ElasticSearch入门学习笔记
ElasticSearch入门笔记
分页查询
from: 开始位置
size: 查多少条
GET /credit_enterprise_info/_search
{
"query": {
"match": {
"qymc": "大"
}
}
, "from": 0
, "size": 5
}
解决数据量很大时 总数只显示10000条
GET /credit_enterprise_info/_search
{
"track_total_hits": true
}
如修改完之后,通过api查询回来的totalhits还是只有10000条,解决如下:
在查询时候把 track_total_hits 设置为 true。
track_total_hits 设置为false禁用跟踪匹配查询的总点击次数
设置为true就会返回真实的命中条数。
GET 索引名/_search
{
"query": {
"match_all": {}
},
"track_total_hits":true
}
java代码在构建条件时候加上:
searchSourceBuilder.trackTotalHits(true);
只查询索引内文档数量
GET /credit_enterprise_info/_count
设置查询10000条以后的数据
PUT /credit_enterprise_info/_settings
{
"index.max_result_window" : "1000000"
}
查询配置
GET /credit_enterprise_info/_settings
返回:
{
"credit_enterprise_info" : {
"settings" : {
"index" : {
"number_of_shards" : "5",
"provided_name" : "credit_enterprise_info",
"max_result_window" : "1000000000",
"creation_date" : "1630920063923",
"number_of_replicas" : "1",
"uuid" : "CXgroui1SyqmWNDlg2-ifQ",
"version" : {
"created" : "7020099"
}
}
}
}
}
精确查询!
term查询是直接通过倒排索引指定的词条进行精确查找的!
- 通过倒排索引
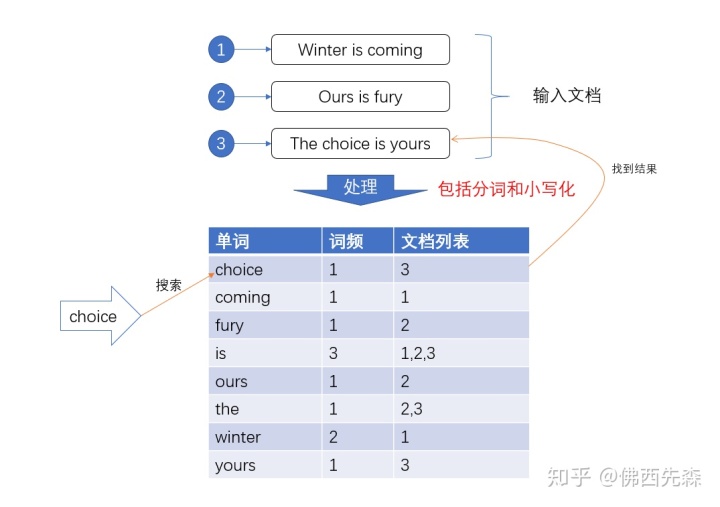
关于分词
trem,直接查询精确的(倒排索引直接查询)
match,会使用分词器解析!(先分析文档,然后在通过分析的文档进行查询!)
两个类型 text keyword
keyword字段类型不会被分词器解析
text类型可以被解析
PUT /testdb/_doc/1
{
"name": "Java name",
"desc": "Java desc"
}
PUT /testdb/_doc/2
{
"name": "Java name",
"desc": "Java desc2"
}
GET _analyze
{
"analyzer": "keyword",
"text": "Java name"
}
GET _analyze
{
"analyzer": "standard",
"text": "Java name"
}
GET /testdb/_search
{
"query": {
"term": {
"name": "测试"
}
}
}
GET /testdb/_search
{
"query": {
"term": {
"desc": "测试"
}
}
}
GET /testdb/_search
{
"query": {
"term": {
"desc": "Java desc"
}
}
}
多个值匹配的精确查询
PUT /testdb/_doc/3
{
"t1": "22",
"t2": "2020-4-6"
}
PUT /testdb/_doc/4
{
"t1": "33",
"t2": "2020-4-7"
}
GET /testdb/_search
{
"query": {
"bool": {
"should": [
{"term": {
"t1": "22"
}},
{"term": {
"t1": "33"
}}
]
}
}
}
must (and),所有条件都要符合 where id = 1 and name = XXX
must not(not)
should(or),所有条件都要符合 where id = 1 or name = XXX
filter
GET /testdb/_search
{
"query": {
"bool": {
"should": [
{"term": {
"t1": "22"
}},
{"term": {
"t1": "33"
}}
]
, "filter": {
"range": {
"t1": {
"gte": 20,
"lte": 30
}
}
}
}
}
}
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于!
