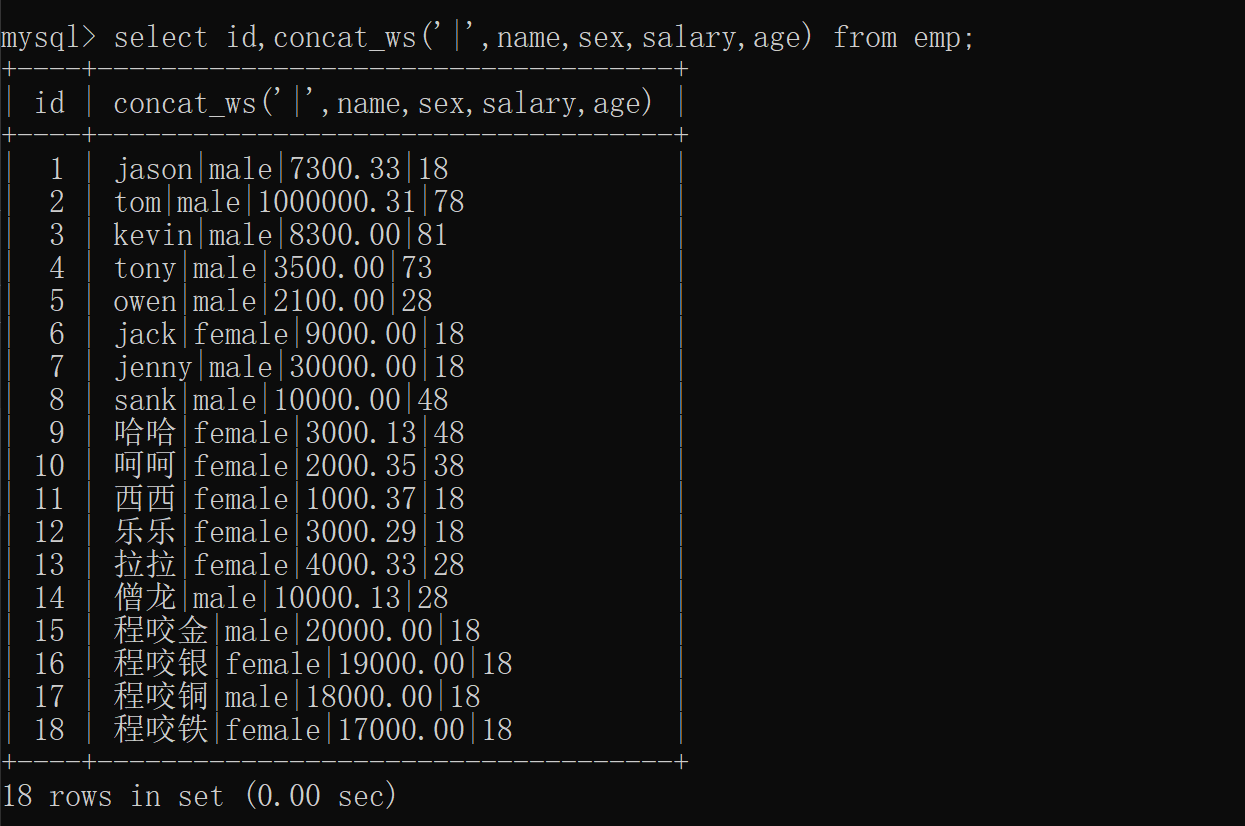
获取多个字段(简写分隔符)分组前
select id,concat_ws('|',name,sex,salary,age) from emp;
concat_ws 当多个字段连接符相同的情况下推荐使用
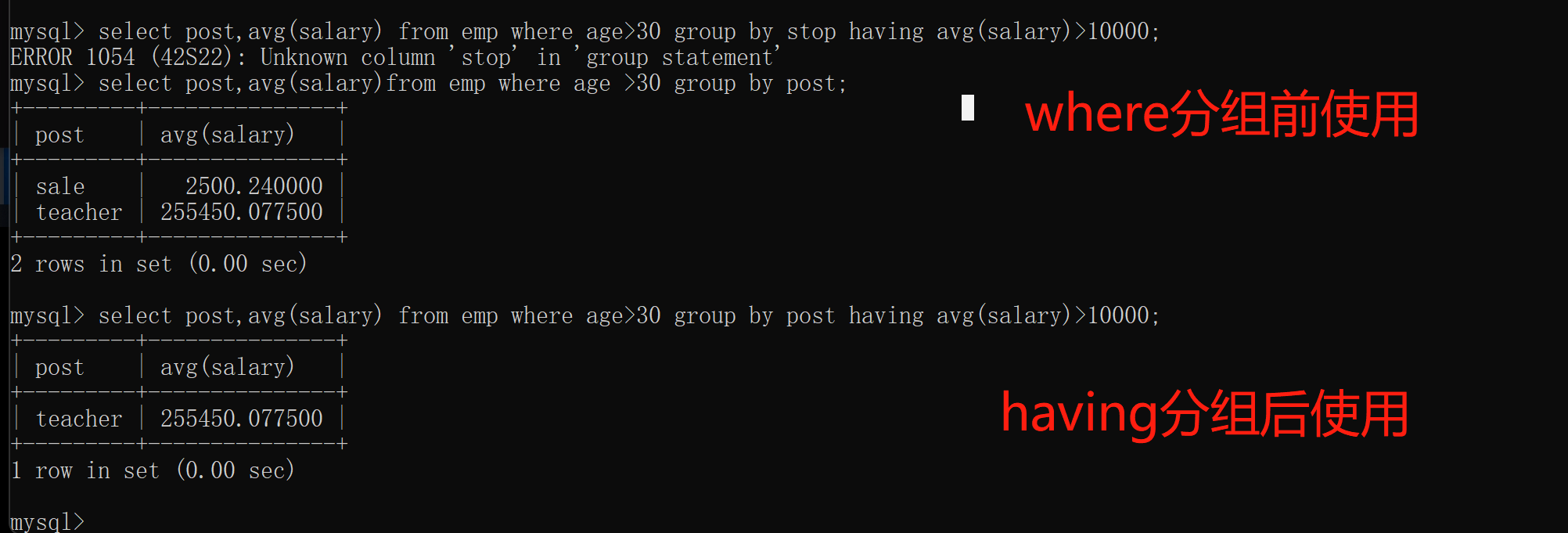
五;查询关键字之having过滤
1.where与having区别
where与having都是用来筛选数据的
但是where用于分组之前的筛选
having用于分组之后的筛选
为了人为的区分开 我们将where用筛选来形容 having用过滤来形容
2.having过滤案例
统计各部门年龄在30岁以上的员工平均工资,并且保留平均工资大于10000的部门
将一个复杂的查询题拆分成多个简单的小题:
1.查看整张表的内容: select * from emp;
2.统计年龄在30岁以上的员工: select * from emp where age > 30;
3.给各个部门进行分组: select post from emp group by post;
4.计算各部门的平均薪资: select post,avg(salary) from emp group by post
5.各部门30岁以上的平均薪资: select post,avg(salary) from emp where age > 30 group by post;
6.使用having(分组之后)过滤,并且保留平均工资大于10000的部门:
select post,avg(salary) from emp where age > 30 group by post having avg(salary)>10000;
六:查询关键字之distinct去重
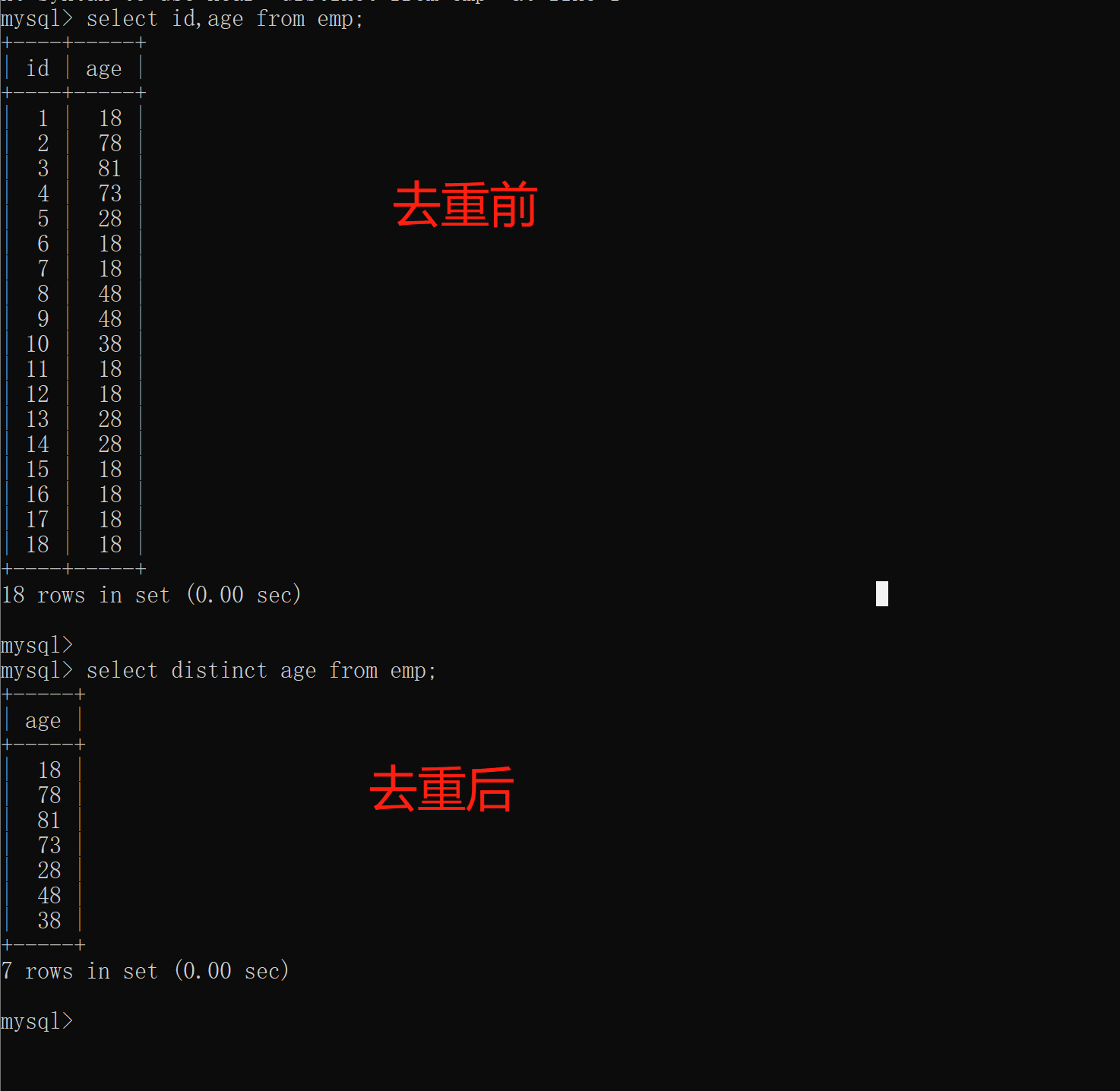
1.distinct去重
1.去重的前提示是存在一模一样的数据
2.如果存在主键肯定无法去重(主键是 非空且唯一)
2.对有重复的展示数据进行去重操作 一定要是重复的数据
select distinct id,age from emp; # 无效果
select distinct id,age distinct from emp; # 报错
select distinct age from emp;
七:查询关键字之order by排序
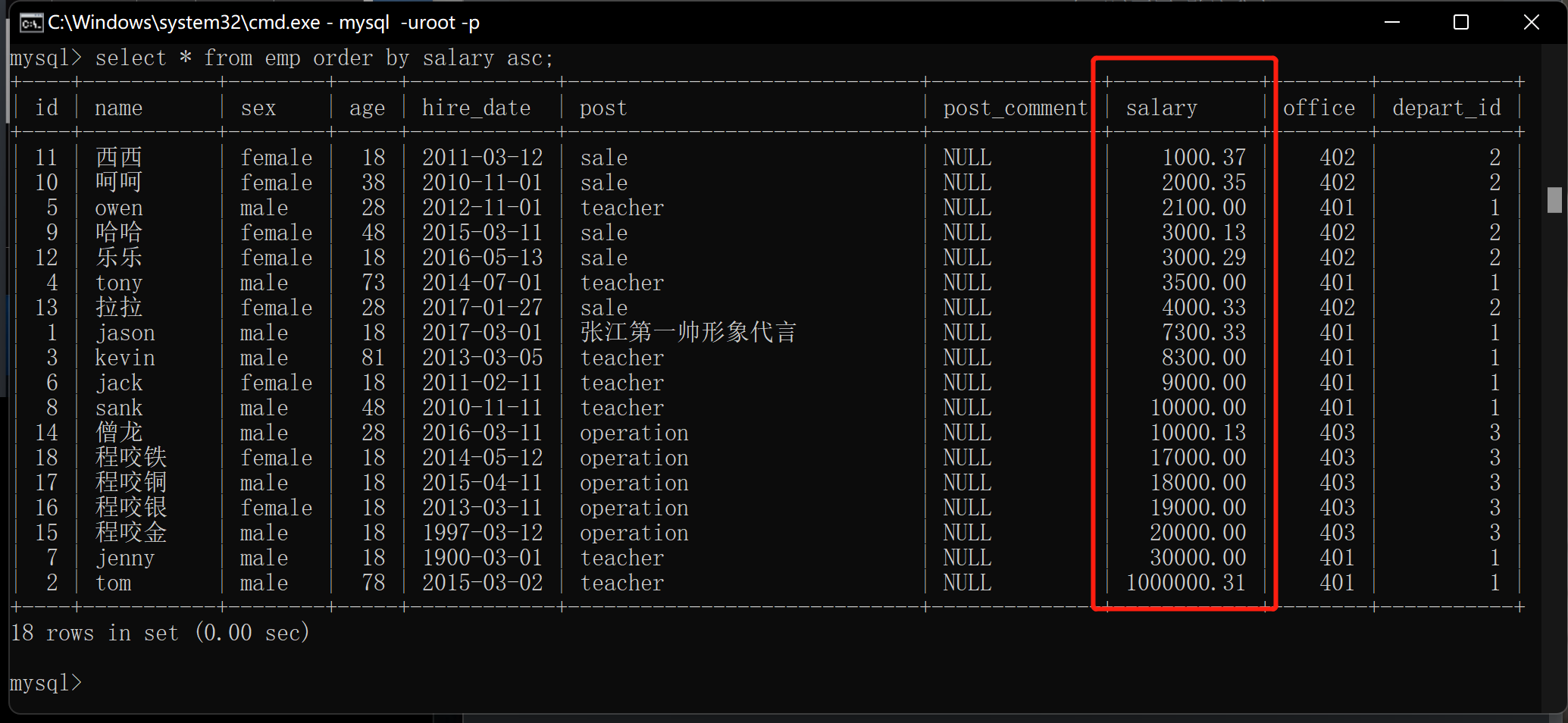
1.关键字order by 排序
order by默认是升序 默认的关键字是asc
升序 : asc
降序 : desc
