Seleniumweb自动化测试01
1、selenium简介
selenium是python的一个web第三方包,主要使用来做web自动化测试的
环境要求:
①、要有谷歌浏览器
②、下载谷歌浏览器的驱动chromedriver(驱动我们操作网页的):
首先需要找到谷歌浏览器的版本号(三个点--->帮助--->关于Google chrome)
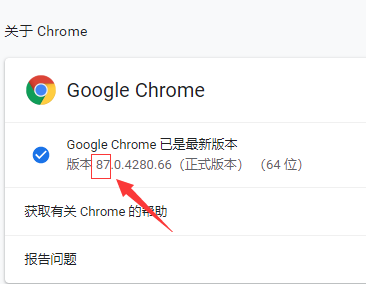
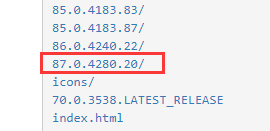
再下载对应版本号的驱动文件,网址:http://npm.taobao.org/mirrors/chromedriver/
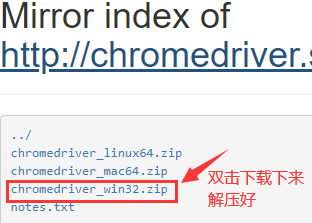
③、安装selenium,以管理员身份打开cmd,输入以下命令:pip3 install selenium -i https://pypi.tuna.tsinghua.edu.cn/simple

2、步骤
2.1、新建文件夹seleniumtest,并且将刚才解压的驱动文件copy进去
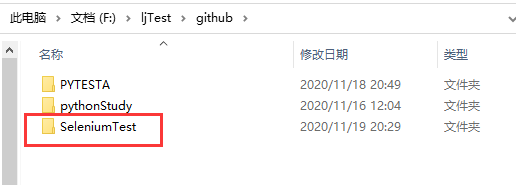
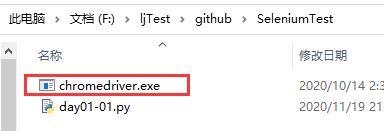
注意,这里取名字的时候,不能取和第三方包名字相同的文件夹,不然导入的时候会出问题
2.2、导入第三方包及驱动:
from selenium import webdriver
2.3、代码实现操作浏览器
2.3.1、打开浏览器:实例化浏览器句柄(把柄)
#1、打开浏览器:实例化浏览器句柄(把柄)
driver = webdriver.Chrome(executable_path="chromedriver.exe")
注意,这里有坑:Chrome,是大写的C
driver:浏览器操作对象(句柄/把柄)
executable_path:浏览器驱动文件路径:右键-复制相对路径
运行代码之后会自动打开浏览器,但是还什么都没有,只是打开浏览器这么一个操作,而且浏览器窗口不会自己关闭,需要手动关闭
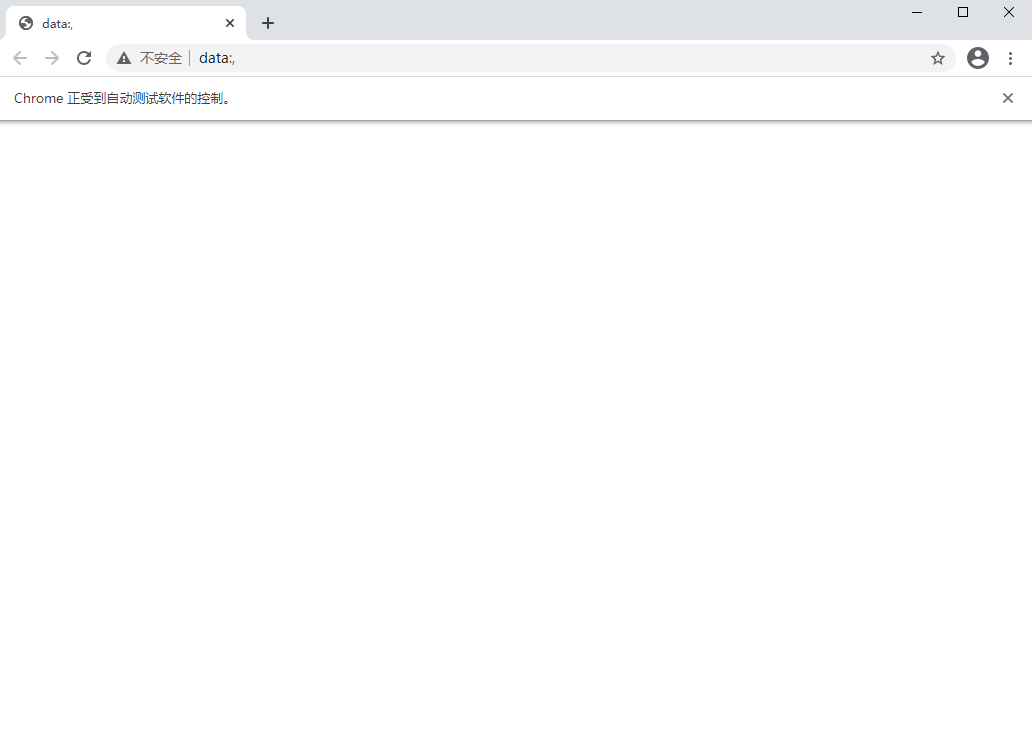
2.2.3、访问网站:用把柄去访问网站
这里使用get类型接口,去访问百度网站
#2、访问网站:用把柄去访问网站,get类型接口
driver.get("https://www.baidu.com")
注意先前运行打开的网页是不会自动关的,必须要手动关
