基于python爬虫技术对于淘宝的数据分析的设计与实现
本篇仅在于交流学习
本文主要介绍通过 selenium 模块和 requests 模块,同时让机器模拟人在浏览器上的行为,登录指定的网站,通过网站内部的搜索引擎来搜索自己相应的信息,从而获取相应关键字的商品信息,并进而获取数据,然后通过csv模块将数据存储到本地库中,接着在通过pandas、jieba、matplotlib 等模块进行分析,得出数据的特征。
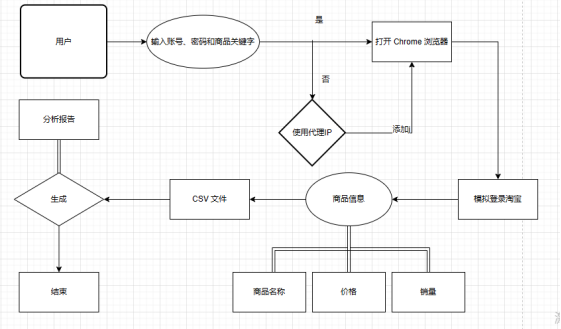
本章对本系统设计的功能性需求和非功能性需求进行了详细的分析。把系统所需要的模块进行了整理和划分,明确了各个功能的需求。
设计任务:完成一个基于爬虫的网络页面和数据分析
(1)访问功能:使用爬虫进行页面访问。
(2)查询功能:运用程序在页面上进行自动关键字查询。
(3)爬取功能:对于页面上的信息进行过滤和针对化的爬取。
(4)存储功能:对于信息进行本地化的存储,将爬取数据保存至csv文件内。
(5)数据分析功能:对于本地化数据进行数据分析和数据展示。
构建HTTP伪装
这是针对 Selenium WebDriver 的 ChromeDriver 来设置的一组浏览器参数,以在爬取网站时提高程序稳定性和安全性。这些参数的主要作用如下:
1. '--disable-extensions':禁用 Chrome 扩展,避免插件对页面渲染产生影响。
2. '--disable-blink-features=AutomationControlled':禁用自动控制特性,避免被目标网站检测到使用了自动化爬虫。
3. '--no-sandbox':关闭 Chrome 浏览器的沙盘机制,提高程序的运行速度。
4. '--disable-dev-shm-usage':禁用 '/dev/shm' 临时文件系统,可避免程序因为内存不足而崩溃。
5. '--disable-gpu':禁用 GPU 硬件加速,减少程序资源占用。
6. '--start-maximized':开启浏览器最大化窗口模式,优化用户体验。
7. 'add_experimental_option('excludeSwitches', ['enable-automation'])':禁用自动化开关,并防止目标网站检测到 WebDriver 的使用情况。
8. 'add_experimental_option('useAutomationExtension', False)':禁用自动化扩展功能,避免被目标网站检测到使用了自动化爬虫。
9. '--user-agent':指定浏览器的 User-Agent,在请求目标网站时伪装成一个正常的浏览器访问,避免被目标网站检测到使用了自动化爬虫。
10.'chrome_options.add_argument("--proxy-server=http://{}".format(proxy_address))' 这行代码可以在使用Selenium自动化测试时配置代理服务器。具体来说,'chrome_options' 是chrome浏览器的选项对象,'add_argument()' 方法是向该选项对象中添加参数的方法。
其中, '--proxy-server' 是Chrome浏览器的一个参数,用来设置代理服务器地址。代理服务器地址一般包括 IP 地址和端口号,这里的 'proxy_address' 就是一个包含IP地址和端口号的变量。
使用格式化字符串 '"{}'".format(proxy_address)' 将代理服务器地址插入到参数字符串中,最终生成一个完整的代理服务器地址,然后将其作为参数传递给 'add_argument()' 方法。
这样,启动 Chrome 浏览器时,就会按照传入的代理服务器地址来进行网络请求,并通过该代理服务器获取网页内容。这在需要匿名爬取数据或测试一些需要使用代理的网站时非常有用。
这些设置是为了在爬取目标网站时提高程序稳定性、安全性和隐蔽性。
headers = {
'User-Agent': '自己的请求头'
}
chrome_options = webdriver.ChromeOptions()
# 设置ChromeDriver的options参数,以隐藏自动化控制
chrome_options.add_argument('--disable-extensions')
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--start-maximized')
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_experimental_option('useAutomationExtension', False)
