[Python] 豆瓣电影top250爬虫
1.分析
<li><div class="item">电影信息</div></li>
每个电影信息都是同样的格式,毕竟在服务器端是用循环生成的html,这样解析出电影的信息就很简单了
豆瓣电影top250的翻页也很简单,直接就在url上修改一个start就行了,start代表这一页从start+1开始
比如 https://movie.douban.com/top250?start=0&filter=, 就是top1到top25,每页25部电影,翻页把start+=25就行了,一直加到225
2.获取网页的html
使用python内置的urllib库
不过得到的网页中并没有中文,而是会出现这样的字符串
\xe8\xae\xa9\xe5\xa5\xbd\xe7\x94\xb5\xe5\xbd\xb1\xe6\x9d\xa5\xe6\x89\xbe\xe4\xbd\xa0
这是中文的utf-8编码的16进制版本
先将\x去除,变成
e8aea9e5a5bde794b5e5bdb1e69da5e689bee4bda0
然后每6位是一个中文字符
E8 AE A9 让
E5 A5 BD 好
E7 94 B5 电
。。。
全文是【让好电影来找你】
可以在这个网站上输入16进制的UTF-8编码来查找对应字符
def GetHtml(url):
print('Url : '+url)
f = request.urlopen(url.format(start))
data = f.read()
htmls.append(data.decode('utf-8'))
3.解析网页
简单提下XPath的语法
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
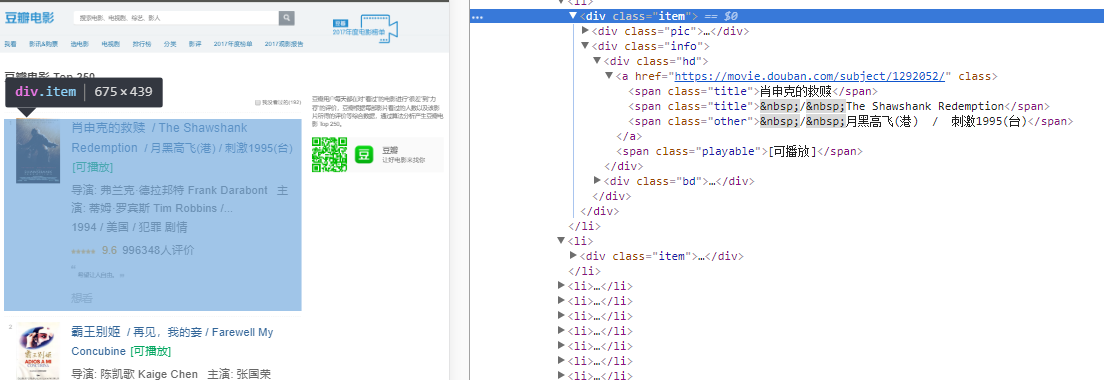
先解析出<div class="item">,再对这个div中的内容进行第二次解析
这里值得注意的是打印一个element内的html要用etree.tostring()
tree = etree.HTML(str)
result = tree.xpath('//div[@class="item"]') //获取所有<div class="item">元素
print(etree.tostring(result[0], encoding='unicode')) //随便打印一个
打印出来的就是这样的
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" class=""/>
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a> <span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br/>
1994 / 美国 / 犯罪 剧情
</p> <div class="star">
<span class="rating5-t"/>
<span class="rating_num" property="v:average">9.6</span>
<span property="v:best" content="10.0"/>
<span>996499人评价</span>
</div> <p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
以上<div class="item">已经拿到了,开始进行第二次解析(可以先用个list把这些div存起来,然后再弄个线程做第二次的解析,那是以后的事了,这里先不管)
记录下这里踩的坑
print(result[0].xpath('//img/@src')) //会返回整个页面的img的src
这个奇怪的问题简直了,我甚至觉得是这个包的bug,我从result[0]那么一小段html用xpath查东西居然能查到整个html的,让我觉得我虽然是用result[0]调用的xpath,但内部没准根本不care谁调用的,一律使用最开始etree.HTML() 的到的这个对象调用xpath
我的解决办法是改下xpath,指定从div开始找,或者是用 “."表示从当前节点开始找
print(result[0].xpath('div//img/@src'))
print(result[0].xpath('.//img/@src'))
下面这段代码中的XPath可能不够简洁,但It's just works,毕竟这是第一个版本,随着我对python的熟练,还会继续改动
主要是将一个p标签下的字符串连接起来并去除空格,转换各种特殊字符
需要注意的是XPath返回的基本都是list类型的,很多博客里都直接调方法都没加下标取值,天知道是不是版本不一样
def ProcessHtml(html):
tree = etree.HTML(html)
items = tree.xpath('//div[@class="item"]') for item in items:
index = item.xpath('div//em/text()')[0]
src = item.xpath('div//img/@src')[0]
info = item.xpath('.//div[@class="bd"]/p')[0].xpath('string(.)').strip().replace(' ','').replace('\xa0',' ').replace('\n',' ')
title = item.xpath('.//div[@class="hd"]/a')[0].xpath('string(.)').strip().replace(' ','').replace('\xa0',' ').replace('\n',' ')
star = item.xpath('.//span[@class="rating_num"]/text()')[0]
print ('''%s
%s
%s
%s
%s
''' % (index,title,info,star,src))
完整代码https://github.com/arcsinw/project_douban
参考链接
scrapy xpath 从response中获取li,然后再获取li中img的src
[Python] 豆瓣电影top250爬虫的更多相关文章
- 记一次python爬虫实战,豆瓣电影Top250爬虫
import requests from bs4 import BeautifulSoup import re import traceback def GetHtmlText(url): for i ...
