MySQL数据库:7、SQL常用查询语句
Python基础之MySQL数据库
一、SQL语句常用查询方法
前期数据准备
为了更加直观的展示、演示SQL语句查询关键字,需导入下列表格与记录(数据)
模拟公司,导入创建公司员工表,表内包含:ID、姓名、年龄、工作时间、岗位
创建人员表格:
create table emp(
id int primary key auto_increment,
name varchar(20) not null,
gender enum('male','female') not null default 'male', #大部分是男的
age int(3) unsigned not null default 28,
hire_date date not null,
post varchar(50),
post_comment varchar(100),
salary double(15,2),
office int, #一个部门一个屋子
depart_id int
);
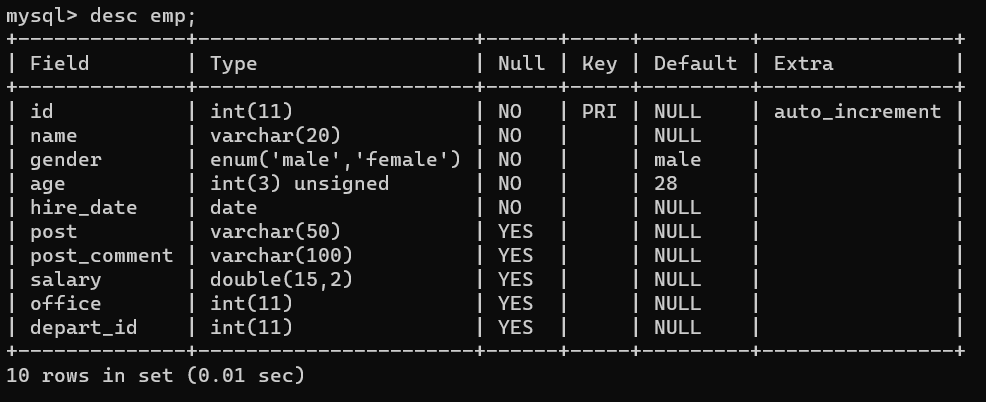
生成人员信息:
#插入记录
#三个部门:教学,销售,运营
insert into emp(name,gender,age,hire_date,post,salary,office,depart_id) values
('jason','male',18,'20170301','浦东第一帅形象代言',7300.33,401,1), #以下是教学部
('tom','male',78,'20150302','teacher',1000000.31,401,1),
('kevin','male',81,'20130305','teacher',8300,401,1),
('tony','male',73,'20140701','teacher',3500,401,1),
('owen','male',28,'20121101','teacher',2100,401,1),
('jack','female',18,'20110211','teacher',9000,401,1),
('jenny','male',18,'19000301','teacher',30000,401,1),
('sank','male',48,'20101111','teacher',10000,401,1),
('哈哈','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门
('呵呵','female',38,'20101101','sale',2000.35,402,2),