2.2.3、模拟执行测试用例过程
打开了百度之后,肯定会想着在百度搜索框里输入内容再进行搜索,所以这里分为了两步,第一步输入文字,第二步点击搜索按钮
这里还需要补充点前置知识:
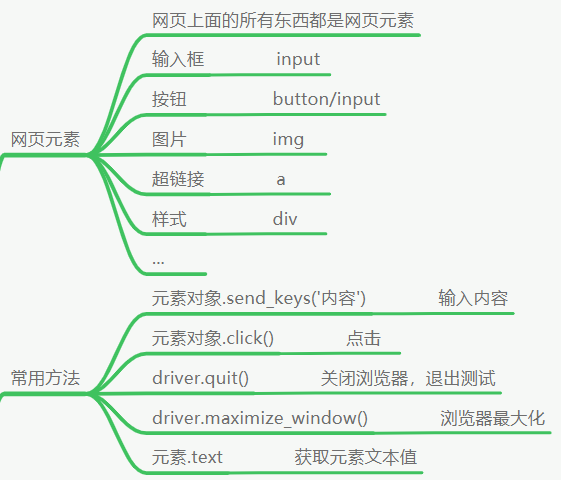
什么是网页元素:网站上的所有东西都是网页元素,通常情况下有以下内容
输入框:input
按钮:button/input
图片:img
超链接:a
样式:div
怎样去查看网页元素:用谷歌浏览器自带的开发者工具查看(element)
常用方法:
输入内容:元素对象.send_keys("内容")
点击:元素对象.click()
关闭测试,退出浏览器:driver.quit()(测试的时候浏览器是不会自动关闭的,调用这个方法就可以实现用完之后自动关闭,写在代码最后边就行)
打开浏览器时全屏显示:driver.maximize_window()(将这段代码加在打开浏览器代码后边,就可以实现打开浏览器时显示全屏)
获取元素的文本值:元素.text
2.3.3.1、输入文字
如果需要用selenium去操作元素的话,首先就要去定位元素,这里就涉及到了八大定位方式
还是一样的,在谷歌浏览器里打开开发者工具,然后点击左上角小箭头,在页面上选择,会自动定位到代码上
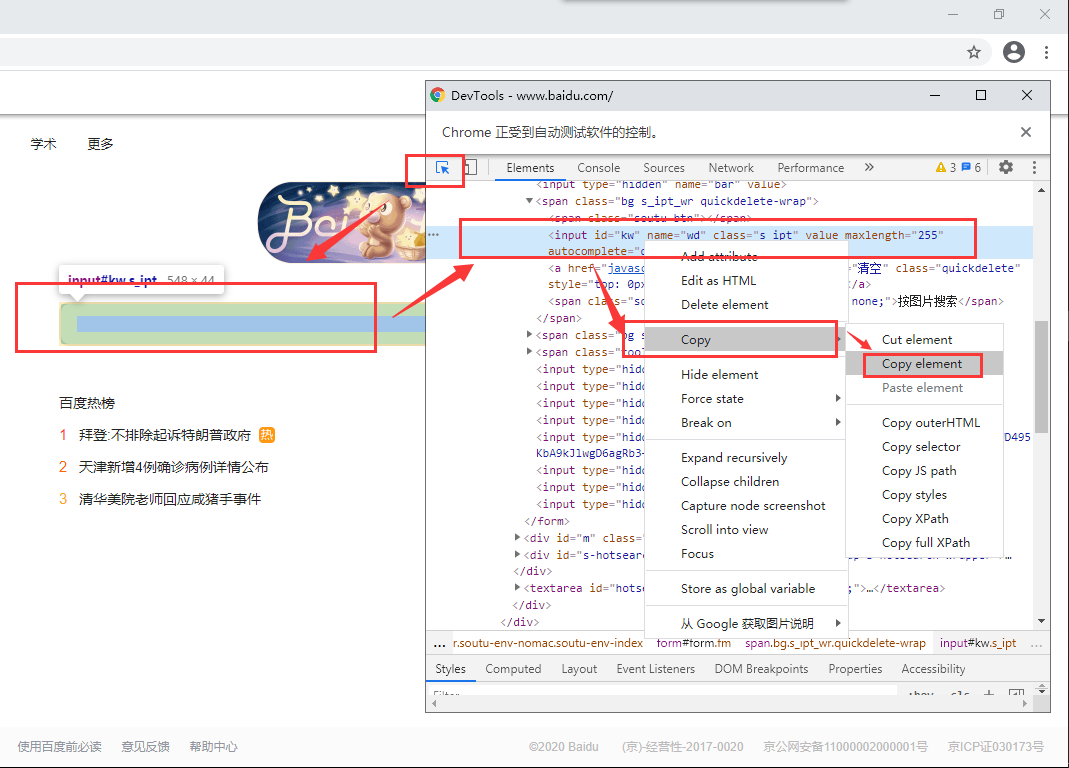
copy——copy element:这样就可以得到源码。例如选择了百度的输入框,复制源码:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
①、通过id值定位:
driver.find_element_by_id('kw').send_keys("hello 明天")
find_element_by_id()是selenium提供的方法
send_keys()是在输入内容
这段代码运行之后就会去打开百度网站并且定位到输入框这个元素,发送输入的内容,但是在这块是没有结果的,因为还没有点击百度一下这个按钮嘛
Ctrl+Shift +C:快速打开开发者工具定位元素
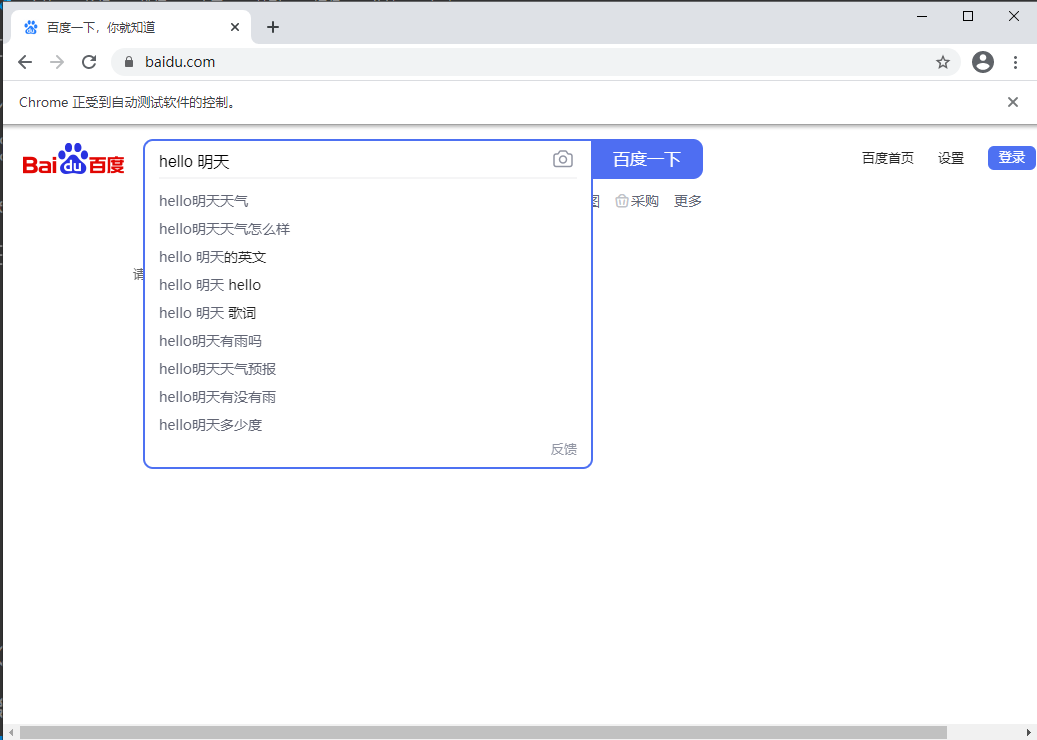
②、通过xpath定位
找到源码,右键copy——copy xpath
从网页上copy到的xpath://*[@id="kw"]
driver.find_element_by_xpath('//*[@id="kw"]').send_keys("hello,明天")
