boxcox1p归一化+pipeline+StackingCVRegressor
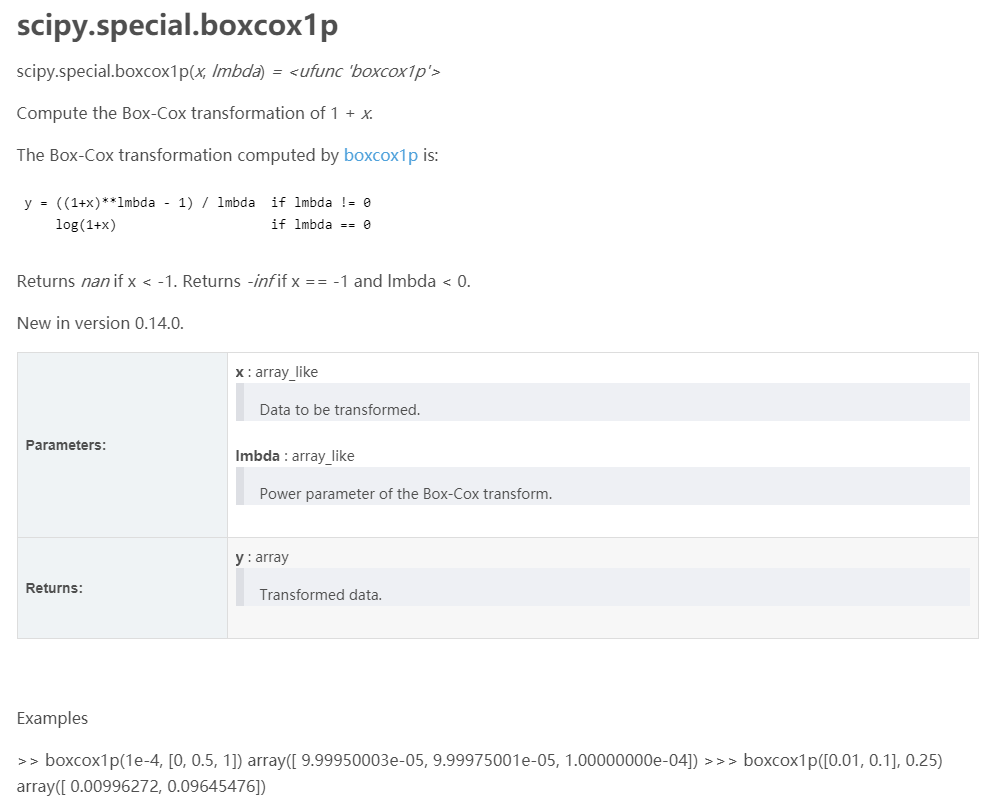
找到最好的那个参数lmbda。


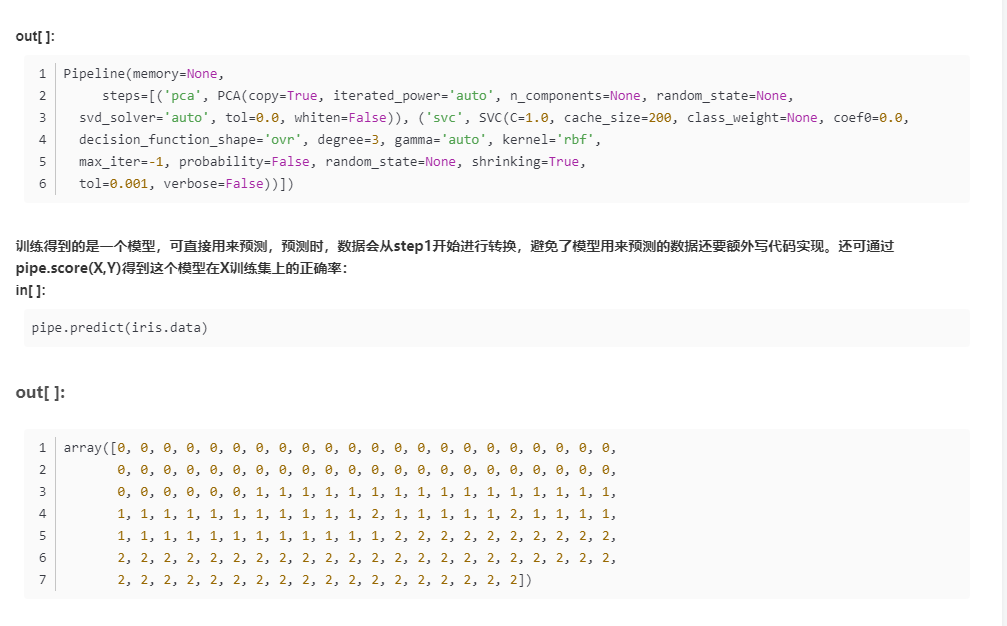





- from mlxtend.regressor import StackingCVRegressor
- from sklearn.datasets import load_boston
- from sklearn.svm import SVR
- from sklearn.linear_model import Lasso
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.model_selection import cross_val_score
- import numpy as np
- RANDOM_SEED = 42
- X, y = load_boston(return_X_y=True)
- svr = SVR(kernel='linear')
- lasso = Lasso()
- rf = RandomForestRegressor(n_estimators=5,
- random_state=RANDOM_SEED)
- # The StackingCVRegressor uses scikit-learn's check_cv
- # internally, which doesn't support a random seed. Thus
- # NumPy's random seed need to be specified explicitely for
- # deterministic behavior
- np.random.seed(RANDOM_SEED)
- stack = StackingCVRegressor(regressors=(svr, lasso, rf),
- meta_regressor=lasso)
- print('5-fold cross validation scores:\n')
- for clf, label in zip([svr, lasso, rf, stack], ['SVM', 'Lasso','Random Forest','StackingClassifier']):
- scores = cross_val_score(clf, X, y, cv=5)
- print("R^2 Score: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))
- 5-fold cross validation scores:
- R^2 Score: 0.45 (+/- 0.29) [SVM]
- R^2 Score: 0.43 (+/- 0.14) [Lasso]
- R^2 Score: 0.52 (+/- 0.28) [Random Forest]
- R^2 Score: 0.58 (+/- 0.24) [StackingClassifier]
- # The StackingCVRegressor uses scikit-learn's check_cv
- # internally, which doesn't support a random seed. Thus
- # NumPy's random seed need to be specified explicitely for
- # deterministic behavior
- np.random.seed(RANDOM_SEED)
- stack = StackingCVRegressor(regressors=(svr, lasso, rf),
- meta_regressor=lasso)
- print('5-fold cross validation scores:\n')
