ConcurrentHashMap实现原理以及源码分析
ConcurrentHashMap是HashMap的高并发版本,是线程安全的,而HashMap是非线程安全的
一、底层实现
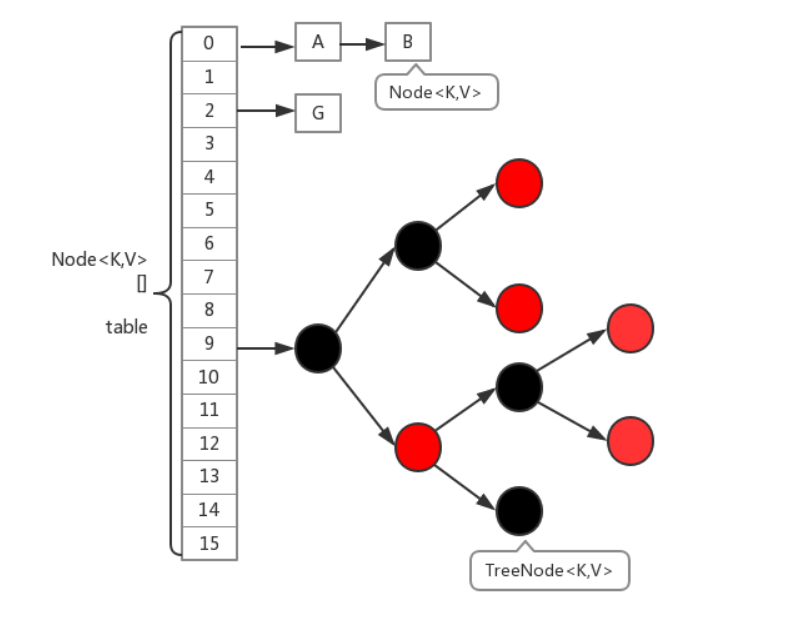
底层结构跟hashmap一样,都是通过数组+链表+红黑树实现的,不过它要保证线程安全性,所以在源码上要复杂一些
线程安全是通过CAS和synchronized实现的
源码分析
相关节点
- Node:该类用于构造table[],只读节点(不提供修改方法)。
- TreeBin:红黑树结构。
- TreeNode:红黑树节点。
- ForwardingNode:临时节点(扩容时使用)。
table
transient volatile Node<K,V>[] table;
所有的数据都存放在table中,table的容量会根据实际情况进行扩容,table[i]存放的类型有一下三种
- TreeBin用于包装红黑树的节点类型
- ForWardingNode扩容时存放的节点类型,并发扩容实现关键之一
- Node普通节点类型,表示链表头节点
sizeCtl
private transient volatile int sizeCtl;
默认为0,用来控制table的初始化和扩容操作,不同值的代表状态如下:
- -1:table[i]正在初始化
- -N:表示有N-1个线程正在进行扩容操作
- 非负数情况:(1)如果table[i]未初始化,则表示table需要初始化的大小(2)如果初始化完成,则表示table[i]扩容的阀值,默认是table[]容量的0.75倍
tabAt()/casTabAt()/setTabAt()
(long)i << ASHIFT) + ABASE得到table[i]的内存偏移地址
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);}static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,Node<K,V> c, Node<K,V> v) {return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);}static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);}
这三个方法都是有原子意义的读、写操作
而casTabAt()与setTabAt()方法的区别
所以真正要进行有原子语义的写操作需要使用casTabAt()方法,setTabAt()是在锁定桶的状态下需要使用的方法,如此方法实现只是带保守性的一种写法而已。
put()方法
public V put(K key, V value) {return putVal(key, value, false);}final V putVal(K key, V value, boolean onlyIfAbsent) {if (key == null || value == null) throw new NullPointerException();int hash = spread(key.hashCode()); //@1int binCount = 0; //i处结点标志,0: 未加入新结点, 2: TreeBin或链表结点数, 其它:链表结点数。主要用于每次加入结点后查看是否要由链表转为红黑树for (Node<K,V>[] tab = table;;) { //CAS经典写法,不成功无限重试Node<K,V> f; int n, i, fh;if (tab == null || (n = tab.length) == 0) // 若table[]未创建,则初始化//除非构造时指定初始化集合,否则默认构造不初始化table,真正添加时元素检查是否需要初始化。tab = initTable(); //@2//CAS操作得到对应table中元素else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //table[i]后面无节点时,直接创建Node(无锁操作)if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; //null创建Node对象做为链表首结点}else if ((fh = f.hash) == MOVED) //如果当前正在扩容,则帮助扩容并返回最新table[]tab = helpTransfer(tab, f); //扩容完毕再在新table中放入键值对,扩容节细讲else { //在链表或者红黑树中追加节点V oldVal = null;synchronized (f) {if (tabAt(tab, i) == f) { //双重检查i处结点未变化if (fh >= 0) { //如果为链表结构 //表明是链表结点类型,hash值是大于0的,即spread()方法计算而来binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) { //找到key,替换valueoldVal = e.val;if (!onlyIfAbsent) //是新元素才加入标志位,一般使用不会用到e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {//jdk1.8版本是把新结点加入链表尾部,next由volatile修饰pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) { //红黑树结点类型Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) { //@4oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD) //默认桶中结点数超过8个数据结构会转为红黑树treeifyBin(tab, i); //@5if (oldVal != null)return oldVal;break;}}}addCount(1L, binCount); //更新size,检测扩容return null;}
从上面代码可以看出,put的步骤大致如下:
1、参数校验。
2、若table[]未创建,则初始化。
3、当table[i]后面无节点时,直接创建Node(无锁操作)。