('西西','female',18,'20110312','sale',1000.37,402,2),
('乐乐','female',18,'20160513','sale',3000.29,402,2),
('拉拉','female',28,'20170127','sale',4000.33,402,2),
('僧龙','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门
('程咬金','male',18,'19970312','operation',20000,403,3),
('程咬银','female',18,'20130311','operation',19000,403,3),
('程咬铜','male',18,'20150411','operation',18000,403,3),
('程咬铁','female',18,'20140512','operation',17000,403,3);:``
1、基本查询
关键字:select
功能:基本、最常用的查询方法,可以通过关键字查询表内所有或指定的数据
select : 指定需要查询的字段信息
select * 查询所有字段
select 字段名 查询指定字段记录
select 方法(指定的字段) 查询处理后的字段记录
from
指定需要查询的表信息
from 库名.表名
from 表名
'''
注意事项:
1、SQL语句中关键字的执行顺序和编写顺序并不是一致的
eg:
select * from t1;
我们先写的是select,执行的顺序却是from t1 ——> select *
2、对于执行的顺序我们不用过多在意,只需要注意功能,熟练之后会编写的很自然
'''
2、编写SQL语句的小技巧
对于查询用法,针对‘select’后面的字段我们可以先使用‘*’占位,然后往后面写,写到需要查询的字段时回来补全
在实际应用中‘select’后面很少直接写‘*’ , 因为星号表示所有,在当前表中数据量非常庞大时会非常浪费数据库资源
SQL语句的编写类似于代码的编写,不是一蹴而就的,也需要缝缝补补
在查询的字段后使用‘as’的方式可以用来修改展示的字段名,不会影响表的结构,只用来当前打印下的展示
3、查询之where筛选
3、1.功能介绍
- 关键字:where
- 功能:SQL语句中最常用的关键字,用于筛选数据,支持成员运算符,逻辑运算符号、身份运算符、模糊查询
- 模糊查询:
- 功能:当条件不足时可使用模糊查询,特征搭配模糊查询字符
- 关键词:like
| 字符 | 方法 | 功能 |
|---|---|---|