2.薪资由低到高排序(升序)
select * from emp order by salary asc; # 也可以不写 默认升序
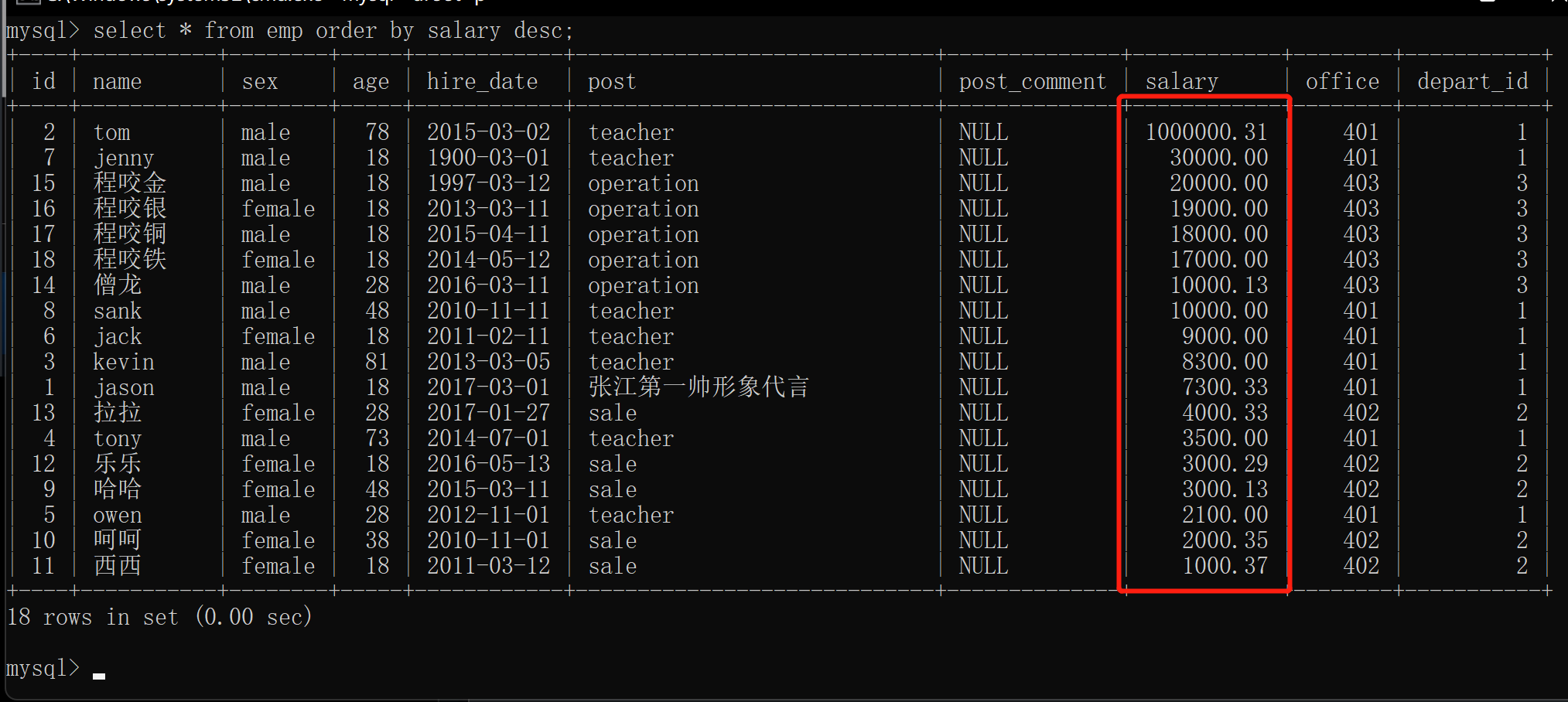
3.薪资由高到低排序(降序)
select * from emp order by salary desc; # 降序
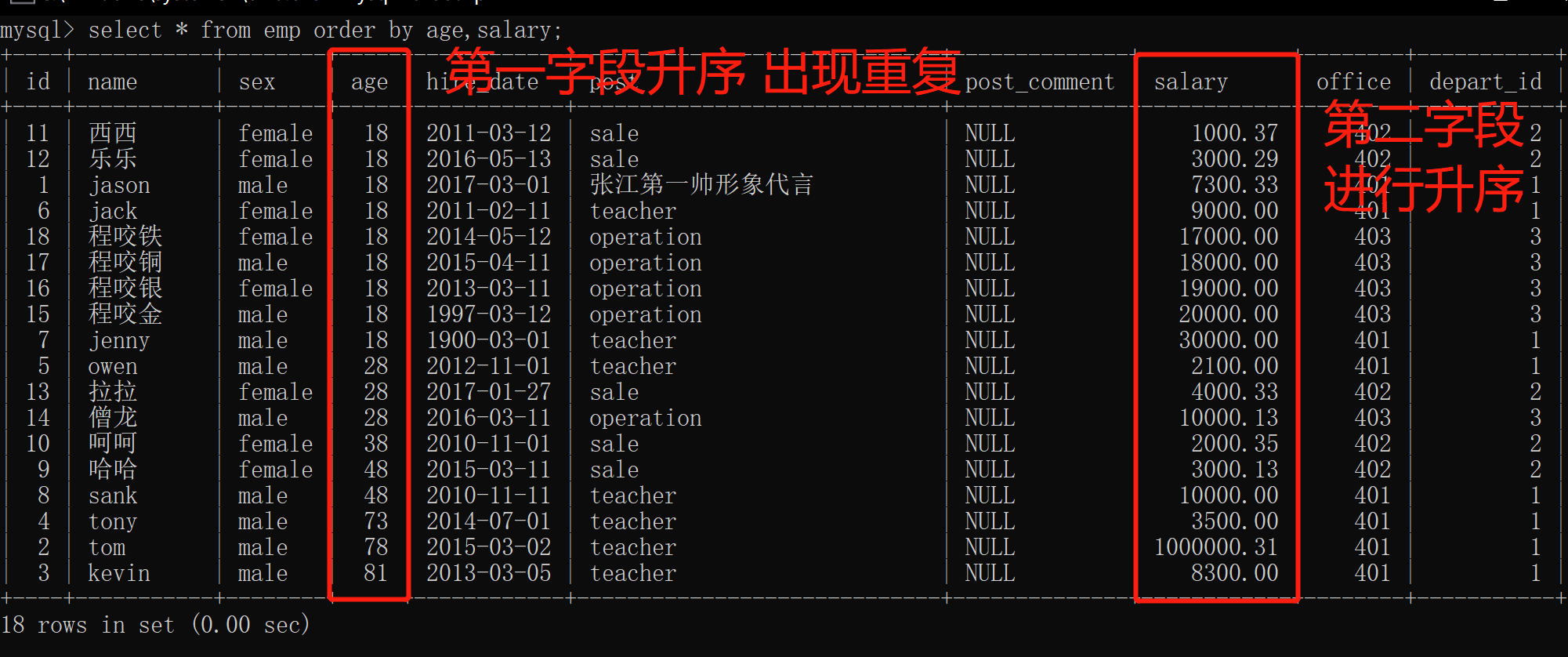
4.order by排序支持多个字段组合(第一个不行 就往后继续排)
解析:
第一个字段排序出现重复时,会从第二个字段排序进行升序比较
select * from emp order by age,salary;
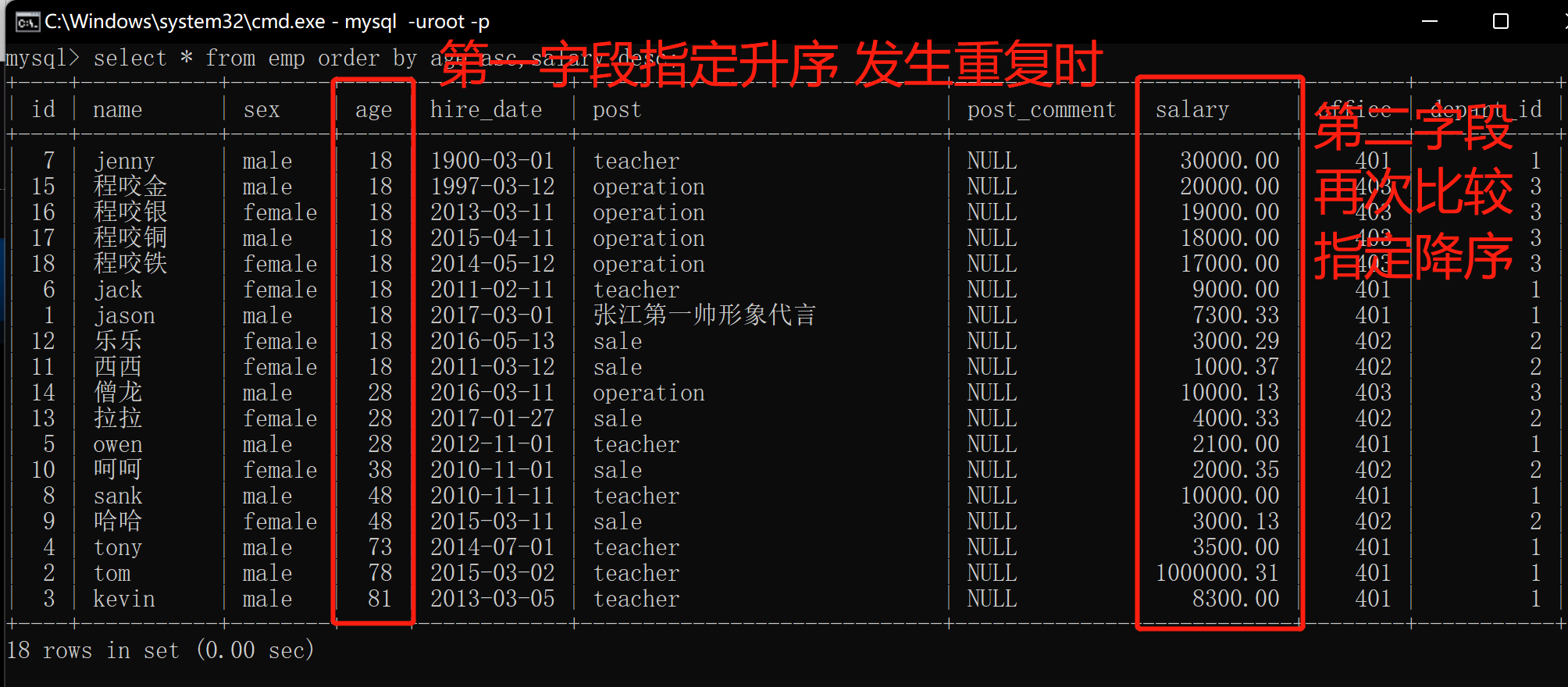
5.order by(多段排序 指定排序)
作用:
可以多段排序,可以给多段排序指定(升序 或 降序)
select * from emp order by age asc,salary desc;
八:表查询关键字limit(分页)
1.limit(分页)
limit 分页
格式:
limit 数字
使用场景:
当我们查看数据过多的情况下,可以使用limit分页限制每次查看的数据的数量。
2.limit分页使用
1.只跟一个数字
(从头开始展示几行数据)
select * from emp limit 5;
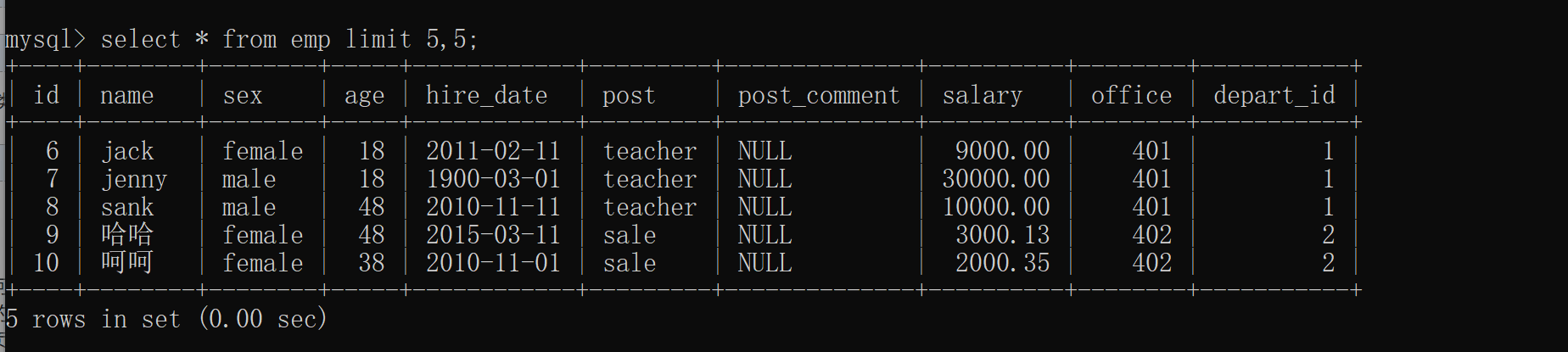
2.只跟两个数字
(第一个是起始位置 第二个是几行数据)
select * from emp limit 5,5;
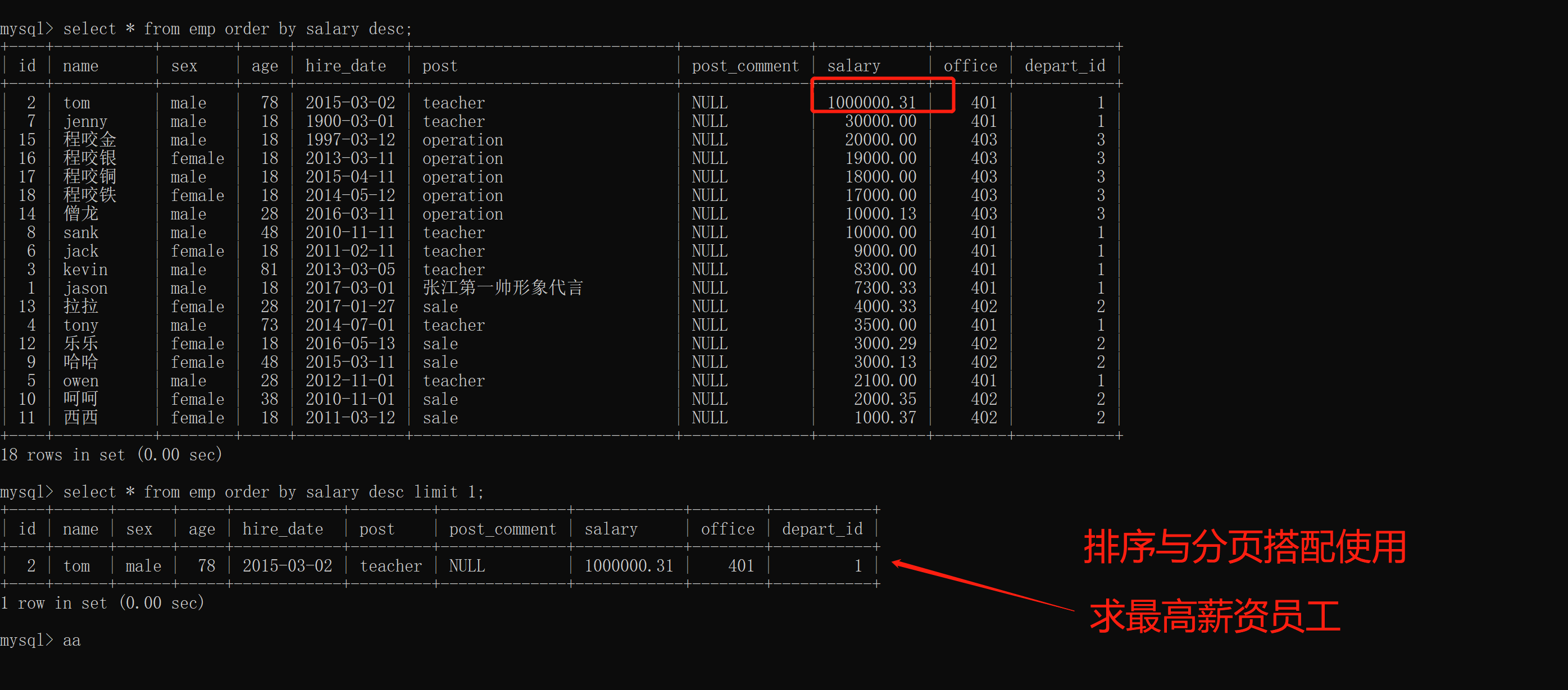
3.分页与排序结合使用
要求:
求薪资最高的员工所有数据
1.先按照薪资降序排序
2.在使用limit限制取一行
select * from emp order by salary desc limit 1;
九:表查询关键字regexp 正则表达式
使用正则 (查询 j开头 y或者n结尾的员工)
select * from emp where name regexp '^j.*(n|y)$';
.* : 零个或多个除换行符以外任意字符

十:表查询关键字exists 判断
1.exists判断
exists定义:
EXISTS关字键字表示存在。在使用EXISTS关键字时,内层查询语句不返回查询的记录,
而是返回一个真假值,True或False。
当返回True时,外层查询语句将进行查询
当返回值为False时,外层查询语句不进行查询。
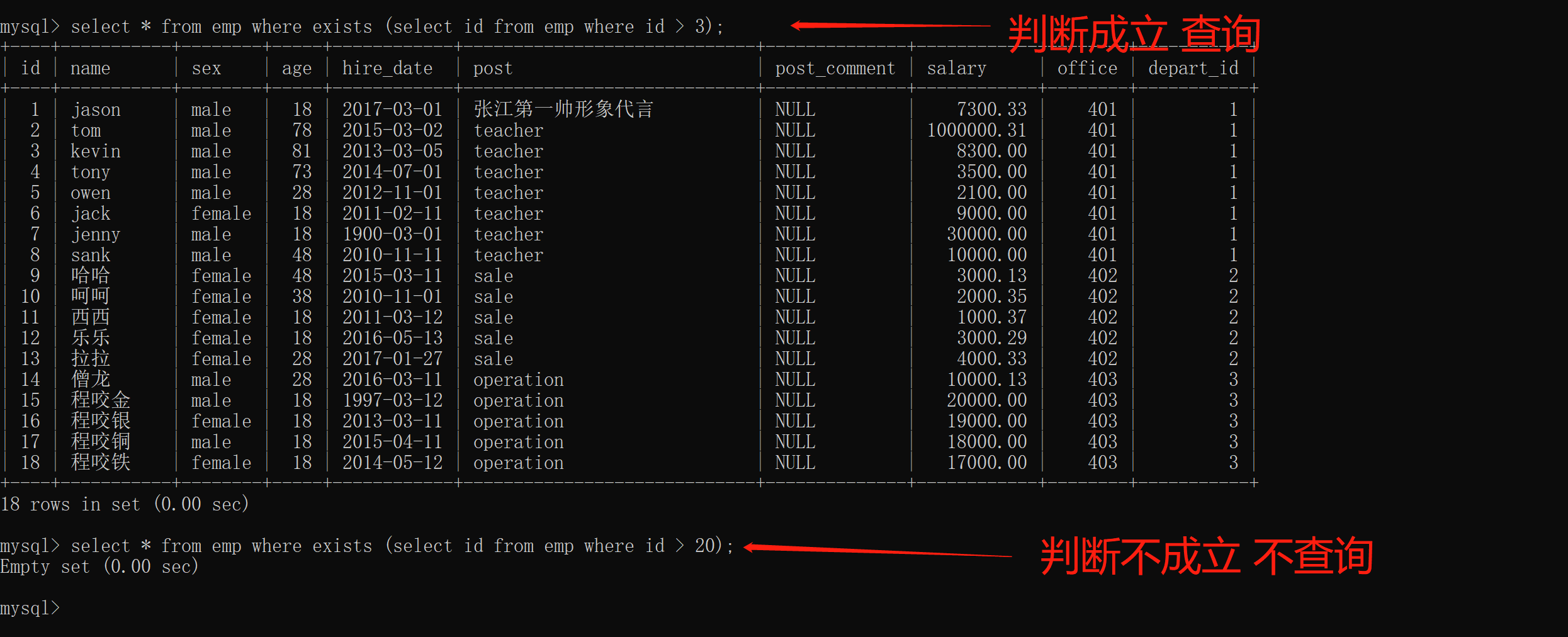
2.exists 判断(案例)
括号内为判断,当判断成立时,外层语句会进程查询
select * from emp where exists (select id from emp where id > 3);
括号内为判断,当判断不成立时,外层语句不会进行查询
select * from emp where exists (select id from emp where id > 250);
MySQL单表查询(分组-筛选-过滤-去重-排序-分页-判断-正则)的更多相关文章
- MySQL单表查询(分组-筛选-过滤-去重-排序)
目录 一:单表查询 1.单表查询(前期准备) 2.插入记录(写入数据) 3.查询关键字 二:查询关键字之where 1.查询id大于等于3小于等于6的数据 2.查询薪资是20000或者18000或者1 ...