4、如果当前正在扩容,则帮助扩容并返回最新table[]。
5、然后在链表或者红黑树中追加节点。
6、最后还回去判断是否到达阀值,如到达变为红黑树结构。
get()方法
public V get(Object key) {Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;int h = spread(key.hashCode());// 定位到table[]中的iif ((tab = table) != null && (n = tab.length) > 0 &&(e = tabAt(tab, (n - 1) & h)) != null) {// 若table[i]存在if ((eh = e.hash) == h) {// 比较链表头部if ((ek = e.key) == key || (ek != null && key.equals(ek)))return e.val;}else if (eh < 0)// 若为红黑树,查找树return (p = e.find(h, key)) != null ? p.val : null;while ((e = e.next) != null) {// 循环链表查找if (e.hash == h &&((ek = e.key) == key || (ek != null && key.equals(ek))))return e.val;}}return null;// 未找到}
get()方法的流程相对简单一点,从上面代码可以看出以下步骤:
1、首先定位到table[]中的i。
2、若table[i]存在,则继续查找。
3、首先比较链表头部,如果是则返回。
4、然后如果为红黑树,查找树。
5、最后再循环链表查找
从上面步骤可以看出,ConcurrentHashMap的get操作上面并没有加锁。所以在多线程操作的过程中,并不能完全的保证一致性。
table扩容机制
触发扩容的时机
- 新增节点后,addcount统计tab中的节点个数大于阙值(sizeCtl),会触发tranfer,重新调整节点位置
- 链表转化红黑树(put()时检查调用treeifyBin(tab, i))时如果table容量小于64,则会触发扩容,调用tryPresize(n << 1)进行扩容;
- 调用putAll()一次性加入大量元素,调用tryPresize(m.size())进行扩容;
addCount()方法
private final void addCount(long x, int check) {...//check就是binCount,有新元素加入成功才检查是否要扩容。if (check >= 0) {Node<K,V>[] tab, nt; int n, sc;//大于当前扩容阈值并且小于最大扩容值才扩容,如果table还未初始化则等待初始化完成。while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY) {int rs = resizeStamp(n); //@1if (sc < 0) { //已经有线程在进行扩容工作//检查是原容量为n的情况下进行扩容,保证sizeCtl与n是一块修改好的,条件2与条件3在当前RESIZE_STAMP_BITS情况下应该不会成功,欢迎指正。条件4与条件5确保tranfer()中的nextTable相关初始化逻辑已走完。if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0)break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) //有新线程参与扩容则sizeCtl统计加1transfer(tab, nt);}else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2)) //有线程检测到需要扩容时走这里,初始值为(rs << RESIZE_STAMP_SHIFT) + 2)),+2没什么特别,只是为符合-(1+扩容线程数)的定义。transfer(tab, null);s = sumCount();}}}
treeifyBin()方法
private final void treeifyBin(Node<K,V>[] tab, int index) {Node<K,V> b; int n, sc;if (tab != null) {if ((n = tab.length) < MIN_TREEIFY_CAPACITY)//如果table.length<64 就扩大一倍 返回tryPresize(n << 1);else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {synchronized (b) {if (tabAt(tab, index) == b) {TreeNode<K,V> hd = null, tl = null;//构造了一个TreeBin对象 把所有Node节点包装成TreeNode放进去for (Node<K,V> e = b; e != null; e = e.next) {TreeNode<K,V> p =new TreeNode<K,V>(e.hash, e.key, e.val,null, null);//这里只是利用了TreeNode封装 而没有利用TreeNode的next域和parent域if ((p.prev = tl) == null)hd = p;elsetl.next = p;tl = p;}//在原来index的位置 用TreeBin替换掉原来的Node对象setTabAt(tab, index, new TreeBin<K,V>(hd));}}}}}
tryPresize()方法