| % | 模糊查询 | 搭配字符前后,匹配任意字符 |
| _ | 模糊查询 | 搭配字符前后,匹配单个字符 |
3、2.实际应用
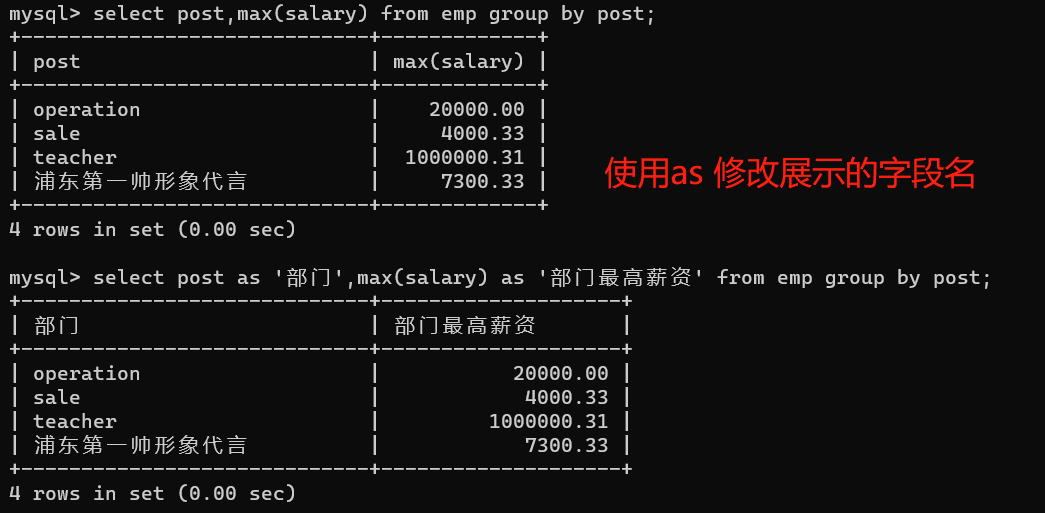
- 1.查询id大于等于3,小于等于6的数据
1、方式一:
select * from emp where id>3 and id<=6;
2、方式二: 搭配关键词:between
select * from emp where id between 3 and 6;

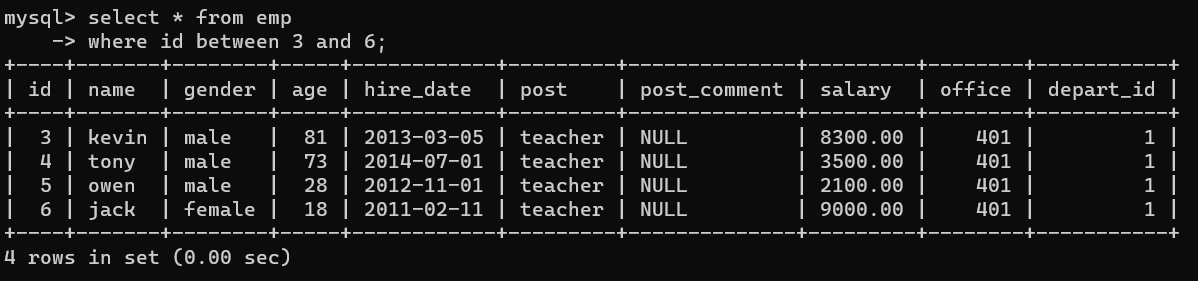
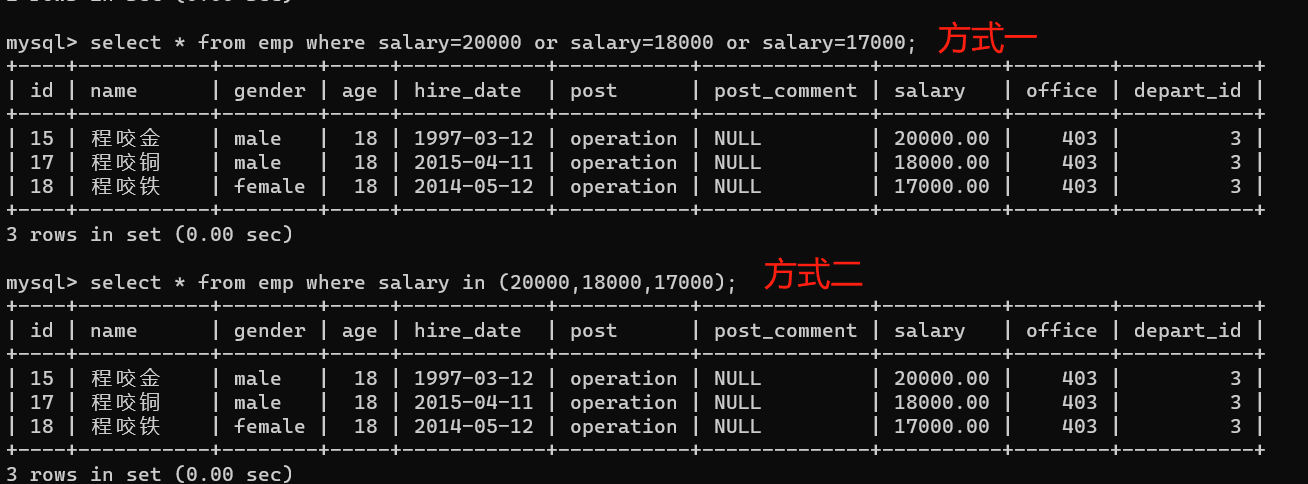
- 2.查询薪资是20000或者18000或者是17000的数据
1、方式一:
select * from emp where salary=20000 or salary=18000 or salary=17000;
2、方式二:
select * from emp where salary in (20000,18000,17000);
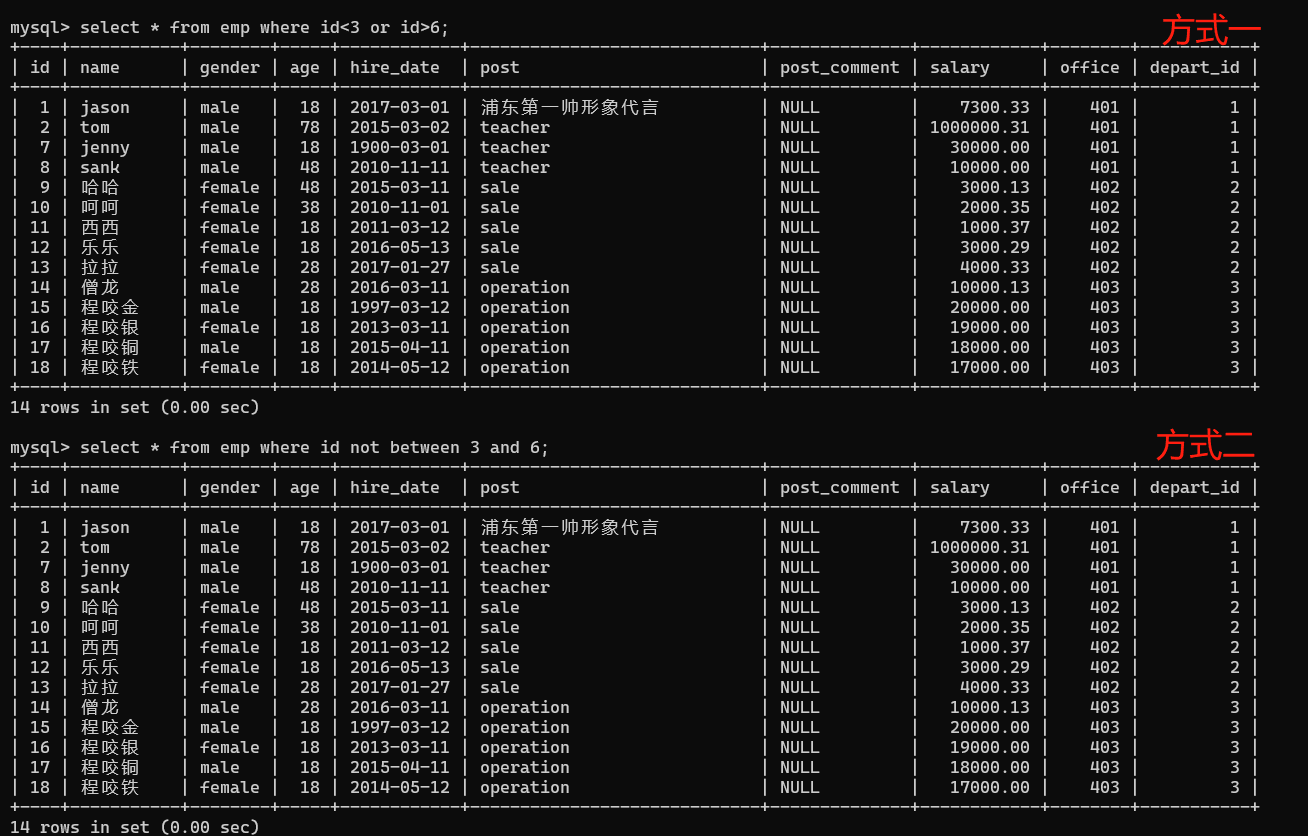
- 3.查询id小于三和大于6的数据
1、方式一:
select * from emp where id<3 or id>6;
2、方式二:
select * from emp where id not between 3 and 6;
- 4.查询姓名中包含o的员工姓名和薪资
条件不够时通常使用模糊查询,搭配查询字符
select * from emp where name like %o%;

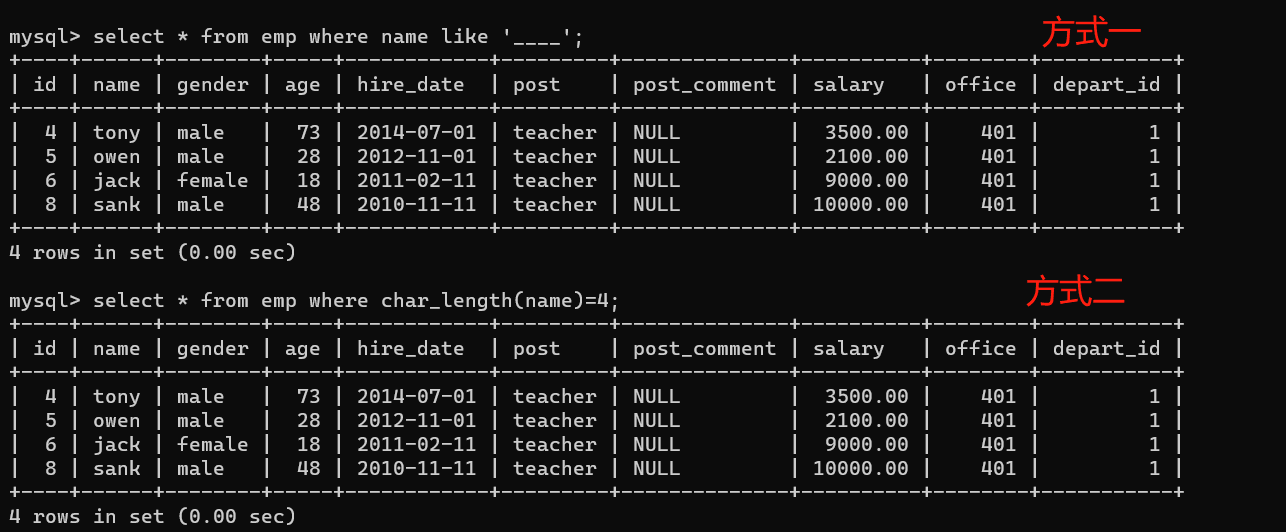
- 5.查询员工姓名是由四个字符组成的员工姓名与其薪资
1、方式一:
selsect * from emp where name like '____';
2、方式二:
select * from emp where char_length(name)=4;
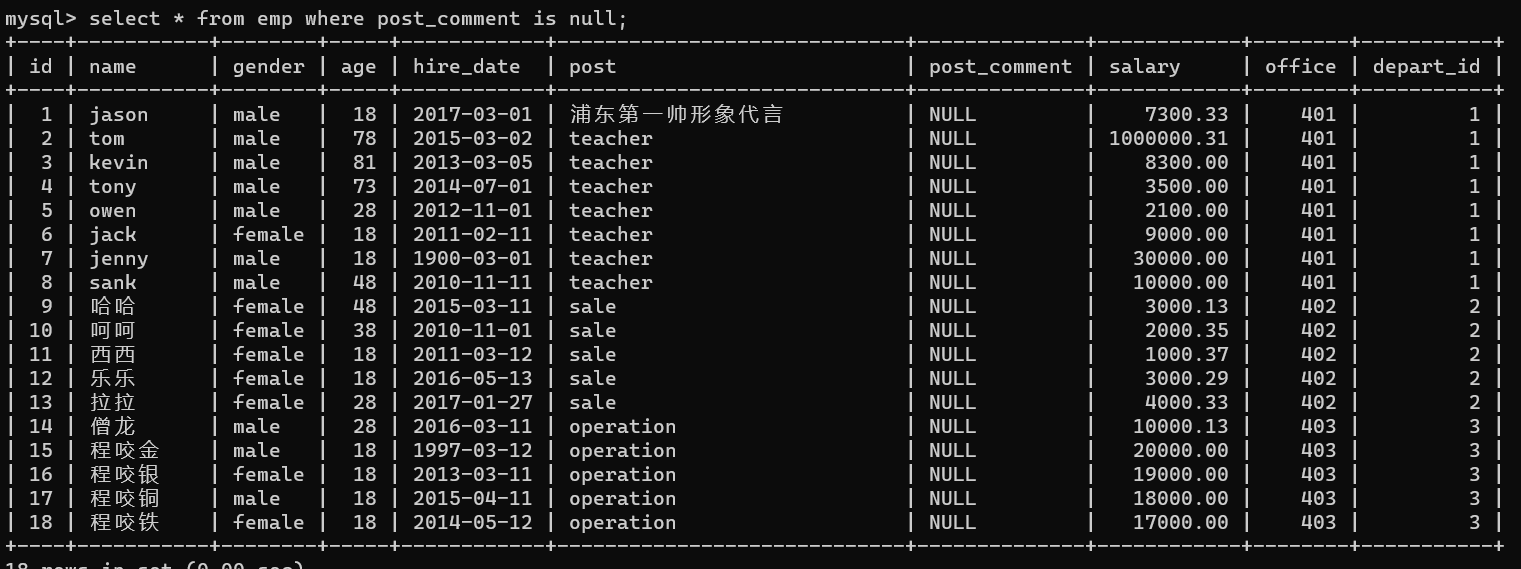
- 6.查询岗位描述为空的员工名与岗位名---针对null不能用等号,只能用is
select * from emp where post_comment is null;
4、查询之group by分组
4、1.功能介绍
- 关键词:group by
- 功能:可以将指定的条件进行分组,例如将多个相同部门的员工按部门分组
- 可搭配聚合函数:
- max():取最大值