chrome_options.add_argument(f'user-agent={headers["User-Agent"]}')
# 判断是否使用代理IP
proxy_address = get_proxy()
if proxy_address is not None:
chrome_options.add_argument("--proxy-server=http://{}".format(proxy_address)) # 添加代理IP地址和端口号到ChromeOptions中
# 创建ChromeDriver对象
driver = webdriver.Chrome(options=chrome_options)
模拟登录
使用 Selenium WebDriver 实现淘宝网站登录的 Python 函数。其主要实现逻辑如下:
1. 跳转到淘宝登录页面:利用 WebDriver 打开淘宝网站登录页面。
2. 输入账号和密码:使用 'find_element_by_id' 方法找到对应的元素并输入对应的账号和密码。
3. 登录验证:等待用户输入验证码,并点击登录按钮进行验证。如果登录成功,则返回登录成功的浏览器实例,否则打印错误信息并关闭浏览器,返回 None。
该函数仅作为示例参考,在实际爬虫开发中需结合目标网站的特定情况进行调整和优化。
def login_taobao(driver, username, password):
# 跳转到淘宝登陆页面
driver.get('https://login.taobao.com/member/login.jhtml')
# 输入账号和密码
username_input = driver.find_element_by_id('fm-login-id')
password_input = driver.find_element_by_id('fm-login-password')
username_input.click()
username_input.send_keys(username)
password_input.click()
password_input.send_keys(password)
time.sleep(10)
# 登陆验证
try:
# 等待用户输入验证码
time.sleep(20)
# 点击登陆按钮
actions = ActionChains(driver)
actions.move_to_element(driver.find_element_by_class_name('fm-submit'))
actions.click().perform()
print('登录成功')
except Exception as e:
print('登录失败: ', e)
driver.quit()
return None
time.sleep(3)
return driver
信息爬取
使用 Selenium WebDriver 实现淘宝网站商品爬取的 Python 函数。主要实现逻辑如下:
1. 通过 'driver.get()' 方法打开淘宝网站搜索页,并使用通过让程序进行暂停操作逃逸反爬虫检测'time.sleep()' 方法等待网页数据加载完成。
2. 使用 'driver.find_elements_by_xpath()' 方法找到页面上所有需要爬取的商品元素,遍历每个元素,并使用 'find_element_by_xpath()' 方法定位元素中需要爬取的信息。
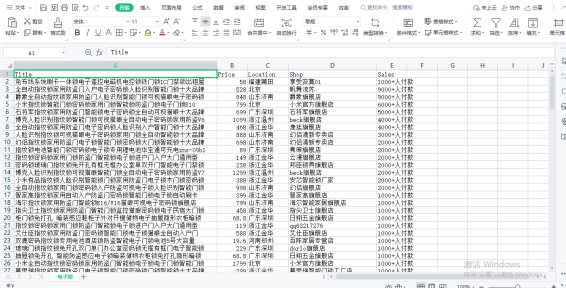
3. 将爬取到的数据存储为字典格式,并添加到 data 列表中。
4. 如果在遍历过程中出现异常情况,将错误信息打印到控制台。
5. 打印当前已完成的页面数。
def crawl_taobao(driver, keyword, pages):
data = []
for i in range(1, pages+1): # 爬取相应页面的商品信息
url = 'https://s.taobao.com/search?q={}&s={}'.format(keyword, (i-1)*44)
driver.get(url)
time.sleep(5)
products = driver.find_elements_by_xpath('//div[@class="items"][1]/div[contains(@class, "item")]')
for product in products:
try:
# 爬取商品名称、价格、地点、店铺和销量等信息
title = product.find_element_by_xpath(".//div[@class='row row-2 title']/a")
