conda环境下使用nvcc -V报错nvcc: command not found的一种解决方法
前言
缘起
实验室的学弟问我为什么他使用nvcc命令报错,起先我以为他用的是老师给的root账户,按照参考文献1便可以解决问题。
但由于并非root用户,/usr/local下没有cuda,于是便无法按照参考1中的方法去做。
这里提供一种方法,其实是参考了文献2,但似乎是歪打正着,因为2要解决的问题和我的不一样O_o。
问题
使用nvcc -V报错如下

解决方法
报错原因在于当前conda环境没有安装nvcc,于是使用如下命令安装即可
conda install -c nvidia cuda-nvcc
补充:执行上述命令后会默认安装cuda-nvcc的最新版本,于是这里涉及到cuda-nvcc版本号的确定问题,需要根据实际情况确定,下面我举一个例子。
我在安装apex时有遇到如下报错

此时需要重新安装cuda-nvcc,版本号需要与安装pytorch的cuda版本号一致,以上图为例,需要安装cuda-nvcc11.3的版本,执行如下命令即可,不需要卸掉之前的cuda-nvcc,安装时会自动进行cuda-nvcc版本迁移。
conda install -c "nvidia/label/cuda-11.3.0" cuda-nvcc
安装其他版本的cuda-nvcc命令参照官网。
再次使用nvcc -V,成功啦!^ _ ^
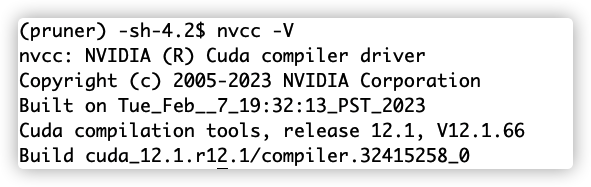
补充:上面我用的我的pruner环境,安装了nvcc,因为不想动base环境~此外,上图中的cuda-nvcc版本号是12.1,这是我直接执行conda install -c nvidia cuda-nvcc的结果。
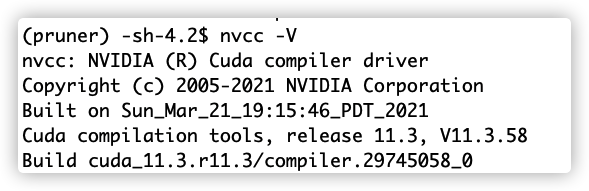
后面我重新安装了cuda-nvcc11.3版本,执行conda install -c "nvidia/label/cuda-11.3.0" cuda-nvcc
cuda-nvcc的版本号为11.3,结果如下所示
参考文献
- 解决nvcc --version显示command not found问题
- TypeError: unsupported operand type(s) for +: 'NoneType' and 'str'
conda环境下使用nvcc -V报错nvcc: command not found的一种解决方法的更多相关文章
- eclipse中不能找到dubbo.xsd报错”cvc-complex-type.2.4.c“的 两种解决方法
配置dubbo环境过程中的xml文件,安装官网的demo配置好后,出错: "Description Resource Path Location Type cvc-complex-type. ...
- MongoDB解压报错gzip: stdin: not in gzip format的解决方法
MongoDB解压报错gzip: stdin: not in gzip format的解决方法 在安装MongoDB时出现如下报错: [root@vm172--- mongodb]# tar -zxv ...
- 支付宝 报错 rsa_private read error : private key is NULL解决方法
原因: 真机调试IOS支付宝功能GDB出现 rsa_private read error : private key is NULL提示 调试iOS 支付宝SDK的时候,执行demo.把 Partn ...
- mysql用查询结果当删除的判断条件进行删除报错1093 You can't specify target table解决方法
mysql用查询结果当删除的判断条件进行删除报错1093 You can't specify target table解决方法 #分开两个sql执行正常的语句,只保留最新1000条数据,删掉1000条 ...
- 报错NameError: name ‘null’ is not defined的解决方法
报错NameError: name 'null' is not defined的解决方法 eval()介绍 eval()函数十分强大,官方demo解释为:将字符串str当成有效的表达式来求值并返回计算 ...