- min():取最小值
- sum():求和
- avg():平均值
- count():计数
4、2.实际应用
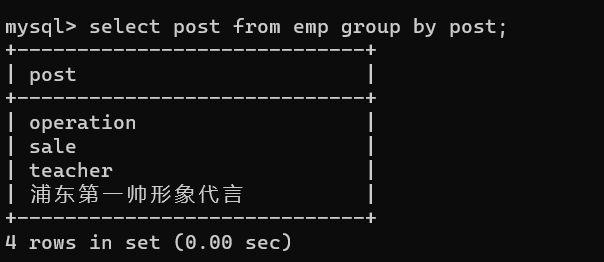
- 1.统计表内公司的总类
在使用,group by 的时候,可能会出现以下这种用法

这种方法在MySQL5.5之前,并不会报错,但是打印的数据并不利于观看,因为它直接将部门的某一行打印出来,我们应该将需要打印的字符名放在selsct后:
select post from group by post;
在MySQL5.5之后,使用这种方法将会报错,可以通过在配置内添加严格模式来改正这种方法
# 将下列代码拷贝至my.ini文件的MySQLd下,重启系统环境中的MySQL服务端
sql_mode='strict_trans_tables,only_full_group_by'
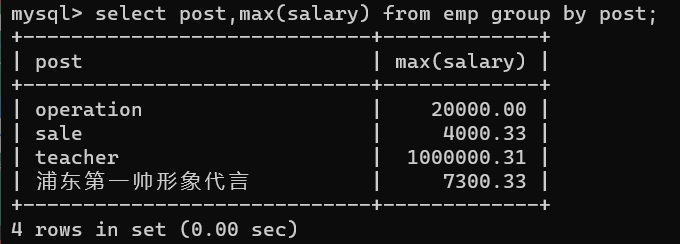
- 2.获取每个部门的最高工资
推导流程:
# 1、先获取部门信息
select post from emp group by post;
# 2、获取部门下人员工资
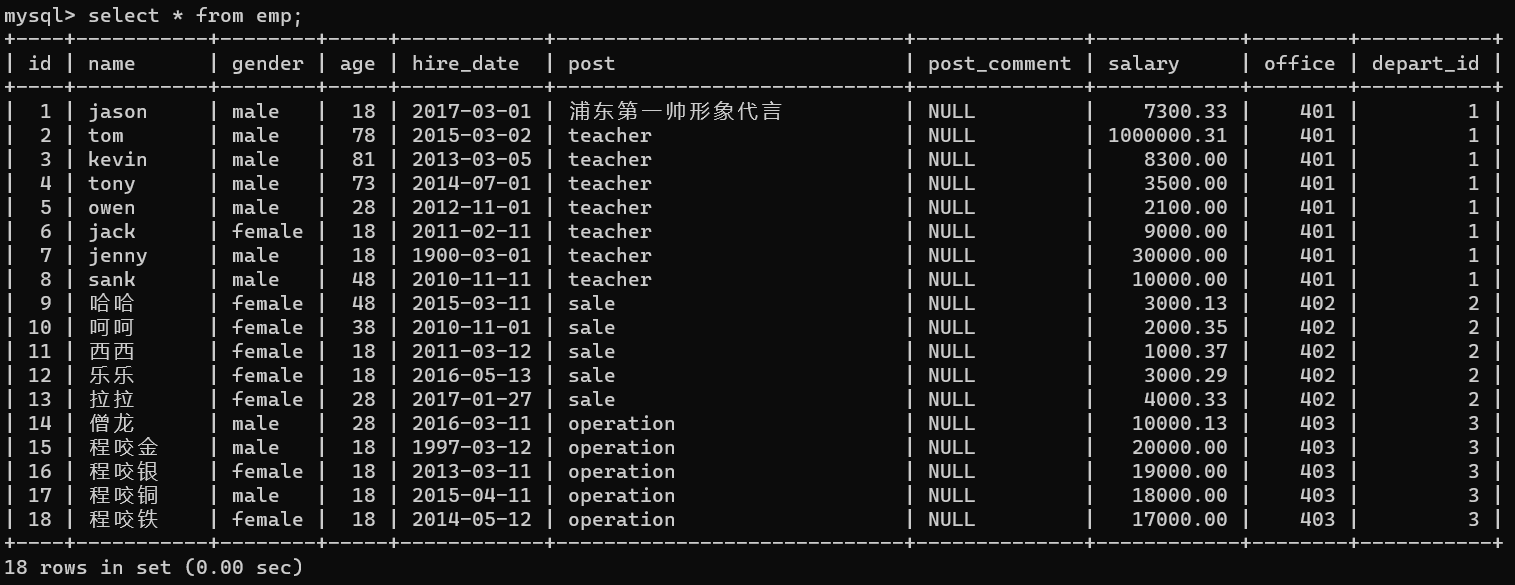
select post,max(salary) from emp group by post;
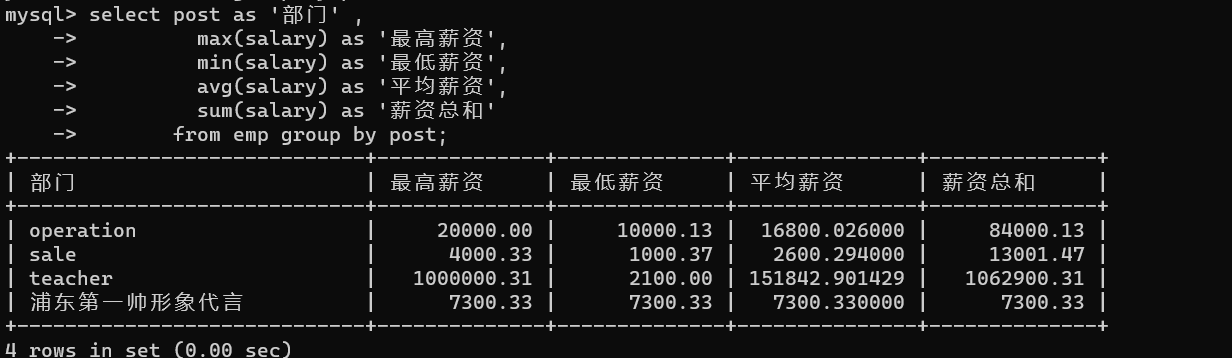
- 3.一次性获取部门薪资的所有数据,最高、最低、平均、薪资总和
推导流程:
# 1、先获取部门信息
select post from emp group by post;
# 2、获取部门下人员工资的综合信息
select post as '部门' ,
max(salary) as '最高薪资',
min(salary) as '最低薪资',
avg(salary) as '平均薪资',
sum(salary) as '薪资总和'
from emp group by post;
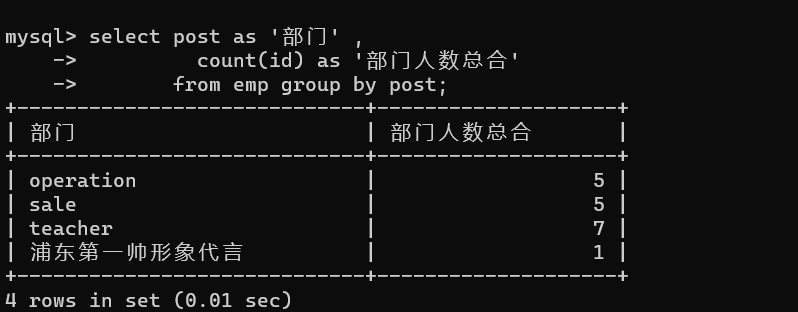
- 4.统计每个部门的人数
推导流程:
# 1、先获取部门信息
select post from emp group by post;
# 2、获取部门下人员工资的综合信息
select post as '部门' ,
count(id) as '部门人数总合'
from emp group by post;
- 5.统计每个部门的部门名称及员工姓名
- 使用group by后,不可直接展示多条字段名,想要展示多条字段名只能使用方法的方式来展示