这里注意引号不相同原则,源码上的xpath有双引号,在方法里边就用单引号
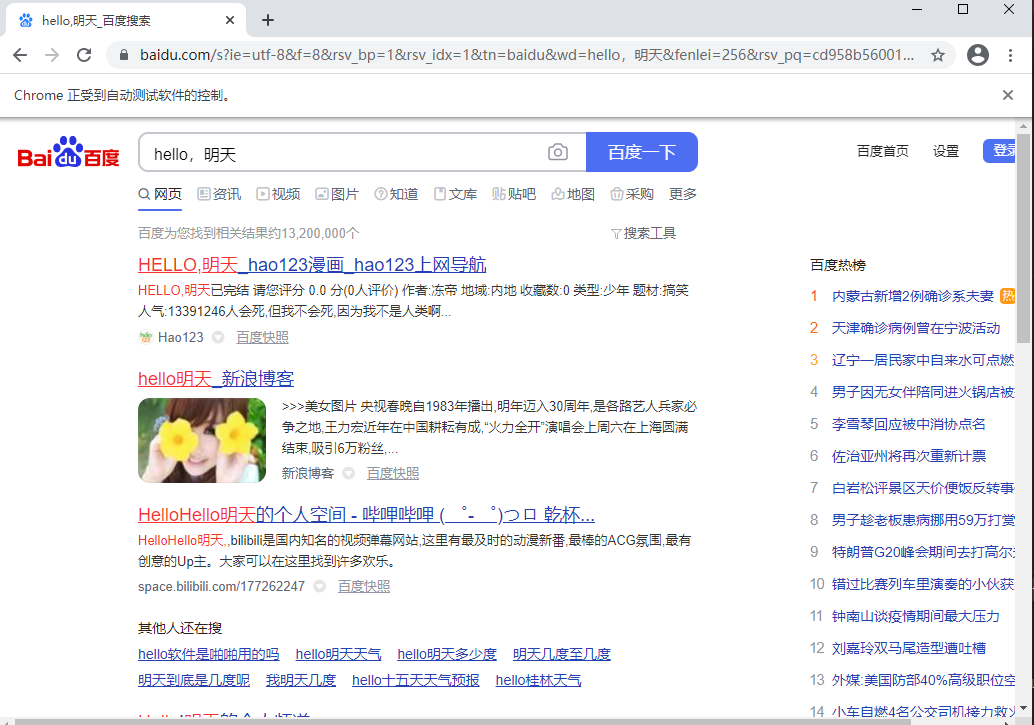
③、通过name定位
首先还是要先复制网页的源码:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
driver.find_element_by_name('wd').send_keys("hello 明天")
注意:这里VScode代码提醒有个坑,是find_element_by_name而不是elements,之后的定位元素也是一样的道理
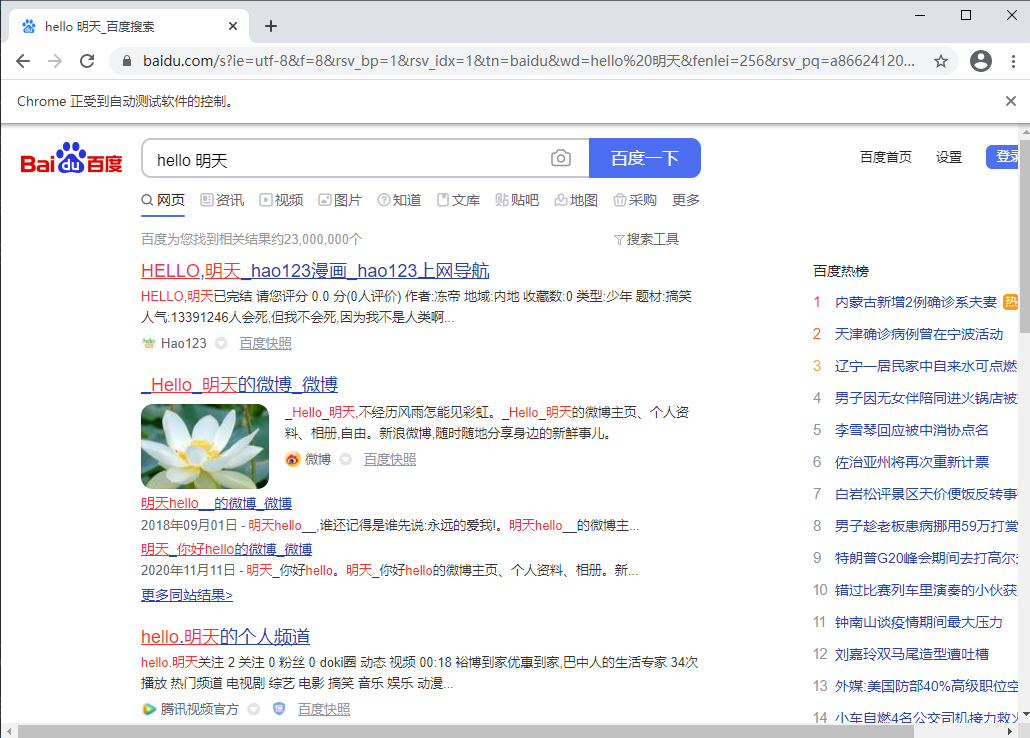
④、通过calssname定位
首先还是要先复制网页的源码:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
driver.find_element_by_class_name('s_ipt').send_keys("hello 明天")
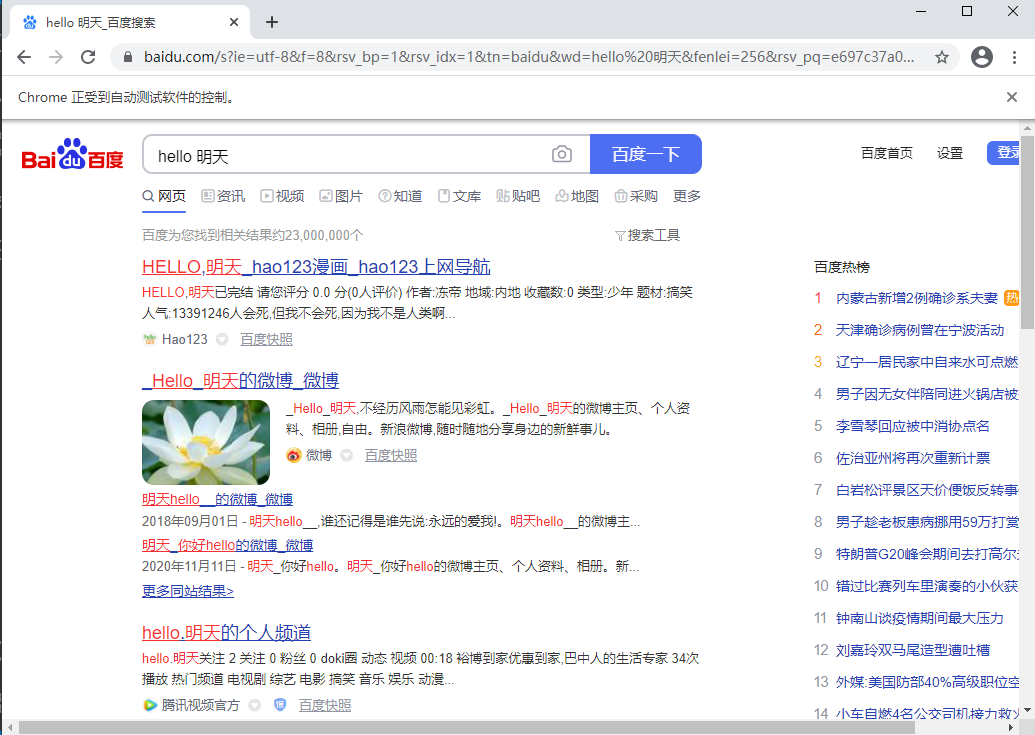
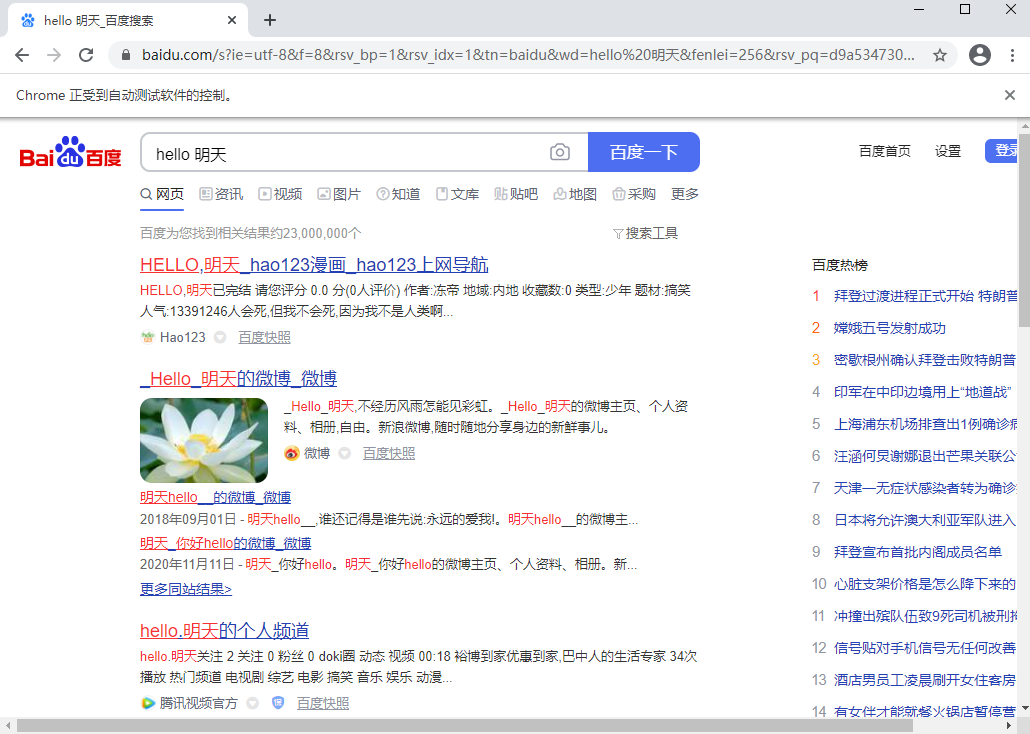
⑤、通过css selector定位
找到输入框的源码,右键copy——copy selector
从源码上复制的selector:#kw
driver.find_element_by_css_selector('#kw').send_keys("hello 明天")
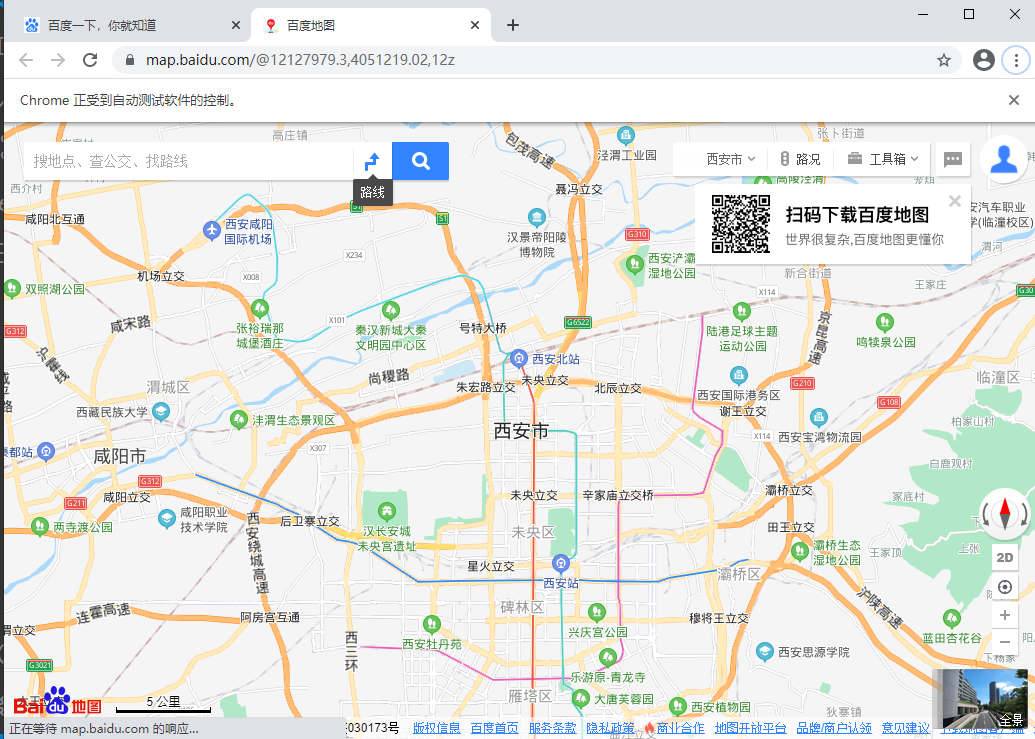
⑥、通过超链接定位
网页上源码以a开头的就是超链接,找到源码,copy——copy element
<a href="http://news.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">地图</a>
driver.find_element_by_link_text('地图').click()
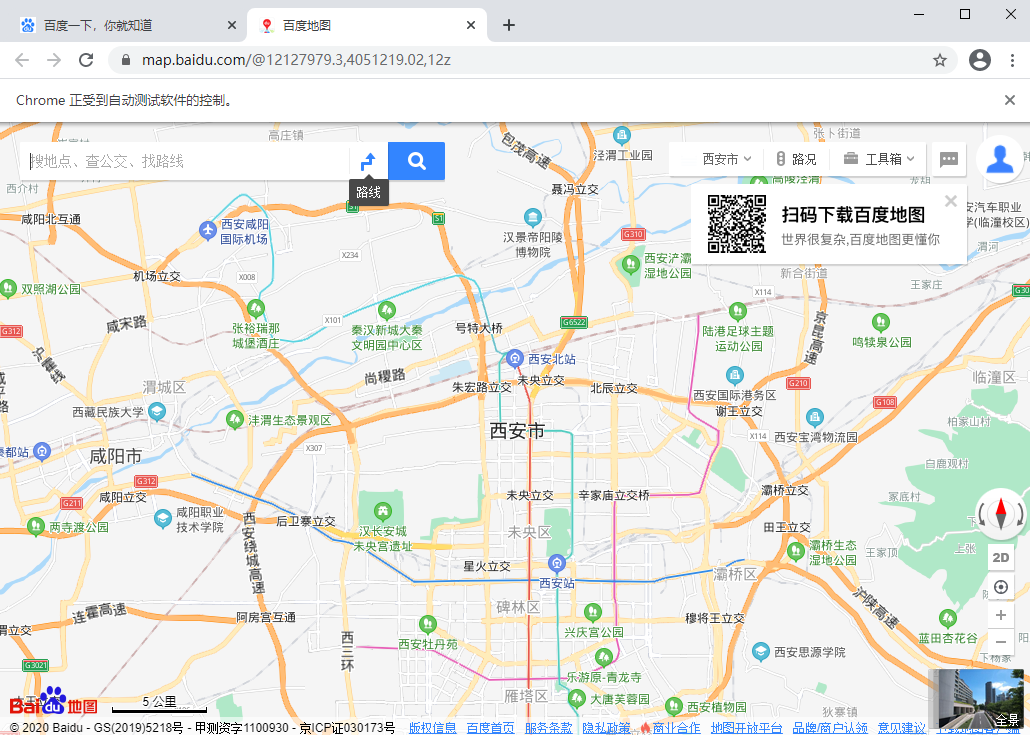
⑦、一部分文字定位超链接
首先还是要先拿到源码的,copy——copy element
<a href="http://map.baidu.com" target="_blank" class="mnav c-font-normal c-color-t">地图</a>