price = product.find_element_by_xpath('.//div[@class="price g_price g_price-highlight"]/strong')
location = product.find_element_by_xpath('.//div[@class="location"]')
shop = product.find_element_by_xpath('.//div[@class="shop"]/a/span[2]')
sales = product.find_element_by_xpath('.//div[@class="deal-cnt"]')
data.append({'Title': title.text.strip(),
'Price': float(price.text.strip()),
'Location': location.text.strip().replace(' ', ''),
'Shop': shop.text.strip(),
'Sales': sales.text.strip()})
except Exception as e:
print('Error:', e)
print('已完成第{}页'.format(i))
# 将数据存储为CSV文件
df = pd.DataFrame(data)
with open(keyword + '.csv', 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f, quoting=csv.QUOTE_ALL)
writer.writerow(['Title', 'Price', 'Location', 'Shop', 'Sales'])
for item in data:
writer.writerow([item['Title'].replace('"', '""'), item['Price'], item['Location'].replace('"', '""'),
item['Shop'].replace('"', '""'), item['Sales']])
return df
1. 使用 Pandas 库的 'DataFrame()' 方法,将爬取到的商品数据 'data' 转换为 DataFrame 格式。
2. 使用 Python 的 CSV 库打开一个新的 CSV 文件,将数据按照指定格式按行写入文件中。
3. 将 DataFrame 格式的数据返回供后续使用。
数据分析
1. 使用 Pandas 库的 'mean()'、'min()' 和 'max()' 方法,分别计算该 DataFrame 中的价格均值、最低价和最高价,并将结果输出到控制台。
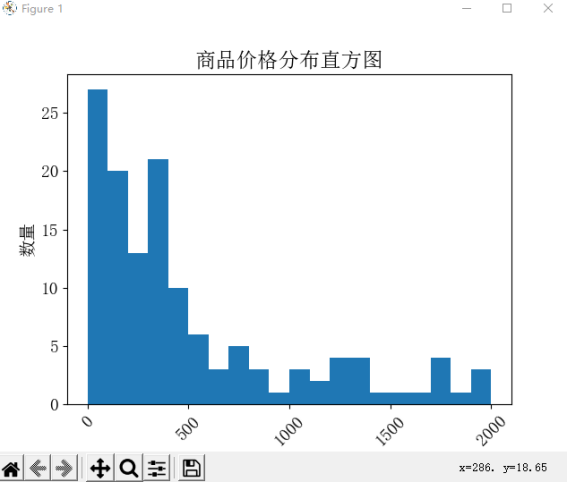
2. 使用 Matplotlib 库的 'hist()' 方法,绘制商品价格的直方图,其中 bins 参数表示划分价格区间的个数,range 参数表示价格区间的范围。
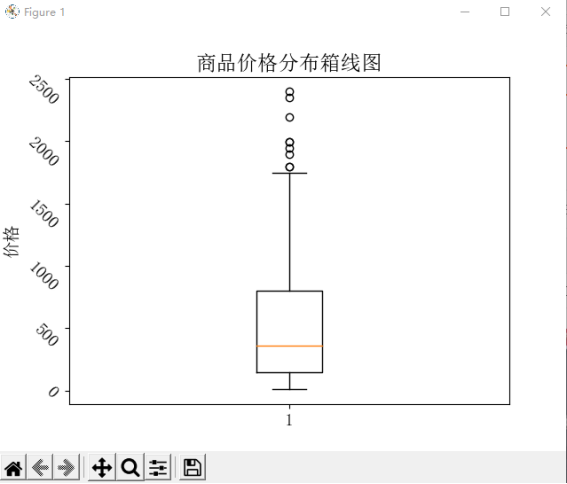
3. 使用 Matplotlib 库的 'boxplot()' 方法,绘制商品价格的箱线图,用于展示价格分布的离散程度,其中 yticks 参数可以调整箱线图的 y 轴标签方向。
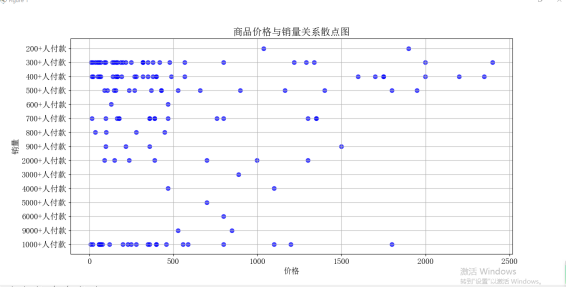
4. 使用 Matplotlib 库的 'scatter()' 方法,绘制商品价格和销量的散点图,用于展示两者之间的相关性。
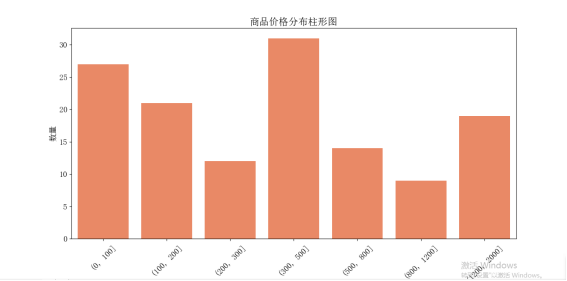
5. 使用 Seaborn 库的 'barplot()' 方法,绘制商品价格的柱形图,其中使用 'pd.cut()' 方法对价格数据进行分组,并可以指定分组区间,以便更好地展示价格分布情况。
生成词云图
1. 将所有的地区名称通过空格拼接成一个字符串,并使用 jieba 库的 'lcut()' 方法对字符串进行分词。
2. 创建 WordCloud 对象,并指定一些参数,例如背景颜色、字体文件路径和停用词列表等。
3. 调用 WordCloud 对象的 'generate()' 方法,根据输入的文本生成词云图。
4. 使用 Matplotlib 库的 'imshow()' 方法,显示生成的词云图,并使用 'axis()' 方法隐藏坐标轴。
# 定义函数分析商品价格
def analyze_price(df):
# 统计均价、最低价和最高价,并显示到控制台
avg_price = round(df['Price'].mean(), 2)
min_price = df['Price'].min()