private final void tryPresize(int size) {int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :tableSizeFor(size + (size >>> 1) + 1);int sc;while ((sc = sizeCtl) >= 0) {Node<K,V>[] tab = table; int n;if (tab == null || (n = tab.length) == 0) {n = (sc > c) ? sc : c;if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {if (table == tab) {@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = nt;sc = n - (n >>> 2);}} finally {sizeCtl = sc;}}}else if (c <= sc || n >= MAXIMUM_CAPACITY)break;else if (tab == table) {int rs = resizeStamp(n);if (sc < 0) {Node<K,V>[] nt;if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||transferIndex <= 0)break;if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))transfer(tab, nt);}else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))transfer(tab, null);}}}
从上面的分析中我们可以看,addCount()是扩容是老老实实按容量x2来扩容的,而tryPresize()会传入一个size参数,可能一次性扩容很多倍。后面采用一样的方式调用transfer()来进行真正的扩容处理。
transfer()(扩容的核心方法)
当table的元素数量达到容量阈值sizeCtl,需要对table进行扩容:
- 构建一个nextTable,大小为table两倍
- 把table的数据复制到nextTable中。
在扩容过程中,依然支持并发更新操作;也支持并发插入。
关于扩容机制,推荐大家看
https://blog.csdn.net/elricboa/article/details/70199409
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {int n = tab.length, stride;if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)stride = MIN_TRANSFER_STRIDE; // subdivide rangeif (nextTab == null) { // initiatingtry {@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; // 构建一个nextTable,大小为table两倍nextTab = nt;} catch (Throwable ex) { // try to cope with OOMEsizeCtl = Integer.MAX_VALUE;return;}nextTable = nextTab;transferIndex = n;}int nextn = nextTab.length;ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);boolean advance = true;boolean finishing = false; // to ensure sweep before committing nextTab//通过for自循环处理每个槽位中的链表元素,默认advace为真,通过CAS设置transferIndex属性值,并初始化i和bound值,i指当前处理的槽位序号,bound指需要处理的槽位边界,先处理槽位15的节点;for (int i = 0, bound = 0;;) {Node<K,V> f; int fh;while (advance) { // 遍历table中的每一个节点int nextIndex, nextBound;if (--i >= bound || finishing)advance = false;else if ((nextIndex = transferIndex) <= 0) {i = -1;advance = false;}else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex,nextBound = (nextIndex > stride ?nextIndex - stride : 0))) {bound = nextBound;i = nextIndex - 1;advance = false;}}if (i < 0 || i >= n || i + n >= nextn) {int sc;if (finishing) { // //如果所有的节点都已经完成复制工作 就把nextTable赋值给table 清空临时对象nextTablenextTable = null;table = nextTab;sizeCtl = (n << 1) - (n >>> 1); //扩容阈值设置为原来容量的1.5倍 依然相当于现在容量的0.75倍return;}// 利用CAS方法更新这个扩容阈值,在这里面sizectl值减一,说明新加入一个线程参与到扩容操作if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)return;finishing = advance = true;i = n; // recheck before commit}}//如果遍历到的节点为空 则放入ForwardingNode指针else if ((f = tabAt(tab, i)) == null)advance = casTabAt(tab, i, null, fwd);//如果遍历到ForwardingNode节点 说明这个点已经被处理过了 直接跳过 这里是控制并发扩容的核心else if ((fh = f.hash) == MOVED)advance = true; // already processedelse {synchronized (f) {if (tabAt(tab, i) == f) {Node<K,V> ln, hn;if (fh >= 0) { // 链表节点int runBit = fh & n; // resize后的元素要么在原地,要么移动n位(n为原capacity),详解见:https://huanglei.rocks/coding/194.html#4%20resize()%E7%9A%84%E5%AE%9E%E7%8E%B0Node<K,V> lastRun = f;//以下的部分在完成的工作是构造两个链表 一个是原链表 另一个是原链表的反序排列for (Node<K,V> p = f.next; p != null; p = p.next) {int b = p.hash & n;if (b != runBit) {runBit = b;lastRun = p;}}if (runBit == 0) {ln = lastRun;hn = null;}else {hn = lastRun;ln = null;}for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}//在nextTable的i位置上插入一个链表setTabAt(nextTab, i, ln);//在nextTable的i+n的位置上插入另一个链表setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd);//设置advance为true 返回到上面的while循环中 就可以执行i--操作advance = true;}//对TreeBin对象进行处理 与上面的过程类似else if (f instanceof TreeBin) {TreeBin<K,V> t = (TreeBin<K,V>)f;TreeNode<K,V> lo = null, loTail = null;TreeNode<K,V> hi = null, hiTail = null;int lc = 0, hc = 0;//构造正序和反序两个链表for (Node<K,V> e = t.first; e != null; e = e.next) {int h = e.hash;TreeNode<K,V> p = new TreeNode<K,V>(h, e.key, e.val, null, null);if ((h & n) == 0) {if ((p.prev = loTail) == null)lo = p;elseloTail.next = p;loTail = p;++lc;}else {if ((p.prev = hiTail) == null)hi = p;elsehiTail.next = p;hiTail = p;++hc;}}// (1)如果lo链表的元素个数小于等于UNTREEIFY_THRESHOLD,默认为6,则通过untreeify方法把树节点链表转化成普通节点链表;(2)否则判断hi链表中的元素个数是否等于0:如果等于0,表示lo链表中包含了所有原始节点,则设置原始红黑树给ln,否则根据lo链表重新构造红黑树。ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :(hc != 0) ? new TreeBin<K,V>(lo) : t;hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :(lc != 0) ? new TreeBin<K,V>(hi) : t;setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);setTabAt(tab, i, fwd); // tab[i]已经处理完了advance = true;}}}}}}
二、ConcurrentHashMap在1.7与1.8的不同
| 区别 | JDK1.7 | JDK1.8 |
|---|---|---|
| 同步机制 | 分段锁,每个segment继承ReentrantLock | CAS+synchronized保证并发更新 |
| 存储结构 | 数组+链表 | 数组+链表+红黑树 |
| 键值对 | HashEntry | Node |
| put操作 | 多个线程同时竞争获取同一个segment锁,获取成功的线程更新map;失败的线程尝试多次获取锁仍未成功,则挂起线程,等待释放锁 | 访问相应的bucket时,使用sychronizeded关键字,防止多个线程同时操作同一个bucket,如果该节点的hash不小于0,则遍历链表更新节点或插入新节点;如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点;更新了节点数量,还要考虑扩容和链表转红黑树 |
| size实现 | 统计每个Segment对象中的元素个数,然后进行累加,但是这种方式计算出来的结果并不一样的准确的。先采用不加锁的方式,连续计算元素的个数,最多计算3次:如果前后两次计算结果相同,则说明计算出来的元素个数是准确的;如果前后两次计算结果都不同,则给每个Segment进行加锁,再计算一次元素的个数; | 通过累加baseCount和CounterCell数组中的数量,即可得到元素的总个数; |
三、ConcurrentHashMap与HashTable的区别
hash table虽然性能上不如ConcurrentHashMap,但并不能完全被取代,两者的迭代器的一致性不同的,hash table的迭代器是强一致性的,而concurrenthashmap是弱一致的。 ConcurrentHashMap的get,clear,iterator 都是弱一致性的。
下面是大白话的解释:
- Hashtable的任何操作都会把整个表锁住,是阻塞的。好处是总能获取最实时的更新,比如说线程A调用putAll写入大量数据,期间线程B调用get,线程B就会被阻塞,直到线程A完成putAll,因此线程B肯定能获取到线程A写入的完整数据。坏处是所有调用都要排队,效率较低。
- ConcurrentHashMap 是设计为非阻塞的。在更新时会局部锁住某部分数据,但不会把整个表都锁住。同步读取操作则是完全非阻塞的。好处是在保证合理的同步前提下,效率很高。坏处 是严格来说读取操作不能保证反映最近的更新。例如线程A调用putAll写入大量数据,期间线程B调用get,则只能get到目前为止已经顺利插入的部分 数据。
选择哪一个,是在性能与数据一致性之间权衡。ConcurrentHashMap适用于追求性能的场景,大多数线程都只做insert/delete操作,对读取数据的一致性要求较低。
ConcurrentHashMap实现原理以及源码分析的更多相关文章
- HashMap和ConcurrentHashMap实现原理及源码分析
HashMap实现原理及源码分析 哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表, ...