driver.find_element_by_partial_link_text('地').click()
⑧、通过tag name定位:即标签做左边的那个元素,比如这里就是input
driver.find_element_by_tag_name('input')
这个方法有很多坑,非常不推荐使用

注意:以上定位之所以能跳转页面,是因为还执行了下边的.click()方法
2.3.3.2、点击搜索按钮
首先还是要先定位到搜索按钮才能进行点击,按钮源码为(右键copy——copy element):
<input type="submit" id="su" value="百度一下" class="bg s_btn">
这里也是用的通过id值定位
driver.find_element_by_id('su').click()
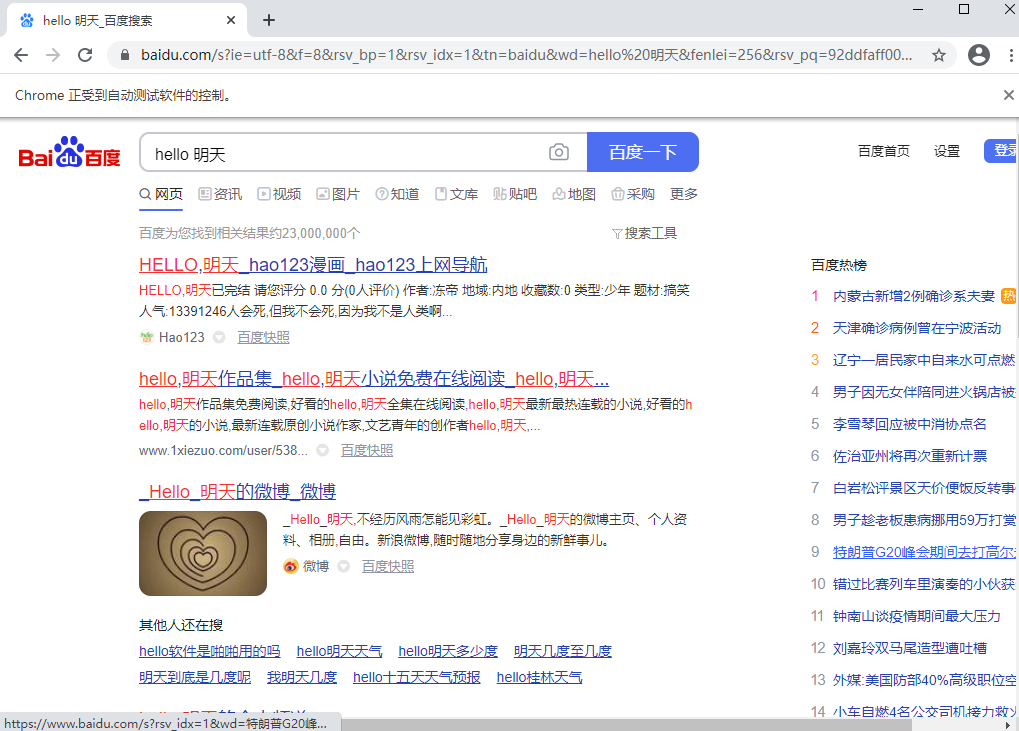
可以发现百度网站输入了指定的内容并且跳转成功搜索出结果了
注意:定位元素能用id就用id,不能用id就尽量用xpath
在开发者工具中双击并复制也可以将id值等元素复制下来,这样就可以不用每次都先把源码给复制下来了
3、元素查找机制
3.1、当找不到一个元素的时候
比如说现在通过id查找一个不存在的东西
driver.find_elements_by_id('cdhsvibvjdln.vlNV')
点击运行,会发现报异常
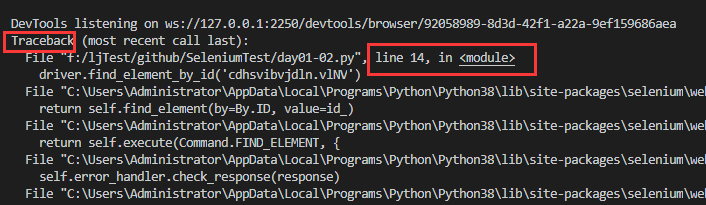
注意这里怎么去看报错的原因:哪一个代码是你写的,肯定就是那句代码报错嘛,比如此处的第十四行代码报错
3.2、当找到元素的时候,会返回网页元素的类型
用一个变量把找到的元素接收起来,再把它打印出来

终端打印出了网页元素的类型

4、练习:
流程:在shopx商城输入框中输入包包,点击搜索按钮,跳转页面
from selenium import webdriver #1、打开浏览器:实例化浏览器句柄(把柄)
#注意,这里有坑:Chrome,是大写的C
#driver:浏览器操作对象(句柄/把柄)
#executable_path:浏览器驱动文件路径:右键-复制相对路径
driver = webdriver.Chrome(executable_path="chromedriver.exe")
#浏览器全屏显示
driver.maximize_window() #2、访问网站:用把柄去访问网站,get类型接口