- 关键词:group_concat()
- 支持在后方阔内填入多条字段名,需要用逗号隔开,同时也支持数据展示自定义
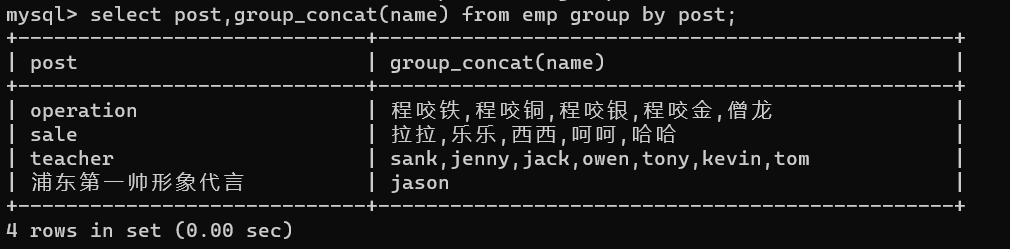
1、打印部门名称及部门下人员姓名
select post,group_concat(name) from emp group by post;
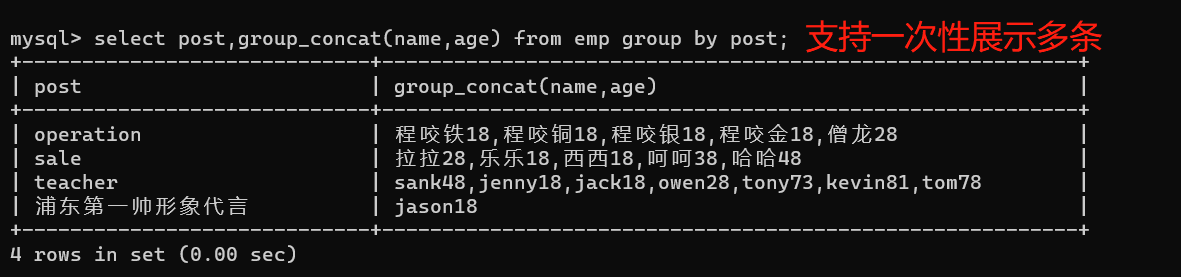
2、打印部门名称,部门下人员姓名、年龄
select post,group_concat(name,age) from emp group by post;
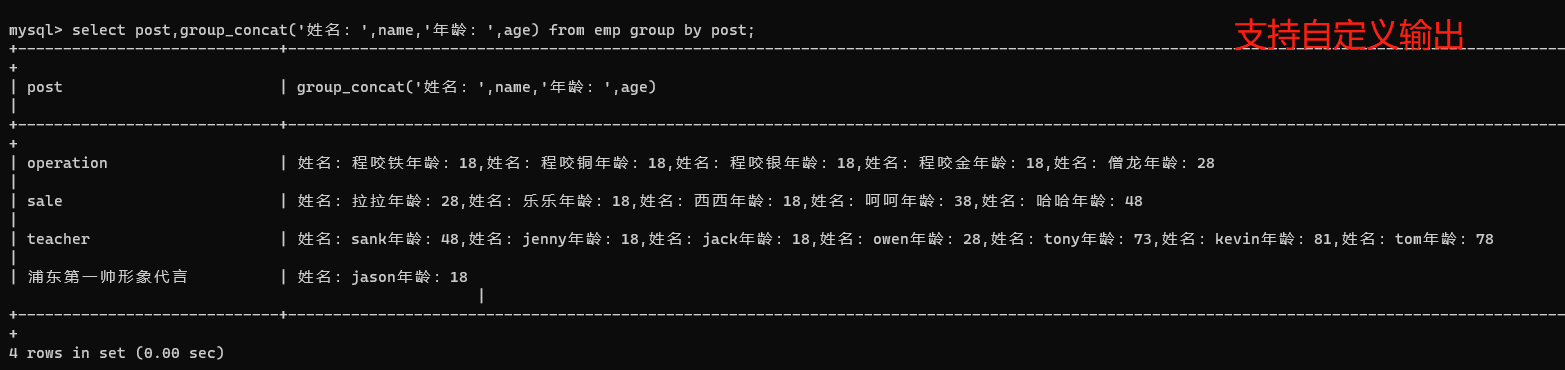
3、自定义输出内容
select post,group_concat('姓名:',name,'年龄:',age) from emp group by post;
5、关查询之having过滤
5、1.功能介绍
- 关键词:having
- 功能:having的功能和where功能的本质是一样的,都是用来对数据进行筛选
- 区别是having用来对数据进行二次筛选
- 功能:having的功能和where功能的本质是一样的,都是用来对数据进行筛选
5、2.实际应用
- 1.统计各部门年龄在30岁以上的员工平均工资 并且保留大于10000的数据
推导流程:
# 1、筛选大于30的员工
select * from emp where age > 30;
# 2、对获取的信息进行部门分类
select post from where age > 30 group by;
# 3、对获取的信息取工资的平均值
select post.vag(salary) from emp where age > 30 group bay;
# 4、对平均工资进行过滤,保留大于10000的数据
select post,vag(salary) from emp where age > 30 group by having vag(salary)>10000;

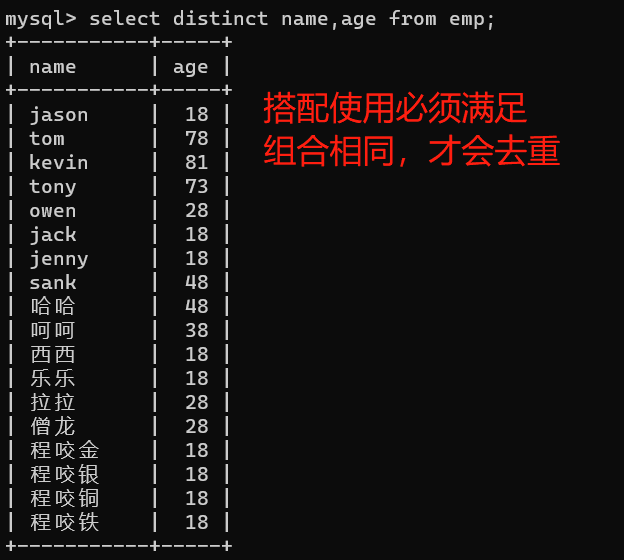
6、查询之distinct去重
6、1.功能介绍
关键词:distinct
功能:可以去除表中重复的数据,但是数据必须要一样才可以,也可以多列使用
- 多列使用时,满足的条件是多个字段的组合发生重复才会去重
6、2.实际应用
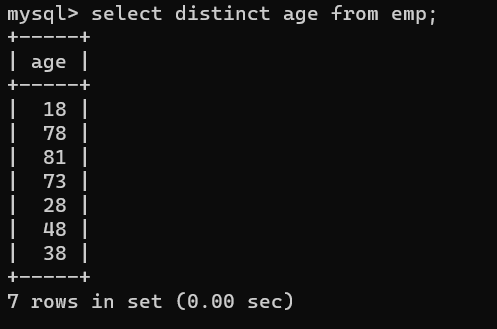
- 去除重复的年龄
1、单列使用
select distinct age from emp;