max_price = df['Price'].max()
print('均价{}元,最低价{}元,最高价{}元'.format(avg_price, min_price, max_price)) # 绘制商品价格的直方图
plt.hist(df['Price'], bins=20, range=(0, 2000))
plt.xlabel('价格', fontsize=14)
plt.ylabel('数量', fontsize=14)
plt.xticks(rotation=45)
plt.yticks(fontsize=14)
plt.title('商品价格分布直方图')
plt.show() # 绘制商品价格的箱线图
plt.boxplot(df['Price'])
plt.ylabel('价格', fontsize=14)
plt.yticks(fontsize=14, rotation=-45)
plt.title('商品价格分布箱线图')
plt.show() # 绘制商品价格和销量的散点图
plt.scatter(df['Price'], df['Sales'], s=50, alpha=0.7, c='b', marker='o')
plt.xlabel('价格')
plt.ylabel('销量')
plt.title('商品价格与销量关系散点图')
plt.grid(True)
plt.show() # 绘制商品价格的柱形图
df_price = df.groupby(pd.cut(df['Price'], bins=[0, 100, 200, 300, 500, 800, 1200, 2000]))['Price'].count()
plt.figure(figsize=(8, 6))
sns.barplot(x=df_price.index.astype(str), y=df_price.values, color='coral')
plt.xlabel('价格区间', fontsize=14)
plt.ylabel('数量', fontsize=14)
plt.xticks(rotation=45)
plt.yticks(fontsize=14)
plt.title('商品价格分布柱形图')
plt.show() # 定义函数生成地区词云图
def make_location_wordcloud(df):
# 合并所有地区数据为一个字符串
location_str = ' '.join(df['Location'])
# 使用jieba库对字符串进行分词
words = jieba.lcut(location_str)
new_location_str = ' '.join(words)
# 停用词列表
stopwords = ['市', '省', '自治区', '特别行政区']
# 创建WordCloud对象
wc = WordCloud(background_color='white', font_path='msyh.ttc', stopwords=stopwords)
# 生成词云图
wc.generate(new_location_str)
# 显示词云图
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
添加代理地址判断功能及有关于输入数据判断出错处理
数据判断
1. 使用 Python 的 'while' 循环,一直等待用户输入,直到输入格式正确为止。
2. 使用内置函数 'int()' 将用户输入的字符串转换为整数类型。
3. 如果输入内容不能正常转换为整数,则捕获 'ValueError' 异常,并提示用户重新输入。
4. 如果用户输入正确,将输入的整数作为函数返回值。
代理IP判断
1. 使用 'input()' 函数让用户选择是否使用代理 IP,当输入不为 'Y' 或者 'N' 时,通过 'while' 循环不断重新提示输入直至正确。
2. 如果用户选择使用代理 IP,通过 'input()' 函数获取代理 IP,如果输入不符合规范,通过多层嵌套的 'try...except...' 分别对输入的 IP 和端口号进行校验,分别检查其是否在规定的范围内和是否符合 IPv4 地址格式。
3. 如有输入不符合规范,通过 'print()' 函数及 'input()' 函数让用户选择操作。
4. 如果用户选择重新输入代理 IP,则通过 'continue' 关键字实现循环,反之返回 'None'。
# 定义函数输入数字是否有误
def get_pages():
while True:
try:
pages = int(input('请输入要爬取的页码数:'))
break
except ValueError:
print("请输入数字!")
