Hadoop学习(3)-mapreduce快速入门加yarn的安装
mapreduce是一个运算框架,让多台机器进行并行进行运算,
他把所有的计算都分为两个阶段,一个是map阶段,一个是reduce阶段
map阶段:读取hdfs中的文件,分给多个机器上的maptask,分文件的时候是按照文件的大小分的
比如每个maptask都会处理128M的文件大小,然后有个500M的文件,就会启动ceil(500/128)个maptask
每读取文件的一行的处理,需要自己去写,注意每个maptask的处理逻辑都是一样的
处理出来的结果一定是一对key和value。
maptask里面的方法叫map(long k, string v, context); k是文件的起始偏移量,v是内容,
context是要把产生的key,value对放入的容器。
reduce阶段:每个机器上有reducetask,其作用是对maptask产生的key和value进行聚合
聚合的原则是key一样的一定分发给一个reducetask,这个操作叫做shuffle
然后把相同key的数据作为一组进行处理。最后会把结果写到hdfs里面
每有几个reducetask,就会生成几个part-r-xxxx文件
reducetask里面的方法reduce(k,value迭代器,context),k就是key,迭代器遍历每一个key相同的value,然后context就是写入hdfs里的,也是一个key和value
入门样例:wordcount
设计思路,每个maptask读取文件,
map里面k 起始偏移量没用,我们每读一行v,产生就是key是每一个单词,然后value就定为1就行,把这个key,value放入context里面
在reduce阶段,每个key相同的就会作为一组,也就是单词相同的作为一组,就统计出现几次就行。
开始在esclipe写mapreduce的业务逻辑,首先我们需要一些jar包,相关的jar包在解压出来的hadoop下的share/hadoop文件夹下

这几个文件夹下的jar包和这几个文件夹下的lib下的jar包都拷贝到esclipe再buildPath
首先编写mapper方法
package test; import java.io.IOException; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; /**
* KEYIN :是map task读取到的数据的key的类型,是一行的起始偏移量Long
* VALUEIN:是map task读取到的数据的value的类型,是一行的内容String
*
* KEYOUT:是用户的自定义map方法要返回的结果kv数据的key的类型,在wordcount逻辑中,我们需要返回的是单词String
* VALUEOUT:是用户的自定义map方法要返回的结果kv数据的value的类型,在wordcount逻辑中,我们需要返回的是整数Integer
*
*
* 但是,在mapreduce中,map产生的数据需要传输给reduce,需要进行序列化和反序列化,而jdk中的原生序列化机制产生的数据量比较冗余,就会导致数据在mapreduce运行过程中传输效率低下
* 所以,hadoop专门设计了自己的序列化机制,那么,mapreduce中传输的数据类型就必须实现hadoop自己的序列化接口
*
* hadoop为jdk中的常用基本类型Long String Integer Float等数据类型封住了自己的实现了hadoop序列化接口的类型:LongWritable,Text,IntWritable,FloatWritable
*
*
*
*
*/
//第一个泛型为起始偏移量,没啥用,第二个为字符串,为读取到的一行内容,第三个,第四个为context中的key,和value,即发送给reduce的k,v对
public class WordcountMapper extends Mapper<LongWritable, Text, Text, IntWritable>{ @Override
//重写map方法
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 切单词
String line = value.toString();
String[] words = line.split(" ");
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
}
接下来是reduce类
package test; import java.io.IOException;
import java.util.Iterator; import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
//第一个,第二个为接收到的map的key,value,第三第四为写入到hdfs的key,value
public class WordcountReducer extends Reducer<Text, IntWritable, Text, IntWritable>{ @Override
//一个key,众多value的迭代器,一个context;
protected void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException { int count = 0;
Iterator<IntWritable> iterator = values.iterator();
while(iterator.hasNext()){ IntWritable value = iterator.next();
count += value.get();
}
context.write(key, new IntWritable(count));
} }
然而我们写的程序需要提交给我们的hadoop集群去运行,而管理这个事情的就是我们的yarn
yarn是一个分布式程序的运行调度平台
yarn中有两大核心角色:
1、Resource Manager
接受用户提交的分布式计算程序,并为其划分资源
接收客户端要运行几个容器,进行任务调度
管理、监控各个Node Manager上的资源情况,以便于均衡负载
2、Node Manager
管理它所在机器的运算资源创建容器(cpu + 内存)
负责接受Resource Manager分配的任务,创建容器、回收资源
我们需要把我们的程序的jar包分发给每一个NodeManager,让他们去运行,
node manager在物理上应该跟data node部署在一起