2、多列使用
select distinct name,age from emp;
7、查询之order by排序
7、1.功能介绍
- 关键词:order by
- 功能:在查看表时,可将指定的字段下的数据排序,支持多列排序(例如先按照年龄排序,再将相同年龄段的用户按照收入排序),默认为升序,可修改为降序
- 升降序
- 升序:
- select * from 表名 order by 字段名;
- select * from 表名 order by 字段名 asc;
- 降序:
- select * from 表名 order by 字段名 desc;
- 升序:
7、2.实际应用
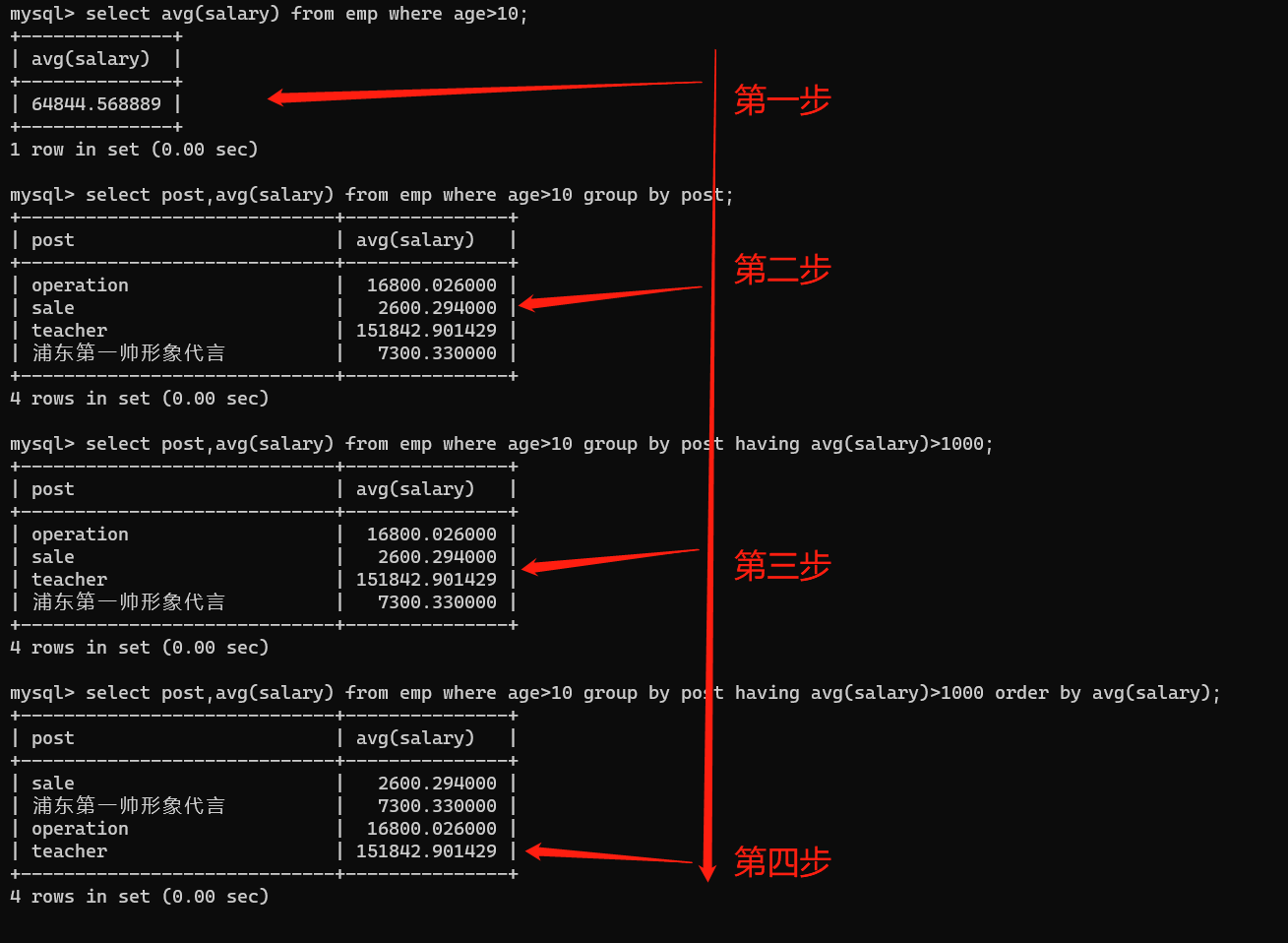
- 统计各部门年龄在10岁以上的员工平均工资,并且保留平均工资大于1000的部门,然后对平均工资进行排序
推导流程:
# 1、先筛选出年龄大于10的人员平均工资
select avg(salary) from emp where age>10;
# 2、将各部门人员信息分开
select post,avg(salary) from emp where age>10 group by post;
# 3、进行二次筛选,保留平均工资大于1000的部门
select post,avg(salary) from emp where age>10 group by post having avg(salary)>1000;
# 4、对工资进行排序
select post,avg(salary) from emp where age>10 group by post having avg(salary)>1000 order by avg(salary);
8、查询之Limit分页
8、1.功能介绍
- 关键词:limit
- 功能:当我们再打开一个数据量较为庞大的表时,会占用很多内存,limit可以帮助我们将表分页,再后方阔内输入参数可控制表打开条数,也可支持打开的范围
8、2.实际应用
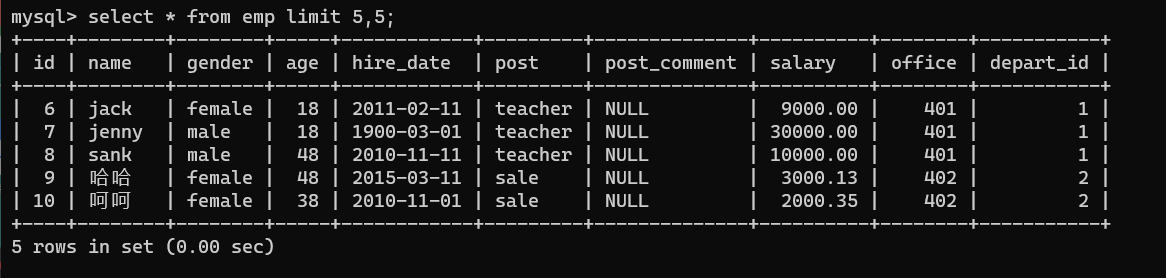
- 常规用法
1、限制表打开的条数
select * from emp limit 5;
2、控制表打开的范围
select * from emp limit 5,5;

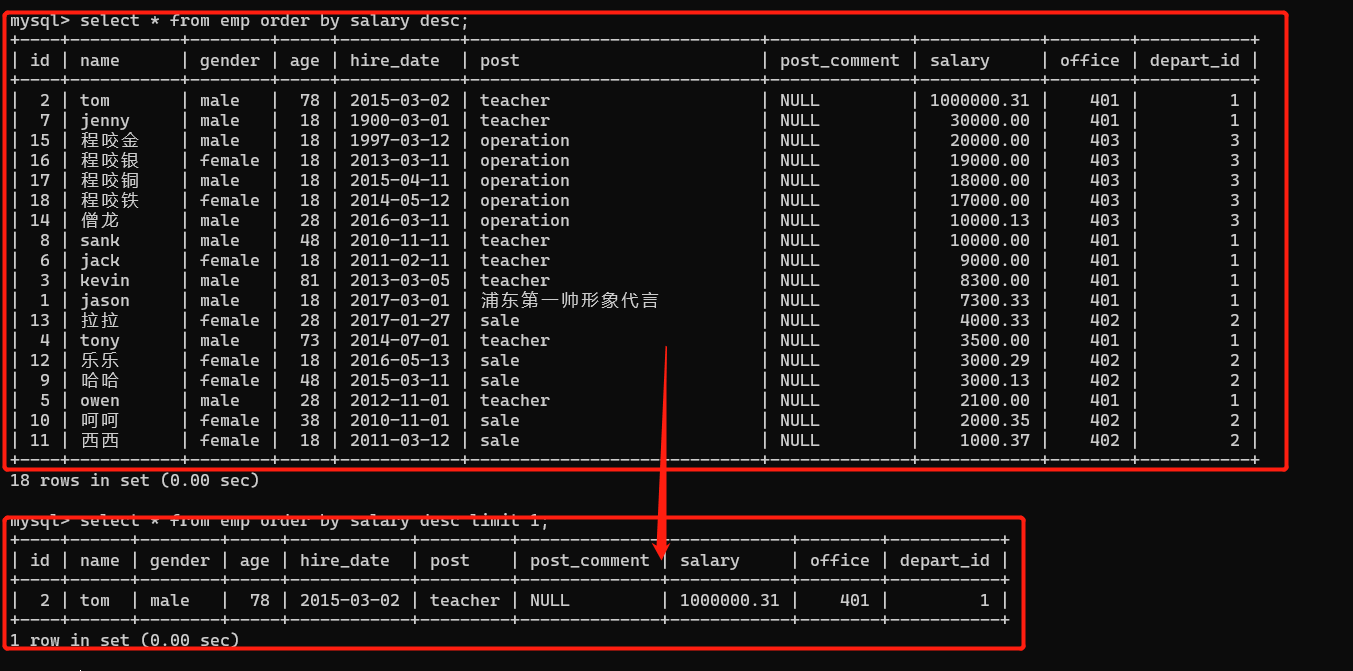
- 查询工资最高的人的信息
推导流程:
# 1、将表内所有人员的工资进行排序 设置为降序
select * from empor order by salary desc limit 1;