匹配多个条件
直接分词 空格
GET /credit_enterprise_info/_search
{
"query": {
"match": {
"qymc": "沈阳 齐齐哈尔"
}
}
}
高亮查询
GET /credit_enterprise_info/_search
{
"query": {
"match": {
"qymc": "沈阳 齐齐哈尔"
}
}
, "highlight": {
"fields": {
"qymc": {}
}
}
}
自定义高亮查询
GET /credit_enterprise_info/_search
{
"query": {
"match": {
"qymc": "沈阳 齐齐哈尔"
}
}
, "highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"qymc": {}
}
}
}
GET /jd_goods/_search
{
"from": 1,
"size": 20,
"timeout": "20s",
"query": {
"term": {
"title": {
"value": "java",
"boost": 1.0
}
}
},
"highlight": {
"pre_tags": ["<sapn style='color:red'>"],
"post_tags": ["</span>"],
"require_field_match": false,
"fields": {
"title": {}
}
}
}
模糊查询 wildcard
GET /credit_enterprise_info/_search
{
"from": 0,
"size": 20,
"timeout": "20s",
"query": {
"bool": {
"must": [{
"wildcard": {
"tyshxydm": "*925309*"
}
}],
"adjust_pure_negative": true,
"boost": 1.0
}
},
"_source": {
"includes": ["inserttime", "qymc", "tyshxydm"],
"excludes": []
},
"sort": [{
"_score": {
"order": "desc"
}
}]
}
这些其实mysql也能做,知识mysql的效率比较低
- 匹配
- 按照条件匹配
- 精确匹配
- 区间范围匹配
- 匹配字段过滤
- 多条件查询
- 高亮查询
索引相关
# 查看全部索引
GET _cat/indices
# 获取一个文档
GET /index/type/id
# 删除索引
DELETE /index
# 查看mapping
GET /index/_mapping
# 创建索引mapping
PUT /index
{
"mappings": {
"type": {
"properties": {
"id": {
"type": "integer"
},
"industry": {
"type": "text",
"index": false
},
"report_type": {
"type": "text",
"index": false
},
"title": {
"type": "text",
"index":true
},
"update_time": {
"type": "date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"url": {
"type": "text",
"index": false
}
}
}
}
}
说明
ignore_malformed:true 忽略格式错误的数值
# 部分更新
POST /index/type/id/_update
{
"doc": {
"update_time": "2019-11-13 12:12:03"
}
}
# 查询,并过滤没有删除,分页,时间排序
get /index/_search
{
"query": {
"bool": {
"filter": {
"bool": {
"must_not": {
"term": {
"is_del": 1
}
}
}
},
"must": {
"match_phrase": {
"title": "国"
}
}
}
},
"size": 10,
"from": 0,
"sort": [
{"publish_date": {"order": "desc"}},
{"_score": {"order": "desc"}}
]
}
# 新增字段
PUT <index>/_mapping/<type>
{
"properties": {
"<name>": {
"type": "integer"
}
}
}
ElasticSearch入门学习笔记的更多相关文章
- Elasticsearch入门学习重点笔记
原文:Elasticsearch入门学习重点笔记 必记知识点 Elasticsearch可以接近实时的搜索和存储大量数据.Elasticsearch是一个近实时的搜索平台.这意味着当你导入一个文档并把 ...
- 【原创】SpringBoot & SpringCloud 快速入门学习笔记(完整示例)
[原创]SpringBoot & SpringCloud 快速入门学习笔记(完整示例) 1月前在系统的学习SpringBoot和SpringCloud,同时整理了快速入门示例,方便能针对每个知 ...
- Hadoop入门学习笔记---part4
紧接着<Hadoop入门学习笔记---part3>中的继续了解如何用java在程序中操作HDFS. 众所周知,对文件的操作无非是创建,查看,下载,删除.下面我们就开始应用java程序进行操 ...
- Hadoop入门学习笔记---part3
2015年元旦,好好学习,天天向上.良好的开端是成功的一半,任何学习都不能中断,只有坚持才会出结果.继续学习Hadoop.冰冻三尺,非一日之寒! 经过Hadoop的伪分布集群环境的搭建,基本对Hado ...