- 一个豆瓣电影Top250爬虫
一个爬虫 这是我第一次接触爬虫,写的第一个爬虫实例. https://movie.douban.com/top250 模块 import requests #用于发送请求 import re #使用正 ...
- 练习:一只豆瓣电影TOP250的爬虫
练习:一只豆瓣电影TOP250爬虫 练习:一只豆瓣电影TOP250爬虫 ①创建project ②编辑items.py import scrapyclass DoubanmovieItem(scrapy ...
- python爬虫 Scrapy2-- 爬取豆瓣电影TOP250
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python小爬虫——抓取豆瓣电影Top250数据
python抓取豆瓣电影Top250数据 1.豆瓣地址:https://movie.douban.com/top250?start=25&filter= 2.主要流程是抓取该网址下的Top25 ...
- Python爬虫入门:爬取豆瓣电影TOP250
一个很简单的爬虫. 从这里学习的,解释的挺好的:https://xlzd.me/2015/12/16/python-crawler-03 分享写这个代码用到了的学习的链接: BeautifulSoup ...
- 【Python爬虫】:使用高性能异步多进程爬虫获取豆瓣电影Top250
在本篇博文当中,将会教会大家如何使用高性能爬虫,快速爬取并解析页面当中的信息.一般情况下,如果我们请求网页的次数太多,每次都要发出一次请求,进行串行执行的话,那么请求将会占用我们大量的时间,这样得不偿 ...
- python 爬虫&爬取豆瓣电影top250
爬取豆瓣电影top250from urllib.request import * #导入所有的request,urllib相当于一个文件夹,用到它里面的方法requestfrom lxml impor ...
随机推荐
- NOIP 2016 组合数问题 题解
一道sb题目,注意范围,可打表解决,打出杨辉三角,在用前缀和求解即可 代码(一维前缀和) #include<bits/stdc++.h> using namespace std; int ...
- Docker详解(一)
目录 Docker简介 Docker组成 永远的HelloWorld 序言:众所周知,近几年的互联网各项技术发展的如火如荼,敏捷开发模式越来越普及,"快"似乎成为了行业的标准,于是 ...
- Git的合并
merge: A---B---C topic / D---E---F---G master A---B---C topic / \ D---E---F---G---H master (在当前的bran ...
- React-Native组件样式合集
最近在阅读RN的文档,但有一点深感遗憾的是——官方对绝大多数RN组件没有用Gif图或者静态图的方式呈现给大家. 所以我通过百度查询,一个一个的查到了这些RN组件的UI表现图,下面呈现给大家 阅前必 ...
- 脱离脚手架来配置、学习 webpack4.x (一)基础搭建项目
序 现在依旧记得第一次看到webpack3.x 版本配置时候的状态 刚开始看到这些真的是一脸懵.希望这篇文章能帮到刚开始入门的同学. webpack 是什么? webpack是一个模块化打包工具,w ...
- 使用Nginx实现反向代理过程(一台服务器部署两个网站)
正向代理指的是客户端的 反向代理指的是服务端的 需要实现的反向代理: 1.首先使用SwitchHosts配置不同域名,如下:(SwitchHosts软件在上一篇博客有链接) 2.在Linux上部署两台 ...
- 如何在Centos服务器上搭建起Oracle10、VNC、以及FTP
一.重装和分区 1.配置所需磁盘阵列(Raid): 2.正确分区: 3.Centos安装:过于简单,请自行bd. 二.连网 系统安装完成之后,我们需为其分配IP和DNS: "编辑连接&quo ...
- hive 包含操作(left semi join)(left outer join = in)迪卡尔积
目前hive不支持 in或not in 中包含查询子句的语法,所以只能通过left join实现. 假设有一个登陆表login(当天登陆记录,只有一个uid),和一个用户注册表regusers(当天注 ...
- Linux 笔记 - 第十五章 MySQL 常用操作和 phpMyAdmin
博客地址:http://www.moonxy.com 一.前言 前面几章介绍了 MySQL 的安装和简单的配置,只会这些还不够,作为 Linux 系统管理员,我们还需要掌握一些基本的操作,以满足日常管 ...
- Nginx 配置Https转发http、 websocket
系统启动Nginx后,报 [emerg] bind() to 0.0.0.0:XXXX failed (13: Permission denied)错误的处理方式,分为两种: 第一种:端口小于1024 ...