9、查询之regexp正则
9、1.功能介绍
- 关键词:regexp
- 功能:可以按照指定正则条件,对表内的数据进行搜索,是模糊搜索的一种
9、2.实际应用
- 搜索j开头n或y结尾的用户信息
select * from emp where name regexp '^j.*(y|n)$';

二、多表查询思路
数据准备
创建部门表:
create table dep(
id int primary key auto_increment,
name varchar(20)
);
创建员工信息表:
create table emp(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
插入数据:
insert into dep values
(200,'技术'),
(201,'人力资源'),
(202,'销售'),
(203,'运营'),
(205,'财务');
insert into emp(name,sex,age,dep_id) values
('jason','male',18,200),
('dragon','female',48,201),
('kevin','male',18,201),
('nick','male',28,202),
('owen','male',18,203),
('jerry','female',18,204);
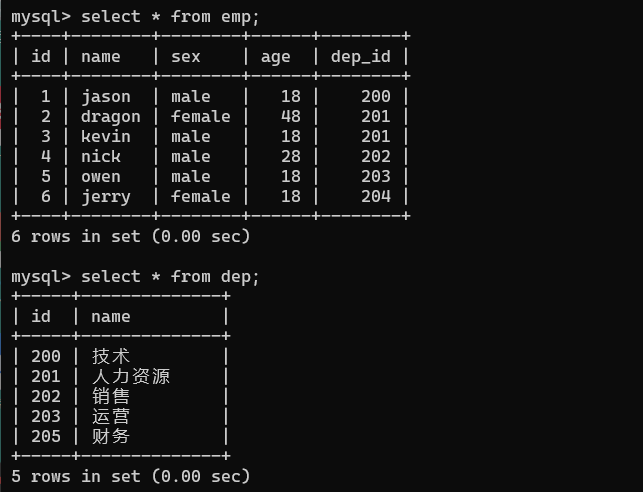
1、实际应用
以上两个表,类似于公司的员工信息,和公司部门表,两张表为关系型表,通过之前的学习,我们了解到想要查询数据可以通过‘select * from 表名’的方式进行查询,其实这个方法也可以一次性查询多张表,方法如下
select * from emp,dep;
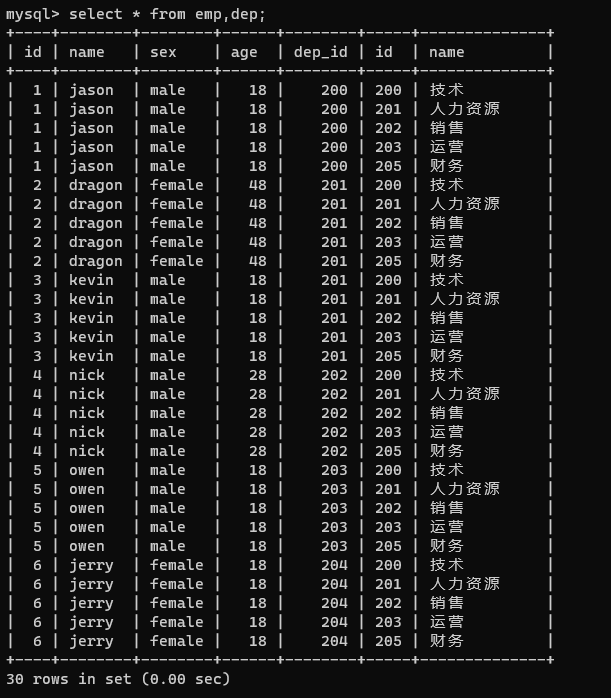
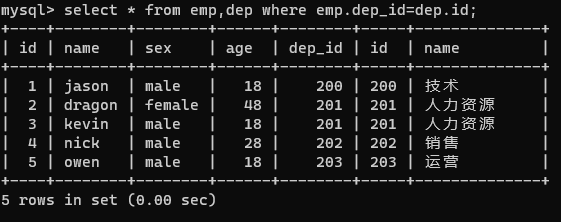
由上图可以看出,select 方法一次性读出了两张表,但是表的数据发生了错乱,字段发生了冲突由此我们可以通过指定表名的方式进行查询,避免发生错乱
select * from emp,dep where emp.dep_id=dep.id;
MySQL数据库:7、SQL常用查询语句的更多相关文章
- Mysql补充部分:SQL逻辑查询语句执行顺序
一 SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_table> <join_type> JOI ...