return pages # 定义函数是否使用代理IP
def get_proxy():
use_proxy = input('是否需要使用代理IP?(Y/N):').upper()
# 判断输入是否有误
while use_proxy not in ['Y', 'N']: # 如果输入的字符不是Y或N,则重新提示输入
print('请输入正确的(Y/N)')
use_proxy = input('是否需要使用代理IP?(Y/N):').upper()
if use_proxy == 'Y':
proxy_address = input('请输入代理IP地址和端口号(例如:ip:port):')
# 判断代理IP是否正确
while True:
try:
ip, port = proxy_address.split(':') # 提取IP地址和端口号
if not (0 < int(port) < 65536): # 端口号不在合法范围内
print('代理IP地址和端口号输入有误,请选择操作:')
print('1. 重新输入代理IP地址和端口号')
print('2. 不使用代理IP')
choice = input('请选择操作(1/2):')
while choice not in ['1', '2']:
print('请输入正确的选项:')
choice = input('请选择操作(1/2):')
if choice == '1':
proxy_address = input('请输入代理IP地址和端口号(例如:ip:port):')
continue
else:
return None
parts = ip.split('.')
if len(parts) != 4 or not all(0 <= int(part) < 256 for part in parts): # IP地址格式不正确
print('代理IP地址和端口号输入有误,请选择操作:')
print('1. 重新输入代理IP地址和端口号')
print('2. 不使用代理IP')
choice = input('请选择操作(1/2):')
while choice not in ['1', '2']:
print('请输入正确的选项:')
choice = input('请选择操作(1/2):')
if choice == '1':
proxy_address = input('请输入代理IP地址和端口号(例如:ip:port):')
continue
else:
return None
break # 输入合法,跳出循环
except Exception:
print('代理IP地址和端口号输入有误,请选择操作:')
print('1. 重新输入代理IP地址和端口号')
print('2. 不使用代理IP')
choice = input('请选择操作(1/2):')
while choice not in ['1', '2']:
print('请输入正确的选项:')
choice = input('请选择操作(1/2):')
if choice == '1':
proxy_address = input('请输入代理IP地址和端口号(例如:ip:port):')
else:
return None
return proxy_address
else:
print('不使用代理IP。') # 直接提示用户不使用代理IP
return None
运行结果

完整代码
import csv
import time
from selenium.webdriver.common.proxy import Proxy, ProxyType
import jieba
import matplotlib as mpl
import matplotlib.pyplot as plt
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from wordcloud import WordCloud
import seaborn as sns mpl.rcParams['font.family'] = 'SimSun'
mpl.rcParams['font.size'] = 14 # 定义函数模拟登陆淘宝
def login_taobao(driver, username, password):
# 跳转到淘宝登陆页面
driver.get('https://login.taobao.com/member/login.jhtml')
# 输入账号和密码
username_input = driver.find_element_by_id('fm-login-id')
password_input = driver.find_element_by_id('fm-login-password')
username_input.click()
username_input.send_keys(username)
password_input.click()
password_input.send_keys(password)
time.sleep(10)
# 登陆验证
try:
# 等待用户输入验证码
time.sleep(20)
# 点击登陆按钮
actions = ActionChains(driver)
actions.move_to_element(driver.find_element_by_class_name('fm-submit'))
actions.click().perform()
print('登录成功')
except Exception as e:
print('登录失败: ', e)
driver.quit()
return None
time.sleep(3)
return driver # 定义函数爬取淘宝商品信息
def crawl_taobao(driver, keyword, pages):
data = []
for i in range(1, pages+1): # 爬取相应页面的商品信息
url = 'https://s.taobao.com/search?q={}&s={}'.format(keyword, (i-1)*44)
driver.get(url)
time.sleep(5)
products = driver.find_elements_by_xpath('//div[@class="items"][1]/div[contains(@class, "item")]')
for product in products:
try:
# 爬取商品名称、价格、地点、店铺和销量等信息
title = product.find_element_by_xpath(".//div[@class='row row-2 title']/a")
price = product.find_element_by_xpath('.//div[@class="price g_price g_price-highlight"]/strong')
location = product.find_element_by_xpath('.//div[@class="location"]')
shop = product.find_element_by_xpath('.//div[@class="shop"]/a/span[2]')