resource manager在物理上应该独立部署在一台专门的机器上
yarn的安装
yarn我们不需要再下载了,在我们的hadoop里面已经有了yarn,我们只需要写一下配置文件就行
[root@hdp-04 ~]# vi apps/hadoop-2.8.1/etc/hadoop/yarn-site.xml
第一个指明哪一台机器当做resourcemanager,第二个指明nodemanager的任务是什么
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hdp-01</value>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> </configuration>
然后复制这个文件到你的其他机器上
在你的resourcemanager机器上敲 start-yarn.sh,(关闭时stop-yarn.sh)
hadoop就会启动resourcemanager,其他的nodemanager,hadoop是通过slave文件知道的(在/root/apps/hadoop-2.8.1/etc/hadoop/slaves),里面写入你的nodemanager的ip就行,一行一个。
启动之后可以敲jps看一下
或者看网页的形式,resourcemanager的端口号是8088.比如hdp-01:8088
然后安装完yarn之后嘞,我们就可以写一个java的提交任务的程序了
package test; import java.net.URI; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class JobSubmitter { public static void main(String[] args) throws Exception { //在JVM中设置访问hdfs的用户身份为root,因为要对存在datanode节点的文件进行读写,不然可能会权限不够
// 构造一个访问指定HDFS系统的客户端对象: 参数1:——HDFS系统的URI,参数2:——客户端要特别指定的参数,参数3:客户端的身份(用户名)
//FileSystem fs = FileSystem.get(new URI("hdfs://172.31.2.38:9000/"), conf, "root");
//如果是这样设置访问用户身份是不行的,因为不光是自己的客户端访问hdfs,
//job还会创建自己的hdfs的对象FileSystem去访问datanode,那么job创建的对象是从系统环境变量拿到的用户名,所以这样设置身份
System.setProperty("HADOOP_USER_NAME", "root"); //设置配置参数
Configuration conf = new Configuration();
//设置job运行时要访问的默认文件系统
conf.set("fs.defaultFS", "hdfs://172.31.2.38:9000"); //设置job要提交到那里去运行,可以是yarn,也可以是local
conf.set("mapreduce.framework.name", "yarn");
//设置resourcemanager在哪
conf.set("yarn.resourcemanager.hostname", "172.31.2.38");
//如果从windows提交job,需要设置跨平台提交时,把windows中的命令,替换成linux的
//比如运行jar包中某个程序,在linux和windows是不一样的,这样可以自动转化
conf.set("mapreduce.app-submission.cross-platform","true");
//设置job
Job job = Job.getInstance(conf); //封装jar包在windows下的位置
job.setJar("d:/wc.jar");
//设置本次job所要调用的Mapper的class类和reduce的class类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class); //设置mapper实现类的产生结果的key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置reduce实现类的产生结果的key,value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); //设置map时,job要处理的数据的路径,和产生的结果的路径在哪
FileInputFormat.setInputPaths(job, new Path("/wordcount/input"));
//注意输出路径一定要不存在
FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); //设置想要启动reduce task的数量是多少
job.setNumReduceTasks(2); //提交给yarn,等待这个job完成才退出
boolean res = job.waitForCompletion(true); System.exit(res?0:-1); } }
额外知识点:
maven创建报错说插件下载失败,右键项目
然后 右键属性Maven,Update project
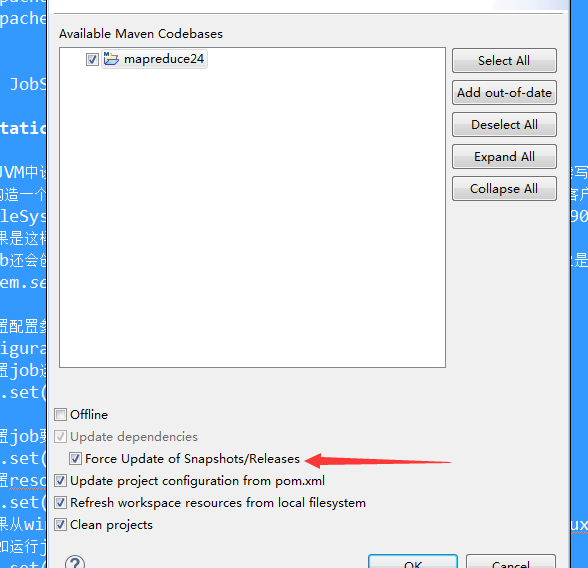
把这个给点上就行了。或者进入到org/apache/maven,把里面的东西全删了,让他自己去下载。
在编程时的易错点:
注意自己写的路径file:\为windows,/为linux
注意改完源码之后,要注意重新生成一个jar包,不然提交到linux里,还是会报错
Hadoop学习(3)-mapreduce快速入门加yarn的安装的更多相关文章
- Hadoop学习篇1 快速入门
Hadoop是Apache Lucene创始人Doug Cutting创建的,Hadoop起源于Apache Nutch,一个开源的网络搜索引擎.最先引起注意是2003年google的一篇论文,该论文 ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- MyBatis学习总结-MyBatis快速入门的系列教程
MyBatis学习总结-MyBatis快速入门的系列教程 [MyBatis]MyBatis 使用教程 [MyBatis]MyBatis XML配置 [MyBatis]MyBatis XML映射文件 [ ...