driver.get("http://118.24.255.132:9090/shopxo/") # 3、模拟测试用例的执行过程
#3.1、输入文字
# <input id="search-input" name="wd" type="text" placeholder="其实搜索很简单^_^ !" value="" autocomplete="off">
driver.find_element_by_id('search-input').send_keys('包包') #3.2、点击搜索按钮
#<input id="ai-topsearch" class="submit am-btn" index="1" type="submit" value="搜索">
driver.find_element_by_id('ai-topsearch').click()
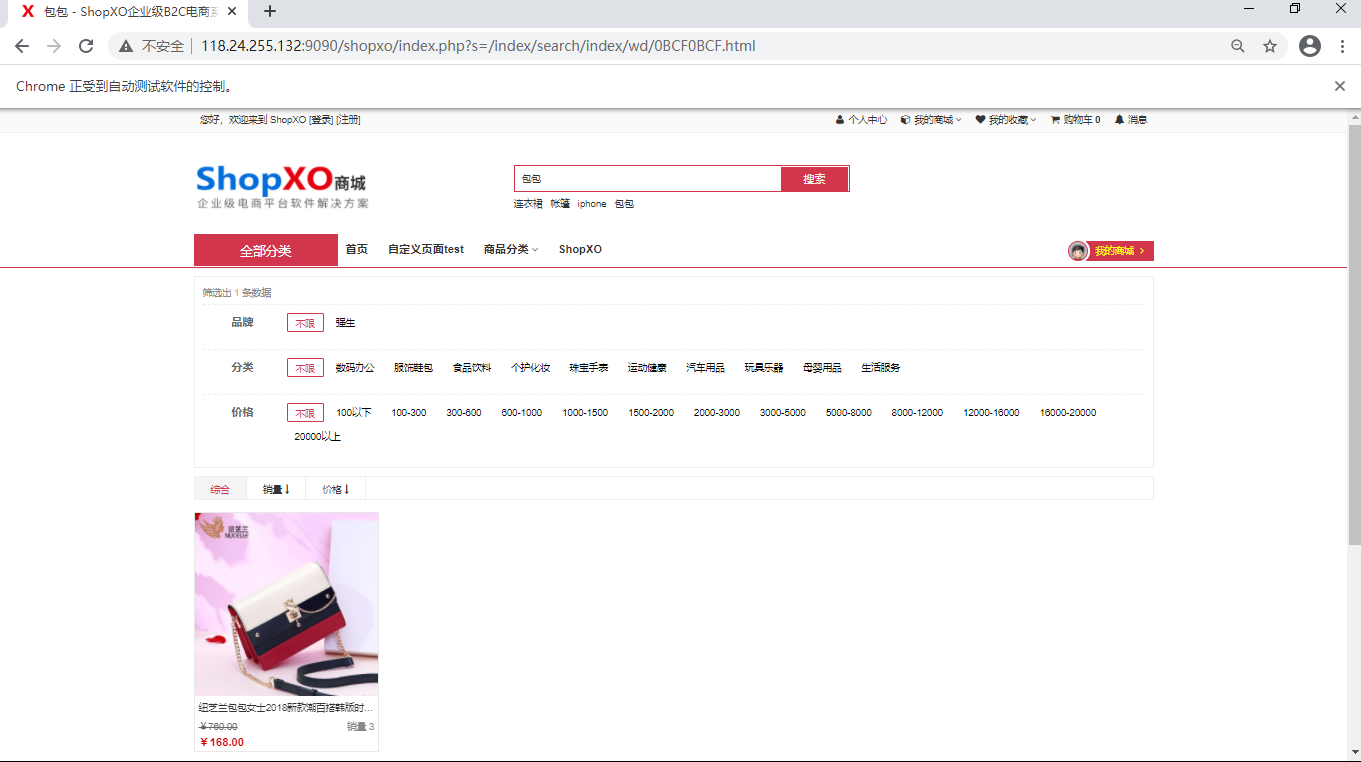
5、断言
就如上边,找出了包包之后,这里又引申出一个问题,怎样判断测试用例的结果,即判断这个结果是否存在,自动化中用断言实现这样的过程
两种方式,第一种通过文本值断言,第二种通过元素是否存在断言
5.1、通过文本值断言
先把正确的结果查找元素(有id值就用id值,没有id值就用xpath)
这里搜索出来的场景是一个包包,查找元素的时候注意找的是这个商品名字,不要找成商品图片啥的
断言即判断搜索出来的结果是否等于正确的商品名即可
# xpath:/html/body/div[4]/div/ul/li/div/a/p
res = driver.find_element_by_xpath('/html/body/div[4]/div/ul/li/div/a/p')
assert res.text == '纽芝兰包包女士2018新款潮百搭韩版时尚单肩斜挎包少女小挎包链条'
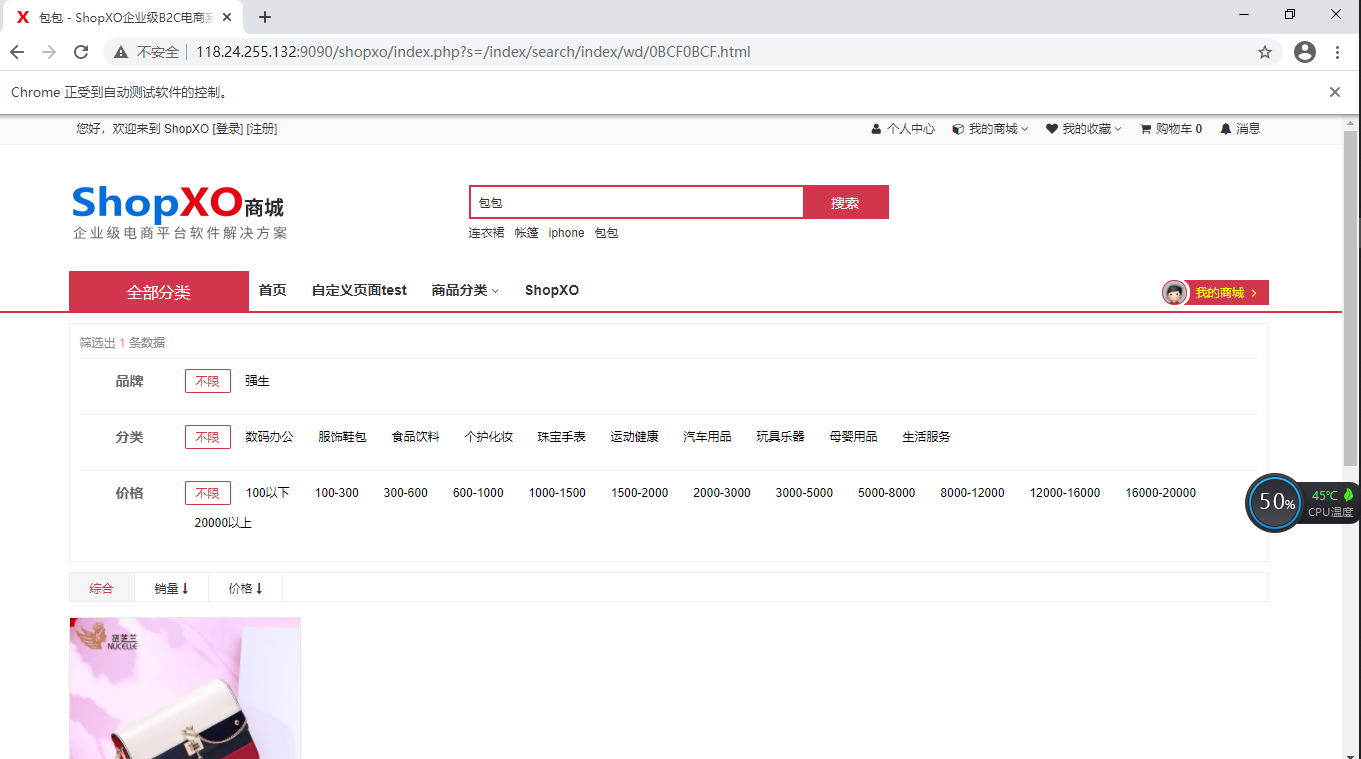
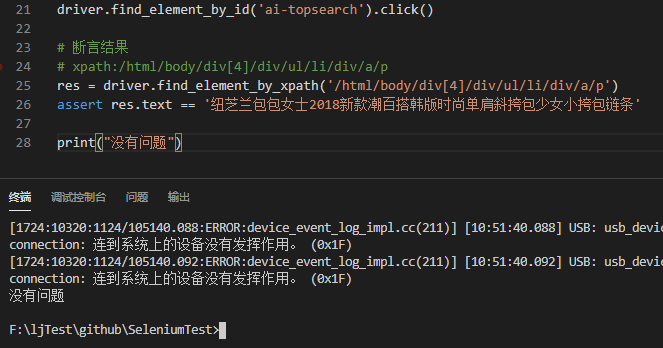
由此可见,页面正常打开
如果有多个商品,即是个列表的话,那就找多次,在断言里边加and即可
5.2、通过元素是否存在断言
断言判断的第二种方式:判断元素是否存在即可(可以判断多个元素)
这会用到一个方法:driver.find_elements_by_id/xpath(八大定位方式均可)(注意这里是elements了)
这个方法的返回值是列表格式,有多少个元素就返回多少个:[元素1,元素2....]