- for clf, label in zip([svr, lasso, rf, stack], ['SVM', 'Lasso','Random Forest','StackingClassifier']):
- scores = cross_val_score(clf, X, y, cv=5, scoring='neg_mean_squared_error')
- print("Neg. MSE Score: %0.2f (+/- %0.2f) [%s]"

- from mlxtend.regressor import StackingCVRegressor
- from sklearn.datasets import load_boston
- from sklearn.linear_model import Lasso
- from sklearn.linear_model import Ridge
- from sklearn.ensemble import RandomForestRegressor
- from sklearn.model_selection import GridSearchCV
- X, y = load_boston(return_X_y=True)
- ridge = Ridge()
- lasso = Lasso()
- rf = RandomForestRegressor(random_state=RANDOM_SEED)
- # The StackingCVRegressor uses scikit-learn's check_cv
- # internally, which doesn't support a random seed. Thus
- # NumPy's random seed need to be specified explicitely for
- # deterministic behavior
- np.random.seed(RANDOM_SEED)
- stack = StackingCVRegressor(regressors=(lasso, ridge),
- meta_regressor=rf,
- use_features_in_secondary=True)
- params = {'lasso__alpha': [0.1, 1.0, 10.0],
- 'ridge__alpha': [0.1, 1.0, 10.0]}
- grid = GridSearchCV(
- estimator=stack,param_grid={'lasso__alpha': [x/5.0 for x in range(1, 10)],
- 'ridge__alpha': [x/20.0 for x in range(1, 10)],
- 'meta-randomforestregressor__n_estimators': [10,100]},
- cv=5,
- refit=True
- )
- grid.fit(X, y)
- print("Best: %f using %s" % (grid.best_score_, grid.best_params_))
- #Best: 0.673590 using {'lasso__alpha': 0.4, 'meta-randomforestregressor__n_estimators': 10, 'ridge__alpha
- cv_keys = ('mean_test_score', 'std_test_score', 'params')
- for r, _ in enumerate(grid.cv_results_['mean_test_score']):
- print("%0.3f +/- %0.2f %r"
- % (grid.cv_results_[cv_keys[0]][r],
- grid.cv_results_[cv_keys[1]][r] / 2.0,
- grid.cv_results_[cv_keys[2]][r]))
- if r > 10:
- break
- print('...')