- SQL常用查询语句及函数
1.日期匹配_获取时间差 select datediff(dd,getdate(),'12/25/2006') --计算从今天到12/25/2006还有多少个月 2.不能通过IP连接数据库 在数据库 ...
- mysql数据库-初始化sql建库建表-关联查询投影问题
下面是一个简易商城的几张表的创建方式 drop database if exists shop ; create database shop CHARACTER SET 'utf8' COLLATE ...
- mysql(数据库,sql语句,普通查询)
第1章 数据库 1.1 数据库概述 l 什么是数据库 数据库就是存储数据的仓库,其本质是一个文件系统,数据按照特定的格式将数据存储起来,用户可以对数据库中的数据进行增加,修改,删除及查询操作. l 什 ...
- 23个MySQL常用查询语句
23个MySQL常用查询语句 一查询数值型数据: SELECT * FROM tb_name WHERE sum > 100; 查询谓词:>,=,<,<>,!=,!> ...
- Oracle,SQL Server 数据库较MySql数据库,Sql语句差异
原文:Oracle,SQL Server 数据库较MySql数据库,Sql语句差异 Oracle,SQL Server 数据库较MySql数据库,Sql语句差异 1.关系型数据库 百度百科 关系数据库 ...
- 【数据库】 SQL 常用语句之系统语法
[数据库] SQL 常用语句之系统语法 1. 获取取数据库服务器上所有数据库的名字 SELECT name FROM master.dbo.sysdatabases 2. 获取取数据库服务器上所有非系 ...
- python 3 mysql sql逻辑查询语句执行顺序
python 3 mysql sql逻辑查询语句执行顺序 一 .SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_t ...
- mysql第四篇--SQL逻辑查询语句执行顺序
mysql第四篇--SQL逻辑查询语句执行顺序 一.SQL语句定义顺序 SELECT DISTINCT <select_list> FROM <left_table> < ...
- 【数据库】 SQL 常用语句
[数据库] SQL 常用语句 1.批量导入 INSERT INTO Table2(field1,field2,...) SELECT value1,value2,... FROMTable1 要求目标 ...
随机推荐
- torch.stack()与torch.cat()
torch.stack():http://www.45fan.com/article.php?aid=1D8JGDik5G49DE1X torch.stack()个人理解:属于先变形再cat的操作,所 ...
- OKR之剑(理念篇)02—— OKR布道之旅
作者:vivo互联网平台产品研发团队 1.我们是如何引入的 1.1.企业文化匹配 大概是在2013年底,一些创业者在硅谷深受OKR洗礼,并在自己的公司内小范围运用,以此OKR开始传入中国.而vivo初 ...
- Django 目录
1 Python Web开发主流框架 2 Django 简介和版本介绍 3 Django 使用cmd 创建工程 4 Django 创建 APP和目录结构介绍 5 Django 使用VScode 创建工 ...
- Kubernetes 监控:Prometheus Adpater =》自定义指标扩缩容
使用 Kubernetes 进行容器编排的主要优点之一是,它可以非常轻松地对我们的应用程序进行水平扩展.Pod 水平自动缩放(HPA)可以根据 CPU 和内存使用量来扩展应用,前面讲解的 HPA 章节 ...
- ProxySQL(4):多层配置系统
文章转载自:https://www.cnblogs.com/f-ck-need-u/p/9280793.html ProxySQL中的库 使用ProxySQL的Admin管理接口连上ProxySQL, ...
- ELK Stack 日志平台性能优化
转载自: https://mp.weixin.qq.com/s?__biz=MzAwNTM5Njk3Mw==&mid=2247487789&idx=1&sn=def0d8c2e ...
- Prometheus高可用部署
Prometheus的本地存储给Prometheus带来了简单高效的使用体验,可以让Promthues在单节点的情况下满足大部分用户的监控需求.但是本地存储也同时限制了Prometheus的可扩展性, ...
- 【设计模式】Java设计模式 - 命令模式
Java设计模式 - 命令模式 生命不息,写作不止 继续踏上学习之路,学之分享笔记 总有一天我也能像各位大佬一样 一个有梦有戏的人 @怒放吧德德 分享学习心得,欢迎指正,大家一起学习成长! 目录 Ja ...
- 洛谷P2865 [USACO06NOV]Roadblocks G(次短路)
一个次短路的问题,可以套用dijkstra求最短路的方法,用dis[0][i]表示最短路:dis[1][i]表示次短路,优先队列中存有最短路和次短路,然后每次找到一条道路对他进行判断,更新最短或次短路 ...
- zookeeper之安装
zookeeper之安装 一.准备条件 1.1 最低三个服务器(一主多从,1个leader,多个flower)1.2 将zookeeper安装包上传到集群并解压zookeeper 二.将conf目录下 ...