e = driver.find_elements_by_id('search-input')
print(e)

如果使用这种方法,直接用len()方法就可以断言判断
e = driver.find_elements_by_id('search-input')
# print(e)
assert len(e) != 0
如果没有元素,那就返回空列表

6、复习
用jmeter跑,模拟网站变卡
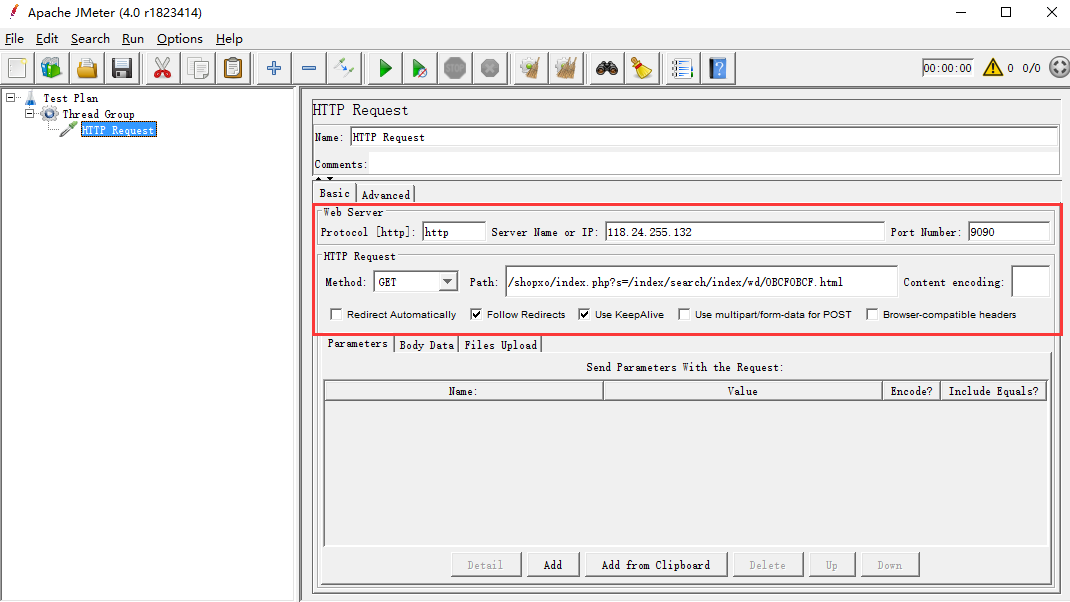
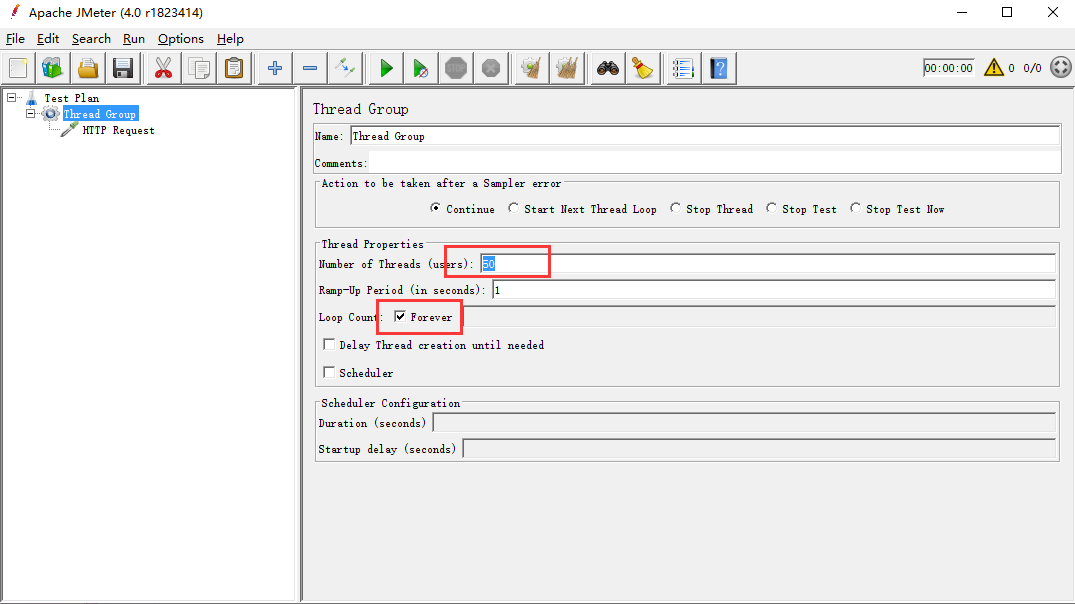

线程数设置为50之后,此时网站开始明显卡顿
7、设置等待
以网站的登录为例:
打开登录页面之后,Ctrl+Shif+C开始定位元素
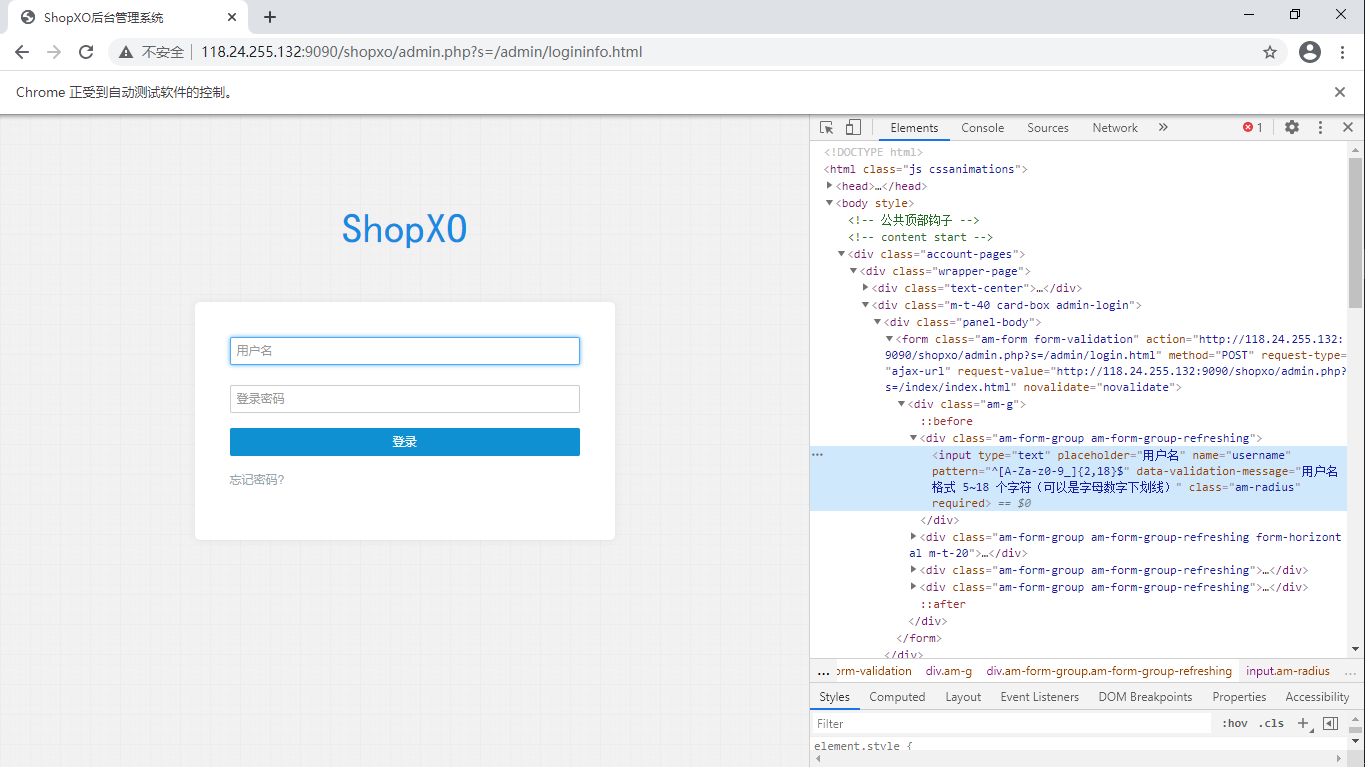
怎样断言登录成功:定位首页这个元素
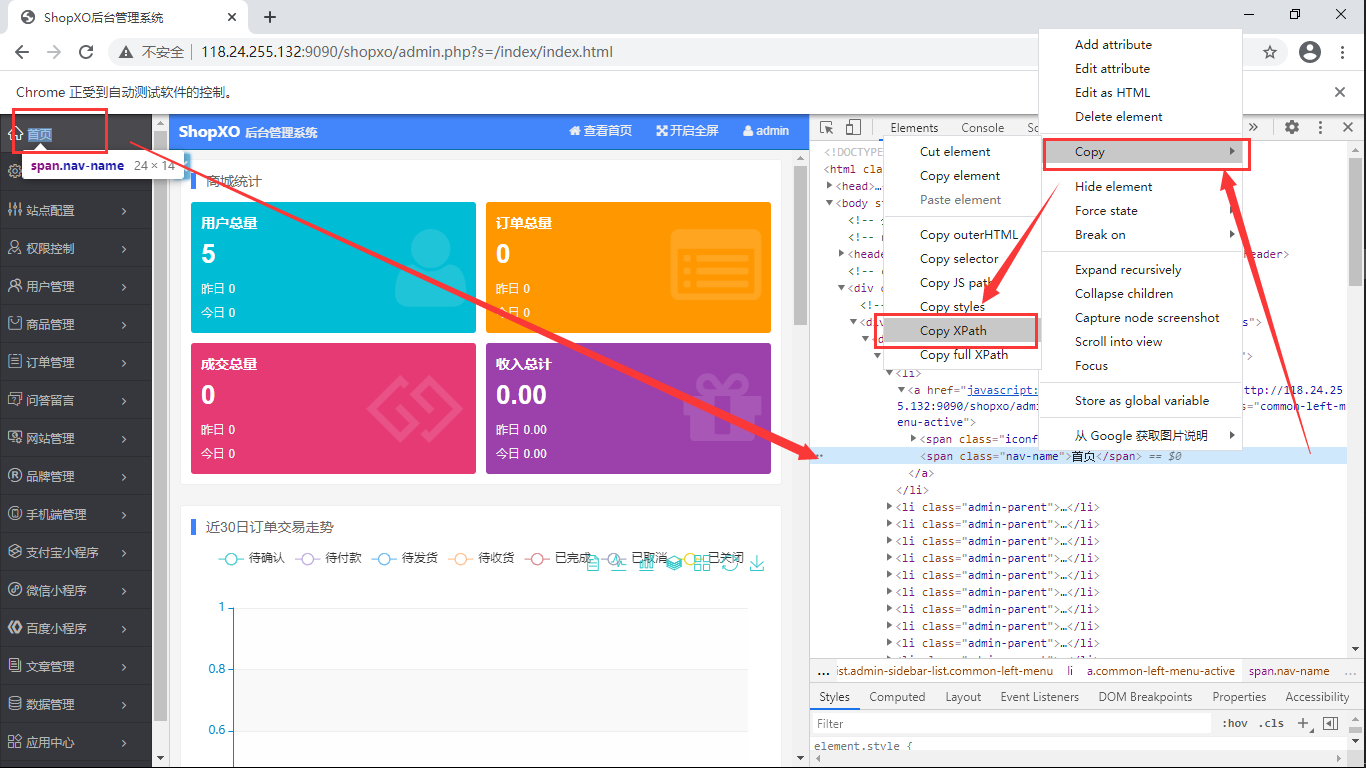
from selenium import webdriver
#1、打开浏览器:实例化浏览器句柄(把柄)
driver = webdriver.Chrome(executable_path="chromedriver.exe")
#浏览器全屏显示
driver.maximize_window()
#2、访问网站:用把柄去访问网站,get类型接口
driver.get("http://118.24.255.132:9090/shopxo/admin.php")
#3、模拟测试用例的执行过程
driver.find_element_by_name('username').send_keys('admin')
driver.find_element_by_name('login_pwd').send_keys('shopxo')
driver.find_element_by_xpath('/html/body/div[1]/div/div[2]/div/form/div/div[3]/button').click()
res = driver.find_element_by_xpath('//*[@id="admin-offcanvas"]/div/ul/li[1]/a/span[2]')
assert res.text == '首页'
右上角点击运行之后发现报错了
明明运行的时候网页都是正常的,但是在终端发现报错,报错的原因显示如下:
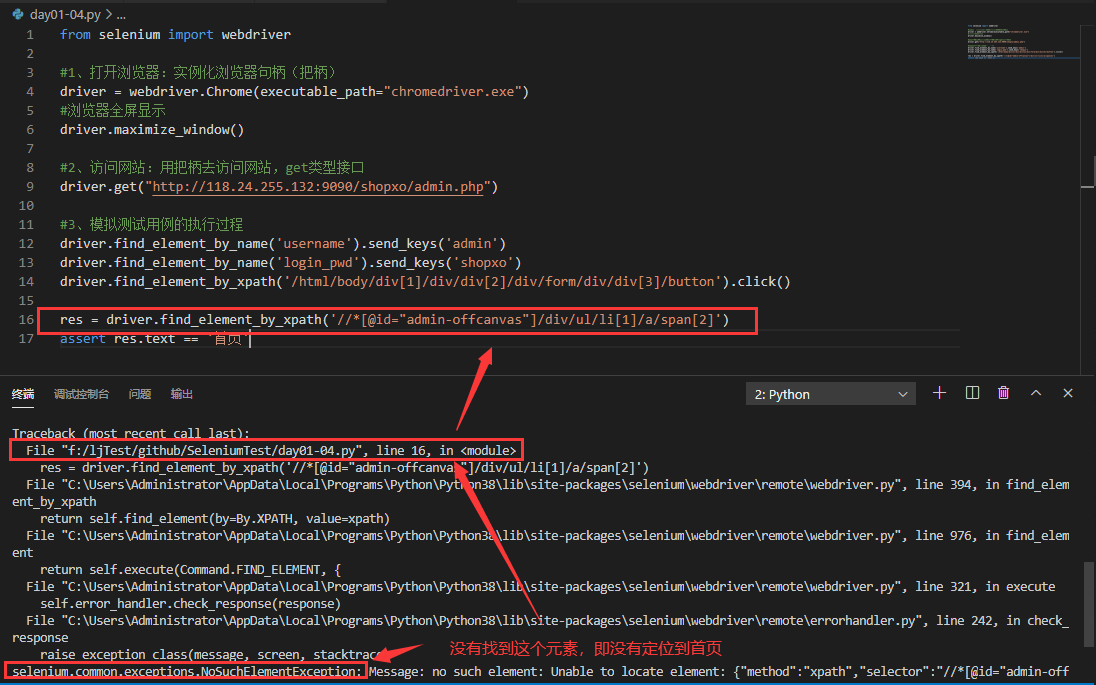
原因就是,因为网站在登录的时候本身服务器也不好,网速也不行,在登录的时候存在着装券和停留的时刻,但是代码在运行的时候是不会停留的,代码上一句没有报错就紧接着会执行下一句代码,代码运行是非常快的,它不会顾及网页是什么情况。
所以代码在找 “首页” 这个元素的时候,很可能网页还正在登录页面没有进去首页,这就出现了时间差(代码执行得过快,网页很慢)
这就涉及到一个等待的问题,一般而言,有网页跳转和元素动态加载的时候需要等待
处理方式主要有三种
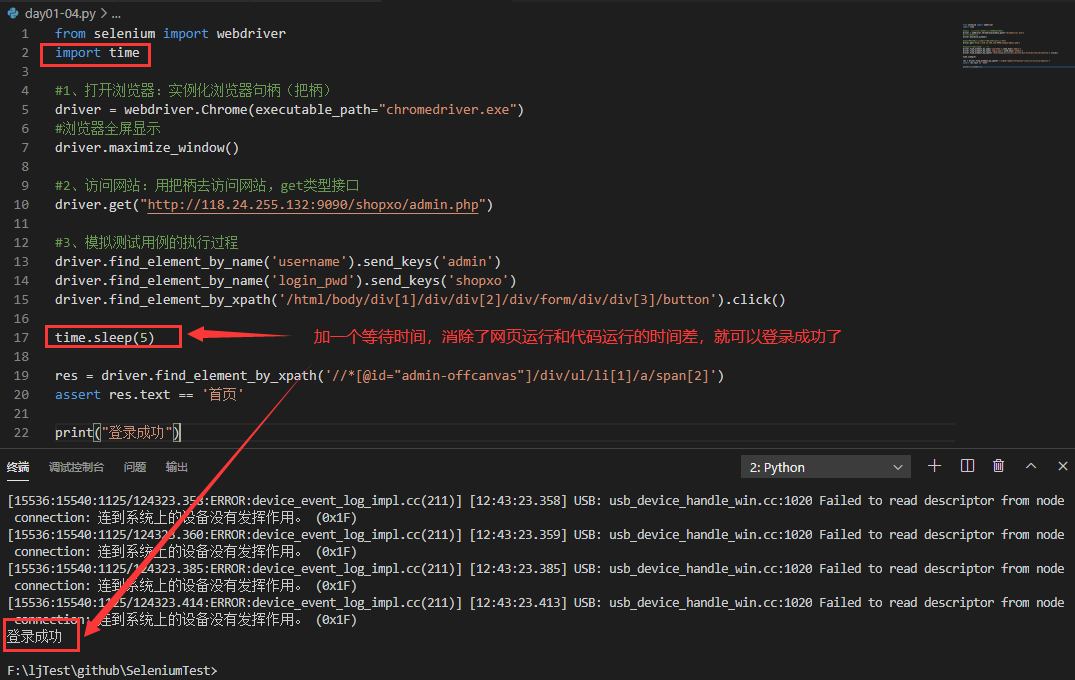
7.1、固定(静态)等待:time.sleep(),使用时需要先导入,是python自带的包:import time
方法括号中间给一个int或者float类型的数