- Android高版本联网失败报错:Cleartext HTTP traffic to xxx not permitted解决方法
前言:为保证用户数据和设备的安全,Google针对下一代 Android 系统(Android P) 的应用程序,将要求默认使用加密连接,这意味着 Android P 将禁止 App 使用所有未加密的 ...
- pip install scrapy报错:error: Unable to find vcvarsall.bat解决方法
今天在使用pip install scrapy 命令安装Scrapy爬虫框架时,出现了很让人头疼的错误,错误截图如下: 在网上查找解决方法时,大致知道了问题的原因.是因为缺少C语言的编译环境,其中一种 ...
- windows环境下安装scrapy框架报错问题--最快捷有效的解决方案
windows在执行如下命令,安装scrapy的过程中会报错: pip install scrapy 报错分析: windows环境下,会出现如下错误: 1.提示的错误是编译环境的问题,字面意思看需要 ...
- window环境下npm install node-sass报错
最近准备想用vue-cli初始化一个项目,需要sass-loader编译: 发现window下npm install node-sass和sass-loader一直报错, window 命令行中提示我 ...
- hadoop ha环境下的datanode启动报错java.lang.NumberFormatException: For input string: "10m"
hadoop ha环境启动start-dfs.sh的时候datanode启动不了,并且报错. [hadoop@datanode2 ~]$ cat /home/hadoop/hadoop-2.7.3/l ...
随机推荐
- 梯度下降算法VS正规方程算法
梯度下降算法的大家族: ①批量梯度下降:有N个样本,求梯度的时候就用了N个样本的梯度数据 优点:准确 缺点:速度慢 ②随机梯度下降:和批量梯度下降算法原理相似,区别在于求梯度时没有用所有的N歌样本数据 ...
- git拉取远程主支内容,在本地进行修改后,重新提交到新建分支的过程
git拉取远程主支内容,在本地进行修改后,重新提交到新建分支的过程 在本地找一个干净的文件夹 git init 进行初始化 git clone 复制拉取远程的地址 在文件夹中打开,进入复制下来的项 ...
- c二级
一·基本数据结构与算法 算法基本概念 算法:解决问题的方法 程序:用某种语言来诠释算法,将算法写成代码. 算法基本特征: 1.可行性 2.确定性 3.有穷性 4.有足够的情报 算法的基本要素 1.算法 ...
- flume往kafka中导入数据
1.编辑flume的配置文件 a1.sources = r1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = ...
- Jmeter添加BeanShell后置处理程序保存响应结果
对于某些请求,无法通过保存响应到文件这个组件来进行保存(会出现UNKNOW文件类型). 那么就可以通过BeanShell后置处理程序来进行将响应结果直接输出到文件,并可以直接指定文件名和后缀. imp ...
- Linux(CentOS7)中安装Docker
Linux(CentOS7)中安装Docker 什么是Docker? Docker是一个开源项目, 诞生于2013年初,最初是dotCloud公司内部的一个业余项目.它基于Google公司推出的Go语 ...
- 升级openssl版本
一.安装步骤 1.下载openssl安装包 2.编译安装 3.备份旧版本openssl 4.添加软连接 5.添加OpenSSL动态链接库并使其生效 二.下载openssl安装包 [root@local ...
- Springboot中使用枚举
枚举映射数据库字段 配置枚举包扫描路径 mybatis-plus: # 扫描通用枚举 type-enums-package: com.xx.**.enums 方法一:@EnumValue 和 @Jso ...
- Python生态工具
Python内置小工具 1秒钟启动一个下载服务器 在实际工作中,时常会有这样的一个需求:将文件传给其他同事.将文件传给同事本身并不是一个很繁琐的工作,现在的聊天工具一般都支持文件传输.但是,如果需要传 ...
- 10、jmeter的 Http的请求默认值
在我们测试过程当中,有很多HTTP协议的请求 这些请求 有很多比如说网址(url)都是相同的 端口也是相同的,路径可能也是相同的 这个时候就需要用到请求默认值,后续直接用就可以 不需要再去配置 后续 ...