- PyQt4入门学习笔记(三)
# PyQt4入门学习笔记(三) PyQt4内的布局 布局方式是我们控制我们的GUI页面内各个控件的排放位置的.我们可以通过两种基本方式来控制: 1.绝对位置 2.layout类 绝对位置 这种方式要 ...
- PyQt4入门学习笔记(一)
PyQt4入门学习笔记(一) 一直没有找到什么好的pyqt4的教程,偶然在google上搜到一篇不错的入门文档,翻译过来,留以后再复习. 原始链接如下: http://zetcode.com/gui/ ...
- Hadoop入门学习笔记---part2
在<Hadoop入门学习笔记---part1>中感觉自己虽然总结的比较详细,但是始终感觉有点凌乱.不够系统化,不够简洁.经过自己的推敲和总结,现在在此处概括性的总结一下,认为在准备搭建ha ...
- Hadoop入门学习笔记---part1
随着毕业设计的进行,大学四年正式进入尾声.任你玩四年的大学的最后一次作业最后在激烈的选题中尘埃落定.无论选择了怎样的选题,无论最后的结果是怎样的,对于大学里面的这最后一份作业,也希望自己能够尽心尽力, ...
- Scala入门学习笔记三--数组使用
前言 本篇主要讲Scala的Array.BufferArray.List,更多教程请参考:Scala教程 本篇知识点概括 若长度固定则使用Array,若长度可能有 变化则使用ArrayBuffer 提 ...
- OpenCV入门学习笔记
OpenCV入门学习笔记 参照OpenCV中文论坛相关文档(http://www.opencv.org.cn/) 一.简介 OpenCV(Open Source Computer Vision),开源 ...
随机推荐
- Educational Codeforces Round 143 (Rated for Div. 2) A-E
比赛链接 A 题意 有两座塔由红蓝方块组成,分别有 \(n,m\) 个方块,一次操作可以把一座塔塔顶的方块移动到另一座塔的塔顶,问通过操作是否能使每座塔中没有颜色相同的相邻方块. 题解 知识点:贪心. ...
- 51nod 1675.序列变换
序列变换 题目描述 \(lyk\) 有两序列 \(a\) 和 \(b\). \(lyk\) 想知道存在多少对 \(x,y\),满足以下两个条件. \(1:\gcd(x,y)=1\). \(2:a_{b ...
- 04#Web 实战:Gitee 贡献图
前言 这次要做的 Web 前端实战是一个 Gitee 个人主页下的贡献图(在线 Demo),偶尔做一两个,熟悉熟悉 JS 以及 jQ.整体来说这个案例并不难,主要是控制第一个节点以及最后一个节点处于星 ...
- 开源分布式任务调度系统就选:DolphinScheduler
分布式任务调度这个话题是每个后端开发和大数据开发都会接触的话题.因为应用场景的广泛,所以有很多开源项目专注于解决这类问题,比如我们熟知的xxl-job. 那么今天要给大家推荐的则是另一个更为强大的开源 ...
- Linux操作命令(九)1.comm命令 2.diff命令 3.patch命令
1.comm 命令 比较文本文件的内容 comm 命令将逐行比较已经排序的两个文件.显示结果包括 3 列:第 1 列为只在第一个文件中找到的行,第 2 列为只在第二个文件中找到的行,第 3 列为两个文 ...
- Mybatis-plus中通用mapper的CRUD(增、删、改、查)操作封装BaseMapper和IService(最详细)
使用Mybatis的开发者,大多数都会遇到一个问题,就是要写大量的SQL在xml文件中,除了特殊的业务逻辑SQL之外,还有大量结构类似的增删改查SQL.而且,当数据库表结构改动时,对应的所有SQL以及 ...
- 随机颜色,加载loading效果,节流,应用周期函数,wxs
随机颜色 data: { colorList:[] }, getColor(){ wx.request({ url: 'https://www.escook.cn/api/color', method ...
- 关于MFC程序关闭之后仍有线程存留
最近弄了一个项目,关闭之后在任务管理器中依然存留,刚开始以为是因为子线程没能退出,就用ExitThread来终止,终止之后发现好像并不是子线程的原因 查了好久没能找到原因 最后只能通杀 HANDLE ...
- 数据库多表连接查询中使用group by分组语句,Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'XXX' which is not functionally dependent on columns in GROUP BY claus
需求描述: 要是用两表联合查询,并对查询的结果进行分组:sql如下: 1 SELECT 2 a.`id`, 3 a.`fr_num`, 4 b.`ent_status` 5 FROM 6 `table ...
- 以图搜图功能实现(windows10版)
1,原理 存储:通过Core项目调取python接口,python通过使用towhee把图片转成向量存在milvus向量数据库中. 查询:通过Core项目调取python接口,python根据查询的图 ...