python自带的库(包):https://www.runoob.com/python3/python3-stdlib.html
7.2、隐式等待:会智能判断网页是否加载完成:driver.implicitly_wait()
括号中间也是int或者float类型的数字
比如:driver.implicitly_wait(5),在前三秒的时候网页加载好了,那剩下的2秒就不会再继续等待了,但是若超过5秒还没好,那也管不了了
7.3、显式等待:这个是在做自动化的时候最经常用到的

Seleniumweb自动化测试01的更多相关文章
- Python接口自动化测试01
1)环境准备: 接口测试的方式有很多,比如可以用工具(jmeter,postman)之类,也可以自己写代码进行接口测试,工具的使用相对来说都比较简单,重点是要搞清楚项目接口的协议是什么,然后有针对性的 ...
- 2020软件测试自学全套教程-基于python自动化软件测试-2020新版软件测试中级程序员学习路线
不知不觉间,在软件测试行业野蛮的折腾了七年之久.七年之痒也即将过去,但我还是热爱着软件测试这一份工作,一路坚持,走到现在.经历过各种难题,有过迷茫,有过焦虑失眠.也踩过无数的坑,深知行业的不易.自从9 ...
- Java自动化测试框架-01 - TestNG之入门篇 - 大佬的鸡肋,菜鸟的盛宴(详细教程)
TestNG是什么? TestNG按照官方的定义: TestNG是一个测试框架,其灵感来自JUnit和NUnit,但引入了一些新的功能,使其功能更强大,使用更方便. TestNG是一个开源自动化测试框 ...
- Pytest自动化测试-简易入门教程(01)
我们今天主讲的内容,就是测试框架Pytest,讲到这个测试框架对于没有做过Web自动化的伙伴来说,会觉得这个东西是陌生的,那么到底什么是框架呢?什么又是自动化呢?自动化为什么又要用框架呢? 难道我学自 ...
- Android-Junit-Report测试报告生成——Android自动化测试学习历程
视频地址: http://www.chuanke.com/v1983382-135467-384869.html 这个内容其实已经在用了,我在上一篇文章robotium—只有apk文件的测试中已经讲过 ...
- [小北De编程手记] : Lesson 01 - Selenium For C# 之 环境搭建
在我看来一个自动化测试平台的构建,是一种很好的了解开发语言,单元测试框架,自动化测试驱动,设计模式等等等的途径.因此,在下选择了自动化测试的这个话题来和大家分享一下本人关于软件开发和自动化测试的认识. ...
- QTP之delphi试用感想一(自动化测试)
这两天一直在琢磨自动化测试,自动化测试,其实与单元测试有一些相同之处,单元测试的目的也是可以一次写,多次运行,对于测试驱动及后期维护真是有非常多的好处,用自动化测试工具也是如何,主要目的是为了回归测试 ...
- 基于Selenium2与Python自动化测试环境搭建
简介: selenium 是一个web的自动化测试工具,不少学习功能自动化的同学开始首选selenium ,相因为它相比QTP有诸多有点: * 免费,也不用再为破解QTP而大伤脑筋 * 小巧,对于 ...
- [小北De编程手记] Lesson 01 - AutoFramework构建 之 从一个简单的Demo聊起