sales = product.find_element_by_xpath('.//div[@class="deal-cnt"]')
data.append({'Title': title.text.strip(),
'Price': float(price.text.strip()),
'Location': location.text.strip().replace(' ', ''),
'Shop': shop.text.strip(),
'Sales': sales.text.strip()})
except Exception as e:
print('Error:', e)
print('已完成第{}页'.format(i))
# 将数据存储为CSV文件
df = pd.DataFrame(data)
with open(keyword + '.csv', 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f, quoting=csv.QUOTE_ALL)
writer.writerow(['Title', 'Price', 'Location', 'Shop', 'Sales'])
for item in data:
writer.writerow([item['Title'].replace('"', '""'), item['Price'], item['Location'].replace('"', '""'),
item['Shop'].replace('"', '""'), item['Sales']])
return df # 定义函数分析商品价格
def analyze_price(df):
# 统计均价、最低价和最高价,并显示到控制台
avg_price = round(df['Price'].mean(), 2)
min_price = df['Price'].min()
max_price = df['Price'].max()
print('均价{}元,最低价{}元,最高价{}元'.format(avg_price, min_price, max_price)) # 绘制商品价格的直方图
plt.hist(df['Price'], bins=20, range=(0, 2000))
plt.xlabel('价格', fontsize=14)
plt.ylabel('数量', fontsize=14)
plt.xticks(rotation=45)
plt.yticks(fontsize=14)
plt.title('商品价格分布直方图')
plt.show() # 绘制商品价格的箱线图
plt.boxplot(df['Price'])
plt.ylabel('价格', fontsize=14)
plt.yticks(fontsize=14, rotation=-45)
plt.title('商品价格分布箱线图')
plt.show() # 绘制商品价格和销量的散点图
plt.scatter(df['Price'], df['Sales'], s=50, alpha=0.7, c='b', marker='o')
plt.xlabel('价格')
plt.ylabel('销量')
plt.title('商品价格与销量关系散点图')
plt.grid(True)
plt.show() # 绘制商品价格的柱形图
df_price = df.groupby(pd.cut(df['Price'], bins=[0, 100, 200, 300, 500, 800, 1200, 2000]))['Price'].count()
plt.figure(figsize=(8, 6))
sns.barplot(x=df_price.index.astype(str), y=df_price.values, color='coral')
plt.xlabel('价格区间', fontsize=14)
plt.ylabel('数量', fontsize=14)
plt.xticks(rotation=45)
plt.yticks(fontsize=14)
plt.title('商品价格分布柱形图')
plt.show() # 定义函数生成地区词云图
def make_location_wordcloud(df):
# 合并所有地区数据为一个字符串
location_str = ' '.join(df['Location'])
# 使用jieba库对字符串进行分词
words = jieba.lcut(location_str)
new_location_str = ' '.join(words)
# 停用词列表
stopwords = ['市', '省', '自治区', '特别行政区']
# 创建WordCloud对象
wc = WordCloud(background_color='white', font_path='msyh.ttc', stopwords=stopwords)
# 生成词云图
wc.generate(new_location_str)
# 显示词云图
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show() # 定义函数输入数字是否有误
def get_pages():
while True:
try:
pages = int(input('请输入要爬取的页码数:'))
break
except ValueError:
print("请输入数字!")
return pages # 定义函数是否使用代理IP
def get_proxy():
use_proxy = input('是否需要使用代理IP?(Y/N):').upper()
# 判断输入是否有误
while use_proxy not in ['Y', 'N']: # 如果输入的字符不是Y或N,则重新提示输入
print('请输入正确的(Y/N)')
use_proxy = input('是否需要使用代理IP?(Y/N):').upper()
if use_proxy == 'Y':
proxy_address = input('请输入代理IP地址和端口号(例如:ip:port):')
# 判断代理IP是否正确
while True:
try:
ip, port = proxy_address.split(':') # 提取IP地址和端口号
if not (0 < int(port) < 65536): # 端口号不在合法范围内
print('代理IP地址和端口号输入有误,请选择操作:')
print('1. 重新输入代理IP地址和端口号')
print('2. 不使用代理IP')
choice = input('请选择操作(1/2):')
while choice not in ['1', '2']:
print('请输入正确的选项:')
choice = input('请选择操作(1/2):')
if choice == '1':
proxy_address = input('请输入代理IP地址和端口号(例如:ip:port):')
continue
else:
return None
parts = ip.split('.')