- print('Best parameters: %s' % grid.best_params_)
- print('Accuracy: %.2f' % grid.best_score_)
boxcox1p归一化+pipeline+StackingCVRegressor的更多相关文章
- 1.3:Render Pipeline and GPU Pipeline
文章著作权归作者所有.转载请联系作者,并在文中注明出处,给出原文链接. 本系列原更新于作者的github博客,这里给出链接. 在学习SubShader之前,我们有必要对 Render Pipeline ...
- sklearn pipeline
sklearn.pipeline pipeline的目的将许多算法模型串联起来,比如将特征提取.归一化.分类组织在一起形成一个典型的机器学习问题工作流. 优点: 1.直接调用fit和predict方法 ...
- 机器学习:多项式回归(scikit-learn中的多项式回归和 Pipeline)
一.scikit-learn 中的多项式回归 1)实例过程 模拟数据 import numpy as np import matplotlib.pyplot as plt x = np.random. ...
- GPU上创建目标检测Pipeline管道
GPU上创建目标检测Pipeline管道 Creating an Object Detection Pipeline for GPUs 今年3月早些时候,展示了retinanet示例,这是一个开源示例 ...
- 【笔记】多项式回归的思想以及在sklearn中使用多项式回归和pipeline
多项式回归以及在sklearn中使用多项式回归和pipeline 多项式回归 线性回归法有一个很大的局限性,就是假设数据背后是存在线性关系的,但是实际上,具有线性关系的数据集是相对来说比较少的,更多时 ...
- 多项式回归 & pipeline & 学习曲线 & 交叉验证
多项式回归就是数据的分布不满足线性关系,而是二次曲线或者更高维度的曲线.此时只能使用多项式回归来拟合曲线.比如如下数据,使用线性函数来拟合就明显不合适了. 接下来要做的就是升维,上面的真实函数是:$ ...
- redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value 就是具体的customerid集合, ...
- Building the Testing Pipeline
This essay is a part of my knowledge sharing session slides which are shared for development and qua ...
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
随机推荐
- Info.plist常见的设置
建立一个工程后,会在Supporting files文件夹下看到一个"工程名-Info.plist"的文件,该文件对工程做一些运行期的配置,非常重要,不能删除 在旧版本Xcode创 ...
- Scala函数高级篇
一.匿名函数 没有名字的函数就是匿名函数,格式:(x:Int)=>{函数体} x:表示输入参数类型:Int:表示输入参数类型:函数体:表示具体代码逻辑 传递匿名函数至简原则: 参数的类型可以省略 ...
- Feign 动态URL 解决记录
Feign中使用动态URL请求 (应当是spring-cloud-starter-openfeign,不知道和一般的feign有何差别) 在spring项目下,假设有这样个Feign的消费接口,原来写 ...
- Linux vi 命令 – 文本编辑器
vi命令是linux系统字符界面下的最常用的文本编辑器. vi编辑器是所有linux的标准编辑器,用于编辑任何ASCⅡ文本,对于编辑源程序尤其有用.iv编辑器功能非常强大,可以对文本进行创建,查找,替 ...
- Solution -「HDU 5498」Tree
\(\mathcal{Description}\) link. 给定一个 \(n\) 个结点 \(m\) 条边的无向图,\(q\) 次操作每次随机选出一条边.问 \(q\) 条边去重后构成生成 ...
- ajax的发展
ajax(Asynchronous Javascript and XML)异步javascrip和XMl. ajax只是一种web交互方法.在客户端(浏览器)和服务区段之间传输少量的信息.从而为用户提 ...
- Vue2.0源码学习(3) - 组件的创建和patch过程
组件化 组件化是vue的另一个核心思想,所谓的组件化就,就是说把页面拆分成多个组件(component),每个组件依赖的css.js.图片等资源放在一起开发和维护.组件是资源独立的,在内部系统中是可以 ...
- Spring Data JPA应用 之查询分析
在Spring Data JPA应用之常规CRUD操作初体验 - 池塘里洗澡的鸭子 - 博客园 (cnblogs.com)尾附上了JpaRepository接口继承关系及方法,可以知道JpaRepos ...
- HTML5/CSS3/JS笔记
HTML笔记: 前言: HTML无非就是围绕标签.属性.属性值这三个词展开的. (标签也可以叫做元素, 元素的内容是开始标签与结束标签之间的内容) *常规标签 <标签 属性1="属性值 ...
- Java高性能本地缓存框架Caffeine
一.序言 Caffeine是一个进程内部缓存框架,使用了Java 8最新的[StampedLock]乐观锁技术,极大提高缓存并发吞吐量,一个高性能的 Java 缓存库,被称为最快缓存. 二.缓存简介 ...