- Hadoop学习(1)-- 入门介绍
Hadoop是Apache基金会开发的一个分布式系统基础架构,是时下最流行的分布式系统架构之一.用户可以在不了解分布式底层的情况下,在Hadoop上快速进行分布式应用的开发,并利用集群的计算和存储能力 ...
- php随笔3-thinkphp 学习-ThinkPHP3.1快速入门(1)基础
ThinkPHP3.1快速入门(1)基础 简介 ThinkPHP是一个快速.简单的基于MVC和面向对象的轻量级PHP开发 框架,遵循Apache2开源协议发布,从诞生以来一直秉承简洁实用的设计原则,在 ...
- Hadoop学习(4)-mapreduce的一些注意事项
关于mapreduce的一些注意细节 如果把mapreduce程序打包放到了liux下去运行, 命令java –cp xxx.jar 主类名 如果报错了,说明是缺少相关的依赖jar包 用命令had ...
- MyBatis入门学习教程-MyBatis快速入门
一.Mybatis介绍 MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以 ...
- MyBatis学习总结_01_MyBatis快速入门
一.Mybatis介绍 MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以 ...
- php随笔4-thinkphp 学习-ThinkPHP3.1快速入门(2)数据CURD
ThinkPHP3.1快速入门(2)数据CURD 浏览:194739 发布日期:2012/09/05 分类:文档教程 关键字: 快速入门 CURD 上一篇中,我们了解了ThinkPHP的基础部分, ...
随机推荐
- qtchooser - a wrapper used to select between Qt development binary(2种方法)
---------------------------------------------------------------------------------------------------- ...
- XPath概述
1. XPath 具体示例可参考网址: http://www.zvon.org/xxl/XPathTutorial/General/examples.html 1.1 概述 * 现节点下所有元素 * ...
- UILabel范例实现代码如下
#import "TWO_ViewController.h" #define SCREEN_Width [[UIScreen mainScreen] bounds].siz ...
- Linux正则和grep命令
设置命令的默认参数和别名 每次都要输入 ls -l ,烦不烦,我想用 ll 来表示 ls -l, 可以,只要在 ~/.bashrc 中加上 alias ll='ls -l' ,然后运行 source ...
- git如何merge github forked repository里的代码更新
git如何merge github forked repository里的代码更新? 问题是这样的,github里有个项目ruby-gmail,我需要从fork自同一个项目的另一个repository ...
- 浅谈jpa、hibernate与spring data jpa三者之间的关系
1.解释hibernate之前先了解下什么是orm,orm是object relation mapping,即对象关系映射,object可以理解成java实体类Entity,relation是关系型数 ...
- Nginx+Keepalived部署流程
环境介绍 1)LB01 Hostname:lb01.example.com VIP:192.168.3.33(eth0:0) IP:192.168.3.31(eth0) OS:Centos 7 2)L ...
- kubernetes client-go解析
注:本次使用的client-go版本为:client-go 11.0,主要参考CSDN上的深入浅出kubernetes之client-go系列,建议看本文前先参考该文档.本文档为CSDN文档的深挖和补 ...
- leadcode的Hot100系列--78. 子集--回溯
上一篇说了使用位运算来进行子集输出,这里使用回溯的方法来进行排序. 回溯的思想,我的理解就是: 把解的所有情况转换为树或者图,然后用深度优先的原则来对所有的情况进行遍历解析. 当然,因为问题中会包涵这 ...
- 玲珑OJ 1082:XJT Loves Boggle(爆搜)
http://www.ifrog.cc/acm/problem/1082 题意:给出的单词要在3*3矩阵里面相邻连续(相邻包括对角),如果不行就输出0,如果可行就输出对应长度的分数. 思路:爆搜,但是 ...