if len(parts) != 4 or not all(0 <= int(part) < 256 for part in parts): # IP地址格式不正确
print('代理IP地址和端口号输入有误,请选择操作:')
print('1. 重新输入代理IP地址和端口号')
print('2. 不使用代理IP')
choice = input('请选择操作(1/2):')
while choice not in ['1', '2']:
print('请输入正确的选项:')
choice = input('请选择操作(1/2):')
if choice == '1':
proxy_address = input('请输入代理IP地址和端口号(例如:ip:port):')
continue
else:
return None
break # 输入合法,跳出循环
except Exception:
print('代理IP地址和端口号输入有误,请选择操作:')
print('1. 重新输入代理IP地址和端口号')
print('2. 不使用代理IP')
choice = input('请选择操作(1/2):')
while choice not in ['1', '2']:
print('请输入正确的选项:')
choice = input('请选择操作(1/2):')
if choice == '1':
proxy_address = input('请输入代理IP地址和端口号(例如:ip:port):')
else:
return None
return proxy_address
else:
print('不使用代理IP。') # 直接提示用户不使用代理IP
return None # 创建总方法调用函数
def main():
# 用户输入账号、密码和要搜索的商品关键字
username = input('请输入淘宝账号:')
password = input('请输入淘宝密码:')
keyword = input('请输入要搜索的商品关键字:') # 输入数字是否有误
pages = get_pages() # 设置请求头信息
headers = {
'User-Agent': '自己的请求头'
}
chrome_options = webdriver.ChromeOptions()
# 设置ChromeDriver的options参数,以隐藏自动化控制
chrome_options.add_argument('--disable-extensions')
chrome_options.add_argument('--disable-blink-features=AutomationControlled')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--start-maximized')
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_experimental_option('useAutomationExtension', False)
chrome_options.add_argument(f'user-agent={headers["User-Agent"]}') # 判断是否使用代理IP
proxy_address = get_proxy()
if proxy_address is not None:
chrome_options.add_argument("--proxy-server=http://{}".format(proxy_address)) # 添加代理IP地址和端口号到ChromeOptions中 # 创建ChromeDriver对象
driver = webdriver.Chrome(options=chrome_options)
driver = login_taobao(driver, username, password) # 如果登陆成功,进行商品信息爬取、价格分析和词云制作
if driver is not None:
df = crawl_taobao(driver, keyword, pages)
# 如果爬取到的数据不为空,才进行价格分析和词云制作
if not df.empty:
analyze_price(df)
make_location_wordcloud(df) # 关闭浏览器
driver.quit() if __name__ == '__main__':
main()
结尾
这是根据模拟登陆进行淘宝网内部商品的数据获取和分析制作的一个小工具,考虑到淘宝网内部进行反爬虫技术强面对滑块登录验证还暂且无法做到,但是进行试验还是可以,在使用时需配合ChromeDriver使用,通过与Selenium Webdriver一起使用,来自动化执行各种Web操作。
基于python爬虫技术对于淘宝的数据分析的设计与实现的更多相关文章
- 利用Python爬虫爬取淘宝商品做数据挖掘分析实战篇,超详细教程
项目内容 本案例选择>> 商品类目:沙发: 数量:共100页 4400个商品: 筛选条件:天猫.销量从高到低.价格500元以上. 项目目的 1. 对商品标题进行文本分析 词云可视化 2. ...
- Python爬虫(三)爬淘宝MM图片
直接上代码: # python2 # -*- coding: utf-8 -*- import urllib2 import re import string import os import shu ...
- 基于python爬虫的github-exploitdb漏洞库监控与下载
基于python爬虫的github-exploitdb漏洞库监控与下载 offensive.py(爬取项目历史更新内容) #!/usr/bin/env python # -*- coding:utf- ...
- 《Python爬虫技术:深入理解原理、技术与开发》已经出版,送Python基础视频课程
好消息,<Python爬虫技术:深入理解原理.技术与开发>已经出版!!! JetBrains官方推荐图书!JetBrains官大中华区市场部经理赵磊作序!送Python基础视频课程!J ...