- mysql——单表查询——分组查询——示例
一.基本查询语句 select的基本语法格式如下: select 属性列表 from 表名和视图列表 [ where 条件表达式1 ] [ group by 属性名1 [ having 条件表达式2 ...
- python 3 mysql 单表查询
python 3 mysql 单表查询 1.准备表 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职 ...
- day04 mysql单表查询 多表查询 pymysql的使用
day04 mysql pymysql 一.单表查询 1.having过滤 一般用作二次筛选 也可以用作一次筛选(残缺的: 只能筛选select里面 ...
- Mysql 单表查询-排序-分页-group by初识
Mysql 单表查询-排序-分页-group by初识 对于select 来说, 分组聚合(((group by; aggregation), 排序 (order by** ), 分页查询 (limi ...
- Mysql 单表查询 子查询 关联查询
数据准备: ## 学院表create table department( d_id int primary key auto_increment, d_name varchar(20) not nul ...
- Mysql 单表查询where初识
Mysql 单表查询where初识 准备数据 -- 创建测试库 -- drop database if exists student_db; create database student_db ch ...
- python mysql 单表查询 多表查询
一.外键 变种: 三种关系: 多对一 站在左表的角度: (1)一个员工 能不能在 多个部门? 不成立 (2)多个员工 能不能在 一个部门? 成立 只要有一个条件成立:多 对 一或者是1对多 如果两个条 ...
- mysql 单表查询
一 单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数 二 ...
随机推荐
- 2022-08-20-nas寄了就搞网络__网络升级计划_(估计又得白给)
layout: post cid: 13 title: nas寄了就搞网络? 网络升级计划 (估计又得白给) slug: 13 date: 2022/08/20 16:31:00 updated: 2 ...
- 深入浅出TCP与IP协议笔记
TCP/IP 4层结构:应用层 传输层 网络层 链路层 探索过程问题:一个主机的数据要经过哪些过程才到达对方的主机上 一组电信号就是一个数据包,一个数据包称为一帧,制定这个规则的就是以太网协议 ...
- 插入排序算法(Java代码实现)
其它经典排序算法:https://blog.csdn.net/weixin_43304253/article/details/121209905 插入排序算法: 思路:将数据分为已经排序好的数据和未排 ...
- v-for和router-link的共同使用
1. 错误例子 <div style="color: red" v-for="item in pressionList" :key="item. ...
- 在mybatis中#{}和${}的区别
文章目录 1.第一个#{} 2.第二个${} 3.区别 1.第一个#{} 解释: 使用#{}格式的语法在mybatis中使用preparement语句来安全的设置值 PreparedStatement ...
- AI人脸识别+换脸
视频换脸可参考 https://github.com/iperov/DeepFaceLab import dlib.dlib as dlib import numpy import sys impor ...
- 测试架构师CAP原理(最简单)
测试架构师CAP原理(最简单) 很多人都不是很了解CAP理论,其实CAP很简单,不要想复杂了! C:一致性,就是数据一致性,就是数据不出错! A:可用性,就是说速度快,不延迟,无论请求成功失败都很快返 ...
- JAVA学习前准备
电脑常用快捷键 Ctrl+C:复制 Ctrl+V:粘贴 Ctrl+A:全选 Ctrl+X:剪切 Ctrl+Z:撤销 Ctrl+S:保存 Alt+F4:关闭窗口 Shift+delete:永久性删除文件 ...
- 在博客中实现播放音乐功能(QQ,网易,酷狗,虾米,百度)
1.在页头head标签里添加: <link rel="stylesheet" href="https://static.likepoems.com/cdn/apla ...
- mysql 子查询 联结 组合查询
子查询 SELECT cust_id FROM orders WHERE order_num IN (SELECT order_num FROM orderitems WHERE prod_id='T ...