- ConcurrentHashMap实现原理及源码分析
ConcurrentHashMap实现原理 ConcurrentHashMap源码分析 总结 ConcurrentHashMap是Java并发包中提供的一个线程安全且高效的HashMap实现(若对Ha ...
- 2.Java集合-ConcurrentHashMap实现原理及源码分析
一.为何用ConcurrentHashMap 在并发编程中使用HashMap可能会导致死循环,而使用线程安全的HashTable效率又低下. 线程不安全的HashMap 在多线程环境下,使用HashM ...
- OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波
http://blog.csdn.net/chenyusiyuan/article/details/8710462 OpenCV学习笔记(27)KAZE 算法原理与源码分析(一)非线性扩散滤波 201 ...
- (转)ReentrantLock实现原理及源码分析
背景:ReetrantLock底层是基于AQS实现的(CAS+CHL),有公平和非公平两种区别. 这种底层机制,很有必要通过跟踪源码来进行分析. 参考 ReentrantLock实现原理及源码分析 源 ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- 【OpenCV】SIFT原理与源码分析:DoG尺度空间构造
原文地址:http://blog.csdn.net/xiaowei_cqu/article/details/8067881 尺度空间理论 自然界中的物体随着观测尺度不同有不同的表现形态.例如我们形 ...
- 《深入探索Netty原理及源码分析》文集小结
<深入探索Netty原理及源码分析>文集小结 https://www.jianshu.com/p/239a196152de
- HashMap实现原理及源码分析之JDK8
继续上回HashMap的学习 HashMap实现原理及源码分析之JDK7 转载 Java8源码-HashMap 基于JDK8的HashMap源码解析 [jdk1.8]HashMap源码分析 一.H ...
随机推荐
- CentOS 7 下网络无法访问 Failed to start LSB: Bring up/.
[root@localhost Desktop]# ping 192.168.2.1PING 192.168.2.1 (192.168.2.1) 56(84) bytes of data.64 byt ...
- sql 多行、一行 互转
原始数据: 期望数据: IF OBJECT_ID('temp_20170701','u') IS NOT NULL DROP TABLE temp_20170701 CREATE TABLE temp ...
- 上传文件的C#代码
1 <%@ WebHandler Language="C#" Class="UpLoadFile" %> 2 3 using System; 4 u ...
- innobackupex备份参数slave-info、safe-slave-backup
mysql物理备份用的比较多的是innobackupex命令,备份常用,但对于里面的两个参数slave-info.safe-slave-backup一直搞的不太明白,今儿亲测了一下. 先解释一下参数意 ...
- Hbase 日常运维
日常维护的命令 1,major_compact 'testtable',通常生产环境会关闭自动major_compact(配置文件中hbase.hregion.majorcompaction设 为0) ...
- thymeleaf+layui加载页面渲染时TemplateProcessingException: Could not parse as expression
Caused by: org.attoparser.ParseException: Could not parse as expression: " {type: 'numbers'}, { ...
- Visual Studio Code编写C/C++代码常见问题
我会把一些常见问题以及自己编写代码过程中遇到的问题以及解决方案放在这里,各位若是遇到的问题也可以在评论区留言. 一.头文件Error 不会影响编译运行,但会报Warm,如下图 解决方案是安装Inclu ...
- C++解决最基本的迷宫问题
问题描述:给定一个最基本的迷宫图,用一个数组表示,值0表示有路,1表示有障碍物,找一条,从矩阵的左上角,到右下角的最短路.求最短路,大家最先想到的可能是用BFS求,本文也是BFS求最短路的. 源代码如 ...
- [Code] 变态之人键合一
目的也比较单纯,选一门语言,走向人键合一. 选了两本书作为操练场:<精通Python设计模式>.<Data Structure and Algorithm in Python> ...
- [Leetcode] 第324题 摆动排序II
一.题目描述 给定一个无序的数组 nums,将它重新排列成 nums[0] < nums[1] > nums[2] < nums[3]... 的顺序. 示例 1: 输入: nums ...