- Python 002- 爬虫爬取淘宝上耳机的信息
参照:https://mp.weixin.qq.com/s/gwzym3Za-qQAiEnVP2eYjQ 一般看源码就可以解决问题啦 #-*- coding:utf-8 -*- import re i ...
- 零基础如何学Python爬虫技术?
在作者学习的众多编程技能中,爬虫技能无疑是最让作者着迷的.与自己闭关造轮子不同,爬虫的感觉是与别人博弈,一个在不停的构建 反爬虫 规则,一个在不停的破译规则. 如何入门爬虫?零基础如何学爬虫技术?那前 ...
- python(27) 抓取淘宝买家秀
selenium 是Web应用测试工具,可以利用selenium和python,以及chromedriver等工具实现一些动态加密网站的抓取.本文利用这些工具抓取淘宝内衣评价买家秀图片. 准备工作 下 ...
- Appium+python自动化3-启动淘宝app
前言 前面两篇环境已经搭建好了,接下来就是需要启动APP,如何启动app呢?首先要获取包名,然后获取launcherActivity.获取这两个关键东西的方法很多,这里就不一一多说,小伙伴们可以各显神 ...
- Python 实现毫秒级淘宝、京东、天猫等秒杀抢购脚本
本篇文章主要介绍了Python 通过selenium实现毫秒级自动抢购的示例代码,通过扫码登录即可自动完成一系列操作,抢购时间精确至毫秒,可抢加购物车等待时间结算的,也可以抢聚划算的商品. 该思路可运 ...
- python爬虫——爬取淘票票正在热映电影
今天正好学习了一下python的爬虫,觉得收获蛮大的,所以写一篇博客帮助想学习爬虫的伙伴们. 这里我就以一个简单地爬取淘票票正在热映电影为例,介绍一下一个爬虫的完整流程. 首先,话不多说,上干货——源 ...
随机推荐
- TFlite 多线程并行
import numpy as np from multiprocessing import Process, Queue def process_data(data, model_TSNet, ts ...
- 在Windows上访问linux的共享文件夹
1. https://blog.csdn.net/weixin_44147924/article/details/123692155
- .Net中跨域问题的解决方案
开发中前端与后端完全分离并分开发布,遇到跨域问题,一通百度之后,解决方案如下: 把下面的代码放在web.config文件中的 System.WebServer 节点下 <httpProtocol ...
- 一篇博客带你学会MyBatis
概念 MyBatis是一款持久层框架,用于简化JDBC操作(JavaEE三层架构:表现层(用来做页面的代码),业务层(业务逻辑代码),持久层(对数据库操作的代码))(框架就是一个半成品软件,是一套可重 ...
- RPA的概念及未来发展趋势
RPA是Robotic Process Automation(机器人自动化)的简称.我们可以把它理解为"虚拟机器人"替代人工的一种方式.RPA不仅可以模拟人类,而且可以利用和融 ...
- 保姆级本地maven安装配置步骤【Windows】
一.前期准备 1.首先需要安装并配置好本地JDK(WIN+R输入cmd,输入java -version如下图) 2.下载maven到本地(链接Maven – Download Apache Maven ...
- 坚叔:让科幻片的概念变成产品丨编程挑战赛 x 嘉宾分享
前言 本文基于资深创业者@坚叔在「RTE 2022 创新编程挑战赛」宣讲活动中分享内容二次整理. 嘉宾简介:陈坚(坚叔),国内二次元 AR/VR 资深创业者,国内第一批空间虚拟数字化从业人员,获得政府 ...
- Net DB Web多级缓存的实现
1.客户端缓存(浏览器缓存) HTTP有一套控制缓存的协议-RFC7234,其中最重要的就是cache-control这个相应报文头,服务器返回时,如果Response带上 cache-control ...
- Java里if和else的用法
前言 在上一篇文章中,壹哥给大家讲解了Java里的输入与输出语句,现在你知道怎么用了吗?接下来我们继续往下学习Java里的流程控制语句,今天先给大家讲一下if和else这一对好基友,这个知识点可以说是 ...
- 64位的单周期 RISC-V 模拟器
分享一个我最近完成过的小项目--64位的单周期 RISC-V 模拟器,这个项目我最近参与一生一芯计划过程中完成的一个小项目. 需要用到的相关知识:Verilog.Verilator.计算机组成原理.汇 ...