写在最前面 这个系列的主旨是要跟大家分享一下关于自动化测试框架的构建的一些心得.这几年,做了一些自动化测试框架以及团队的构建的工作.过程中遇到了很多这样的同学,他们在学习了某一门语言和一些自动化测试的 ...
- SoapUI实践:自动化测试、压力测试、持续集成
因为项目的原因,前段时间研究并使用了 SoapUI 测试工具进行自测开发的 api.下面将研究的成果展示给大家,希望对需要的人有所帮助. SoapUI 是什么? SoapUI 是一个开源测试工具,通过 ...
随机推荐
- 带你了解S12直播中的“黑科技”
摘要:让精彩更流畅.让较量更清晰.让参与更沉浸.让体验更有趣,幕后的舞台,从来都是技术的战场,S12背后的名场面同样场场高能. 本文分享自华为云社区<用硬核方式打开S12名场面>,作者:华 ...
- Java外包程序员的技术出路
学习的两个目的: 应付面试 应付工作(解决问题) 首先要明白学习的目的,不同阶段,不同技术的学习目的是不一样的. 有些技术,仅仅是应用级别的,有些技术是原理级别的(主要还是应试).所以不同技术.不同时 ...
- re、base64的结合使用爬取豆瓣top250
一.缘由 对于豆瓣的这个网站,记得使用了不少于三种的爬取和解析方式来进行的.今天的这种解析方式是我使用起来较为顺手,后来就更喜欢使用xpath解析,但是这两种也需要掌握. 二.代码展示 '''爬取豆瓣 ...
- 《MySQL必知必会》之快速入门游标和触发器
第二十四章 使用游标 本章将介绍什么是游标以及如何使用游标 游标 之前的select语句检索出来的数据,没有办法得到第一行或者下一行 有时,需要在检索出来的行中前进或后退一行或多行.这就是使用游标的原 ...
- Flaks框架(g对象,session,数据库连接池,信号,flask-script,SQLAlchemy(ORM))
目录 一:g对象 简介 1.g对象和session的区别 2.g对象实战代码 二:flask-session(借助于第三方插件连接redis保存session ) 1.方式一: 2.方式二(flask ...
- CBV如何添加装饰器?
目录 一:CBV如何添加装饰器 1.CBV中django不建议直接给类的方法加装饰器 2.CBC添加装饰器的三种方法 3.CBV添加装饰器实战 一:CBV如何添加装饰器 1.CBV中django不建议 ...
- SQL审核平台Yearning
1.关于Yearming Yearming是一个Sql审核平台,底层使用Go语言,安装和部署方式也很便捷 项目地址 https://guide.yearning.io/install.html git ...
- Mac系统下word论文参考文献更新域
写论文的时候可能会遇到后续要增加文献的情况 在参考文献增加后会发现文章中的交叉引用的序号并没有更新 下面分享两种情况的处理方法 一.更新全部域 首先确认自己的打印️项是选中的 2. 打开word偏好 ...
- PPT排版技巧
- jmeter 之修改报告取样间隔时间以及APDEX 区间设置
1.取样间隔时间设置 在jmeter 生成的报告中取样间隔默认设置的是1分钟,而非1秒,故样本间的间隔为1分钟,如下图所示: 取样间隔时间可通过修改bin/user.properties配置文件实现自 ...