【十大经典数据挖掘算法】k-means
【十大经典数据挖掘算法】系列
1. 引言
k-means与kNN虽然都是以k打头,但却是两类算法——kNN为监督学习中的分类算法,而k-means则是非监督学习中的聚类算法;二者相同之处:均利用近邻信息来标注类别。
聚类是数据挖掘中一种非常重要的学习流派,指将未标注的样本数据中相似的分为同一类,正所谓“物以类聚,人以群分”嘛。k-means是聚类算法中最为简单、高效的,核心思想:由用户指定k个初始质心(initial centroids),以作为聚类的类别(cluster),重复迭代直至算法收敛。
2. 基本算法
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster);
repeat:
对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
重新计算k个cluser对应的质心;
until 质心不再发生变化
对于欧式空间的样本数据,以平方误差和(sum of the squared error, SSE)作为聚类的目标函数,同时也可以衡量不同聚类结果好坏的指标:
\]
表示样本点\(x\)到cluster \(C_i\) 的质心 \(c_i\) 距离平方和;最优的聚类结果应使得SSE达到最小值。
下图中给出了一个通过4次迭代聚类3个cluster的例子:

k-means存在缺点:
k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果(SSE较大):
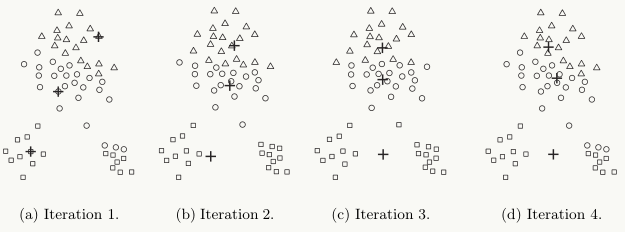
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
3. 优化
为了解决上述存在缺点,在基本k-means的基础上发展而来二分 (bisecting) k-means,其主要思想:一个大cluster进行分裂后可以得到两个小的cluster;为了得到k个cluster,可进行k-1次分裂。算法流程如下:
初始只有一个cluster包含所有样本点;
repeat:
从待分裂的clusters中选择一个进行二元分裂,所选的cluster应使得SSE最小;
until 有k个cluster
上述算法流程中,为从待分裂的clusters中求得局部最优解,可以采取暴力方法:依次对每个待分裂的cluster进行二元分裂(bisect)以求得最优分裂。二分k-means算法聚类过程如图:

从图中,我们观察到:二分k-means算法对初始质心的选择不太敏感,因为初始时只选择一个质心。
4. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
[2] Xindong Wu, Vipin Kumar, The Top Ten Algorithms in Data Mining.
【十大经典数据挖掘算法】k-means的更多相关文章
- 【十大经典数据挖掘算法】k
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
- 【十大经典数据挖掘算法】kNN
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 顶级数据挖掘会议ICDM ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
随机推荐
- web Api 返回json 的两种方式
web api写api接口时默认返回的是把你的对象序列化后以XML形式返回,那么怎样才能让其返回为json呢,下面就介绍两种方法: 方法一:(改配置法) 找到Global.asax文件,在Applic ...
- 多文档上传(upload multiple documents)功能不能使用怎么办?
问题描述: 在SharePoint 2010的文档库里选择documents标签,然后选择upload document下拉菜单,你会发现upload multiple documents那个按钮是灰 ...
- PHP ob_start() 函数介绍
ob_start() 函数介绍: http://www.nowamagic.net/php/php_ObStart.php ob_start()作用: http://zhidao.baidu.com/ ...
- NEsper Nuget包
Esper是专门进行复杂事件处理(CEP)的流处理平台,Java版本为Esper,.Net版本为NEsper.Esper & NEsper可以方便开发者快速开发部署处理大容量消息和事件的应用系 ...
- MVC学习一:EF
目录 一.EF修改和删除的多种方法 二.标准查询where 三.include 四.skip take 五.反射获取实例属性 六.EF DLL数据访问帮助类 一.EF修改和删除的多种方法 方法1:官方 ...
- Lesson 9 A cold welcome
Text On Wednesday evening, we went to the Town Hall. It was the last day of the year and a large cro ...
- 玩转Windows服务系列——命令行管理Windows服务
说到Windows服务的管理就不得不说通过命令行的方式管理Windows服务,因为无论是系统管理员,还是通过编程的方式调用cmd命令,命令行都是非常方便以及强大的工具. 接下来就看一下如何通过cmd命 ...
- 新功能发布!Markdown写博客!
有一种神奇的语言,它比html还简单,它巧妙地将内容与格式整合在一起--它就是Markdown. 现在我们实现了博客对Markdown的内置支持,可以让您轻松地在园子里用这个神奇的语言写博客! &qu ...
- 【PRINCE2是什么】PRINCE2认证之七大原则(2)
我们先来回顾一下,PRINCE2七大原则分别是持续的业务验证,经验学习,角色与责任,按阶段管理,例外管理,关注产品,剪裁. 第二个原则:吸取经验教训. PRINCE2要求项目团队吸取以前的经验教训,在 ...
- 1代 angularjs ember vue 比较
angularjs ember vue 比较 看了别人的ppt,直接贴结果,仅供参考